DSPL es la sigla en inglés de Dataset Publishing Language. Conjuntos de datos descritos en DSPL se pueden importar a la página Explorer, una herramienta que permite realizar una exploración visual enriquecida del de datos no estructurados.
Nota: Para subir datos a la sección de datos públicos de Google, sigue estos pasos: con la Herramienta de carga de datos públicos debes tener una Cuenta de Google.
En este instructivo, se muestra un ejemplo paso a paso de cómo preparar una preparación Conjunto de datos DSPL.
Un conjunto de datos DSPL es un paquete que contiene un archivo XML y un conjunto de CSV. Los archivos CSV son tablas simples que contienen los datos de del conjunto de datos. El archivo en formato XML describe los metadatos del conjunto de datos. incluidos metadatos informativos, como descripciones de medidas, así como los metadatos estructurales, como las referencias entre tablas. Los metadatos permiten usuarios inexpertos exploren y visualicen tus datos.
El único requisito previo para comprender este tutorial es un buen nivel de comprensión de XML. Cierta comprensión de los conceptos de bases de datos simples (p.ej., tablas, claves primarias) pueden ser útiles, pero no es obligatorio. A modo de referencia, el archivo en formato XML completado y conjunto de datos completo paquete asociado con este instructivo también están disponibles para su revisión.
Descripción general
Antes de empezar a crear nuestro conjunto de datos, aquí hay una descripción general de alto nivel de qué contiene un conjunto de datos DSPL:
- Información general: Acerca del conjunto de datos
- Conceptos: Definiciones de "cosas". que aparecen en el conjunto de datos (p.ej., países, tasa de desempleo, género, etc.)
- Slices: Son combinaciones de conceptos para los que hay datos
- Tablas: Son datos para conceptos y porciones. Tablas de conceptos las enumeraciones, mientras que las tablas de segmentos contienen datos estadísticos
- Temas: Se usan para organizar los conceptos del conjunto de datos. en una jerarquía significativa mediante el etiquetado
Para ilustrar estas nociones más bien abstractas, considera el conjunto de datos (con datos ficticios) utilizados en este tutorial: series temporales estadísticas para la población y el desempleo, agregados por diversas combinaciones de países, el estado de EE.UU. y el género.
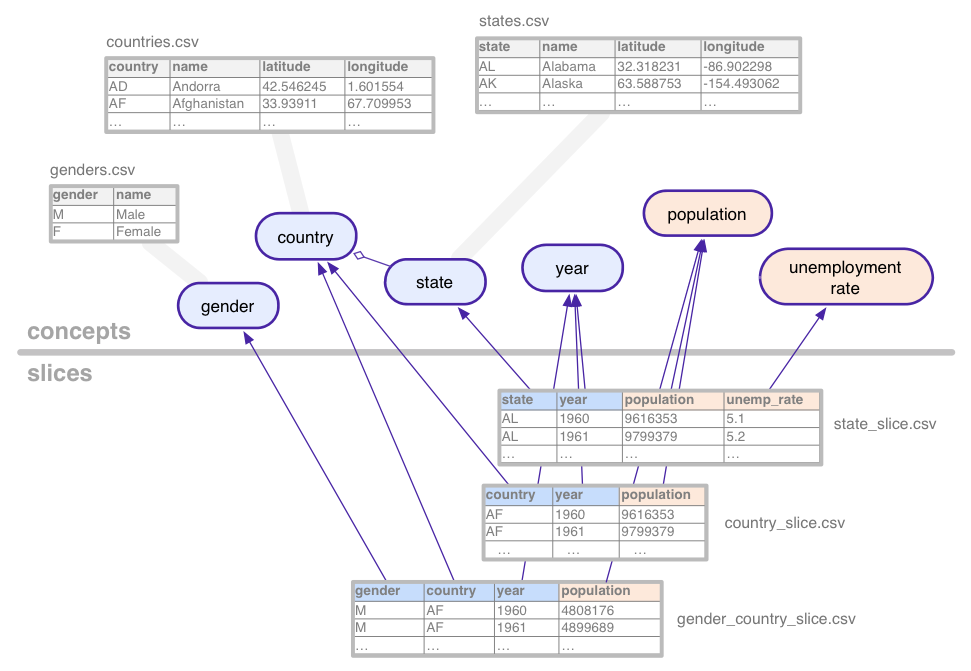
Este conjunto de datos de ejemplo define los siguientes conceptos:
- country
- género
- population
- state
- tasa de desempleo
- año
Los conceptos que son categóricos, como el estado, se asocian con el concepto tablas, que enumeran todos sus valores posibles (California, Arizona, etcétera). Los conceptos pueden tener columnas adicionales para propiedades como el nombre o el país de un estado.
Las Slices definen cada combinación de conceptos para la que hay
datos estadísticos del conjunto de datos. Una porción contiene dimensiones, y
métricas. En la imagen de arriba, las dimensiones son azules y las
las métricas son de color naranja. En este ejemplo, la porción
gender_country_slice tiene datos de la métrica
population y las dimensiones country,
year y gender. Otra porción, llamada
country_slice, proporciona los números de la población anual total (métrica) de
países.
Además de las dimensiones y métricas, las secciones también hacen referencia tablas, que contienen los datos reales.
Ahora, revisemos paso a paso la creación de un conjunto de datos de este tipo en DSPL.
Información del conjunto de datos
Para comenzar, debemos crear un archivo en formato XML para nuestro conjunto de datos. Este es el comienzo de una descripción en DSPL para nuestro conjunto de datos de ejemplo:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
La descripción del conjunto de datos comienza con un <dspl> de nivel superior
. El atributo targetNamespace contiene un URI que
identifica este conjunto de datos de forma única. El espacio de nombres del conjunto de datos es especialmente
importante al publicar el conjunto de datos, ya que será el identificador global de
tu conjunto de datos y los medios para que otros se refieran a él.
Ten en cuenta que se puede omitir el atributo targetNamespace. En
En este caso, se genera automáticamente un espacio de nombres único
importado.
Usa información de otros conjuntos de datos
Los conjuntos de datos pueden volver a usar definiciones y datos de otros conjuntos de datos mediante la importación
esos conjuntos de datos. Cada elemento <import> especifica la
de otro conjunto de datos al que hará referencia.
En nuestro conjunto de datos de ejemplo, necesitaremos algunas definiciones de http://www.google.com/publicdata/dataset/google/quantity (un conjunto de datos creado por Google que contiene conceptos útiles para definir cantidades numéricas) y de los conjuntos de datos de tiempo, entidad y ubicación geográfica, que proporcionan definiciones relacionadas con el tiempo, las entidades y la ubicación geográfica, respectivamente.
El elemento <dspl> superior proporciona un prefijo de espacio de nombres
(p.ej., xmlns:time="http://...") para cada
de los conjuntos de datos importados. Se necesitan declaraciones de prefijo para hacer referencia
elementos de otros conjuntos de datos
de forma concisa. Por ejemplo:
time:year hace referencia a la definición de year en el
conjunto de datos importado cuyo espacio de nombres está asociado con el prefijo
time
Información del proveedor y del conjunto de datos
El elemento <info> contiene información general sobre
conjunto de datos: nombre, descripción y una URL donde se pueda obtener más información
encontradas.
El elemento <provider> contiene información sobre el
del conjunto de datos: su nombre y una URL donde se pueda obtener más información
(generalmente, la página principal del proveedor de datos).
Definición de conceptos
Ahora que proporcionamos información general sobre el conjunto de datos, estamos listos para comenzar a definir su contenido. Nuestro próximo objetivo es agregar estadísticas sobre la población de los países en los últimos 50 años.
Lo primero que debemos hacer es proporcionar algunas definiciones para las nociones, de la población, el país y el año. En la DSPL, estas definiciones se denominan conceptos.
Un concepto es una definición de un tipo de datos que aparece en un de tu conjunto de datos. Los valores de datos que corresponden a un concepto determinado se denominan instancias de ese concepto.
Población
Empecemos por definir el concepto de población. En una
documento DSPL, los conceptos se definen en un <concepts>
que aparece justo después del conjunto de datos y la información del proveedor.
Este es un concepto de población con la información mínima requerida
para cualquier concepto: id (un identificador único), name y
type
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
A continuación, te mostramos cómo funciona esta muestra:
- Cada concepto debe proporcionar un
idque identifique de forma única el concepto dentro del conjunto de datos. Esto significa que no hay dos conceptos definidos en el mismo conjunto de datos puede tener el mismo ID. - Al igual que ocurre con el conjunto de datos y su proveedor, el
Los elementos
<info>proporcionan información textual sobre el como su nombre y descripción. - El elemento
<type>especifica el tipo de datos del instancias del concepto (en otras palabras, sus “valores”). En este ejemplo, el tipo depopulationesintegerLa DSPL admite los siguientes tipos de datos:stringintegerfloatbooleandate
País
Ahora, escribamos la definición del concepto de país:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
La definición del concepto país comienza como la anterior,
con un id, info y type.
Valores de conceptos
Los conceptos categóricos, como los países, tienen una enumeración de todas las opciones posibles
individuales. En otras palabras, puedes enumerar todos los países posibles
a los que se hace referencia. Sin embargo, para hacerlo, cada país necesita un identificador único.
Este ejemplo utiliza
Códigos ISO de países para identificar países estos códigos son
del tipo string.
En este ejemplo, no necesitas usar el código ISO; tú también podría usar el nombre del país. Sin embargo, los nombres difieren según el idioma, pueden cambiar con el tiempo y no siempre se usan de manera coherente en todos los conjuntos de datos. Para los países, y para los conceptos categóricos en general, es una buena práctica para elegir, breve, estable, de uso frecuente e independiente del lenguaje identificadores (si existen).
Propiedades de los conceptos
Además de su id, el concepto de país tiene una
Es el elemento <property> que especifica el nombre del país.
En otras palabras, el nombre del país ("Irlanda") es una propiedad
del país con id IE. Las propiedades son cómo la DSPL proporciona
información estructurada adicional sobre las instancias de un concepto.
Al igual que el concepto en sí, las propiedades tienen un id,
info y type.
Datos de conceptos
Por último, el concepto de país tiene un elemento <table>.
Este elemento hace referencia a una tabla que enumera la lista de todos
países.
Usar tablas tiene sentido para algunos conceptos, pero no para otros. Para por ejemplo, no tiene sentido enumerar todos los valores posibles para el concepto “población”. Sin embargo, si haces referencia a una tabla para un concepto, la tabla debe contener todas las instancias del concepto, por ejemplo, debe incluir todos los países, no solo algunos ejemplos.
El conjunto de datos define la tabla countries_table de la siguiente manera:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
La tabla de países especifica las columnas de la tabla y sus tipos,
y hace referencia a un archivo CSV
que contiene los datos. Este archivo CSV puede
agrupar y subir con el conjunto de datos XML o al que se accede de forma remota a través de HTTP, HTTPS,
o FTP. En los últimos casos, reemplazarías countries.csv por
una URL, por ejemplo http://www.myserver.com/mydata/countries.csv.
Donde sea que esté almacenado, el archivo CSV se verá de la siguiente manera:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
En la primera fila de la tabla, se enumeran los ID de columna, como se especifica en la DSPL.
Definición de table. Cada una de las siguientes filas corresponde a una
instancia del concepto de país. Si el concepto tiene una tabla, entonces
la tabla debe contener todas las instancias del concepto, en este
En este caso, debe indicar todos los países.
Las columnas se asignan al concepto de país y sus propiedades según
su ID. El ID de la primera columna, country, coincide con el concepto
ID. Esto significa que esta columna contiene el identificador único de país
definido por el concepto de país. La siguiente columna corresponde a
La propiedad name del concepto de país Los valores
de esta columna coinciden con los valores de la propiedad name.
Hay algunos requisitos para los datos CSV de la tabla de conceptos:
- Los encabezados de columna en la primera línea del archivo de datos deben
coinciden exactamente con el concepto
idy la propiedadiddel concepto con el que se asocian los datos (aunque el orden puede variar). - Cada fila debe tener exactamente la misma cantidad de elementos que la cantidad de propiedades en el concepto (incluso si el valor está vacío).
- Cada valor para el campo
iddel concepto (aquí, el código de país) debe ser único y no debe estar vacío (un campo vacío es uno con cero o solo caracteres de espacio en blanco). - Los valores de propiedades que hacen referencia a otros conceptos deben ser estar vacía o ser un valor válido del concepto al que se hace referencia.
- Los valores que contengan comas, comillas dobles o caracteres de línea nueva se deben encerrado por completo entre comillas dobles.
- Cualquier carácter literal de comillas dobles dentro de un valor debe ser inmediatamente precedida por otra comilla doble.
Año
El último concepto que necesitamos para nuestros datos sobre la población de un país es un concepto para
representan años. En lugar de definir un concepto nuevo, usaremos el
año a partir de uno de los conjuntos de datos que importamos:
"http://www.google.com/publicdata/dataset/google/time". Para ello,
necesitamos hacer referencia a él como time:year, donde time
representa el conjunto de datos al que se hace referencia, y year identifica
el concepto.
Conceptos canónicos
time:year forma parte de un pequeño conjunto de conceptos canónicos
definidas por Google. Los conceptos canónicos proporcionan definiciones básicas de tiempo,
geografía, cantidades numéricas, unidades, etc.
De hecho, el concepto de país definido anteriormente existe como un
canónico. Solo lo creamos aquí con fines ilustrativos.
Siempre que sea posible, debes usar conceptos canónicos en tus conjuntos de datos, ya sea
directamente o extendiéndolos (más información sobre la extensión a continuación). Conceptos canónicos
permite comparar tus datos con otros conjuntos de datos y habilita funciones para tu
conjuntos de datos en Public Data Explorer. Por ejemplo, animar datos en el tiempo
o datos geográficos en un mapa se basan en el uso de time y
Conceptos canónicos de geo, respectivamente.
Primera porción
Ahora que tenemos los conceptos de población, país y año, es momento de para reunirlos.
Para eso, debemos crear una slice que los combine. En DSPL, una porción es una combinación de conceptos para los que existen datos.
¿Por qué no crear una tabla con las columnas correctas? Debido a que los segmentos capturan la información del conjunto de datos en términos de sus conceptos. Esto se convertirá sea más clara a medida que creemos más partes de nuestro conjunto de datos.
Las Slices aparecen en el archivo DSPL en un <slices>
que debe aparecer justo después de la sección concepts.
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices>Al igual que los conceptos, cada porción tiene un id.
(countries_slice) que identifica de forma única la porción dentro del
de tu conjunto de datos.
Una porción contiene dos tipos de referencias de conceptos: Dimensiones y
métricas. Los valores de las métricas varían con los valores de
dimensiones. Aquí, el valor de population (la métrica) varía en función
las dimensiones country y year
Al igual que los conceptos, las porciones incluyen una referencia a una tabla que contiene los datos de la porción. La tabla referenciada debe tener una columna para cada dimensión y métrica de la porción. Igual que con los conceptos, la porción las dimensiones y métricas se asignan a las columnas de la tabla con los mismos IDs.
Tabla de Slice
La tabla para nuestra porción de población aparece en tables.
del archivo DSPL:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
Ten en cuenta que la columna year incluye un format
que especifica el formato de los años. Los formatos de fecha admitidos son los siguientes:
aquellos definidos por el formato de fecha y hora de Joda.
La tabla countries_slice especifica las columnas de la tabla y
sus tipos y apunta a un archivo CSV que contiene los datos. El archivo CSV
se ve así:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
Cada fila de la tabla de datos contiene una combinación única de dimensiones
country y year, junto con el valor correspondiente
de la métrica population (por ejemplo, la población -
metric: de Afganistán en 1960; dimensiones
Ten en cuenta que los valores de la columna country coinciden con el
valor/identificador del concepto country, que es la norma ISO 3166
Es el código de 2 letras del país.
Los datos CSV de una porción deben cumplir con las siguientes restricciones:
- Cada valor de un campo de dimensión (como
countryyyear) no puede estar vacío. Los valores para los campos de métricas (comopopulation) puede estar vacío. Un valor vacío se representa como no caracteres. - Cada valor de un campo de dimensión que hace referencia a un concepto debe
presente en los datos de ese concepto. Por ejemplo, el valor
AFdebe estar presente en la tabla de datos del conceptocountry. - Cada combinación única de valores de dimensión, p.ej.,
AF, 2000, puede ocurrir una sola vez. - Los datos se deben ordenar por las columnas de dimensiones que no son de tiempo (en cualquier orden).
y luego, opcionalmente, por cualquiera de las otras columnas. Por ejemplo,
en una tabla con las columnas
[date, dimension1, dimension2, metric1, metric2], puedes ordenar pordimension1, despuésdimension2, luegodate, pero no dedatey, luego, las dimensiones.
Resumen
En este punto, contamos con suficiente información en nuestra DSPL para describir el país. datos demográficos. En resumen, lo que tuvimos que hacer fue lo siguiente:
- Crear el encabezado y la descripción DSPL del conjunto de datos y su proveedor
- Crea un concepto para la población y otro para el país, con una .csv que enumera todos los países y sus nombres.
- Crear una porción con los números de la población de cada país a lo largo del tiempo y hace referencia al concepto de año ya definido en el conjunto de datos de tiempo importado de Google.
En el resto de este instructivo, enriqueceremos nuestro conjunto de datos agregar más dimensiones en más porciones, así como más métricas agrupadas por en el tema.
Cómo agregar una dimensión: Estados de EE.UU.
Ahora, enriquezcamos nuestro conjunto de datos agregando datos sobre la población de los estados de EE.UU. Primero tenemos que definir un concepto para los estados. Esto parece mucho como el concepto de país que definimos antes.
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>Extensiones de conceptos y propiedad referencias
El concepto de estado introduce varias funciones nuevas de la DSPL.
Primero, el estado extiende otro concepto,
geo:location (definido en el conjunto de datos geográficos externos que
importados al comienzo del conjunto de datos). Semánticamente, esto significa que
state es un tipo de geo:location. Una consecuencia es
que hereda todos los atributos y propiedades de
geo:location En particular, la ubicación define propiedades para
latitude y longitude; si se extiende la anterior
general, estas propiedades también se aplican al estado. Además, ya que
ubicación hereda de entity:entity, el estado también obtiene
todas las propiedades de estas últimas, incluidas name,
description y info_url.
Nota: El concepto de país definido anteriormente
debería, técnicamente, también extenderse desde geo:location.
Este punto se omitió antes por cuestiones de simplicidad: incluimos el
de la ubicación a la herencia del país, en la
archivo XML final.
Nota: Puedes usar el extends
construir en tus propios conjuntos de datos para reutilizar la información definida por otros conjuntos de datos.
Usar extends requiere que todas las instancias de tu concepto se
instancias válidas del concepto que estás extendiendo. Las extensiones te permiten agregar
propiedades y atributos adicionales, y restringir el conjunto de instancias a una
subconjunto de instancias del concepto extendido.
Además de la herencia, la propiedad de estado también presenta la
de referencias de conceptos.
En particular, el concepto de estado tiene una propiedad llamada country,
que hace referencia al concepto de país que creamos anteriormente. Esto lo hace
con un atributo concept. Ten en cuenta que esta propiedad no
proporciona un ID, solo una referencia de concepto. Esto equivale a crear un ID
con el mismo valor que el ID del concepto al que se hace referencia (es decir,
country en este ejemplo). La relación jerárquica entre
estado y condado se capturan con un atributo
isParent="true" en la referencia. En general,
dimensiones con relaciones jerárquicas, como las geografías, deben
se representa de esta manera, y el concepto secundario tiene una propiedad que
hace referencia al concepto superior con el atributo isParent.
La definición de tabla para los estados se ve de la siguiente manera:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
La columna país tiene un valor constante para todos los estados. Si lo especificas en
la DSPL evita repetir ese valor para cada estado de los datos. También ten en cuenta
que incluimos columnas para name, latitude y
longitude, ya que el estado heredó estas propiedades de
geo:location Por otro lado, algunas propiedades heredadas
(p.ej., description) no tienen columnas. Esto está bien.
si se omite una propiedad de una tabla de definición de conceptos, entonces su valor es
se supone que no está definido
para cada instancia del concepto.
El archivo CSV se ve de la siguiente manera:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
Como ya tenemos conceptos para población y año, podemos reutilizarlos. para definir una nueva porción para la población estatal.
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>La definición de la tabla de datos se ve de la siguiente manera:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
Y el archivo CSV se ve así:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
¿Por qué creamos una porción nueva en lugar de agregar otra al anterior?
Una porción con dimensiones para el estado y el país no sería correcta, ya que algunas filas serían para datos de países y otras, para estados. de datos no estructurados. La tabla tendría "agujeros" para algunas dimensiones, que es (recuerda que los valores faltantes solo se permiten para métricas y y no dimensiones).
Las dimensiones actúan como una "clave primaria" para la porción. Esto significa que Cada fila de datos debe tener valores para todas las dimensiones y no puede haber dos filas de datos pueden tener exactamente los mismos valores en todas las dimensiones.
Agrega una métrica: Desempleo de conv.
Ahora, agreguemos otra métrica a nuestro conjunto de datos:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
La sección info de esta métrica tiene un nombre, una descripción y una
URL (con vínculo a la Oficina de Estadísticas Laborales de EE.UU.).
Este concepto también extiende el concepto canónico de quantity:rate.
La cantidad
conjunto de datos define los conceptos principales para representar cantidades numéricas. En
conjunto de datos, debes crear tus conceptos numéricos extendiendo
el concepto de cantidad adecuada. Por lo tanto, el concepto population
definidos anteriormente deberían, técnicamente, haberse extendido de
quantity:amount
Atributos de conceptos
Este concepto también introduce la construcción de un atributo. En
En este ejemplo, se usa un atributo para indicar que unemployment_rate
es un porcentaje. El atributo is_percentage se hereda de
el concepto de quantity:rate que extiende este concepto. Esta
pública que utiliza Public Data Explorer para mostrar signos de porcentaje cuando
visualizar los datos.
Los atributos proporcionan un mecanismo general para adjuntar pares clave-valor a un
(en contraste con las propiedades, que asocian valores adicionales con
instancias de un concepto). Al igual que los conceptos y las propiedades,
tienen un valor de id, info y un
type Al igual que las propiedades, pueden hacer referencia a otros conceptos.
Los atributos no son solo para elementos generales predefinidos, como valores propiedades. Puedes definir tus propios atributos para los conceptos.
Agregar datos sobre la tasa de desempleo para EE.UU. Estados
Ahora estamos listos para agregar los datos sobre la tasa de desempleo en estados de EE.UU. Porque la tasa de desempleo es una métrica y ya tenemos datos sobre la población de los estados, podemos agregarla a la porción que ya creamos para el estado y el año. dimensiones:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... y agrega otra columna a la definición de la tabla:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... y al archivo CSV:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
Antes dijimos que para cada porción, las dimensiones forman una clave primaria. para la porción. Además, cada conjunto de datos solo puede contener una porción para una una combinación de dimensiones determinada. Todas las métricas disponibles para estas deben pertenecer a la misma porción.
Más dimensiones: Desglose de la población por género
Enriquezcamos nuestro conjunto de datos con un desglose de población por género para países. A esta altura, ya estás empezando a saber el taladro... Primero necesitamos agrega un concepto de género:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
La sección info del concepto de género tiene una
pluralName, que proporciona el texto que se usará para hacer referencia a
múltiples instancias del concepto de género. La sección info también
incluye un totalName, que proporciona el texto que se usará para
se refieren a todas las instancias
del concepto de género en su totalidad. Ambos son
utilizadas por Public Data Explorer para mostrar información relacionada con el género
concepto. En general, debes proporcionarlos para conceptos que se pueden usar como
dimensiones.
Ten en cuenta que el concepto de género también se extiende
entity:entity Esta es una buena práctica para los conceptos
que se utilizan como dimensiones, ya que te permite agregar nombres personalizados
las URLs y los colores de las diversas instancias de conceptos.
El concepto de género hace referencia a la tabla genders_table, que
Contiene los valores posibles para el género y sus nombres visibles
(se omite aquí).
Para agregar población por género a nuestro conjunto de datos, necesitamos crear una nueva porción. (recuerda que cada combinación de dimensiones disponible corresponde a una porción en conjunto de datos).
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
La definición de tabla para la porción se ve de la siguiente manera:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
El archivo CSV de la tabla tiene el siguiente aspecto:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
En comparación con los países anteriores, la población y la porción de desempleo, esta tiene una dimensión adicional: cada valor de la métrica de población corresponden no solo a un país y un año determinados, sino también a un género en particular.
Ten en cuenta que creamos de tu conjunto de datos. Es posible que no todas las métricas están disponibles para todas las dimensiones: la población es disponible anualmente para países y estados de EE.UU., mientras que los niveles de desempleo solo está disponible para países. El desglose por género está disponible para la población por país solamente; no está disponible para la tasa de desempleo y no para la dimensión de estado. La dispersión también puede existir en los datos a nivel de la cuenta, y ciertas métricas no tienen valores para ciertos valores de dimensión, pero eso no está representado en la DSPL.
Temas
La última función de DSPL que usaremos en nuestro conjunto de datos son los temas. Los temas se usan para clasificar conceptos de forma jerárquica, aplicaciones para ayudar a los usuarios a navegar hacia tus datos.
En el archivo DSPL, los temas aparecen justo antes de los conceptos. Aquí hay un ejemplo jerarquía de temas:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>Puedes anidar temas con la profundidad necesaria.
Para usar temas, solo debes hacer referencia a ellos desde el concepto definición, de la siguiente manera:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
Un concepto puede hacer referencia a más de un tema.
Envía tu conjunto de datos
Ahora que creaste el conjunto de datos, el siguiente paso es comprimirlo y subir el archivo ZIP para la herramienta Google Public Data Explorer. Si tienes algún problema, revisa las Preguntas frecuentes, que incluyen un análisis de los problemas de carga más comunes.
Como referencia, también puedes descargar el archivo en formato XML completo y el paquete completo de conjuntos de datos asociadas con este instructivo.
Lo que vendrá
¡Felicitaciones por crear tu primer conjunto de datos en DSPL! Ahora que comprender los conceptos básicos, te recomendamos que leas la Guía para desarrolladores, que, entre otras cosas, documentos "avanzados" Funciones de DSPL como en varios lenguajes y conceptos asignables.
También puedes analizar más ejemplos de conjuntos de datos.