DSPL è l'acronimo di Dataset Publishing Language. Set di dati descritti in DSPL possono essere importati in Google Public Data Spazio di esplorazione, uno strumento che permette di esplorare visivamente e in modo approfondito e i dati di Google Cloud.
Nota: per caricare i dati su Google Public Data. usando lo strumento di caricamento dei dati pubblici, devi avere un Account Google.
Questo tutorial fornisce un esempio dettagliato di come preparare un set di dati DSPL.
Un set di dati DSPL è un set contenente un file XML e un set di file CSV. I file CSV sono semplici tabelle contenenti i dati di del set di dati. Il file XML descrive i metadati del set di dati, inclusi metadati informativi come le descrizioni delle misure, nonché metadati strutturali come riferimenti tra tabelle. I metadati consentono di utenti non esperti esplorano e visualizzano i dati.
L'unico prerequisito per comprendere questo tutorial è un buon livello di nel linguaggio XML. Una certa comprensione di concetti semplici dei database (ad es. tabelle, chiavi primarie) può essere utile, ma non è obbligatorio. Come riferimento, file XML completo e set di dati completo bundle associato a questo tutorial sono disponibili per la revisione.
Panoramica
Prima di iniziare a creare il nostro set di dati, ecco una panoramica generale Contenuto di un set di dati DSPL:
- Informazioni generali: informazioni sul set di dati
- Concetti:definizioni di "cose" che Compaiono nel set di dati (ad es. paesi, tasso di disoccupazione, genere, etc.)
- Sezioni: combinazioni di concetti per cui esistono dati
- Tabelle: dati per concetti e sezioni. Tabelle concettuali contengono enumerazioni, mentre le tabelle delle sezioni contengono dati statistici
- Argomenti:per organizzare i concetti del set di dati in una gerarchia significativa attraverso l'etichettatura
Per illustrare queste nozioni alquanto astratte, consideriamo il set di dati (con dati fittizi) utilizzati in questo tutorial: serie temporali statistiche per popolazione e disoccupazione, aggregati per varie combinazioni di paese, stato USA e genere.
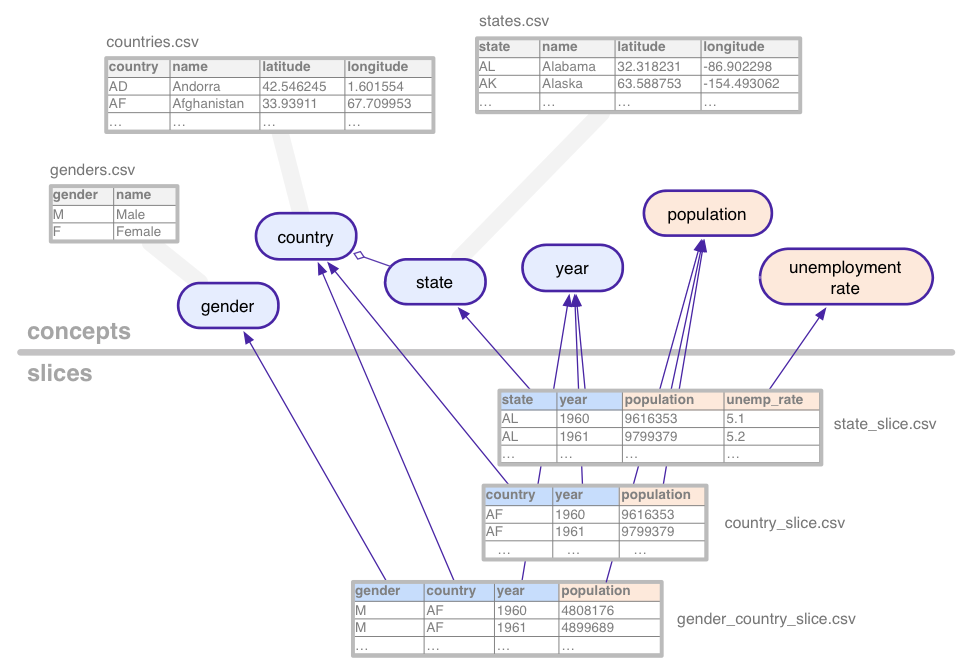
Questo set di dati di esempio definisce i seguenti concetti:
- country
- genere
- population
- stato
- tasso di disoccupazione
- anno
I concetti categorici, come lo stato, sono associati ai concetti tables, che enumerano tutti i loro valori possibili (California, Arizona e così via). I concetti possono avere colonne aggiuntive per proprietà quali il nome o il paese di uno stato.
Le sezioni definiscono ogni combinazione di concetti per cui esistono
statistici nel set di dati. Una sezione contiene dimensioni e
metriche. Nell'immagine qui sopra, le dimensioni sono blu e
sono in arancione. In questo esempio, la sezione
gender_country_slice contiene dati per la metrica
population e le dimensioni country,
year e gender. Un'altra sezione, chiamata
country_slice, restituisce i numeri totali annuali della popolazione (metrica) per
paesi.
Oltre a dimensioni e metriche, le sezioni fanno riferimento anche tabelle, che contengono i dati effettivi.
Vediamo ora passo passo la creazione di un set di dati di questo tipo DSPL
Informazioni sul set di dati
Per iniziare, dobbiamo creare un file XML per il nostro set di dati. Ecco il l'inizio di una descrizione DSPL per il nostro set di dati di esempio:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
La descrizione del set di dati inizia con un <dspl> di primo livello
. L'attributo targetNamespace contiene un URI che
identifica in modo univoco questo set di dati. Lo spazio dei nomi del set di dati è specifico
è importante durante la pubblicazione del set di dati, in quanto sarà l'identificatore globale
il tuo set di dati e il mezzo che gli altri possono farvi riferimento.
Tieni presente che l'attributo targetNamespace potrebbe essere omesso. Nella
In questo caso viene generato automaticamente uno spazio dei nomi univoco quando il set di dati
importati.
Utilizzo di informazioni di altri set di dati
I set di dati possono riutilizzare le definizioni e i dati di altri set di dati importando
per i set di dati. Ogni elemento <import> specifica
di un altro set di dati a cui farà riferimento questo set di dati.
Nel set di dati di esempio, avremo bisogno di alcune definizioni da http://www.google.com/publicdata/dataset/google/quantity (un set di dati creato da Google che contiene concetti utili per definire quantità numeriche) e dai set di dati time, entity e geo, che forniscono definizioni correlate rispettivamente a tempo, entità e area geografica.
L'elemento <dspl> superiore fornisce un prefisso dello spazio dei nomi
dichiarazione (ad es. xmlns:time="http://...") per ciascuno
dei set di dati importati. Le dichiarazioni dei prefissi sono necessarie per fare riferimento
gli elementi da altri set di dati in modo conciso. Ad esempio,
time:year fa riferimento alla definizione di year nel
set di dati importato il cui spazio dei nomi è associato al prefisso
time.
Informazioni su set di dati e provider
L'elemento <info> contiene informazioni generali su
set di dati: nome, descrizione e URL in cui è possibile ottenere
trovato.
L'elemento <provider> contiene informazioni sull'elemento
del set di dati: il nome e l'URL in cui è possibile trovare ulteriori informazioni
(di solito, la home page del fornitore di dati).
Definizione dei concetti
Ora che abbiamo fornito alcune informazioni generali sul set di dati, possiamo iniziare a definirne i contenuti. Il nostro prossimo obiettivo è aggiungere statistiche sulla popolazione per i paesi negli ultimi 50 anni.
La prima cosa da fare è fornire alcune definizioni delle nozioni della popolazione, del paese e dell'anno. In DSPL, queste definizioni sono chiamate concetti.
Un concetto è la definizione di un tipo di dati che compaiono in un del set di dati. I valori dei dati che corrispondono a un dato concetto vengono chiamati istanze di quel concetto.
Popolazione
Iniziamo definendo il concetto di popolazione. In un
documento DSPL, i concetti sono definiti in un <concepts>
immediatamente dopo le informazioni del set di dati e del provider.
Ecco un concetto di popolazione con le informazioni minime richieste
per qualsiasi concetto: id (un identificatore univoco), name e
type.
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
Ecco come funziona questo codice di esempio:
- Ogni concetto deve fornire un
idche identifichi in modo univoco il concetto all'interno del set di dati. Ciò significa che non esistono due concetti definiti lo stesso set di dati può avere lo stesso ID. - Proprio come per il set di dati e il suo provider,
Gli elementi
<info>forniscono informazioni testuali sull'elemento concetto, come il nome e la descrizione. - L'elemento
<type>specifica il tipo di dati per istanze del concetto (in altre parole, i suoi "valori"). In questo esempio, il tipo dipopulationèinteger. DSPL supporta i seguenti tipi di dati:stringintegerfloatbooleandate
Paese
Ora scriviamo la definizione del concetto di paese:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
La definizione del concetto di paese inizia come la precedente,
con id, info e type.
Valori del concetto
Per concetti categorici come le nazioni, viene enumerato tutto il possibile
di Compute Engine. In altre parole, è possibile elencare tutti i paesi possibili
a cui viene fatto riferimento. Tuttavia, per farlo, ogni paese ha bisogno di un identificatore univoco.
Questo esempio utilizza
i codici paese ISO per identificare i paesi. questi codici sono
di tipo string.
In questo esempio, non è necessario utilizzare il codice ISO; tu potresti anche usare il nome del paese. I nomi, tuttavia, variano a seconda della lingua possono cambiare nel tempo e non sono sempre utilizzati in modo coerente nei set di dati. Per i paesi e per i concetti categorici in generale, è consigliabile pratica per scegliere, brevi, stabili, comunemente usati e indipendenti dal linguaggio identificatori (se presenti).
Proprietà del concetto
Oltre al valore id, il concetto di paese ha un
Elemento <property> che specifica il nome del paese.
In altre parole, il nome del paese ("Irlanda") è una proprietà.
del paese con id IE. Le proprietà sono il modo in cui DSPL fornisce
informazioni strutturate aggiuntive sulle istanze di un concetto.
Proprio come il concetto stesso, le proprietà hanno un id,
info e type.
Dati concettuale
Infine, il concetto di paese ha un elemento <table>.
Questo elemento fa riferimento a una tabella che enumera l'elenco di tutti
paesi.
L'utilizzo delle tabelle ha senso per alcuni concetti, ma non per altri. Per Ad esempio, non ha senso enumerare tutti i valori possibili per la popolazione dei concetti. Tuttavia, se fai riferimento a una tabella un concetto, la tabella deve contenere tutte le istanze del concetto, ad esempio è necessario elencare tutti i paesi, non soltanto alcuni esempi.
Il set di dati definisce la tabella countries_table in questo modo:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
La tabella countries specifica le colonne della tabella e i relativi tipi,
e fa riferimento a un file CSV contenente i dati. Questo CSV può essere
in bundle e caricati con il set di dati XML o accesso remoto tramite HTTP, HTTPS
o FTP. Negli ultimi casi, dovrai sostituire countries.csv con
un URL, ad esempio http://www.myserver.com/mydata/countries.csv.
Dove è archiviato, il file CSV ha il seguente aspetto:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
Nella prima riga della tabella sono elencati gli ID delle colonne, come specificato nella
Definizione di table. Ognuna delle righe seguenti corrisponde a una
esempio del concetto di paese. Se il concetto ha una tabella,
la tabella deve contenere tutte le istanze del concetto, in questo
deve elencare tutti i paesi.
Le colonne vengono mappate al concetto di paese e alle sue proprietà in base a
il relativo ID. L'ID della prima colonna, country, corrisponde al concetto
ID. Ciò significa che questa colonna contiene l'identificatore univoco del paese
definita dal concetto di paese. La colonna successiva corrisponde a
la proprietà name del concetto di paese. I valori
in questa colonna corrispondono ai valori della proprietà name.
Esistono alcuni requisiti per i dati CSV relativi alla tabella concettuale:
- Le intestazioni di colonna nella prima riga del file di dati devono
Corrispondere esattamente al concetto
ide alla proprietàiddel concetto a cui sono associati i dati (sebbene l'ordine può variare). - Ogni riga deve contenere esattamente lo stesso numero di elementi del numero di proprietà sul concetto (anche se il valore è vuoto).
- Ogni valore per il campo
iddel concetto (qui, il codice paese) deve essere univoco e non vuoto (un campo vuoto corrisponde a uno con zero o solo spazi vuoti). - I valori delle proprietà che fanno riferimento ad altri concetti devono essere vuoto o essere un valore valido del concetto a cui viene fatto riferimento.
- I valori che contengono virgole, virgolette doppie o caratteri di nuova riga devono essere è completamente racchiuso tra virgolette doppie.
- Le virgolette letterali doppie all'interno di un valore devono essere immediatamente preceduta da un'altra virgoletta doppia.
Anno
L'ultimo concetto di cui abbiamo bisogno per i dati sulla popolazione di un paese
rappresentano gli anni. Anziché definire un nuovo concetto, utilizzeremo
di anno in anno derivato da uno dei set di dati che abbiamo importato:
"http://www.google.com/publicdata/dataset/google/time". Per farlo,
dobbiamo farvi riferimento come time:year, dove time
rappresenta il set di dati a cui viene fatto riferimento e year identifica
il concetto.
Concetti canonici
time:year fa parte di un piccolo insieme di concetti canonici
definiti da Google. I concetti canonici forniscono definizioni di base di tempo,
area geografica, quantità numeriche, unità ecc.
Infatti, il concetto di paese sopra definito esiste come un
concetto canonico. L'abbiamo creato qui solo a scopo illustrativo.
Quando possibile, è consigliabile utilizzare concetti canonici nei set di dati,
direttamente o estendendole (ulteriori informazioni nell'estensione di seguito). Concetti canonici
rendere i dati paragonabili ad altri set di dati e abilitare le funzionalità
in Public Data Explorer. Ad esempio, l'animazione dei dati nel tempo
o mostrare i dati geografici su una mappa, affidati all'uso dei time e
geo concetti canonici.
Prima sezione
Ora che abbiamo i concetti di popolazione, paese e anno, è il momento per metterli insieme!
Per farlo, dobbiamo creare una sezione che li combini. In DSPL, Una sezione è una combinazione di concetti per cui esistono dati.
Perché non creare semplicemente una tabella con le colonne giuste? Poiché l'acquisizione delle sezioni le informazioni del set di dati in termini di concetti. Questo diventerà più chiaro man mano che creiamo più porzioni del nostro set di dati.
Le sezioni vengono visualizzate nel file DSPL sotto un <slices>
, che deve apparire subito dopo la sezione concepts.
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices>Proprio come i concetti, ogni sezione ha un id
(countries_slice) che identifica in modo univoco la sezione all'interno di
del set di dati.
Una sezione contiene due tipi di riferimenti concettuali: Dimensioni e
metriche. I valori delle metriche variano con i valori di
dimensioni. In questo caso, il valore di population (la metrica) varia in base a
le dimensioni country e year.
Come i concetti, le sezioni includono un riferimento a una tabella contiene i dati della sezione. La tabella a cui viene fatto riferimento deve avere una colonna per ogni dimensione e metrica della sezione. Come per i concetti, il valore dimensioni e metriche vengono mappate alle colonne della tabella con gli stessi ID.
Tabella delle sezioni
La tabella per la nostra sezione di popolazione viene visualizzata in tables
del file DSPL:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
Tieni presente che la colonna year include un valore format
che specifica come sono formattati gli anni. I formati di data supportati sono
quelle definite dal formato Joda DateTime.
La tabella countries_slice specifica le colonne della tabella e
i rispettivi tipi e punta a un file CSV che contiene i dati. Il file CSV
ha il seguente aspetto:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
Ogni riga della tabella di dati contiene una combinazione unica delle dimensioni
country e year, insieme al valore corrispondente
della metrica population (ad es. popolazione -
metric - dell'Afghanistan nel 1960 - dimensioni).
Tieni presente che i valori nella colonna country corrispondono ai
valore/identificatore del concetto country, ovvero ISO 3166
Il codice a 2 lettere del paese.
I dati CSV di una sezione devono soddisfare i seguenti vincoli:
- Ogni valore di un campo dimensione (ad esempio
countryeyear) non può essere vuoto. I valori per i campi delle metriche (ad esempiopopulation) può essere vuoto. Un valore vuoto è rappresentato da un caratteri. - Ogni valore di un campo dimensione che fa riferimento a un concetto deve essere
presenti nei dati di quel concetto. Ad esempio, il valore
AFdevono essere presenti nella tabella di dati concettualicountry. - Ogni combinazione unica di valori delle dimensioni, ad es.
AF, 2000, possono verificarsi una sola volta. - I dati devono essere ordinati in base alle colonne di dimensioni non temporali (in qualsiasi ordine),
e poi, facoltativamente, da una qualsiasi delle altre colonne. Quindi, ad esempio,
in una tabella con le colonne
[date, dimension1, dimension2, metric1, metric2], puoi ordinarla in base adimension1, poidimension2, quindidate, ma non perdateseguito dalle dimensioni.
Riepilogo
A questo punto, il nostro DSPL è sufficiente per descrivere il paese dati sulla popolazione. Ricapitolando, abbiamo dovuto:
- Creare l'intestazione e la descrizione DSPL del set di dati e delle relative fornitore
- Crea un concetto per la popolazione e un altro per il paese, con un CSV con l'elenco di tutti i paesi e i relativi nomi.
- Crea una sezione con i dati sulla popolazione per i paesi nel tempo, riferimento al concetto di anno già definito nel set di dati temporali importato di Google.
Nel resto di questo tutorial, renderemo il nostro set di dati più completo aggiungendo più dimensioni in più sezioni, nonché più metriche raggruppate per per ogni argomento.
Aggiunta di una dimensione: stati USA
Arricchiamo ora il nostro set di dati aggiungendo dati sulla popolazione per gli stati negli Stati Uniti. Dobbiamo prima definire un concetto per gli stati. Sembra molto probabile come il concetto di paese che abbiamo definito prima.
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>Estensioni dei concetti e proprietà riferimenti
Il concetto di stato introduce diverse nuove funzionalità di DSPL.
In primo luogo, lo stato estende un altro concetto,
geo:location (definito nel set di dati geografici esterno che
importati all'inizio del nostro set di dati). Dal punto di vista semantico, significa che
state è un tipo di geo:location. Una conseguenza è
eredita tutti gli attributi e le proprietà
geo:location. In particolare, la località definisce le proprietà
latitude e longitude; estendendo il primo modello
queste proprietà vengono applicate anche allo stato. Inoltre, poiché
la località eredita da entity:entity, lo stato riceve anche
tutte le proprietà di quest'ultimo, tra cui name,
description e info_url.
Nota: il concetto di paese definito in precedenza.
tecnicamente dovrebbe essere stato esteso anch'esso dal giorno geo:location.
Questo punto è stato omesso in precedenza per semplicità; abbiamo incluso
dall'ereditarietà al paese, tuttavia,
file XML finale.
Nota: puoi utilizzare extends
nei tuoi set di dati per riutilizzare le informazioni definite da altri set di dati.
L'utilizzo di extends richiede che tutte le istanze del concetto siano
istanze valide del concetto che stai estendendo. Con le estensioni puoi aggiungere
ulteriori proprietà e attributi e limita l'insieme di istanze a un
un sottoinsieme di istanze del concetto esteso.
Oltre all'ereditarietà, la proprietà state introduce anche la
l'idea dei riferimenti concettuali.
In particolare, il concetto di stato ha una proprietà chiamata country,
che fa riferimento al concetto di paese che abbiamo creato sopra. Ciò viene fatto
utilizzando un attributo concept. Tieni presente che questa proprietà non
fornire un ID, ma solo un riferimento concettuale. Equivale a creare un ID
con lo stesso valore dell'ID del concetto a cui viene fatto riferimento (ad es.
country in questo esempio). Il rapporto gerarchico tra
lo stato e la contea vengono acquisiti tramite un attributo
isParent="true" sul riferimento. In generale,
dimensioni con relazioni gerarchiche, come le aree geografiche,
rappresentato in questo modo, con il concetto figlio che ha una proprietà
fa riferimento al concetto principale utilizzando l'attributo isParent.
La definizione della tabella degli stati ha il seguente aspetto:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
La colonna del paese ha un valore costante per tutti gli stati. Specificarlo in
il DSPL evita di ripetere quel valore per ogni stato nei dati. Nota anche
che abbiamo incluso le colonne per name, latitude e
longitude poiché lo stato ha ereditato queste proprietà da
geo:location. Al contrario, alcune proprietà ereditate
(ad es. description) non hanno colonne; va bene-
Se una proprietà viene omessa da una tabella di definizione dei concetti, il suo valore è
che si presume non sia definita per ogni istanza del concetto.
Il file CSV ha il seguente aspetto:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
Poiché abbiamo già dei concetti di popolazione e anno, possiamo riutilizzarli per definire una nuova sezione per la popolazione degli stati.
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>La definizione della tabella dati ha il seguente aspetto:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
Il file CSV sarà simile al seguente:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
Perché abbiamo creato una nuova sezione invece di aggiungerne un'altra? dimensione a quella precedente?
Una sezione con le dimensioni sia per lo stato sia per il paese non sarebbe corretta, perché alcune righe servono per i dati del paese e altre per lo stato e i dati di Google Cloud. La tabella avrebbe dei "buchi" per alcune dimensioni, ovvero non consentito (ricorda che i valori mancanti sono consentiti solo per le metriche e non le dimensioni).
Le dimensioni fungono da "chiave principale" per la sezione. Ciò significa che ogni riga di dati deve contenere valori per tutte le dimensioni e non due righe di dati possono avere esattamente gli stessi valori per tutte le dimensioni.
Aggiunta di una metrica: Disoccupazione Frequenza
Ora aggiungiamo un'altra metrica al nostro set di dati:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
La sezione info di questa metrica contiene un nome, una descrizione e un
URL (collegamento allo US Bureau of Labor Statistics).
Questo concetto estende anche il concetto canonico di quantity:rate.
La quantità
set di dati definisce i concetti fondamentali per la rappresentazione di quantità numeriche. Nella
del set di dati, dovresti creare i concetti numerici estendendo
concetto di quantità più appropriato. Di conseguenza, il concetto population
precedentemente definiti devono essere tecnicamente estesi
quantity:amount.
Attributi dei concetti
Questo concetto introduce anche il costrutto di un attributo. Nella
In questo esempio, un attributo viene utilizzato per indicare che unemployment_rate
è una percentuale. L'attributo is_percentage viene ereditato da
il concetto di quantity:rate esteso. Questo
informazioni vengono utilizzate da Public Data Explorer per mostrare i segni di percentuale quando
per visualizzare i dati.
Gli attributi costituiscono un meccanismo generale per associare coppie chiave/valore a un
concetto (al contrario delle proprietà, che associano valori aggiuntivi a
istanze di un concetto). Esattamente come i concetti e le proprietà,
hanno id, info e un
type. Come per le proprietà, possono fare riferimento ad altri concetti.
Gli attributi non sono indicati solo per elementi generici predefiniti, ad esempio proprietà. Puoi definire i tuoi attributi personali per i concetti.
Aggiunta di dati sul tasso di disoccupazione per gli Stati Uniti Stati
Ora siamo pronti ad aggiungere i dati sul tasso di disoccupazione per gli stati USA. Poiché il tasso di disoccupazione è una metrica e già disponiamo di dati sulla popolazione per stati, possiamo semplicemente aggiungerlo alla sezione che abbiamo già creato per lo stato e l'anno, dimensioni:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... e aggiungi un'altra colonna alla definizione della tabella:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... e al file CSV:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
In precedenza abbiamo detto che per ogni sezione le dimensioni formano una chiave primaria per la sezione. Inoltre, ogni set di dati può contenere solo una sezione per una determinata combinazione di dimensioni. Tutte le metriche disponibili devono appartenere alla stessa sezione.
Altre dimensioni: suddivisione della popolazione per genere
Arricchiamo il nostro set di dati con una suddivisione della popolazione in base al genere per paesi. A questo punto, stai iniziando a conoscere la procedura... Dobbiamo prima aggiungi un concetto di genere:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
La sezione del concetto di genere info ha un
pluralName, che fornisce il testo da utilizzare per fare riferimento a
più occorrenze del concetto di genere. Anche la sezione info
include un totalName, che fornisce il testo da utilizzare per
si riferisce a tutte le occorrenze del concetto di genere nel suo complesso. Entrambe le opzioni sono
utilizzato da Public Data Explorer per visualizzare informazioni relative al genere
concetto. In generale, dovresti fornirli per concetti che possono essere usati come
dimensioni.
Il concetto di genere si sta estendendo anche
entity:entity. È una buona pratica per i concetti
usate come dimensioni, in quanto consente
di aggiungere nomi personalizzati,
gli URL e i colori delle varie istanze dei concetti.
Il concetto di genere fa riferimento alla tabella genders_table, che
contiene i possibili valori per il genere e i relativi nomi visualizzati
(omesso qui).
Per aggiungere la popolazione per genere al nostro set di dati, dobbiamo creare una nuova sezione (ricorda: ogni combinazione di dimensioni disponibile corrisponde a una sezione in nel set di dati).
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
La definizione della tabella per la sezione ha il seguente aspetto:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
Il file CSV per la tabella ha il seguente aspetto:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
Rispetto ai paesi, alla popolazione e alla fetta di disoccupazione precedenti, questa ha una dimensione aggiuntiva: ogni valore della metrica della popolazione corrisponde non solo a un determinato paese e anno, ma anche a un di un determinato genere.
Tieni presente che abbiamo creato una finestra del set di dati. Non tutte sono disponibili metriche per tutte le dimensioni: la popolazione è disponibile per i paesi e gli stati degli Stati Uniti, su base annuale, mentre il tasso di disoccupazione è disponibile solo per i paesi. La suddivisione per genere è disponibile solo per la popolazione per paese; non è disponibile per il tasso di disoccupazione e non per la dimensione dello stato. La sparsità può esistere anche a livello a livello di progetto, con alcune metriche che non hanno valori per determinati valori di dimensione, ma che non è rappresentato in DSPL.
Argomenti
L'ultima funzionalità di DSPL che utilizzeremo nel nostro set di dati è topics. Gli argomenti vengono utilizzati per classificare i concetti in modo gerarchico e sono usati per aiutare gli utenti a raggiungere i tuoi dati.
Nel file DSPL, gli argomenti vengono visualizzati subito prima dei concetti. Ecco un esempio gerarchia degli argomenti:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>Puoi nidificare gli argomenti quando necessario.
Per utilizzare gli argomenti, devi solo farvi riferimento dal concetto definizione, come segue:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
Un concetto può fare riferimento a più di un argomento.
Invio del set di dati
Ora che hai creato il set di dati, il passaggio successivo è comprimerlo carica il file ZIP su lo strumento Google Public Data Explorer. In caso di problemi, controlla Domande frequenti, che include una discussione dei problemi di caricamento più comuni.
Come riferimento, puoi anche scaricare il file XML completo e il pacchetto di set di dati completo associati a questo tutorial.
Passaggi successivi
Congratulazioni per aver creato il tuo primo set di dati DSPL. Ora che comprendere le nozioni di base, ti consigliamo di leggere la Guida per gli sviluppatori, che, "avanzate" dei documenti, tra le altre cose Funzionalità DSPL come supporto multilingue e concetti mappabili.
Puoi anche esaminare altri set di dati di esempio.