DSPL to skrót od Dataset Publishing Language, Zbiory danych opisane w DSPL mogą być importowane do Google Public Data Eksplorator, czyli narzędzie, które umożliwia rozbudowane, wizualne poznawanie i skalowalnych danych.
Uwaga: aby przesłać dane do Google Public Data za pomocą narzędzia do przesyłania danych publicznych, musisz mieć konto Google.
W tym samouczku znajdziesz szczegółowy przykład, jak przygotować Zbiór danych DSPL.
Zbiór danych DSPL to pakiet zawierający plik XML oraz zestaw CSV. Pliki CSV to proste tabele zawierające dane zbioru danych. Plik XML opisuje metadane zbioru danych, obejmujące metadane informacyjne, takie jak opisy wskaźników, a także metadane strukturalne, takie jak odwołania między tabelami. Metadane którzy nie są doświadczeni, przeglądają i wizualizują Twoje dane.
Jedynym warunkiem wstępnym do zrozumienia tego samouczka jest dobry poziom języka XML. Pewna znajomość prostych pojęć związanych z bazami danych (np. (tabele, klucze podstawowe) może pomóc, ale nie jest to wymagane. Dla porównania kompletny plik XML oraz kompletny zbiór danych pakiet powiązany z tym samouczkiem jest również dostępny do sprawdzenia.
Omówienie
Zanim zaczniesz tworzyć zbiór danych, zapoznaj się z ogólnym omówieniem tego, co zawiera zbiór danych DSPL:
- Informacje ogólne: informacje o zbiorze danych.
- Pojęcia: definicje „rzeczy”. które mogą pojawić się w zbiorze danych (np. kraje, stopa bezrobocia, płeć, etc.)
- Wycinki: kombinacje pojęć, w przypadku których występują dane
- Tabele: dane dla pojęć i wycinków. Tabele koncepcyjne blokady wyliczeń, a tabele wycinków zawierają dane statystyczne
- Tematy: służą do porządkowania koncepcji zbioru danych. w istotną hierarchię dzięki etykietowaniu
Aby zilustrować te dość abstrakcyjne pojęcia, przeanalizuj zbiór danych (z fikcyjnych danych), używanych w tym samouczku: statystyczne ciągi czasowe dla populacja i bezrobocie, agregowane według różnych kombinacji kraju, stan w USA, płeć;
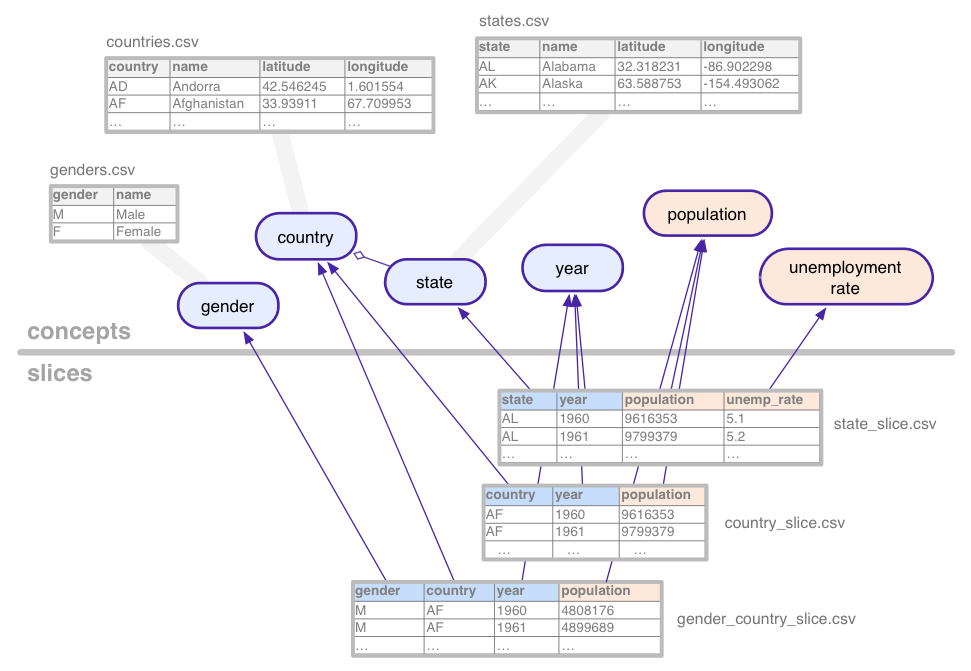
Ten przykładowy zbiór danych definiuje te koncepcje:
- country
- płeć
- populacja
- stan
- stopa bezrobocia
- rok
Pojęcia kategoryczne, takie jak stan, są powiązane z koncepcją tabele, które wyliczają wszystkie możliwe wartości (Kalifornia, Arizona itp.). Pojęcia mogą zawierać dodatkowe kolumny właściwości, takich jak nazwa lub kraj stanu.
Wycinki definiują każdą kombinację pojęć, dla których
do danych statystycznych. Wycinek zawiera wymiary i
danych. Na powyższej ilustracji wymiary są niebieskie,
są pomarańczowe. W tym przykładzie wycinek
gender_country_slice zawiera dane tego typu
population i wymiary country,
year i gender. Kolejny wycinek,
country_slice daje łączne roczne dane o populacji (dane) dla
krajów.
Poza wymiarami i danymi wycinki odnoszą się również do tabele, które zawierają rzeczywiste dane.
Przyjrzyjmy się teraz krok po kroku tworzenia takiego zbioru danych w DSPL.
Informacje o zbiorze danych
Najpierw musimy utworzyć plik XML dla naszego zbioru danych. Oto początek opisu DSPL dla przykładowego zbioru danych:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
Opis zbioru danych zaczyna się od atrybutu <dspl> najwyższego poziomu
. Atrybut targetNamespace zawiera identyfikator URI, który
jednoznacznie identyfikuje ten zbiór danych. Przestrzeń nazw zbioru danych jest szczególnie
ważne przy publikowaniu zbioru danych, bo będzie to globalny identyfikator
oraz sposoby, w jakie inni mogą się do niego odwoływać.
Pamiętaj, że atrybut targetNamespace może zostać pominięty. W
W tym przypadku, gdy zbiór danych zostanie automatycznie wygenerowany,
.
Korzystanie z informacji z innych zbiorów danych
Zbiory danych mogą korzystać z definicji i danych z innych zbiorów danych, importując
dla tych zbiorów danych. Każdy element <import> określa
przestrzeni nazw innego zbioru danych, do którego będzie się odwoływać ten zbiór danych.
W naszym przykładowym zbiorze danych potrzebujemy definicji z http://www.google.com/publicdata/dataset/google/quantity. (zbiór danych utworzony przez Google, który zawiera koncepcje przydatne do zdefiniowania wielkości liczbowych) oraz ze zbiorów danych time, entity i geo, które udostępniają odpowiednio do czasu, jednostek i danych geograficznych.
Górny element <dspl> zawiera prefiks przestrzeni nazw
(np. xmlns:time="http://...") za każdą
zaimportowanych zbiorów danych. Aby się odwołać, wymagane są deklaracje prefiksów
elementów z innych zbiorów danych w zwięzły sposób. Przykład:
Funkcja time:year odwołuje się do definicji słowa year w
zaimportowany zbiór danych, którego przestrzeń nazw jest powiązana z prefiksem
time
Informacje o zbiorze danych i dostawcy
Element <info> zawiera ogólne informacje o:
zbiór danych: nazwa, opis i adres URL, pod którym można znaleźć więcej informacji;
.
Element <provider> zawiera informacje o parametrach
dostawca zbioru danych: jego nazwa i adres URL, pod którym można znaleźć więcej informacji
(zwykle jest to strona główna dostawcy danych).
Definiowanie pojęć
Teraz, gdy już znamy ogólne informacje o zbiorze danych, możemy zacząć definiować jej treść. Naszym następnym celem jest dodanie statystyki populacji krajów za ostatnie 50 lat.
Najpierw musimy podać definicje pojęć danych o populacji, kraju i roku. W DSPL definicje te są nazywane pojęcia.
Pojęcie to definicja typu danych pojawiających się w w gromadzeniu danych. Wartości danych odpowiadające danej koncepcji nazywamy przykładów tej koncepcji.
Populacja
Zacznijmy od zdefiniowania koncepcji populacji. W
Dokument DSPL, koncepcje są zdefiniowane w polu <concepts>
który znajduje się zaraz za informacjami o zbiorze danych i dostawcy.
Oto pojęcie populacji z minimalną ilością informacji
dla dowolnego elementu: id (unikalny identyfikator), name i
type
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
Oto jak działa ten przykładowy kod:
- Każdy element koncepcyjny musi zawierać atrybut
id, który jednoznacznie identyfikuje w obrębie zbioru danych. Oznacza to, że żadne dwa pojęcia zdefiniowane w ten sam zbiór danych może mieć taki sam identyfikator. - Tak jak w przypadku zbioru danych i jego dostawcy
Elementy
<info>zawierają informacje tekstowe takie jak nazwa i opis. - Element
<type>określa typ danych dla funkcji przypadków koncepcji (czyli jej „wartości”). W tym przykładziepopulationtointegerDSPL obsługuje następujące typy danych:stringintegerfloatbooleandate
Kraj
Wpiszmy teraz definicję pojęcia kraju:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
Definicja koncepcji kraju zaczyna się tak jak poprzednia,
z id, info i type.
Wartości koncepcyjne
Pojęcia kategorialne, takie jak kraje, obejmują wszystkie możliwe
instancji. Innymi słowy, można wymienić wszystkie możliwe kraje, w których
wymienionych. Aby było to możliwe, każdy kraj musi mieć unikalny identyfikator.
W tym przykładzie użyto
kody krajów ISO do identyfikacji krajów; Te kody są
typu string.
W tym przykładzie nie trzeba używać kodu ISO. Ty równie dobrze można użyć nazwy kraju. Nazwy różnią się w zależności od języka, mogą się zmieniać z czasem i nie zawsze są używane w zbiorach danych w sposób spójny. W przypadku krajów i ogólnie pojęć kategorialnych ćwiczą wybieranie, krótkie, stabilne, powszechnie używane i niezależne od języka identyfikatory (jeśli istnieją).
Właściwości koncepcji
Oprócz id, koncepcja kraju ma też
<property> – element określający nazwę kraju.
Innymi słowy, nazwa kraju („Irlandia”) oznacza usługę
kraju, w którym obowiązuje id IE. DSPL udostępnia właściwości
dodatkowe uporządkowane informacje na temat wystąpień danego koncepcji.
Tak jak sama koncepcja, właściwości mają atrybut id,
info i type.
Dane koncepcji
Pojęcie „country” również zawiera element <table>.
Ten element odwołuje się do tabeli, która zawiera listę wszystkich
krajów.
Korzystanie z tabel ma sens w przypadku niektórych pojęć, ale nie w przypadku innych. Dla: na przykład nie ma sensu wyliczanie wszystkich możliwych wartości dla argumentu całej populacji koncepcji. Jeśli jednak spojrzysz na tabelę zawierającą zagadnienie, tabela musi zawierać wszystkie jego wystąpienia, na przykład musi uwzględniać każdy kraj, a nie tylko kilka przykładów.
Zbiór danych definiuje tabelę countries_table w ten sposób:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
Tabela krajów określa kolumny tabeli i ich typy,
i odwołuje się do pliku CSV zawierającego dane. Ten plik CSV może być
zawarte w pakiecie i przesyłane razem ze zbiorem danych w formacie XML lub dostępne zdalnie przez HTTP, HTTPS,
lub FTP. W tych ostatnich przypadkach zamienisz countries.csv na
adres URL, np. http://www.myserver.com/mydata/countries.csv.
Bez względu na to, gdzie jest przechowywany, plik CSV wygląda tak:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
Pierwszy wiersz tabeli zawiera identyfikatory kolumn podane w DSPL.
table – definicja. Każdy z poniższych wierszy odpowiada jednemu
przykład koncepcji kraju. Jeśli pojęcie ma tabelę,
tabela musi zawierać wszystkie wystąpienia koncepcji w tym
musi zawierać listę wszystkich krajów.
Kolumny są mapowane do koncepcji kraju i jego właściwości na podstawie
identyfikator. Identyfikator pierwszej kolumny, country, odpowiada koncepcji
id. Oznacza to, że ta kolumna zawiera unikalny identyfikator kraju.
jest koncepcja kraju. Następna kolumna odpowiada
właściwość name reprezentującą koncepcję kraju. Wartości
są zgodne z wartościami właściwości name.
Jest kilka wymagań dotyczących danych CSV związanych z tabelą pojęć:
- Nagłówki kolumn w pierwszym wierszu pliku danych muszą
dokładnie pasują do pojęcia
idi właściwościidkoncepcji, z którą są powiązane dane (chociaż kolejność może być inna). - Każdy wiersz musi zawierać dokładnie taką samą liczbę elementów, jak liczba właściwości (nawet jeśli wartość jest pusta).
- Każda wartość w polu
idkoncepcji (w tym miejscu kodu kraju) musi być niepowtarzalny i nie może być pusty (puste pole to jedno z zero lub tylko spacje). - Wartości właściwości, które odwołują się do innych pojęć, muszą być: puste lub być prawidłową wartością odniesienia.
- Wartości zawierające przecinki, podwójne cudzysłowy lub znaki nowego wiersza muszą być: umieszczone w podwójnym cudzysłowie.
- Wszystkie znaki cudzysłowu w cudzysłowie prostym w wartości muszą być natychmiast poprzedza kolejny cudzysłów podwójny.
Rok
Ostatnią koncepcją, jakiej potrzebujemy w przypadku danych dotyczących populacji danego kraju, jest koncepcja
reprezentują lata. Zamiast definiować nową koncepcję użyjemy funkcji
koncepcja roku z jednego z zaimportowanych przez nas zbiorów danych:
"http://www.google.com/publicdata/dataset/google/time". Aby to zrobić:
musisz go użyć jako time:year, gdzie time
reprezentuje zbiór danych, do którego odwołuje się zbiór, a year identyfikuje
nad koncepcją.
Pojęcia kanoniczne
time:year to część niewielkiego zestawu koncepcji kanonicznych.
zdefiniowane przez Google. Koncepcje kanoniczne zawierają podstawowe definicje czasu,
geografia, wielkości liczbowe, jednostki itp.
W rzeczywistości zdefiniowana powyżej koncepcja kraju istnieje
koncepcja kanoniczna. Stworzyliśmy je wyłącznie w celach ilustracyjnych.
W miarę możliwości używaj w zbiorach danych koncepcji kanonicznych.
bezpośrednio lub przez rozszerzenie (więcej informacji o rozszerzeniu znajdziesz poniżej). Pojęcia kanoniczne
porównywać dane z innymi zbiorami danych i korzystać z funkcji
na zbiorach danych w narzędziu Public Data Explorer. Na przykład animowanie danych w czasie
lub wyświetlanie danych geograficznych na mapie korzysta z interfejsów time i
geo – odpowiednio koncepcje kanoniczne.
Pierwszy wycinek
Mamy już pojęcia dotyczące populacji, kraju i roku. Nadszedł czas, aby je połączyć.
W tym celu musimy utworzyć wycinek, który będzie je łączyć. W DSPL wycinek to połączenie koncepcji, dla których istnieją dane.
Dlaczego nie wystarczy utworzyć tabeli z odpowiednimi kolumnami? Wycinki przechwytują i koncepcję informacji w zbiorze danych. Będzie to gdy będziemy tworzyć więcej zbiorów danych.
Wycinki są widoczne w pliku DSPL w obszarze <slices>
który musi występować zaraz za sekcją concepts.
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices>Podobnie jak koncepcje, każdy wycinek ma id
(countries_slice), który jednoznacznie identyfikuje wycinek w kolumnie
w gromadzeniu danych.
Wycinek zawiera 2 rodzaje odwołań do pojęć: Wymiary i
danych. Wartości danych różnią się w zależności od wartości
wymiarów. W tym przypadku wartość population (dane) zmienia się o
wymiary country i year.
Podobnie jak koncepcje, wycinki zawierają odwołanie do tabeli, która zawiera dane wycinka. Wskazana tabela musi mieć 1 kolumnę dla wszystkich wymiarów i danych wycinka. Podobnie jak w przypadku koncepcji, wycinek wymiary i dane są mapowane na kolumny tabeli o tych samych identyfikatorach.
Tabela wycinków
Tabela dla naszego wycinka populacji znajduje się w: tables
pliku DSPL:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
Zwróć uwagę, że kolumna year zawiera format
Atrybut, który określa format lat. Obsługiwane formaty daty to
te zdefiniowane w formacie Joda DateTime.
Tabela countries_slice określa kolumny tabeli oraz
różnych typów i wskazuje plik CSV z danymi. Plik CSV
wygląda tak:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
Każdy wiersz tabeli danych zawiera unikalną kombinację wymiarów
country i year wraz z odpowiednią wartością
danych population (np. populacja –
dane – o Afganistanie w roku 1960 – wymiary).
Zauważ, że wartości w kolumnie country odpowiadają
wartość/identyfikator funkcji country, która jest zgodna z normą ISO 3166
Dwuliterowy kod kraju.
Dane CSV dotyczące wycinka muszą spełniać te ograniczenia:
- Każda wartość w polu wymiaru (np.
countryiyear) nie może być pusty. Wartości w polach danych (takich jakpopulation) może być puste. Pusta wartość jest przedstawiona jako nie znaków. - Każda wartość pola wymiaru, która odwołuje się do danej koncepcji, musi być
w danych dotyczących tej koncepcji. Na przykład wartość
AFmusi znajdować się w tabeli danych o koncepcjachcountry. - Każda unikalna kombinacja wartości wymiarów, np.
AF, 2000, może wystąpić tylko raz. - Dane należy sortować według kolumn wymiarów innych niż czasowe (w dowolnej kolejności),
a następnie, opcjonalnie, przez dowolną inną kolumnę. Na przykład:
w tabeli z kolumnami
[date, dimension1, dimension2, metric1, metric2]możesz sortować wedługdimension1, potemdimension2, a następniedate, ale nie przezdatei wymiary.
Podsumowanie
Mamy już dość informacji w naszej DSPL, by opisać kraj dane o populacji. Podsumowując, musieliśmy:
- Tworzenie nagłówka DSPL i opisu zbioru danych oraz jego świadczeniodawca
- Należy utworzyć jedną koncepcję dotyczącą populacji, a drugą dotyczącą kraju, za pomocą csv z listą wszystkich krajów i ich nazwami.
- Utwórz wycinek z danymi o populacji krajów w czasie, odwołując się do zdefiniowanej już koncepcji roku w zaimportowanym zbiorze danych czasowych od Google.
W dalszej części tego samouczka powiększymy nasz zbiór danych o dodając więcej wymiarów w większej liczbie wycinków, a także więcej danych pogrupowanych według temat.
Dodawanie wymiaru: Stany Zjednoczone
Wzbogaćmy teraz nasz zbiór danych, dodając dane o populacji stanów w Stanach Zjednoczonych. Najpierw musimy zdefiniować pojęcie dla stanów. Wygląda to bardzo jak koncepcja kraju, którą zdefiniowaliśmy wcześniej.
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>Rozszerzenia i właściwość koncepcyjna referencje
Koncepcja stanu wprowadza kilka nowych funkcji DSPL.
Po pierwsze, stan rozszerza inną koncepcję,
geo:location (zdefiniowany w zewnętrznym zbiorze danych geograficznych, który
zaimportowane na początku zbioru danych). Z semantycznego punktu widzenia oznacza to,
state to rodzaj geo:location. Konsekwencją jest
że dziedziczy wszystkie atrybuty i właściwości
geo:location Konkretnie lokalizacja definiuje właściwości
latitude i longitude; przedłużając stary termin
koncepcja ta ma również zastosowanie do stanu. Ponadto, ponieważ
lokalizacja dziedziczy z: entity:entity, stan otrzymuje również
wszystkich tych ostatnich, w tym name,
description i info_url.
Uwaga: pojęcie kraju zdefiniowano wcześniej.
technicznie powinien być także przedłużony z geo:location.
Ten punkt został wcześniej pominięty dla uproszczenia. uwzględniliśmy
w przypadku dziedziczenia zależnego od lokalizacji,
final XML.
Uwaga: możesz użyć tagu extends
tworzyć własne zbiory danych w celu ponownego wykorzystania informacji zdefiniowanych w innych zbiorach danych.
Użycie właściwości extends wymaga, aby wszystkie wystąpienia koncepcji były
prawidłowe wystąpienia koncepcji, którą rozszerzasz. Rozszerzenia umożliwiają dodawanie
właściwości i atrybuty oraz ogranicz zbiór instancji do
podzbioru instancji rozszerzonej koncepcji.
Oprócz dziedziczenia właściwość stanowa wprowadza również
koncepcji referencji.
W szczególności pojęcie stanu ma właściwość o nazwie country,
który odwołuje się do koncepcji kraju, którą omówiliśmy powyżej. Robi to:
za pomocą atrybutu concept. Pamiętaj, że ta właściwość nie
podasz identyfikator, tylko odwołanie do pojęcia. Jest to odpowiednik utworzenia identyfikatora
z tą samą wartością co identyfikator wskazanego pojęcia (np.
country). Relacja hierarchiczna między
województwo i hrabstwo są określane za pomocą atrybutu
isParent="true" w pliku referencyjnym. Ogólnie rzecz biorąc,
hierarchiczne, takie jak wymiary geograficzne,
w ten sposób, a koncepcja podrzędna ma właściwość,
odwołuje się do elementu nadrzędnego za pomocą atrybutu isParent.
Definicja tabeli dla stanów wygląda tak:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
Kolumna „Kraj” zawiera stałą wartość dla wszystkich województw. Określanie
DSPL zapobiega powtarzaniu tej wartości w przypadku każdego stanu w danych. Pamiętaj też o tym
że uwzględniliśmy kolumny name, latitude i
longitude, ponieważ stan odziedziczył te właściwości z:
geo:location Z drugiej strony niektóre dziedziczone usługi
(np. description) nie ma kolumn; w porządku-
Jeśli właściwość jest pominięta w tabeli definicji pojęć, jej wartość wynosi
jako niezdefiniowane dla każdego wystąpienia koncepcji.
Plik CSV wygląda tak:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
Mamy już koncepcje dotyczące populacji i roku, więc możemy je wykorzystać ponownie. aby zdefiniować nowy wycinek dla populacji stanów.
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>Definicja tabeli danych wygląda tak:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
A plik CSV wygląda tak:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
Dlaczego utworzyliśmy nowy wycinek zamiast dodać kolejny do poprzedniego wymiaru?
Wycinek z wymiarami zarówno dla województwa, jak i kraju byłby nieprawidłowy, bo niektóre wiersze będą zawierały dane kraju, a inne stanowe. i skalowalnych danych. Tabela będzie miała „dziury” dla niektórych wymiarów, niedozwolone (pamiętaj, że brakujące wartości są dozwolone tylko w przypadku danych i nie wymiarów).
Wymiary pełnią funkcję „klucza podstawowego” danego kawałka. Oznacza to, że każdy wiersz danych musi mieć wartości dla wszystkich wymiarów, ale nie może mieć dwóch wierszy danych mogą mieć identyczne wartości dla wszystkich wymiarów.
Dodawanie wartości: Bezrobocie Oceń
Dodajmy teraz kolejne dane do naszego zbioru danych:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
Sekcja info tych danych ma nazwę, opis i
Adres URL (link do amerykańskiego Biura Statystyki Pracy).
Ta koncepcja rozszerza także koncepcję kanoniczną quantity:rate.
Argument ilość
zbiór danych definiuje podstawowe pojęcia związane z reprezentowaniem wielkości liczbowych. W
należy tworzyć koncepcje liczbowe, rozszerzając
odpowiednią ilość informacji. Dlatego koncepcja population
zdefiniowano powyżej powinien być technicznie przedłużony
quantity:amount
Atrybuty koncepcji
Ta koncepcja zawiera też wprowadzenie do konstrukcji atrybutu. W
w tym przykładzie atrybut wskazuje, że unemployment_rate
jest wartością procentową. Atrybut is_percentage jest dziedziczony z
quantity:rate, który jest rozwinięciem tej koncepcji. Ten
używane przez Eksploratora danych publicznych do pokazywania znaków procentowych,
dzięki wizualizacji danych.
Atrybuty zapewniają ogólny mechanizm dołączania par klucz/wartość do
pojęcie (w przeciwieństwie do właściwości, które wiążą dodatkowe wartości z
wystąpienia koncepcji). Podobnie jak koncepcje i właściwości,
atrybuty mają id, info oraz
type Podobnie jak właściwości, mogą się odwoływać do innych koncepcji.
Atrybuty nie służą tylko do zdefiniowanych ogólnych rzeczy, takich jak wartości liczbowe usług. Możesz definiować własne atrybuty koncepcji.
Dodawanie danych o stopie bezrobocia w USA Stany
Jesteśmy teraz gotowi dodać dane o stopie bezrobocia w stanach USA. Ponieważ stopa bezrobocia to jeden z tych wskaźników, a mamy już dane o populacji stanów, możemy po prostu dodać go do wycinka, który już utworzyliśmy dla stanu i roku wymiary:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... i dodasz kolejną kolumnę do definicji tabeli:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... i do pliku CSV:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
Mówiliśmy wcześniej, że dla każdego wycinka wymiary tworzą klucz podstawowy danego kawałka. Dodatkowo każdy zbiór danych może zawierać tylko jeden wycinek dla dla danej kombinacji wymiarów. Wszystkie dane dostępne dla tych muszą należeć do tego samego wycinka.
Więcej wymiarów: podział populacji według płci
Wzbogaćmy nasz zbiór danych o podział populacji według płci krajów. Wiesz już, co i jak... Najpierw musimy dodaj pojęcie płci:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
Sekcja Pojęcie płci info zawiera
pluralName zawiera tekst, który będzie używany w odniesieniu do odwołania
wiele przykładów koncepcji płci. Sekcja info też
zawiera element totalName, który zawiera tekst służący do
odnosi się do wszystkich przykładów
koncepcji płci w całości. Oba te elementy są
używane przez Public Data Explorer do wyświetlania informacji o płci
koncepcją działania. Ogólnie rzecz biorąc, należy je przedstawiać w przypadku koncepcji, które można wykorzystać jako
wymiarów.
Zwróć uwagę, że pojęcie płci rozciąga się również
entity:entity Jest to dobre rozwiązanie w przypadku koncepcji
które służą jako wymiary, ponieważ umożliwiają dodawanie niestandardowych nazw.
Adresy URL i kolory poszczególnych instancji koncepcyjnych.
Termin „płeć” odnosi się do tabeli genders_table, która
zawiera możliwe wartości atrybutu płeć i ich wyświetlane nazwy
(pominięto tutaj).
Aby dodać do zbioru danych populację według płci, musimy utworzyć nowy wycinek (pamiętaj: każda dostępna kombinacja wymiarów odpowiada wycinkowi w zbioru danych).
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
Definicja tabeli wycinka wygląda tak:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
Plik CSV tabeli wygląda tak:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
W porównaniu z poprzednimi krajami, populacją i bezrobociem wycinkiem ma dodatkowy wymiar, każda wartość metryki populacji odpowiada nie tylko krajowi i rokowi, ale także dla konkretnej płci.
Utworzyliśmy „rozproszony”, w gromadzeniu danych. Nie wszystkie Dane są dostępne dla wszystkich wymiarów: populacja jest dostępna w krajach i stanach USA (rocznie), podczas gdy stawka jest dostępna tylko w przypadku krajów. Dostępny jest podział według płci tylko dane dotyczące populacji według kraju; nie jest dostępny dla stopy bezrobocia danych, a nie dla wymiaru stanu. Rozbieżności w danych mogą też występować a pewne dane nie mają żadnych wartości wymiarów, ale nie jest reprezentowane w DSPL.
Tematy
Ostatnią funkcją DSPL, której użyjemy w naszym zbiorze danych, będą tematy. Tematy służą do hierarchicznego klasyfikowania koncepcji. Są również używane przez dzięki którym użytkownicy mogą łatwiej znajdować dane.
W pliku DSPL tematy pojawiają się tuż przed pojęciami. Oto przykład hierarchia tematów:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>Tematy możesz zagnieżdżać odpowiednio do potrzeb.
Aby korzystać z tematów, musisz odwoływać się do nich od koncepcji w następujący sposób:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
Jeden temat może odnosić się do więcej niż jednego tematu.
Przesyłanie zbioru danych
Kolejnym krokiem po utworzeniu zbioru danych jest skompresowanie go prześlij plik ZIP do za pomocą narzędzia Google Public Data Explorer. W razie problemów sprawdź odpowiedzi na najczęstsze pytania, które zawierają omówienie o najczęstszych problemach z przesyłaniem.
Możesz też pobrać kompletny plik XML i pełny pakiet zbiorów danych. powiązane z tym samouczkiem.
Co dalej
Gratulujemy utworzenia pierwszego zbioru danych DSPL. Gdy już zalecamy zapoznanie się z podstawowymi informacjami, zapoznaj się z Przewodnikiem dla programistów, w którym między innymi „zaawansowane” dokumenty Funkcje DSPL takie jak obsługę wielu języków i koncepcje możliwe do mapowania.
Możesz także zapoznać się z innymi przykładowymi zbiorami danych.