
API گوگل داکز به شما امکان میدهد از هر تبی در سند به محتوا دسترسی داشته باشید.
برگهها (tabs) چیستند؟
گوگل داکز (Google Docs) دارای یک لایه سازمانی به نام تب (tab) است. داکز به کاربران اجازه میدهد تا یک یا چند تب (tab) را در یک سند واحد ایجاد کنند، مشابه تبهای امروزی در Sheets. هر تب عنوان و شناسه (ID) خاص خود را دارد (که در URL اضافه شده است). یک تب همچنین میتواند تبهای فرزند (child tabs ) داشته باشد، که تبهایی هستند که در زیر تب دیگر قرار گرفتهاند.
تغییرات ساختاری در نحوه نمایش محتوای سند در منبع سند
در گذشته، اسناد مفهومی به نام تب (tab) نداشتند، بنابراین منبع Document Resource) مستقیماً شامل تمام محتوای متنی از طریق فیلدهای زیر بود:
-
document.body -
document.headers -
document.footers -
document.footnotes -
document.documentStyle -
document.suggestedDocumentStyleChanges -
document.namedStyles -
document.suggestedNamedStylesChanges -
document.lists -
document.namedRanges -
document.inlineObjects -
document.positionedObjects
با سلسله مراتب ساختاری اضافی تبها، این فیلدها دیگر از نظر معنایی محتوای متنی همه تبهای موجود در سند را نشان نمیدهند. محتوای مبتنی بر متن اکنون در یک لایه متفاوت نمایش داده میشود. ویژگیها و محتوای تب در Google Docs با document.tabs قابل دسترسی هستند، که لیستی از اشیاء Tab است که هر کدام شامل تمام فیلدهای محتوای متنی فوقالذکر هستند. بخشهای بعدی یک مرور کلی ارائه میدهند. نمایش Tab JSON همچنین اطلاعات دقیقتری را ارائه میدهد.
دسترسی به ویژگیهای برگه
با استفاده از tab.tabProperties به ویژگیهای تب دسترسی پیدا کنید، که شامل اطلاعاتی مانند شناسه، عنوان و موقعیت تب است.
دسترسی به محتوای متنی درون یک تب
محتوای واقعی سند درون تب به صورت tab.documentTab نمایش داده میشود. تمام فیلدهای محتوای متنی فوقالذکر با استفاده از tab.documentTab قابل دسترسی هستند. برای مثال، به جای استفاده از document.body ، باید document.tabs[indexOfTab].documentTab.body استفاده کنید.
سلسله مراتب تب
تبهای فرزند در API به صورت یک فیلد tab.childTabs در Tab نمایش داده میشوند. دسترسی به همه تبها در یک سند نیاز به پیمایش «درخت» تبهای فرزند دارد. برای مثال، سندی را در نظر بگیرید که شامل سلسله مراتب تب به شرح زیر است:
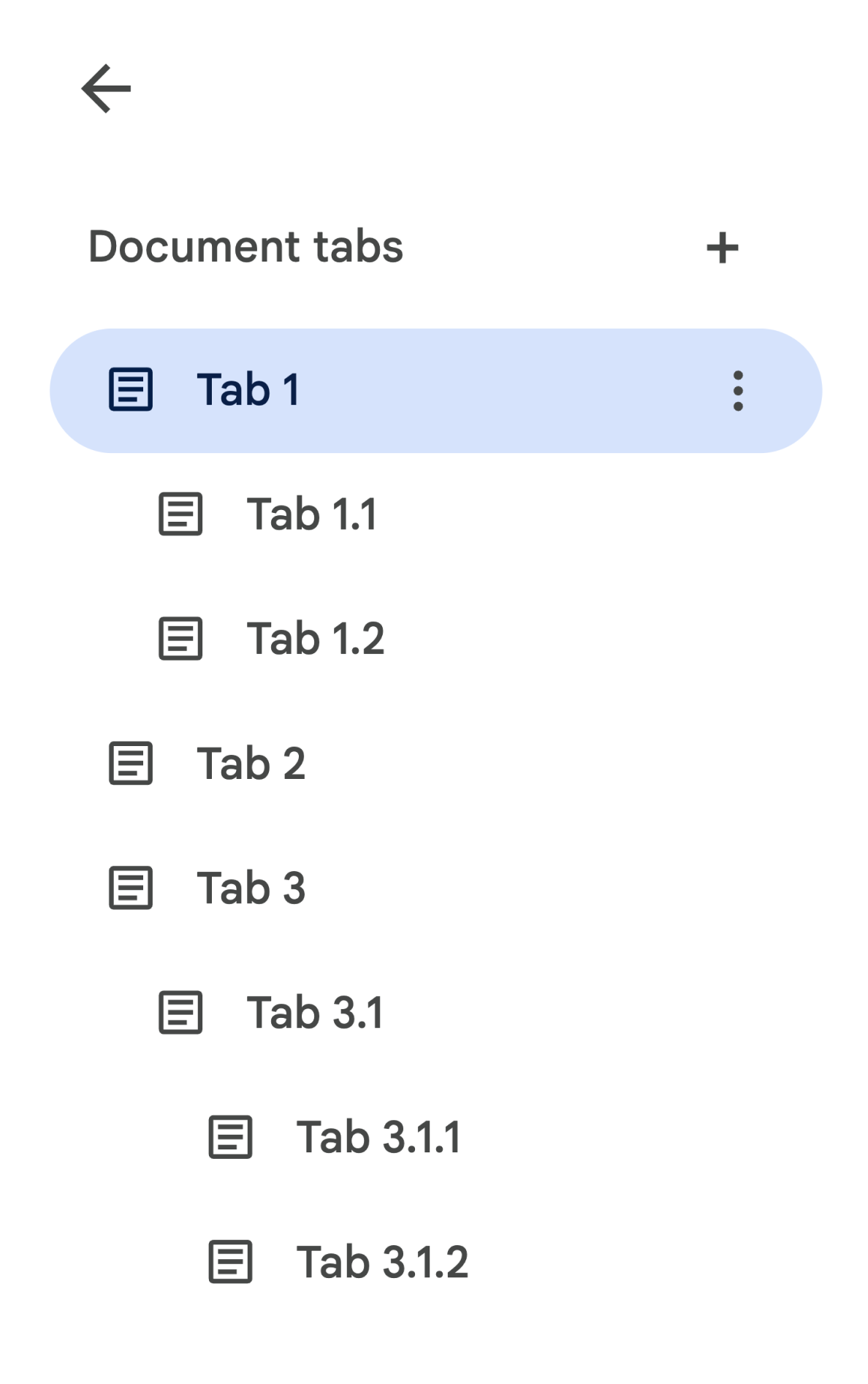
برای بازیابی Body از تب ۳.۱.۲ ، باید به document.tabs[2].childTabs[0].childTabs[1].documentTab.body دسترسی داشته باشید. بلوکهای کد نمونه را در بخش بعدی مشاهده کنید، که کد نمونهای برای تکرار در تمام تبهای یک سند ارائه میدهد.
تغییرات در روشها
با معرفی تبها، هر یک از متدهای سند تغییراتی خواهند داشت که ممکن است نیاز باشد کد خود را بهروزرسانی کنید.
اسناد.دریافت
به طور پیشفرض، تمام محتوای تبها برگردانده نمیشوند. توسعهدهندگان باید کد خود را برای دسترسی به همه تبها بهروزرسانی کنند. متد documents.get یک پارامتر includeTabsContent را نمایش میدهد که امکان پیکربندی ارائه محتوای همه تبها در پاسخ را فراهم میکند.
- اگر
includeTabsContentرویtrueتنظیم شده باشد، متدdocuments.getیکDocumentResource با فیلدdocument.tabsپر شده برمیگرداند. تمام فیلدهای متنی که مستقیماً درdocumentقرار دارند (مثلاًdocument.body) خالی باقی میمانند. - اگر
includeTabsContentارائه نشود، فیلدهای متنی درDocumentResource (مثلاًdocument.body) فقط با محتوای اولین تب پر میشوند. فیلدdocument.tabsخالی خواهد بود و محتوای تبهای دیگر بازگردانده نمیشود.
اسناد.ایجاد
متد documents.create یک Document Resource برمیگرداند که نشاندهندهی سند خالی ایجاد شده است. Document Resource برگردانده شده، محتوای سند خالی را هم در فیلدهای محتوای متنی سند و هم در document.tabs پر میکند.
بهروزرسانی دستهای سند
هر Request شامل روشی برای مشخص کردن تبهایی است که بهروزرسانی روی آنها اعمال میشود. به طور پیشفرض، اگر تبی مشخص نشده باشد، Request در بیشتر موارد روی اولین تب در سند اعمال میشود. ReplaceAllTextRequest ، DeleteNamedRangeRequest و ReplaceNamedRangeContentRequest سه درخواست ویژه هستند که به طور پیشفرض روی همه تبها اعمال میشوند.
برای جزئیات بیشتر به مستندات Request مراجعه کنید.
تغییرات در لینکهای داخلی
کاربران میتوانند به تبها، بوکمارکها و سرتیترها در یک سند لینک داخلی ایجاد کنند. با معرفی ویژگی تبها، فیلدهای link.bookmarkId و link.headingId در منبع Link دیگر نمیتوانند نشاندهنده یک بوکمارک یا سرتیتر در یک تب خاص در سند باشند.
توسعهدهندگان باید کد خود را برای استفاده link.bookmark و link.heading در عملیات خواندن و نوشتن بهروزرسانی کنند. آنها لینکهای داخلی را با استفاده از اشیاء BookmarkLink و HeadingLink نمایش میدهند که هر کدام حاوی شناسهی نشانه یا عنوان و شناسهی برگهای است که در آن قرار دارد. علاوه بر این، link.tabId لینکهای داخلی را به برگهها نمایش میدهد.
محتوای لینکهای پاسخ documents.get نیز میتواند بسته به پارامتر includeTabsContent متفاوت باشد:
- اگر
includeTabsContentرویtrueتنظیم شده باشد، تمام لینکهای داخلی به صورتlink.bookmarkوlink.headingنمایش داده میشوند. فیلدهای قدیمی دیگر استفاده نخواهند شد. - اگر
includeTabsContentارائه نشود، در اسنادی که حاوی یک تب واحد هستند، هرگونه لینک داخلی به بوکمارکها یا سرتیترها در آن تب واحد همچنان به صورتlink.bookmarkIdوlink.headingIdنمایش داده میشود. در اسنادی که حاوی چندین تب هستند، لینکهای داخلی به صورتlink.bookmarkوlink.headingنمایش داده میشوند.
در document.batchUpdate ، اگر یک لینک داخلی با استفاده از یکی از فیلدهای قدیمی ایجاد شود، بوکمارک یا عنوان از شناسه برگه مشخص شده در Request در نظر گرفته میشود. اگر هیچ برگهای مشخص نشود، از اولین برگه در سند در نظر گرفته میشود.
نمایش Link JSON اطلاعات دقیقتری ارائه میدهد.
الگوهای رایج استفاده از تبها
نمونههای کد زیر روشهای مختلف تعامل با تبها را شرح میدهند.
محتوای تب را از تمام تبهای موجود در سند بخوانید
کد موجودی که قبل از ویژگی تبها این کار را انجام میداد، میتواند با تنظیم پارامتر includeTabsContent به true ، پیمایش سلسله مراتب درخت تبها و فراخوانی متدهای getter از Tab و DocumentTab به جای Document ، به پشتیبانی از تبها منتقل شود. نمونه کد جزئی زیر بر اساس قطعه کد Extract the text from a document است. این کد نحوه چاپ تمام محتوای متن از هر تب در یک سند را نشان میدهد. این کد پیمایش تب را میتوان برای بسیاری از موارد استفاده دیگر که به ساختار واقعی تبها اهمیتی نمیدهند، تطبیق داد.
جاوا
/** Prints all text contents from all tabs in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from each tab in the document. for (Tab tab: allTabs) { // Get the DocumentTab from the generic Tab. DocumentTab documentTab = tab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); } } /** * Returns a flat list of all tabs in the document in the order they would * appear in the UI (top-down ordering). Includes all child tabs. */ private List<Tab> getAllTabs(Document doc) { List<Tab> allTabs = new ArrayList<>(); // Iterate over all tabs and recursively add any child tabs to generate a // flat list of Tabs. for (Tab tab: doc.getTabs()) { addCurrentAndChildTabs(tab, allTabs); } return allTabs; } /** * Adds the provided tab to the list of all tabs, and recurses through and * adds all child tabs. */ private void addCurrentAndChildTabs(Tab tab, List<Tab> allTabs) { allTabs.add(tab); for (Tab tab: tab.getChildTabs()) { addCurrentAndChildTabs(tab, allTabs); } } /** * Recurses through a list of Structural Elements to read a document's text * where text may be in nested elements. * * <p>For a code sample, see * <a href="https://developers.google.com/workspace/docs/api/samples/extract-text">Extract * the text from a document</a>. */ private static String readStructuralElements(List<StructuralElement> elements) { ... }
خواندن محتوای تب از اولین تب در سند
این مشابه خواندن همه تبها است.
جاوا
/** Prints all text contents from the first tab in the document. */ static void printAllText(Docs service, String documentId) throws IOException { // Fetch the document with all of the tabs populated, including any nested // child tabs. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); List<Tab> allTabs = getAllTabs(doc); // Print the content from the first tab in the document. Tab firstTab = allTabs.get(0); // Get the DocumentTab from the generic Tab. DocumentTab documentTab = firstTab.getDocumentTab(); System.out.println( readStructuralElements(documentTab.getBody().getContent())); }
درخواست بهروزرسانی اولین برگه را ارسال کنید
نمونه کد جزئی زیر نحوه هدف قرار دادن یک تب خاص در یک Request را نشان میدهد. این کد بر اساس نمونه موجود در راهنمای درج، حذف و انتقال متن است.
جاوا
/** Inserts text into the first tab of the document. */ static void insertTextInFirstTab(Docs service, String documentId) throws IOException { // Get the first tab's ID. Document doc = service.documents().get(<var>DOCUMENT_ID</var>).setIncludeTabsContent(true).execute(); Tab firstTab = doc.getTabs().get(0); String tabId = firstTab.getTabProperties().getTabId(); List<Request>requests = new ArrayList<>(); requests.add(new Request().setInsertText( new InsertTextRequest().setText(text).setLocation(new Location() // Set the tab ID. .setTabId(tabId) .setIndex(25)))); BatchUpdateDocumentRequest body = new BatchUpdateDocumentRequest().setRequests(requests); BatchUpdateDocumentResponse response = docsService.documents().batchUpdate(<var>DOCUMENT_ID</var>, body).execute(); }