
Google Cloud Datastore एक NoSQL दस्तावेज़ डेटाबेस है. इसे अपने-आप स्केलिंग, बेहतर परफ़ॉर्मेंस, और ऐप्लिकेशन डेवलपमेंट को आसान बनाने के लिए बनाया गया है.
आपको क्या सीखने को मिलेगा
- Spring Boot में Java ऑब्जेक्ट को सेव करने और वापस पाने के लिए, Cloud Datastore का इस्तेमाल कैसे करें
आपको किन चीज़ों की ज़रूरत होगी
इस ट्यूटोरियल का इस्तेमाल कैसे किया जाएगा?
Google Cloud Platform की सेवाओं को इस्तेमाल करने के अपने अनुभव को आप क्या रेटिंग देंगे?
अपने हिसाब से एनवायरमेंट सेट अप करना
अगर आपके पास पहले से कोई Google खाता (Gmail या Google Apps) नहीं है, तो आपको एक खाता बनाना होगा. Google Cloud Platform Console (console.cloud.google.com) में साइन इन करें और एक नया प्रोजेक्ट बनाएं:



प्रोजेक्ट आईडी याद रखें. यह सभी Google Cloud प्रोजेक्ट के लिए एक यूनीक नाम होता है. ऊपर दिया गया नाम पहले ही इस्तेमाल किया जा चुका है. इसलिए, यह आपके लिए काम नहीं करेगा. माफ़ करें! इस कोड लैब में इसे बाद में PROJECT_ID के तौर पर दिखाया जाएगा.
इसके बाद, Google Cloud संसाधनों का इस्तेमाल करने के लिए, आपको Cloud Console में बिलिंग चालू करनी होगी.
इस कोडलैब को पूरा करने में आपको कुछ डॉलर से ज़्यादा खर्च नहीं करने पड़ेंगे. हालांकि, अगर आपको ज़्यादा संसाधनों का इस्तेमाल करना है या उन्हें चालू रखना है, तो यह खर्च बढ़ सकता है. इस दस्तावेज़ के आखिर में "सफ़ाई" सेक्शन देखें.
Google Cloud Platform के नए उपयोगकर्ता, 300 डॉलर के क्रेडिट के साथ मुफ़्त में आज़माने की सुविधा पा सकते हैं.
Google Cloud Shell चालू करना
GCP Console में, सबसे ऊपर दाईं ओर मौजूद टूलबार पर मौजूद Cloud Shell आइकॉन पर क्लिक करें:

इसके बाद, "Cloud Shell शुरू करें" पर क्लिक करें:

इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस लैब में ज़्यादातर काम, सिर्फ़ ब्राउज़र या Google Chromebook से किया जा सकता है.
Cloud Shell से कनेक्ट होने के बाद, आपको दिखेगा कि आपकी पुष्टि पहले ही हो चुकी है और प्रोजेक्ट को आपके PROJECT_ID पर पहले ही सेट कर दिया गया है.
पुष्टि करने के लिए कि आपने पुष्टि कर ली है, Cloud Shell में यह कमांड चलाएं:
gcloud auth list
कमांड आउटपुट
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
कमांड आउटपुट
[core] project = <PROJECT_ID>
अगर ऐसा नहीं है, तो इस कमांड का इस्तेमाल करके इसे सेट किया जा सकता है:
gcloud config set project <PROJECT_ID>
कमांड आउटपुट
Updated property [core/project].
GCP Console में, मेन्यू -> स्टोरेज सेक्शन में Datastore पर जाएं.
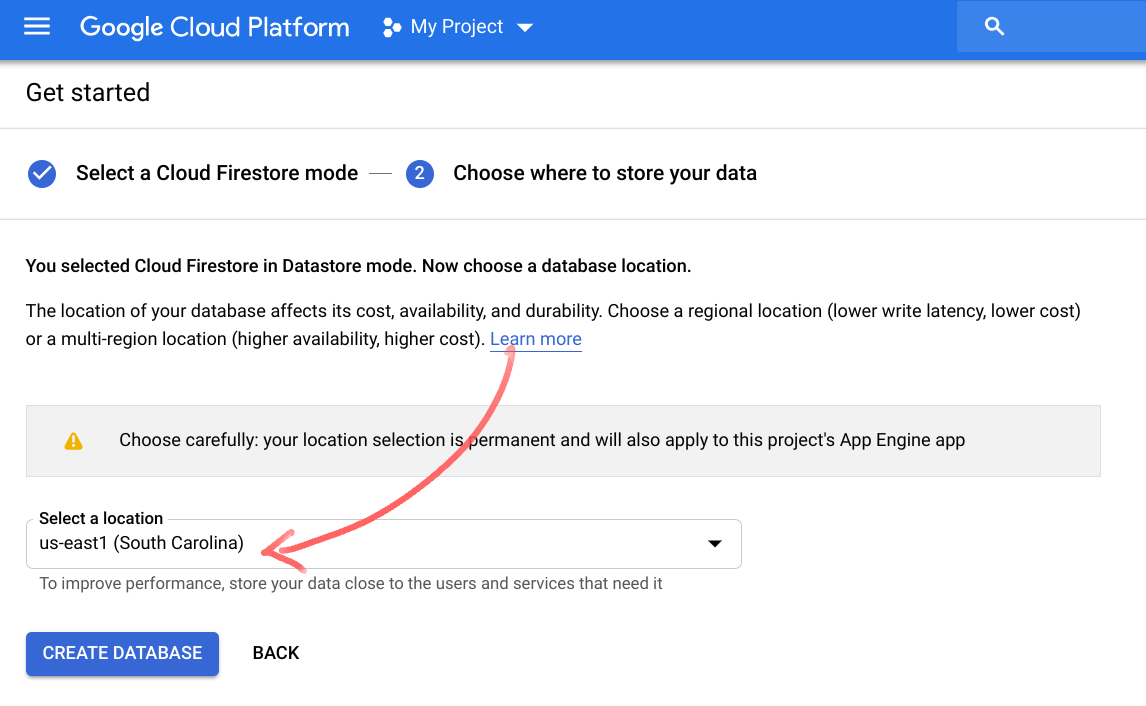
अगर आपने मौजूदा प्रोजेक्ट में कभी Datastore का इस्तेमाल नहीं किया है, तो आपको "Cloud Firestore मोड चुनें" स्क्रीन दिखेगी. "Datastore mode" विकल्प चुनें.

इसके बाद, आपको "चुनें कि आपको अपना डेटा कहां सेव करना है" स्क्रीन दिखेगी. us-east1 या कोई अन्य क्षेत्रीय जगह चुनें. इसके बाद, "डेटाबेस बनाएं" पर क्लिक करें:
CloudShell एनवायरमेंट में, नया Spring Boot ऐप्लिकेशन शुरू करने और बूटस्ट्रैप करने के लिए, यहां दिया गया निर्देश इस्तेमाल करें:
$ curl https://start.spring.io/starter.tgz \ -d packaging=war \ -d dependencies=cloud-gcp \ -d baseDir=datastore-example \ -d bootVersion=2.1.1.RELEASE | tar -xzvf -
इससे एक नई datastore-example/ डायरेक्ट्री बन जाएगी. इसमें एक नया Maven प्रोजेक्ट, Maven का pom.xml, Maven रैपर, और ऐप्लिकेशन एंट्रीपॉइंट होगा.
हमारा ऐप्लिकेशन, उपयोगकर्ताओं को कमांड डालने और नतीजे देखने के लिए सीएलआई उपलब्ध कराएगा. हम एक क्लास बनाएंगे, जो किसी किताब को दिखाएगी. इसके बाद, हम इसे Datastore Repository का इस्तेमाल करके Cloud Datastore में सेव करेंगे.
हमें pom.xml में एक और ज़रूरी डिपेंडेंसी जोड़नी होगी.
Cloud Shell मेन्यू में जाकर, कोड एडिटर लॉन्च करें पर क्लिक करके, Web Code Editor खोलें.
एडिटर लोड होने के बाद, Spring Data Cloud Datastore Spring Boot starter डिपेंडेंसी जोड़ने के लिए, pom.xml फ़ाइल में बदलाव करें:
pom.xml
<project>
...
<dependencies>
...
<!-- Add GCP Datastore Starter -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-gcp-starter-data-datastore</artifactId>
</dependency>
<!-- Add Spring Shell Starter -->
<dependency>
<groupId>org.springframework.shell</groupId>
<artifactId>spring-shell-starter</artifactId>
<version>2.0.0.RELEASE</version>
</dependency>
</dependencies>
</project>Editor का इस्तेमाल करके, इस कॉन्टेंट के साथ Book क्लास बनाएं:
datastore-example/src/main/java/com/example/demo/Book.java
package com.example.demo;
import org.springframework.cloud.gcp.data.datastore.core.mapping.Entity;
import org.springframework.data.annotation.Id;
@Entity(name = "books")
public class Book {
@Id
Long id;
String title;
String author;
int year;
public Book(String title, String author, int year) {
this.title = title;
this.author = author;
this.year = year;
}
public long getId() {
return this.id;
}
@Override
public String toString() {
return "Book{" +
"id=" + this.id +
", title='" + this.title + '\'' +
", author='" + this.author + '\'' +
", year=" + this.year +
'}';
}
}जैसा कि आप देख सकते हैं, यह एक सामान्य POJO है. क्लास को @Entity के साथ एनोटेट किया जाता है, ताकि यह पता चल सके कि इसे Datastore में सेव किया जा सकता है. साथ ही, यह काइंड का नाम भी देता है. काइंड को SQL डेटाबेस में टेबल के तौर पर देखा जा सकता है. ज़्यादा जानकारी के लिए, दस्तावेज़ देखें. तरह का नाम देना ज़रूरी नहीं है. अगर इसे नहीं दिया जाता है, तो क्लास के नाम के आधार पर तरह का नाम जनरेट किया जाएगा.
ध्यान दें कि हमने id प्रॉपर्टी को @Id के साथ एनोटेट किया है. इससे पता चलता है कि हम चाहते हैं कि इस फ़ील्ड का इस्तेमाल, Datastore Key के आइडेंटिफ़ायर पार्ट के तौर पर किया जाए. हर Datastore इकाई के लिए एक आइडेंटिफ़ायर की ज़रूरत होती है. String और Long टाइप की फ़ाइलें इस्तेमाल की जा सकती हैं.
हम toString मेथड को ओवरराइड करते हैं, ताकि ऑब्जेक्ट के स्ट्रिंग प्रज़ेंटेशन को ज़्यादा आसानी से पढ़ा जा सके. यह तब काम आएगा, जब हम उन्हें प्रिंट करेंगे.
फ़ाइल सेव करना न भूलें!
इस कॉन्टेंट के साथ BookRepository क्लास बनाएं:
datastore-example/src/main/java/com/example/demo/BookRepository.java
package com.example.demo;
import java.util.List;
import org.springframework.cloud.gcp.data.datastore.repository.DatastoreRepository;
public interface BookRepository extends DatastoreRepository<Book, Long> {
List<Book> findByAuthor(String author);
List<Book> findByYearGreaterThan(int year);
List<Book> findByAuthorAndYear(String author, int year);
}यह इंटरफ़ेस DatastoreRepository<Book, Long> को बढ़ाता है. इसमें Book डोमेन क्लास है और Long, Id टाइप है. हम अपनी रिपॉज़िटरी में तीन क्वेरी के तरीके बताते हैं. इनके लिए, बैकग्राउंड में अपने-आप लागू होने वाले कोड जनरेट होते हैं.
पहला विकल्प findByAuthor है. जैसा कि आपको पता है, इस तरीके को लागू करने पर एक क्वेरी एक्ज़ीक्यूट होगी. इसमें उपयोगकर्ता की ओर से दी गई वैल्यू का इस्तेमाल, समानता के लिए शर्त वाले फ़िल्टर में किया जाएगा.
findByYearGreaterThan तरीका, ऐसी क्वेरी को लागू करता है जो साल वाले फ़ील्ड को उपयोगकर्ता की दी गई वैल्यू से ज़्यादा के लिए फ़िल्टर करती है.
findByAuthorAndYear ऐसी क्वेरी को एक्ज़ीक्यूट करता है जो ऐसी इकाइयों को खोजती है जिनमें लेखक और साल के फ़ील्ड, उपयोगकर्ता की दी गई वैल्यू से मेल खाते हों.
मुख्य ऐप्लिकेशन DemoApplication क्लास खोलें और इसे इस तरह से बदलें:
datastore-example/src/main/java/com/example/demo/DemoApplication.java
package com.example.demo;
import java.util.List;
import com.google.common.collect.Lists;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.shell.standard.ShellComponent;
import org.springframework.shell.standard.ShellMethod;
@ShellComponent
@SpringBootApplication
public class DemoApplication {
@Autowired
BookRepository bookRepository;
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@ShellMethod("Saves a book to Cloud Datastore: save-book <title> <author> <year>")
public String saveBook(String title, String author, int year) {
Book savedBook = this.bookRepository.save(new Book(title, author, year));
return savedBook.toString();
}
@ShellMethod("Loads all books")
public String findAllBooks() {
Iterable<Book> books = this.bookRepository.findAll();
return Lists.newArrayList(books).toString();
}
@ShellMethod("Loads books by author: find-by-author <author>")
public String findByAuthor(String author) {
List<Book> books = this.bookRepository.findByAuthor(author);
return books.toString();
}
@ShellMethod("Loads books published after a given year: find-by-year-after <year>")
public String findByYearAfter(int year) {
List<Book> books = this.bookRepository.findByYearGreaterThan(year);
return books.toString();
}
@ShellMethod("Loads books by author and year: find-by-author-year <author> <year>")
public String findByAuthorYear(String author, int year) {
List<Book> books = this.bookRepository.findByAuthorAndYear(author, year);
return books.toString();
}
@ShellMethod("Removes all books")
public void removeAllBooks() {
this.bookRepository.deleteAll();
}
}ध्यान दें कि हमने क्लास को @ShellComponent से कैसे एनोटेट किया है. इससे Spring को पता चलता है कि हमें इस क्लास का इस्तेमाल, सीएलआई कमांड के सोर्स के तौर पर करना है. @ShellMethod के साथ एनोटेट किए गए तरीकों को हमारे ऐप्लिकेशन में सीएलआई कमांड के तौर पर दिखाया जाएगा.
यहां हमने BookRepository इंटरफ़ेस में बताए गए तरीकों का इस्तेमाल किया है: findByAuthor, findByYearGreaterThan, findByAuthorAndYear. हम तीन इन-बिल्ट तरीकों का भी इस्तेमाल करते हैं: save, findAll, और deleteAll.
आइए, saveBook तरीके के बारे में जानते हैं. हम Book ऑब्जेक्ट बनाते हैं. इसके लिए, उपयोगकर्ता की ओर से दिए गए टाइटल, लेखक, और साल की वैल्यू का इस्तेमाल किया जाता है. जैसा कि आप देख सकते हैं, हम id वैल्यू नहीं देते हैं. इसलिए, इसे सेव करने पर, आईडी फ़ील्ड में अपने-आप असाइन कर दिया जाएगा. save वाला तरीका, Book टाइप के ऑब्जेक्ट को स्वीकार करता है और उसे Cloud Datastore में सेव करता है. यह सभी फ़ील्ड में डेटा के साथ Book ऑब्जेक्ट दिखाता है. इसमें id फ़ील्ड भी शामिल है. आखिर में, हम इस ऑब्जेक्ट का स्ट्रिंग वर्शन दिखाते हैं.
बाकी तरीके भी इसी तरह काम करते हैं: वे सही रिपॉज़िटरी के तरीकों के लिए, पास किए गए पैरामीटर स्वीकार करते हैं और स्ट्रिंग के तौर पर नतीजे दिखाते हैं.
ऐप्लिकेशन बनाने और उसे शुरू करने के लिए, Cloud Shell में यह निर्देश चलाएं. यह निर्देश, प्रोजेक्ट के उस रूट से चलाएं datastore-example/ जहां pom.xml मौजूद है:
$ mvn spring-boot:run
बिल्ड स्टेज पूरा होने के बाद, स्प्रिंग का लोगो दिखेगा और शेल प्रॉम्प्ट दिखेगा:
. ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \ \\/ ___)| |_)| | | | | || (_| | ) ) ) ) ' |____| .__|_| |_|_| |_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v2.1.1.RELEASE) shell:>
अब उन निर्देशों के साथ एक्सपेरिमेंट किया जा सकता है जिनके बारे में हमने पहले बताया था. कमांड की सूची देखने के लिए, सहायता कमांड का इस्तेमाल करें:
shell:> help ... find-all-books: Loads all books find-by-author: Loads books by author: find-by-author <author> find-by-author-year: Loads books by author and year: find-by-author-year <author> <year> find-by-year-after: Loads books published after a given year: find-by-year-after <year> remove-all-books: Removes all books save-book: Saves a book to Cloud Datastore: save-book <title> <author> <year>
ये तरीके आज़माएं:
save-bookकमांड का इस्तेमाल करके कुछ किताबें बनाएंfind-all-booksकमांड का इस्तेमाल करके खोजें- किसी खास लेखक की किताबें ढूंढना (
find-by-author <author>) - किसी साल के बाद पब्लिश हुई किताबें ढूंढना (
find-by-year-after <year>) - किसी लेखक और साल के हिसाब से किताबें ढूंढना (
find-by-author-year <author> <year>)
Cloud Datastore में इकाइयां कैसे सेव की जाती हैं, यह देखने के लिए GCP Console पर जाएं. इसके बाद, मेन्यू -> Datastore (स्टोरेज सेक्शन में) -> इकाइयां पर जाएं. अगर ज़रूरी हो, तो "[default]" नेमस्पेस और "books" तरह की इकाइयां चुनें.
सभी किताबों को हटाने के लिए, ऐप्लिकेशन शेल में remove-all-books कमांड का इस्तेमाल करें.
shell:> remove-all-books
ऐप्लिकेशन से बाहर निकलने के लिए, quit कमांड का इस्तेमाल करें. इसके बाद, Ctrl+C दबाएं.
इस कोडलैब में, आपने एक इंटरैक्टिव सीएलआई ऐप्लिकेशन बनाया है. यह Cloud Datastore से ऑब्जेक्ट सेव और वापस पा सकता है!
ज़्यादा जानें
- Cloud Datastore: https://cloud.google.com/datastore/
- Spring Shell: https://projects.spring.io/spring-shell/
- GCP प्रोजेक्ट पर Spring: http://cloud.spring.io/spring-cloud-gcp/
- GCP GitHub रिपॉज़िटरी पर Spring: https://github.com/spring-cloud/spring-cloud-gcp
- Google Cloud Platform पर Java: https://cloud.google.com/java/
लाइसेंस
इस काम के लिए, Creative Commons एट्रिब्यूशन 2.0 जेनेरिक लाइसेंस के तहत लाइसेंस मिला है.