DSPL הוא ראשי תיבות של Dataset Publishing Language. מערכי נתונים שמתוארים ב-DSPL ניתנים לייבוא אל Google Public Data Explorer, כלי שמאפשר לחקור ויזואלית ועשירה של .
הערה: כדי להעלות נתונים ל-Google Public Data באמצעות הכלי להעלאת נתונים ציבוריים, חייב להיות לכם חשבון Google.
המדריך הזה מדגים הוראות מפורטות להכנת מערך נתונים של DSPL.
מערך נתונים של DSPL הוא חבילה שמכילה קובץ XML וקבוצה של קובצי CSV. קובצי ה-CSV הם טבלאות פשוטות שמכילות את הנתונים של מערך הנתונים. קובץ ה-XML מתאר את המטא-נתונים של מערך הנתונים, כולל מטא-נתונים אינפורמטיביים, כמו תיאורים של מדדים, וגם מטא-נתונים מבניים, כמו הפניות בין טבלאות. המטא-נתונים מאפשרים משתמשים שאינם מומחים בודקים וממחישים את הנתונים.
הדרישה המוקדמת היחידה להבנת המדריך הזה היא רמה טובה של הבנה של XML. הבנה מסוימת של מושגים פשוטים של מסדי נתונים (למשל, טבלאות ומפתחות ראשיים), אבל זה לא חובה. לידיעתכם, קובץ ה-XML המלא, מערך הנתונים המלא החבילה שמשויכת למדריך הזה זמינה גם לבדיקה.
סקירה כללית
לפני שנתחיל ליצור את מערך הנתונים שלנו, הנה סקירה כללית ברמה גבוהה מה מכיל מערך נתונים של DSPL:
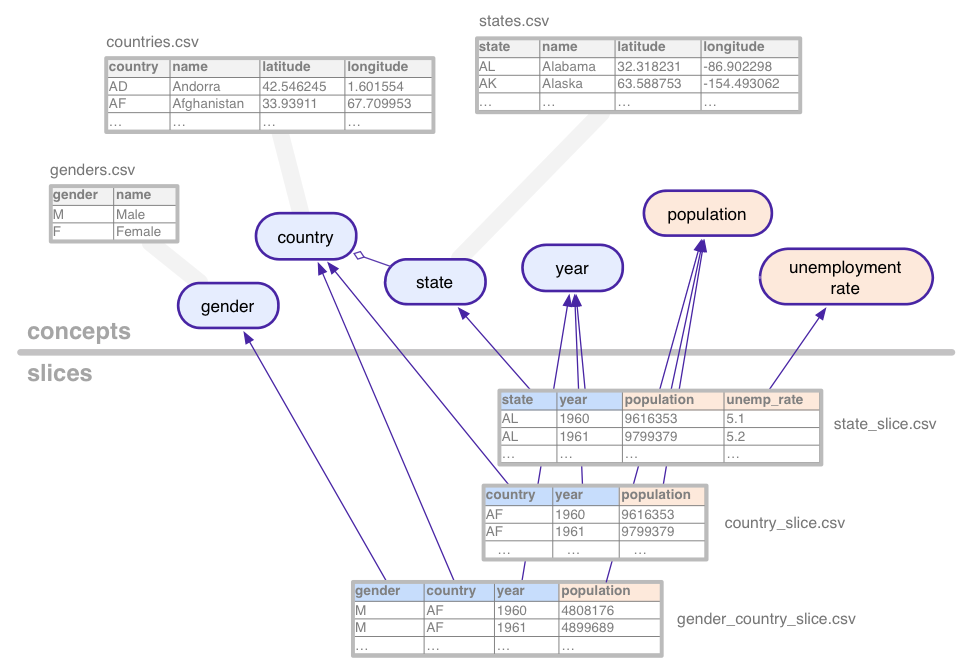
- מידע כללי: מידע על מערך הנתונים
- מושגים: הגדרות של 'דברים' ש מופיעים במערך הנתונים (למשל מדינות, שיעור אבטלה, מגדר, etc.)
- פרוסות: שילובים של מושגים שעבורם יש רוחב פס
- טבלאות: נתונים של מושגים ופלחים. טבלאות מושגים להחזיק ספירות וטבלאות פרוסות כוללות נתונים סטטיסטיים
- נושאים: משמשים לארגון המושגים של מערך הנתונים בהיררכיה משמעותית באמצעות
כדי להמחיש מושגים מופשטים אלה, נבחן את מערך הנתונים (עם נתוני דמה) ששימשו לאורך המדריך הזה: סדרות זמנים סטטיסטיות עבור אוכלוסייה ואטלה, במצטבר לפי שילובים שונים של מדינות, מדינה בארה"ב ומגדר.
במערך הנתונים לדוגמה הזה מוגדרים המושגים הבאים:
- country
- gender
- אוכלוסייה
- הסמוי הסופי
- שיעור אבטלה
- שנה
מושגים שמחולקים לקטגוריות, כמו מדינה, קשורים לקונספט tables, שמפרטים את כל הערכים האפשריים שלהם (קליפורניה, אריזונה וכו'). למושגים יכולים להיות עמודות נוספות למאפיינים, כמו שם או מדינה של מדינה מסוימת.
פרוסות מגדירות כל שילוב של מושגים שעבורו יש
הנתונים הסטטיסטיים במערך הנתונים. פרוסה מכילה מאפיינים ו
מדדים. בתמונה שלמעלה, המידות הן כחולות
המדדים כתומים. בדוגמה הזאת, הפלח
ל-gender_country_slice יש נתונים עבור המדד
population והמאפיינים country,
year וגם gender. פלח נוסף שנקרא
country_slice, מציג את סך מספרי האוכלוסייה השנתיים (מדד) עבור
מדינות.
בנוסף למאפיינים ולמדדים, הפלחים מפנים גם הם טבלאות, שמכילות את הנתונים בפועל.
עכשיו נעבור שלב אחר שלב בתהליך היצירה של מערך נתונים כזה. DSPL.
פרטי מערך הנתונים
כדי להתחיל, אנחנו צריכים ליצור קובץ XML למערך הנתונים שלנו. אלה סוגי המודלים בהתחלה של תיאור DSPL של מערך הנתונים לדוגמה:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
התיאור של מערך הנתונים מתחיל בערך <dspl> ברמה העליונה
לרכיב מסוים. המאפיין targetNamespace מכיל URI
משמש לזיהוי ייחודי של מערך הנתונים הזה. במיוחד מרחב השמות של מערך הנתונים
חשוב מאוד לפרסם את מערך הנתונים, כי הוא יהיה המזהה הגלובלי של
מערך הנתונים, ואמצעים אחרים כדי להתייחס אליו.
לתשומת ליבכם, אפשר להשמיט את המאפיין targetNamespace. לחשבון
במקרה כזה, מרחב שמות ייחודי נוצר באופן אוטומטי כשמערך הנתונים
שיובאו.
שימוש במידע ממערכי נתונים אחרים
במערכי נתונים אפשר לייבא הגדרות ונתונים ממערכי נתונים אחרים
מערכי הנתונים האלה. כל רכיב <import> מציין את
של מערך נתונים אחר שמערך הנתונים הזה יתייחס אליו.
במערך הנתונים לדוגמה שלנו נזדקק להגדרות מ-http://www.google.com/publicdata/dataset/google/quantity. (מערך נתונים שנוצר על ידי Google ומכיל מושגים שמועילים להגדרה כמויות מספריות), וממערכי הנתונים זמן, ישות ומיקום גיאוגרפי, שמספקים הגדרות שקשורות לזמן, לישויות ולמיקום גיאוגרפי, בהתאמה.
רכיב <dspl> העליון מספק קידומת של מרחב שמות
הצהרה (למשל xmlns:time="http://...") לכל אחד מהם
מערכי הנתונים שיובאו. נדרשות הצהרות קידומת כדי להפנות
אלמנטים ממערכי נתונים אחרים בצורה מתומצתת. לדוגמה,
time:year מפנה להגדרה של year
של מערך נתונים מיובא שמרחב השמות שלו משויך לתחילית
time.
פרטי מערך הנתונים והספק
הרכיב <info> מכיל מידע כללי על
מערך הנתונים: שם, תיאור וכתובת URL שבה אפשר למצוא מידע נוסף
נמצא.
הרכיב <provider> מכיל מידע על
הספק של מערך הנתונים: השם שלו וכתובת URL שבה אפשר למצוא מידע נוסף
שנמצא (בדרך כלל דף הבית של ספק הנתונים).
הגדרת מושגים
עכשיו, אחרי שסיפקנו מידע כללי על מערך הנתונים, אנחנו מוכנים להתחיל להגדיר את התוכן. המטרה הבאה שלנו היא נתונים סטטיסטיים של אוכלוסיות במדינות במהלך 50 השנים האחרונות.
הדבר הראשון שאנחנו צריכים לעשות הוא לספק כמה הגדרות עבור המושגים של אוכלוסייה, מדינה ושנה. ב-DSPL, ההגדרות האלה נקראות מושגים.
קונספט הוא הגדרה של סוג של נתונים שמופיעים של הכיתובים. ערכי הנתונים שתואמים לקונספט מסוים נקראים מכונות של הקונספט הזה.
אוכלוסייה
נתחיל עם הגדרת המושג 'אוכלוסייה'. תוך שימוש
מסמך DSPL, המושגים מוגדרים ב<concepts>
שמופיע מיד אחרי פרטי מערך הנתונים והספק.
הנה קונספט של אוכלוסייה עם המידע המינימלי שנדרש
לכל קונספט: id (מזהה ייחודי), name וגם
type.
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
כך עובדת דוגמה זו:
- כל קונספט חייב לספק
idשמזהה באופן ייחודי את המושג במערך הנתונים. כלומר, לא מוגדרים שני מושגים יכול להיות לאותו מערך נתונים אותו מזהה. - בדיוק כמו לגבי מערך הנתונים והספק שלו,
רכיבי
<info>מספקים מידע טקסטואלי על של המונח, כגון השם והתיאור שלו. - הרכיב
<type>מציין את סוג הנתונים של מכונות של המושג (במילים אחרות, ה"ערכים"). בדוגמה הזו, הסוג שלpopulationהואinteger. DSPL תומך בסוגי הנתונים הבאים:stringintegerfloatbooleandate
מדינה
עכשיו נכתוב את ההגדרה של המושג מדינה:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
הגדרת הקונספט של המדינה מתחילה כמו ההגדרה הקודמת,
עם id, info ו-type.
ערכי הקונספט
למושגים קטגוריים, כמו מדינות, יש מספר של כל האפשרויות
במקרים שונים. במילים אחרות, אפשר לציין את כל המדינות האפשריות
שיש הפניה אליו. עם זאת, כדי לעשות זאת, לכל מדינה נדרש מזהה ייחודי.
בדוגמה הזו נעשה שימוש ב-
קודי מדינות (לפי תקן ISO) כדי לזהות מדינות. הקודים האלה
מסוג string.
בדוגמה הזו לא צריך להשתמש בקוד ISO. עבורך אפשר להשתמש בשם המדינה. עם זאת, השמות משתנים משפה לשפה, יכולים להשתנות עם הזמן, ולא תמיד נעשה בהם שימוש עקבי במערכי נתונים שונים. לגבי מדינות, ועבור מושגים שמבוססים על קטגוריות באופן כללי, להתאמן על בחירה, קצר, יציב, בשימוש נפוץ ובלתי תלוי בשפה מזהים (אם הם קיימים).
מאפייני קונספט
בנוסף לישות id, לקונספט של מדינה יש
רכיב <property> שמציין את שם המדינה.
במילים אחרות, שם המדינה (אירלנד) הוא נכס
של המדינה עם id IE. המאפיינים הם האופן שבו DSPL מספקת
לקבל מידע מובנה נוסף על המופעים של קונספט מסוים.
בדיוק כמו בתפיסה עצמה, לנכסים יש id,
info ו-type.
נתוני קונספט
לבסוף, קונספט המדינה כולל רכיב <table>.
הרכיב הזה מפנה לטבלה שמספורת את הרשימה של כל
מדינות.
השימוש בטבלאות הגיוני לחלק מהמושגים, אבל לא למושגים אחרים. עבור לא הגיוני לספור את כל הערכים האפשריים אוכלוסיית המושג. אבל אם אתם מפנים לטבלה של מושג מסוים, הטבלה חייבת להכיל את כל המופעים של המושג - לדוגמה יש לכלול בו רשימה של כל המדינות, לא רק כמה דוגמאות.
מערך הנתונים מגדיר את הטבלה countries_table באופן הבא:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
בטבלת המדינות מפורטות העמודות של הטבלה והסוגים שלהן.
ומפנה לקובץ CSV שמכיל את הנתונים. קובץ ה-CSV הזה יכול להיות
בחבילה והועלו עם ה-XML של מערך הנתונים או ניגשו מרחוק דרך HTTP, HTTPS,
או FTP. במקרים האחרונים, היית מחליף את countries.csv עם
כתובת URL, למשל http://www.myserver.com/mydata/countries.csv.
בכל מקום שבו הוא מאוחסן, קובץ ה-CSV נראה כך:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
השורה הראשונה בטבלה מפרטת את מזהי העמודות, כפי שמצוין ב-DSPL
ההגדרה של table. כל אחת מהשורות הבאות תואמת
מופע בקונספט של מדינה. אם הקונספט כולל טבלה, אז
הטבלה חייבת להכיל את כל המופעים של הקונספט
צריך לציין את כל המדינות.
העמודות ממופות למושג המדינה ולמאפיינים שלה על סמך
את המזהה שלו. מזהה העמודה הראשונה, country, תואם לקונספט
למזהה נתון. כלומר העמודה הזו מכילה את מזהה המדינה הייחודי
מוגדר בקונספט של מדינה. העמודה הבאה תואמת
המאפיין name של קונספט המדינה. הערכים
בעמודה הזו תואמים לערכים של הנכס name.
יש כמה דרישות לגבי נתוני CSV של טבלת המושגים:
- כותרות העמודות בשורה הראשונה של קובץ הנתונים חייבות
התאמה מדויקת לקונספט
idולנכסidמהקונספט שאליו הנתונים משויכים (אם כי עשויים להשתנות). - כל שורה צריכה להכיל בדיוק אותו מספר רכיבים כמו מספר הרכיבים מאפיינים בקונספט (גם אם הערך ריק).
- כל ערך בשדה
idשל הקונספט (כאן מופיע קוד מדינה) חייב להיות ייחודי ולא ריק (שדה ריק הוא 1 עם אפס או רק תווי רווח לבן). - ערכים של מאפיינים שמפנים למושגים אחרים צריכים להיות ריק או ערך חוקי של המושג שאליו מתבצעת ההפניה.
- ערכים שכוללים פסיקים, מירכאות כפולות או תווי שורה חדשה חייבים להיות מוקף במירכאות כפולות.
- כל תו של מירכאות כפולות בתוך הערך חייב להופיע באופן מיידי. ולפניו מירכאות כפולות נוספות.
שנה
הקונספט האחרון שדרוש לנו לנתוני אוכלוסיית המדינה הוא קונספט
שמייצגים שנים. במקום להגדיר קונספט חדש, נשתמש
אחד ממערכי הנתונים שייבאנו:
"http://www.google.com/publicdata/dataset/google/time". כדי לעשות את זה,
אנחנו צריכים להתייחס אליו בתור time:year, כאשר time
שמייצג את מערך הנתונים שיש אליו הפניה, ו-year מזהה
את הקונספט שלו.
מושגים קנוניים
time:year הוא חלק מקבוצה קטנה של מושגים קנוניים
מוגדר על ידי Google. מושגים קנוניים מספקים הגדרות בסיסיות של זמן,
גיאוגרפיה, כמויות מספריות, יחידות וכו'.
למעשה, מושג המדינה שהוגדר למעלה קיים
מושג קנוני. יצרנו אותו כאן למטרות המחשה בלבד.
כשאפשר, כדאי להשתמש במושגים קנוניים במערכי הנתונים:
באופן ישיר או על ידי הרחבתם (בהמשך מפורט מידע נוסף בנושא). מושגים קנוניים
לבצע השוואה של הנתונים למערכי נתונים אחרים, ולהפעיל תכונות
מערכי נתונים ב-Public Data Explorer. לדוגמה, הוספת אנימציה של נתונים לאורך זמן
או הצגת נתונים גיאוגרפיים במפה על סמך השימוש בtime וגם
geo מושגים קנוניים, בהתאמה.
פרוסה ראשונה
עכשיו, אחרי שיש לנו מושגים לגבי אוכלוסייה, מדינה ושנה, הגיע הזמן להרכיב אותם!
לשם כך, עלינו ליצור פלח שמשלב ביניהם. ב-DSPL, פרוסה (slice) היא שילוב של מושגים שעבורם קיימים נתונים.
למה לא פשוט ליצור טבלה עם העמודות הנכונות? כי פרוסות מתעדות את הנתונים של מערך הנתונים במונחים של המושגים שלו. השינוי הזה יהפוך ככל שאנחנו יוצרים יותר חלקים ממערך הנתונים שלנו.
פרוסות מופיעות בקובץ ה-DSPL עם <slices>
שחייב להופיע מיד אחרי הקטע concepts.
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices>בדיוק כמו במושגים, לכל פרוסה יש id
(countries_slice) שמזהה באופן ייחודי את הפלח בתוך
של הכיתובים.
פלח מכיל שני סוגים של הפניות למושגים: מאפיינים ו
מדדים. ערכי המדדים משתנים עם הערכים של
מאפיינים. כאן, הערך של population (המדד) משתנה בהתאם
המאפיינים country ו-year.
בדיוק כמו במושגים, פרוסות כוללות הפניה לטבלה מכיל את נתוני הפלח. הטבלה שאליה מתבצעת ההפניה חייבת לכלול עמודה אחת עבור כל מאפיין וערך של הפלח. בדיוק כמו במושגים, מאפיינים ומדדים ממופים לעמודות בטבלה עם אותם מזהים.
טבלת פרוסות
הטבלה של פילוח האוכלוסייה שלנו מופיעה בקטע tables
בקטע של קובץ ה-DSPL:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
חשוב לשים לב שהעמודה year כוללת format.
שמציין את הפורמט של השנים. הפורמטים הנתמכים של תאריכים הם
שהוגדרו באמצעות פורמט DateTime של Joda.
הטבלה countries_slice מציינת את עמודות הטבלה
הסוגים שלהם, ומפנה לקובץ CSV שמכיל את הנתונים. קובץ ה-CSV
נראה כך:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
כל שורה בטבלת הנתונים מכילה שילוב ייחודי של המאפיינים
country ו-year, יחד עם הערך המתאים
של המדד population (לדוגמה, האוכלוסייה -
metric – של אפגניסטן בשנת 1960 – מאפיינים).
חשוב לשים לב שהערכים בעמודה country תואמים
ערך/מזהה של הקונספט country, שהוא ISO 3166
קוד בן 2 אותיות של המדינה.
נתוני ה-CSV של פרוסה חייבים לעמוד במגבלות הבאות:
- כל ערך בשדה מאפיין (כגון
countryו-year) לא יכול להיות ריק. ערכים עבור שדות מדדים (כמוpopulation) יכול להיות ריק. ערך ריק מיוצג באמצעות לא תווים. - כל ערך בשדה מאפיין שמפנה למושג חייב להיות
קיימים בנתונים של הקונספט הזה. לדוגמה, הערך
AF. חייב להיכלל בטבלת נתוני הקונספטcountry. - כל שילוב ייחודי של ערכי מאפיינים, למשל
AF, 2000, יכולה להתרחש פעם אחת בלבד. - יש למיין את הנתונים לפי עמודות המאפיינים שאינן זמן (בכל סדר שהוא),
ולאחר מכן, באופן אופציונלי, באמצעות כל אחת מהעמודות האחרות. כך, למשל,
בטבלה עם העמודות
[date, dimension1, dimension2, metric1, metric2], אפשר למיין לפיdimension1, ואזdimension2, ואזdate, אבל לא לפיdateולאחר מכן המאפיינים.
סיכום
בשלב הזה, יש לנו מספיק מידע ב-DSPL כדי לתאר את המדינה של נתוני האוכלוסייה. לסיכום, מה שהצלחנו לעשות היה:
- יוצרים את הכותרת והתיאור של ה-DSPL של מערך הנתונים ספק
- יוצרים קונספט אחד לאוכלוסייה וקונספט אחר למדינה, באמצעות קובץ CSV שבו מפורטים כל המדינות והשמות שלהן.
- ליצור פילוח עם מספרי האוכלוסייה שלנו עבור מדינות לאורך זמן, התייחסות למושג השנה המוגדר כבר במערך נתוני הזמן המיובא מ-Google.
בהמשך המדריך הזה נשנה את מערך הנתונים באמצעות הוספת עוד מאפיינים בפרוסות, וגם מדדים נוספים המקובצים לפי נושא.
הוספת מאפיין: מדינות בארה"ב
עכשיו נעשיר את מערך הנתונים באמצעות הוספת נתוני אוכלוסייה של מדינות ארה"ב. קודם צריך להגדיר קונספט של מדינות. זה נראה מאוד כמו מושג המדינה שהגדרנו קודם.
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>תוספי קונספט ונכס הפניות
תפיסת המדינה כוללת כמה תכונות חדשות של DSPL.
ראשית, מצב מרחיב קונספט אחר,
geo:location (מוגדר במערך הנתונים הגיאוגרפי החיצוני,
שיובא בתחילת מערך הנתונים שלנו). מבחינה סמנטית,
state הוא סוג של geo:location. התוצאה היא
שהיא יורשת את כל המאפיינים והתכונות
geo:location באופן ספציפי, המיקום מגדיר נכסים עבור
latitude וגם longitude. באמצעות הרחבה של
כללי, המאפיינים האלה מוחלים גם על מצב. יתרה מכך, מאז
ירושה של מיקום מ-entity:entity, גם המדינה מקבלת
כל המאפיינים של השניים, כולל name,
description ו-info_url.
הערה: הקונספט של המדינה שהוגדר קודם לכן
מבחינה טכנית, הוא היה צריך להרחיב גם מ-geo:location.
הנקודה הזו הושמטה קודם לצורך פשטות; כללנו את
מיקום לירושה של מדינה,
קובץ ה-XML הסופי.
הערה: אפשר להשתמש בextends
ליצור במערכי נתונים משלכם לעשות שימוש חוזר במידע שהוגדר על ידי מערכי נתונים אחרים.
כדי להשתמש ב-extends צריך שכל המופעים של הקונספט יהיו
מופעים תקפים של הקונספט שמתרחב. תוספים מאפשרים לך להוסיף
מאפיינים ומאפיינים נוספים, ומגבילים את קבוצת המכונות
תת-קבוצה של המופעים של המושג המורחב.
בנוסף לירושה, נכס המדינה כולל גם את
של קונספטים של הפניות.
באופן ספציפי, למושג 'מדינה' יש נכס בשם country,
שמתייחס לרעיון של המדינה שיצרנו למעלה. הפעולה מתבצעת על ידי
באמצעות מאפיין concept. שימו לב שהנכס הזה לא
לספק מזהה, רק הפניה לקונספט. הדבר מקביל ליצירת מזהה
עם ערך זהה לזה של המזהה של הקונספט שאליו מפנה (כלומר,
country בדוגמה הזו). הקשר ההיררכי בין
את המדינה והמחוז מתעדים באמצעות מאפיין
isParent="true" בהפניה. באופן כללי,
מאפיינים עם קשרים היררכיים, כמו אזורים גיאוגרפיים, צריכים להיות
שמיוצגת בצורה הזאת, ולמושג הצאצא יש נכס
מפנה למושג ההורה באמצעות המאפיין isParent.
הגדרת הטבלה של מצבים נראית כך:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
בעמודה 'מדינה' יש ערך קבוע לכל המדינות. לציין זאת ב:
ה-DSPL נמנע מחזרה על הערך הזה בכל מדינה בנתונים. יש לשים לב גם
שכללנו עמודות עבור name, latitude ו-
longitude מאחר שהמדינה קיבלה בירושה את הנכסים האלה מ-
geo:location לעומת זאת, חלק מהנכסים שעברו בירושה
(למשל description) לא כוללות עמודות; זה בסדר-
אם מאפיין יושמט מטבלת הגדרת קונספט, הערך שלו הוא
מניחים שהם לא מוגדרים לכל מופע של המושג.
קובץ ה-CSV נראה כך:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
מכיוון שכבר יש לנו מושגים שקשורים לאוכלוסייה ולשנה, אנחנו יכולים להשתמש בהם שוב כדי להגדיר פלח חדש לאוכלוסיית המדינות.
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>ההגדרה של טבלת הנתונים נראית כך:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
וקובץ ה-CSV נראה כך:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
רגע. למה יצרנו פרוסה חדשה, במקום להוסיף עוד פרוסה? במאפיין הקודם?
פלח עם מימדים גם למדינה וגם למדינה יהיה שגוי. כי חלק מהשורות ייצגו נתוני מדינה וחלק מהשורות יכילו נתוני מדינה . בטבלה יש 'חורים' למאפיינים מסוימים, אסור (חשוב לזכור שערכים חסרים מותרים רק עבור מדדים ו ולא מאפיינים).
המאפיינים משמשים כ'מפתח ראשי' לפלח. המשמעות היא כל שורת נתונים חייבת לכלול ערכים לכל המאפיינים, ולא שתי שורות נתונים. יכולים להיות להם ערכים זהים בכל המאפיינים.
הוספת מדד: אבטלה המרה
עכשיו נוסיף עוד מדד למערך הנתונים:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
הקטע info במדד הזה כולל שם, תיאור ו
כתובת URL (קישור ללשכת העבודה, לסטטיסטיקה של ארה"ב).
הקונספט הזה גם מרחיב את הקונספט הקנוני quantity:rate.
הכמות
מערך הנתונים מגדיר מושגי ליבה לייצוג כמויות מספריות. לחשבון
של מערך הנתונים, צריך ליצור את המושגים המספריים על ידי הרחבת
קונספט של כמות מתאימה. לכן, הקונספט population
כפי שהוגדר למעלה, מבחינה טכנית, צריך להרחיב
quantity:amount.
מאפייני הקונספט
הרעיון הזה מציג גם את המבנה של מאפיין. לחשבון
בדוגמה הזו, מאפיין משמש לציון unemployment_rate
הוא אחוז. המאפיין is_percentage עובר בירושה מ
הקונספט quantity:rate שהמושג הזה כולל הזה
משמש את Public Data Explorer להצגת סימני אחוזים כאשר
להמחשה חזותית של הנתונים.
מאפיינים מספקים מנגנון כללי לצירוף צמדי מפתח/ערך
(בניגוד לנכסים, שמשייכים ערכים נוספים עם
מכונות של קונספט כלשהו). בדיוק כמו מושגים ונכסים,
יש להם id, info ו-
type. בדומה לנכסים, הם יכולים להפנות למושגים אחרים.
מאפיינים לא מיועדים רק לדברים כלליים שהוגדרו מראש, כמו נכסים. אתם יכולים להגדיר מאפיינים משלכם לקונספטים שלכם.
הוספת נתונים של שיעור אבטלה בארה"ב מצבים
אנחנו מוכנים עכשיו להוסיף נתונים של שיעור האבטלה במדינות בארה"ב. כי שיעור אבטלה הוא מדד וכבר יש לנו נתוני אוכלוסייה עבור מדינות, אפשר פשוט להוסיף אותו לפלח שכבר יצרנו עבור המדינה והשנה מימדים:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... ומוסיפים עוד עמודה להגדרת הטבלה:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... ולקובץ ה-CSV:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
בעבר אמרנו שלכל פרוסה, המאפיינים יוצרים מפתח ראשי לפלח. בנוסף, כל מערך נתונים יכול להכיל רק פרוסה אחת בשילוב של מאפיינים מסוימים. כל המדדים שזמינים המאפיינים חייבים להשתייך לאותו פלח.
מאפיינים נוספים: פירוט של אוכלוסייה לפי מגדר
נעשיר את מערך הנתונים עם פירוט של האוכלוסייה לפי מגדר, מדינות. עכשיו אתם מתחילים להכיר את התרגיל... קודם אנחנו צריכים הוספת קונספט של מגדר:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
הקטע של מושג המגדר info כולל
pluralName, שמספק את הטקסט שצריך להתייחס אליו
של קונספט המגדרים, גם הקטע info
כולל totalName, שמספק את הטקסט
להתייחס לכל המופעים של קונספט המגדר כמכלול. שתי האפשרויות האלה
משמש את Public Data Explorer להצגת מידע הקשור למגדר
בטרנספורמר. באופן כללי, עליך לספק אותם למושגים שניתן להשתמש בהם
מאפיינים.
שימו לב שהמושג מגדר חל גם
entity:entity זו שיטה טובה לפיתוח קונספטים
שמשמשות כמאפיינים, כי הן מאפשרות להוסיף שמות מותאמים אישית
כתובות URL וצבעים של מופעי הקונספט השונים.
המושג מגדר מתייחס לטבלה genders_table,
מכיל את הערכים האפשריים של מגדר והשמות המוצגים שלהם
(הושמט כאן).
כדי להוסיף אוכלוסייה לפי מגדר למערך הנתונים, צריך ליצור פלח חדש (חשוב לזכור: כל שילוב זמין של מאפיינים תואם לפלח מערך הנתונים).
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
הגדרת הטבלה של הפרוסה נראית כך:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
קובץ ה-CSV של הטבלה נראה כך:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
בהשוואה למדינות, לאוכלוסייה ולפלח האבטלה הקודם, יש מאפיין נוסף: כל ערך של מדד האוכלוסייה מתייחס לא רק למדינה מסוימת ולשנה מסוימת, אלא גם מגדר מסוים.
שימו לב שיצרנו את הערך 'sparse' של הכיתובים. לא הכול המדדים זמינים לכל המאפיינים: האוכלוסייה היא זמין עבור מדינות ומדינות בארה"ב, על בסיס שנתי, בזמן האבטלה התעריף זמין רק למדינות. הפירוט לפי מגדר זמין לאוכלוסייה לפי מדינות בלבד; הוא לא זמין לשיעור אבטלה ולא למאפיין המצב. יכול להיות שיש הפרדה גם בנתונים ברמה מסוימת, כאשר למדדים מסוימים אין ערכים עבור ערכי מאפיינים מסוימים, אבל הוא לא מיוצג ב-DSPL.
נושאים
התכונה האחרונה של DSPL שבה נשתמש במערך הנתונים שלנו היא topics (נושאים). הנושאים משמשים לסיווג היררכי של מושגים, והם משמשים כדי לעזור למשתמשים לנווט לנתונים.
בקובץ ה-DSPL, הנושאים מופיעים ממש לפני המושגים. הנה דוגמה היררכיית נושאים:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>אפשר למקם נושאים בעומק גדול ככל הצורך.
כדי להשתמש בנושאים, צריך פשוט להפנות אותם מהרעיון היא:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
קונספט כלשהו יכול להתייחס ליותר מנושא אחד.
שליחת מערך הנתונים
אחרי שיוצרים את מערך הנתונים, השלב הבא הוא לדחוס את הנתונים להעלות את קובץ ה-ZIP אל הכלי Google Public Data Explorer. אם נתקלת בבעיות, אפשר לבדוק בשאלות הנפוצות, שכולל דיון של הבעיות הנפוצות ביותר בהעלאה.
לידיעתך, אפשר גם להוריד את קובץ ה-XML המלא ואת חבילת מערכי הנתונים המלאה. שמשויכים למדריך הזה.
לאן ממשיכים מכאן
מעולה! יצרת את מערך הנתונים הראשון של DSPL. עכשיו, אחרי להבין את היסודות. מומלץ לקרוא את המדריך למפתחים, בין היתר, מסמכים "מתקדם", תכונות DSPL כמו תמיכה במגוון שפות ומושגים שניתנים למיפוי.
אפשר גם לעיין בעוד מערכי נתונים לדוגמה.