
Lorsque vous renvoyez une réponse à l'Assistant Google, vous pouvez utiliser une partie des le langage de balisage de synthèse vocale (SSML) dans vos réponses. Par en utilisant le langage SSML, vous pouvez rendre les réponses de votre conversation plus naturelles la voix. Voici un exemple de balisage SSML et la façon dont il est lu par Assistant Google.
<ph type="x-smartling-placeholder">function saySSML(conv) { const ssml = '<speak>' + 'Here are <say-as interpret-as="characters">SSML</say-as> samples. ' + 'I can pause <break time="3" />. ' + 'I can play a sound <audio src="https://www.example.com/MY_WAVE_FILE.wav">your wave file</audio>. ' + 'I can speak in cardinals. Your position is <say-as interpret-as="cardinal">10</say-as> in line. ' + 'Or I can speak in ordinals. You are <say-as interpret-as="ordinal">10</say-as> in line. ' + 'Or I can even speak in digits. Your position in line is <say-as interpret-as="digits">10</say-as>. ' + 'I can also substitute phrases, like the <sub alias="World Wide Web Consortium">W3C</sub>. ' + 'Finally, I can speak a paragraph with two sentences. ' + '<p><s>This is sentence one.</s><s>This is sentence two.</s></p>' + '</speak>'; conv.ask(ssml); }
{ "expectUserResponse": true, "expectedInputs": [ { "possibleIntents": [ { "intent": "actions.intent.TEXT" } ], "inputPrompt": { "richInitialPrompt": { "items": [ { "simpleResponse": { "textToSpeech": "<speak>Here are <say-as interpret-as=\"characters\">SSML</say-as> samples. I can pause <break time=\"3\" />. I can play a sound <audio src=\"https://www.example.com/MY_WAVE_FILE.wav\">your wave file</audio>. I can speak in cardinals. Your position is <say-as interpret-as=\"cardinal\">10</say-as> in line. Or I can speak in ordinals. You are <say-as interpret-as=\"ordinal\">10</say-as> in line. Or I can even speak in digits. Your position in line is <say-as interpret-as=\"digits\">10</say-as>. I can also substitute phrases, like the <sub alias=\"World Wide Web Consortium\">W3C</sub>. Finally, I can speak a paragraph with two sentences. <p><s>This is sentence one.</s><s>This is sentence two.</s></p></speak>" } } ] } } } ] }
Audio
Le langage SSML est compatible avec le simulateur d'actions, mais pas avec Dialogflow. de machine learning.
URL en SSML
Lorsque vous définissez une réponse SSML qui n'inclut qu'une URL, une esperluette dans cette URL
peut entraîner des problèmes
en raison du format XML. Pour s'assurer que l'URL est correcte
référencées, remplacez les instances de & par &.
Même si votre réponse SSML ne comprend qu'une URL, Actions on Google requiert
afficher le texte de la réponse. Comme le texte de la balise <audio> ne sera pas
prononcée par l'Assistant, vous pouvez insérer un texte de remplissage ou une brève description dans votre
<audio> pour répondre à cette exigence. Le texte de la balise <audio> ne sera pas
par l'Assistant après la lecture de l'audio, et rencontre le
exigence pour une version texte d'affichage de votre SSML.
Voici un exemple de réponse SSML problématique:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
</audio>
</speak>
L'exemple ci-dessus n'échappe pas le & pour une mise en forme XML correcte.
Voici à quoi ressemble une version corrigée de la même réponse SSML:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
text
</audio>
</speak>
Compatibilité des éléments SSML
Les sections qui suivent présentent les éléments et options SSML que vous pouvez utiliser dans vos actions.
<speak>
Élément racine de la réponse SSML.
Pour en savoir plus sur l'élément speak, consultez la spécification W3.
Exemple
<speak> my SSML content </speak>
<break>
Élément vide qui contrôle les pauses ou d'autres limites prosodiques entre les mots. La spécification de <break> entre une paire de jetons est facultative. Si cet élément n'est pas présent entre les mots, la rupture est automatiquement déterminée en fonction du contexte linguistique.
Pour en savoir plus sur l'élément break, consultez la spécification W3.
Attributs
| Attribut | Description |
|---|---|
time |
Définit la durée de la rupture en secondes ou en millisecondes (par exemple, "3s" ou "250ms"). |
strength |
Définit l'intensité de la rupture prosodique de la sortie en termes relatifs. Les valeurs valides sont : "x-weak", "weak", "medium", "strong" et "x-strong" (très faible, faible, moyenne, forte et très forte). La valeur "none" (aucune) indique qu'aucune limite de rupture prosodique ne doit être générée, ce qui peut permettre d'éviter une rupture que le processeur produirait sans cela. Les autres valeurs indiquent une intensité de rupture monotone non décroissante (augmentant de manière conceptuelle) entre les jetons. Les limites les plus fortes s'accompagnent généralement de pauses. |
Exemple
L'exemple suivant montre comment marquer une pause entre des étapes à l'aide de l'élément <break> :
<speak> Step 1, take a deep breath. <break time="200ms"/> Step 2, exhale. Step 3, take a deep breath again. <break strength="weak"/> Step 4, exhale. </speak>
<say‑as>
Cet élément vous permet d'indiquer des informations sur le type de construction de texte qu'il contient. Il permet également de spécifier le niveau de détail pour le rendu du texte contenu.
L'élément <say‑as> possède l'attribut obligatoire interpret-as, qui détermine la façon dont la valeur est prononcée. Les attributs facultatifs format et detail peuvent être utilisés en fonction de la valeur interpret-as indiquée.
Exemples
L'attribut interpret-as accepte les valeurs suivantes :
-
currencyL'exemple suivant est prononcé "quarante deux dollars et un cent". Si l'attribut "language" est omis, les paramètres régionaux actuels sont utilisés.
<speak> <say-as interpret-as='currency' language='en-US'>$42.01</say-as> </speak> -
telephoneReportez-vous à la description de
interpret-as='telephone'dans la note du groupe de travail W3C sur les valeurs des attributs de l'élément say-as SSML 1.0.L'exemple suivant est dit en anglais "one eight zero zero two zero two one two one two". Si l'attribut "google:style" est omis, "zero" est prononcé comme la lettre "o" en anglais.
L'attribut "google:style='zero-as-zero'" ne fonctionne actuellement que dans les paramètres régionaux EN.
<speak> <say-as interpret-as='telephone' google:style='zero-as-zero'>1800-202-1212</say-as> </speak> -
verbatimouspell-outL'exemple suivant est épelé une lettre à la fois :
<speak> <say-as interpret-as="verbatim">abcdefg</say-as> </speak> -
dateL'attribut
formatest une séquence de codes de caractère de champ de date. Les codes de caractère de champ compatibles avec l'attributformatsont {y,m,d} pour l'année, le mois et le jour (du mois) respectivement. Si le code de champ apparaît une fois pour l'année, le mois ou le jour, le nombre attendu de chiffres est respectivement de 4, 2 et 2. Si le code de champ est répété, le nombre attendu de chiffres correspond au nombre de répétitions du code. Les champs du texte de date peuvent être séparés par des signes de ponctuation et/ou des espaces.L'attribut
detailcontrôle la forme orale de la date. Pourdetail='1', seuls les champs de jour et un champ de mois ou d'année sont requis, bien que les deux puissent être indiqués. Il s'agit du paramétrage par défaut lorsque les trois champs ne sont pas tous fournis. La forme orale est "The {nombre ordinal du jour} of {mois}, {année}".L'exemple suivant est prononcé "The tenth of September, nineteen sixty" :
<speak> <say-as interpret-as="date" format="yyyymmdd" detail="1"> 1960-09-10 </say-as> </speak>L'exemple suivant est prononcé "The tenth of September" :
<speak> <say-as interpret-as="date" format="dm">10-9</say-as> </speak>Pour
detail='2', les champs de jour, de mois et d'année sont requis. Il s'agit du paramétrage par défaut lorsque les trois champs sont fournis. La forme orale est "{mois} {nombre ordinal du jour}, {année}".L'exemple suivant est prononcé "September tenth, nineteen sixty" :
<speak> <say-as interpret-as="date" format="dmy" detail="2"> 10-9-1960 </say-as> </speak> -
charactersL'exemple suivant est prononcé "C A N" :
<speak> <say-as interpret-as="characters">can</say-as> </speak> -
cardinalL'exemple suivant est prononcé "Twelve thousand three hundred forty five" (pour l'anglais américain) ou "Twelve thousand three hundred and forty five" (pour l'anglais britannique) :
<speak> <say-as interpret-as="cardinal">12345</say-as> </speak> -
ordinalL'exemple suivant est prononcé "First" :
<speak> <say-as interpret-as="ordinal">1</say-as> </speak> -
fractionL'exemple suivant est prononcé "five and a half" :
<speak> <say-as interpret-as="fraction">5+1/2</say-as> </speak> -
expletiveoubleepL'exemple suivant émet un bip, comme si le texte avait été censuré :
<speak> <say-as interpret-as="expletive">censor this</say-as> </speak> -
unitConvertit les unités au singulier ou au pluriel selon le nombre indiqué. L'exemple suivant est prononcé "10 feet" :
<speak> <say-as interpret-as="unit">10 foot</say-as> </speak> -
timeL'exemple suivant est prononcé "Two thirty P.M." :
<speak> <say-as interpret-as="time" format="hms12">2:30pm</say-as> </speak>L'attribut
formatest une séquence de codes de caractères de champ d'heure. Les codes de caractère de champ compatibles avec l'attributformatsont {h,m,s,Z,12,24} pour l'heure, la minute (de l'heure), la seconde (de la minute), le fuseau horaire, le format 12 heures et le format 24 heures, respectivement. Si le code de champ apparaît une fois pour l'heure, la minute ou la seconde, le nombre attendu de chiffres est respectivement de 1, 2 et 2. Si le code de champ est répété, le nombre attendu de chiffres correspond au nombre de répétitions du code. Les champs du texte d'heure peuvent être séparés par des signes de ponctuation et/ou des espaces. Si l'heure, la minute ou la seconde ne sont pas spécifiées dans le format ou s'il n'y a pas de chiffres correspondants, le champ est traité comme une valeur nulle. La valeur par défaut de l'attributformatest "hms12".L'attribut
detailcontrôle si l'heure prononcée est au format 12 heures ou 24 heures. Elle est au format 24 heures sidetail='1', ou sidetailest omis et que le format de l'heure est défini sur 24 heures. Elle est au format 12 heures sidetail='2', ou sidetailest omis et que le format de l'heure est défini sur 12 heures.
Pour en savoir plus sur l'élément say-as, consultez la spécification W3.
<audio>
Permet l'insertion de fichiers audio enregistrés et d'autres formats audio conjointement avec une sortie vocale synthétisée.
Attributs
| Attribut | Obligatoire | Par défaut | Valeurs |
|---|---|---|---|
src |
Oui | N/A | URI faisant référence à la source audio multimédia. Le protocole compatible est https. |
clipBegin |
Non | 0 | Désignation temporelle qui correspond au décalage entre le début de la source audio et le démarrage de la lecture. Si cette valeur est supérieure ou égale à la durée réelle de la source audio, aucun son n'est inséré. |
clipEnd |
Non | infini | Désignation temporelle qui correspond au décalage entre le début de la source audio et la fin de la lecture. Si la durée réelle de la source audio est inférieure à cette valeur, la lecture se termine à ce moment-là. Si la valeur de clipBegin est supérieure ou égale à clipEnd, aucun son n'est inséré. |
speed |
Non | 100 % | Ratio entre la vitesse de lecture de la sortie et la vitesse d'entrée normale, exprimé en pourcentage. Le format est un nombre réel positif suivi du symbole %. La plage actuellement acceptée est [50 % (lent – moitié de la vitesse) - 200 % (rapide – double de la vitesse)]. Les valeurs situées en dehors de cette plage peuvent être (ou non) ajustées afin d'y figurer. |
repeatCount |
Non | 1, ou 10 si repeatDur est défini |
Nombre réel spécifiant le nombre d'insertions du contenu audio (après le découpage, le cas échéant, avec clipBegin et/ou avec clipEnd). Les répétitions fractionnaires ne sont pas acceptées. La valeur est donc arrondie à l'entier le plus proche. La valeur zéro n'est pas valide et est donc traitée comme si aucune valeur n'avait été spécifiée. La valeur par défaut est alors utilisée. |
repeatDur |
Non | infini | Désignation temporelle qui constitue une limite appliquée à la durée de l'audio inséré après le traitement de la source pour les attributs clipBegin, clipEnd, repeatCount et speed (plutôt qu'à la durée de lecture normale). Si la durée de l'audio traité est inférieure à cette valeur, la lecture se termine à ce moment-là. |
soundLevel |
Non | +0 dB | Ajuste le niveau sonore de l'audio d'autant de décibels qu'indiqué par soundLevel. La plage maximale est de +/-40 dB, mais la plage réelle peut être inférieure en réalité, et la qualité de la sortie peut ne pas être bonne sur toute la plage. |
Les paramètres audio actuellement acceptés sont les suivants :
- Format : MP3 (MPEG v2)
- 24 000 échantillons par seconde
- 24 000 à 96 000 bits par seconde, taux fixe
- Format : Opus en Ogg
- 24 000 échantillons par seconde (bande ultralarge)
- 24 000 à 96 000 bits par seconde, taux fixe
- Format (obsolète) : WAV (RIFF)
- PCM signé 16 bits, little-endian
- 24 000 échantillons par seconde
- Pour tous les formats :
- Un seul canal de préférence, mais la configuration stéréo est acceptable.
- Durée maximale de 240 secondes. Si vous souhaitez lire de l'audio d'une durée plus longue, envisagez de configurer une réponse multimédia.
- Taille de fichier limitée à 5 mégaoctets.
- L'URL source doit utiliser le protocole HTTPS.
- La valeur UserAgent lors de l'extraction de l'audio est "Google-Speech-Actions".
Le contenu de l'élément <audio> est facultatif et est utilisé si le fichier audio ne peut pas être lu ou si l'appareil de sortie n'est pas compatible avec l'audio. Ce contenu peut inclure un élément <desc>, auquel cas le contenu textuel de cet élément est utilisé pour l'affichage. Pour plus d'informations, consultez la section "Audio enregistré" de la checklist relative aux réponses.
L'URL src doit également être une URL https (Google Cloud Storage peut héberger les fichiers audio sur une URL https).
Pour en savoir plus sur les réponses multimédias, consultez la section Réponses multimédias du guide "Réponses".
Pour en savoir plus sur l'élément audio, consultez la spécification W3.
Exemple
<speak> <audio src="cat_purr_close.ogg"> <desc>a cat purring</desc> PURR (sound didn't load) </audio> </speak>
<p>,<s>
Éléments de phrase et de paragraphe.
Pour en savoir plus sur les éléments p et s, consultez la spécification W3.
Exemple
<p><s>This is sentence one.</s><s>This is sentence two.</s></p>
Bonnes pratiques
- Nous vous recommandons d'utiliser des tags <s>...</s> pour encapsuler des phrases entières, surtout lorsque celles-ci contiennent des éléments SSML qui modifient la prosodie (tels que <audio>, <break>, <emphasis>, <par>, <prosody>, <say-as>, <seq> et <sub>).
- Si l'énoncé comprend une rupture suffisamment longue pour qu'on puisse l'entendre, utilisez des tags <s>...</s> et insérez cette rupture entre les phrases.
<sub>
Indique que le texte figurant dans la valeur de l'attribut alias remplace le texte contenu pour la prononciation.
Vous pouvez également utiliser l'élément sub pour fournir une prononciation plus simple d'un mot difficile à lire. Le dernier exemple ci-dessous illustre ce cas d'utilisation en japonais.
Pour en savoir plus sur l'élément sub, consultez la spécification W3.
Exemples
<sub alias="World Wide Web Consortium">W3C</sub>
<sub alias="にっぽんばし">日本橋</sub>
<mark>
Élément vide qui insère un marqueur dans la séquence de texte ou de tags. Cet élément permet de faire référence à un emplacement spécifique dans la séquence ou d'insérer un marqueur dans un flux de sortie pour une notification asynchrone.
Pour en savoir plus sur l'élément mark, consultez la spécification W3.
Exemple
<speak> Go from <mark name="here"/> here, to <mark name="there"/> there! </speak>
<prosody>
Permet de personnaliser la hauteur vocale, la vitesse d'élocution et le volume de texte contenu par l'élément. Actuellement, les attributs rate, pitch et volume sont disponibles.
Les attributs rate et volume peuvent être définis conformément aux spécifications W3. Il existe trois options permettant de définir la valeur de l'attribut pitch :
| Attribut | Description |
|---|---|
name |
ID de la chaîne pour chaque marque. |
| Option | Description |
|---|---|
| Relative | Spécifiez une valeur relative, par exemple, "low" (faible), "medium" (moyenne), "high" (élevée), etc., "medium" étant la hauteur vocale par défaut. |
| Demi-tons | Augmentez ou diminuez la hauteur vocale de "N" demi-tons en utilisant respectivement "+Nst" ou "-Nst". Notez que "+/-" et "st" sont requis. |
| Pourcentage | Augmentez ou diminuez la hauteur vocale de "N" % en utilisant respectivement "+N%" ou "-N%". Notez que "%" est requis, mais que "+/-" est facultatif. |
Pour en savoir plus sur l'élément prosody, consultez la spécification W3.
Exemple
L'exemple suivant utilise l'élément <prosody> pour que le locuteur s'exprime lentement, deux demi-tons plus bas que la normale :
<prosody rate="slow" pitch="-2st">Can you hear me now?</prosody>
<emphasis>
Utilisé pour ajouter ou supprimer une emphase dans le texte contenu par l'élément. L'élément <emphasis> modifie la voix de la même manière que <prosody>, mais sans qu'il ne soit nécessaire de définir des attributs de parole individuels.
Cet élément accepte un attribut "level" (niveau) facultatif avec les valeurs valides suivantes :
strongmoderatenonereduced
Pour en savoir plus sur l'élément emphasis, consultez la spécification W3.
Exemple
L'exemple suivant utilise l'élément <emphasis> pour faire une annonce :
<emphasis level="moderate">This is an important announcement</emphasis>
<par>
Conteneur multimédia parallèle qui vous permet de lire plusieurs éléments multimédias simultanément. Le seul contenu autorisé est un ensemble d'un ou de plusieurs éléments <par>, <seq> et <media>. L'ordre des éléments <media> n'est pas important.
À moins qu'un élément enfant ne spécifie une heure de début différente, l'heure de début implicite de l'élément est identique à celle du conteneur <par>. Si un élément enfant a une valeur de décalage définie pour son attribut begin (début) ou end (fin), le décalage de l'élément est déterminé par rapport à l'heure de début du conteneur <par>. Pour l'élément <par> racine, l'attribut "begin" (début) est ignoré, et l'heure de début correspond au moment où le processus de synthèse vocale SSML commence à générer une sortie pour l'élément <par> racine (autrement dit, au temps "zéro").
Exemple
<speak>
<par>
<media xml:id="question" begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media xml:id="answer" begin="question.end+2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media begin="answer.end-0.2s" soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</par>
</speak><seq>
Conteneur multimédia séquentiel qui vous permet de lire les éléments multimédias les uns après les autres. Le seul contenu autorisé est un ensemble d'un ou de plusieurs éléments <seq>, <par> et <media>. L'ordre des éléments multimédias est celui dans lequel ils sont affichés.
Les attributs begin (début) et end (fin) des éléments enfants peuvent être définis sur des valeurs de décalage (consultez la section Spécification temporelle ci-dessous). Les valeurs de décalage de ces éléments enfants sont déterminées par rapport à la fin de l'élément précédent de la séquence ou, dans le cas du premier élément de la séquence, par rapport au début de son conteneur <seq>.
Exemple
<speak>
<seq>
<media begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media begin="2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</seq>
</speak><media>
Représente une couche multimédia dans un élément <par> ou <seq>. Le contenu autorisé d'un élément <media> est un élément SSML <speak> ou <audio>. Le tableau suivant décrit les attributs valides pour un élément <media>.
Attributs
| Attribut | Obligatoire | Par défaut | Valeurs |
|---|---|---|---|
| xml:id | Non | Aucune valeur | Identifiant XML unique pour cet élément. Les entités encodées ne sont pas acceptées. Les valeurs d'identifiant autorisées correspondent à l'expression régulière "([-_#]|\p{L}|\p{D})+". Pour en savoir plus, consultez la page XML-ID. |
| begin | Non | 0 | Heure de début de ce conteneur multimédia. Ignoré s'il s'agit de l'élément racine du conteneur multimédia (traité de la même manière que la valeur par défaut "0"). Pour connaître les valeurs de chaîne valides, consultez la section Spécification temporelle ci-dessous. |
| end | Non | Aucune valeur | Spécification pour l'heure de fin de ce conteneur multimédia. Pour connaître les valeurs de chaîne valides, consultez la section Spécification temporelle ci-dessous. |
| repeatCount | Non | 1 | Nombre réel spécifiant le nombre d'insertions du contenu multimédia. Les répétitions fractionnaires ne sont pas acceptées. La valeur est donc arrondie à l'entier le plus proche. La valeur zéro n'est pas valide et est donc traitée comme si aucune valeur n'avait été spécifiée. La valeur par défaut est alors utilisée. |
| repeatDur | Non | Aucune valeur | Désignation temporelle qui constitue une limite appliquée à la durée du contenu multimédia inséré. Si la durée du contenu multimédia est inférieure à cette valeur, la lecture se termine à ce moment-là. |
| soundLevel | Non | +0 dB | Ajuste le niveau sonore de l'audio d'autant de décibels qu'indiqué par soundLevel. La plage maximale est de +/-40 dB, mais la plage réelle peut être inférieure en réalité, et la qualité de la sortie peut ne pas être bonne sur toute la plage. |
| fadeInDur | Non | 0 s | Désignation temporelle au cours de laquelle le contenu multimédia passe progressivement du mode silencieux à la valeur soundLevel spécifiée en option. Si la durée du contenu multimédia est inférieure à cette valeur, le fondu s'arrête à la fin de la lecture sans atteindre le niveau sonore spécifié. |
| fadeOutDur | Non | 0 s | Désignation temporelle au cours de laquelle le contenu multimédia passe progressivement de la valeur soundLevel spécifiée en option au mode silencieux. Si la durée du contenu multimédia est inférieure à cette valeur, le niveau sonore est défini sur une valeur inférieure afin de garantir que le son est coupé à la fin de la lecture. |
Spécification temporelle
Une spécification temporelle, utilisée pour la valeur des attributs "begin" (début) et "end" (fin) des éléments <media> et des conteneurs multimédias (éléments <par> et <seq>), est soit une valeur de décalage (par exemple, +2.5s), soit une valeur de base de synchronisation (par exemple, foo_id.end-250ms).
- Valeur de décalage : la valeur de décalage temporel est une valeur de compte de temps SMIL qui autorise les valeurs correspondant à l'expression régulière :
"\s\*(+|-)?\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"La première chaîne de chiffres correspond à la partie entière du nombre décimal et la deuxième chaîne de chiffres à la partie décimale. Le signe par défaut (c'est-à-dire "(+|-)?") est "+". Les valeurs unitaires correspondent respectivement aux heures, aux minutes, aux secondes et aux millisecondes. La valeur par défaut pour les unités est "s" (secondes).
- Valeur de base de synchronisation : il s'agit d'une valeur de base de synchronisation SMIL qui autorise les valeurs correspondant à l'expression régulière :
"([-_#]|\p{L}|\p{D})+\.(begin|end)\s\*(+|-)\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"Les chiffres et les unités sont interprétés de la même manière que pour une valeur de décalage.
Simulateur de synthèse vocale
La console Actions inclut un simulateur de synthèse vocale qui vous permet de tester le code SSML avec l'un des éléments ci-dessus. Le simulateur de synthèse vocale est disponible dans la console sous Simulateur > Audio : Saisissez votre texte et votre fichier SSML dans le simulateur, puis cliquez sur Mettre à jour et écouter pour entendre la sortie TTS.
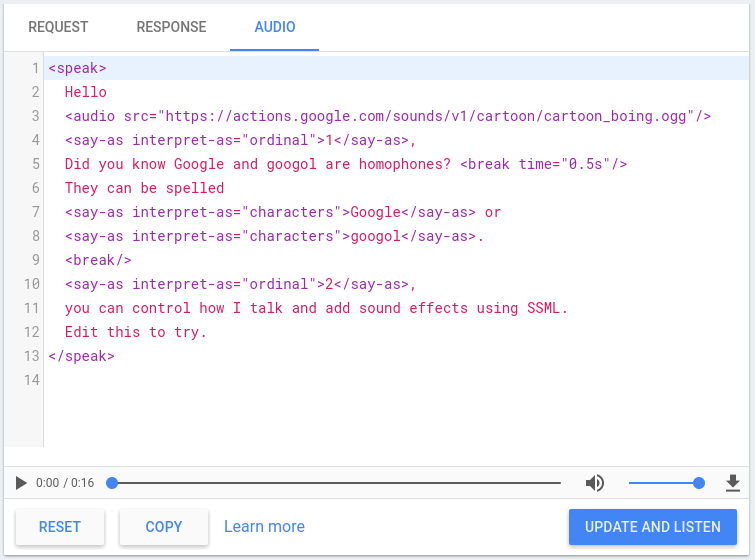
Vous pouvez également cliquer sur le bouton de téléchargement pour enregistrer un fichier .mp3 de votre synthèse vocale.
de sortie.