DSPL 代表資料集發布語言,DSPL 中描述的資料集 可以匯入 Google Public Data Explorer這項工具 資料。
注意:將資料上傳至 Google 公開資料 使用公開資料上傳工具, 你必須擁有 Google 帳戶。
本教學課程提供逐步操作範例,說明如何準備基本資料 DSPL 資料集。
DSPL 資料集是包含 XML 檔案和一組 XML 檔案的組合 CSV 檔案。CSV 檔案是簡單的表格,內含的資料 XML 檔案會說明資料集的中繼資料。 包括指標說明等資訊中繼資料 結構中繼資料,例如資料表之間的參照。中繼資料可讓您 非專家使用者會探索資料並以視覺化方式呈現
瞭解本教學課程的唯一先決條件是 對 XML 的瞭解對簡易資料庫概念有一定程度的瞭解 (例如 資料表、主鍵) 可能有幫助,但這不是必要步驟。提醒您, 完成的 XML 檔案並 完整資料集 或是與本教學課程相關的套裝組合。
總覽
開始建立資料集前,在此提供 DSPL 資料集包含下列項目:
- 一般資訊:關於資料集
- 概念:「事物」的定義並 (例如國家/地區、失業率、性別 etc.)
- 配量:概念組合 資料
- 表格:概念和片段的資料。概念資料表 擁有列舉,而切片表則會保留統計資料
- 主題:用於整理資料集的概念 幫助他們透過標籤
為了說明這些相反的抽象記法,請考慮使用 虛擬資料),例如: 匯總人口及失業人數 美國州別和性別
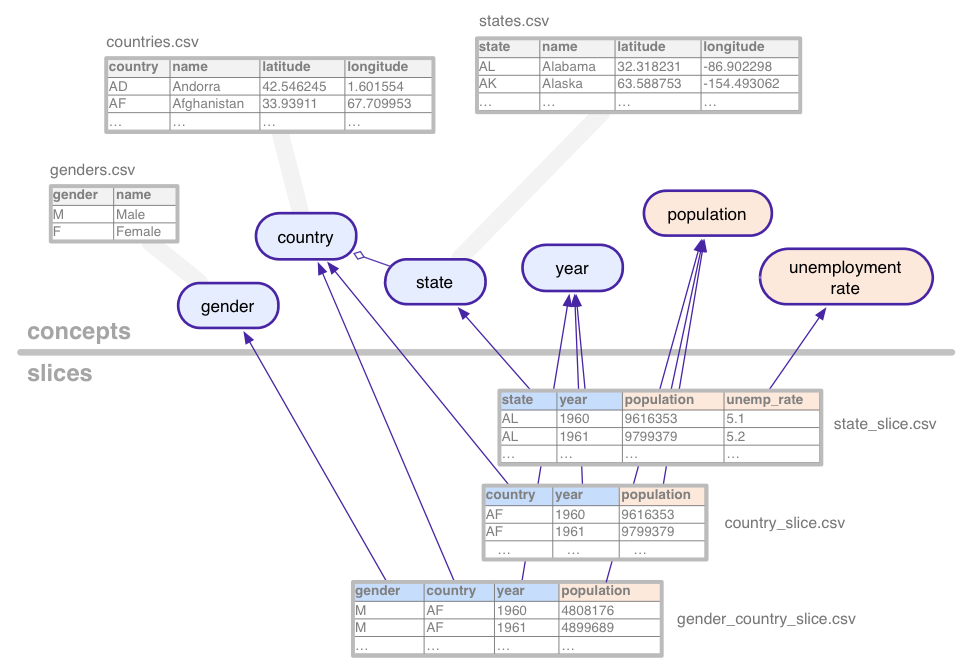
這個範例資料集定義了下列概念:
- country
- gender
- 人口
- 州
- 失業率
- 年
類別的概念 (例如狀態) 與概念有關 tables,會列舉所有可能的值 (加州、 例如亞利桑那州)。概念可能包含額外欄,用於表示屬性,例如: 國家/地區的名稱或國家/地區。
Slice 定義了各個概念的組合
資料集內的統計資料切片包含維度和
指標。在上圖中,維度是藍色的
指標會以橘色表示在這個範例中
gender_country_slice有這項指標的資料
population 和維度 country,
year和gender。另一個切片叫做
country_slice,提供下列資料的全年人口總數 (指標)
國家。
除了維度和指標外,區隔也能參照 資料表,內含實際資料。
現在,逐步示範如何在 DSPL。
資料集資訊
首先,我們需要為資料集建立 XML 檔案。接著來介紹 我們範例資料集的 DSPL 說明開頭:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
資料集說明的開頭是頂層 <dspl>
元素。targetNamespace 屬性包含的 URI
專門用於識別此資料集。資料集的命名空間
因為該資料集會成為
自己的資料集和其他人都能稱呼這個資料集的方式。
請注意,targetNamespace 屬性可以省略。於
在這個例子中,系統會在資料集
已匯入。
使用其他資料集的資訊
透過匯入方式,資料集可以重複使用其他資料集的定義和資料
和資料集每個 <import> 元素都會指定
其他資料集的命名空間
在資料集範例中,我們需要透過 http://www.google.com/publicdata/dataset/google/quantity 中的定義 (由 Google 建立的資料集,其中包含可用來定義 數值),以及擷取自時間、實體和地理資料集, 分別代表與時間、實體和地理位置相關的定義。
頂端的 <dspl> 元素會提供命名空間前置字串
宣告 (例如xmlns:time="http://...")
資料集的一分子必須宣告前置碼宣告
以精簡的方式擷取其他資料集的元素舉例來說:
time:year 參照了year
已匯入且命名空間與前置字串相關聯的資料集
time。
資料集和提供者資訊
<info> 元素包含以下項目的一般資訊:
資料集的名稱、說明,以及可供更多資訊的網址
找到。
<provider> 元素包含
資料集的名稱和網址
(通常是資料供應商的首頁)。
定義概念
我們已提供一些關於資料集的一般資訊 我們準備開始定義目錄內容了我們的下一個目標 過去 50 年各國家/地區的人口統計資料。
首先,我們要說明這些概念的定義 人口、國家/地區和年份在 DSPL 中,這些定義稱為 概念。
「概念」指的是出現在 與指定概念對應的資料值稱為 執行個體。
人口
讓我們先定義母體概念。在
DSPL 文件,其概念定義於 <concepts>
加入的子元素
這個人口概念只提供最少量資訊
任何概念:id (專屬 ID)、name 和
type。
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
這個範例的運作原理如下:
- 每個概念都必須提供可明確識別的
id可解釋性與透明度也就是說, 同一個資料集可以有相同的 ID。 - 就像資料集及其供應商一樣
<info>元素可提供文字資訊 例如名稱和說明 <type>元素會指定 概念的例項 (也就是其「值」)。 在這個範例中,population的類型為integer。DSPL 支援下列資料類型:stringintegerfloatbooleandate
國家/地區
現在我們來寫下國家/地區概念的定義:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
國家/地區概念的定義與上一個類似
搭配 id、info 和 type。
概念值
國家/地區等類別概念列舉了所有可能性
執行個體。換句話說,您應將所有可能
參照。但為此,每個國家/地區都需要專屬的 ID。
本範例使用
用於識別國家/地區的 ISO 國家/地區代碼;這些代碼
為 string 類型。
在此範例中,您不需要使用 ISO 代碼。你 請同樣使用國家/地區名稱不過,每個語言的名稱 可能會隨時間改變,而且不一定每次都會用於資料集。 以國家/地區來說,以一般類別概念來說, 練習選擇、簡短、穩定、常用,而且不考量語言 識別碼 (如果有的話)。
概念屬性
除了 id 以外,國家/地區概念還有
<property> 元素,用於指定國家/地區名稱。
也就是說,國家/地區名稱 (「愛爾蘭」) 是資源
國家/地區使用 id IE。屬性是 DSPL 如何提供屬性
某個概念例項的其他結構化資訊。
就像概念本身一樣,屬性也具有 id。
info和type。
概念資料
最後,國家/地區概念含有 <table> 元素。
這個元素參照的資料表,列舉了所有清單項目
國家。
在某些概念中,使用表格是合理的做法,但在其他概念上則不一定。適用對象 舉例來說,逐一列舉 概念數量不過,如果您要將資料表 某個概念,這個資料表必須包含該概念的所有例項,例如: 則必須列出所有國家/地區,而不是只列出部分國家/地區。
資料集會定義 countries_table 資料表,如下所示:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
國家/地區表格說明表格的資料欄和類型
並參照包含資料的 CSV 檔案。這個 CSV 檔案
可與資料集 XML 封裝並上傳,或是透過 HTTP、HTTPS、
或 FTP。在第二種情況下,您應將 countries.csv 替換為
網址,例如 http://www.myserver.com/mydata/countries.csv。
儲存位置後,CSV 檔案看起來會像這樣:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
表格第一列會列出 DSPL 中指定的欄 ID
table 定義。下列各列對應的
一個國家/地區概念的執行個體如果概念中有表格
資料表必須包含概念的「所有」執行個體,因此,
如果是,則必須列出所有國家/地區。
這些資料欄會對應至該國家/地區概念及其屬性
他們的 ID第一欄的 ID country 與概念相符
編號。這代表此欄包含專屬的國家/地區 ID
國家/地區概念下一欄對應至
國家/地區概念的 name 屬性。設定值
與 name 屬性的值一致。
概念表的 CSV 資料有以下幾項規定:
- 資料檔案第一行的欄標題必須
與
id概念和屬性「完全相符」 資料相關概念的id(不過 實際順序可能有所不同)。 - 每個資料列包含的元素數量必須與 屬性 (即使值為空白)。
- 概念的
id欄位的每個值 (此處 國家/地區代碼) 不得重複,且不得留空 (空白欄位即為 0 的值) 或只有空白字元)。 - 如果屬性值參照其他概念,值必須 空白,或參照概念的有效值。
- 含有逗號、雙引號或換行字元的值必須為 。
- 值中的所有雙引號字元都必須緊接在 前面加上另一個雙引號
年
國家/地區人口資料的最後一項概念是
代表年份。我們不會定義新的概念,而是使用
我們匯入的其中一個資料集得出的年份概念:
"http://www.google.com/publicdata/dataset/google/time".方法如下
我們需要將其稱為 time:year,其中 time
代表參照的資料集,而 year 代表參照的資料集
基本概念
標準概念
time:year 屬於少數標準概念的一部分
都是由 Google 定義標準化概念提供時間的基本概念、
地理位置、數值和單位等
事實上,上述國家/地區的概念是
代表性概念這裡僅供參考。
請盡可能在資料集中使用標準概念,
或擴充其內容 (請見下方擴充說明)。標準概念
將資料與其他資料集進行比較,
存取「公開資料瀏覽器」資料集例如,隨著時間的推移,為資料建立動畫效果
或是在地圖上顯示地理資料必須使用 time 和
分別對應 geo 標準概念。
第一個切片
現在我們已瞭解人口、國家/地區和年份的概念,接著就來思考 把它們都拼湊起來!
因此,我們必須建立結合這些字串的配量。在 DSPL 中 配量是資料存在的概念組合。
為何不只要建立內含合適資料欄的表格即可?由於 Slice 會擷取 依據其概念生成資料集的資訊這將成為 因為我們的資料集越多,就越清楚
配量會顯示在 DSPL 檔案中 <slices> 的下方
元素,且必須位於 concepts 部分之後。
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices>就像概念一樣,每個配量都有 id
(countries_slice) 可明確識別其中的切片
切片包含兩種概念參照:Dimensions 和
指標。指標的值會因
維度。此處的 population 值 (指標) 會隨著
country 和 year 這兩個維度
就像概念一樣,配量也包含表格參照, 包含該片段的資料。參照的表格必須有一個資料欄: 每個維度和指標的每個維度和指標就像概念一樣 維度及指標會對應到 ID 相同的表格資料欄。
配量表
我們的母體片段表格隨即顯示在tables
部分:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
請注意,year 欄隨附 format
屬性,用於指定年份的格式。系統支援的日期格式為
Joda DateTime 格式定義的值。
countries_slice 資料表會指定資料表的資料欄,以及
並指向包含所需資料的 CSV 檔案。CSV 檔案
如下所示:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
資料表的每一列都包含一個不重複的維度組合
country 和 year,以及對應的值
的「population」指標 (例如:人口 -
metric - 1960 年以來的阿富汗指標 - 維度)。
請注意,country 欄中的值與
country 概念的值/ID,即 ISO 3166
國家/地區的雙字母代碼。
切片的 CSV 資料必須符合下列限制:
- 維度欄位的每個值 (例如
country和year) 不得留空。指標欄位的值 (例如population) 可以留空。空白值不會 字元。 - 凡是參照某個概念的維度欄位值都必須
都會出現於該概念的資料中例如,值為
AF都必須出現在country概念資料表裡。 - 每個不重複的維度值組合,例如:
AF, 2000, 只會出現一次 - 資料應按照非時間維度欄 (任意順序) 排序,
然後視需要使用任何其他資料欄舉例來說
在包含
[date, dimension1, dimension2, metric1, metric2]欄的表格中,您可以按dimension1排序, 然後依序是dimension2和date,但不是date,然後是尺寸。
摘要
目前我們的 DSPL 已足夠能描述該國家/地區 人口資料。回顧一下,我們執行的操作如下:
- 建立資料集及其 DSPL 標頭和說明 提供者
- 分別構思人口和國家/地區的概念 列出所有國家/地區及其名稱的 CSV 檔案。
- 根據各國家/地區的人口數據建立資料片段 參考匯入時間資料集中已定義的年份概念 都是由 Google 開發的
在本教學課程的後續部分中,我們會透過 在更多區塊中新增更多維度,以及 主題。
新增維度:美國各州
現在,讓我們新增美國各州的人口資料,充實資料集 網路。首先需要定義狀態的概念看起來很像 例如我們先前定義的國家/地區概念
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>概念擴充功能與屬性 參考資料
這個狀態概念導入了 DSPL 的幾項新功能。
首先,說明會「延伸」另一個概念
geo:location (在外部地理區域資料集中定義)
開頭已匯入 )。從語意的角度來說
state 是一種 geo:location。結果是
該元件會沿用
geo:location。特別是,location 會定義
latitude 和 longitude;擴充
這些屬性也會套用至狀態再來,自
位置繼承自 entity:entity,狀態也會獲得
後者的所有屬性,包括 name
description和info_url。
注意:前文定義的國家/地區概念
從技術層面來說,這應包含從 geo:location 擴充的內容。
為求簡單,在此之前省略了這個點。加入
不過,在
最終 XML 檔案。
注意:您可以使用 extends
,就能重複使用其他資料集定義的資訊。
使用 extends 時,概念的所有例項都必須是
與您所擴充概念的有效執行個體相同您可以透過擴充功能
還能將一組執行個體限制在
屬於延伸概念的執行個體子集
除了繼承之外,狀態屬性也會導入
參照概念。
具體來說,狀態概念包含一個名為 country 的屬性
提到前面提到的國家/地區概念做法是
使用 concept 屬性。請注意,這個屬性
只能提供概念參考資料這相當於建立 ID
與參考概念 ID 相同 (亦即
country)。階層關係
若要擷取州和郡,則必須使用屬性
參考檔案的 isParent="true"。一般來說
以及包含階層關係的維度 (例如地理位置)
子概念
使用 isParent 屬性參照父項概念。
狀態的資料表定義如下所示:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
國家/地區欄會顯示所有州別都有一個常數值。指定
以免資料中的每個狀態重複。其他注意事項
我們已納入 name、latitude 和
longitude,因為狀態繼承了這些屬性
geo:location。另一方面,某些沿用的屬性
(例如:description) 不包含資料欄;沒關係-
如果概念定義表省略某個屬性,其值會是
假設概念的每個例項都是未定義。
CSV 檔案內容大致如下:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
由於我們已經有母體和年份的概念,因此可以重複使用 定義州人口的新切片。
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>資料表的定義如下所示:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
CSV 檔案看起來會像這樣:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
等等,我們當初是選擇新增片段,而不是新增其他 與上一個維度相較?
如果切片同時包含州和國家/地區的資料,則不會不正確。 因為有些資料列適用於國家/地區資料 資料。桌上會有「孔」對於某些維度而言 不允許 (請注意,缺少的值僅適用於指標和 而非尺寸)。
維度做為「主鍵」片段也就是說 每個資料列都必須包含所有維度的值,且不能有兩列 所有維度的值可能都相同。
新增指標:失業 率
現在,請將另一個指標新增至資料集:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
這項指標的 info 區段包含名稱、說明和
網址 (連結至美國勞工統計局)。
這個概念也延伸了 quantity:rate 標準概念。
數量
資料集定義了表示數值數量的核心概念。於
您必須擴充
適當的數量概念因此,population 的概念
從技術上來說,上述定義應從
quantity:amount。
概念屬性
這個概念也包含屬性的建構。於
在這個範例中,我們使用屬性來表示 unemployment_rate
都是百分比is_percentage 屬性沿用自
這個概念延伸的 quantity:rate 概念。這個
資訊,公開資料瀏覽器會使用這些資訊來顯示
以視覺化方式呈現資料
屬性可提供一般的機制,讓您將鍵/值組合附加至
概念 (與屬性相較,可將其他值連結至其他值)
執行個體)。就像概念和屬性一樣
屬性都有 id、info 和
type。就像屬性一樣,可參考其他概念。
屬性不只適用於預先定義的一般項目,例如數值 資源。您可以自行定義概念的屬性。
新增美國的失業率資料 狀態
我們現在已準備好新增美國各州的失業率資料。由於 失業率是指標,我們已取得各州的人口資料 就能直接加入先前為州和年份建立的切片 尺寸:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... 並在資料表定義中新增另一個資料欄:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... 以及 CSV 檔案:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
我們先前提過,對於每個管道,維度會形成一個主鍵 片段此外,對於每個資料集,每個資料集只能包含一個切片。 特定的維度組合。可用於 維度必須屬於同一個配量
更多維度:按性別劃分的人口詳細資料
現在讓我們來充實資料集,按性別細分母體 國家。你現在已經開始瞭解演習...首先 加入性別概念:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
性別概念「info」部分
pluralName,提供用於參照的文字
出現多個性別概念的例項還有 info 部分
包含 totalName,可提供要用於
則參考這個性別概念的所有項目兩者皆是
「公開資料瀏覽器」使用的樣式,顯示與性別相關的資訊
概念原則上,建議您提供這些概念
維度。
請注意,性別概念
entity:entity。這是很好的做法
維度,以便你新增自訂名稱
各種概念執行個體的網址和顏色。
性別概念是指 genders_table 資料表,
包含可能的性別及其顯示名稱的值
(在此省略)。
為了在資料集中新增依性別區分的人口數,需要建立新的配量 (請注意:每個可用的維度組合都會對應至一個片段 )。
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
各片段的資料表定義如下所示:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
資料表的 CSV 檔案如下所示:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
與前一個國家/地區、人口和失業階段相比 這個維度還有另一個維度每個人口指標的每個值 不只對應至特定國家/地區和年份 特定性別
請注意,我們建立了「稀疏」並非 指標適用於所有維度:人口是 每年為每個國家/地區和美國各州提供此功能,但就業機會 房價僅適用於國家/地區。目前提供依性別細分的資料 僅限按國家/地區劃分的人口無法取得失業率 而非狀態維度此外,資料中也可能會有 某些指標沒有特定維度值的值 但不在 DSPL 中。
主題
我們在資料集中使用的最後一個 DSPL 功能是 topics。 主題的用途是依階層分類概念,並用於 協助使用者瀏覽資料。
在 DSPL 檔案中,主題會顯示在概念前面。以下是一些範例 主題階層:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>您可以視需要建立多個主題的巢狀結構。
如要使用主題,只需從概念中提及 定義如下:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
一個概念可能會提及多個主題。
提交資料集
建立資料集後,下一步就是壓縮資料集 將 ZIP 檔案上傳至 Google 公開資料瀏覽器工具如果遇到任何問題,請確認 常見問題,包括相關討論內容 最常見的上傳問題
如需參考,您也可以下載完整的 XML 檔案和完整資料集組合 後續的所有課程
接下來該做什麼
恭喜您建立了第一個 DSPL 資料集!現在 瞭解基本概念,建議您詳閱開發人員指南, 「進階」文件DSPL 功能,例如 支援多種語言和可對應概念
建議您也參考其他資料集範例。