DSPL은 데이터 세트 게시 언어를 의미합니다. DSPL에 설명된 데이터 세트 Google 공개 데이터 Google 탐색 도구를 이용하면 Google 지도를 풍부하고 시각적으로 데이터를 수집하는 데 사용됩니다
참고: Google Public Data에 데이터를 업로드하려면 다음 안내를 따르세요. 공개 데이터 업로드 도구를 사용해 Google 계정이 있어야 합니다.
이 튜토리얼에서는 Google Cloud 콘솔의 DSPL 데이터 세트입니다.
DSPL 데이터 세트는 XML 파일과 일련의 데이터 세트를 포함하는 번들입니다. CSV 파일. CSV 파일은 CSV 파일의 데이터를 포함하는 간단한 테이블입니다. 데이터 세트입니다. XML 파일은 데이터 세트의 메타데이터를 설명합니다. 측정에 대한 설명과 같은 정보 메타데이터와 구조적 메타데이터(예: 테이블 간 참조) 메타데이터를 사용하면 비전문가 사용자가 데이터를 탐색하고 시각화할 수 있습니다.
이 튜토리얼을 이해하려면 이해할 수 있을 것입니다. 간단한 데이터베이스 개념 (예: 테이블, 기본 키)가 도움이 될 수 있지만 필수는 아닙니다. 참고로 완전한 XML 파일을 포함하고 전체 데이터 세트 이 튜토리얼과 연결된 번들도 검토할 수 있습니다.
개요
데이터 세트를 만들기 전에 Google Cloud의 DSPL 데이터 세트에 포함된 내용은 다음과 같습니다.
- 일반 정보: 데이터 세트 정보
- 개념: '사물'의 정의 저것 데이터 세트에 표시되는 이름 (예: 국가, 실업률, 성별, etc.)
- 슬라이스: 슬라이스에 있는 개념의 조합입니다. 데이터
- 테이블: 개념 및 슬라이스 데이터입니다. 개념 테이블 열거형 및 슬라이스 테이블에 통계 데이터 보관
- 주제: 데이터 세트의 개념을 구성하는 데 사용됩니다. 계층 구조를 만들고
이와 같이 추상적인 개념을 설명하기 위해 데이터 세트( 더미 데이터)를 사용할 수도 있습니다. 다양한 국가 조합별로 집계된 인구 및 실업률 확인할 수 있습니다.
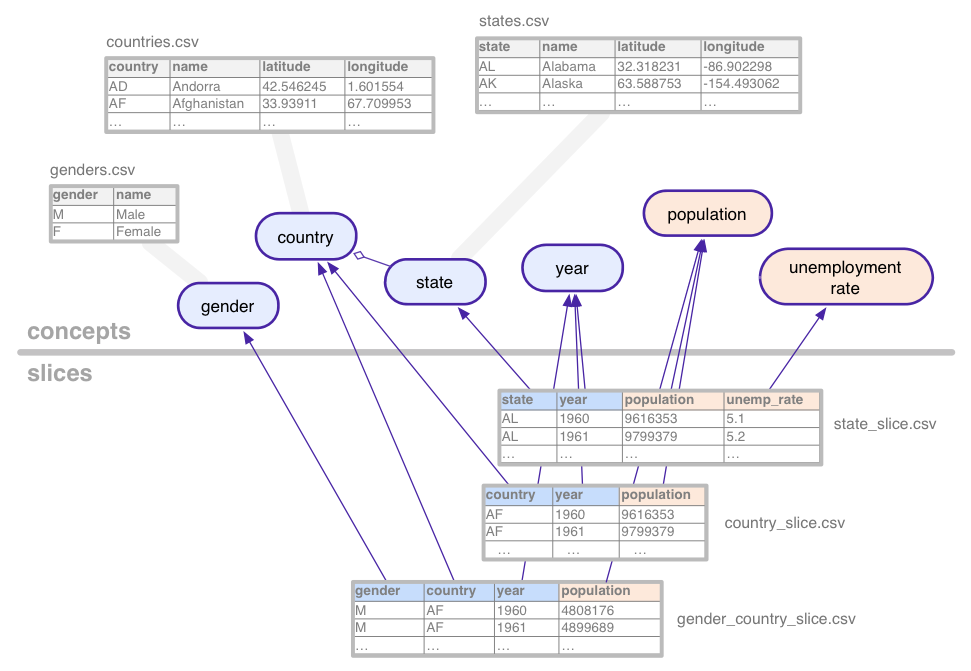
이 데이터 세트 예는 다음과 같은 개념을 정의합니다.
- 국가
- gender
- population
- 주
- 실업률
- 년
상태와 같이 범주형 개념은 개념과 연결됩니다. tables는 가능한 모든 값 (캘리포니아, 애리조나 등). 개념에는 다음과 같은 속성에 대한 추가 열이 있을 수 있습니다. 주 이름 또는 국가일 수 있습니다.
슬라이스는 해당 개념의 각 조합을 정의합니다.
데이터 세트의 통계 데이터입니다. 슬라이스에는 측정기준과
측정항목: 위의 그림에서 크기는 파란색이고
주황색입니다. 이 예에서 슬라이스는
gender_country_slice에 측정항목에 대한 데이터가 있습니다.
population 및 country 크기
year 및 gender 또 다른 슬라이스는
country_slice: 다음에 대한 연간 총 인구 수 (측정항목) 제공
국가.
슬라이스는 측정기준 및 측정항목 외에도 테이블 - 실제 데이터가 포함되어 있습니다.
이제 인코더-디코더 아키텍처에서 이러한 데이터 세트를 만드는 DSPL
데이터 세트 정보
시작하려면 데이터 세트를 위한 XML 파일을 만들어야 합니다. 여기에서 DSPL 설명 시작 부분:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
데이터 세트 설명은 최상위 <dspl>로 시작합니다.
요소가 포함됩니다. targetNamespace 속성에는
이 데이터 세트를 고유하게 식별합니다. 데이터 세트의 네임스페이스는
이는 데이터 세트의 전역 식별자가 되므로
다른 사람이 그것을 참조할 수 있는 수단을 제공합니다.
targetNamespace 속성은 생략할 수 있습니다. 포함
이 경우 데이터 세트가
가져온 것입니다.
다른 데이터 세트의 정보 사용
데이터 세트는 다른 데이터 세트의 정의와 데이터를
Vertex AI Feature
Store에서 제공되는 각 <import> 요소는
이 데이터 세트가 참조할 다른 데이터 세트의 네임스페이스입니다.
이 예시 데이터 세트에는 http://www.google.com/publicdata/dataset/google/quantity의 정의가 필요합니다. (정의하는 데 유용한 개념이 포함된 Google에서 만든 데이터 세트 숫자 수량), 시간, 항목, 지리 데이터 세트를 기준으로 각각 시간, 항목 및 지리와 관련된 정의입니다.
상단 <dspl> 요소는 네임스페이스 프리픽스를 제공합니다.
선언 (예: xmlns:time="http://...")
가져온 데이터 세트입니다 참조하기 위해 접두사 선언이 필요합니다.
다른 데이터 세트의 요소를 간결하게
작성할 수 있습니다 예를 들면 다음과 같습니다.
time:year은 year의 정의를
네임스페이스가 프리픽스와 연결된 가져온 데이터 세트
time입니다.
데이터 세트 및 제공업체 정보
<info> 요소에는
데이터 세트: 이름, 설명, 추가 정보가 있는 URL
발견.
<provider> 요소에는
데이터 세트의 제공업체: 이름 및 추가 정보를 확인할 수 있는 URL
(일반적으로 데이터 제공자의 홈페이지)에 저장됩니다.
개념 정의
이제 데이터 세트에 관한 일반 정보를 제공했으므로 콘텐츠를 정의할 준비가 되었습니다 다음 목표는 국가별 인구 통계 자료입니다.
가장 먼저 해야 할 일은 이 개념에 대한 정의를 제공하는 것입니다. 볼 수 있습니다. DSPL에서는 이러한 정의를 개념
개념은 표에 나타나는 데이터 유형의 정의입니다. 데이터 세트로 그룹화됩니다. 주어진 개념에 해당하는 데이터 값을 인스턴스를 만들 수 있습니다.
인구
모집단 개념부터 정의해 보겠습니다.
DSPL 문서, 개념은 <concepts>에 정의되어 있음
요소가 포함됩니다.
다음은 필요한 최소한의 정보만 가지고 있는 모집단 개념입니다.
모든 개념: id (고유 식별자), name,
type입니다.
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
샘플의 기본 원리는 다음과 같습니다.
- 모든 개념은 다음을 고유하게 식별하는
id를 제공해야 합니다. 학습합니다. 즉, 두 가지 개념이 동일한 데이터 세트가 동일한 ID를 가질 수 있습니다. - 데이터 세트 및 제공자와 마찬가지로
<info>요소는 개념(예: 이름, 설명)을 뜻합니다 <type>요소는 개념의 인스턴스 (즉, '값')를 반환합니다. 이 예에서population의 유형은 다음과 같습니다.integer입니다. DSPL은 다음 데이터 유형을 지원합니다. <ph type="x-smartling-placeholder">- </ph>
stringintegerfloatbooleandate
국가
이제 국가 개념의 정의를 작성해 보겠습니다.
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
국가 개념 정의는 이전과 같이 시작됩니다.
id, info, type를 사용합니다.
개념 값
국가와 같은 범주형 개념에는 가능한 모든
인스턴스 즉, 광고가 게재될 수 있는 가능한 모든 국가를
참조됩니다. 하지만 이를 위해서는 국가별로 고유 식별자가 필요합니다.
이 예에서는
ISO 국가 코드로 국가를 식별합니다. 이러한 코드는
string 유형입니다.
이 예에서는 ISO 코드를 사용하지 않아도 됩니다. 나 국가 이름도 사용할 수 있습니다 하지만 이름은 언어별로 다르며 변할 수 있으며 데이터 세트에서 항상 일관되게 사용되는 것은 아닙니다. 국가와 일반적으로 범주형 개념의 경우 간결하고 안정적이며 흔히 사용되며 언어에 구애받지 않고 연습할 수 있어야 합니다. 사용할 수 있습니다.
개념 속성
id 외에도 국가 개념에는
국가 이름을 지정하는 <property> 요소.
즉, 국가 이름('아일랜드')은 속성입니다.
id 아일랜드와 현재 거래하고 있습니다. 숙박 시설은 DSPL이
개념의 인스턴스에 대한 구조화된 추가적인 정보를 제공합니다.
개념 자체와 마찬가지로 속성에는 id,
info, type
개념 데이터
마지막으로 국가 개념에는 <table> 요소가 있습니다.
이 요소는 모든
국가.
표를 사용하는 것은 일부 개념에는 적합하지만 다른 개념에는 적합하지 않습니다. 대상 예를 들어, 열에 대해 가능한 모든 값을 열거하는 것은 개념 인구입니다. 그러나 해당 테이블은 개념의 모든 인스턴스를 포함해야 합니다(예: 표본 몇 개가 아닌 모든 국가를 나열해야 합니다.
데이터 세트는 countries_table 테이블을 다음과 같이 정의합니다.
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
국가 테이블은 테이블의 열과 유형을 지정합니다.
를 사용하고 데이터가 포함된 CSV 파일을 참조합니다. 이 CSV는
데이터 세트 XML과 함께 번들로 제공 및 업로드되거나 HTTP, HTTPS,
또는 FTP입니다. 후자의 경우 countries.csv를 다음으로 바꿉니다.
URL(예: http://www.myserver.com/mydata/countries.csv)
어디에 저장되든 CSV 파일은 다음과 같이 표시됩니다.
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
표의 첫 번째 행에는 DSPL에 지정된 대로 열 ID가 나열됩니다.
table 정의. 다음 각 행은
국가 개념의 인스턴스입니다. 개념에 테이블이 있는 경우
테이블에는 개념의 모든 인스턴스가 포함되어야 합니다.
모든 국가를 나열해야 합니다.
열은 국가 개념에 매핑되며 속성은
확인할 수 있습니다. 첫 번째 열의 ID인 country는 개념과 일치합니다.
있습니다. 즉, 이 열에는 고유한 국가 식별자가 포함됩니다.
정의될 수 있습니다. 다음 열은
국가 개념의 name 속성입니다. 값
이 열의 값은 name 속성의 값과 일치합니다.
개념 테이블의 CSV 데이터에는 다음과 같은 몇 가지 요구사항이 있습니다.
- 데이터 파일의 첫 번째 줄에 있는 열 제목이
id및 속성과 정확히 일치 데이터가 연결되는 개념의id입니다. 주문은 다를 수 있음). - 각 행에는 속성 (값이 비어 있는 경우에도)을 반환합니다.
- 개념의
id필드에 대한 각 값 (여기에서는 국가 코드)는 고유해야 하며 비어 있지 않아야 합니다. 빈 필드는 0을 의미합니다. 공백 문자만 포함) - 다른 개념을 참조하는 속성 값은 비어 있거나 참조된 개념의 유효한 값이어야 합니다.
- 쉼표, 큰따옴표 또는 줄바꿈 문자가 포함된 값은 큰따옴표로 묶여 있습니다.
- 값 안에 있는 리터럴 큰따옴표 문자는 큰따옴표가 있습니다
연도
국가 인구 데이터에 필요한 마지막 개념은
는 년을 나타냅니다. 새로운 개념을 정의하는 대신
연도 개념을 살펴 보겠습니다.
"http://www.google.com/publicdata/dataset/google/time". 이렇게 하려면
time:year로 참조해야 합니다. 여기서 time는
는 참조되는 데이터 세트를 나타내며 year는
살펴보겠습니다
표준 개념
time:year는 소규모 표준 개념의 일부입니다.
Google에서 정의합니다 표준 개념은 시간에 대한 기본적인 정의를 제공합니다.
지리, 숫자 수량, 단위 등입니다.
사실 위에서 정의한 국가 개념은
표준 개념입니다. 여기에서는 참고용으로만 사용하겠습니다.
가능하면 데이터 세트에 표준 개념을 사용해야 합니다.
확장할 수 있습니다 (자세한 내용은 아래 참조). 표준 개념
데이터를 다른 데이터 세트와 비교할 수 있도록 만들고,
데이터 세트를 살펴볼 수 있습니다 예를 들어 시간 경과에 따른 데이터 애니메이션을
지도에 지리 데이터를 표시하려면 time 및
각각 geo 표준 개념입니다.
첫 번째 슬라이스
인구, 국가, 연도에 대한 개념이 생겼으니 하나로 합치는 거죠!
이를 위해 두 속성을 결합하는 슬라이스를 만들어야 합니다. DSPL에서 슬라이스는 데이터가 존재하는 개념의 조합입니다.
올바른 열로 테이블을 만들면 안 되나요? 슬라이스는 개념의 관점에서 데이터 세트의 정보를 처리합니다. 이 작업은 더 명확해 집니다.
슬라이스는 DSPL 파일의 <slices> 아래에 표시됩니다.
요소(concepts 섹션 바로 뒤에 표시되어야 함)
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices>개념과 마찬가지로 각 슬라이스에는 id가 있습니다.
(countries_slice)로,
데이터 세트로 그룹화됩니다.
슬라이스에는 크기와 같은 두 가지 개념 참조가 포함됩니다.
측정항목: 측정항목 값은
측정기준에 따라 달라집니다. 여기서 population (측정항목)의 값은 다음에 따라 다릅니다.
크기는 country 및 year입니다.
개념과 마찬가지로 슬라이스에는 각 항목의 의미 있는 테이블에 대한 참조가 포함됩니다. 슬라이스의 데이터를 포함합니다. 참조된 테이블에는 다음 열에 하나의 열이 있어야 합니다. 슬라이스의 각 차원과 측정항목을 나타냅니다. 개념과 마찬가지로 슬라이스의 측정기준과 측정항목은 ID가 동일한 표 열에 매핑됩니다.
슬라이스 표
인구 분할 표는 tables에 표시됩니다.
섹션에 다음 코드를 추가하세요.
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
year 열은 format와 함께 제공됩니다.
연도의 형식 지정 방식을 지정하는 속성입니다. 지원되는 날짜 형식은
Joda DateTime 형식으로 정의된 날짜/시간 형식.
countries_slice 테이블은 테이블의 열과
데이터가 포함된 CSV 파일을 가리킵니다. CSV 파일
다음과 같습니다.
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
데이터 표의 각 행에는 측정기준의 고유한 조합이 포함됩니다.
country, year, 상응하는 값
population 측정항목 (예: 인구 -
1960년 아프가니스탄의 측정항목 - 측정기준).
country 열의 값은
ISO 3166인 country 개념의 값/식별자입니다.
두 글자로 된 국가 코드입니다.
슬라이스의 CSV 데이터는 다음과 같은 제약 조건을 충족해야 합니다.
- 측정기준 필드의 각 값 (예:
country및year)은 비어 있지 않아야 합니다. 측정항목 필드 값 (예:population)은 비워 둘 수 있습니다. 빈 값은 no로 표시됩니다. 있습니다. - 개념을 참조하는 측정기준 필드의 각 값은
어떤 특성이 있는지
확인해야 합니다 예를 들어
AF값이 있습니다.country개념 데이터 테이블에 있어야 합니다. - 측정기준 값의 고유한 각 조합(예:
AF, 2000, 한 번만 발생할 수 있습니다. - 데이터는 시간 이외의 측정기준 열을 기준으로 정렬해야 합니다 (순서와 상관없음).
원하는 경우 다른 열 별로 이름을 지정할 수 있습니다. 예를 들어
[date, dimension1, dimension2, metric1, metric2]열이 있는 테이블에서dimension1을 기준으로 정렬할 수 있습니다. 이후dimension2, 이후date, 이후 제외date를 선택한 다음 크기를 클릭합니다.
요약
이제 DSPL에 국가를 설명하기에 인구 데이터입니다. 요약하자면, 우리가 해야 할 일은 다음과 같습니다.
- 데이터 세트의 DSPL 헤더 및 설명 및 제공업체
- 인구에 대한 개념과 국가에 대한 개념을 각각 만들어 보겠습니다. 모든 국가와 국가 이름이 나와 있는 csv 파일입니다.
- 시간 경과에 따른 국가의 인구 수를 사용하여 슬라이스를 만듭니다. 가져온 시간 데이터 세트에서 이미 정의된 연도 개념 참조 확인하세요.
이 튜토리얼의 나머지 부분에서는 더 많은 슬라이스에 더 많은 측정기준을 추가하고, 기준으로 그룹화된 측정항목도 더 많이 주제에 대해 살펴보겠습니다.
측정기준 추가: 미국 주
이제 미국의 주에서 인구 데이터를 추가하여 이용할 수 있습니다. 먼저 상태에 대한 개념을 정의해야 합니다. 이 작업들은 이전에 정의한 국가 개념과 같습니다.
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>개념 확장 및 속성 참조
상태 개념으로 인해 DSPL의 몇 가지 새로운 기능이 도입됩니다.
첫째, 상태는 다른 개념을 확장합니다.
geo:location (외부 지역 데이터 세트에 정의됨)
가져온 것입니다. 의미론적으로 이것은
state는 geo:location의 일종입니다. 결과는
모든 속성과 속성을 상속한다는 것을
geo:location 특히 위치는
latitude 및 longitude 인코더-디코더 아키텍처를
이러한 속성은 상태에도 적용됩니다. 게다가
위치는 entity:entity에서 상속되며 상태도
name를 비롯한 후자의 모든 속성
description, info_url
참고: 이전에 정의된 국가 개념은
엄밀히 말해 geo:location에서 확장되어야 합니다.
이전에는 편의상 이 점을 생략했습니다. 이 과정의 뒷부분에서
국가 상속으로
최종 XML 파일입니다.
참고: extends
다른 데이터 세트에 정의된 정보를 재사용할 수 있습니다.
extends를 사용하려면 개념의 모든 인스턴스가
정의하는 것이 더 중요합니다. 확장 프로그램을 사용하면
추가 속성과 속성을 설정하고, 인스턴스 집합을
확장된 개념의 인스턴스 하위 집합입니다.
상속 외에도 상태 속성은
참조 개념에 대한 아이디어를 얻을 수 있습니다.
특히 상태 개념에는 country이라는 속성이 있습니다.
위에서 만든 국가 개념을 참조합니다. 이는
concept 속성 사용 이 속성은
ID는 제공하고 개념 참조만 제공합니다. 이는 ID를 만드는 것과 같습니다.
참조된 개념의 ID와 동일한 값을 사용합니다 (예:
country)을 입력합니다. 데이터 모델과
'주'와 '국가'를 구분하려면
참조에 대한 isParent="true" 일반적으로
지역과 같이 계층적 관계가 있는 측정기준은
다음과 같이 표현됩니다. 하위 개념에는
isParent 속성을 사용하여 상위 개념을 참조합니다.
상태의 테이블 정의는 다음과 같습니다.
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
국가 열에는 모든 주에 대한 상수 값이 있습니다. 다음에서 지정:
DSPL은 데이터의 모든 상태에 대해 해당 값을 반복하지 않습니다. 추가 참고사항
name, latitude, 열이 포함되어 있습니다.
상태가 longitude로부터 이러한 속성을 상속받음
geo:location입니다. 반면에 일부 상속된 속성은
(예: description)에 열이 없습니다. 괜찮습니다.
개념 정의 테이블에서 속성이 생략된 경우 그 값은
개념의 모든 인스턴스에 대해 정의되지 않은 것으로 가정됩니다.
CSV 파일은 다음과 같습니다.
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
인구와 연도에 대한 개념이 이미 있으므로 다시 사용할 수 있습니다. 주 인구의 새 슬라이스를 정의합니다.
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>데이터 테이블 정의는 다음과 같습니다.
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
CSV 파일은 다음과 같습니다.
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
잠깐, 왜 새로운 슬라이스를 추가하지 않고 새 슬라이스를 만들었나요? 어떻게 해야 할까요?
주와 국가에 대한 측정기준이 있는 슬라이스는 올바르지 않습니다. 일부 행은 국가 데이터를 위한 것이고 일부 행은 주를 위한 것이기 때문입니다. 데이터를 수집하는 데 사용됩니다 테이블에는 '구멍'이 있습니다. 일부 측정기준의 경우 허용되지 않음 (누락된 값은 측정항목 및 '측정기준이 아님').
측정기준은 '기본 키' 역할 슬라이스를 선택합니다. 즉, 모든 데이터 행에 모든 측정기준에 대한 값이 있어야 하며 2개의 데이터 행이 없어야 함 모든 측정기준에 대해 정확히 동일한 값을 가질 수 있습니다.
측정항목 추가: 실업 평가
이제 데이터 세트에 또 다른 측정항목을 추가해 보겠습니다.
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
이 측정항목의 info 섹션에는 이름, 설명,
URL (미국 노동통계국으로 연결되는 링크)
이 개념은 quantity:rate 표준 개념도 확장합니다.
수량
데이터 세트는 숫자 수량을 나타내는 핵심 개념을 정의합니다. 포함
숫자 개념을 생성해야 하며
도움이 될 수 있습니다 따라서 population 개념은 다음과 같습니다.
기술적으로
quantity:amount입니다.
개념 속성
이 개념은 속성의 구성도 도입합니다. 포함
이 예시에서는 속성은 unemployment_rate
백분율입니다. is_percentage 속성은 다음에서 상속됩니다.
이 개념이 확장하는 quantity:rate 개념입니다. 이
공개 데이터 익스플로러는
데이터를 시각화하는 것입니다.
속성은 키-값 쌍을
추가 값을
인스턴스를 만들 때 유용합니다. 개념 및 속성과 마찬가지로
속성에는 id, info,
type입니다. 속성과 마찬가지로 다른 개념을 참조할 수 있습니다.
속성은 숫자, 텍스트, 이미지, 오디오, 음성 데이터 등 사전 정의된 속성 개념에 대한 고유한 속성을 정의할 수 있습니다.
미국의 실업률 데이터 추가 상태
이제 미국 주의 실업률 데이터를 추가할 준비가 되었습니다. 왜냐하면 실업률은 측정항목이며 이미 주에 대한 인구 데이터가 있으므로 주와 연도에 대해 이미 만든 슬라이스에 추가하기만 하면 됩니다. 측정기준:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>테이블 정의에 다른 열을 추가합니다.
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
그리고 다음과 같이 CSV 파일로 내보냅니다.
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
앞서 모든 슬라이스에 대해 차원은 각 슬라이스의 기본 키를 형성하고 슬라이스를 선택합니다. 또한 각 데이터 세트는 측정기준의 조합으로 표시됩니다. 이러한 측정항목에 사용할 수 있는 모든 측정항목은 차원은 해당 동일한 슬라이스에 속해야 합니다.
추가 측정기준: 성별에 따른 인구 분석
성별에 따라 모집단을 분류하여 데이터 세트를 보강합시다. 국가. 이제야 익힐 수 있는 방법을 알게 되셨을 겁니다... 먼저 성별에 대한 개념 추가:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
성별 개념 info 섹션에는
pluralName:
성별 개념의 다중 인스턴스입니다. info 섹션도
totalName가 포함되어 있으며, 이는
성별 개념의 모든 인스턴스를 전체적으로 지칭함 이 두 가지 모두
Public Data Explorer에서 성별과 관련된 정보를 표시하는 데 사용됩니다.
있습니다. 일반적으로 비즈니스 요구사항으로 사용할 수 있는 개념에 대해
측정기준에 따라 달라집니다.
성별 개념은 또한
entity:entity 이것은 개념을 이해하고
맞춤 이름을 추가할 수 있기 때문에
URL, 색상 등 여러 개념 인스턴스에 적용할 수 있습니다.
성별 개념은 genders_table 테이블을 의미하며
에는 성별 및 표시 이름에 사용할 수 있는 값이 포함됩니다.
(여기 생략)
데이터 세트에 성별별 인구를 추가하려면 새 슬라이스를 만들어야 합니다. (주의: 사용 가능한 각 차원 조합은 합니다.
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
슬라이스에 대한 테이블 정의는 다음과 같습니다.
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
테이블의 CSV 파일은 다음과 같습니다.
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
이전 국가, 인구 및 실업률과 비교하면 여기에 추가 측정기준이 있습니다. 모집단 측정항목의 각 값 특정 국가 및 연도에 해당할 뿐만 아니라 확인할 수 있습니다.
여기서는 'sparse'라는 데이터 세트로 그룹화됩니다. 일부 측정항목은 모든 측정기준에 대해 사용할 수 있습니다. 모집단: 실업률은 증가하지만 미국에서는 세율은 국가에서만 사용할 수 있습니다. 성별에 따른 분류를 사용할 수 있습니다. 국가별 인구만 실업률에 대한 데이터가 없음 주 측정기준이 아닌 측정항목이 사용되었습니다. 데이터에도 희소성이 존재할 수 있음 특정 측정항목에 대해 특정 측정기준 값에 대한 값이 없는 경우 DSPL에는 표시되지 않습니다
주제
데이터 세트에서 사용할 DSPL의 마지막 기능은 topics입니다. 주제는 개념을 계층적으로 분류하는 데 사용되며 사용자가 데이터를 탐색할 수 있도록 지원하는 애플리케이션을 제공합니다.
DSPL 파일에서 주제는 개념 바로 앞에 표시됩니다. 다음은 샘플입니다 주제 계층 구조:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>필요에 따라 주제를 깊게 중첩할 수 있습니다.
주제를 사용하려면 개념에서 참조하기만 하면 됩니다. 정의합니다.
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
하나의 개념은 둘 이상의 주제를 참조할 수 있습니다.
데이터 세트 제출
이제 데이터 세트를 만들었으므로 다음 단계는 이를 압축하고 ZIP 파일을 Google 공개 데이터 탐색기 도구 문제가 발생하면 FAQ(토론 내용 포함) 가장 일반적인 업로드 문제의 해결 방법을 알아보겠습니다.
참고로 전체 XML 파일 및 전체 데이터 세트 번들을 다운로드할 수도 있습니다. 확인할 수 있습니다
다음 단계
축하합니다. 첫 번째 DSPL 데이터 세트를 만들었습니다. 이제 기본사항을 이해하려면 개발자 가이드를 읽어보는 것이 좋습니다. 무엇보다도 "고급" 문서를 다음과 같은 DSPL 기능은 매핑 가능한 개념에 대해 살펴봤습니다.
예시 데이터 세트를 추가로 살펴볼 수도 있습니다.