เกี่ยวกับเอกสารนี้
เมื่ออ่านบทความนี้ คุณจะทำสิ่งต่อไปนี้ได้
- ทำความเข้าใจกลยุทธ์ที่ควรสร้างก่อนสร้างรายงานสรุป
- ขอเชิญรู้จักกับ Noise Lab ซึ่งเป็นเครื่องมือที่ช่วยให้เข้าใจผลกระทบของพารามิเตอร์เสียงรบกวนต่างๆ รวมถึงช่วยให้สำรวจและประเมินกลยุทธ์การจัดการเสียงรบกวนต่างๆ ได้อย่างรวดเร็ว
แชร์ความคิดเห็น
แม้ว่าเอกสารนี้จะสรุปหลักการ 2-3 ข้อในการทำงานกับรายงานสรุป การจัดการเสียงรบกวนมีอยู่หลายวิธีด้วยกันที่อาจยังไม่เห็น ที่นี่ เรายินดีรับฟังคำแนะนำ ข้อมูลเสริม และคำถามของคุณ
- หากต้องการแสดงความคิดเห็นแบบสาธารณะเกี่ยวกับกลยุทธ์การจัดการเสียงรบกวน ให้เปิด ยูทิลิตีหรือความเป็นส่วนตัวของ API (epsilon) และแชร์การสังเกตการณ์ของคุณเมื่อ จำลองด้วย Noise Lab: แสดงความคิดเห็นเกี่ยวกับปัญหานี้
- แสดงความคิดเห็นแบบสาธารณะเกี่ยวกับ Noise Lab (ถามคำถาม รายงานข้อบกพร่อง ขอฟีเจอร์): สร้างรายการใหม่ที่นี่
- หากต้องการแสดงความคิดเห็นแบบสาธารณะเกี่ยวกับอีกแง่มุมหนึ่งของ API ให้ทำดังนี้ สร้างรายการใหม่ที่นี่
ก่อนจะเริ่ม
- อ่านข้อมูลเบื้องต้นเกี่ยวกับการรายงานการระบุแหล่งที่มา: รายงานสรุป และภาพรวมระบบแบบเต็มของการรายงานการระบุแหล่งที่มา
- สแกนทำความเข้าใจสัญญาณรบกวนและทำความเข้าใจคีย์การรวมเพื่อใช้คู่มือนี้ให้เกิดประโยชน์สูงสุด
การตัดสินใจออกแบบ
หลักการออกแบบหลัก
มีความแตกต่างพื้นฐานระหว่างวิธีการทำงานของคุกกี้ของบุคคลที่สามและรายงานสรุป ความแตกต่างที่สำคัญอย่างหนึ่งคือ noise ลงในข้อมูลการวัดผลในรายงานสรุป อีกวิธีหนึ่งคือการตั้งเวลารายงาน
เพื่อเข้าถึงข้อมูลการวัดรายงานสรุปที่มีสัญญาณรบกวนสูงกว่า แพลตฟอร์มฝั่งซื้อ (DSP) และผู้ให้บริการวัดผลโฆษณาจะต้อง ทำงานร่วมกับผู้ลงโฆษณาเพื่อพัฒนากลยุทธ์การจัดการเสียงรบกวน เพื่อพัฒนากลยุทธ์เหล่านี้ DSP และผู้ให้บริการการวัดผลต้องเป็นผู้ตัดสินใจเรื่องการออกแบบ การตัดสินใจเหล่านี้เกี่ยวข้องกับแนวคิดสำคัญอย่างหนึ่ง นั่นคือ
แม้ว่าระบบจะดึงค่าสัญญาณรบกวนจากการกระจายมา แต่จริงๆ แล้วจะขึ้นอยู่กับ 2 พารามิเตอร์เท่านั้นค่ะ ⏤epsilon และงบประมาณการสนับสนุน⏤ คุณมีการควบคุมอื่นๆ มากมายซึ่งจะส่งผลต่อ อัตราส่วนสัญญาณต่อสัญญาณรบกวนของข้อมูลการวัดเอาต์พุต
แม้ว่าเราจะคาดหวังว่ากระบวนการปรับปรุงจะนำไปสู่การตัดสินใจที่ดีที่สุด แต่การเปลี่ยนแปลงแต่ละครั้งของการตัดสินใจเหล่านี้ นำไปสู่การติดตั้งที่แตกต่างกันเล็กน้อย จึงต้องทำการตัดสินใจเหล่านี้ก่อนที่จะเขียนโค้ดซ้ำ (และก่อนที่จะแสดงโฆษณา)
การตัดสินใจ: รายละเอียดมิติข้อมูล
ลองใช้งานใน Noise Lab
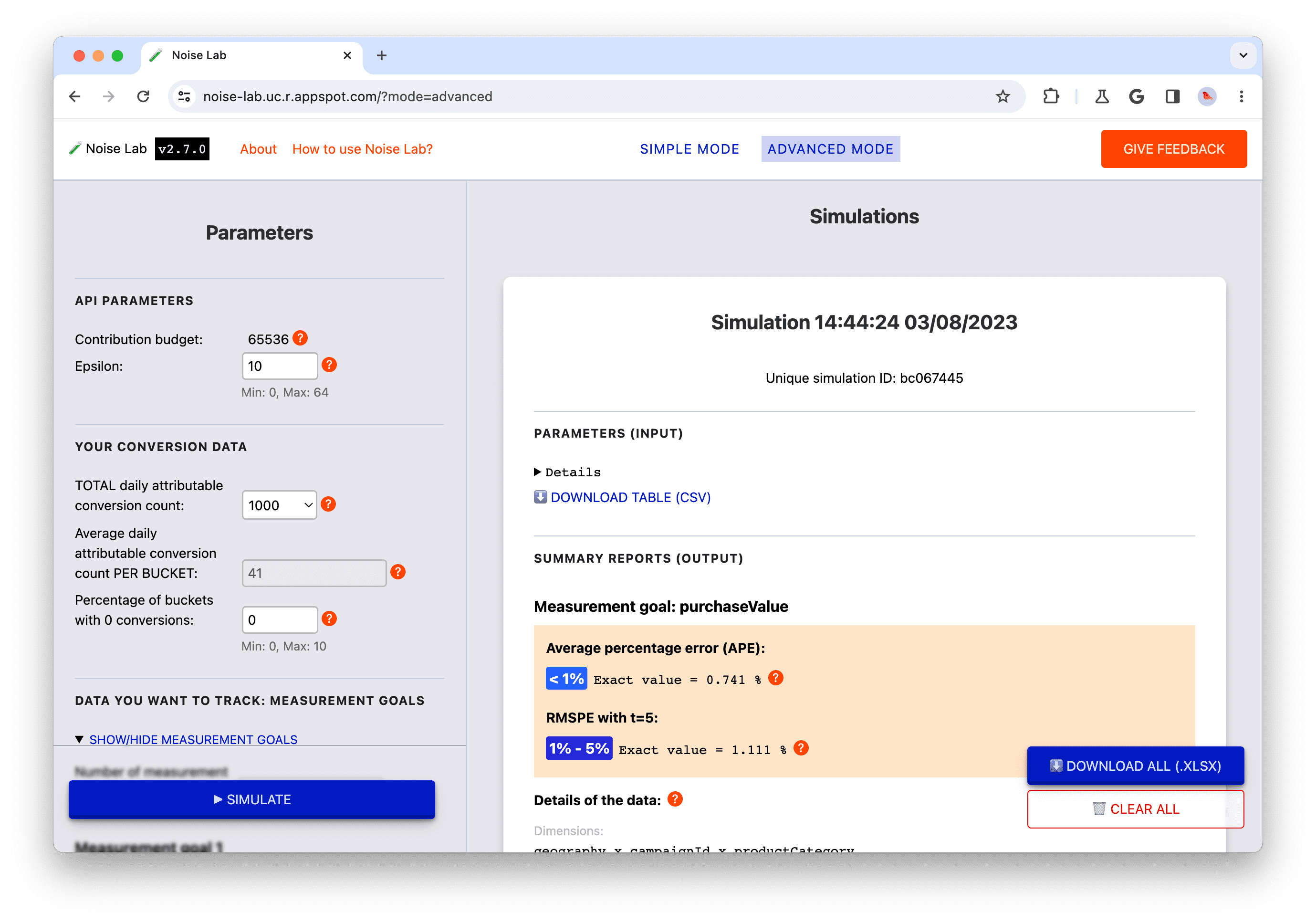
- ไปที่โหมดขั้นสูง
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหาข้อมูล Conversion ของคุณ
- สังเกตพารามิเตอร์เริ่มต้น โดยค่าเริ่มต้น เมตริก TOTAL ต่อวัน จำนวน Conversion ที่ระบุแหล่งที่มาได้คือ 1000 ซึ่งค่าเฉลี่ยจะอยู่ที่ประมาณ 40 ที่เก็บข้อมูลหากคุณใช้การตั้งค่าเริ่มต้น (มิติข้อมูลเริ่มต้น, จํานวนเริ่มต้นของ ค่าที่แตกต่างกันได้สำหรับแต่ละมิติข้อมูล กลยุทธ์คีย์ A) สังเกต ค่าเป็น 40 ในข้อมูลป้อนจำนวน Conversion ที่ระบุแหล่งที่มาได้รายวันโดยเฉลี่ย ต่อที่เก็บข้อมูล
- คลิก "จำลอง" เพื่อเรียกใช้การจำลองด้วยพารามิเตอร์เริ่มต้น
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหามิติข้อมูล เปลี่ยนชื่อ ภูมิศาสตร์เป็นเมือง และเปลี่ยนจำนวนค่าที่แตกต่างกันที่เป็นไปได้เป็น 50
- สังเกตว่าการเปลี่ยนแปลงนี้เปลี่ยนแปลง Conversion ที่ระบุแหล่งที่มาได้รายวันโดยเฉลี่ยอย่างไร จำนวน PER BUCKET ตอนนี้ลดต่ำลงมากแล้ว นั่นเป็นเพราะหากคุณเพิ่ม จำนวนค่าที่เป็นไปได้ภายในมิติข้อมูลนี้โดยไม่เปลี่ยนแปลง ผลลัพธ์อื่น ก็จะเป็นการเพิ่ม จำนวนที่เก็บข้อมูลทั้งหมด โดยไม่มีการเปลี่ยนแปลง จำนวนเหตุการณ์ Conversion ที่จะอยู่ในที่เก็บข้อมูลแต่ละชุด
- คลิก "จำลอง"
- สังเกตอัตราส่วนสัญญาณรบกวนในการจำลองที่ได้ อัตราส่วนสัญญาณรบกวนคือ สูงกว่าการจำลองก่อนหน้านี้
เมื่อพิจารณาจากหลักการออกแบบหลัก ค่าสรุปสั้นๆ มีแนวโน้มที่จะเป็น รบกวนมากกว่าค่าสรุปขนาดใหญ่ ดังนั้น ตัวเลือกการกำหนดค่า ส่งผลต่อจํานวนเหตุการณ์ Conversion ที่มีการระบุแหล่งที่มาซึ่งลงท้ายด้วยแต่ละที่เก็บข้อมูล (มิเช่นนั้น เรียกว่าคีย์การรวมของคุณ) และจำนวนนั้นจะส่งผลต่อข้อมูลรบกวนใน รายงานสรุปผลลัพธ์สุดท้าย
การตัดสินใจออกแบบ 1 ข้อที่ส่งผลต่อจํานวนเหตุการณ์ Conversion ที่มีการระบุแหล่งที่มา ภายในที่เก็บข้อมูลเดียวคือรายละเอียดมิติข้อมูล ลองดูตัวอย่างต่อไปนี้ ของคีย์การรวมและมิติข้อมูล
- วิธีที่ 1: โครงสร้างหลักเดียวที่มีขนาดคร่าวๆ ได้แก่ ประเทศ x แคมเปญโฆษณา (หรือแคมเปญที่ใหญ่ที่สุด ที่เก็บข้อมูลรวม) x ประเภทผลิตภัณฑ์ (จากประเภทผลิตภัณฑ์ที่เป็นไปได้ 10 ประเภท)
- วิธีที่ 2: โครงสร้างหลักเดียวที่มีมิติข้อมูลแบบละเอียด ได้แก่ เมือง x รหัสครีเอทีฟโฆษณา x ผลิตภัณฑ์ (จากผลิตภัณฑ์ที่เป็นไปได้ 100 รายการ)
เมืองเป็นมิติข้อมูลที่ละเอียดกว่าประเทศ รหัสครีเอทีฟโฆษณาจะละเอียดยิ่งขึ้น Campaign และ Product มีรายละเอียดมากกว่า Product type ดังนั้น วิธีที่ 2 จะมีจํานวนเหตุการณ์ (Conversion) ต่อที่เก็บข้อมูลน้อยกว่า (= ต่อ ) ในผลลัพธ์ของรายงานสรุปมากกว่าวิธีที่ 1 เมื่อพิจารณาจากเสียงที่เพิ่มเข้าไป ผลลัพธ์ไม่เกี่ยวข้องกับจำนวนเหตุการณ์ในที่เก็บข้อมูล ข้อมูลการวัด ในรายงานสรุปจะมีความยุ่งยากมากขึ้นเมื่อใช้วิธีที่ 2 สำหรับผู้ลงโฆษณาแต่ละราย ให้ทดสอบด้วยตัวแปรต่างๆ รายละเอียดในการออกแบบของคีย์เพื่อให้มีคุณประโยชน์สูงสุด ผลลัพธ์
การตัดสินใจ: โครงสร้างหลัก
ลองใช้งานใน Noise Lab
ในโหมดเรียบง่าย ระบบจะใช้โครงสร้างคีย์เริ่มต้น ขั้นสูง คุณสามารถทำการทดสอบกับโครงสร้างหลักที่แตกต่างกันได้ ตัวอย่างมิติข้อมูลบางส่วน ที่มีอยู่ ซึ่งคุณสามารถแก้ไขสิ่งเหล่านี้ได้
- ไปที่โหมดขั้นสูง
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหากลยุทธ์คีย์ สังเกตการณ์ กลยุทธ์เริ่มต้นที่ชื่อว่า A ในเครื่องมือ ใช้คีย์แบบละเอียด 1 คีย์ โครงสร้างที่รวมมิติข้อมูลทั้งหมด ได้แก่ ภูมิศาสตร์ x รหัสแคมเปญ x ผลิตภัณฑ์ หมวดหมู่
- คลิก "จำลอง"
- สังเกตอัตราส่วนสัญญาณรบกวนของการจำลองที่ได้
- เปลี่ยนกลยุทธ์คีย์เป็น B การดำเนินการนี้จะแสดงการควบคุมเพิ่มเติม เพื่อให้คุณกำหนดค่าโครงสร้างคีย์ได้
- กำหนดค่าโครงสร้างคีย์ เช่น ดังนี้
- จำนวนโครงสร้างหลัก: 2
- โครงสร้างหลัก 1 = ภูมิศาสตร์ x หมวดหมู่ผลิตภัณฑ์
- โครงสร้างคีย์ 2 = รหัสแคมเปญ x หมวดหมู่ผลิตภัณฑ์
- คลิก "จำลอง"
- สังเกตว่าตอนนี้คุณจะได้รับรายงานสรุป 2 ฉบับต่อ 1 ประเภทเป้าหมายการวัดผล (2 สำหรับจำนวนการซื้อ 2 สำหรับมูลค่าการซื้อ) เนื่องจากคุณใช้ 2 โครงสร้างหลักที่แตกต่างกัน สังเกตอัตราส่วนสัญญาณรบกวน
- หรือคุณจะลองทำกับมิติข้อมูลที่กำหนดเองก็ได้ โดยดูที่ สำหรับข้อมูลที่คุณต้องการติดตาม: มิติข้อมูล ลองนำตัวอย่างออก มิติข้อมูล และการสร้างมิติข้อมูลของคุณเองโดยใช้การเพิ่ม/นำออก/รีเซ็ต ใต้มิติข้อมูลสุดท้าย
การตัดสินใจออกแบบอีกแบบหนึ่งที่จะส่งผลต่อจํานวน Conversion ที่มีการระบุแหล่งที่มา เหตุการณ์ภายในที่เก็บข้อมูลเดียว โครงสร้างหลัก ที่คุณเลือกใช้ ลองดูตัวอย่างต่อไปนี้ของคีย์การรวม
- โครงสร้างหลักเดียวที่มีมิติข้อมูลทั้งหมด เราจะเรียกกลยุทธ์นี้ว่า "กลยุทธ์หลัก A"
- โครงสร้างหลัก 2 โครงสร้าง โดยแต่ละโครงสร้างมีส่วนย่อยของมิติข้อมูล มาเรียกสิ่งนี้ว่า กลยุทธ์หลัก ข.
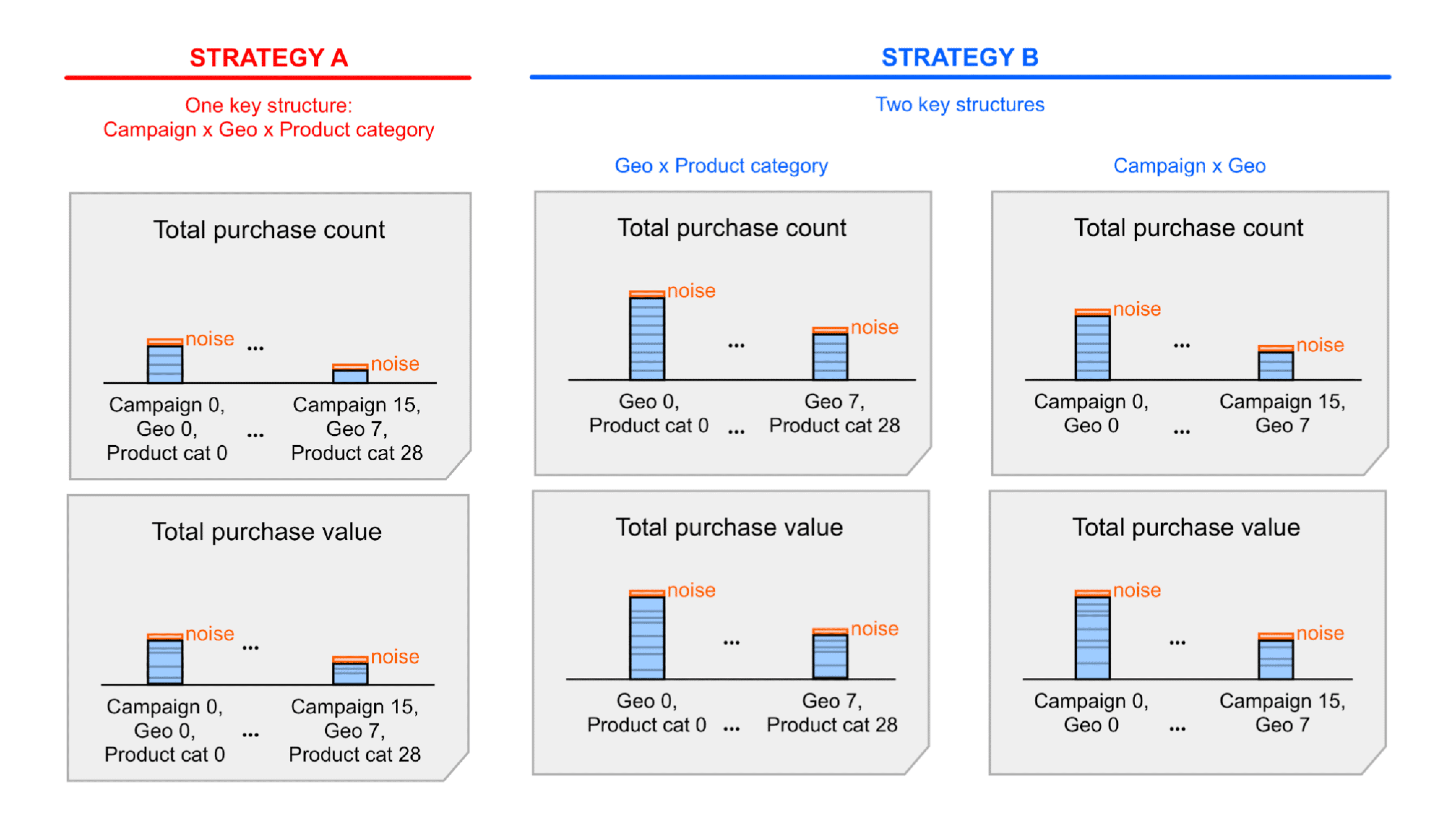
กลยุทธ์ ก ทำได้ง่ายขึ้น แต่คุณอาจต้องรวม (ผลรวม) ค่าสรุปที่รบกวนซึ่งประกอบไปด้วยรายงานสรุปเพื่อเข้าถึงข้อมูลเชิงลึกบางอย่าง การสรุปค่าเหล่านี้ถือเป็นการสรุปสัญญาณรบกวนด้วย สำหรับกลยุทธ์ B จะแสดงค่าสรุปในข้อมูลสรุป อาจให้ข้อมูลที่คุณต้องการอยู่แล้ว ซึ่งหมายความว่ากลยุทธ์ B จึงมีแนวโน้มที่จะทำให้ได้อัตราส่วนสัญญาณต่อสัญญาณรบกวนที่ดีกว่ากลยุทธ์ ก อย่างไรก็ตาม สัญญาณรบกวนอาจใช้ได้กับกลยุทธ์ A อยู่แล้ว คุณจึงอาจตัดสินใจที่จะยึดตาม กลยุทธ์ ก เพื่อความง่าย ดูข้อมูลเพิ่มเติมในตัวอย่างโดยละเอียดซึ่งอธิบายกลยุทธ์ 2 รายการนี้
การจัดการที่สำคัญเป็นหัวข้อที่ลึกมาก อาจมีเทคนิคที่ละเอียดซับซ้อนต่อไปนี้ พิจารณาเพื่อปรับปรุงอัตราส่วนของสัญญาณต่อสัญญาณรบกวน มีคำอธิบายอยู่ในคีย์ความปลอดภัย การจัดการ
ผลการตัดสิน: ความถี่ในการเผยแพร่แบบกลุ่ม
ลองใช้งานใน Noise Lab
- ไปที่โหมดแบบง่าย (หรือโหมดขั้นสูง — ทั้ง 2 โหมดสามารถใช้ ในลักษณะเดียวกันเมื่อพูดถึงความถี่การจัดกลุ่ม)
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหากลยุทธ์การรวบรวมข้อมูลของคุณ > ความถี่ในการแบบกลุ่ม หมายถึงความถี่แบบกลุ่มของ รายงานที่รวบรวมได้ซึ่งประมวลผลด้วยบริการรวมข้อมูลใน งานเดียว
- สังเกตความถี่ในการจัดกลุ่มเริ่มต้น: โดยค่าเริ่มต้น การจัดกลุ่มรายวัน มีการจำลองความถี่
- คลิก "จำลอง"
- สังเกตอัตราส่วนสัญญาณรบกวนของการจำลองที่ได้
- เปลี่ยนความถี่ในการจัดกลุ่มเป็นรายสัปดาห์
- สังเกตอัตราส่วนสัญญาณรบกวนในการจำลองที่ได้ อัตราส่วนสัญญาณรบกวนคือ จะต่ำกว่า (ดีกว่า) การจำลองก่อนหน้านี้
การตัดสินใจออกแบบอีกแบบหนึ่งที่จะส่งผลต่อจํานวน Conversion ที่มีการระบุแหล่งที่มา เหตุการณ์ภายในที่เก็บข้อมูลเดียวคือความถี่ในการจัดกลุ่มที่คุณตัดสินใจจะใช้ ความถี่ในการจัดกลุ่มคือความถี่ที่คุณประมวลผลรายงานที่รวบรวมได้
รายงานที่มีการตั้งเวลาไว้ในการรวบรวมข้อมูลบ่อยขึ้น (เช่น ทุกชั่วโมง) จะ มีเหตุการณ์ Conversion รวมน้อยกว่ารายงานเดียวกันที่มีความถี่น้อยกว่า กำหนดการรวมข้อมูล (เช่น ในแต่ละสัปดาห์) ด้วยเหตุนี้ รายงานรายชั่วโมงจะมีความผันผวนเพิ่มขึ้น" มีเหตุการณ์ Conversion รวมน้อยกว่ารายงานเดียวกันที่มีความถี่น้อยกว่า กำหนดการรวมข้อมูล (เช่น ในแต่ละสัปดาห์) ดังนั้น รายงานรายชั่วโมงจะมี อัตราส่วนสัญญาณต่อสัญญาณรบกวนต่ำกว่ารายงานรายสัปดาห์ แต่สิ่งอื่นๆ ทั้งหมดเท่ากัน ทดสอบกับข้อกำหนดการรายงานที่ความถี่ต่างๆ และประเมินอัตราส่วนสัญญาณต่อสัญญาณรบกวนในแต่ละช่วง
ดูข้อมูลเพิ่มเติมใน การรวมกลุ่ม และการรวบรวมข้อมูลในระยะเวลาที่ยาวนานขึ้น
การตัดสินใจ: ตัวแปรของแคมเปญที่ส่งผลต่อ Conversion ที่ระบุแหล่งที่มาได้
ลองใช้งานใน Noise Lab
แม้ว่านี่อาจเป็นเรื่องที่คาดเดาได้ยาก และ อาจมีตัวแปรที่มีนัยสำคัญใน นอกเหนือจากผลกระทบตามฤดูกาล ให้พยายามประมาณจำนวน Conversion จากการแตะครั้งเดียวที่ระบุแหล่งที่มาได้ยกกำลัง 10: 10, 100 ที่ใกล้เคียงที่สุด 1,000 หรือ 10,000
- ไปที่โหมดขั้นสูง
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหาข้อมูล Conversion ของคุณ
- สังเกตพารามิเตอร์เริ่มต้น โดยค่าเริ่มต้น เมตริก TOTAL ต่อวัน จำนวน Conversion ที่ระบุแหล่งที่มาได้คือ 1000 ซึ่งค่าเฉลี่ยจะอยู่ที่ประมาณ 40 ที่เก็บข้อมูลหากคุณใช้การตั้งค่าเริ่มต้น (มิติข้อมูลเริ่มต้น, จํานวนเริ่มต้นของ ค่าที่แตกต่างกันได้สำหรับแต่ละมิติข้อมูล กลยุทธ์คีย์ A) สังเกต ค่าเป็น 40 ในข้อมูลป้อนจำนวน Conversion ที่ระบุแหล่งที่มาได้รายวันโดยเฉลี่ย ต่อที่เก็บข้อมูล
- คลิก "จำลอง" เพื่อเรียกใช้การจำลองด้วยพารามิเตอร์เริ่มต้น
- สังเกตอัตราส่วนสัญญาณรบกวนของการจำลองที่ได้
- จากนั้นตั้งค่าจำนวน Conversion ที่ระบุแหล่งที่มาได้รายวัน TOTAL เป็น 100 สังเกตว่าค่านี้จะลดค่าของการระบุแหล่งที่มารายวันเฉลี่ย จำนวน Conversion PER BUCKET
- คลิก "จำลอง"
- สังเกตว่าอัตราส่วนของเสียงรบกวนสูงขึ้น นั่นเป็นเพราะเมื่อคุณ มีจำนวน Conversion ต่อที่เก็บข้อมูลน้อยลง จะมีการใช้สัญญาณรบกวนมากขึ้นเพื่อรักษา ความเป็นส่วนตัว
ความแตกต่างที่สำคัญคือ จำนวน Conversion ที่เป็นไปได้ทั้งหมดสำหรับ ผู้ลงโฆษณา เทียบกับจำนวน Conversion ที่มีการระบุแหล่งที่มาที่เป็นไปได้ทั้งหมด ซึ่งเป็นสิ่งที่ส่งผลต่อความผันผวนในรายงานสรุปในท้ายที่สุด มีการระบุแหล่งที่มา Conversion คือชุดย่อยของ Conversion ทั้งหมดที่มีแนวโน้มจะสร้างแคมเปญ เช่น งบประมาณโฆษณาและการกำหนดเป้าหมายโฆษณา ตัวอย่างเช่น คุณจะคาดหวังว่า จำนวน Conversion ที่มีการระบุแหล่งที่มาสำหรับแคมเปญโฆษณามูลค่า 10 ล้านดอลลาร์สหรัฐสูงกว่าเมื่อเทียบกับโฆษณามูลค่า 1 หมื่นดอลลาร์สหรัฐ แคมเปญ หากอย่างอื่นทั้งหมดเท่าเทียมกัน
สิ่งที่จะต้องพิจารณามีดังนี้
- ประเมิน Conversion ที่มีการระบุแหล่งที่มาโดยเทียบกับอุปกรณ์เดียวกันด้วยการแตะเพียงครั้งเดียว รูปแบบการระบุแหล่งที่มา เนื่องจากอยู่ในขอบเขตของรายงานสรุป ที่รวบรวมด้วย Attribution Reporting API
- พิจารณาทั้งจำนวนกรณีที่เลวร้ายที่สุดและสถานการณ์ที่ดีที่สุด สำหรับ Conversion ที่มีการระบุแหล่งที่มา ตัวอย่างเช่น หากปัจจัยอื่นทั้งหมดเหมือนกัน ให้พิจารณา งบประมาณขั้นต่ำและสูงสุดที่เป็นไปได้สำหรับผู้ลงโฆษณา Conversion ที่ระบุแหล่งที่มาได้ของทั้ง 2 ผลลัพธ์เป็นอินพุตของโปรเจ็กต์ การจำลอง
- หากคุณกำลังคิดจะใช้ Privacy Sandbox ของ Android, ให้พิจารณาใช้ Conversion ที่มีการระบุแหล่งที่มาข้ามแพลตฟอร์มในการคำนวณ
การตัดสินใจ: การใช้การปรับขนาด
ลองใช้งานใน Noise Lab
- ไปที่โหมดขั้นสูง
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหากลยุทธ์การรวบรวมข้อมูลของคุณ > การปรับขนาด โดยจะตั้งค่าเป็น "ใช่" โดยค่าเริ่มต้น
- เพื่อให้เข้าใจถึงผลดีของการปรับขนาดต่อเสียงรบกวน ขั้นแรกให้ตั้งค่าการปรับขนาดเป็นไม่
- คลิก "จำลอง"
- สังเกตอัตราส่วนสัญญาณรบกวนของการจำลองที่ได้
- ตั้งค่าการปรับขนาดเป็น "ใช่" โปรดทราบว่า Noise Lab คำนวณโดยอัตโนมัติ ค่าตัวคูณมาตราส่วนที่จะใช้ระบุช่วง (ค่าเฉลี่ยและค่าสูงสุด) คือ เป้าหมายการวัดผลสำหรับสถานการณ์ของคุณ ในระบบจริงหรือช่วงทดลองใช้จากต้นทาง คุณต้องนำการคำนวณปัจจัยในการกำหนดมาตราส่วนมาใช้เอง
- คลิก "จำลอง"
- สังเกตว่าอัตราส่วนสัญญาณรบกวนลดลง (ดีขึ้น) ในวินาทีนี้ การจำลอง เนื่องจากคุณกำลังใช้การปรับขนาด
ตามหลักการสำคัญในการออกแบบ สัญญาณรบกวนที่เพิ่มเข้ามาคือ ฟังก์ชันของงบประมาณการสนับสนุน
ดังนั้น หากต้องการเพิ่มอัตราส่วนของสัญญาณต่อสัญญาณรบกวน คุณสามารถตัดสินใจเปลี่ยนรูปแบบ มูลค่าที่รวบรวมระหว่างเหตุการณ์ Conversion โดยการปรับขนาดค่าให้สอดคล้องกับ งบประมาณสนับสนุน (และลดการปรับขนาดหลังการรวม) ใช้การปรับขนาดเพื่อเพิ่มอัตราส่วนของสัญญาณต่อสัญญาณรบกวน
ตัดสินใจ: จํานวนเป้าหมายการวัดผลและการแบ่งงบประมาณความเป็นส่วนตัว
สิ่งนี้เกี่ยวข้องกับการปรับขนาด โปรดอ่านการใช้ การปรับขนาด
ลองใช้งานใน Noise Lab
เป้าหมายการวัดคือจุดข้อมูลที่ไม่ซ้ำกันซึ่งรวบรวมในเหตุการณ์ Conversion
- ไปที่โหมดขั้นสูง
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหาข้อมูลที่ต้องการติดตาม ดังนี้ เป้าหมายการวัดผล โดยค่าเริ่มต้น คุณมีเป้าหมายการวัดผล 2 อย่าง ได้แก่ การซื้อ มูลค่า และจํานวนการซื้อ
- คลิก "จำลอง" เพื่อเรียกใช้การจำลองที่มีเป้าหมายเริ่มต้น
- คลิก "นำออก" การดำเนินการนี้จะนำเป้าหมายการวัดสุดท้าย (การซื้อ ในกรณีดังกล่าว)
- คลิก "จำลอง"
- สังเกตว่าตอนนี้อัตราส่วนสัญญาณรบกวนสำหรับมูลค่าการซื้อลดลง (ดีกว่า) สำหรับการจำลองครั้งที่ 2 นี้ เนื่องจากคุณมี เป้าหมายการวัด ดังนั้นตอนนี้เป้าหมายการวัด 1 ข้อของคุณจะได้รับ งบประมาณการสนับสนุน
- คลิก "รีเซ็ต" ตอนนี้คุณมีเป้าหมายในการวัดผลอีกครั้ง 2 อย่าง ได้แก่ การซื้อ มูลค่า และจํานวนการซื้อ โปรดทราบว่า Noise Lab จะคำนวณค่า ค่าตัวคูณมาตราส่วนที่จะใช้เมื่อพิจารณาจากช่วง (ค่าเฉลี่ยและค่าสูงสุด) ของฟิลด์ เป้าหมายในการวัดผลของสถานการณ์ โดยค่าเริ่มต้น Noise Lab จะแยก ในเป้าหมายการวัดผลแต่ละครั้งเท่าๆ กัน
- คลิก "จำลอง"
- สังเกตอัตราส่วนสัญญาณรบกวนของการจำลองที่ได้ จดบันทึก ค่าตัวคูณมาตราส่วนที่แสดงในการจำลอง
- ทีนี้เรามาปรับแต่งการแบ่งงบประมาณความเป็นส่วนตัวกันเพื่อให้ได้ผลลัพธ์ที่ดีขึ้น อัตราส่วนสัญญาณต่อสัญญาณรบกวน
- ปรับ % งบประมาณที่กำหนดสำหรับเป้าหมายการวัดผลแต่ละรายการ ตามค่าเริ่มต้น เป้าหมายการวัด 1 เช่น มูลค่าการซื้อ มีช่วงที่กว้างขึ้น (ระหว่าง 0 ถึง 1000) มากกว่าเป้าหมายการวัดผลที่ 2 ซึ่งได้แก่ จำนวนการซื้อ (ระหว่าง 1 ถึง 1 นั่นคือ เท่ากับ 1 เสมอ) เนื่องจาก สิ่งนี้ต้องการ "พื้นที่มากขึ้นในการปรับขนาด": ขอแนะนำให้กำหนด งบประมาณสนับสนุนให้กับเป้าหมายการวัด 1 มากกว่าเป้าหมายการวัด 2 เพื่อให้ สามารถปรับขนาดได้อย่างมีประสิทธิภาพมากขึ้น (ดูการปรับขนาด) และด้วยเหตุนี้
- กำหนดงบประมาณ 70% ให้กับเป้าหมายการวัดผล 1 กำหนด 30% ให้กับการวัด เป้าหมายที่ 2
- คลิก "จำลอง"
- สังเกตอัตราส่วนสัญญาณรบกวนของการจำลองที่ได้ สำหรับการซื้อ ตอนนี้อัตราส่วนสัญญาณรบกวนต่ำลงอย่างเห็นได้ชัด (ดีกว่า) ค่าก่อนหน้านี้ การจำลอง สำหรับยอดรวมการซื้อ จะไม่มีการเปลี่ยนแปลงคร่าวๆ
- คอยปรับการแบ่งงบประมาณตามเมตริกต่างๆ อยู่เสมอ สังเกตผลกระทบที่เกิดขึ้น เสียงรบกวน
โปรดทราบว่าคุณตั้งเป้าหมายการวัดผลที่กำหนดเองได้โดยใช้ ปุ่มเพิ่ม/นำออก/รีเซ็ต
ในกรณีที่คุณวัดจุดข้อมูล 1 จุด (เป้าหมายการวัดผล) ในเหตุการณ์ Conversion เช่น Conversion, จุดข้อมูลนั้นจะได้รับงบประมาณการสนับสนุนทั้งหมด (65536) หากคุณตั้งเป้าหมายการวัดหลายรายการในเหตุการณ์ Conversion 1 เหตุการณ์ เช่น จำนวน Conversion และมูลค่าการซื้อ จุดข้อมูลเหล่านั้นจะต้อง แชร์งบประมาณการสนับสนุน ซึ่งหมายความว่าคุณมีงบประมาณเพิ่มขึ้นน้อยลง
ดังนั้น ยิ่งคุณมีเป้าหมายในการวัดมากเท่าใด อัตราส่วนสัญญาณต่อสัญญาณรบกวนก็จะยิ่งต่ำเท่านั้น มีแนวโน้มที่จะเป็น (เสียงรบกวนสูงกว่า)
อีกการตัดสินใจหนึ่งเกี่ยวกับเป้าหมายการวัดผลคือการแบ่งงบประมาณ หากคุณแบ่งงบประมาณการมีส่วนร่วมใน 2 จุดข้อมูลเท่าๆ กัน จุดข้อมูลแต่ละจุดจะได้รับ งบประมาณ 65536/2 = 32768 วิธีนี้อาจมีประสิทธิภาพสูงสุดหรือไม่เหมาะสม ขึ้นอยู่กับ ค่าสูงสุดที่เป็นไปได้สำหรับจุดข้อมูลแต่ละจุด เช่น หากคุณกำลังวัด จำนวนการซื้อที่มีมูลค่าสูงสุดเป็น 1 และมูลค่าการซื้อที่มีมูลค่า อย่างน้อย 1 และไม่เกิน 120 มูลค่าการซื้อจะได้รับประโยชน์จาก "พื้นที่มากขึ้น" เพื่อขยายขนาดขึ้น ซึ่งก็คือการได้รับส่วนแบ่งการตลาดในสัดส่วนที่มากขึ้น งบประมาณการสนับสนุน คุณจะเห็นว่าเป้าหมายการวัดผลบางรายการควรมีลำดับความสำคัญสูงกว่า อื่นๆ เกี่ยวกับผลกระทบจากเสียงรบกวน
การตัดสินใจ: การจัดการ Outlier
ลองใช้งานใน Noise Lab
เป้าหมายการวัดคือจุดข้อมูลที่ไม่ซ้ำกันซึ่งรวบรวมในเหตุการณ์ Conversion
- ไปที่โหมดขั้นสูง
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหากลยุทธ์การรวบรวมข้อมูลของคุณ > การปรับขนาด
- ตรวจสอบว่าได้ตั้งค่าการปรับขนาดเป็น "ใช่" โปรดทราบว่า Noise Lab คำนวณค่าตัวคูณมาตราส่วนที่จะใช้โดยอัตโนมัติ โดยอิงจาก (ค่าเฉลี่ยและค่าสูงสุด) ที่คุณได้กำหนดไว้สำหรับเป้าหมายการวัดผล
- สมมติว่ายอดซื้อสูงสุดที่เคยเกิดขึ้นคือ $2000 แต่ การซื้อส่วนใหญ่เกิดขึ้นในช่วง 300-3,600 บาท ก่อนอื่น มาดูว่าเกิดอะไรขึ้น หากเราใช้วิธีการปรับขนาดแบบลิเทอรัล (ไม่แนะนำ): ให้ป้อน $2000 เป็น มูลค่าสูงสุดสำหรับ purchaseValue
- คลิก "จำลอง"
- สังเกตว่าอัตราส่วนของเสียงรบกวนอยู่ในระดับสูง นั่นเป็นเพราะการปรับขนาดของเรา ค่าปัจจัยปัจจุบันคำนวณจาก 60, 000 บาท ในความเป็นจริงส่วนใหญ่ มูลค่าการซื้อจะต่ำกว่านั้นอย่างเห็นได้ชัด
- ตอนนี้เราจะใช้วิธีการปรับขนาดที่สมเหตุสมผลมากขึ้น เปลี่ยนขีดจำกัดราคาเสนอ มูลค่าการซื้อเป็น 3,600 บาท
- คลิก "จำลอง"
- สังเกตว่าอัตราส่วนสัญญาณรบกวนต่ำลง (ดีกว่า) ในการจำลองครั้งที่ 2 นี้
ในการใช้การปรับขนาด คุณมักจะคำนวณค่าตัวคูณมาตราส่วนตาม มูลค่าสูงสุดที่เป็นไปได้สําหรับเหตุการณ์ Conversion หนึ่งๆ (ดูข้อมูลเพิ่มเติมในตัวอย่างนี้)
อย่างไรก็ตาม ให้หลีกเลี่ยงการใช้ค่าสูงสุดที่แท้จริงในการคำนวณค่าตัวคูณมาตราส่วนนั้น เพราะจะทำให้อัตราส่วนสัญญาณต่อสัญญาณรบกวนแย่ลง ให้นําค่าผิดปกติออกแทนและ ใช้ค่าสูงสุดในทางปฏิบัติ
การจัดการ Outlier เป็น หัวข้อที่ซับซ้อน อาจมีเทคนิคที่ละเอียดซับซ้อนต่อไปนี้ พิจารณาเพื่อปรับปรุงอัตราส่วนของสัญญาณต่อสัญญาณรบกวน มีคำอธิบายอยู่ใน การจัดการ Outlier ขั้นสูง
ขั้นตอนถัดไป
เมื่อคุณได้ประเมินกลยุทธ์การจัดการเสียงรบกวนต่างๆ สำหรับกรณีการใช้งานแล้ว คุณก็พร้อมที่จะเริ่มต้นการทดสอบกับรายงานสรุป โดยการรวบรวม ข้อมูลการวัดผลผ่านช่วงทดลองใช้จากต้นทาง ดูคำแนะนำและเคล็ดลับในการลองใช้ API
ภาคผนวก
ทัวร์ชมสั้นๆ ของ Noise Lab
Noise Lab ช่วยให้คุณ ประเมินและเปรียบเทียบกลยุทธ์การจัดการเสียงรบกวน ใช้เพื่อ
- ทำความเข้าใจพารามิเตอร์หลักที่อาจส่งผลกระทบต่อสัญญาณรบกวน และ ผลกระทบต่างๆ ที่คุณสามารถทำได้
- จำลองผลกระทบของสัญญาณรบกวนที่มีต่อข้อมูลการวัดเอาต์พุตที่กำหนด ด้านการออกแบบที่แตกต่างกัน ปรับแต่งพารามิเตอร์การออกแบบจนกว่าจะได้ อัตราส่วนสัญญาณต่อสัญญาณรบกวนที่เหมาะกับกรณีการใช้งานของคุณ
- แชร์ความคิดเห็นของคุณเกี่ยวกับประโยชน์ของรายงานสรุป ค่าของพารามิเตอร์ epsilon และ Noise มีประโยชน์ไหม อยู่ที่ไหน จุดเปลี่ยนผันได้คืออะไร
ให้คิดว่าสิ่งนี้เป็นเหมือนขั้นตอนการเตรียมตัว ห้องทดลอง Noise จะสร้างข้อมูลการวัดเพื่อจำลองผลลัพธ์ของรายงานสรุป โดยอิงจาก อินพุต โดยข้อมูลดังกล่าวจะไม่คงอยู่หรือแชร์ข้อมูลใดๆ
Noise Lab มี 2 โหมด ได้แก่
- โหมดง่าย: ทำความเข้าใจพื้นฐานของการควบคุมที่มี กับเสียงรบกวน
- โหมดขั้นสูง: ทดสอบกลยุทธ์การจัดการเสียงรบกวนแบบต่างๆ และประเมิน ว่าแบบไหนให้อัตราส่วนสัญญาณต่อสัญญาณรบกวนที่เหมาะกับกรณีการใช้งานของคุณที่สุด
คลิกปุ่มในเมนูด้านบนเพื่อสลับระหว่างปุ่ม (#1 ในภาพหน้าจอด้านล่าง)
โหมดง่าย
- เมื่อใช้โหมดแบบง่าย คุณจะสามารถควบคุมพารามิเตอร์ (แสดงอยู่ทางด้านซ้าย หรือ #2 ในภาพหน้าจอด้านล่าง) เช่น Epsilon และดูว่าสิ่งเหล่านี้ส่งผลกระทบต่อเสียงรบกวนอย่างไร
- แต่ละพารามิเตอร์จะมีเคล็ดลับเครื่องมือ (ปุ่ม "?") คลิกปุ่มเหล่านี้เพื่อดู คำอธิบายของพารามิเตอร์แต่ละรายการ (#3 ในภาพหน้าจอด้านล่าง)
- เริ่มต้นด้วยการคลิกปุ่ม "จำลอง" แล้วดูว่าเอาต์พุตเป็นอย่างไร เช่น (#4 ในภาพหน้าจอด้านล่าง)
- ในส่วนเอาต์พุต คุณสามารถดูรายละเอียดได้มากมาย ใช้บ้าง องค์ประกอบมีเครื่องหมาย "?" อยู่ข้างๆ คลิกที่แต่ละ "?" เพื่อดู คำอธิบายข้อมูลส่วนต่างๆ
- ในส่วน "เอาต์พุต" ให้คลิกปุ่มสลับ "รายละเอียด" หากคุณต้องการดูตารางในเวอร์ชันขยาย (#5. ในภาพหน้าจอด้านล่าง)
- ด้านล่างตารางข้อมูลแต่ละตารางในส่วนเอาต์พุตจะมีตัวเลือก เพื่อดาวน์โหลดตารางไว้ใช้งานแบบออฟไลน์ นอกจากนี้ในส่วนด้านล่าง มุมขวา จะมีตัวเลือกให้ดาวน์โหลดตารางข้อมูลทั้งหมด (#6. ใน ภาพหน้าจอด้านล่าง)
- ทดสอบการตั้งค่าต่างๆ สำหรับพารามิเตอร์ในส่วนพารามิเตอร์
แล้วคลิก จำลอง เพื่อดูว่าส่งผลต่อผลลัพธ์อย่างไร ดังนี้
วันที่ 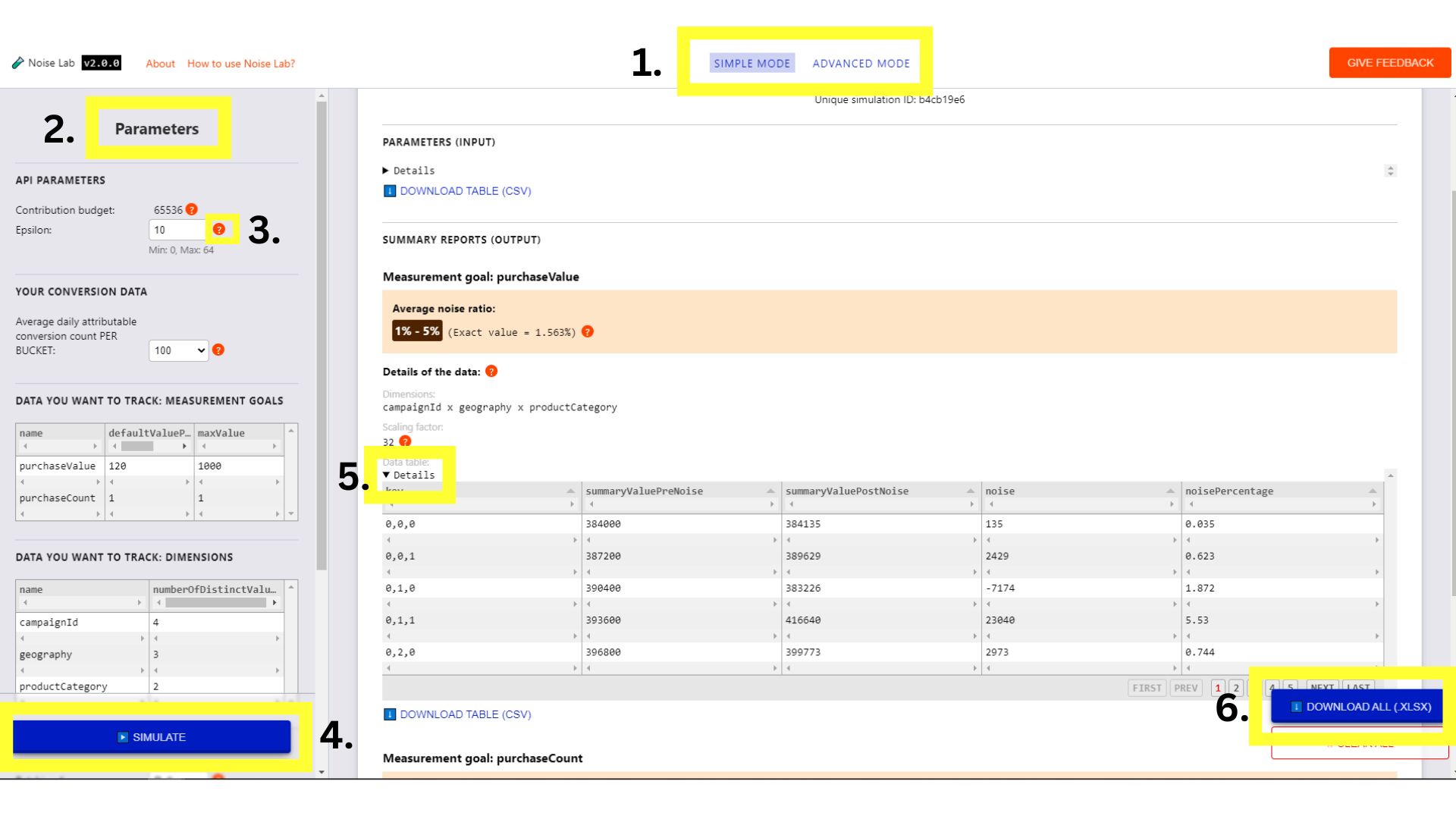
อินเทอร์เฟซ Noise Lab สำหรับโหมดแบบง่าย
โหมดขั้นสูง
- ในโหมดขั้นสูง คุณจะควบคุมพารามิเตอร์ได้มากขึ้น คุณ สามารถเพิ่มเป้าหมายการวัดผลและมิติข้อมูลที่กำหนดเอง (ข้อ 1 และ 2 ในภาพหน้าจอ ด้านล่าง)
- เลื่อนลงไปอีกในส่วน "พารามิเตอร์" และดูคีย์
ตัวเลือกกลยุทธ์ ใช้เพื่อทดสอบโครงสร้างหลักต่างๆ ได้
(#3. ในภาพหน้าจอด้านล่าง)
- หากต้องการทดสอบโครงสร้างคีย์ที่แตกต่างกัน ให้เปลี่ยนกลยุทธ์หลักเป็น "B"
- ป้อนจำนวนโครงสร้างคีย์ต่างๆ ที่ต้องการใช้ (ค่าเริ่มต้นคือ "2")
- คลิกสร้างโครงสร้างหลัก
- คุณจะเห็นตัวเลือกเพื่อระบุโครงสร้างหลักโดยคลิก ช่องทำเครื่องหมายถัดจากคีย์ที่คุณต้องการรวมไว้ในโครงสร้างคีย์แต่ละแบบ
- คลิก จำลอง เพื่อดูผลลัพธ์
วันที่ 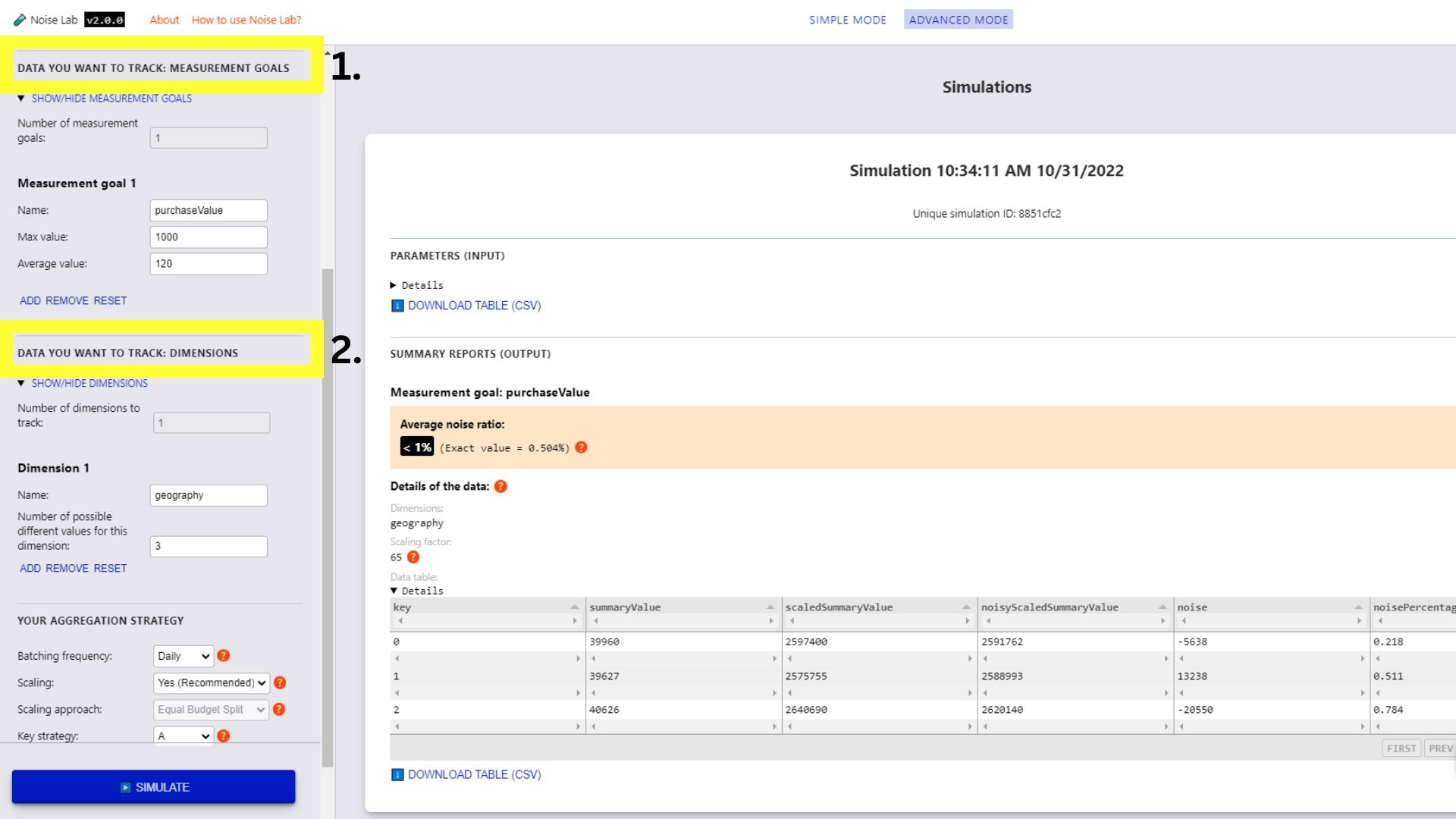
อินเทอร์เฟซ Noise Lab สำหรับโหมดขั้นสูง 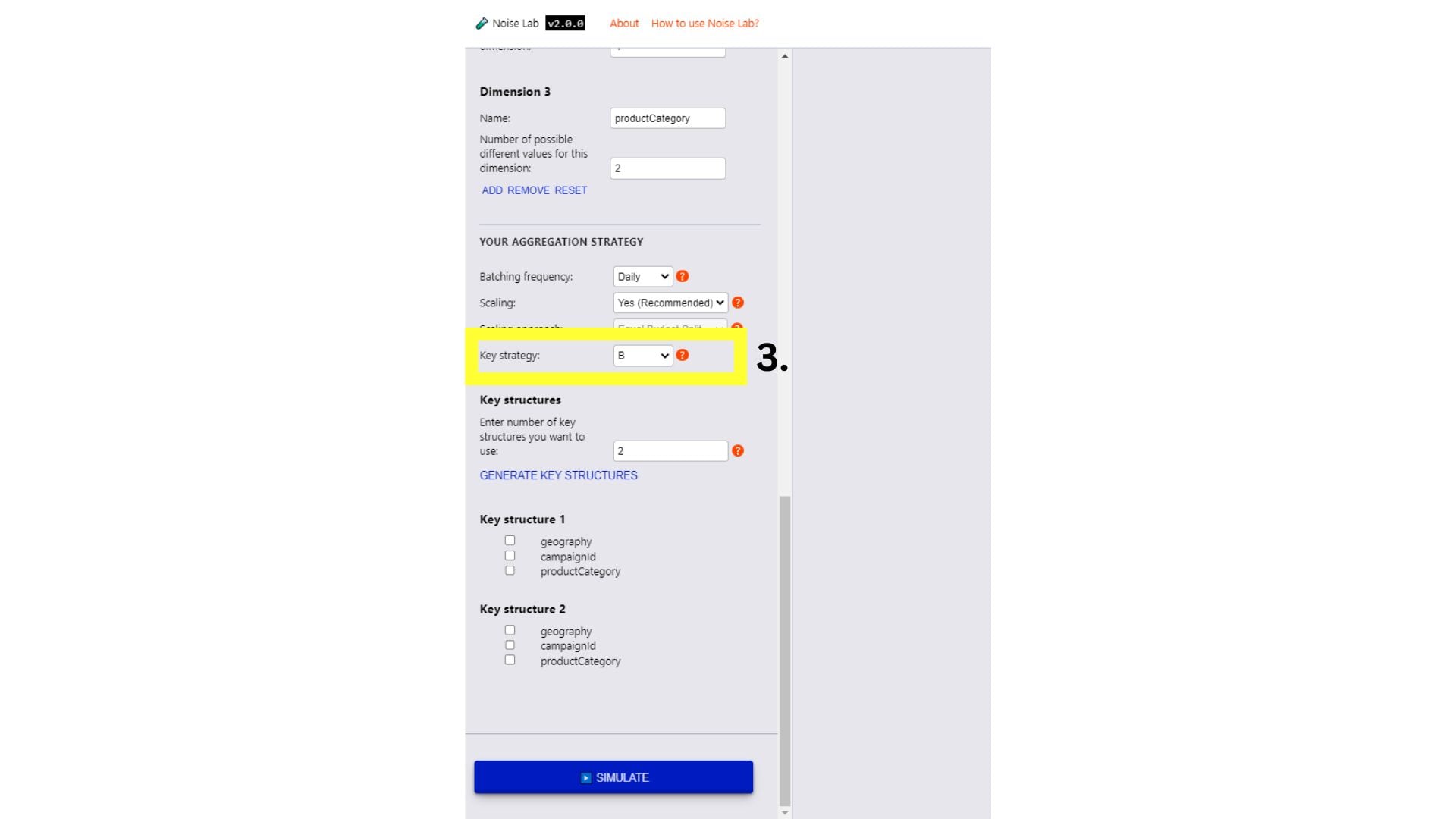
อินเทอร์เฟซ Noise Lab สำหรับโหมดขั้นสูง
เมตริกเสียงรบกวน
แนวคิดหลัก
มีการเพิ่มเสียงรบกวนเพื่อปกป้องความเป็นส่วนตัวของผู้ใช้แต่ละราย
ค่าสัญญาณรบกวนที่สูงบ่งชี้ว่าที่เก็บข้อมูล/คีย์มีปริมาณน้อยและ มีการสนับสนุนจากเหตุการณ์ที่มีความละเอียดอ่อนเพียงไม่กี่เหตุการณ์ เสร็จแล้ว กับ Noise Lab โดยอัตโนมัติ เพื่อให้ผู้เข้าร่วม "ซ่อนตัวในฝูงชน" ได้ หรือใน หรือกล่าวอีกนัยหนึ่งคือ ปกป้องบุคคลที่ถูกจำกัดเหล่านี้ ความเป็นส่วนตัวที่มากขึ้น ของสัญญาณรบกวนที่เพิ่มเข้ามา
ค่าสัญญาณรบกวนต่ำบ่งบอกว่าการตั้งค่าข้อมูลได้รับการออกแบบมาในลักษณะดังกล่าว วิธีการที่อนุญาตให้บุคคล "ซ่อนตัวในฝูงชน" อยู่แล้ว ซึ่งหมายความว่า ที่เก็บข้อมูลจะมีการมีส่วนร่วมจากเหตุการณ์ในจำนวนที่เพียงพอเพื่อดูแลให้ ความเป็นส่วนตัวของผู้ใช้แต่ละรายจะได้รับการปกป้อง
ข้อความนี้เป็นจริงสำหรับทั้งเปอร์เซ็นต์ข้อผิดพลาดเฉลี่ย (APE) และ RMSRE_T (ข้อผิดพลาดสัมพัทธ์ "ราก-ค่าเฉลี่ย-กำลังสอง" ที่มีเกณฑ์)
APE (ข้อผิดพลาดเปอร์เซ็นต์เฉลี่ย)
APE คืออัตราส่วนของสัญญาณรบกวนต่อสัญญาณ ซึ่งก็คือค่าสรุปที่แท้จริงp> ค่า APE ที่ต่ำหมายถึงอัตราส่วนสัญญาณต่อสัญญาณรบกวนที่ดีกว่า
สูตร
สำหรับรายงานสรุปที่กำหนด APE คำนวณได้ดังนี้
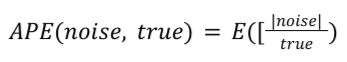
True คือค่าสรุปที่เป็นจริง APE คือค่าเฉลี่ยของสัญญาณรบกวนใน ค่าสรุปที่แท้จริง ซึ่งเป็นค่าเฉลี่ยจากรายการทั้งหมดในรายงานสรุป ใน Noise Lab ให้นำไปคูณ 100 เพื่อหาเปอร์เซ็นต์
ข้อดีและข้อเสีย
ที่เก็บข้อมูลที่มีขนาดเล็กจะมีผลกระทบกับค่า APE ในสัดส่วนที่ไม่เหมาะสม ซึ่งอาจทําให้เข้าใจผิดเมื่อประเมินเสียงรบกวน นี่คือเหตุผลที่เราได้เพิ่มเมตริกอื่นคือ RMSRE_T ที่ออกแบบมาเพื่อลดข้อจำกัดของ APE นี้ ดูรายละเอียดในตัวอย่าง
รหัส
ตรวจสอบซอร์สโค้ด สำหรับการคำนวณ APE
RMSRE_T (ข้อผิดพลาดแบบสัมพัทธ์ "รากกลาง-กำลังสอง" ที่มีเกณฑ์)
RMSRE_T (ข้อผิดพลาดเชิงสัมพัทธ์ของค่าเฉลี่ยรากกำลังสองโดยมีเกณฑ์) เป็นอีกหนึ่งการวัดค่าสัญญาณรบกวน
วิธีตีความ RMSRE_T
ค่า RMSRE_T ที่ต่ำกว่าหมายถึงอัตราส่วนสัญญาณต่อสัญญาณรบกวนที่ดีกว่า
ตัวอย่างเช่น หากอัตราส่วนสัญญาณรบกวนที่ยอมรับได้สำหรับกรณีการใช้งานของคุณคือ 20% และ RMSRE_T เป็น 0.2 คุณสามารถมั่นใจได้ว่าระดับสัญญาณรบกวนอยู่ในช่วงที่ยอมรับได้
สูตร
สำหรับรายงานสรุปที่กำหนด RMSRE_T มีการคำนวณดังนี้:
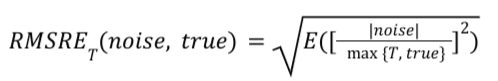
ข้อดีและข้อเสีย
RMSRE_T มีความซับซ้อนในการทำความเข้าใจมากกว่า APE เล็กน้อย อย่างไรก็ตาม ในบางกรณีวิธีนี้อาจเหมาะสมกว่า APE สำหรับการวิเคราะห์เสียงรบกวนในรายงานสรุป
- RMSRE_T มีความเสถียรมากกว่า "ท" เป็นเกณฑ์ "ท" ใช้เพื่อให้น้ำหนักที่น้อยลงในการคำนวณ RMSRE_T สำหรับที่เก็บข้อมูลที่มี Conversion น้อยกว่า ดังนั้นจึงมีความไวต่อสัญญาณรบกวนมากกว่าเนื่องจากมีขนาดเล็ก เมื่อใช้ T เมตริกจะไม่พุ่งสูงขึ้นในที่เก็บข้อมูลที่มี Conversion น้อย หาก T เท่ากับ 5 ระบบจะไม่แสดงค่าสัญญาณรบกวนที่เล็กเท่ากับ 1 ในที่เก็บข้อมูลที่มี Conversion เป็น 0 ว่ามากกว่า 1 แต่จะจำกัดที่ 0.2 ซึ่งเทียบเท่ากับ 1/5 เนื่องจาก T เท่ากับ 5 การให้น้ำหนักกับที่เก็บข้อมูลขนาดเล็กน้อยลงซึ่งไวต่อสัญญาณรบกวนมากกว่า จะทำให้เมตริกนี้คงที่มากขึ้น และทำให้สามารถเปรียบเทียบการจำลองสองชุดได้ง่ายขึ้น
- RMSRE_T ช่วยให้รวบรวมข้อมูลได้ง่าย การทราบ RMSRE_T ของที่เก็บข้อมูลหลายชุดรวมกับจำนวนที่แท้จริงของที่เก็บข้อมูลทั้งสองจะช่วยให้คุณคำนวณ RMSRE_T ของผลรวมของที่เก็บข้อมูลได้ ซึ่งช่วยให้คุณสามารถเพิ่มประสิทธิภาพสำหรับ RMSRE_T สำหรับค่ารวมเหล่านี้
แม้ว่า APE นั้นจะมีการรวมข้อมูลได้ แต่สูตรก็ค่อนข้างซับซ้อนเนื่องจากมีค่าสัมบูรณ์ของผลรวมของเสียงลาปลาซ ซึ่งทำให้เพิ่มประสิทธิภาพ APE ได้ยากขึ้น
รหัส
ตรวจสอบซอร์สโค้ดสำหรับการคำนวณ RMSRE_T
ตัวอย่าง
รายงานสรุปที่มีที่เก็บข้อมูล 3 ส่วน ได้แก่
- ที่เก็บข้อมูล_1 = สัญญาณรบกวน: 10, trueSummaryValue: 100
- ที่เก็บข้อมูล_2 = สัญญาณรบกวน: 20, trueSummaryValue: 100
- ที่เก็บข้อมูล_3 = สัญญาณรบกวน: 20, trueSummaryValue: 200
APE = (0.1 + 0.2 + 0.1) / 3 = 13%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,200))^2) / 3) = sqrt( (0.01 + 0.04 + 0.01) / 3) = 0.14
รายงานสรุปที่มีที่เก็บข้อมูล 3 ส่วน ได้แก่
- ที่เก็บข้อมูล_1 = สัญญาณรบกวน: 10, trueSummaryValue: 100
- ที่เก็บข้อมูล_2 = สัญญาณรบกวน: 20, trueSummaryValue: 100
- ที่เก็บข้อมูล_3 = สัญญาณรบกวน: 20, trueSummaryValue: 20
APE = (0.1 + 0.2 + 1) / 3 = 43%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,20))^2) / 3) = sqrt( (0.01 + 0.04 + 1.0) / 3) = 0.59
รายงานสรุปที่มีที่เก็บข้อมูล 3 ส่วน ได้แก่
- ที่เก็บข้อมูล_1 = สัญญาณรบกวน: 10, trueSummaryValue: 100
- ที่เก็บข้อมูล_2 = สัญญาณรบกวน: 20, trueSummaryValue: 100
- ที่เก็บข้อมูล_3 = สัญญาณรบกวน: 20, trueSummaryValue: 0
APE = (0.1 + 0.2 + อนันต์) / 3 = อนันต์
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,0))^2) / 3) = sqrt( (0.01 + 0.04 + 16.0) / 3) = 2.31
การจัดการคีย์ขั้นสูง
DSP หรือบริษัทวัดผลโฆษณาอาจมีการโฆษณาระดับโลกหลายพันรายการ ลูกค้าจากหลายอุตสาหกรรม สกุลเงิน และราคาซื้อ ที่เป็นไปได้ ซึ่งหมายความว่าการสร้างและจัดการคีย์การรวม 1 คีย์ต่อ มีแนวโน้มมากที่สุด ที่จะในทางปฏิบัติไม่ได้ นอกจากนี้ ยัง ความท้าทายในการเลือกมูลค่ารวมสูงสุดและงบประมาณการรวบยอดที่สามารถ จำกัดผลกระทบของข้อมูลรบกวนต่อผู้ลงโฆษณาทั่วโลกหลายพันราย แต่ โปรดพิจารณาสถานการณ์ต่อไปนี้
กลยุทธ์หลัก ก
ผู้ให้บริการเทคโนโลยีโฆษณาตัดสินใจสร้างและจัดการคีย์เดียวในทุกคีย์ ลูกค้าที่ลงโฆษณา สำหรับผู้ลงโฆษณาทั้งหมดและสกุลเงินทั้งหมด ช่วงของ การซื้ออาจแตกต่างกันไปตั้งแต่ปริมาณน้อย การซื้อระดับไฮเอนด์ ไปจนถึงปริมาณสูง ระดับต่ำ การซื้อ ซึ่งจะส่งผลให้เกิดคีย์ต่อไปนี้
| คีย์ (หลายสกุลเงิน) | |
|---|---|
| ค่าสูงสุดที่รวบรวมได้ | 5,000,000 คน |
| ช่วงมูลค่าการซื้อ | [120-500,000] |
กลยุทธ์หลัก ข
ผู้ให้บริการเทคโนโลยีโฆษณาตัดสินใจสร้างและจัดการคีย์ 2 คีย์ในคีย์ทั้งหมด ลูกค้าที่ลงโฆษณา พวกเขาตัดสินใจที่จะแยกคีย์ตามสกุลเงิน ทั้งหมด ผู้ลงโฆษณาและสกุลเงินทั้งหมด จำนวนการซื้อจะแตกต่างกันไปตามปริมาณการซื้อน้อย จากการซื้อระดับสูงไปจนถึงการซื้อในปริมาณต่ำ แยกตามสกุลเงิน พวกเขาสร้างคีย์ 2 อัน ได้แก่
| คีย์ 1 (USD) | คีย์ 2 (¥) | |
|---|---|---|
| ค่าสูงสุดที่รวบรวมได้ | 1,200,000 บาท | ¥5,000,000 |
| ช่วงมูลค่าการซื้อ | [120 - 40,000] | [15,000-5,000,000 คน] |
กลยุทธ์คีย์ B จะมีสัญญาณรบกวนน้อยกว่ากลยุทธ์คีย์ A เนื่องจาก ค่าสกุลเงินไม่ได้กระจายอย่างเท่าเทียมกันในทุกสกุลเงิน ตัวอย่างเช่น พิจารณาว่าการซื้อที่ใช้สกุลเงิน ¥ ใช้ร่วมกับการซื้อในสกุลเงิน ¥ ได้อย่างไร USD จะปรับเปลี่ยนข้อมูลพื้นฐานและผลลัพธ์ที่มีเสียงดัง
กลยุทธ์หลัก ค
ผู้ให้บริการเทคโนโลยีโฆษณาตัดสินใจสร้างและจัดการคีย์ 4 รายการในทุก ลูกค้าโฆษณาของตน และแยกลูกค้าตามสกุลเงิน x ผู้ลงโฆษณา อุตสาหกรรม:
| คีย์ 1 (USD x ผู้ลงโฆษณาเครื่องประดับระดับไฮเอนด์) |
คีย์ 2 (¥ x ผู้ลงโฆษณาเครื่องประดับระดับไฮเอนด์) |
คีย์ 3 (USD x ผู้ลงโฆษณาผู้ค้าปลีกเสื้อผ้า) |
คีย์ 4 (¥ x ผู้ลงโฆษณาร้านค้าปลีกเสื้อผ้า) |
|
|---|---|---|---|---|
| ค่าสูงสุดที่รวบรวมได้ | 1,200,000 บาท | ¥5,000,000 | $500 | ¥65,000 |
| ช่วงมูลค่าการซื้อ | [10,000-40,000 คน] | [1,250,000 - 5,000,000] | [120 - 500] | [15,000 - 65,000] |
กลยุทธ์คีย์ C จะมีสัญญาณรบกวนน้อยกว่ากลยุทธ์คีย์ B เนื่องจาก มูลค่าการซื้อของผู้ลงโฆษณาจะกระจายให้กับผู้ลงโฆษณาต่างๆ อย่างเท่าเทียมกัน สำหรับ ตัวอย่างเช่น ลองพิจารณาว่าการซื้อเครื่องประดับระดับไฮเอนด์ร่วมรวมกับการซื้ออย่างไร สำหรับหมวกเบสบอลจะปรับเปลี่ยนข้อมูลพื้นฐานและทำให้เกิดเสียงดัง
พิจารณาสร้างมูลค่ารวมสูงสุดและปัจจัยการปรับขนาดที่แชร์ร่วมกัน เพื่อความเท่าเทียมกันในผู้ลงโฆษณาหลายราย เพื่อลดเสียงรบกวนใน เอาต์พุต ตัวอย่างเช่น คุณอาจทดลองใช้กลยุทธ์ต่างๆ ด้านล่างนี้สำหรับ ผู้ลงโฆษณาของคุณ:
- กลยุทธ์หนึ่งซึ่งแยกตามสกุลเงิน (USD, ¥, CAD ฯลฯ)
- กลยุทธ์หนึ่งแยกตามอุตสาหกรรมของผู้ลงโฆษณา (ประกันภัย ยานยนต์ ค้าปลีก ฯลฯ)
- 1 กลยุทธ์ที่คั่นด้วยช่วงมูลค่าการซื้อที่คล้ายกัน ([100], [1000], [10000] ฯลฯ)
ด้วยการสร้างกลยุทธ์สำคัญๆ เกี่ยวกับคุณสมบัติทั่วไปของผู้ลงโฆษณา หลักสำคัญ และ โค้ดที่เกี่ยวข้องจะจัดการได้ง่ายกว่า และอัตราส่วนสัญญาณต่อสัญญาณรบกวนจะกลายเป็น สูงขึ้น ทดลองใช้กลยุทธ์ต่างๆ กับผู้ลงโฆษณารายอื่น ที่พบได้ทั่วไปในการค้นพบจุดเปลี่ยนผันในการเพิ่มผลกระทบจากเสียงรบกวนให้สูงสุดเมื่อเทียบกับโค้ด การจัดการ
การจัดการ Outlier ขั้นสูง
ลองพิจารณาสถานการณ์สำหรับผู้ลงโฆษณา 2 ราย:
- ผู้ลงโฆษณา A:
- ราคาซื้อสำหรับทุกผลิตภัณฑ์บนเว็บไซต์ของผู้ลงโฆษณา A ที่เป็นไปได้ตั้งแต่ [$120 - $1,000] ในช่วง $880
- ราคาซื้อจะกระจายอย่างเท่าๆ กันในช่วง $880 ไม่มีค่าผิดปกติเกินค่าเบี่ยงเบนมาตรฐาน 2 ค่าจากค่ามัธยฐานของราคาซื้อ
- ผู้ลงโฆษณา B:
- ราคาซื้อสำหรับทุกผลิตภัณฑ์บนไซต์ของผู้ลงโฆษณา B ที่เป็นไปได้ตั้งแต่ [$120 - $1,000] ในช่วง $880
- ราคาซื้อผันผวนอย่างมากระหว่าง 3,600-15,000 บาท โดยมีเพียง 5% ของการซื้อที่เกิดขึ้นในช่วง $500 - $1,000
เนื่องจาก ข้อกำหนดงบประมาณการสนับสนุน และระเบียบวิธี [ใช้สัญญาณรบกวน](/privacy-sandbox/relevance/attribution-reporting/understanding-noise/#how-noise-is-applied) กับผลลัพธ์สุดท้าย ผู้ลงโฆษณา ข จะมีเอาต์พุตที่มีเสียงดังกว่าโดยค่าเริ่มต้น ผู้ลงโฆษณา A เนื่องจากผู้ลงโฆษณา B มีโอกาสสูงกว่าที่ค่าผิดปกติที่จะได้รับผลกระทบ การคำนวณที่สำคัญ
คุณอาจลดปัญหานี้ได้ด้วยการตั้งค่าคีย์เฉพาะ ทดสอบกลยุทธ์หลัก ที่ช่วยจัดการข้อมูล Outlier และกระจายมูลค่าการซื้อให้เท่าเทียมกัน ในช่วงการซื้อของคีย์
สำหรับผู้ลงโฆษณา ข คุณสามารถสร้างคีย์ 2 คีย์แยกกันเพื่อบันทึกคีย์ 2 คีย์ ช่วงมูลค่าการซื้อ ในตัวอย่างนี้ เทคโนโลยีโฆษณาได้ระบุถึงค่าผิดปกติ จะแสดงให้สูงกว่ามูลค่าการซื้อ 15,000 บาท ลองใช้คีย์ 2 อันแยกกันสำหรับ ผู้ลงโฆษณารายนี้:
- โครงสร้างหลัก 1 : คีย์ที่บันทึกเฉพาะการซื้อระหว่าง อยู่ในช่วง 3,600-15,000 บาท (ครอบคลุมประมาณ 95% ของปริมาณการซื้อทั้งหมด)
- โครงสร้างหลัก 2: คีย์ที่บันทึกเฉพาะการซื้อที่มากกว่า 15,000 บาทเท่านั้น (ครอบคลุมประมาณ 5% ของปริมาณการซื้อทั้งหมด)
การใช้กลยุทธ์ที่สำคัญนี้ควรจะช่วยจัดการสิ่งที่รบกวนผู้ลงโฆษณา B และ เพื่อช่วยเพิ่มประโยชน์ให้ได้สูงสุดจากรายงานสรุป เนื่องจากไฟล์ใหม่ที่มีขนาดเล็กกว่า คีย์ A และคีย์ B ควรมีการกระจายข้อมูลแบบเดียวกันมากขึ้น ในแต่ละคีย์ที่เกี่ยวข้อง สำหรับคีย์เดี่ยวก่อนหน้า ซึ่งจะส่งผล ลดเสียงรบกวนในเอาต์พุตของแต่ละคีย์ให้กับคีย์เดียวก่อนหน้า