Scopri cosa significa rumore, dove viene aggiunto e come influisce sulle tue iniziative di misurazione.
I report di riepilogo sono il risultato dell'aggregazione dei report aggregabili. Quando i report aggregabili vengono raggruppati da un raccoglitore ed elaborati dal servizio di aggregazione, ai report di riepilogo risultanti viene aggiunto del rumore, una quantità casuale di dati. Viene aggiunto rumore per proteggere la privacy dell'utente. L'obiettivo di questo meccanismo è avere un framework in grado di supportare una misurazione diversamente privata.
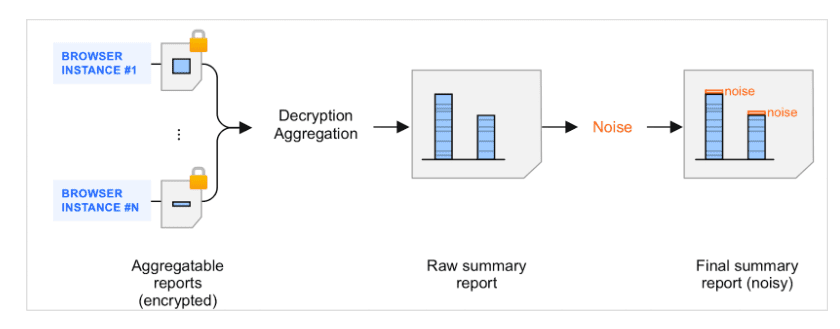
Introduzione al rumore nei report di riepilogo
Sebbene attualmente l'aggiunta di rumore non faccia parte della misurazione degli annunci, in molti casi non cambierà in modo sostanziale il modo in cui interpreti i risultati.
Potrebbe essere utile considerare la situazione nel seguente modo: Saresti in grado di prendere una decisione in base a un determinato dato se i dati non fossero rumorosi?
Ad esempio, sarebbe un inserzionista in grado di modificare la strategia o i budget della propria campagna in base al fatto che la campagna A ha ricevuto 15 conversioni e la campagna B ne ha avute 16?
Se la risposta è no, il rumore non è pertinente.
È consigliabile configurare l'utilizzo dell'API in modo tale che:
- La risposta alla domanda precedente è sì.
- Il rumore viene gestito in un modo che non influisce in modo significativo sulla tua capacità di prendere decisioni in base a determinati dati. Per ottenere un numero minimo previsto di conversioni, devi mantenere il rumore nella metrica raccolta al di sotto di una determinata percentuale.
In questa sezione e in quelle che seguono, illustreremo le strategie per raggiungere 2.
Concetti principali
Il servizio di aggregazione aggiunge il rumore una volta a ogni valore di riepilogo, ovvero una volta per chiave, ogni volta che viene richiesto un report di riepilogo.
Questi valori del rumore vengono ricavati in modo casuale da una specifica distribuzione di probabilità, discussa di seguito.
Tutti gli elementi che influiscono sul rumore si basano su due concetti principali.
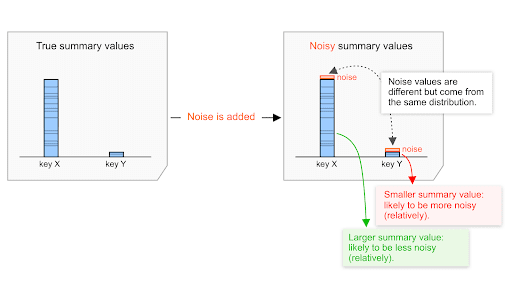
La distribuzione del rumore (dettagli sotto) è la stessa indipendentemente dal valore di riepilogo, basso o alto. Pertanto, più alto è il valore di riepilogo, minore è l'impatto che potrebbe avere il rumore rispetto a questo valore.
Ad esempio, supponiamo che un valore di acquisto totale aggregato di 20.000 $e un valore di acquisto aggregato totale di 200 $siano soggetti al rumore selezionato dalla stessa distribuzione.
Supponiamo che il rumore di questa distribuzione vari approssimativamente tra -100 e +100.
- Per il valore di acquisto riepilogativo di 20.000 $, il rumore varia tra 0 e 100/20.000=0,5%.
- Per il valore di acquisto riepilogativo di 200 $, il rumore varia tra 0 e 100/200=50%.
Pertanto, è probabile che il rumore abbia un impatto inferiore sul valore di acquisto aggregato di 20.000 $rispetto al valore di 200 $. In termini relativi, 20.000 $ è probabilmente meno rumoroso, ovvero ha un rapporto segnale-disturbo più elevato.
Ciò presenta alcune importanti implicazioni pratiche descritte nella prossima sezione. Questo meccanismo fa parte della progettazione dell'API e le implicazioni pratiche sono a lungo termine. Continueranno a svolgere un ruolo importante quando le tecnologie pubblicitarie progettano e valutano varie strategie di aggregazione.
Anche se il rumore viene estratto dalla stessa distribuzione indipendentemente dal valore di riepilogo, questa distribuzione dipende da diversi parametri. Uno di questi parametri, epsilon, potrebbe essere modificato dalle tecnologie pubblicitarie durante la prova dell'origine terminata per valutare vari aggiustamenti di utilità/privacy. Tuttavia, considera la possibilità di modificare l'epsilon come temporaneo. Apprezziamo il tuo feedback sui tuoi casi d'uso e sui valori dell'epsilon che funzionano bene.
Sebbene un'azienda di ad tech non abbia il controllo diretto su come viene aggiunto il rumore, può influenzare l'impatto del rumore sui suoi dati di misurazione. Nelle prossime sezioni, vedremo in che modo il rumore può essere influenzato nella pratica.
Prima di farlo, diamo un'occhiata più da vicino al modo in cui viene applicato il rumore.
Aumentare lo zoom: come viene applicato il rumore
Una distribuzione del rumore
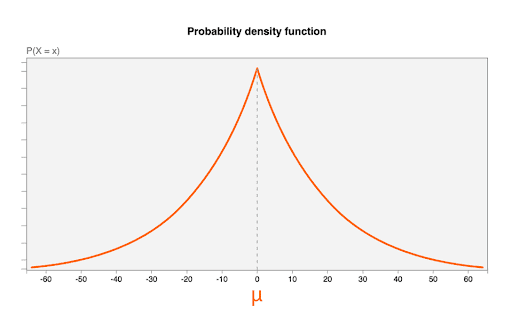
Il rumore viene estratto dalla distribuzione di Laplace, con i seguenti parametri:
- Una media (
μ) pari a 0. Ciò significa che il valore del rumore più probabile è 0 (nessun rumore aggiunto) e che il valore del rumore ha maggiori probabilità di essere inferiore all'originale (questo valore viene a volte definito imparziato). - Un parametro di scala di
b = CONTRIBUTION_BUDGET/epsilon.CONTRIBUTION_BUDGETè definito nel browser.- Il valore
epsilonè fisso nel server di aggregazione.
Il seguente diagramma mostra la funzione di densità di probabilità per una distribuzione di Laplace con μ=0, b = 20:
Valori del rumore casuale, una distribuzione del rumore
Supponiamo che un ad tech richieda report di riepilogo per due chiavi di aggregazione, chiave1 e chiave2.
Il servizio di aggregazione seleziona due valori del rumore x1 e x2, seguendo la stessa distribuzione del rumore. x1 viene aggiunto al valore di riepilogo per chiave1 e x2 viene aggiunto al valore di riepilogo per chiave2.
Nei diagrammi, rappresenteremo i valori del rumore come identici. Questa è una semplificazione; in realtà, i valori del rumore variano, poiché vengono ricavati in modo casuale dalla distribuzione.
Ciò mostra che i valori del rumore provengono tutti dalla stessa distribuzione e sono indipendenti dal valore di riepilogo a cui sono applicati.
Altre proprietà del rumore
Il rumore viene applicato a ogni valore di riepilogo, inclusi quelli vuoti (0).
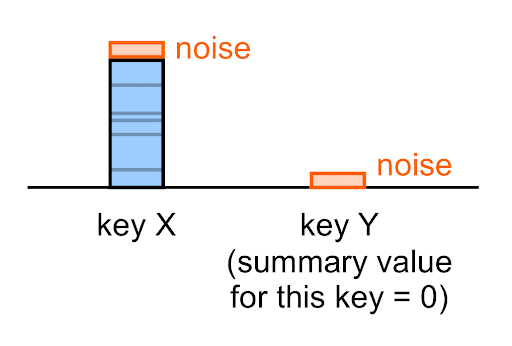
Ad esempio, anche se il vero valore di riepilogo per una determinata chiave è 0, il valore di riepilogo che appare nel report di riepilogo per questa chiave (molto probabilmente) non sarà 0.
Il rumore può essere un numero positivo o un numero negativo.
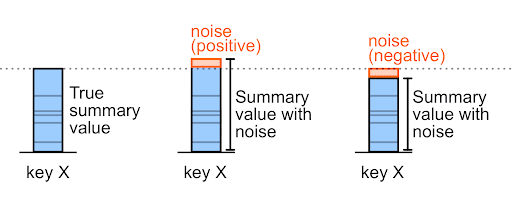
Ad esempio, per un importo di acquisto pre-rumore di 327.000, il rumore può essere +6000 o -6000 (questi sono valori di esempio arbitrari).
Valutazione del rumore
Calcolo della deviazione standard del rumore
La deviazione standard del rumore è:
b*sqrt(2) = (CONTRIBUTION_BUDGET / epsilon)*sqrt(2)
Esempio
Con epsilon = 10, la deviazione standard del rumore è:
b*sqrt(2) = (CONTRIBUTION_BUDGET / epsilon)*sqrt(2) = (65,536/10)*sqrt(2) = 9,267
Valutazione quando le differenze nelle misurazioni sono significative
Poiché conosci la deviazione standard del rumore aggiunto a ogni output del valore dal servizio di aggregazione, puoi determinare le soglie appropriate per il confronto per determinare se le differenze osservate potrebbero essere dovute al rumore.
Ad esempio, se il rumore aggiunto a un valore è di circa +/- 10 (tenendo conto della scalabilità) e la differenza del valore tra due campagne è superiore a 100, è probabile che la differenza di valore misurata tra ciascuna campagna non sia dovuta solo al rumore.
Interagisci e condividi il tuo feedback
Puoi partecipare e sperimentare con questa API.
- Scopri di più sui report aggregabili e sul servizio di aggregazione, fai domande e suggerisci feedback.
- Leggi le guide ai report sull'attribuzione.
- Fai domande e partecipa alle discussioni nel repository dell'assistenza per gli sviluppatori Privacy Sandbox.
Passaggi successivi
- Per sapere quali variabili puoi controllare per migliorare il rapporto tra segnale e rumore, consulta Operazioni con il rumore.
- Consulta l'articolo Fare esperimenti con le decisioni di progettazione dei report di riepilogo per semplificare la pianificazione delle strategie per i report sull'aggregazione.
- Prova Noise Lab.