Ditujukan untuk diimplementasikan di Project Open Source Android (AOSP), penjelasan teknis ini membahas motivasi di balik Personalisasi di Perangkat (ODP), prinsip desain yang memandu pengembangannya, privasinya melalui model kerahasiaan, dan bagaimana hal ini membantu memastikan pengalaman pribadi yang dapat diverifikasi.
Kami berencana mencapai hal ini dengan menyederhanakan model akses data dan memastikan semua data pengguna yang meninggalkan batas keamanan bersifat pribadi diferensial pada tingkat per- (pengguna, pengguna, model_instance) (terkadang dipersingkat ke tingkat pengguna dalam dokumen ini).
Semua kode yang terkait dengan potensi traffic keluar data pengguna akhir dari perangkat pengguna akhir akan bersifat open source dan dapat diverifikasi oleh entitas eksternal. Pada tahap awal proposal, kami berusaha membangkitkan minat dan mengumpulkan masukan untuk platform yang memfasilitasi peluang Personalisasi di Perangkat. Kami mengundang pemangku kepentingan seperti pakar privasi, analis data, dan praktisi keamanan untuk bergabung dengan kami.
Vision
Personalisasi di Perangkat dirancang untuk melindungi informasi pengguna akhir dari bisnis yang belum berinteraksi dengan mereka. Bisnis dapat terus menyesuaikan produk dan layanan mereka untuk pengguna akhir (misalnya menggunakan model machine learning yang memiliki privasi diferensial dan dianonimkan sebagaimana mestinya), tetapi mereka tidak akan dapat melihat penyesuaian sebenarnya yang dibuat untuk pengguna akhir (yang tidak hanya bergantung pada aturan penyesuaian yang dibuat oleh pemilik bisnis, tetapi juga pada preferensi setiap pengguna akhir) kecuali jika ada interaksi langsung antara bisnis dan pengguna akhir. Jika suatu bisnis memproduksi model machine learning atau analisis statistik, ODP akan berusaha memastikan bahwa model atau analisis tersebut dianonimkan dengan benar menggunakan mekanisme Privasi Diferensial yang sesuai.
Rencana kami saat ini adalah mengeksplorasi ODP dalam beberapa tonggak pencapaian yang mencakup fitur dan fungsi berikut. Kami juga mengundang pihak-pihak yang berminat untuk merekomendasikan fitur atau alur kerja tambahan secara konstruktif untuk melanjutkan eksplorasi ini:
- Lingkungan dalam sandbox tempat semua logika bisnis dimuat dan dijalankan, yang memungkinkan banyak sinyal pengguna akhir memasuki sandbox sekaligus membatasi output.
Penyimpanan data terenkripsi end-to-end untuk:
- Kontrol pengguna, dan data lain terkait pengguna. Data ini dapat disediakan atau dikumpulkan oleh pengguna akhir, dan disimpulkan oleh bisnis, beserta kontrol time to live (TTL), kebijakan penghapusan total, kebijakan privasi, dan lainnya.
- Konfigurasi bisnis. ODP menyediakan algoritma untuk mengompresi atau meng-obfuscate data ini.
- Hasil pemrosesan bisnis. Hasil ini dapat berupa:
- Digunakan sebagai input dalam putaran pemrosesan selanjutnya,
- Didengarkan sesuai mekanisme Privasi Diferensial yang sesuai dan diupload ke endpoint yang memenuhi syarat.
- Diupload menggunakan alur upload tepercaya ke Trusted Execution Environments (TEE) yang menjalankan beban kerja Open Source dengan mekanisme Privasi Diferensial pusat yang sesuai
- Ditampilkan ke pengguna akhir.
API yang didesain untuk:
- Update 2(a), secara batch atau bertahap.
- Update 2(b) secara berkala, baik batch maupun bertahap.
- Upload 2(c), dengan mekanisme derau yang sesuai di lingkungan agregasi yang tepercaya. Hasil tersebut dapat menjadi 2(b) untuk putaran pemrosesan berikutnya.
Prinsip-prinsip desain
Ada tiga pilar yang ingin diseimbangkan oleh ODP: privasi, keadilan, dan utilitas.
Model data bertingkat untuk perlindungan privasi yang ditingkatkan
ODP mengikuti Privasi dari Desain, dan dirancang dengan perlindungan privasi pengguna akhir sebagai default.
ODP mempelajari pemindahan pemrosesan personalisasi ke perangkat pengguna akhir. Pendekatan ini menyeimbangkan privasi dan utilitas dengan menyimpan data di perangkat sebanyak mungkin dan hanya memprosesnya di luar perangkat saat diperlukan. ODP berfokus pada:
- Kontrol perangkat atas data pengguna akhir, bahkan saat data tersebut keluar dari perangkat. Tujuan harus sudah teruji sebagai Trusted Execution Environment yang ditawarkan oleh penyedia cloud publik yang menjalankan kode yang ditulis ODP.
- Verifikasi perangkat atas apa yang terjadi pada data pengguna akhir jika data tersebut keluar dari perangkat. ODP menyediakan beban kerja Federated Compute, Open Source untuk mengoordinasikan analisis statistik dan machine learning lintas perangkat bagi penggunanya. Perangkat pengguna akhir akan membuktikan bahwa beban kerja tersebut dijalankan di Trusted Execution Environment yang tidak diubah.
- Privasi teknis yang terjamin (misalnya agregasi, derau, Privasi Diferensial) dari output yang keluar dari batas yang dikontrol perangkat/dapat diverifikasi.
Oleh karena itu, personalisasi akan bersifat spesifik per perangkat.
Selain itu, bisnis juga memerlukan langkah-langkah privasi yang harus ditangani oleh platform. Tindakan ini berarti mempertahankan data bisnis mentah di servernya masing-masing. Untuk mencapai hal ini, ODP mengadopsi model data berikut:
- Setiap sumber data mentah akan disimpan di perangkat atau sisi server sehingga memungkinkan pembelajaran dan inferensi lokal.
- Kami akan menyediakan algoritma untuk memfasilitasi pengambilan keputusan di berbagai sumber data, seperti memfilter antara dua lokasi data yang berbeda atau pelatihan atau inferensi di berbagai sumber.
Dalam konteks ini, mungkin ada menara bisnis dan menara pengguna akhir:
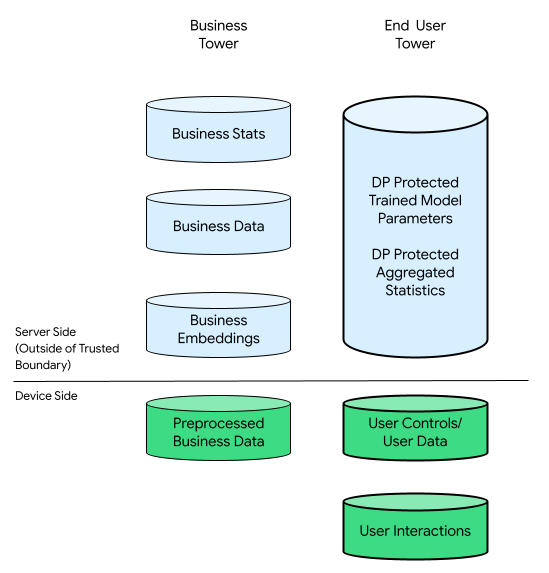
Menara pengguna akhir terdiri dari data yang disediakan oleh pengguna akhir (misalnya informasi dan kontrol akun), data yang dikumpulkan terkait interaksi pengguna akhir dengan perangkatnya, dan data turunan (misalnya, minat dan preferensi) yang disimpulkan oleh bisnis. Data yang disimpulkan tidak menimpa deklarasi langsung pengguna mana pun.
Sebagai perbandingan, dalam infrastruktur yang berfokus pada cloud, semua data mentah dari menara pengguna akhir akan ditransfer ke server bisnis. Sebaliknya, dalam infrastruktur yang berfokus pada perangkat, semua data mentah dari menara pengguna akhir tetap berada di asalnya, sementara data bisnis tetap disimpan di server.
Personalisasi Di Perangkat menggabungkan hal terbaik dari kedua hal tersebut dengan hanya mengaktifkan kode open source yang telah disahkan untuk memproses data yang memiliki potensi terkait dengan pengguna akhir di TEE menggunakan saluran output yang lebih pribadi.
Interaksi publik yang inklusif untuk solusi yang adil
ODP bertujuan memastikan lingkungan yang seimbang bagi semua peserta dalam ekosistem yang beragam. Kami menyadari kerumitan ekosistem ini, yang terdiri dari berbagai pemain yang menawarkan layanan dan produk berbeda.
Untuk menginspirasi inovasi, ODP menawarkan API yang dapat diterapkan oleh developer dan bisnis yang mereka wakili. Personalisasi di Perangkat memfasilitasi integrasi yang lancar dari implementasi ini sekaligus mengelola rilis, pemantauan, alat developer, dan alat masukan. Personalisasi di Perangkat tidak menghasilkan logika bisnis yang konkret, tetapi berfungsi sebagai katalisator untuk kreativitas.
ODP dapat menawarkan lebih banyak algoritma dari waktu ke waktu. Kolaborasi dengan ekosistem sangat penting dalam menentukan tingkat fitur yang tepat dan berpotensi menetapkan batas resource perangkat yang wajar untuk setiap bisnis yang berpartisipasi. Kami mengharapkan masukan dari ekosistem untuk membantu kami mengenali dan memprioritaskan kasus penggunaan baru.
Utilitas developer untuk meningkatkan pengalaman pengguna
Dengan ODP, tidak akan ada data peristiwa atau penundaan observasi karena semua peristiwa dicatat secara lokal di tingkat perangkat. Tidak ada error penggabungan, dan semua peristiwa dikaitkan dengan perangkat tertentu. Hasilnya, semua peristiwa yang diamati secara alami membentuk urutan kronologis yang mencerminkan interaksi pengguna.
Proses yang disederhanakan ini menghilangkan kebutuhan untuk menggabungkan atau mengatur ulang data sehingga memungkinkan aksesibilitas data pengguna yang mendekati real-time dan tidak hilang. Hasilnya, hal ini dapat meningkatkan utilitas yang dipahami pengguna akhir saat berinteraksi dengan produk dan layanan berbasis data sehingga berpotensi menghasilkan tingkat kepuasan yang lebih tinggi dan pengalaman yang lebih bermakna. Dengan ODP, bisnis dapat beradaptasi secara efektif dengan kebutuhan pengguna mereka.
Model privasi: privasi melalui kerahasiaan
Bagian berikut membahas model produsen-konsumen sebagai dasar analisis privasi ini, dan privasi lingkungan komputasi versus akurasi output.
Model produsen-konsumen sebagai dasar analisis privasi ini
Kami akan menggunakan model produsen-konsumen untuk memeriksa jaminan privasi dari privasi melalui kerahasiaan. Komputasi dalam model ini direpresentasikan sebagai node dalam Directed Acyclic Graph (DAG) yang terdiri dari node dan subgrafik. Setiap node komputasi memiliki tiga komponen: input yang digunakan, output yang dihasilkan, dan input pemetaan komputasi ke output.

Dalam model ini, perlindungan privasi berlaku untuk ketiga komponen:
- Privasi input. Node dapat memiliki dua jenis input. Jika input dihasilkan oleh node pendahulu, input tersebut sudah memiliki jaminan privasi output dari pendahulunya. Jika tidak, input harus lolos kebijakan traffic masuk data menggunakan mesin kebijakan.
- Privasi output. Output mungkin perlu diprivatisasi, seperti yang disediakan oleh Privasi Diferensial (DP).
- Kerahasiaan lingkungan komputasi. Komputasi harus terjadi dalam
lingkungan yang disegel dengan aman untuk memastikan tidak seorang pun memiliki akses ke
status perantara dalam node. Teknologi yang memungkinkan hal ini mencakup
Federated Computations (FC), Trusted Execution Environment
(TEE) berbasis hardware, Multi-Party Computation (sMPC) yang aman, enkripsi homomorfik (HPE),
dan banyak lagi. Perlu diperhatikan bahwa privasi melalui status perantara perlindungan kerahasiaan
dan semua output yang keluar dari batas kerahasiaan
masih perlu dilindungi oleh mekanisme Privasi Diferensial. Dua klaim
yang diperlukan adalah:
- Kerahasiaan lingkungan untuk memastikan bahwa output yang dideklarasikan keluar dari lingkungan, dan
- Kesehatan, memungkinkan pengurangan yang akurat atas klaim privasi output dari klaim privasi input. Tingkat kesehatan memungkinkan penyebaran properti privasi ke DAG.
Sistem pribadi menjaga privasi input, kerahasiaan lingkungan komputasi, dan privasi output. Namun, jumlah penerapan mekanisme Privasi Diferensial dapat dikurangi dengan menyegel lebih banyak pemrosesan di dalam lingkungan komputasi yang rahasia.
Model ini menawarkan dua keunggulan utama. Pertama, sebagian besar sistem, besar dan kecil, dapat direpresentasikan sebagai DAG. Kedua, properti Pasca-Pemrosesan [Section 2.1] dan komposisi Lemma 2.4 di The Complexity of Differential Privacy memberikan alat yang ampuh untuk menganalisis keseimbangan privasi dan akurasi (kasus terburuk) untuk seluruh grafik:
- Pasca-Pemrosesan menjamin bahwa setelah kuantitas diprivatisasi, kuantitas tidak dapat "dibatalkan privatisasinya" jika data asli tidak digunakan lagi. Selama semua input untuk node bersifat pribadi, output-nya akan bersifat pribadi, terlepas dari komputasinya.
- Komposisi Lanjutan menjamin bahwa jika setiap bagian grafik adalah DP, grafik keseluruhan juga demikian, secara efektif membatasi ε dan δ dari output akhir grafik kira-kira sebesar ε√κ, dengan asumsi grafik memiliki unit κ dan output setiap unit adalah (ε, δ)-DP.
Kedua properti ini diterjemahkan menjadi dua prinsip desain untuk setiap node:
- Properti 1 (Dari Pasca-Pemrosesan) jika semua input node adalah DP, output-nya adalah DP, yang mengakomodasi logika bisnis arbitrer apa pun yang dieksekusi dalam node, dan mendukung "rahasia sukses" bisnis.
- Properti 2 (Dari Komposisi Lanjutan) jika input node tidak semuanya DP, output-nya harus dibuat sesuai dengan DP. Jika node komputasi adalah node yang berjalan di Trusted Execution Environment dan mengeksekusi beban kerja dan konfigurasi open source yang disediakan Personalisasi di Perangkat, batas DP yang lebih ketat dimungkinkan. Jika tidak, Personalisasi di Perangkat mungkin perlu menggunakan batas DP dalam kasus terburuk. Karena keterbatasan resource, Trusted Execution Environment yang ditawarkan oleh penyedia cloud publik akan diprioritaskan pada awalnya.
Privasi lingkungan komputasi versus akurasi output
Oleh karena itu, Personalisasi di Perangkat akan berfokus pada peningkatan keamanan lingkungan komputasi rahasia dan memastikan bahwa status perantara tetap tidak dapat diakses. Proses keamanan ini, yang dikenal sebagai penyegelan, akan diterapkan pada tingkat subgrafik, sehingga beberapa node dapat dibuat sesuai DP secara bersamaan. Ini berarti bahwa properti 1 dan properti 2 yang disebutkan sebelumnya berlaku pada tingkat subgrafik.

Tentu saja output grafik akhir, Output 7, di-DP per komposisi. Artinya, akan ada 2 DP untuk grafik ini; dibandingkan dengan 3 DP (lokal) total jika tidak ada penyegelan yang digunakan.
Pada dasarnya, dengan mengamankan lingkungan komputasi dan menghilangkan peluang bagi penyerang untuk mengakses input dan status perantara grafik atau subgrafik, hal ini memungkinkan penerapan DP Pusat (yaitu, output lingkungan tertutup sesuai dengan DP), yang dapat meningkatkan akurasi dibandingkan dengan DP lokal (yaitu, input individual sesuai dengan DP). Prinsip ini mendasari pertimbangan FC, TEE, sMPC, dan HPE sebagai teknologi privasi. Lihat Bab 10 di Kompleksitas Privasi Diferensial.
Contoh praktis yang baik adalah pelatihan model dan inferensi. Diskusi di bawah mengasumsikan bahwa (1), populasi pelatihan dan populasi inferensi tumpang-tindih, dan (2), fitur maupun label merupakan data pengguna pribadi. Kita bisa menerapkan DP ke semua input:

Personalisasi di Perangkat dapat menerapkan DP lokal ke fitur dan label pengguna sebelum mengirimkannya ke server. Pendekatan ini tidak memberlakukan persyaratan apa pun pada lingkungan eksekusi server atau logika bisnisnya.



Ini adalah desain Personalisasi di Perangkat saat ini.
Terverifikasi pribadi
Tujuan Personalisasi di Perangkat adalah terverifikasi pribadi. Fokusnya adalah memverifikasi apa yang terjadi dari perangkat pengguna. ODP akan menulis kode yang memproses data yang keluar dari perangkat pengguna akhir dan akan menggunakan Arsitektur Prosedur Pengesahan Jarak Jauh (RATS) RFC 9334 NIST untuk membuktikan bahwa kode tersebut berjalan tanpa dimodifikasi dalam server yang tidak memiliki hak istimewa admin instance yang mematuhi Confidential Computing Consortium. Kode ini akan bersifat open source dan dapat diakses untuk verifikasi transparan guna membangun kepercayaan. Tindakan tersebut dapat memberikan keyakinan kepada individu bahwa data mereka terlindungi, dan bisnis dapat membangun reputasi berdasarkan landasan jaminan privasi yang kuat.
Mengurangi jumlah data pribadi yang dikumpulkan dan disimpan adalah aspek penting lainnya dari Personalisasi di Perangkat. Fitur ini mematuhi prinsip ini dengan mengadopsi teknologi seperti Federated Compute dan Privasi Diferensial sehingga pola data berharga dapat diungkap tanpa mengekspos detail individu yang sensitif atau informasi yang dapat diidentifikasi.
Mempertahankan jejak audit yang mencatat aktivitas terkait pemrosesan dan berbagi data ke dalam log adalah aspek utama lain dari privasi yang dapat diverifikasi. Hal ini memungkinkan pembuatan laporan audit dan identifikasi kerentanan yang menunjukkan komitmen kami terhadap privasi.
Kami meminta kolaborasi yang konstruktif dari para pakar privasi, otoritas, industri, dan individu untuk membantu kami terus meningkatkan desain dan implementasi.
Grafik di bawah menunjukkan jalur kode untuk derau dan agregasi lintas-perangkat sesuai Privasi Diferensial.
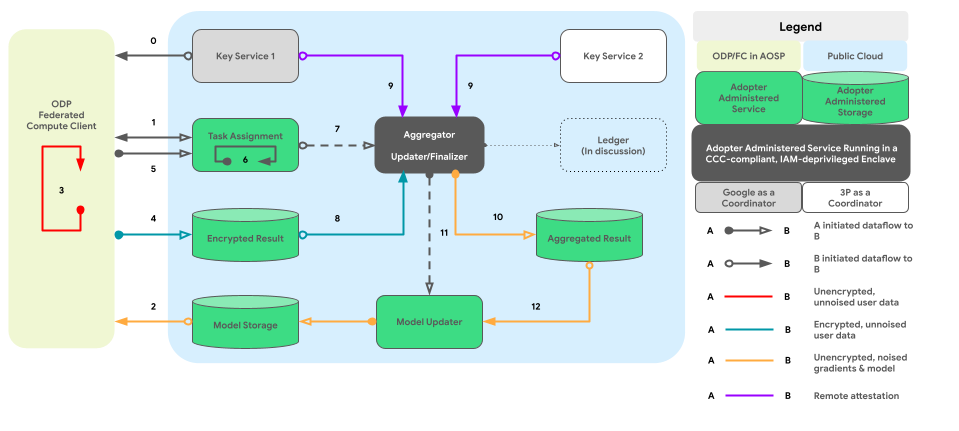
Desain tingkat tinggi
Bagaimana cara mengimplementasikan privasi melalui kerahasiaan? Pada tingkat tinggi, mesin kebijakan yang ditulis oleh ODP yang berjalan di lingkungan tersegel berfungsi sebagai komponen inti yang mengawasi setiap node/subgrafik sekaligus melacak status DP input dan output-nya:
- Dari perspektif mesin kebijakan, perangkat dan server diperlakukan dengan cara yang sama. Perangkat dan server yang menjalankan mesin kebijakan yang identik dianggap identik secara logis setelah mesin kebijakannya dibuktikan secara timbal balik.
- Di perangkat, isolasi dicapai melalui proses yang diisolasi AOSP (atau pKVM dalam jangka panjang setelah ketersediaannya menjadi tinggi). Pada server, isolasi bergantung pada "pihak tepercaya", yang bisa berupa TEE ditambah solusi penyegelan teknis lainnya yang lebih disukai, perjanjian kontrak, atau keduanya.
Dengan kata lain, semua lingkungan tersegel yang menginstal dan menjalankan mesin kebijakan platform dianggap sebagai bagian dari Trusted Computing Base (TCB) kami. Data dapat diterapkan tanpa derau tambahan dengan TCB. DP perlu diterapkan ketika data meninggalkan TCB.
Desain tingkat tinggi dari Personalisasi di Perangkat secara efektif mengintegrasikan dua elemen penting:
- Arsitektur proses berpasangan untuk eksekusi logika bisnis
- Kebijakan dan mesin kebijakan untuk mengelola operasi masuk, keluar, dan yang diizinkan.
Desain yang kohesif ini menawarkan peluang yang sama bagi bisnis untuk menjalankan kode eksklusifnya di Trusted Execution Environment, dan mengakses data pengguna yang telah lolos pemeriksaan kebijakan yang sesuai.
Bagian berikut akan menguraikan dua aspek utama ini.
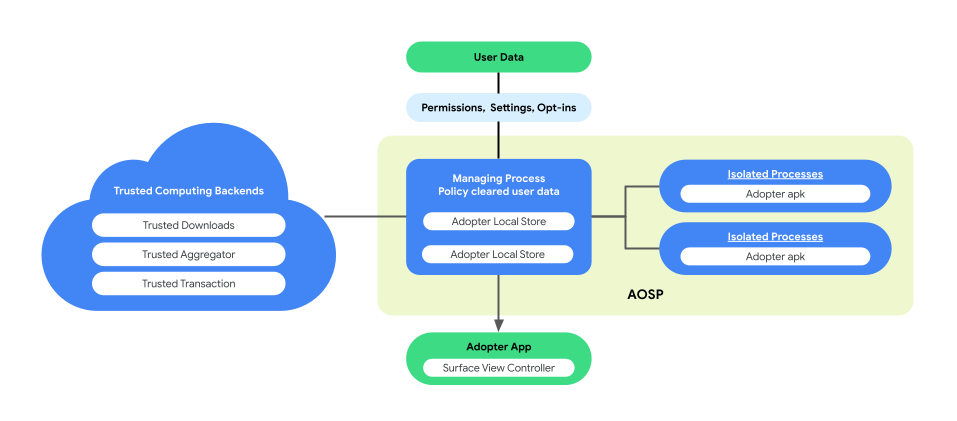
Arsitektur proses berpasangan untuk eksekusi logika bisnis
Personalisasi di Perangkat memperkenalkan arsitektur proses berpasangan di AOSP untuk meningkatkan privasi pengguna dan keamanan data selama eksekusi logika bisnis. Arsitektur ini terdiri dari:
ManagingProcess. Proses ini membuat dan mengelola IsolatedProcesses, memastikan proses tersebut tetap terisolasi di tingkat proses dengan akses yang terbatas pada API yang diizinkan dan tanpa izin disk atau jaringan. ManagingProcess menangani pengumpulan semua data bisnis, semua data pengguna akhir, dan kebijakan meloloskannya untuk kode bisnis untuk mendorongnya ke IsolatedProcesses untuk dieksekusi. Selain itu, proses ini memediasi interaksi antara IsolatedProcesses dan proses lain, seperti system_server.
IsolatedProcess. Ditetapkan sebagai terisolasi (
isolatedprocess=truedalam manifes), proses ini menerima data bisnis, data pengguna akhir yang telah lolos kebijakan, dan kode bisnis dari ManagingProcess. Proses ini memungkinkan kode bisnis beroperasi pada data dan data pengguna akhir yang telah lolos kebijakan. IsolatedProcess berkomunikasi secara eksklusif dengan ManagingProcess untuk traffic masuk maupun keluar, tanpa izin tambahan.
Arsitektur proses berpasangan memberikan peluang untuk verifikasi independen terhadap kebijakan privasi data pengguna akhir tanpa mengharuskan bisnis untuk menjadikan logika atau kode bisnis mereka sebagai open source. Dengan ManagingProcess yang menjaga independensi IsolatedProcesses, dan IsolatedProcesses yang menjalankan logika bisnis secara efisien, arsitektur ini memastikan solusi yang lebih aman dan efisien untuk menjaga privasi pengguna selama personalisasi.
Gambar berikut menunjukkan arsitektur proses yang berpasangan ini.
Kebijakan dan mesin kebijakan untuk operasi data
Personalisasi di Perangkat memperkenalkan lapisan penerapan kebijakan antara platform dan logika bisnis. Tujuannya adalah menyediakan serangkaian alat yang memetakan kontrol bisnis dan pengguna akhir menjadi keputusan kebijakan terpusat yang dapat ditindaklanjuti. Kebijakan ini kemudian ditegakkan secara komprehensif dan andal di seluruh alur dan bisnis.
Dalam arsitektur proses berpasangan, mesin kebijakan berada dalam ManagingProcess, yang mengawasi traffic masuk dan keluar data bisnis dan pengguna akhir. Arsitektur ini juga akan menyediakan operasi yang diizinkan untuk IsolatedProcess. Contoh area cakupan meliputi pemberian kontrol kepada pengguna akhir, perlindungan anak, pencegahan terhadap pembagian data tanpa izin, dan privasi bisnis.
Arsitektur penegakan kebijakan ini terdiri dari tiga jenis alur kerja yang dapat dimanfaatkan:
- Alur kerja offline yang dimulai secara lokal dengan komunikasi
Trusted Execution Environment (TEE):
- Alur download data: download tepercaya
- Alur upload data: transaksi tepercaya
- Alur kerja online yang dimulai secara lokal:
- Alur pelayanan real-time
- Alur inferensi
- Alur kerja offline yang dimulai secara lokal:
- Alur pengoptimalan: pelatihan model di perangkat yang diterapkan melalui Federated Learning (FL)
- Alur pelaporan: agregasi lintas-perangkat yang diterapkan melalui Federated Analytics (FA)
Gambar berikut menunjukkan arsitektur dari perspektif kebijakan dan mesin kebijakan.
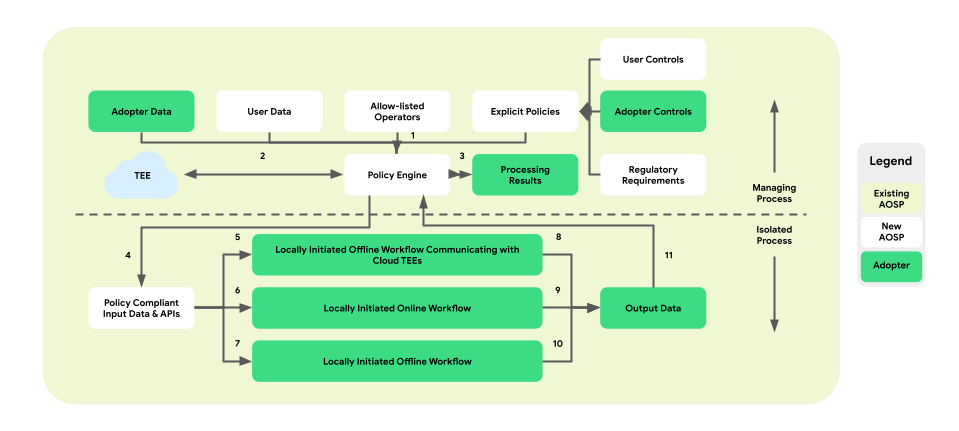
- Download: 1 -> 2 -> 4 -> 7 -> 10 -> 11 -> 3
- Pelayanan: 1 + 3 -> 4 -> 6 -> 9 -> 11 -> 3
- Pengoptimalan: 2 (memberikan rencana pelatihan) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
- Pelaporan: 3 (menyediakan rencana agregasi) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
Secara keseluruhan, pengenalan lapisan penegakan kebijakan dan mesin kebijakan dalam arsitektur proses berpasangan Personalisasi di Perangkat memastikan lingkungan yang terisolasi dan menjaga privasi untuk menjalankan logika bisnis sekaligus memberikan akses terkontrol ke data dan operasi yang diperlukan.
Platform API berlapis
Personalisasi di Perangkat menyediakan arsitektur API berlapis untuk bisnis yang berminat. Lapisan atas terdiri dari aplikasi yang dibangun untuk kasus penggunaan tertentu. Calon bisnis dapat menghubungkan data mereka ke aplikasi ini, yang dikenal sebagai API Lapisan Atas. API Lapisan Atas dibangun di atas API Lapisan Tengah.
Seiring waktu, kami berharap dapat menambahkan lebih banyak API Lapisan Atas. Jika API Lapisan Atas tidak tersedia untuk kasus penggunaan tertentu, atau jika API Lapisan Atas yang ada tidak cukup fleksibel, bisnis dapat langsung menerapkan API Lapisan Tengah, yang menyediakan dukungan dan fleksibilitas melalui primitif pemrograman.
Kesimpulan
Personalisasi di Perangkat adalah proposal riset tahap awal untuk mengetahui minat dan masukan tentang solusi jangka panjang yang menangani masalah privasi pengguna akhir dengan teknologi terbaru dan terbaik yang diharapkan dapat memberikan utilitas tinggi.
Kami ingin berinteraksi dengan pemangku kepentingan seperti pakar privasi, analis data, dan calon pengguna akhir untuk memastikan ODP memenuhi kebutuhan mereka dan menangani kekhawatiran mereka.