DSPL steht für Dataset Publishing Language (Dataset-Veröffentlichungssprache). In DSPL beschriebene Datasets können in die Google Public Data Explorer, einem Tool, mit dem Sie den gesamten Daten.
Hinweis: Wenn Sie Daten in Google Public Data hochladen möchten, mit dem Tool zum Hochladen öffentlicher Daten benötigen Sie ein Google-Konto.
In dieser Anleitung finden Sie ein Schritt-für-Schritt-Beispiel für die Vorbereitung DSPL-Dataset.
Ein DSPL-Dataset ist ein Bundle, das eine XML-Datei und eine Reihe von CSV-Dateien. Die CSV-Dateien sind einfache Tabellen, die die Daten der des Datasets. Die XML-Datei beschreibt die Metadaten des Datasets, einschließlich informativer Metadaten wie Beschreibungen von Maßnahmen sowie strukturelle Metadaten wie Referenzen zwischen Tabellen. Die Metadaten können auch unerfahrene Nutzende Ihre Daten untersuchen und visualisieren.
Die einzige Voraussetzung für das Verständnis dieses Tutorials ist ein gutes von XML verstehen. Verständnis für einfache Datenbankkonzepte (z.B. Tabellen, Primärschlüssel) kann helfen, ist aber nicht erforderlich. Zu Ihrer Information: vollständige XML-Datei und vollständiges Dataset Bundle, das mit dieser Anleitung verknüpft ist, können Sie sich ebenfalls ansehen.
Übersicht
Bevor Sie mit der Erstellung des Datasets beginnen, was ein DSPL-Dataset enthält:
- Allgemeine Informationen:Informationen zum Dataset
- Konzepte:Definitionen von „Dingen“ das im Dataset angezeigt werden (z.B. Länder, Arbeitslosenquote, Geschlecht, etc.)
- Segmente:Kombinationen von Konzepten, für die es Daten
- Tabellen: Daten für Konzepte und Segmente. Konzepttabellen enthalten Aufzählungen und Slice-Tabellen statistische Daten
- Themen:Wird verwendet, um die Konzepte des Datasets zu organisieren durch Beschriftungen in einer sinnvollen Hierarchie
Betrachten Sie zur Veranschaulichung dieser eher abstrakten Konzepte das Dataset (mit Dummy-Daten), die in dieser Anleitung verwendet werden: statistische Zeitreihen für Bevölkerung und Arbeitslosigkeit, aggregiert nach verschiedenen Kombinationen aus Ländern, US-Bundesstaat und Geschlecht.
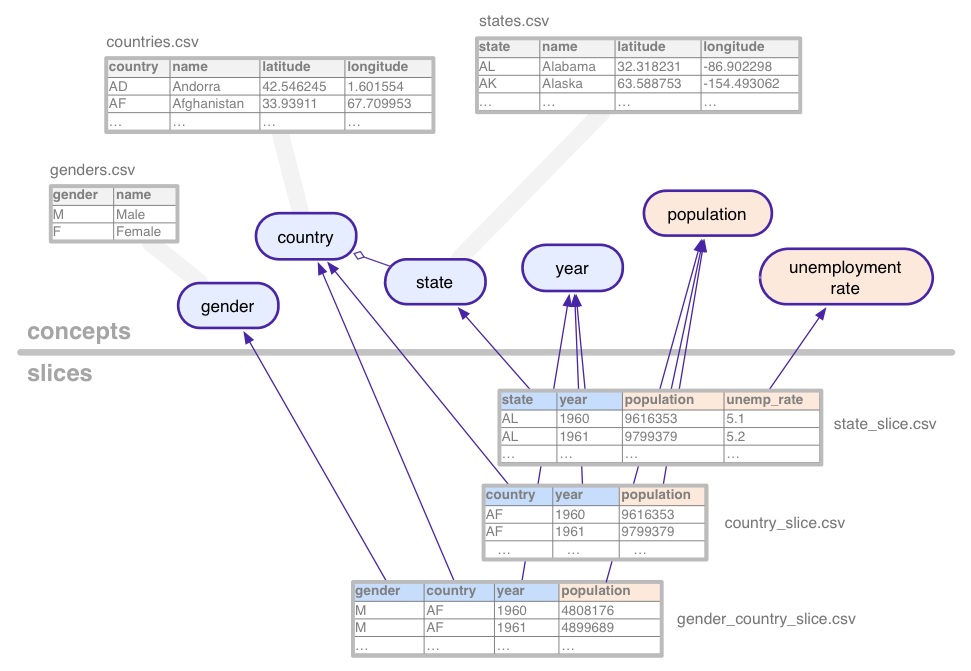
In diesem Beispiel-Dataset werden die folgenden Konzepte definiert:
- country
- gender
- Population
- Bundesstaat
- Arbeitslosenquote
- Jahr
Kategoriale Konzepte wie „state“ sind mit einem Konzept verknüpft Tabellen, in denen alle ihre möglichen Werte aufgeführt sind (Kalifornien, Arizona usw.). Konzepte können zusätzliche Spalten für Eigenschaften wie den Namen oder das Land eines Bundesstaates.
Segmente sind jede Kombination von Konzepten, für die es
statistische Daten im Dataset. Ein Slice enthält Dimensionen und
Messwerte. Im obigen Bild sind die Abmessungen blau und der
Messwerte orange. In diesem Beispiel hat das Segment
gender_country_slice enthält Daten für den Messwert
population und die Dimensionen country,
year und gender. Ein weiteres Segment namens
country_slice gibt die Gesamtzahl der jährlichen Bevölkerungszahlen (Messwert) für
Ländern.
Zusätzlich zu Dimensionen und Messwerten beziehen sich Slices auch auf Tabellen, die die tatsächlichen Daten enthalten.
Gehen wir nun Schritt für Schritt durch die Erstellung eines solchen Datasets in DSPL.
Dataset-Informationen
Zuerst müssen wir eine XML-Datei für unser Dataset erstellen. Hier sind die Anfang einer DSPL-Beschreibung für unser Beispieldatensatz:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
Die Dataset-Beschreibung beginnt mit einem übergeordneten <dspl>-Element
-Elements. Das Attribut targetNamespace enthält einen URI, der
dieses Dataset eindeutig identifiziert. Der Namespace des Datasets ist besonders
beim Veröffentlichen des Datasets, da es die globale Kennung
und wie andere darauf Bezug nehmen können.
Das Attribut targetNamespace kann weggelassen werden. In
In diesem Fall wird automatisch ein eindeutiger Namespace generiert, wenn das Dataset
importiert.
Informationen aus anderen Datasets verwenden
Datasets können Definitionen und Daten aus anderen Datasets durch Importieren von Daten wiederverwenden
dieser Datasets. Jedes <import>-Element gibt die
Namespace eines anderen Datasets, auf das dieses Dataset verweist.
In unserem Beispiel-Dataset benötigen wir Definitionen aus http://www.google.com/publicdata/dataset/google/quantity. (ein von Google erstelltes Dataset, das Konzepte enthält, die nützlich für die Definition numerische Größen) und aus den Datasets time, entity und geo, die Informationen liefern, Definitionen in Bezug auf Zeit, Entitäten bzw. Geografie.
Das obere <dspl>-Element stellt ein Namespace-Präfix bereit
Deklaration (z.B. xmlns:time="http://...") für jedes
der importierten Datasets. Für den Verweis sind Präfixdeklarationen erforderlich
Elemente aus anderen Datasets kurz und bündig. Beispiel:
time:year verweist auf die Definition von year im
importiertes Dataset, dessen Namespace mit dem Präfix verknüpft ist
time
Informationen zum Datensatz und -anbieter
Das Element <info> enthält allgemeine Informationen zu
Das Dataset: Name, Beschreibung und eine URL, unter der weitere Informationen
gefunden.
Das Element <provider> enthält Informationen zum
Anbieter des Datasets: sein Name und eine URL, unter der weitere Informationen
gefunden (normalerweise die Startseite des Datenanbieters).
Konzepte definieren
Nachdem wir nun einige allgemeine Informationen zum Dataset bereitgestellt haben, können wir nun mit der Definition des Inhalts beginnen. Unser nächstes Ziel ist es, Bevölkerungsstatistiken für Länder der letzten 50 Jahre.
Zunächst müssen wir einige Definitionen für die Begriffe definieren, Bevölkerung, Land und Jahr. In DSPL werden diese Definitionen Konzepte.
Ein Konzept ist eine Definition eines Datentyps, der in einer Dataset. Die Datenwerte, die einem bestimmten Konzept entsprechen, werden Instanzen dieses Konzepts.
Bevölkerung
Beginnen wir mit der Definition des Populationskonzepts. In einer
DSPL-Dokument – Konzepte sind in <concepts> definiert
-Element, das direkt nach dem Dataset und den Anbieterinformationen steht.
Hier ist ein Populationskonzept mit nur den minimal erforderlichen Informationen.
für jedes Konzept: id (eine eindeutige Kennung), name und
type
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
Erklärung:
- Für jedes Konzept muss ein
idangegeben werden, der eindeutig identifiziert das Konzept innerhalb des Datasets. Das bedeutet, dass keine zwei Konzepte dasselbe Dataset dieselbe ID haben kann. - Genau wie für das Dataset und seinen Anbieter
<info>-Elemente enthalten Textinformationen zum Konzept wie Name und Beschreibung. - Das Element
<type>gibt den Datentyp für die Instanzen des Konzepts, d. h. die zugehörigen „Werte“. In diesem Beispiel ist der Typpopulationinteger. DSPL unterstützt die folgenden Datentypen: <ph type="x-smartling-placeholder">- </ph>
stringintegerfloatbooleandate
Land
Schreiben wir nun die Definition des Länderkonzepts auf:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
Die Definition des Länderkonzepts
fängt wie die vorherige an,
mit id, info und type.
Konzeptwerte
Für kategorische Konzepte wie Länder sind alle möglichen
Instanzen. Sie können also alle Länder auflisten,
auf die verwiesen wird. Dazu benötigt jedes Land aber eine eindeutige Kennung.
In diesem Beispiel wird verwendet.
ISO-Ländercodes zur Identifizierung von Ländern. sind diese Codes
vom Typ string.
In diesem Beispiel müssen Sie den ISO-Code nicht verwenden. ich kann auch der Ländername verwendet werden. Namen unterscheiden sich jedoch je nach Sprache, können sich im Laufe der Zeit ändern und werden nicht immer einheitlich für alle Datasets verwendet. Für Länder und kategoriale Konzepte im Allgemeinen die Auswahl zu üben, kurz, stabil, häufig verwendet und sprachunabhängig Kennzeichnungen (falls vorhanden).
Konzeptattribute
Zusätzlich zu id umfasst das Länderkonzept
<property>-Element, das den Namen des Landes angibt.
Mit anderen Worten: Der Ländername ("Irland") ist eine Property.
des Landes mit dem id IE. Über Eigenschaften bietet DSPL
zusätzliche strukturierte Informationen
zu den Instanzen eines Konzepts.
Genau wie das Konzept selbst haben Attribute ein id,
info und type.
Konzeptdaten
Das Länderkonzept hat schließlich ein <table>-Element.
Dieses Element verweist auf eine Tabelle, in der die Liste aller
Ländern.
Die Verwendung von Tabellen ist bei einigen Konzepten sinnvoll, bei anderen jedoch nicht. Für ist es nicht sinnvoll, alle möglichen Werte für die Konzeptpopulation. Wenn Sie jedoch auf eine Tabelle verweisen, Konzept ist, muss diese Tabelle alle Instanzen des Konzepts enthalten, z. B. Es muss jedes Land aufgeführt sein, nicht nur einige.
Das Dataset definiert die Tabelle countries_table so:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
Die Ländertabelle gibt die Spalten der Tabelle und ihre Typen an,
und auf eine CSV-Datei mit den Daten verweist. Diese CSV-Datei kann entweder
gebündelt mit dem Dataset-XML gebündelt und hochgeladen oder per Fernzugriff über HTTP, HTTPS,
oder FTP. In letzteren Fällen ersetzen Sie countries.csv durch
eine URL, z. B. http://www.myserver.com/mydata/countries.csv.
Wo auch immer sie gespeichert ist, sieht die CSV-Datei wie folgt aus:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
Die erste Zeile der Tabelle enthält die Spalten-IDs, wie in der DSPL angegeben.
table-Definition. Jede der folgenden Zeilen entspricht einer
Instanz des Länderkonzepts. Wenn das Konzept eine Tabelle hat,
muss die Tabelle alle Instanzen des Konzepts enthalten.
müssen alle Länder aufgelistet sein.
Die Spalten sind dem Länderkonzept und seinen Eigenschaften
ihre ID. Die ID der ersten Spalte (country) entspricht dem Konzept
id [ID]. Das bedeutet, dass diese Spalte die eindeutige Länderkennung enthält,
durch das Länderkonzept definiert wird. Die nächste Spalte entspricht
Das Attribut name des Länderkonzepts. Die Werte
in dieser Spalte mit den Werten des Attributs name übereinstimmen.
Für die Konzepttabelle gelten einige Anforderungen an die CSV-Daten:
- Die Spaltenüberschriften in der ersten Zeile der Datendatei müssen
genau dem Konzept
idund der Eigenschaft entsprechen,iddes Konzepts, mit dem die Daten verknüpft sind, Reihenfolge kann variieren). - Jede Zeile muss genau die gleiche Anzahl an Elementen enthalten wie die Anzahl der Eigenschaften des Konzepts (auch wenn der Wert leer ist).
- Jeder Wert für das Feld
iddes Konzepts (hier der Ländercode) muss eindeutig und nicht leer sein (ein leeres Feld enthält eine Zahl mit Null) oder nur Leerzeichen). - Werte für Eigenschaften, die auf andere Konzepte verweisen, müssen entweder leer oder ein gültiger Wert des referenzierten Konzepts sein.
- Werte, die Kommas, doppelte Anführungszeichen oder Zeilenumbruchzeichen enthalten, müssen vollständig in doppelte Anführungszeichen gesetzt ist.
- Alle doppelten Anführungszeichen innerhalb eines Werts müssen sofort angegeben werden ein weiteres doppeltes Anführungszeichen vorangestellt ist.
Jahr
Das letzte Konzept, das wir für unsere
Landesbevölkerungsdaten benötigen, ist
Jahre darstellen. Anstatt ein neues Konzept zu definieren, verwenden wir
Year-Konzept aus einem der importierten Datasets:
"http://www.google.com/publicdata/dataset/google/time". Gehen Sie dazu wie folgt vor:
müssen wir darauf als time:year verweisen, wobei time
stellt das referenzierte Dataset dar und year identifiziert
des Konzepts.
Kanonische Konzepte
time:year gehört zu einer kleinen Gruppe kanonischer Konzepte.
die von Google definiert wurden. Kanonische Konzepte liefern
grundlegende Definitionen für Zeit,
Geografie, numerische Größen, Einheiten usw.
Tatsächlich besteht das oben definierte Länderkonzept als
kanonischen Begriffs. Wir haben es hier nur zur Veranschaulichung erstellt.
Verwenden Sie nach Möglichkeit immer kanonische Konzepte in Ihren Datasets, entweder
entweder direkt oder durch Erweitern. Weitere Informationen zur Erweiterung finden Sie unten. Kanonische Konzepte
Sie können Ihre Daten mit anderen Datasets vergleichen und Funktionen für Ihre
Datasets im Public Data Explorer. Zum Beispiel können Sie durch das Animieren von Daten im Zeitverlauf
oder geografische Daten auf einer Karte darstellen, sind das time und
geo.
Erster Slice
Nachdem wir nun Konzepte für Bevölkerung, Land und Jahr haben, um sie zusammenzufassen.
Dazu müssen wir einen Slice erstellen, in dem beide Segmente kombiniert werden. In DSPL Ein Slice ist eine Kombination von Konzepten, für die Daten vorhanden sind.
Warum nicht einfach eine Tabelle mit den richtigen Spalten erstellen? Da Slices die des Datasets in Bezug auf seine Konzepte. Dies wird zu immer verständlicher werden.
Segmente werden in der DSPL-Datei unter einem <slices>
-Element, das direkt nach dem Abschnitt concepts erscheinen muss.
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices>Genau wie bei Konzepten hat jedes Segment ein id
(countries_slice), die das Segment innerhalb des
Dataset.
Ein Slice enthält zwei Arten von Konzeptverweisen: Dimensionen und
metrics: Die Werte variieren je nach
Dimensionen. Hier variiert der Wert von population (der Messwert)
Dimensionen country und year
Genau wie Konzepte enthalten auch Slices einen Verweis auf eine Tabelle, die enthält die Daten des Slice. Die referenzierte Tabelle muss eine Spalte für Dimensionen und Messwerte des Slice angezeigt werden. Genau wie bei den Konzepten Dimensionen und Messwerte werden den Tabellenspalten mit denselben IDs zugeordnet.
Slice-Tabelle
Die Tabelle für unser Bevölkerungssegment erscheint im tables
der DSPL-Datei:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
Die Spalte year enthält einen format-Wert
, das die Formatierung von Jahren angibt. Unterstützte Datumsformate:
die durch das Joda DateTime-Format definiert sind.
Die Tabelle countries_slice gibt die Spalten der Tabelle und
und verweist auf eine CSV-Datei, die die Daten enthält. Die CSV-Datei
sieht so aus:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
Jede Zeile der Datentabelle enthält eine eindeutige Kombination der Dimensionen.
country und year sowie der entsprechende Wert
des Messwerts population (zum Beispiel die Bevölkerung –
metric – von Afghanistan im Jahr 1960 – Dimensionen).
Die Werte in der Spalte country entsprechen dem Wert
Wert/ID des country-Konzepts (ISO 3166)
Ländercode aus zwei Buchstaben.
Die CSV-Daten für ein Slice müssen die folgenden Einschränkungen erfüllen:
- Jeder Wert eines Dimensionsfelds, z. B.
countryundyear) darf nicht leer sein. Werte für Messwertfelder (z. B.population) darf leer sein. Ein leerer Wert wird durch „Nein“ Zeichen. - Jeder Wert eines Dimensionsfelds, das auf ein Konzept verweist, muss
die in den Daten
dieses Konzepts vorhanden sind. Beispiel: Der Wert
AFmuss in der Konzeptdatentabellecountryvorhanden sein. - Jede eindeutige Kombination von Dimensionswerten, z.B.
AF, 2000, kann nur einmal vorkommen. - Die Daten sollten nach den Spalten für Nicht-Zeitdimensionen (in beliebiger Reihenfolge) sortiert werden.
und dann, optional, nach jeder anderen Spalte. Zum Beispiel
in einer Tabelle mit den Spalten
[date, dimension1, dimension2, metric1, metric2]können Sie nachdimension1sortieren, danndimension2, danndate, aber nicht nachdateund dann die Dimensionen.
Zusammenfassung
In unserem DSPL stehen derzeit genügend Informationen zur Verfügung, um das Land Bevölkerungsdaten. Fassen wir zusammen:
- Erstellen Sie den DSPL-Header und die Beschreibung des Datensatzes sowie dessen Anbieter
- Erstelle ein Konzept für die Bevölkerung und ein anderes für ein Land. CSV-Datei, in der alle Länder und ihre Namen aufgeführt sind.
- Erstelle ein Segment mit unseren Bevölkerungszahlen für Länder im Zeitverlauf. Verweist auf das bereits definierte Jahreskonzept im importierten Zeit-Dataset von Google.
Im weiteren Verlauf dieser Anleitung vergrößeren wir unser Dataset, weitere Dimensionen in weiteren Segmenten hinzufügen und .
Dimension hinzufügen: US-Bundesstaaten
Anreichern wir unser Dataset nun, indem wir Bevölkerungsdaten für Bundesstaaten in USA. Zunächst müssen wir ein Konzept für Bundesstaaten definieren. Das sieht sehr wie das zuvor definierte Länderkonzept.
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>Konzepterweiterungen und Property Referenzen
Mit dem Konzept für Bundesstaaten werden mehrere neue Funktionen von DSPL eingeführt.
Erstens: Geben Sie an, dass ein anderes Konzept erweitert wird,
geo:location (definiert im externen Geo-Dataset, das wir
am Anfang des Datasets importiert). Semantisch bedeutet das, dass
state ist eine Art von geo:location. Eine Konsequenz ist:
alle Attribute und Eigenschaften von
geo:location Der Standort definiert insbesondere Eigenschaften für
latitude und longitude; durch die Erweiterung der vorherigen
werden diese Eigenschaften auch auf Zustand angewendet. Da wir zudem
Standort übernimmt entity:entity, Status erhält ebenfalls
alle Attribute des zweiten Pfads, einschließlich name,
description und info_url.
Hinweis: Das zuvor definierte Länderkonzept
technisch gesehen auch für geo:location verlängert worden sein.
Dieser Punkt wurde der Einfachheit halber zuvor weggelassen. haben wir die
Vererbung von Standort zu Land.
finale XML-Datei
Hinweis: Sie können den extends
Daten in Ihren eigenen Datasets verwenden, um von anderen Datasets definierte Informationen wiederzuverwenden.
Für die Verwendung von extends müssen alle Instanzen Ihres Konzepts
gültige Instanzen des Konzepts,
das Sie erweitern möchten. Mit Erweiterungen können Sie
zusätzliche Eigenschaften und Attribute hinzufügen und die Gruppe von Instanzen auf eine
Teilmenge der Instanzen des erweiterten Konzepts.
Neben der Vererbung führt die Eigenschaft „state“ auch die Eigenschaft
Konzept von Referenzen.
Das Konzept "Bundesstaat" hat eine Eigenschaft namens country,
das auf das oben erstellte Länderkonzept verweist. Dies geschieht durch
mithilfe eines concept-Attributs. Beachten Sie, dass diese Eigenschaft
eine ID, nur eine Konzeptreferenz. Dies entspricht der Erstellung einer ID.
mit demselben Wert wie die ID des referenzierten Konzepts (d.h.
country). Die hierarchische Beziehung zwischen
„Bundesstaat“ und „Landkreis“
werden durch ein Attribut
isParent="true" für die Referenz. Im Allgemeinen
Dimensionen mit hierarchischen Beziehungen, wie z. B. Regionen,
dargestellt, wobei das untergeordnete Konzept eine Eigenschaft hat,
verweist mit dem Attribut isParent auf das übergeordnete Konzept.
Die Tabellendefinition für Bundesstaaten sieht so aus:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
Die Spalte country enthält für alle Bundesstaaten einen konstanten Wert. Die Angabe in
Der DSPL vermeidet es, diesen Wert für jeden Status in den Daten zu wiederholen. Weitere Hinweise
Spalten für name, latitude und
longitude, da der Bundesstaat diese Eigenschaften von übernommen hat
geo:location. Andererseits können übernommene Eigenschaften
(z.B. description) haben keine Spalten. Das ist okay –
Wird eine Eigenschaft in einer Konzeptdefinitionstabelle weggelassen, ist ihr Wert
für jede Instanz des Konzepts als nicht definiert.
Die CSV-Datei sieht so aus:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
Da wir bereits Konzepte für Bevölkerung und Jahr haben, können wir diese um ein neues Segment für die Bevölkerung der Bundesstaaten zu definieren.
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>Die Definition der Datentabelle sieht so aus:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
Die CSV-Datei sieht so aus:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
Warum haben wir ein neues Segment erstellt, mit der vorherigen Dimension vergleichen?
Ein Segment mit Dimensionen für Bundesstaat und Land wäre nicht korrekt. da einige Zeilen für Länderdaten und andere Zeilen für Bundesstaat Daten. Der Tisch hätte „Löcher“ für einige Dimensionen, nicht zulässig (vergessen Sie nicht, dass fehlende Werte nur für Messwerte und und nicht auf Abmessungen).
Dimensionen dienen als Primärschlüssel für das Slice. Das bedeutet, dass Jede Datenzeile muss Werte für alle Dimensionen enthalten. Es dürfen jedoch keine zwei Datenzeilen vorhanden sein. kann für alle Dimensionen exakt dieselben Werte haben.
Messwert hinzufügen: Arbeitslosigkeit Bewerten
Jetzt fügen wir unserem Dataset einen weiteren Messwert hinzu:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
Der Abschnitt info dieses Messwerts hat einen Namen, eine Beschreibung und einen
URL (Link zum US-amerikanischen Bureau of Labor Statistics).
Mit diesem Konzept wird auch das kanonische Konzept quantity:rate erweitert.
Die Menge
Dataset definiert zentrale Konzepte für die Darstellung numerischer Größen. In
sollten Sie Ihre numerischen Konzepte
durch Erweitern des Datasets
Mengenkonzept geeignet sind. Das Konzept population
technisch gesehen vom
quantity:amount.
Konzeptattribute
Mit diesem Konzept wird auch das Konstrukt eines Attributs eingeführt. In
In diesem Beispiel gibt ein Attribut an, dass unemployment_rate
ist ein Prozentsatz. Das Attribut is_percentage wird übernommen von
das quantity:rate-Konzept, das mit diesem Konzept erweitert wird. Dieses
verwendet der Public Data Explorer, um Prozentzeichen anzuzeigen,
Visualisierung der Daten.
Attribute stellen einen allgemeinen Mechanismus zum Anhängen von Schlüssel/Wert-Paaren an einen
-Konzept (im Gegensatz zu Eigenschaften, die zusätzliche Werte mit
Instanzen eines Konzepts). Genau wie Konzepte und Eigenschaften
haben die Attribute id, info und
type Wie Eigenschaften können sie auf andere Konzepte verweisen.
Attribute sind nicht nur für vordefinierte allgemeine Dinge gedacht, z. B. für numerische Werte. Eigenschaften. Sie können eigene Attribute für Ihre Konzepte definieren.
Daten zur Arbeitslosenquote für die USA hinzufügen Bundesstaaten
Wir können jetzt Daten zur Arbeitslosenquote für US-Bundesstaaten hinzufügen. Weil Die Arbeitslosenquote ist eine Metrik. Wir haben bereits Bevölkerungsdaten für Bundesstaaten, können wir sie einfach dem Segment hinzufügen, das wir bereits für „Bundesstaat“ und Dimensionen:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... und fügen Sie der Tabellendefinition eine weitere Spalte hinzu:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... und in die CSV-Datei:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
Wie bereits erwähnt, bilden die Dimensionen für jedes Segment einen Primärschlüssel für das Slice. Außerdem darf jedes Dataset nur ein Segment für eine einer Kombination von Dimensionen. Alle Messwerte, die für diese müssen zum selben Segment gehören.
Weitere Dimensionen: Bevölkerungsaufschlüsselung nach Geschlecht
Erweitern wir unser Dataset mit einer Aufschlüsselung der Bevölkerung nach Geschlecht für Ländern. Mittlerweile fangen Sie an, sich mit der Bohrmaschine vertraut zu machen... Zunächst müssen wir ein Konzept für das Geschlecht hinzufügen:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
Der Abschnitt info für das Geschlechtskonzept enthält Folgendes:
pluralName: Text, der für den Verweis verwendet werden soll
das Geschlechtskonzept vor. Der Abschnitt info
enthält ein totalName, das den Text bereitstellt, der für die Ausführung
beziehen sich auf alle Instanzen des Geschlechtskonzepts als Ganzes. Beide sind
wird vom Public Data Explorer verwendet, um Informationen zum Geschlecht anzuzeigen
Konzept. Im Allgemeinen sollten Sie sie für Konzepte bereitstellen, die als
Dimensionen.
Beachten Sie, dass sich das Geschlechterkonzept
entity:entity Dies ist eine gute Übung für Konzepte,
die als Dimensionen verwendet werden, da Sie damit benutzerdefinierte Namen,
URLs und Farben für die verschiedenen Konzeptinstanzen.
Das Geschlechtskonzept bezieht sich auf die Tabelle genders_table, die
enthält die möglichen Werte für das Geschlecht und die zugehörigen Anzeigenamen
(hier ausgelassen).
Um unserem Dataset Bevölkerung nach Geschlecht hinzuzufügen, müssen wir ein neues Segment Jede verfügbare Kombination von Dimensionen entspricht einem Segment in des Datasets).
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
Die Tabellendefinition für das Segment sieht so aus:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
Die CSV-Datei für die Tabelle sieht so aus:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
Im Vergleich zu den vorherigen Ländern, zur Bevölkerung und zum Anteil der Arbeitslosigkeit hat dieses eine zusätzliche Dimension: jeder Wert des Bevölkerungsmesswerts nicht nur einem bestimmten Land und Jahr, sondern auch Geschlechts angeben.
Beachten Sie, dass wir ein "dünn besetztes" Dataset. Nicht alle Messwerte sind für alle Dimensionen verfügbar: Population ist in Ländern und US-Bundesstaaten jährlich verfügbar, während Arbeitslosigkeit ist nur für Länder verfügbar. Eine Aufschlüsselung nach Geschlecht ist verfügbar. nur für die Bevölkerung nach Land; es ist für die Arbeitslosenquote nicht verfügbar und nicht für die Dimension „Bundesland“. Sie können auch an den Daten wobei bestimmte Messwerte keine Werte für bestimmte Dimensionswerte haben, aber das ist nicht in DSPL enthalten.
Themen
Die letzte Funktion von DSPL, die wir in unserem Dataset verwenden, ist topics. Themen werden verwendet, um Konzepte hierarchisch zu klassifizieren, und werden von Anwendungen, die Nutzenden bei der Navigation zu Ihren Daten helfen.
In der DSPL-Datei werden Themen direkt vor Konzepten angezeigt. Hier ist ein Beispiel Themenhierarchie:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>Sie können Themen so tief wie nötig verschachteln.
Um Themen zu verwenden, müssen Sie nur vom Konzept aus darauf verweisen. wie folgt definiert:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
Ein Konzept kann sich auf mehr als ein Thema beziehen.
Dataset senden
Nachdem Sie nun Ihr Dataset erstellt haben, besteht der nächste Schritt darin, es zu komprimieren und laden Sie die ZIP-Datei hoch in Google Public Data Explorer. Falls Probleme auftreten, prüfen Sie, den FAQs (einschließlich einer Diskussion) der häufigsten Probleme beim Hochladen.
Als Referenz können Sie auch die vollständige XML-Datei und das vollständige Dataset-Bundle herunterladen. die mit dieser Anleitung verknüpft sind.
Fortsetzung
Herzlichen Glückwunsch zur Erstellung Ihres ersten DSPL-Datasets! Jetzt, da Sie sollten Sie den Entwicklerleitfaden lesen. Dort finden Sie „Erweitert“ DSPL-Funktionen wie mehrsprachige Unterstützung und zuordenbare Konzepte.
Sehen Sie sich bei Bedarf weitere Beispiel-Datasets an.