DSPL مخفف Dataset Publishing Language است. مجموعه داده های توصیف شده در DSPL را می توان به Google Public Data Explorer وارد کرد، ابزاری که امکان کاوش غنی و بصری داده ها را فراهم می کند.
توجه: برای آپلود دادهها در Google Public Data با استفاده از ابزار بارگذاری دادههای عمومی ، باید یک حساب Google داشته باشید.
این آموزش یک مثال گام به گام از نحوه تهیه یک مجموعه داده پایه DSPL را ارائه می دهد.
مجموعه داده DSPL یک بسته نرم افزاری است که حاوی یک فایل XML و مجموعه ای از فایل های CSV است. فایل های CSV جداول ساده ای هستند که حاوی داده های مجموعه داده هستند. فایل XML فراداده مجموعه داده را توصیف می کند، از جمله ابرداده های اطلاعاتی مانند توصیف معیارها، و همچنین ابرداده های ساختاری مانند مراجع بین جداول. ابرداده به کاربران غیر متخصص اجازه می دهد تا داده های شما را کاوش و تجسم کنند.
تنها پیش نیاز برای درک این آموزش، سطح خوب درک XML است. برخی از درک مفاهیم ساده پایگاه داده (به عنوان مثال، جداول، کلیدهای اصلی) ممکن است کمک کند، اما لازم نیست. برای مرجع، فایل XML تکمیل شده و مجموعه داده کامل مرتبط با این آموزش نیز برای بررسی موجود است.
نمای کلی
قبل از شروع به ایجاد مجموعه داده ما، در اینجا یک نمای کلی سطح بالا از آنچه یک مجموعه داده DSPL شامل می شود آورده شده است:
- اطلاعات عمومی: درباره مجموعه داده
- مفاهیم: تعاریف "چیزهایی" که در مجموعه داده ظاهر می شوند (به عنوان مثال، کشورها، نرخ بیکاری، جنسیت و غیره)
- Slices: ترکیبی از مفاهیم که داده هایی برای آنها وجود دارد
- جداول: داده ها برای مفاهیم و برش ها. جداول مفهومی شامل شمارش و جداول برش داده های آماری است
- موضوعات: برای سازماندهی مفاهیم مجموعه داده در یک سلسله مراتب معنی دار از طریق برچسب زدن استفاده می شود
برای نشان دادن این مفاهیم نسبتاً انتزاعی، مجموعه داده (با دادههای ساختگی) مورد استفاده در این آموزش را در نظر بگیرید: سریهای زمانی آماری برای جمعیت و بیکاری، که با ترکیبهای مختلف کشور، ایالت ایالات متحده و جنسیت جمعآوری شدهاند.
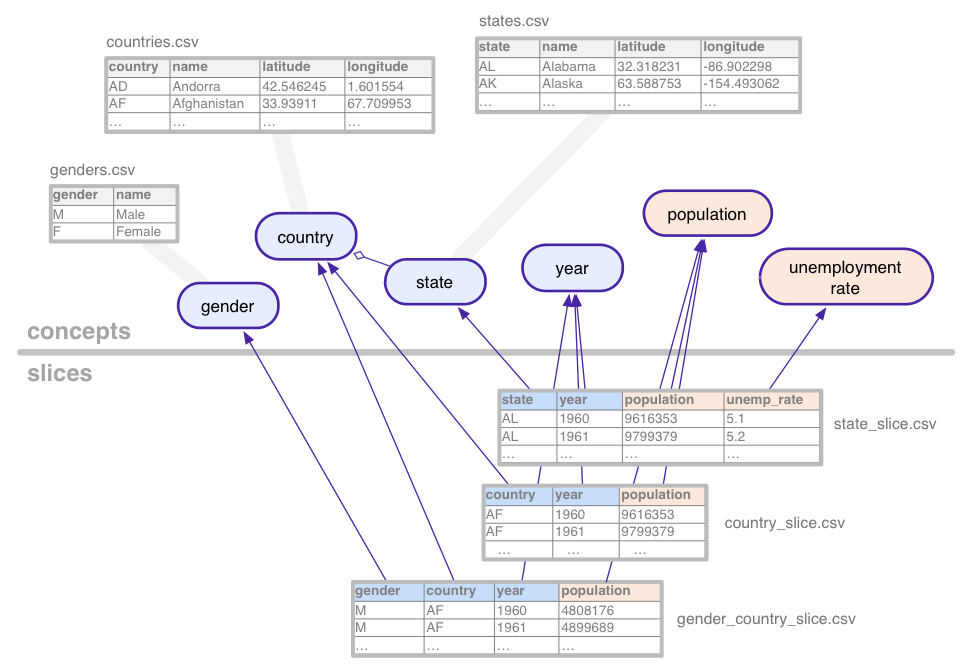
این مجموعه داده نمونه مفاهیم زیر را تعریف می کند:
- کشور
- جنسیت
- جمعیت
- دولت
- نرخ بیکاری
- سال
مفاهیمی که دسته بندی می شوند، مانند حالت، با جداول مفهومی مرتبط هستند که تمام مقادیر ممکن آنها را برمی شمارند (کالیفرنیا، آریزونا و غیره). مفاهیم ممکن است دارای ستون های اضافی برای ویژگی هایی مانند نام یا کشور یک ایالت باشد.
برش ها هر ترکیبی از مفاهیم را که داده های آماری در مجموعه داده وجود دارد، تعریف می کنند. یک برش شامل ابعاد و معیارها است. در تصویر بالا ابعاد آبی و متریک ها نارنجی است. در این مثال، برش gender_country_slice داده هایی برای population متریک و ابعاد country ، year و gender دارد. برش دیگری به نام country_slice ، تعداد کل جمعیت سالانه (متریک) را برای کشورها نشان می دهد.
برش ها علاوه بر ابعاد و معیارها، به جداول نیز اشاره می کنند که حاوی داده های واقعی است.
بیایید اکنون قدم به قدم ایجاد چنین مجموعه داده ای در DSPL را طی کنیم.
اطلاعات مجموعه داده
برای شروع، باید یک فایل XML برای مجموعه داده خود ایجاد کنیم. در اینجا شروع یک توضیح DSPL برای مجموعه داده نمونه ما است:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
توضیحات مجموعه داده با عنصر سطح بالای <dspl> شروع می شود. ویژگی targetNamespace حاوی یک URI است که به طور منحصر به فرد این مجموعه داده را شناسایی می کند. فضای نام مجموعه داده به ویژه هنگام انتشار مجموعه داده مهم است، زیرا شناسه جهانی مجموعه داده شما و وسیله ای برای سایرین برای مراجعه به آن خواهد بود.
توجه داشته باشید که ویژگی targetNamespace ممکن است حذف شود. در این مورد یک فضای نام منحصر به فرد به طور خودکار زمانی که مجموعه داده وارد می شود ایجاد می شود.
استفاده از اطلاعات سایر مجموعه های داده
مجموعه داده ها می توانند با وارد کردن آن مجموعه داده ها از تعاریف و داده های دیگر مجموعه داده ها استفاده مجدد کنند. هر عنصر <import> فضای نام مجموعه داده دیگری را که این مجموعه داده به آن ارجاع می دهد، مشخص می کند.
در مجموعه داده مثال ما، به تعاریفی از http://www.google.com/publicdata/dataset/google/quantity (یک مجموعه داده ایجاد شده توسط Google که حاوی مفاهیم مفید برای تعریف کمیت های عددی است) نیاز داریم، و از زمان ، موجودیت و مجموعه داده های جغرافیایی که به ترتیب تعاریف مربوط به زمان، موجودیت ها و جغرافیا را ارائه می دهند.
عنصر <dspl> بالای یک اعلان پیشوند فضای نام (مثلا xmlns:time="http://..." ) برای هر یک از مجموعه داده های وارد شده ارائه می کند. اعلانهای پیشوند برای ارجاع عناصر از مجموعه دادههای دیگر به صورت مختصر مورد نیاز است. به عنوان مثال، time:year به تعریف year در مجموعه داده وارد شده اشاره می کند که فضای نام آن با پیشوند time مرتبط است.
مجموعه داده و اطلاعات ارائه دهنده
عنصر <info> حاوی اطلاعات کلی در مورد مجموعه داده است: نام، توضیحات، و یک URL که در آن اطلاعات بیشتری می توان یافت.
عنصر <provider> حاوی اطلاعاتی درباره ارائهدهنده مجموعه داده است: نام آن و یک URL که در آن اطلاعات بیشتری میتوان یافت (به طور کلی صفحه اصلی ارائهدهنده داده).
تعریف مفاهیم
اکنون که اطلاعات کلی در مورد مجموعه داده ارائه کردهایم، آماده شروع تعریف محتوای آن هستیم. هدف بعدی ما اضافه کردن آمار جمعیت کشورها در 50 سال گذشته است.
اولین کاری که باید انجام دهیم این است که تعاریفی برای مفاهیم جمعیت، کشور و سال ارائه کنیم. در DSPL به این تعاریف مفاهیم می گویند.
مفهوم تعریفی از نوع داده ای است که در یک مجموعه داده ظاهر می شود. مقادیر داده ای که با یک مفهوم معین مطابقت دارند، نمونه هایی از آن مفهوم نامیده می شوند.
جمعیت
بیایید با تعریف مفهوم جمعیت شروع کنیم. در یک سند DSPL، مفاهیم در یک عنصر <concepts> که درست بعد از مجموعه داده و اطلاعات ارائه دهنده قرار می گیرد، تعریف می شوند.
در اینجا یک مفهوم جمعیت با حداقل اطلاعات مورد نیاز برای هر مفهوم وجود دارد: id (یک شناسه منحصر به فرد)، name و type .
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
در اینجا نحوه کار این نمونه آمده است:
- هر مفهومی باید یک
idارائه دهد که به طور منحصر به فرد مفهوم را در مجموعه داده مشخص کند. این بدان معناست که هیچ دو مفهومی که در یک مجموعه داده تعریف شده اند نمی توانند شناسه یکسانی داشته باشند. - درست مانند مجموعه داده و ارائه دهنده آن، عناصر
<info>اطلاعات متنی در مورد مفهوم، مانند نام و توضیحات آن را ارائه می دهند. - عنصر
<type>نوع داده را برای نمونه های مفهوم مشخص می کند (به عبارت دیگر، "مقادیر" آن). در این مثال، نوعpopulationintegerاست. DSPL از انواع داده های زیر پشتیبانی می کند:-
string -
integer -
float -
boolean -
date
-
کشور
حال بیایید تعریف مفهوم کشور را بنویسیم:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
تعریف مفهوم کشور مانند تعریف قبلی با یک id ، info و یک type شروع می شود.
ارزش های مفهومی
مفاهیم مقولهای مانند کشورها دارای شمارشی از همه موارد ممکن است. به عبارت دیگر، شما می توانید تمام کشورهای ممکنی را که می توان به آنها ارجاع داد لیست کرد. اما برای انجام این کار، هر کشور به یک شناسه منحصر به فرد نیاز دارد. این مثال از کدهای کشور ISO برای شناسایی کشورها استفاده می کند. این کدها از نوع string هستند.
در این مثال، شما نیازی به استفاده از کد ISO ندارید. شما می توانید به خوبی از نام کشور استفاده کنید. با این حال، نام ها بر اساس زبان متفاوت هستند، می توانند در طول زمان تغییر کنند، و همیشه به طور مداوم در مجموعه داده ها استفاده نمی شوند. برای کشورها و به طور کلی برای مفاهیم طبقه بندی شده، انتخاب شناسه های کوتاه، پایدار، معمولی و مستقل از زبان (در صورت وجود) روش خوبی است.
ویژگی های مفهومی
علاوه بر id ، مفهوم کشور یک عنصر <property> دارد که نام کشور را مشخص می کند. به عبارت دیگر، نام کشور ("ایرلند") دارایی کشور با id IE است. ویژگی ها نحوه ارائه اطلاعات ساختاریافته اضافی DSPL در مورد نمونه های یک مفهوم است.
درست مانند خود مفهوم، ویژگی ها دارای id ، info و type هستند.
داده های مفهومی
در نهایت، مفهوم کشور یک عنصر <table> دارد. این عنصر به جدولی اشاره می کند که فهرست همه کشورها را برمی شمارد.
استفاده از جداول برای برخی مفاهیم منطقی است، اما برای برخی دیگر نه. برای مثال، برشمردن تمام مقادیر ممکن برای جمعیت مفهومی منطقی نیست. با این حال، اگر به جدولی برای مفهومی ارجاع می دهید، آن جدول باید همه نمونه های مفهوم را داشته باشد – برای مثال، باید همه کشورها را فهرست کند، نه فقط چند نمونه را.
مجموعه داده، جدول countries_table را به صورت زیر تعریف می کند:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
جدول کشورها ستون های جدول و انواع آنها را مشخص می کند و به یک فایل CSV که حاوی داده است ارجاع می دهد. این CSV میتواند همراه و با مجموعه داده XML آپلود شود یا از راه دور از طریق HTTP، HTTPS یا FTP قابل دسترسی باشد. در موارد دوم، شما باید countries.csv با یک URL جایگزین کنید، به عنوان مثال http://www.myserver.com/mydata/countries.csv .
هرجا که ذخیره شود، فایل CSV به شکل زیر است:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
ردیف اول جدول، شناسه های ستون را همانطور که در تعریف table DSPL مشخص شده است، فهرست می کند. هر یک از ردیف های زیر با یک نمونه از مفهوم کشور مطابقت دارد. اگر مفهوم یک جدول داشته باشد، جدول باید شامل تمام نمونه های مفهوم باشد - در این مورد، باید همه کشورها را فهرست کند.
ستون ها با مفهوم کشور و ویژگی های آن بر اساس شناسه آنها نگاشت می شوند. شناسه ستون اول، country ، با شناسه مفهومی مطابقت دارد. این بدان معنی است که این ستون حاوی شناسه منحصر به فرد کشور است که با مفهوم کشور تعریف شده است. ستون بعدی مربوط به name ویژگی مفهوم کشور است. مقادیر این ستون با مقادیر ویژگی name مطابقت دارد.
چند الزام برای داده های CSV برای جدول مفهومی وجود دارد:
- عناوین ستون ها در خط اول فایل داده باید دقیقاً با
idمفهومی وidویژگی مفهومی که داده ها با آن مرتبط هستند مطابقت داشته باشد (اگرچه ترتیب ممکن است متفاوت باشد). - هر ردیف باید دقیقاً همان تعداد عناصر را داشته باشد که تعداد ویژگی های مفهوم (حتی اگر مقدار خالی باشد).
- هر مقدار برای فیلد
idمفهوم (در اینجا، کد کشور) باید منحصر به فرد و غیر خالی باشد (یک فیلد خالی یک با نویسه های صفر یا فقط خالی است). - مقادیر برای ویژگی هایی که به مفاهیم دیگر ارجاع می دهند یا باید خالی باشند یا یک مقدار معتبر از مفهوم ارجاع شده باشند.
- مقادیری که حاوی کاما، گیومه های دوتایی یا کاراکترهای خط جدید هستند باید به طور کامل در گیومه های دوتایی محصور شوند.
- هر کاراکتر دو نقل قول تحت اللفظی درون یک مقدار باید بلافاصله قبل از یک نقل قول مضاعف دیگر قرار گیرد.
سال
آخرین مفهومی که برای داده های جمعیت کشورمان نیاز داریم، مفهومی است که سال ها را نشان دهد. به جای تعریف یک مفهوم جدید، از مفهوم سال از یکی از مجموعه دادههایی که وارد کردهایم استفاده میکنیم: "http://www.google.com/publicdata/dataset/google/time". برای انجام این کار، باید آن را به عنوان time:year ارجاع دهیم، جایی که time نشان دهنده مجموعه داده ای است که به آن ارجاع داده شده است، و year مفهوم را مشخص می کند.
مفاهیم متعارف
time:year بخشی از مجموعه کوچکی از مفاهیم متعارف تعریف شده توسط گوگل است. مفاهیم متعارف تعاریف اساسی برای زمان، جغرافیا، کمیت های عددی، واحدها و غیره ارائه می دهند.
در واقع، مفهوم کشور تعریف شده در بالا به عنوان یک مفهوم متعارف وجود دارد. ما آن را در اینجا فقط برای مصورسازی ایجاد کردیم. در صورت امکان، باید از مفاهیم متعارف در مجموعه داده های خود استفاده کنید، چه به طور مستقیم یا با گسترش آنها (در مورد پسوند در زیر بیشتر توضیح دهید). مفاهیم متعارف، دادههای شما را با سایر مجموعههای داده قابل مقایسه میسازد و ویژگیهایی را برای مجموعه دادههای شما در Public Data Explorer فعال میکند. به عنوان مثال، متحرک سازی داده ها در طول زمان یا نشان دادن داده های جغرافیایی بر روی نقشه به ترتیب بر استفاده از مفاهیم time و geo متعارف تکیه دارد.
برش اول
اکنون که مفاهیمی برای جمعیت، کشور و سال داریم، وقت آن است که آنها را کنار هم بگذاریم!
برای آن، ما باید یک برش ایجاد کنیم که آنها را ترکیب کند. در DSPL، یک برش ترکیبی از مفاهیم است که داده ها برای آنها وجود دارد.
چرا فقط یک جدول با ستون های سمت راست ایجاد نمی کنید؟ زیرا برش ها اطلاعات مجموعه داده را بر حسب مفاهیم آن می گیرند. با ایجاد قطعات بیشتری از مجموعه داده خود، این موضوع واضح تر می شود.
برش ها در فایل DSPL در زیر عنصر <slices> ظاهر می شوند که باید درست بعد از بخش concepts ظاهر شود.
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices> درست مانند مفاهیم، هر برش دارای یک id ( countries_slice ) است که به طور منحصر به فرد برش را در مجموعه داده مشخص می کند.
یک برش شامل دو نوع مرجع مفهومی است: ابعاد و معیارها . مقادیر معیارها با مقادیر ابعاد متفاوت است. در اینجا، ارزش population (متریک) بر اساس ابعاد country و year متفاوت است.
درست مانند مفاهیم، برش ها شامل ارجاع به جدولی است که حاوی داده های برش است. جدول ارجاع شده باید یک ستون برای هر بعد و متریک برش داشته باشد. درست مانند مفاهیم، ابعاد و معیارهای برش با همان شناسهها به ستونهای جدول نگاشت میشوند.
جدول برش
جدول برای برش جمعیت ما در بخش tables فایل DSPL ظاهر می شود:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
توجه داشته باشید که ستون year دارای ویژگی format است که نحوه قالب بندی سال ها را مشخص می کند. فرمت های تاریخ پشتیبانی شده آنهایی هستند که با فرمت Joda DateTime تعریف شده اند.
جدول countries_slice ستون های جدول و انواع آنها را مشخص می کند و به یک فایل CSV که حاوی داده ها است اشاره می کند. فایل CSV به شکل زیر است:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
هر ردیف از جدول داده ها حاوی ترکیبی منحصر به فرد از ابعاد country و year به همراه مقدار متناظر متریک population است (مثلاً ابعاد جمعیت - متریک - افغانستان در سال 1960).
توجه داشته باشید که مقادیر در ستون country با مقدار/شناسه مفهوم country که کد ۲ حرفی ISO 3166 کشور است مطابقت دارد.
داده CSV برای یک برش باید محدودیت های زیر را برآورده کند:
- هر مقدار فیلد بعد (مانند
countryوyear) باید خالی نباشد. مقادیر فیلدهای متریک (مانندpopulation) می توانند خالی باشند. یک مقدار خالی با هیچ کاراکتری نشان داده نمی شود. - هر مقدار یک فیلد بعد که به مفهومی ارجاع می دهد باید در داده های آن مفهوم وجود داشته باشد. به عنوان مثال، مقدار
AFباید در جدول داده مفهومcountryوجود داشته باشد. - هر ترکیب منحصر به فردی از مقادیر ابعاد، به عنوان مثال
AF, 2000، ممکن است فقط یک بار رخ دهد. - داده ها باید بر اساس ستون های بعد غیر زمان (به هر ترتیب) و سپس، به صورت اختیاری، با هر یک از ستون های دیگر مرتب شوند. بنابراین، برای مثال، در یک جدول با ستونهای
[date, dimension1, dimension2, metric1, metric2]، میتوانید بر اساسdimension1و سپسdimension2و سپسdateمرتب کنید، اما نه بر اساسdateو سپس ابعاد.
خلاصه
در این مرحله، ما به اندازه کافی در DSPL خود برای توصیف داده های جمعیت کشور داریم. برای جمع بندی، کاری که باید انجام می دادیم این بود:
- هدر DSPL و توضیحات مجموعه داده و ارائه دهنده آن را ایجاد کنید
- یک مفهوم برای جمعیت و مفهومی دیگر برای کشور ایجاد کنید، با یک فایل csv که همه کشورها و نام آنها را برمی شمرد.
- با ارجاع به مفهوم سال از قبل تعریف شده در مجموعه دادههای زمانی وارد شده از Google، برشی با تعداد جمعیت ما برای کشورها در طول زمان ایجاد کنید.
در ادامه این آموزش، مجموعه داده خود را با افزودن ابعاد بیشتر در برشهای بیشتر و همچنین معیارهای بیشتر گروهبندی شده بر اساس موضوع، غنیتر میکنیم.
افزودن یک بعد: ایالات ایالات متحده
بیایید اکنون مجموعه داده خود را با افزودن داده های جمعیتی برای ایالت های ایالات متحده غنی کنیم. ابتدا باید یک مفهوم برای دولت ها تعریف کنیم. این بسیار شبیه مفهوم کشوری است که قبلاً تعریف کردیم.
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>پسوندهای مفهومی و ارجاعات دارایی
مفهوم حالت چندین ویژگی جدید DSPL را معرفی می کند.
اول، state مفهوم دیگری را گسترش می دهد ، geo:location (تعریف شده در مجموعه داده جغرافیایی خارجی که در ابتدای مجموعه داده خود وارد کردیم). از نظر معنایی، این بدان معنی است که state نوعی geo:location است. نتیجه این است که تمام ویژگی ها و ویژگی های geo:location را به ارث می برد. به طور خاص، مکان ویژگیهای latitude و longitude جغرافیایی را تعریف میکند. با بسط مفهوم قبلی، این ویژگی ها برای حالت نیز اعمال می شوند. علاوه بر این، از آنجایی که مکان از entity:entity به ارث میبرد، state نیز تمام ویژگیهای دومی، از جمله name ، description ، و info_url را دریافت میکند.
توجه: مفهوم کشوری که قبلاً تعریف شده بود، باید از لحاظ فنی، از geo:location نیز گسترش یابد. این نکته قبلاً برای سادگی حذف شد. با این حال، ما مکان به ارث بری کشور را در فایل XML نهایی قرار داده ایم.
توجه: می توانید از ساختار extends در مجموعه داده های خود برای استفاده مجدد از اطلاعات تعریف شده توسط مجموعه داده های دیگر استفاده کنید. استفاده از extends مستلزم آن است که تمام نمونه های مفهوم شما نمونه های معتبر مفهومی باشند که شما در حال گسترش آن هستید. برنامه های افزودنی به شما امکان می دهند ویژگی ها و ویژگی های اضافی اضافه کنید و مجموعه نمونه ها را به زیر مجموعه ای از نمونه های مفهوم توسعه یافته محدود کنید.
علاوه بر ارث، دارایی دولتی ایده ارجاعات مفهومی را نیز مطرح می کند. به طور خاص، مفهوم state دارای خاصیتی به نام country است که به مفهوم کشوری که در بالا ایجاد کردیم اشاره دارد. این کار با استفاده از یک ویژگی concept انجام می شود. توجه داشته باشید که این ویژگی یک شناسه ارائه نمی کند، فقط یک مرجع مفهومی ارائه می دهد. این معادل ایجاد یک شناسه با همان مقدار id مفهوم ارجاع شده است (یعنی country در این مثال). رابطه سلسله مراتبی بین ایالت و شهرستان با داشتن یک ویژگی isParent="true" در مرجع بدست می آید. به طور کلی، ابعاد با روابط سلسله مراتبی، مانند جغرافیاها، باید به این صورت نشان داده شوند، با مفهوم فرزند دارای خاصیتی است که با استفاده از ویژگی isParent به مفهوم والد ارجاع می دهد.
تعریف جدول برای حالت ها به صورت زیر است:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
ستون کشور یک مقدار ثابت برای همه ایالت ها دارد. تعیین آن در DSPL از تکرار آن مقدار برای هر حالت در داده جلوگیری می کند. همچنین توجه داشته باشید که ما ستونهایی را برای name ، latitude و longitude اضافه کردهایم زیرا state این ویژگیها را از geo:location به ارث برده است. از سوی دیگر، برخی از ویژگی های به ارث برده شده (به عنوان مثال، description ) ستون ندارند. این مشکلی ندارد - اگر یک ویژگی از جدول تعریف مفهوم حذف شود، آنگاه مقدار آن برای هر نمونه از مفهوم تعریف نشده فرض می شود.
فایل CSV به شکل زیر است:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
از آنجایی که ما از قبل مفاهیمی برای جمعیت و سال داریم، میتوانیم از آنها برای تعریف یک برش جدید برای جمعیت ایالتها استفاده مجدد کنیم.
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>تعریف جدول داده ها به صورت زیر است:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
و فایل CSV به شکل زیر است:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
صبر کنید، چرا به جای اضافه کردن بعد دیگری به قسمت قبلی، یک برش جدید ایجاد کردیم؟
یک برش با ابعاد هم برای ایالت و هم برای کشور صحیح نیست، زیرا برخی از ردیف ها برای داده های کشور و برخی ردیف ها برای داده های وضعیت هستند. جدول برای برخی از ابعاد دارای "سوراخ" است که مجاز نیست (به یاد داشته باشید که مقادیر از دست رفته فقط برای معیارها مجاز هستند و نه ابعاد).
ابعاد به عنوان یک "کلید اصلی" برای برش عمل می کنند. این بدان معنی است که هر ردیف داده باید مقادیری برای همه ابعاد داشته باشد و هیچ دو ردیف داده نمی توانند مقادیر دقیقاً یکسان را برای همه ابعاد داشته باشند.
اضافه کردن یک متریک: نرخ بیکاری
حال بیایید معیار دیگری را به مجموعه داده خود اضافه کنیم:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
بخش info این معیار دارای یک نام، توضیحات و یک URL (پیوند به اداره آمار کار ایالات متحده) است.
این مفهوم همچنین مفهوم متعارف quantity:rate گسترش می دهد. مجموعه داده کمیت مفاهیم اصلی را برای نمایش کمیت های عددی تعریف می کند. در مجموعه داده خود، باید مفاهیم عددی خود را با گسترش مفهوم کمیت مناسب ایجاد کنید. بنابراین، مفهوم population تعریف شده در بالا، از نظر فنی، باید از quantity:amount گسترش یافته باشد.
ویژگی های مفهومی
این مفهوم همچنین ساختار یک ویژگی را معرفی می کند. در این مثال، یک ویژگی برای گفتن اینکه unemployment_rate یک درصد است استفاده می شود. ویژگی is_percentage از مفهوم quantity:rate به ارث برده شده است که این مفهوم بسط می دهد. این اطلاعات توسط Public Data Explorer برای نشان دادن علائم درصد هنگام تجسم داده ها استفاده می شود.
ویژگیها مکانیزمی کلی برای پیوست کردن جفتهای کلید/مقدار به یک مفهوم ارائه میکنند (بر خلاف ویژگیها، که مقادیر اضافی را با نمونههایی از یک مفهوم مرتبط میکنند). درست مانند مفاهیم و ویژگی ها، ویژگی ها دارای id ، info و type هستند. مانند خواص، آنها می توانند به مفاهیم دیگر ارجاع دهند.
ویژگی ها فقط برای چیزهای کلی از پیش تعریف شده مانند ویژگی های عددی نیستند. شما می توانید ویژگی های خود را برای مفاهیم خود تعریف کنید.
افزودن داده های نرخ بیکاری برای ایالات متحده
ما اکنون آماده هستیم تا داده های نرخ بیکاری را برای ایالت های ایالات متحده اضافه کنیم. از آنجایی که نرخ بیکاری یک معیار است و ما قبلاً دادههای جمعیت ایالتها را داریم، میتوانیم آن را به برشی که قبلاً برای ابعاد ایالت و سال ایجاد کردهایم اضافه کنیم:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... و ستون دیگری به تعریف جدول اضافه کنید:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... و به فایل CSV:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
قبلاً گفتیم که برای هر برش، ابعاد یک کلید اصلی برای برش است. علاوه بر این، هر مجموعه داده فقط می تواند شامل یک برش برای ترکیب معینی از ابعاد باشد. تمام معیارهای موجود برای این ابعاد باید به همان برش تعلق داشته باشند.
ابعاد بیشتر: تفکیک جمعیت بر اساس جنسیت
بیایید مجموعه داده خود را با تفکیک جمعیت بر اساس جنسیت برای کشورها غنی کنیم. در حال حاضر، شما شروع به دانستن این تمرین کرده اید... ابتدا باید یک مفهوم برای جنسیت اضافه کنیم:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
بخش info مفهوم جنسیت دارای یک pluralName است که متنی را برای ارجاع به چندین نمونه از مفهوم جنسیت ارائه میکند. بخش info همچنین شامل یک totalName است که متنی را برای ارجاع به تمام نمونههای مفهوم جنسیت به عنوان یک کل ارائه میکند. هر دوی اینها توسط Public Data Explorer برای نمایش اطلاعات مربوط به مفهوم جنسیت استفاده می شود. به طور کلی، شما باید آنها را برای مفاهیمی که می توانند به عنوان ابعاد استفاده شوند، ارائه دهید.
توجه داشته باشید که مفهوم جنسیت نیز از entity:entity گسترش یافته است. این یک روش خوب برای مفاهیمی است که به عنوان ابعاد استفاده می شوند، زیرا به شما امکان می دهد نام ها، URL ها و رنگ های سفارشی را برای نمونه های مفهومی مختلف اضافه کنید.
مفهوم جنسیت به جدول genders_table اشاره دارد که حاوی مقادیر ممکن برای جنسیت و نامهای نمایشی آنها است (در اینجا حذف شده است).
برای افزودن جمعیت بر اساس جنسیت به مجموعه داده خود، باید یک برش جدید ایجاد کنیم (به یاد داشته باشید: هر ترکیب موجود از ابعاد مربوط به یک برش در مجموعه داده است).
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
تعریف جدول برای برش به صورت زیر است:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
فایل CSV برای جدول به صورت زیر است:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
در مقایسه با کشورهای قبلی، جمعیت و برش بیکاری، این یکی بعد دیگری دارد. هر مقدار از متریک جمعیت نه تنها با یک کشور و سال خاص، بلکه با یک جنسیت خاص نیز مطابقت دارد.
توجه داشته باشید که ما یک مجموعه داده "پراکنده" ایجاد کرده ایم. همه معیارها برای همه ابعاد در دسترس نیستند: جمعیت برای کشورها و ایالت های ایالات متحده به صورت سالانه در دسترس است، در حالی که نرخ بیکاری فقط برای کشورها در دسترس است. تفکیک بر اساس جنسیت فقط برای جمعیت بر اساس کشور در دسترس است. برای معیار نرخ بیکاری و نه برای بعد دولتی در دسترس نیست. پراکندگی همچنین می تواند در سطح داده وجود داشته باشد، با معیارهای خاصی که مقادیری برای مقادیر ابعاد خاصی ندارند، اما این در DSPL نشان داده نمی شود.
موضوعات
آخرین ویژگی DSPL که در مجموعه داده خود استفاده خواهیم کرد موضوعات است. موضوعات برای طبقه بندی مفاهیم به صورت سلسله مراتبی استفاده می شوند و توسط برنامه های کاربردی برای کمک به کاربران جهت حرکت به داده های شما استفاده می شوند.
در فایل DSPL، موضوعات درست قبل از مفاهیم ظاهر می شوند. در اینجا یک نمونه سلسله مراتب موضوع وجود دارد:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>می توانید موضوعات را تا آنجا که لازم است عمیقاً لانه کنید.
برای استفاده از موضوعات، فقط باید به آنها از تعریف مفهوم ارجاع دهید، به شرح زیر:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
یک مفهوم ممکن است به بیش از یک موضوع اشاره کند.
ارسال مجموعه داده شما
اکنون که مجموعه داده خود را ایجاد کرده اید، گام بعدی این است که آن را فشرده کرده و فایل فشرده را در ابزار Google Public Data Explorer آپلود کنید . اگر با مشکلی مواجه شدید، سؤالات متداول را بررسی کنید، که شامل بحث در مورد رایج ترین مشکلات بارگذاری است.
برای مرجع، همچنین می توانید فایل XML کامل و مجموعه داده کامل مرتبط با این آموزش را دانلود کنید.
از اینجا به کجا برویم
به خاطر ایجاد اولین مجموعه داده DSPL خود را تبریک می گویم! اکنون که اصول اولیه را فهمیدید، توصیه میکنیم راهنمای توسعهدهنده را مطالعه کنید، که در میان چیزهای دیگر، ویژگیهای «پیشرفته» DSPL مانند پشتیبانی از چند زبان و مفاهیم قابل نقشهبرداری را مستند میکند.
همچنین ممکن است بخواهید به چند مجموعه داده نمونه دیگر نگاه کنید.