Узнайте, что означает шум, где он добавляется и как он влияет на ваши усилия по измерению.
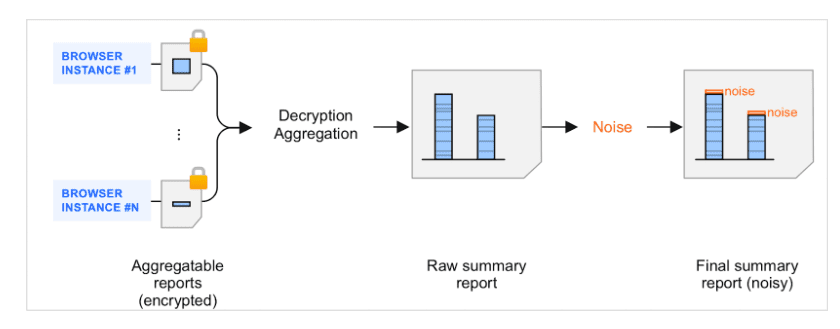
Сводные отчеты являются результатом агрегирования агрегированных отчетов . Когда агрегированные отчеты группируются сборщиком и обрабатываются службой агрегирования, к результирующим сводным отчетам добавляется шум — случайное количество данных. Шум добавляется для защиты конфиденциальности пользователей. Целью этого механизма является создание структуры, которая могла бы поддерживать дифференцированное частное измерение.
Введение в шум в сводных отчетах
Хотя сегодня добавление шума обычно не является частью измерения рекламы, во многих случаях добавленный шум не существенно изменит вашу интерпретацию результатов.
Возможно, будет полезно подумать об этом следующим образом: были бы вы уверены в принятии решения на основе определенного фрагмента данных, если бы эти данные не были зашумлены?
Например, будет ли рекламодатель уверен в изменении стратегии или бюджета своей кампании, основываясь на том факте, что в кампании А было 15 конверсий, а в кампании Б — 16?
Если ответ отрицательный, шум не имеет значения.
Что вам нужно сделать, так это настроить использование API таким образом, чтобы:
- Ответ на вопрос выше – да.
- Шум управляется таким образом, чтобы не оказывать существенного влияния на вашу способность принимать решения на основе определенных данных. Вы можете подойти к этому следующим образом: для ожидаемого минимального количества конверсий вы хотите, чтобы шум в собираемых показателях был ниже определенного %.
В этом и последующих разделах мы обрисуем стратегии достижения 2.
Основные понятия
Служба агрегирования добавляет шум один раз к каждому сводному значению (то есть один раз для каждого ключа) каждый раз, когда запрашивается сводный отчет.
Эти значения шума случайным образом извлекаются из определенного распределения вероятностей , обсуждаемого ниже.
Все элементы, влияющие на шум, основаны на двух основных концепциях.
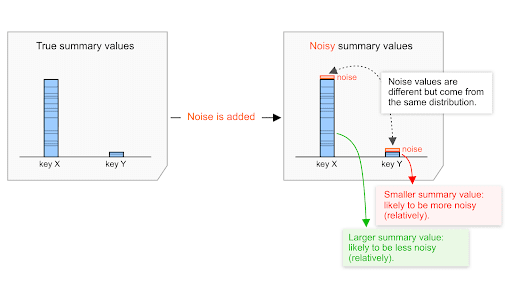
Распределение шума ( подробности ниже ) одинаково независимо от суммарного значения, низкого или высокого. Следовательно, чем выше суммарное значение, тем меньшее влияние может оказать шум по сравнению с этим значением.
Например, предположим, что как общая совокупная стоимость покупки в размере 20 000 долларов США, так и общая совокупная стоимость покупки в размере 200 долларов США подвержены шуму, выбранному из одного и того же распределения.
Предположим, что шум этого распределения варьируется примерно от -100 до +100.
- Для суммарной стоимости покупки в 20 000 долларов США шум варьируется от 0 до 100/20 000 = 0,5% .
- Для суммарной стоимости покупки в 200 долларов шум варьируется от 0 до 100/200 = 50% .
Следовательно, шум, вероятно, окажет меньшее влияние на совокупную стоимость покупки в 20 000 долларов, чем на стоимость в 200 долларов. Условно говоря, $20 000, скорее всего, будут менее шумными, то есть у них будет более высокое соотношение сигнал/шум.
Это имеет несколько важных практических последствий, которые изложены в следующем разделе. Этот механизм является частью разработки API, и его практическое значение носит долгосрочный характер. Они будут продолжать играть важную роль, когда специалисты по рекламе разрабатывают и оценивают различные стратегии агрегирования.
Хотя шум извлекается из одного и того же распределения независимо от суммарного значения, это распределение зависит от нескольких параметров. Один из этих параметров, epsilon , может быть изменен рекламными специалистами во время завершения испытания происхождения для оценки различных корректировок полезности/конфиденциальности. Однако считайте возможность настройки эпсилон временной. Мы приветствуем ваши отзывы о ваших вариантах использования и значениях эпсилона, которые хорошо работают.
Хотя компания, занимающаяся рекламными технологиями, не контролирует напрямую способы добавления шума, она может влиять на влияние шума на данные измерений. В следующих разделах мы углубимся в то, как на практике можно повлиять на шум.
Прежде чем мы это сделаем, давайте более подробно рассмотрим способ применения шума.
Увеличение масштаба: как применяется шум
Одно распределение шума
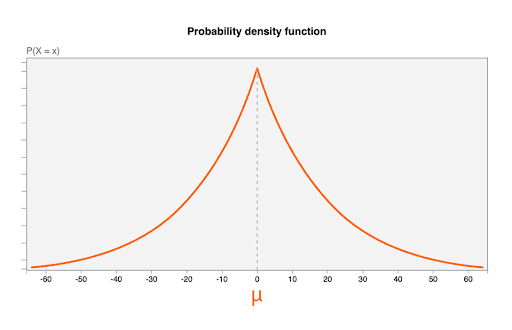
Шум извлекается из распределения Лапласа со следующими параметрами:
- Среднее значение (
μ) равно 0. Это означает, что наиболее вероятное значение шума равно 0 (без добавления шума), и что зашумленное значение с такой же вероятностью будет меньше исходного, как и больше (иногда это называют несмещенным ). ). - Параметр масштаба
b = CONTRIBUTION_BUDGET/epsilon.-
CONTRIBUTION_BUDGETопределяется в браузере. -
epsilonфиксируется на сервере агрегации.
-
На следующей диаграмме показана функция плотности вероятности для распределения Лапласа с µ=0, b = 20:
Случайные значения шума, одно распределение шума
Предположим, что специалист по рекламе запрашивает сводные отчеты по двум ключам агрегации: ключ1 и ключ2.
Служба агрегирования выбирает два значения шума x1 и x2, соответствующие одному и тому же распределению шума . x1 добавляется к сводному значению для ключа1, а x2 добавляется к сводному значению для ключа2.
На диаграммах мы будем представлять значения шума одинаковыми. Это упрощение; на самом деле значения шума будут различаться, поскольку они выбираются случайным образом из распределения.
Это показывает, что все значения шума происходят из одного и того же распределения и не зависят от суммарного значения, к которому они применяются.
Другие свойства шума
Шум применяется к каждому сводному значению, включая пустые (0).
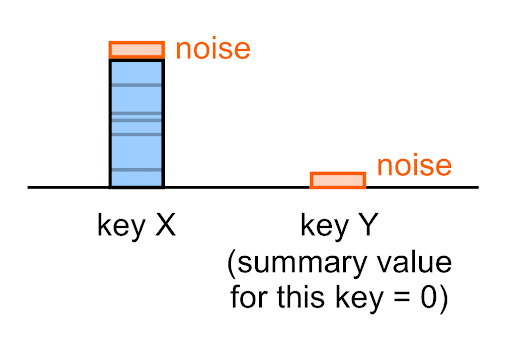
Например, даже если истинное суммарное значение для данного ключа равно 0, зашумленное суммарное значение, которое вы увидите в сводном отчете для этого ключа, (скорее всего) не будет равно 0.
Шум может быть как положительным, так и отрицательным числом.
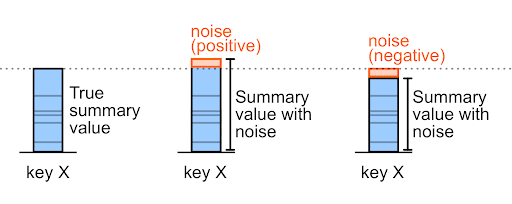
Например, для суммы покупки до уровня шума, равной 327 000, шум может составлять +6 000 или -6 000 (это произвольные примерные значения).
Оценка шума
Расчет стандартного отклонения шума
Стандартное отклонение шума составляет:
b*sqrt(2) = (CONTRIBUTION_BUDGET / epsilon)*sqrt(2)
Пример
При эпсилоне = 10 стандартное отклонение шума составляет:
b*sqrt(2) = (CONTRIBUTION_BUDGET / epsilon)*sqrt(2) = (65,536/10)*sqrt(2) = 9,267
Оценка того, когда различия в измерениях значительны
Поскольку вы будете знать стандартное отклонение шума, добавляемого к каждому значению, выводимому службой агрегирования, вы можете определить соответствующие пороговые значения для сравнения, чтобы определить, могут ли наблюдаемые различия быть вызваны шумом.
Например, если шум, добавленный к значению, составляет примерно +/- 10 (с учетом масштабирования), а разница в значении между двумя кампаниями превышает 100, вероятно, можно с уверенностью заключить, что разница в значении, измеренном между каждой кампанией, составляет не только из-за шума.
Привлекайте и делитесь отзывами
Вы можете участвовать и экспериментировать с этим API .
- Читайте об агрегированных отчетах и службе агрегирования , задавайте вопросы и предлагайте отзывы.
- Прочтите руководства по созданию отчетов по атрибуции .
- Задавайте вопросы и присоединяйтесь к обсуждениям в репозитории поддержки разработчиков Privacy Sandbox .
Следующие шаги
- Чтобы узнать, какими переменными можно управлять, чтобы улучшить соотношение сигнал/шум, обратитесь к разделу Работа с шумом .
- Просмотрите «Эксперимент с решениями по дизайну сводных отчетов» , чтобы получить помощь в планировании стратегий агрегированных отчетов.
- Попробуйте лабораторию шума .