
A API Google Docs permite acessar conteúdo de qualquer guia no documento.
O que são guias?
O Google Docs tem uma camada organizacional chamada guias. O Google Docs permite que os usuários criem uma ou mais guias em um único documento, assim como as guias das Planilhas Google. Cada guia tem um título e um ID próprios (adicionados ao URL). Uma guia também pode ter guias filhas, que são guias aninhadas abaixo de outra guia.
Mudanças estruturais na forma como o conteúdo do documento é representado no recurso de documento
No passado, os documentos não tinham o conceito de guias. Por isso, o recurso Document continha diretamente todo o conteúdo de texto pelos seguintes campos:
document.bodydocument.headersdocument.footersdocument.footnotesdocument.documentStyledocument.suggestedDocumentStyleChangesdocument.namedStylesdocument.suggestedNamedStylesChangesdocument.listsdocument.namedRangesdocument.inlineObjectsdocument.positionedObjects
Com a hierarquia estrutural adicional das guias, esses campos não representam mais semanticamente o conteúdo de texto de todas as guias no documento. O conteúdo
baseado em texto agora é representado em uma camada diferente. As propriedades e o conteúdo das guias no Google Documentos podem ser acessados com document.tabs, que é uma lista de objetos Tab. Cada um deles contém todos os campos de conteúdo de texto mencionados acima. As seções posteriores oferecem uma breve visão geral. A representação JSON da guia também fornece informações mais detalhadas.
Acessar propriedades da guia
Acesse as propriedades da guia usando
tab.tabProperties,
que inclui informações como ID, título e posicionamento da guia.
Acessar conteúdo de texto em uma guia
O conteúdo real do documento na guia é exposto como
tab.documentTab.
Todos os campos de conteúdo de texto mencionados podem ser acessados usando
tab.documentTab. Por exemplo, em vez de usar document.body, use
document.tabs[indexOfTab].documentTab.body.
Hierarquia de guias
As guias filhas são representadas na API como um campo
tab.childTabs em
Tab. Para acessar todas as guias de um documento, é necessário percorrer a "árvore" de guias secundárias. Por exemplo, considere um documento que contém uma hierarquia de guias da seguinte maneira:
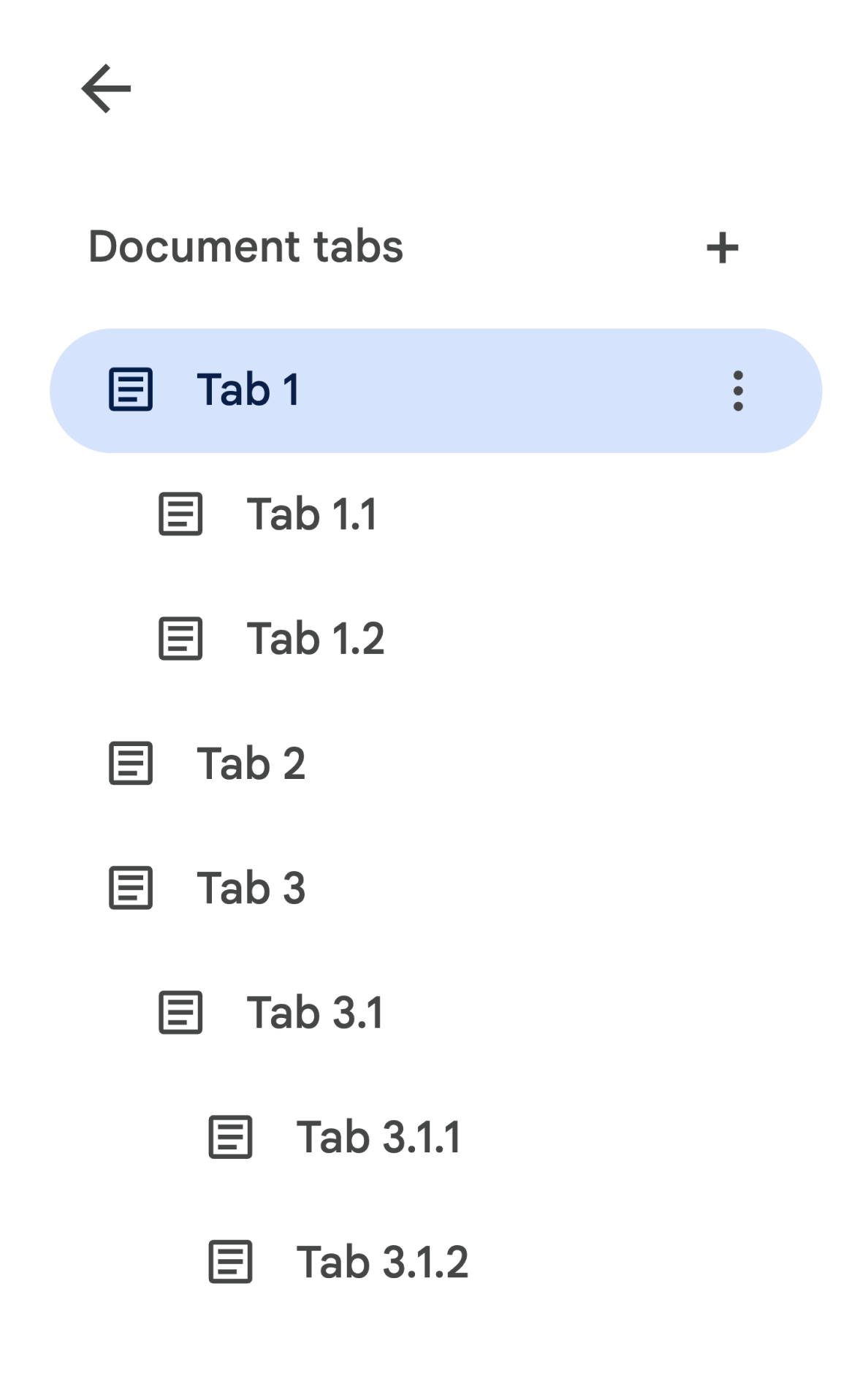
Para recuperar o Body
da Tabela 3.1.2, acesse
document.tabs[2].childTabs[0].childTabs[1].documentTab.body. Consulte os blocos de exemplo
na seção posterior, que fornece um exemplo de código para iterar
em todas as guias de um documento.
Mudanças nos métodos
Com a introdução das guias, cada um dos métodos de documento tem algumas mudanças que podem exigir a atualização do seu código.
documents.get
Por padrão, nem todo o conteúdo das guias é retornado. Os desenvolvedores precisam atualizar o código para acessar todas as guias. O método
documents.get
expõe um parâmetro includeTabsContent que permite configurar se
o conteúdo de todas as guias será fornecido na resposta.
- Se
includeTabsContentfor definido comotrue, o métododocuments.getvai retornar um recursoDocumentcom o campodocument.tabspreenchido. Todos os campos de texto diretamente emdocument(por exemplo,document.body) vão ficar vazios. - Se
includeTabsContentnão for fornecido, os campos de texto no recursoDocument(por exemplo,document.body) serão preenchidos com o conteúdo apenas da primeira guia. O campodocument.tabsvai ficar vazio, e o conteúdo de outras guias não será retornado.
documents.create
O método documents.create
retorna um recurso Document
que representa o documento vazio criado. O recurso Document retornado vai preencher o conteúdo vazio do documento nos campos de conteúdo de texto do documento e em document.tabs.
document.batchUpdate
Cada
Request
inclui uma maneira de especificar as guias em que a atualização será aplicada. Por padrão, se uma guia não for especificada, o Request será aplicado à primeira guia do documento na maioria dos casos.
ReplaceAllTextRequest, DeleteNamedRangeRequest e ReplaceNamedRangeContentRequest são três solicitações especiais que, em vez disso, serão aplicadas a todas as guias por padrão.
Consulte a documentação do
Request para mais detalhes.
Mudanças nos links internos
Os usuários podem criar links internos para guias, favoritos e cabeçalhos em um documento.
Com a introdução do recurso de guias, os campos link.bookmarkId e link.headingId no recurso Link não podem mais representar um marcador ou cabeçalho em uma guia específica do documento.
Os desenvolvedores precisam atualizar o código para usar link.bookmark e link.heading em
operações de leitura e gravação. Eles expõem links internos usando objetos
BookmarkLink
e HeadingLink, cada um contendo o ID do marcador ou cabeçalho e o ID da guia
em que ele está localizado. Além disso, link.tabId expõe links internos a guias.
O conteúdo do link de uma resposta documents.get também pode variar dependendo do parâmetro includeTabsContent:
- Se
includeTabsContentestiver definido comotrue, todos os links internos serão expostos comolink.bookmarkelink.heading. Os campos legados não serão mais usados. - Se
includeTabsContentnão for fornecido, nos documentos que contêm uma única guia, todos os links internos para favoritos ou cabeçalhos nessa guia singular continuarão sendo expostos comolink.bookmarkIdelink.headingId. Em documentos com várias guias, os links internos vão aparecer comolink.bookmarkelink.heading.
Em
document.batchUpdate,
se um link interno for criado usando um dos campos legados, o marcador de página ou
cabeçalho será considerado do ID da guia especificado no
Request. Se nenhuma guia for especificada, ela será considerada a primeira guia do documento.
A representação JSON do link fornece informações mais detalhadas.
Padrões de uso comuns para guias
As amostras de código a seguir descrevem várias maneiras de interagir com guias.
Ler o conteúdo de todas as guias no documento
O código que fazia isso antes do recurso de guias pode ser migrado para oferecer suporte a
guias definindo o parâmetro includeTabsContent como true, percorrendo a
hierarquia de árvore de guias e chamando métodos getter de
Tab e
DocumentTab
em vez de Document. O
exemplo de código parcial a seguir é baseado no snippet em Extrair o texto
de um documento. Ele mostra como
imprimir todo o conteúdo de texto de cada guia em um documento. Esse código de navegação por guias
pode ser adaptado para muitos outros casos de uso que não se importam com a estrutura
real das guias.
Java
/** Prints all text contents from all tabs in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from each tab in the document. for (Tab tab: allTabs) { // Get the DocumentTab from the generic Tab. DocumentTab documentTab = tab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); } } /** * Returns a flat list of all tabs in the document in the order they would * appear in the UI (top-down ordering). Includes all child tabs. */ private List<Tab> getAllTabs(Document doc) { List<Tab> allTabs = new ArrayList<>(); // Iterate over all tabs and recursively add any child tabs to generate a // flat list of Tabs. for (Tab tab: doc.getTabs()) { addCurrentAndChildTabs(tab, allTabs); } return allTabs; } /** * Adds the provided tab to the list of all tabs, and recurses through and * adds all child tabs. */ private void addCurrentAndChildTabs(Tab tab, List<Tab> allTabs) { allTabs.add(tab); for (Tab tab: tab.getChildTabs()) { addCurrentAndChildTabs(tab, allTabs); } } /** * Recurses through a list of Structural Elements to read a document's text * where text may be in nested elements. * * <p>For a code sample, see * <a href="https://developers.google.com/workspace/docs/api/samples/extract-text">Extract * the text from a document</a>. */ private static String readStructuralElements(List<StructuralElement> elements) { ... }
Ler o conteúdo da guia Leitura no documento
Isso é semelhante a ler todas as guias.
Java
/** Prints all text contents from the first tab in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from the first tab in the document. Tab firstTab = allTabs.get(0); // Get the DocumentTab from the generic Tab. DocumentTab documentTab = firstTab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); }
Fazer uma solicitação para atualizar a primeira guia
O exemplo de código parcial a seguir mostra como segmentar uma guia específica em um
Request.
Esse código é baseado no exemplo do guia
Inserir, excluir e mover texto.
Java
/** Inserts text into the first tab of the document. */ static void insertTextInFirstTab(Docs service, String documentId) throws IOException { // Get the first tab's ID. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); Tab firstTab = doc.getTabs().get(0); String tabId = firstTab.getTabProperties().getTabId(); List<Request>requests = new ArrayList<>(); requests.add(new Request().setInsertText( new InsertTextRequest().setText(text).setLocation(new Location() // Set the tab ID. .setTabId(tabId) .setIndex(25)))); BatchUpdateDocumentRequest body = new BatchUpdateDocumentRequest().setRequests(requests); BatchUpdateDocumentResponse response = docsService.documents().batchUpdate(<var>DOCUMENT_ID</var>, body).execute(); }