DSPL は、Dataset Publishing Language の略です。DSPL で記述されたデータセット Google Public Data および エクスプローラを使用すると、 分析できます
注: Google Public Data にデータをアップロードするには、 一般公開データのアップロード ツールを使用する Google アカウントが必要です。
このチュートリアルでは、基本的な Compute Engine インスタンスを DSPL データセットを使用します。
DSPL データセットは、XML ファイルと一連のドキュメントで構成されるバンドルです。 使用できます。CSV ファイルは、次のデータを含むシンプルなテーブルです。 表示されます。XML ファイルには、データセットのメタデータが記述されます。 情報メタデータ(メジャーの説明など)や テーブル間の参照などの構造的メタデータです。メタデータにより データを探索して可視化できます。
このチュートリアルを理解するための前提条件は、 XML の知識が必要です単純なデータベース コンセプト( テーブル、主キーなど)が役立つかもしれませんが、必須ではありません。参考までに、 完成した XML ファイル 完全なデータセット このチュートリアルに関連するバンドルもご確認いただけます。
概要
データセットの作成を開始する前に、データセットの概要について DSPL データセットの内容
- 全般情報: データセットについて
- 概念: 「物」の定義 データセットに含まれる情報(国、失業率、性別、 etc.)
- スライス: なんらかの データ
- テーブル: コンセプトとスライスのデータ。コンセプト テーブル 列挙値を保持し、スライス テーブルで統計データを保持する
- トピック: データセットのコンセプトを整理するために使用します。 ラベルを使って意味のある階層に
これらのむしろ抽象的な概念を説明するために、 ダミーデータ)が使用されます。 (国、地域、国、地域、職種の組み合わせ別に集計) 米国の州、性別です。
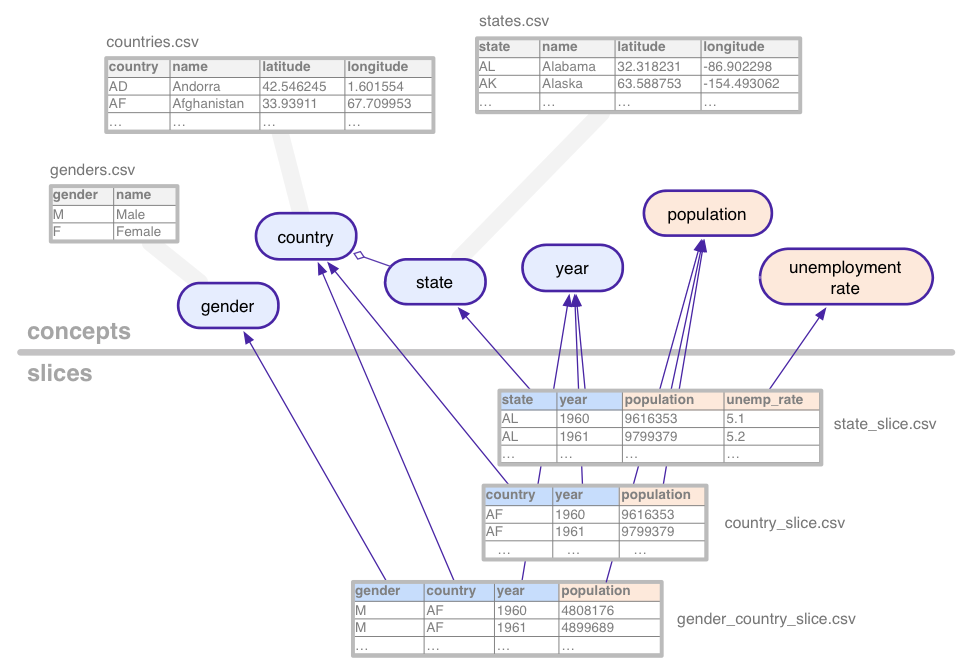
このサンプル データセットは、次のコンセプトを定義します。
- country
- gender
- population
- state
- 失業率
- 年
状態などのカテゴリカルなコンセプトは、コンセプト tables: 取り得るすべての値が列挙されます。 アリゾナなど)。Concepts には、 州の名前や国を入力します。
スライスは、それに対応するコンセプトの各組み合わせを定義します。
予測します。スライスには、ディメンションと
指標。上の画像では、寸法は青色で、
指標がオレンジ色になります。この例では、スライスは
gender_country_slice には指標のデータがあります
population、ディメンション country です。
year、gender。スライスである
country_slice は、次の国の年間総人口数(指標)を返します。
。
スライスは、ディメンションと指標に加えて、 テーブルには実際のデータが格納されます。
ここでは、Google Cloud コンソールでこのようなデータセットを DSPL
データセット情報
まず、データセットの XML ファイルを作成します。こちらの は、サンプル データセットの DSPL 説明の冒頭です。
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
データセットの説明は最上位の <dspl> で始まります。
要素です。targetNamespace 属性には、次の URI 情報が含まれます。
このデータセットを一意に識別します。このデータセットの名前空間は、
データセットのグローバル識別子になるため、データセットの公開時に重要です。
他のユーザーがデータセットを参照する手段です。
targetNamespace 属性は省略される場合があります。イン
この場合、データセットの作成時に一意の名前空間が
表示されます。
他のデータセットからの情報の使用
データセットでは、他のデータセットの定義やデータを再利用できます。
取得します各 <import> 要素には、
このデータセットが参照する別のデータセットの名前空間です。
サンプル データセットでは、http://www.google.com/publicdata/dataset/google/quantity から定義する必要があります。 (Google が作成したデータセットで、データセットを 時間、エンティティ、地理の各データセットから得られる情報を それぞれ時間、エンティティ、地域に関する定義があります。
最上位の <dspl> 要素に名前空間の接頭辞を指定します
宣言(例:(xmlns:time="http://...")
必要があります。参照するには接頭辞の宣言が必要です
他のデータセットの要素を簡潔にまとめます。たとえば
time:year は、year の定義を参照します。
名前空間が接頭辞に関連付けられているインポート済みのデータセット
time。
データセットとプロバイダの情報
<info> 要素には、リソースに関する一般情報が含まれます。
データセット: 名前、説明、詳細情報を確認できる URL
できます。
<provider> 要素には、インスタンスに関する情報が含まれます。
データセットのプロバイダ: データセットの名前と、詳細情報を確認できる URL
(通常はデータ プロバイダのホームページ)に表示されます。
コンセプトの定義
データセットに関する一般的な情報を確認したので、 その内容を定義する準備が整いました次の目標は 過去 50 年間の各国の人口統計。
最初に行うべきことは、この概念の意味を定義することです。 人口、国、年に基づく予測ですDSPL では、これらの定義を 概念。
コンセプトとは、 見てみましょう。ある特定のコンセプトに対応するデータ値を インスタンスです。
人口
まず、母集団の概念を定義します。新しい
DSPL ドキュメント。コンセプトは <concepts> で定義されています。
データセットとプロバイダの情報の直後に配置されます。
これは、必要最小限の情報のみを含む人口の概念です。
任意のコンセプト: id(一意の識別子)、name、
type。
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
このサンプルについて解説します:
- すべてのコンセプトで、一意に識別する
idを指定する必要があります データセット内のコンセプトを表します。つまり、Terraform で定義される 2 つのコンセプトは 同じデータセットを同じ ID にすることもできます。 - データセットとそのプロバイダの場合と同様に、
<info>要素は、 名前や説明などです。 <type>要素では、変数のデータ型を指定します。 インスタンス(つまりその「値」)。 この例では、populationのタイプは次のとおりです。integer。DSPL は次のデータ型をサポートしています。 <ph type="x-smartling-placeholder">- </ph>
stringintegerfloatbooleandate
国
次に、国の概念の定義を書いてみましょう。
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
国のコンセプトの定義も前の例と同じように始まります。
id、info、type を使用します。
コンセプト値
国などのカテゴリ概念には、考えられるすべての項目が
説明します。つまり、対象となる可能性があるすべての国をリストアップできる
あります。ただし、これを行うには、国ごとに一意の ID が必要です。
この例では を使用しています。
ISO 国コード: 国を識別します。これらのコードは
string 型。
この例では、ISO コードを使用する必要はありません。 国名も使用できますただし名前は言語によって異なり 時間の経過とともに変化する可能性があり、データセット間で常に一貫して使用されるとは限りません。 国およびカテゴリ概念全般については、 短い、安定している、一般的に使用される、言語に依存しない、 識別子(存在する場合)を指定します。
コンセプトのプロパティ
id に加えて、country のコンセプトには以下があります。
国の名前を指定する <property> 要素。
つまり、国名(「アイルランド」)はプロパティです。
id IE と締結した国。プロパティは、DSPL が
コンセプトのインスタンスに関する追加の構造化情報。
コンセプト自体と同様に、プロパティには id があります。
info、type。
コンセプト データ
最後に、country のコンセプトには <table> 要素があります。
この要素は、すべてのデータソースのリストを列挙するテーブルを参照します。
。
テーブルの使用は、一部のコンセプトでは理にかなっていますが、他のコンセプトでは意味がありません。対象 使用可能なすべての値を列挙することは 学習しますただし、テーブルを参照する場合は そのテーブルには、そのコンセプトのすべてのインスタンスが含まれている必要があります(例: サンプルだけでなく、すべての国を記載する必要があります。
このデータセットでは、次のように countries_table テーブルを定義します。
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
country テーブルでは、テーブルの列とそのタイプを指定します。
データを含む CSV ファイルを参照します。この CSV は
データセット XML でバンドルしてアップロードするか、HTTP、HTTPS、
できます後者の場合は、countries.csv を次のように置き換えます。
URL(例: http://www.myserver.com/mydata/countries.csv)。
CSV ファイルは、保存場所にかかわらず次のようになります。
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
表の 1 行目には、DSPL で指定されている列 ID がリストされている
table の定義。以下の各行は、対応する 1 つの
国のコンセプトのインスタンスです。コンセプトに表がある場合は
テーブルにはコンセプトのすべてのインスタンスが含まれている必要があります。この例では
すべての国がリストされている必要があります
列は、国のコンセプトとそのプロパティに、
表示されます。最初の列の ID country はコンセプトと一致しています
あります。つまり、この列には一意の国識別子が
国のコンセプトで定義されます。次の列は
国のコンセプトの name プロパティ。値
name プロパティの値と一致させます。
コンセプト テーブルの CSV データには、いくつかの要件があります。
- データファイルの最初の行の列見出しは、
完全一致の
idとプロパティ データが関連付けられているコンセプトのid( 注文は異なる場合があります)。 - 各行の要素の数は、指定した数と完全に同じである必要があります。 コンセプトの複数のプロパティを定義します(値が空であっても)。
- コンセプトの
idフィールドの各値(ここでは、 国コード)は、一意かつ空にできない(空白のフィールドは 0 を含む 1 つのフィールド) 空白文字のみなど)。 - 他のコンセプトを参照するプロパティの値は、次のいずれかにする必要があります。 空にするか、参照するコンセプトの有効な値にすることができます。
- カンマ、二重引用符、改行文字を含む値は、 二重引用符で囲む必要があります。
- 値の中にリテラル二重引用符文字がある場合は、 付けられます。
年
国の人口データに必要な最後のコンセプトは、
年を表します。新しいコンセプトを定義するのではなく、
年のコンセプトを使用します。
"http://www.google.com/publicdata/dataset/google/time".そのためには、
time:year として参照する必要があります。ここで、time
参照先のデータセットを表します。year は参照するデータセットを識別します。
説明します。
正規概念
time:year は少数の正規概念の一部です。
定義します。正規化された概念は、時刻、時間、時刻、
地理、数値、単位など
実際、上で定義した国の概念は、
説明します。ここでは説明のみを目的としています。
可能な限り、データセットでは正規の概念を使用する必要があります。
直接または拡張できます(拡張については後述します)。正規概念
他のデータセットと比較できるようにし、独自の機能を有効にしたり、
Public Data Explorer で確認できます。たとえば、時間の経過に伴うデータのアニメーション化
地図上に地理データを表示する場合は、time と
それぞれ geo の正規の概念があります。
最初のスライス
人口、国、年の概念がわかったところで、次は 考えてみましょう
そのためには、それらを組み合わせるスライスを作成する必要があります。DSPL では、 スライスは、データが存在するコンセプトの組み合わせです。
適切な列を持つテーブルを作成すればよいのでしょうか。スライスは コンセプトから見たデータセットの情報です。これは次の形式になります: より明確になります。
スライスは DSPL ファイルの <slices> の下に表示される
この要素は concepts セクションの直後に配置する必要があります。
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices>コンセプトと同様に、各スライスには id があります。
(countries_slice)で、スライスを一意に識別します
見てみましょう。
スライスには、ディメンションと、2 種類のコンセプト参照が含まれます。
指標。指標の値は、指標の値によって
定義できます。ここで、population の値(指標)は、
ディメンション country と year。
コンセプトと同様に、スライスには、テーブルを参照する スライスのデータが含まれています。参照先のテーブルには、 スライスの各ディメンションと指標を指定しますコンセプトと同様に、スライスの ディメンションと指標は、同じ ID を持つ表の列にマッピングされます。
スライス テーブル
人口スライスのテーブルは tables に表示されます。
セクションを次のように追加します。
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
year 列には format が付属しています。
年の形式を指定する属性です。サポートされている日付形式は次のとおりです。
Joda DateTime 形式で定義された値を使用します。
countries_slice テーブルは、テーブルの列を指定します。
そのデータを含む CSV ファイルを指定します。CSV ファイル
次のようになります。
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
データ表の各行には、固有のディメンションの組み合わせが含まれています。
country、year、および対応する値
population 指標(母集団 -
metric - 1960 年のアフガニスタンの「dimension」など)。
country 列の値は、
country コンセプトの値/識別子(ISO 3166)
国の 2 文字のコード。
スライスの CSV データは、次の制約を満たす必要があります。
- ディメンション フィールドの各値(
countryやyearなど)を空にすることはできません。指標フィールドの値(population)は空にできます。空の値は「no」で表され、 あります。 - コンセプトを参照するディメンション フィールドの各値は、
存在するという意味です。たとえば、値
AFです。countryコンセプト データテーブルに存在する必要があります。 - ディメンション値の各一意の組み合わせ。例:
AF, 2000, 1 回だけです。 - データは、時間以外のディメンション列を基準に(順不同)並べ替える必要があります。
必要に応じて他の列も結合できますたとえば
[date, dimension1, dimension2, metric1, metric2]列を含むテーブルでは、dimension1で並べ替えることができます。 その後はdimension2、次にdateとなり、ただし、date、そしてディメンションです。
概要
この時点で、DSPL には国を説明するのに十分な量があります。 提供しますここまでの内容をまとめます。
- DSPL ヘッダー、データセットおよびその説明を作成する 提供元
- 人口、国などの概念を 1 つずつ作成し、 すべての国とその名前が列挙された CSV ファイル
- 国の人口の推移からスライスを作成します。 インポートされた時間データセットですでに定義されている年のコンセプトを参照する 提供します。
このチュートリアルの残りの部分では、Google Cloud で 分割項目や分割項目を増やすことで 説明します。
ディメンションを追加する: 米国の州
次に、カリフォルニア州の人口データを追加してデータセットを拡充しましょう。 米国。まず、状態の概念を定義する必要があります。これは非常に 前に定義した国のようなコンセプトです
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>コンセプトの拡張とプロパティ 参照
状態のコンセプトには、DSPL のいくつかの新機能が導入されています。
まず、状態は別のコンセプトを拡張します。
geo:location(外部の地域データセットで定義)
など)が含まれます。意味的には
state は geo:location の一種です。結果として
そのすべての属性とプロパティを
geo:location。特に、location 要素のプロパティを定義して、
latitude、longitude前者を拡張することで、
これらのプロパティは状態にも適用されます。さらに、
ロケーションは entity:entity から継承され、状態も取得されます。
後者のすべてのプロパティ(name を含む)を
description、info_url。
注: 前に定義した国の概念は、
技術的には geo:location からも拡張されるはずです。
これまでは、わかりやすくするためにこの点は省略しました。Chronicle の
国と地域間の継承は異なりますが、
最終的な XML ファイル。
注: extends を使用して、
他のデータセットで定義された情報を再利用するために独自のデータセットを構築します。
extends を使用するには、コンセプトのすべてのインスタンスが
実例を持つことになります。拡張機能を使用すると
追加のプロパティと属性を設定し、インスタンスのセットを
インスタンスのサブセットです。
state プロパティでは継承の他に
コンセプト参照のアイデア。
特に、状態の概念には country というプロパティがあります。
これは、先ほど作成した国のコンセプトを参照します。これは、
concept 属性を使用します。このプロパティでは、
ID を提供し、コンセプトの参照のみを提供します。これは UDM イベントで ID を作成するのと
に、参照先のコンセプトの ID と同じ値(
country など)。モデル間の階層関係は
都道府県や郡は属性を使用して
リファレンスの isParent="true"。一般的に
地域などの階層関係を持つディメンションは、
子コンセプトに、親子関係を表す
isParent 属性を使用して親コンセプトを参照します。
状態のテーブル定義は次のようになります。
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
country 列には、すべての州で定数値が含まれます。環境変数で
DSPL は、データ内のすべての状態について、その値を繰り返すことを回避します。また、
name 列、latitude 列、
longitude(州がこれらのプロパティを次から継承しているため)
geo:location。一方 一部の継承されたプロパティは
(例:description)には列がありません。大丈夫です-
概念定義テーブルでプロパティが省略されている場合、その値は
コンセプトのすべてのインスタンスで未定義とみなされます。
CSV ファイルは次のようになります。
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
すでに人口と年のコンセプトがあるので、それらを再利用できます。 州人口の新しいスライスを定義するとします。
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>データテーブルの定義は次のようになります。
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
CSV ファイルは次のようになります。
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
なぜスライスを追加するのではなく、新しいスライスを作成したのか どうすればよいでしょうか?
州と国の両方のディメンションを持つスライスは正しくありません。 一部の行は国データ用で、一部の行は州用であるためです。 分析できますテーブルには「穴」があります。一部のディメンションについては 許可されない(不足している値は、指標と値のみ ディメンションではなく)。
ディメンションは「主キー」として機能する使用します。つまり すべてのデータ行にすべてのディメンションの値が含まれ、データ行が 2 つないようにする必要があります すべてのディメンションでまったく同じ値を使用できます。
指標の追加: 失業 レート
次に、データセットに別の指標を追加しましょう。
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
この指標の info セクションには、名前、説明、
URL(米国労働統計局へのリンク)。
このコンセプトも quantity:rate 正規コンセプトを拡張したものです。
数量
数値量を表すための基本コンセプトを定義します。イン
数値の概念を作成するには、Python 関数を拡張して
適切な数量の概念です。したがって、population のコンセプトは
定義したプロパティは、厳密には
quantity:amount。
コンセプト属性
このコンセプトでは属性の構成も紹介します。イン
この例では、属性を使用して、unemployment_rate を指定します。
割合ですis_percentage 属性は
quantity:rateこのコンセプトを拡張するコンセプトです。この
Public Data Explorer では、この情報を使用して、
データの可視化です。
属性は、Key-Value ペアを
(プロパティは追加の値をリソースに関連付けるため)
インスタンスなど)が使用されます。コンセプトやプロパティと同様に
各属性には、id、info、および
type。プロパティと同様に、他のコンセプトを参照できます。
属性は、事前定義された一般的な情報(たとえば、 プロパティです。コンセプトに対して独自の属性を定義できます。
米国の失業率データの追加 状態
これで、米国の州の失業率データを追加する準備が整いました。なぜなら、 失業率の指標です 州の人口データはすでにあるので 州と年にすでに作成したスライスに追加するだけです ディメンション:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>さらに、テーブル定義に列を追加します。
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
CSV ファイルを次のように追加します。
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
前述のとおり、スライスごとに、ディメンションが主キーを形成します。 使用します。また、各データセットに含めることができるスライスは、 ディメンションの組み合わせですこれらの指標で利用できるすべての指標は 同じスライスに属している必要があります
その他のディメンション: 性別による人口の内訳
データセットを、2023 年 9 月 31 日 。もうやり方はわかってるよね...まず、 追加することもできます。
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
性別のコンセプト info セクションには
pluralName: 参照するテキストを指定します。
ジェンダーの概念の複数のインスタンスがあります。info セクションも
テキストを指定する totalName が含まれています。
ジェンダーの概念のすべての例を全体として指します。これらは両方とも
性別に関する情報を表示するために、公共データ エクスプローラによって使用されます。
コンセプトです。一般に、Google Cloud のインフラストラクチャ ソリューションとして使用できる
定義できます。
なお、性別の概念は、
entity:entity。これはコンセプトの理解に
カスタム名を追加したり
さまざまなコンセプト インスタンスの URL、色などです。
性別のコンセプトは、genders_table テーブルを参照します。
には、性別と表示名に使用できる値が含まれています。
(ここでは省略)。
データセットに性別ごとの人口を追加するには、新しいスライスを作成する必要があります (利用可能なディメンションの組み合わせは、それぞれが 1 つのスライスに対応する あります。
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
スライスのテーブル定義は次のようになります。
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
このテーブルの CSV ファイルは次のようになります。
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
前の国、人口、失業分野に比べると、 ここには別のディメンションがあります母集団の指標の各値 特定の国と年だけでなく 特定できます
ここでは「スパース」な見てみましょう。すべてではありません すべてのディメンションで指標を使用できます。母集団は 失業保険制度を利用できる中、国および米国の州で 税率は国でのみ使用できます。性別ごとの内訳は 国別の人口のみ失業率では利用できません 指標であることがわかります。データにもスパース性が存在する 特定のディメンション値に値がない指標や、 これは DSPL では表現されません
トピック
このデータセットで使用する DSPL の最後の特徴は、topics です。 トピックはコンセプトを階層的に分類するために使用され、 ユーザーが簡単にデータに移動できるようにします。
DSPL ファイルでは、トピックがコンセプトの直前にあります。サンプル トピックの階層:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>トピックは必要に応じて深くネストできます。
トピックはコンセプトから参照するだけで使用できます 定義します。
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
1 つのコンセプトで複数のトピックを参照することもできます。
データセットの送信
データセットを作成したら、次はそれを zip 形式で圧縮し、 zip ファイルをアップロードし、 Google 公共データ エクスプローラ ツール。問題が発生した場合は、 よくある質問(ディスカッションを含む) よくある問題を見てみましょう
参考として、完全な XML ファイルと完全なデータセット バンドルをダウンロードすることもできます。 関連しています
さらに活用する
これで最初の DSPL データセットが作成されました。これで、 デベロッパー ガイドをお読みになることをおすすめします。 「高度な」ドキュメントなど次のような DSPL 機能を使用できます。 多言語サポートとマッピング可能なコンセプトです
その他のサンプル データセットもご覧いただけます。