
Cloud Search 的查詢解讀功能會自動解讀使用者查詢中的運算子和篩選條件,並將這些元素轉換為以運算子為基礎的結構化查詢。查詢解讀功能會使用結構定義中定義的運算子,以及已建立索引的文件,推斷使用者查詢的意義。使用者只要輸入最少的關鍵字,就能獲得精確的搜尋結果。
向使用者顯示的實際結果取決於查詢解讀的信心指數。信賴度取決於多項因素,包括查詢字串在已建立索引的文件中出現的位置。如果演員「湯姆漢克斯」的名字等字串持續出現在名為 actors 的結構化資料欄位中,可信度就會提高。如果段落中出現相同的字串 (「Tom Hanks」),而不是結構化資料欄位,信賴度可能會降低。如果系統對結果有高度信心,只會向使用者顯示查詢解讀結果。如果信心程度較低,系統會將查詢解讀結果與一般關鍵字搜尋結果混合。
查詢解讀範例
假設您有一個資料來源 (例如資料庫),其中包含電影相關資訊。圖 1 顯示搜尋查詢範例和解讀結果。
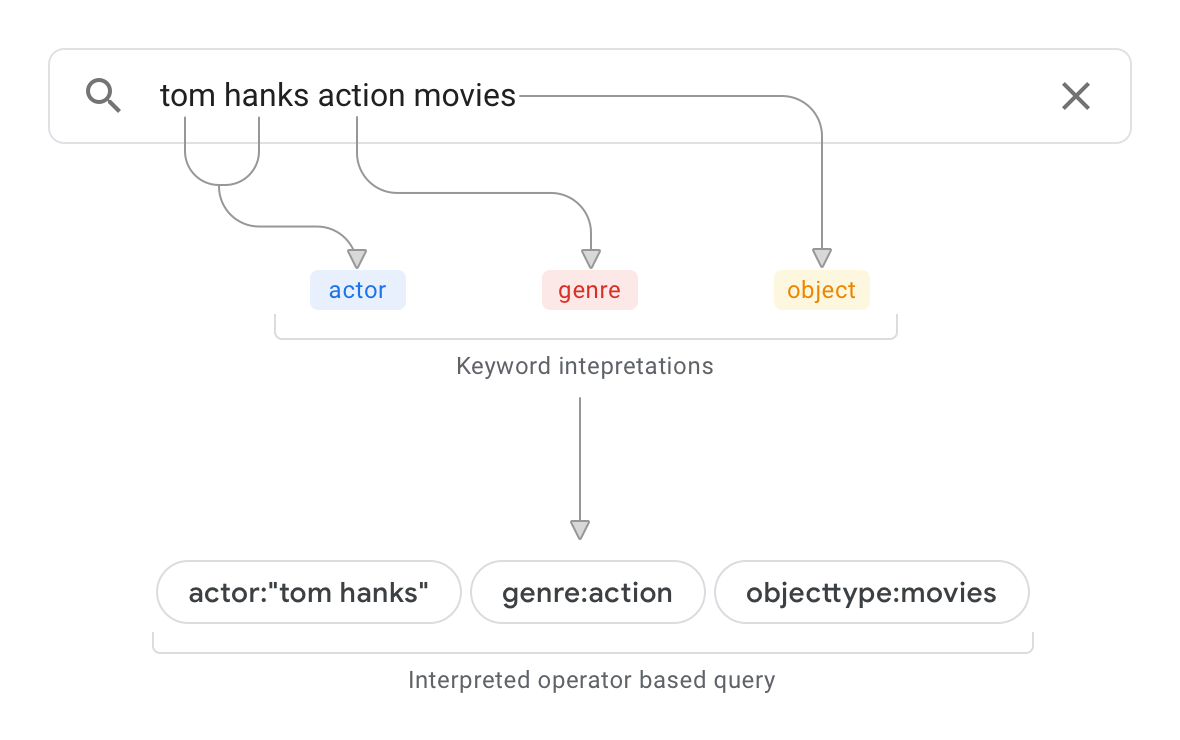
以這個查詢範例來說,查詢解讀會執行下列操作:
剖析架構並判斷資料來源中的頂層物件分類為
objecttype:movies。查詢解讀功能現在知道查詢中的「電影」是物件類型。掃描資料來源中的文件,並搭配結構定義,判斷字串「action」出現的位置。如果字串主要出現在特定「類型」資料來源欄位中,查詢解讀就會有信心「動作」是結構定義中定義的「類型」屬性值。如果字串主要出現在內容段落中,查詢解讀的信賴水準就會降低。
查詢結果的解讀如下:
actor:“tom hanks” genre:action objecttype:movies
所有 Cloud Search 客戶都會自動啟用查詢解讀功能,無須額外設定。不過,如要獲得最佳查詢解讀結果,請按照本文中的說明建構結構定義。
建構結構定義以支援查詢解讀
您應建構結構定義,確保能從查詢解讀功能獲益。
啟用顯示名稱解讀功能
Cloud Search 的查詢解讀功能會使用結構定義中的 objectDefinitions 和 propertyDefinitions 解讀使用者查詢,並調整搜尋結果。如要盡量發揮這些結構定義元素的效益,請使用 displayLabel 建立屬性名稱、使用 objectDisplayLabel 建立物件名稱,並使用 operatorName 建立運算子,藉此建立直覺式的顯示名稱。
以下結構定義顯示電影物件的直覺式顯示名稱:
{
"objectDefinitions": [
{
"name": "movie",
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
...
},
"propertyDefinitions": [
{
"name": "genre",
"isReturnable": true,
"isRepeatable": true,
"isFacetable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": {
"operatorName": "genre"
}
},
"displayOptions": {
"displayLabel": "Category"
}
},
...
]
}
]
}
在上述範例中:
電影物件定義包含「電影」
objectDisplayLabel。類型屬性定義包含「類型」
operatorName和「類別」displayLabel。
有了這些顯示名稱,Cloud Search 就能進行下列查詢解讀:
- 「動作片」、「類型動作片」或「電影類型動作」會解讀為
genre:action object:movies。 - 「類型為動作或驚悚的電影」會解讀為
objecttype:movies genre:(action OR thriller)。 - 「動作片」或「動作電影」會解讀為
genre:action objecttype:movies。 - 「comedy category movies」會解讀為
genre:comedy objecttype:movies。
啟用日期、數字和排序解讀結果
您應為所有日期和數值屬性定義 lessThanOperatorName 和 greaterThanOperatorName,如 IntegerOperatorOptions 中所指定。這些設定可啟用自動日期和數字解讀功能。此外,如要啟用排序解讀功能,請為日期和數值屬性設定 isSortable 選項。下列結構定義說明如何啟用這些選項。
{
"objectDefinitions": [
{
"options": {
"displayOptions": {
"objectDisplayLabel": "Films"
}
},
"propertyDefinitions": [
{
"name": "runtime",
"isReturnable": true,
"isSortable": true,
"integerPropertyOptions": {
"orderedRanking": "DESCENDING",
"minimumValue": {
"value": 10
},
"maximumValue": {
"value": 500
},
"operatorOptions": {
"operatorName": "runtime",
"lessThanOperatorName": "runtimelessthan",
"greaterThanOperatorName": "runtimegreaterthan"
}
},
"displayOptions": {
"displayLabel": "Length"
}
},
{
"name": "releasedate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "releasedate",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
}
}
]
}
]
}
在上述範例中:
- 數字屬性
runtime是指電影長度。這項資源已設定runtimelessthan和runtimegreaterthan。 - 日期屬性
releaseDate是指電影在戲院上映的日期。這項資源已設定releasedbefore和releasedafter。
這些設定可讓 Cloud Search 進行下列查詢解讀:
- 假設年份為 2019 年,「今年上映的電影」會解讀為
objecttype: movies releasedafter:2019-1-1 releasedbefore:2019-12-31。 - 假設目前是三月的第三週,「上週上映的電影」會解讀為
objecttype: movies releasedafter:2019-3-10 releasedbefore:2019-3-16 - 「片長小於 90 分鐘的電影」會解讀為
objjecttype: movies runtimelessthan:90。 - 假設年份為 2019 年,「今年上映的電影,片長超過 120 分鐘」會解讀為
releasedafter:2019-1-1 releasedbefore:2019-12-31 objecttype:movies runtimegreaterthan:120。 - 「依上映日期排序電影」會依「objecttype: movies」篩選,並依上映日期排序結果,預設排序順序為遞增。
啟用預約口譯員服務
您也可以使用 type、before、after、objecttype 保留的內建運算子,加強查詢解讀。為文件建立索引時,請執行下列操作:
在
ItemMetadata中填入updateTime欄位,即可使用before和after運算子。這些設定可讓 Cloud Search 進行下列查詢解讀:- 「上週的電影」會列出前一週更新的所有電影。
- 「movies before jan 2019」會列出 2019 年 1 月前建立索引的所有電影。
在
ItemMetadata中填入mimeType欄位,即可使用自動偵測類型功能。查詢「動作片」會列出所有 MIME 類型為application/mp4、application/mpeg4、application/x-shockwave-flash、video/和application/vnd.google-apps.video的動作片文件。
查詢解讀限制
查詢解讀功能有以下限制。
- 查詢解讀功能僅適用於下列資料來源 ACL:
- 所有文件都對網域公開 (網域中的所有人都能存取)。
- 所有文件都是資料來源公開文件 (所有有權存取資料來源 ACL 的使用者)。
- 資料來源中的大多數文件具有相同的 ACL (所有文件都會從相同的容器項目繼承 ACL),且未定義其他讀取者。
- 如果多個結構化架構運算子的值相同,系統會根據查詢解譯系統傳回的整體信賴度因子,解讀該值對查詢運算子意圖的意義。舉例來說,假設您在結構定義中定義了具有相同運算子名稱的
priority和severity屬性。假設兩個運算子都可以有 0、1、2 或 3 的值。 在本範例中,查詢中的「0」可以是指priority或severity的運算子值。這些值模稜兩可,信心水準較低。 - 根據預設,Cloud Search 的查詢解讀功能會在解讀查詢時,將欄位值轉換為小寫,但以
exactMatchWithOperator選項定義的文字運算子除外。 - 查詢不支援
source運算子。 - 系統不會解讀結合運算符字詞和任意文字字詞的查詢。舉例來說,系統不支援「p0 priority cases severity:s0」查詢,因為「p0 priority cases」是任意文字字詞,而「severity:s0」是運算符字詞。
- 查詢解讀策略一律會將解讀結果與一般 (未解讀、依相關性排序) 結果混合。不會完全取代結果頁面。