DSPL означает язык публикации наборов данных. Наборы данных, описанные в DSPL, можно импортировать в Google Public Data Explorer — инструмент, позволяющий проводить богатое визуальное исследование данных.
Примечание. Чтобы загрузить данные в общедоступные данные Google с помощью инструмента загрузки общедоступных данных , у вас должен быть аккаунт Google .
В этом руководстве представлен пошаговый пример подготовки базового набора данных DSPL.
Набор данных DSPL — это пакет , содержащий файл XML и набор файлов CSV. Файлы CSV представляют собой простые таблицы, содержащие данные набора данных. Файл XML описывает метаданные набора данных, включая информационные метаданные, такие как описания мер, а также структурные метаданные, такие как ссылки между таблицами. Метаданные позволяют неопытным пользователям исследовать и визуализировать ваши данные.
Единственным необходимым условием для понимания этого руководства является хороший уровень понимания XML. Некоторое понимание простых концепций баз данных (например, таблиц, первичных ключей) может помочь, но это не обязательно. Для справки: готовый XML-файл и полный пакет набора данных, связанные с этим руководством, также доступны для просмотра.
Обзор
Прежде чем приступить к созданию нашего набора данных, вот общий обзор того, что содержит набор данных DSPL:
- Общая информация: О наборе данных
- Концепции: определения «вещей», которые появляются в наборе данных (например, страны, уровень безработицы, пол и т. д.).
- Срезы: комбинации концепций, для которых имеются данные.
- Таблицы: данные для концепций и срезов. Таблицы понятий содержат перечисления, а таблицы срезов — статистические данные.
- Темы: используется для организации понятий набора данных в содержательную иерархию посредством маркировки.
Чтобы проиллюстрировать эти довольно абстрактные понятия, рассмотрим набор данных (с фиктивными данными), используемый в этом руководстве: статистические временные ряды по численности населения и безработице, агрегированные по различным комбинациям стран, штатов США и пола.
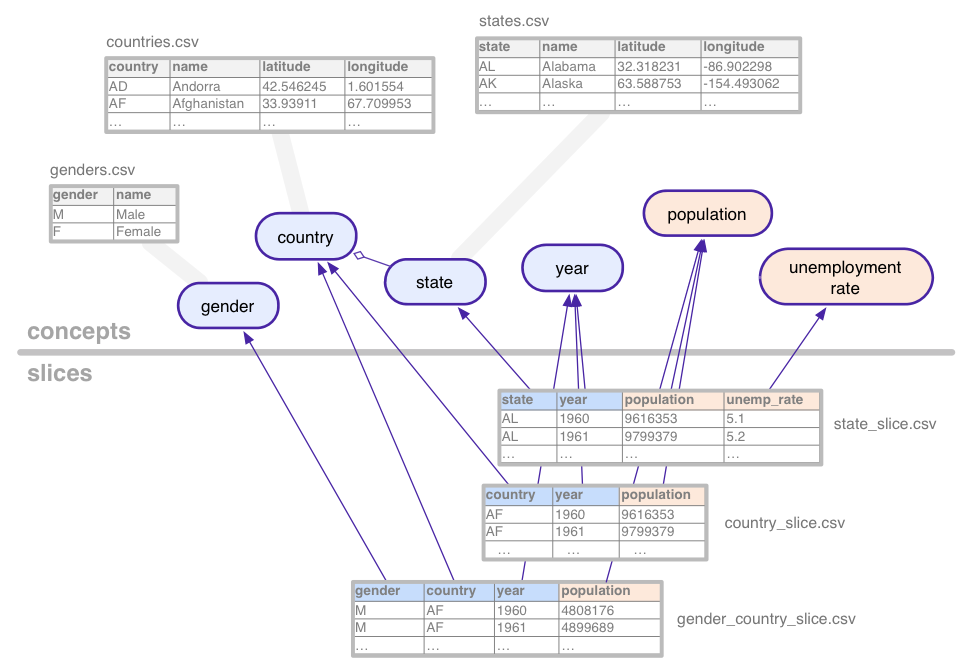
В этом примере набора данных определены следующие понятия :
- страна
- пол
- население
- состояние
- уровень безработицы
- год
Категориальные понятия, такие как состояние, связаны с таблицами понятий, в которых перечислены все их возможные значения (Калифорния, Аризона и т. д.). Концепции могут иметь дополнительные столбцы для таких свойств, как название или страна штата.
Срезы определяют каждую комбинацию понятий, для которых в наборе данных есть статистические данные. Срез содержит измерения и метрики . На рисунке выше размеры выделены синим цветом, а показатели — оранжевым. В этом примере срез gender_country_slice содержит данные для метрики population и измерений country , year и gender . Другой срез, называемый country_slice , дает общую годовую численность населения (показатель) для стран.
Помимо параметров и показателей, срезы также ссылаются на таблицы , содержащие фактические данные.
Давайте теперь шаг за шагом пройдемся по созданию такого набора данных в DSPL.
Информация о наборе данных
Для начала нам нужно создать XML-файл для нашего набора данных. Вот начало описания DSPL для нашего примера набора данных:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
Описание набора данных начинается с элемента <dspl> верхнего уровня. Атрибут targetNamespace содержит URI, который уникально идентифицирует этот набор данных. Пространство имен набора данных особенно важно при публикации набора данных, поскольку оно будет глобальным идентификатором вашего набора данных и средством, с помощью которого другие могут ссылаться на него.
Обратите внимание, что атрибут targetNamespace можно опустить. В этом случае уникальное пространство имен автоматически генерируется при импорте набора данных.
Использование информации из других наборов данных
Наборы данных могут повторно использовать определения и данные из других наборов данных путем импорта этих наборов данных. Каждый элемент <import> указывает пространство имен другого набора данных, на который будет ссылаться этот набор данных.
В нашем примере набора данных нам потребуются некоторые определения из http://www.google.com/publicdata/dataset/google/quantity (набора данных, созданного Google и содержащего понятия, полезные для определения числовых величин), а также с того момента , как объект и наборы географических данных, которые предоставляют определения, связанные со временем, объектами и географией соответственно.
Верхний элемент <dspl> предоставляет объявление префикса пространства имен (например, xmlns:time="http://..." ) для каждого из импортированных наборов данных. Объявления префиксов необходимы для краткой ссылки на элементы из других наборов данных. Например, time:year ссылается на определение year в импортированном наборе данных, пространство имен которого связано с префиксом time .
Информация о наборе данных и поставщике
Элемент <info> содержит общую информацию о наборе данных: имя, описание и URL-адрес, по которому можно найти дополнительную информацию.
Элемент <provider> содержит информацию о поставщике набора данных: его имя и URL-адрес, по которому можно найти дополнительную информацию (обычно домашняя страница поставщика данных).
Определение концепций
Теперь, когда мы предоставили некоторую общую информацию о наборе данных, мы готовы приступить к определению его содержимого. Наша следующая цель — добавить статистику населения по странам за последние 50 лет.
Первое, что нам нужно сделать, это дать некоторые определения понятиям населения, страны и года. В DSPL эти определения называются понятиями .
Концепция — это определение типа данных, которые появляются в наборе данных. Значения данных, соответствующие данному понятию, называются экземплярами этого понятия.
Население
Начнем с определения понятия народонаселения. В документе DSPL концепции определяются в элементе <concepts> , который идет сразу после информации о наборе данных и поставщике.
Вот концепция популяции с минимальной информацией, необходимой для любой концепции: id (уникальный идентификатор), name и type .
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
Вот как работает этот образец:
- Каждая концепция должна иметь
id, который однозначно идентифицирует концепцию в наборе данных. Это означает, что никакие два понятия, определенные в одном наборе данных, не могут иметь одинаковый идентификатор. - Как и в случае с набором данных и его поставщиком, элементы
<info>предоставляют текстовую информацию о концепции, например ее имя и описание. - Элемент
<type>определяет тип данных для экземпляров понятия (другими словами, его «значения»). В этом примере типpopulation—integer. DSPL поддерживает следующие типы данных:-
string -
integer -
float -
boolean -
date
-
Страна
Давайте теперь напишем определение понятия страна:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
Определение понятия страны начинается, как и предыдущее, с id , info и type .
Концептуальные ценности
Категориальные понятия, такие как страны, перечисляют все возможные случаи. Другими словами, вы можете перечислить все возможные страны, на которые можно ссылаться. Но для этого каждой стране нужен уникальный идентификатор. В этом примере для идентификации стран используются коды стран ISO ; эти коды имеют тип string .
В этом примере вам не нужно использовать код ISO; с тем же успехом вы могли бы использовать название страны. Однако имена различаются в зависимости от языка, могут меняться со временем и не всегда последовательно используются в разных наборах данных. Для стран и для категориальных понятий в целом рекомендуется выбирать короткие, стабильные, широко используемые и независимые от языка идентификаторы (если они существуют).
Свойства концепции
Помимо id , концепция страны имеет элемент <property> , который определяет название страны. Другими словами, название страны («Ирландия») является собственностью страны с id IE. Свойства — это то, как DSPL предоставляет дополнительную структурированную информацию об экземплярах понятия.
Как и сама концепция, свойства имеют id , info и type .
Концептуальные данные
Наконец, концепция страны имеет элемент <table> . Этот элемент ссылается на таблицу, в которой перечислен список всех стран.
Использование таблиц имеет смысл для некоторых концепций, но не для других. Например, нет смысла перечислять все возможные значения совокупности концептов. Однако если вы ссылаетесь на таблицу для концепции, эта таблица должна содержать все экземпляры концепции — например, в ней должна быть указана каждая страна, а не только несколько примеров.
Набор данных определяет countries_table следующим образом:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
Таблица стран определяет столбцы таблицы и их типы, а также ссылается на файл CSV, содержащий данные. Этот CSV-файл можно либо связать и загрузить вместе с XML-набором данных, либо получить к нему удаленный доступ через HTTP, HTTPS или FTP. В последних случаях вы должны заменить countries.csv URL-адресом, например http://www.myserver.com/mydata/countries.csv .
Где бы он ни хранился, файл CSV выглядит так:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
В первой строке таблицы перечислены идентификаторы столбцов, как указано в определении table DSPL. Каждая из следующих строк соответствует одному экземпляру концепции страны. Если у концепции есть таблица, то она должна содержать все экземпляры концепции — в этом случае она должна содержать список всех стран.
Столбцы сопоставляются с концепцией страны и ее свойствами на основе их идентификатора. Идентификатор первого столбца, country , соответствует идентификатору концепции. Это означает, что этот столбец содержит уникальный идентификатор страны, определенный концепцией страны. Следующий столбец соответствует свойству name концепции страны. Значения в этом столбце соответствуют значениям свойства name .
Существует несколько требований к данным CSV для таблицы концепций:
- Заголовки столбцов в первой строке файла данных должны точно соответствовать
idпонятия иidсвойства понятия, с которым связаны данные (хотя порядок может меняться). - Каждая строка должна содержать точно такое же количество элементов, как и количество свойств концепции (даже если значение пустое).
- Каждое значение поля
idконцепции (здесь код страны) должно быть уникальным и непустым (пустым полем считается поле, содержащее ноль или только пробельные символы). - Значения свойств, ссылающихся на другие понятия, должны быть либо пустыми, либо быть допустимыми значениями ссылочного понятия.
- Значения, содержащие запятые, двойные кавычки или символы новой строки, должны быть полностью заключены в двойные кавычки.
- Любым буквальным символам двойной кавычки внутри значения должна непосредственно предшествовать другая двойная кавычка.
Год
Последнее понятие, которое нам нужно для данных о населении нашей страны, — это понятие, представляющее годы. Вместо определения новой концепции мы будем использовать концепцию года из одного из импортированных нами наборов данных: «http://www.google.com/publicdata/dataset/google/time». Для этого нам нужно сослаться на него как time:year , где time представляет набор данных, на который имеется ссылка, а year идентифицирует концепцию.
Канонические концепции
time:year является частью небольшого набора канонических понятий, определенных Google. Канонические концепции дают основные определения времени, географии, числовых величин, единиц и т. д.
Фактически, определенная выше концепция страны существует как каноническая концепция. Мы создали его здесь только в целях иллюстрации. По возможности вам следует использовать канонические концепции в своих наборах данных либо напрямую, либо путем их расширения (подробнее о расширении ниже). Концепции Canonical делают ваши данные сопоставимыми с другими наборами данных и включают функции для ваших наборов данных в Public Data Explorer. Например, анимация данных во времени или отображение географических данных на карте основаны на использовании time и geo концепций соответственно.
Первый кусочек
Теперь, когда у нас есть понятия о населении, стране и году, пришло время соединить их вместе!
Для этого нам нужно создать срез , который их объединит. В DSPL срез — это комбинация концепций, для которых существуют данные.
Почему бы просто не создать таблицу с правильными столбцами? Потому что срезы фиксируют информацию набора данных с точки зрения его концепций. Это станет яснее, когда мы создадим больше частей нашего набора данных.
Фрагменты отображаются в файле DSPL в элементе <slices> , который должен располагаться сразу после раздела concepts .
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices> Как и в случае с концепциями, каждый срез имеет id ( countries_slice ), который однозначно идентифицирует срез в наборе данных.
Срез содержит два типа ссылок на понятия: измерения и метрики . Значения метрик различаются в зависимости от значений измерений. Здесь значение population (показатель) варьируется в зависимости от country и year .
Как и концепты, срезы включают ссылку на таблицу , содержащую данные среза. В указанной таблице должен быть один столбец для каждого измерения и показателя среза. Как и в случае с понятиями, измерения и показатели среза сопоставляются со столбцами таблицы с одинаковыми идентификаторами.
Таблица срезов
Таблица для нашего среза населения появляется в разделе tables файла DSPL:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
Обратите внимание, что столбец year имеет атрибут format , который определяет формат года. Поддерживаемые форматы даты определяются форматом Joda DateTime .
Таблица countries_slice определяет столбцы таблицы и их типы, а также указывает на файл CSV, содержащий данные. CSV-файл выглядит следующим образом:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
Каждая строка таблицы данных содержит уникальную комбинацию измерений country и year , а также соответствующее значение показателя population (например, население – показатель – Афганистана в 1960 году – измерения ).
Обратите внимание, что значения в столбце country соответствуют значению/идентификатору понятия country , которое представляет собой двухбуквенный код страны по стандарту ISO 3166.
Данные CSV для среза должны удовлетворять следующим ограничениям:
- Каждое значение поля измерения (например,
countryиyear) не должно быть пустым. Значения полей показателей (например,population) могут быть пустыми. Пустое значение не представлено никакими символами. - Каждое значение поля измерения, которое ссылается на концепцию, должно присутствовать в данных этой концепции. Например, значение
AFдолжно присутствовать в таблице данных концепцииcountry. - Каждая уникальная комбинация значений измерений, например
AF, 2000, может встречаться только один раз. - Данные следует сортировать по столбцам невременных измерений (в любом порядке), а затем, при необходимости, по любому из других столбцов. Так, например, в таблице со столбцами
[date, dimension1, dimension2, metric1, metric2]вы можете сортировать поdimension1, затемdimension2, затем поdate, но не поdate, а затем по измерениям.
Краткое содержание
На данный момент в нашем DSPL достаточно данных для описания данных о населении страны. Подводя итог, нам нужно было сделать следующее:
- Создайте заголовок DSPL и описание набора данных и его поставщика.
- Создайте одну концепцию для населения и другую для страны, используя файл CSV, в котором будут перечислены все страны и их названия.
- Создайте срез с численностью населения по странам с течением времени, ссылаясь на уже определенную концепцию года в импортированном наборе временных данных из Google.
В оставшейся части этого руководства мы расширим наш набор данных, добавив больше измерений в большем количестве срезов, а также больше показателей, сгруппированных по темам.
Добавление измерения: штаты США
Давайте теперь обогатим наш набор данных, добавив данные о населении штатов США. Сначала нам нужно определить концепцию государств. Это очень похоже на концепцию страны, которую мы определили ранее.
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>Расширения концепций и ссылки на свойства
Концепция штата вводит несколько новых функций DSPL.
Во-первых, состояние расширяет другую концепцию — geo:location (определенную во внешнем наборе географических данных, который мы импортировали в начале нашего набора данных). Семантически это означает, что state — это своего рода geo:location . Следствием этого является то, что он наследует все атрибуты и свойства geo:location . В частности, location определяет свойства latitude и longitude ; расширяя первую концепцию, эти свойства применяются и к состоянию. Более того, поскольку location наследуется entity:entity ,state также получает все свойства последнего, включая name , description и info_url .
Примечание. Определенная ранее концепция страны должна технически распространяться и на geo:location . Ранее этот пункт был опущен для простоты; Однако мы включили местоположение для наследования страны в окончательный XML-файл .
Примечание. Вы можете использовать конструкцию extends в своих собственных наборах данных для повторного использования информации, определенной в других наборах данных. Использование extends требует, чтобы все экземпляры вашей концепции были допустимыми экземплярами расширяемой вами концепции. Расширения позволяют добавлять дополнительные свойства и атрибуты и ограничивать набор экземпляров подмножеством экземпляров расширенной концепции.
Помимо наследования, государственная собственность также вводит идею ссылок на понятия. В частности, у концепции штата есть свойство под названием country , которое ссылается на концепцию страны, которую мы создали выше. Это делается с помощью атрибута concept . Обратите внимание, что это свойство не предоставляет идентификатор, а только ссылку на концепцию. Это эквивалентно созданию идентификатора с тем же значением, что и идентификатор ссылочного понятия (т. е. country в этом примере). Иерархические отношения между штатом и округом фиксируются наличием атрибута isParent="true" в ссылке. В общем, измерения с иерархическими отношениями, такие как географические регионы, должны быть представлены таким образом, при этом дочернее понятие имеет свойство, которое ссылается на родительское понятие с помощью атрибута isParent .
Определение таблицы для состояний выглядит следующим образом:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
Столбец страны имеет постоянное значение для всех штатов. Указание его в DSPL позволяет избежать повторения этого значения для каждого состояния данных. Также обратите внимание, что мы включили столбцы для name , latitude и longitude поскольку состояние унаследовало эти свойства от geo:location . С другой стороны, некоторые унаследованные свойства (например, description ) не имеют столбцов; это нормально: если свойство опущено в таблице определения понятия, то его значение считается неопределенным для каждого экземпляра понятия.
CSV-файл выглядит следующим образом:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
Поскольку у нас уже есть концепции численности населения и года, мы можем повторно использовать их, чтобы определить новый срез населения штата.
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>Определение таблицы данных выглядит следующим образом:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
И CSV-файл выглядит так:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
Подождите, почему мы создали новый срез вместо того, чтобы добавить еще одно измерение к предыдущему?
Срез с измерениями как для штата, так и для страны будет неправильным, поскольку некоторые строки будут предназначены для данных о стране, а некоторые строки — для данных о штате. В таблице могут быть «дыры» для некоторых измерений, что недопустимо (помните, что пропущенные значения допускаются только для показателей, но не для измерений).
Размеры действуют как «первичный ключ» для среза. Это означает, что каждая строка данных должна иметь значения для всех измерений, и никакие две строки данных не могут иметь одинаковые значения для всех измерений.
Добавление показателя: уровень безработицы
Давайте теперь добавим еще одну метрику в наш набор данных:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
info раздел этого показателя имеет имя, описание и URL-адрес (ссылка на Бюро статистики труда США).
Эта концепция также расширяет каноническую концепцию quantity:rate . Набор количественных данных определяет основные концепции представления числовых величин. В вашем наборе данных вам следует создавать числовые концепции, расширяя соответствующую количественную концепцию. Таким образом, концепция population , определенная выше, технически должна была быть расширена из quantity:amount .
Атрибуты концепции
Эта концепция также вводит конструкцию атрибута . В этом примере атрибут используется, чтобы указать, что unemployment_rate представляет собой процент. Атрибут is_percentage унаследован от концепции quantity:rate , которую расширяет эта концепция. Эта информация используется Public Data Explorer для отображения знаков процента при визуализации данных.
Атрибуты предоставляют общий механизм прикрепления пар ключ/значение к концепции (в отличие от свойств, которые связывают дополнительные значения с экземплярами концепции). Как и понятия и свойства, атрибуты имеют id , info и type . Как и свойства, они могут ссылаться на другие понятия.
Атрибуты предназначены не только для предопределенных общих вещей, таких как числовые свойства. Вы можете определить свои собственные атрибуты для своих концепций.
Добавление данных об уровне безработицы для штатов США
Теперь мы готовы добавить данные об уровне безработицы в штатах США. Поскольку уровень безработицы является показателем, и у нас уже есть данные о населении штатов, мы можем просто добавить их к срезу, который мы уже создали для измерений штата и года:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... и добавьте еще один столбец в определение таблицы:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... и в файл CSV:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
Ранее мы говорили, что для каждого среза измерения образуют первичный ключ среза. Кроме того, каждый набор данных может содержать только один срез для заданной комбинации измерений. Все метрики, доступные для этих измерений, должны принадлежать одному и тому же срезу.
Дополнительные измерения: разбивка населения по полу
Давайте дополним наш набор данных разбивкой населения по полу по странам. К этому моменту вы уже начинаете понимать суть... Сначала нам нужно добавить понятие пола:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
Раздел info о гендерной концепции имеет pluralName , которое предоставляет текст, который будет использоваться для ссылки на несколько экземпляров гендерной концепции. Раздел info также включает в себя totalName , который предоставляет текст, который будет использоваться для ссылки на все экземпляры гендерной концепции в целом. Оба они используются Public Data Explorer для отображения информации, связанной с гендерной концепцией. В общем, вам следует предоставить их для концепций, которые можно использовать в качестве измерений.
Обратите внимание, что концепция пола также исходит из entity:entity . Это хорошая практика для концепций, которые используются в качестве измерений, поскольку она позволяет добавлять собственные имена, URL-адреса и цвета для различных экземпляров концепций.
Концепция пола относится к таблице genders_table , которая содержит возможные значения пола и их отображаемые имена (здесь опущены).
Чтобы добавить население по полу в наш набор данных, нам нужно создать новый срез (помните: каждая доступная комбинация измерений соответствует срезу в наборе данных).
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
Определение таблицы для среза выглядит следующим образом:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
CSV-файл таблицы выглядит следующим образом:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
По сравнению с предыдущими срезами по странам, населению и безработице, этот имеет дополнительное измерение; каждое значение показателя населения соответствует не только определенной стране и году, но и определенному полу.
Обратите внимание, что мы создали «разреженный» набор данных. Не все показатели доступны для всех измерений: население доступно для стран и штатов США на ежегодной основе, а уровень безработицы доступен только для стран. Разбивка по полу доступна только для населения по странам; он недоступен для показателя уровня безработицы, а также для государственного измерения. Разреженность также может существовать на уровне данных, когда определенные показатели не имеют значений для определенных значений измерений, но это не представлено в DSPL.
Темы
Последняя функция DSPL, которую мы будем использовать в нашем наборе данных, — это темы . Темы используются для иерархической классификации понятий и используются приложениями, чтобы помочь пользователям переходить к вашим данным.
В файле DSPL темы появляются непосредственно перед понятиями. Вот пример иерархии тем:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>Вы можете вкладывать темы настолько глубоко, насколько это необходимо.
Чтобы использовать темы, вам просто нужно ссылаться на них из определения концепции следующим образом:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
Концепция может относиться к более чем одной теме.
Отправка вашего набора данных
Теперь, когда вы создали свой набор данных, следующим шагом будет его архивирование и загрузка zip-файла в инструмент Google Public Data Explorer. Если у вас возникнут какие-либо проблемы, ознакомьтесь с разделом часто задаваемых вопросов , в котором обсуждаются наиболее распространенные проблемы с загрузкой.
Для справки вы также можете загрузить полный XML-файл и полный пакет набора данных, связанные с этим руководством.
Куда идти отсюда
Поздравляем с созданием вашего первого набора данных DSPL! Теперь, когда вы поняли основы, мы рекомендуем прочитать Руководство разработчика , в котором, среди прочего, описаны «расширенные» функции DSPL, такие как многоязычная поддержка и отображаемые концепции.
Вы также можете просмотреть еще несколько примеров наборов данных .