Destinada a ser implementada no Android Open Source Project (AOSP), esta explicação técnica discute a motivação por trás da personalização no dispositivo (ODP, na sigla em inglês), os princípios de design que orientam o desenvolvimento dela, a privacidade via modelo de confidencialidade e como ela ajuda a garantir uma experiência particular.
Planejamos fazer isso simplificando o modelo de acesso a dados e garantindo que todos os dados do usuário que saírem do limite de segurança sejam diferencialmente particulares no nível por (usuário, adotante, model_instance) (às vezes encurtado para nível do usuário neste documento).
Todo o código relacionado à possível saída de dados do usuário final dos dispositivos deles será de código aberto e poderá ser verificado por entidades externas. Nas etapas iniciais da nossa proposta, buscamos gerar interesse e coletar feedback sobre uma plataforma que facilite oportunidades de personalização no dispositivo. Convidamos as partes interessadas, como especialistas em privacidade, analistas de dados e profissionais de segurança, a enviar respostas e feedback.
Visão
A personalização no dispositivo foi criada para proteger as informações dos usuários finais de empresas com quem eles não interagiram. As empresas podem continuar personalizando os produtos e serviços delas para os usuários finais (por exemplo, usando modelos de aprendizado de máquina devidamente anonimizados e com privacidade diferenciada), mas não será possível conferir as personalizações exatas feitas para um usuário final, o que depende não apenas da regra de personalização gerada pelo proprietário da empresa, mas também da preferência individual do usuário final, a menos que haja interações diretas com a empresa. Se uma empresa produzir modelos de aprendizado de máquina ou análises estatísticas, a ODP vai tentar garantir que eles sejam devidamente anonimizados usando os mecanismos de privacidade diferencial adequados.
Nosso plano atual é analisar a ODP em vários marcos, abrangendo os recursos e funcionalidades abaixo. Também convidamos as partes interessadas a sugerir de maneira construtiva outros recursos ou fluxos de trabalho para promover essa análise:
- Um ambiente em sandbox em que toda a lógica de negócios é contida e executada, permitindo que vários indicadores de usuários finais entrem no sandbox ao mesmo tempo que limita as saídas.
Armazenamentos de dados com criptografia de ponta a ponta para:
- Controles de usuário e outros dados relacionados ao usuário. Podem ser fornecidos pelo usuário final ou coletados e inferidos por empresas, bem como controles de time to live (TTL), políticas de exclusão de dados, políticas de privacidade e muito mais.
- Configurações da empresa. A ODP oferece algoritmos para compactar ou ofuscar esses dados.
- Resultados do processamento de empresas. Esses resultados podem ser:
- Consumidos como entradas em etapas futuras de processamento.
- Anonimizados com ruído de acordo com os mecanismos de privacidade diferencial adequados e enviados para endpoints qualificados.
- Enviados usando o fluxo de upload confiável para ambientes de execução confiáveis (TEE) que executam cargas de trabalho de código aberto com mecanismos centrais adequados de privacidade diferencial.
- Mostrados aos usuários finais.
APIs projetadas para:
- Atualizar 2(a), por lote ou de forma incremental.
- Atualizar 2(b) periodicamente, por lote ou de forma incremental.
- Fazer upload de 2(c), com mecanismos de ruído adequados em ambientes de agregação confiáveis. Esses resultados podem se tornar 2(b) para as próximas etapas de processamento.
Cronograma
Este é o plano de registro atual para testar a ODP na versão Beta. O cronograma está sujeito a mudanças.
| Recurso | 1º semestre de 2025 | 3o trimestre de 2025 |
|---|---|---|
| Treinamento no dispositivo + inferência | Entre em contato com a equipe do Sandbox de privacidade para discutir possíveis opções de teste durante esse período. | Começa a ser lançada para dispositivos Android T ou versões mais recentes qualificados. |
Princípios de design
Existem três pilares que a ODP busca equilibrar: privacidade, imparcialidade e utilidade.
Modelo de dados em torre para proteção de privacidade reforçada
A ODP segue a privacidade desde a concepção (link em inglês) e foi projetada com a proteção da privacidade do usuário final por padrão.
Ela explora como mover o processamento da personalização para o dispositivo de um usuário final. Essa abordagem equilibra privacidade e utilidade, mantendo os dados no dispositivo o máximo possível e fazendo o processamento fora do dispositivo apenas quando necessário. A ODP se concentra em:
- Controle dos dados do usuário final no dispositivo, mesmo quando eles saem do aparelho. Os destinos precisam ser ambientes de execução confiáveis atestados oferecidos por provedores de nuvem pública com um código criado pela ODP em execução.
- Verificação do dispositivo em relação ao que acontece com os dados do usuário final quando eles saem do aparelho. A ODP oferece cargas de trabalho de computação federada e código aberto para coordenar o aprendizado de máquina entre dispositivos e a análise estatística dos usuários. O dispositivo de um usuário final vai atestar que essas cargas de trabalho são executadas em ambientes de execução confiáveis sem modificações.
- Privacidade técnica garantida (por exemplo, agregação, ruído, privacidade diferencial) de saídas que saem do limite controlado/verificável do dispositivo.
Como resultado, a personalização será específica para cada aparelho.
Além disso, as empresas também exigem medidas de privacidade, que a plataforma precisa atender. Isso envolve manter dados brutos da empresa nos respectivos servidores. Para isso, a ODP adota o modelo de dados abaixo:
- Cada fonte de dados brutos será armazenada no dispositivo ou no servidor, permitindo aprendizado e inferência locais.
- Vamos fornecer algoritmos para facilitar a tomada de decisões em várias fontes de dados, como filtragem entre dois locais de dados ou treinamentos diferentes ou inferência em várias fontes.
Nesse contexto, pode haver uma torre da empresa e uma torre do usuário final:
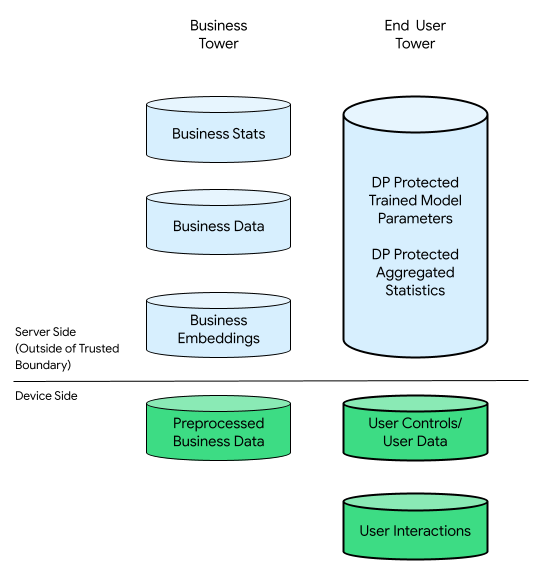
Consiste em dados fornecidos pelo usuário final (por exemplo, informações e controles da conta), dados coletados relacionados às interações de um usuário final com o dispositivo e dados derivados (por exemplo, interesses e preferências) inferidos pela empresa. Os dados inferidos não substituem as declarações diretas do usuário.
Para fins de comparação, em uma infraestrutura centrada na nuvem, todos os dados brutos da torre do usuário final são transferidos para os servidores da empresa. Por outro lado, em uma infraestrutura centrada em dispositivos, todos os dados brutos da torre do usuário final permanecem na origem, enquanto os dados da empresa permanecem armazenados nos servidores.
A personalização no dispositivo combina o melhor dos dois mundos, ativando apenas códigos de código aberto atestados para processar dados com potencial de se relacionar com usuários finais em TEEs com canais de saída mais particulares.
Engajamento público inclusivo para soluções equitativas
A ODP busca garantir um ambiente equilibrado para todos os participantes em um ecossistema diversificado. Reconhecemos a complexidade desse ecossistema, que consiste em várias empresas oferecendo serviços e produtos distintos.
Para inspirar a inovação, a ODP oferece APIs que podem ser implementadas pelos desenvolvedores e pelas empresas que eles representam. A personalização no dispositivo facilita a integração dessas implementações e gerencia versões, garante o monitoramento e oferece ferramentas para desenvolvedores e de feedback. A personalização no dispositivo não cria nenhuma lógica de negócios concreta, mas serve como catalisador da criatividade.
Ela pode oferecer mais algoritmos com o tempo. A colaboração com o ecossistema é essencial para determinar o nível certo de recursos e, possivelmente, estabelecer um limite razoável de recursos de dispositivos para cada empresa participante. Aguardamos o feedback do ecossistema para nos ajudar a reconhecer e priorizar novos casos de uso.
Utilitário do desenvolvedor para melhorar a experiência do usuário
Com a ODP, não há perda de dados de eventos ou atrasos de observação, já que todos os eventos são gravados localmente no dispositivo. Não há erros de mesclagem, e todos os eventos são associados a um dispositivo específico. Como resultado, todos os eventos observados naturalmente formam uma sequência cronológica que reflete as interações do usuário.
Esse processo simplificado elimina a necessidade de mesclar ou reorganizar dados, permitindo a acessibilidade dos dados do usuário quase em tempo real e sem perdas. Isso pode melhorar a utilidade que os usuários finais percebem ao interagir com produtos e serviços baseados em dados, podendo levar a maiores níveis de satisfação e experiências mais significativas. Com a ODP, as empresas podem se adaptar efetivamente às necessidades dos usuários.
O modelo de privacidade: privacidade via confidencialidade
Nas próximas seções, vamos discutir o modelo consumidor-produtor como base desta análise de privacidade e comparar a privacidade do ambiente de computação com a precisão da saída.
Modelo consumidor-produtor como base desta análise de privacidade
Vamos usar o modelo consumidor-produtor para examinar as garantias de privacidade da privacidade via confidencialidade. As computações nesse modelo são representadas como nós em um gráfico acíclico dirigido (DAG) que consiste em nós e subgráficos. Cada nó de computação tem três componentes: entradas consumidas, saídas produzidas e computação que mapeia entradas para saídas.

Nesse modelo, a proteção de privacidade se aplica aos três componentes:
- Privacidade de entrada. Os nós podem ter dois tipos de entrada. Se uma entrada é gerada por um nó anterior, ela já tem as garantias de privacidade de saída dele. Caso contrário, as entradas precisam limpar as políticas de entrada de dados usando o mecanismo de políticas.
- Privacidade de saída. A saída pode precisar ser privatizada, como quando é fornecida pela privacidade diferencial (DP, na sigla em inglês).
- Confidencialidade do ambiente de computação. A computação precisa ocorrer em um
ambiente fechado com segurança, garantindo que ninguém tenha acesso a
estados intermediários dentro de um nó. As tecnologias que permitem isso incluem
computação federada (FC), ambientes de execução confiáveis (TEE) baseados em
hardware, computação segura de várias partes (sMPC), criptografia homomórfica (HPE)
e muito mais (siglas em inglês). A privacidade por confidencialidade protege
estados intermediários, e todas as saídas fora do limite de confidencialidade
ainda precisam ser protegidas por mecanismos de privacidade diferencial. Confira duas
declarações obrigatórias:
- Confidencialidade de ambientes, garantindo que apenas as saídas declaradas saiam do ambiente, e
- Solidez, permitindo deduções precisas de declarações de privacidade de saída das declarações de privacidade de entrada. A solidez permite a propagação de propriedades de privacidade em um DAG.
Um sistema particular mantém a privacidade de entrada, a confidencialidade do ambiente de computação e a privacidade de saída. No entanto, o número de aplicativos dos mecanismos de privacidade diferencial pode ser reduzido selando mais processamento em um ambiente de computação confidencial.
Esse modelo oferece duas vantagens principais. Primeiro, a maioria dos sistemas, grandes e pequenos, pode ser representada como um DAG. Em segundo lugar, as propriedades de pós-processamento (Seção 2.1) e composição Lemma 2.4 em The Complexity of Differential Privacy de DP oferecem ferramentas poderosas para analisar a relação de privacidade e precisão (no pior dos casos) em um gráfico inteiro (links em inglês):
- O pós-processamento garante que, quando uma quantidade for privatizada, ela não poderá ser "desprivatizada" se os dados originais não forem usados de novo. Contanto que todas as entradas de um nó sejam particulares, a saída dele será particular, independente dos cálculos.
- A composição avançada garante que, se cada parte do gráfico tiver DP, o gráfico geral também terá, limitando o ε e δ do resultado final de um gráfico em aproximadamente ε√κ, respectivamente, supondo que o gráfico tenha unidades κ e a saída de cada uma seja (ε, δ)-DP.
Essas duas propriedades se traduzem em dois princípios de design para cada nó:
- Propriedade 1 (de pós-processamento): se as entradas de um nó todas tiverem DP, a saída terá DP, acomodando qualquer lógica de negócios arbitrária executada no nó e oferecendo suporte aos "ingredientes secretos" das empresas.
- Propriedade 2 (da composição avançada): se as entradas de um nó não tiverem DP, a saída dele precisará ser compatível com a DP. Se um nó de computação for executado em ambientes de execução confiáveis e estiver executando cargas de trabalho e configurações de código aberto fornecidos pela personalização no dispositivo, será possível usar limites de DP mais rígidos. Caso contrário, a personalização no dispositivo talvez precise usar limites de DP de pior caso. Devido a restrições de recursos, os ambientes de execução confiáveis oferecidos por um provedor de nuvem pública serão priorizados.
Privacidade do ambiente de computação em comparação com a precisão de saída
Assim sendo, a personalização no dispositivo vai se concentrar em melhorar a segurança de ambientes de computação confidencial e garantir que os estados intermediários permaneçam inacessíveis. Esse processo de segurança, conhecido como isolamento, será aplicado no nível do subgráfico, permitindo que vários nós sejam compatíveis com DP ao mesmo tempo. Isso significa que a propriedade 1 e a propriedade 2 mencionadas anteriormente se aplicam ao nível do subgráfico.

É claro que a saída do gráfico final, a Saída 7, tem DP por composição. Isso significa que haverá 2 DPs no total para esse gráfico, em comparação com 3 DPs totais (locais) se nenhuma vedação for usada.
Essencialmente, ao proteger o ambiente de computação e eliminar oportunidades para adversários acessarem as entradas e estados intermediários de um gráfico ou subgráfico, isso permite a implementação de DP central (ou seja, a saída de um ambiente fechado é compatível com DP), o que pode melhorar a precisão em comparação com a DP local (ou seja, as entradas individuais são compatíveis com DP). Esse princípio é a base da consideração de FCs, TEEs, sMPCs e HPEs como tecnologias de privacidade. Consulte o capítulo 10 em The Complexity of Differential Privacy (link em inglês).
Um exemplo bom e prático é o treinamento de modelo e a inferência. As discussões abaixo presumem que (1) a população de treinamento e a de inferência se sobrepõem e (2) os recursos e rótulos constituem dados particulares do usuário. Podemos aplicar DP a todas as entradas:

A personalização no dispositivo pode aplicar DP local a identificadores e recursos do usuário antes de enviá-los aos servidores. Essa abordagem não impõe requisitos ao ambiente de execução do servidor nem à lógica de negócios dele.



Este é o design atual da personalização no dispositivo.
Privacidade comprovável
O objetivo da personalização no dispositivo é que seja possível comprovar a privacidade. Ela coloca o foco em verificar o que acontece nos dispositivos dos usuários. A ODP vai criar o código que processa os dados que saem dos dispositivos dos usuários finais e usar a arquitetura de procedimentos de atestado remoto (RATS, na sigla em inglês) RFC 9334 do NIST para atestar que esse código está em execução sem modificações em um servidor desprivilegiado de administrador de instância compatível com o Confidential Computing Consortium (links em inglês). Esses códigos terão código aberto e poderão ser acessados para verificação transparente para gerar confiança. Essas medidas dão às pessoas a confiança de que os dados delas estão protegidos, e as empresas podem estabelecer reputações baseadas em uma fundação sólida de garantia de privacidade.
A redução da quantidade de dados particulares coletados e armazenados é outro aspecto essencial da personalização no dispositivo. Ela adere a esse princípio adotando tecnologias como a computação federada e a privacidade diferencial, o que permite a revelação de padrões de dados valiosos sem expor detalhes confidenciais individuais ou informações identificáveis.
A manutenção de uma trilha de auditoria que registre atividades relacionadas ao processamento e compartilhamento de dados é outro aspecto importante da privacidade comprovável. Isso permite a criação de relatórios de auditoria e a identificação de vulnerabilidades, demonstrando nosso compromisso com a privacidade.
Pedimos colaborações construtivas de especialistas em privacidade, autoridades, setores e indivíduos para nos ajudar a melhorar cada vez mais o design e as implementações.
O gráfico abaixo mostra o caminho do código para agregação entre dispositivos e ruídos por privacidade diferencial.
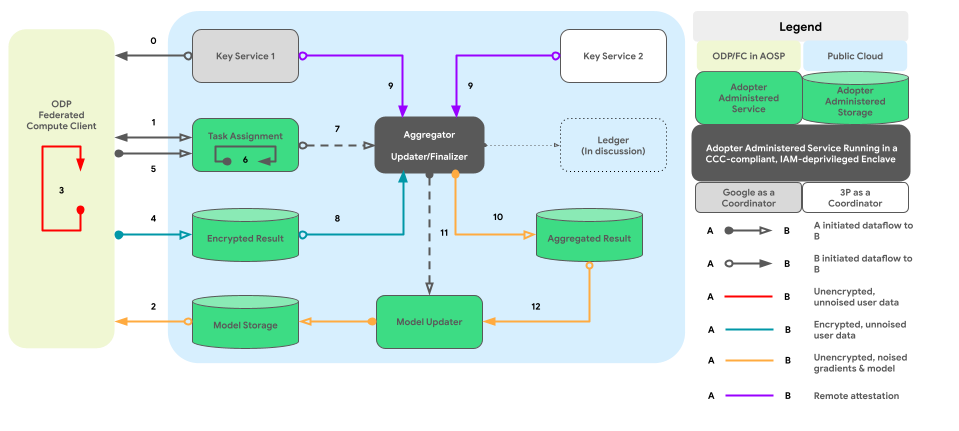
Design de alto nível
Como implementar a privacidade via confidencialidade? Em um alto nível, um mecanismo de política criado pela ODP e executado em um ambiente fechado serve como o principal componente responsável pela supervisão de cada nó/subgráfico ao mesmo tempo que rastreia o status de DP das entradas e saídas:
- Do ponto de vista do mecanismo de política, os dispositivos e servidores são tratados da mesma forma. Os dispositivos e servidores que executam um mecanismo de política idêntico são considerados logicamente idênticos, já que os mecanismos foram atestados mutuamente.
- Em dispositivos, o isolamento é alcançado por processos isolados do AOSP (ou pKVM a longo prazo, quando a disponibilidade fica alta). Nos servidores, o isolamento depende de uma "parte confiável", que é um TEE com outras soluções técnicas de selamento de preferência, um acordo contratual ou ambos.
Em outras palavras, todos os ambientes selados que instalam e executam o mecanismo de política da plataforma são considerados parte da nossa base de computação confiável (TCB, link e sigla em inglês). Com a TCB, os dados podem ser propagados sem ruído extra. A DP precisa ser aplicada quando os dados saem da TCB.
O design de alto nível da personalização no dispositivo integra dois elementos essenciais:
- Arquitetura de processos pareados para execução de lógica de negócios
- Políticas e um mecanismo de política para gerenciar operações de entrada e saída de dados, bem como operações permitidas
Esse design coeso oferece às empresas um nível de igualdade em que elas podem executar o código reservado em um ambiente de execução confiável e acessar dados do usuário que tenham passado pelas verificações de política adequadas.
As seções abaixo detalham esses dois aspectos importantes.
Arquitetura de processos pareados para execução de lógica de negócios
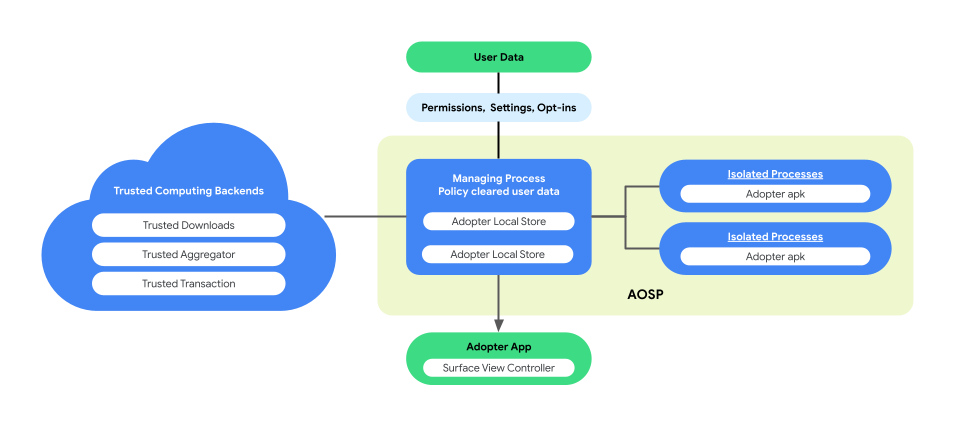
A personalização no dispositivo apresenta uma arquitetura de processos pareados no AOSP para melhorar a privacidade do usuário e a segurança dos dados durante a execução da lógica de negócios. Essa arquitetura consiste em dois processos:
ManagingProcess. Esse processo cria e gerencia IsolatedProcesses, garantindo que permaneçam isolados no nível de processo, com acesso limitado a APIs da lista de permissões sem permissão de rede ou disco. O ManagingProcess processa a coleta de todos os dados da empresa, todos os dados do usuário final e a limpeza deles de acordo com a política para o código comercial, enviando-os para execução em IsolatedProcesses. Além disso, ele media a interação entre IsolatedProcesses e outros processos, como system_server.
IsolatedProcess. Designado como isolado (
isolatedprocess=trueno manifesto), este processo recebe dados da empresa, dados de usuários finais limpos pela política e códigos comerciais de ManagingProcess. Isso permite que o código comercial opere nos próprios dados e nos dados do usuário final que passaram pela política. O IsolatedProcess se comunica exclusivamente com o ManagingProcess para entrada e saída, sem outras permissões.
A arquitetura de processos pareados oferece a oportunidade de verificação independente das políticas de privacidade de dados do usuário final, sem exigir que as empresas tenham código aberto da lógica ou código de negócios. Com o ManagingProcess mantendo a independência de IsolatedProcesses, que executa com eficiência a lógica de negócios, essa arquitetura garante uma solução mais segura e eficiente para preservar a privacidade do usuário durante a personalização.
A figura abaixo mostra essa arquitetura de processos pareados.
Políticas e mecanismos de política para operações de dados
A personalização no dispositivo apresenta uma camada de aplicação de políticas entre a plataforma e a lógica de negócios. O objetivo é fornecer um conjunto de ferramentas que mapeie controles comerciais e de usuários finais para decisões de política centralizadas e acionáveis. Em seguida, essas políticas são aplicadas de maneira abrangente e confiável em fluxos e empresas.
Na arquitetura de processos pareados, o mecanismo de política fica dentro do ManagedProcess, supervisionando a entrada e saída de dados do usuário final e da empresa. Ele também oferece operações da lista de permissões para IsolatedProcess. Os exemplos incluem o cumprimento do controle pelo usuário final, proteção à criança, prevenção de compartilhamento de dados sem consentimento e privacidade empresarial.
Essa arquitetura de aplicação de política compreende três tipos de fluxos de trabalho que podem ser aproveitados:
- Fluxos de trabalho off-line iniciados localmente com comunicações de ambientes de execução confiáveis
(TEE):
- Fluxos de download de dados: downloads confiáveis
- Fluxos de upload de dados: transações confiáveis
- Fluxos de trabalho on-line iniciados localmente:
- Fluxos de veiculação em tempo real
- Fluxos de inferência
- Fluxos de trabalho off-line iniciados localmente:
- Fluxos de otimização: treinamento de modelo no dispositivo implementado usando o aprendizado federado (FL, na sigla em inglês)
- Fluxos de relatórios: agregação entre dispositivos implementada usando a análise federada (FA, na sigla em inglês)
A figura abaixo mostra a arquitetura da perspectiva das políticas e dos mecanismos de política.
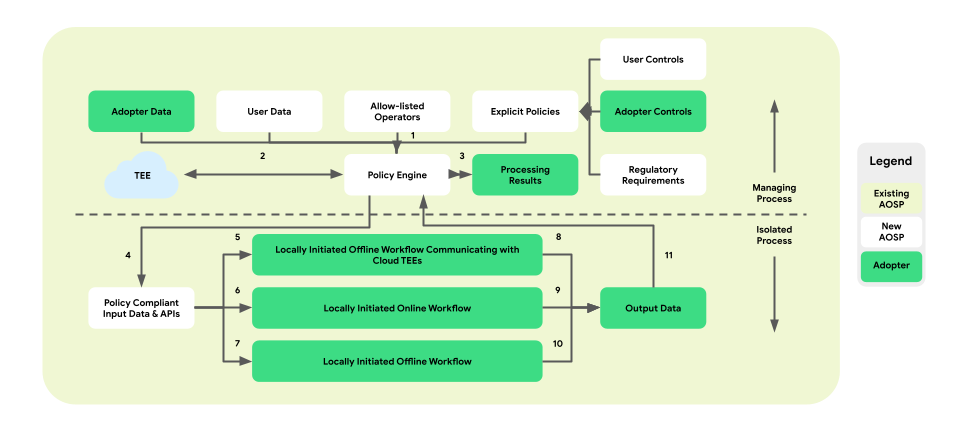
- Download: 1 -> 2 -> 4 -> 7 -> 10 -> 11 -> 3
- Veiculação: 1 + 3 -> 4 -> 6 -> 9 -> 11 -> 3
- Otimização: 2 (fornece um plano de treinamento) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
- Relatórios: 3 (fornece um plano de agregação) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
Em geral, a introdução da camada de aplicação de políticas e do mecanismo de políticas na arquitetura de processos pareados da personalização no dispositivo garante um ambiente isolado que preserva a privacidade para executar a lógica de negócios e oferecer acesso controlado às operações e aos dados necessários.
Superfícies de API em camadas
A personalização no dispositivo oferece uma arquitetura de API em camadas para as empresas interessadas. A camada superior consiste em aplicativos criados para casos de uso específicos. As empresas podem conectar os dados delas a esses aplicativos, conhecidos como APIs de camada superior. As APIs de camada superior são criadas com base nas APIs de camada intermediária.
Com o tempo, esperamos adicionar mais APIs de camada superior. Quando uma API de camada superior não está disponível para um caso de uso específico ou quando as APIs de camada superior existentes não são flexíveis o suficiente, as empresas podem implementar diretamente as APIs de camada intermediária, que fornecem potência e flexibilidade usando primitivos de programação.
Conclusão
A personalização no dispositivo é uma proposta de pesquisa em estágio inicial para solicitar interesse e feedback sobre uma solução de longo prazo que aborda as preocupações com a privacidade do usuário final com as melhores e mais recentes tecnologias, que podem oferecer um alto nível de utilidade.
Queremos interagir com as partes interessadas, como especialistas em privacidade, analistas de dados e possíveis usuários finais, para garantir que a ODP atenda às necessidades e esclareça as preocupações delas.