Bảng băm nhỏ
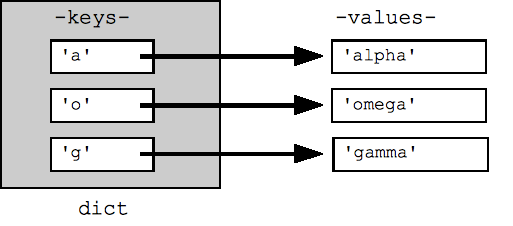
Cấu trúc bảng băm giá trị/khoá hiệu quả của Python được gọi là một "dict". Nội dung của lệnh chính tả có thể được viết dưới dạng một chuỗi cặp khoá:giá trị trong dấu ngoặc nhọn { }, ví dụ: dict = {key1:value1, key2:value2, ... }. Lệnh "trống" chỉ là một cặp dấu ngoặc nhọn trống {}.
Việc tra cứu hoặc đặt giá trị trong lệnh chính tả sử dụng dấu ngoặc vuông, ví dụ: dict['foo'] tra cứu giá trị dưới khoá 'foo'. Chuỗi, số và bộ dữ liệu hoạt động như khoá và mọi kiểu đều có thể là một giá trị. Các loại khác có thể hoạt động không chính xác hoặc không hoạt động chính xác dưới dạng khoá (chuỗi và bộ dữ liệu hoạt động trơn tru vì chúng không thể thay đổi). Việc tra cứu một giá trị không có trong lệnh chính sẽ tạo ra KeyError -- sử dụng "in" để kiểm tra xem khoá có nằm trong lệnh dict hay không hoặc sử dụng dict.get(key) để trả về giá trị hoặc Không có nếu không có khoá (hoặc get(key, not-found) cho phép bạn chỉ định giá trị nào cần trả về trong trường hợp không tìm thấy).
## Can build up a dict by starting with the empty dict {} ## and storing key/value pairs into the dict like this: ## dict[key] = value-for-that-key dict = {} dict['a'] = 'alpha' dict['g'] = 'gamma' dict['o'] = 'omega' print(dict) ## {'a': 'alpha', 'o': 'omega', 'g': 'gamma'} print(dict['a']) ## Simple lookup, returns 'alpha' dict['a'] = 6 ## Put new key/value into dict 'a' in dict ## True ## print(dict['z']) ## Throws KeyError if 'z' in dict: print(dict['z']) ## Avoid KeyError print(dict.get('z')) ## None (instead of KeyError)
Theo mặc định, vòng lặp for trên từ điển sẽ lặp lại các khoá của từ điển. Các khoá sẽ xuất hiện theo thứ tự tuỳ ý. Các phương thức dict.keys() và dict.values() trả về danh sách các khoá hoặc giá trị một cách rõ ràng. Ngoài ra còn có một items() trả về danh sách các bộ dữ liệu (khoá, giá trị), đây là cách hiệu quả nhất để kiểm tra tất cả dữ liệu khoá-giá trị trong từ điển. Tất cả danh sách này có thể được chuyển đến hàm được sắp xếp().
## By default, iterating over a dict iterates over its keys. ## Note that the keys are in a random order. for key in dict: print(key) ## prints a g o ## Exactly the same as above for key in dict.keys(): print(key) ## Get the .keys() list: print(dict.keys()) ## dict_keys(['a', 'o', 'g']) ## Likewise, there's a .values() list of values print(dict.values()) ## dict_values(['alpha', 'omega', 'gamma']) ## Common case -- loop over the keys in sorted order, ## accessing each key/value for key in sorted(dict.keys()): print(key, dict[key]) ## .items() is the dict expressed as (key, value) tuples print(dict.items()) ## dict_items([('a', 'alpha'), ('o', 'omega'), ('g', 'gamma')]) ## This loop syntax accesses the whole dict by looping ## over the .items() tuple list, accessing one (key, value) ## pair on each iteration. for k, v in dict.items(): print(k, '>', v) ## a > alpha o > omega g > gamma
Lưu ý về chiến lược: từ quan điểm hiệu suất, từ điển là một trong những công cụ tuyệt vời nhất của bạn và bạn nên sử dụng từ điển ở nơi bạn có thể dễ dàng sắp xếp dữ liệu. Ví dụ: bạn có thể đọc một tệp nhật ký trong đó mỗi dòng bắt đầu bằng một địa chỉ IP và lưu trữ dữ liệu vào một lệnh chính tả bằng cách sử dụng địa chỉ IP làm khoá và danh sách các dòng mà nó xuất hiện dưới dạng giá trị. Sau khi bạn đã đọc toàn bộ tệp, bạn có thể tra cứu bất kỳ địa chỉ IP nào và xem ngay danh sách các dòng của địa chỉ IP đó. Từ điển lấy dữ liệu phân tán và làm cho dữ liệu trở nên mạch lạc.
Định dạng nhập bằng giọng nói
Toán tử % hoạt động một cách thuận tiện để thay thế các giá trị từ một lệnh chính tả vào một chuỗi theo tên:
h = {} h['word'] = 'garfield' h['count'] = 42 s = 'I want %(count)d copies of %(word)s' % h # %d for int, %s for string # 'I want 42 copies of garfield' # You can also use str.format(). s = 'I want {count:d} copies of {word}'.format(h)
Xóa
Chữ "del" sẽ xoá. Trong trường hợp đơn giản nhất, nó có thể loại bỏ định nghĩa của biến, như thể biến đó chưa được xác định. Bạn cũng có thể dùng Del trên các phần tử hoặc lát cắt của danh sách để xoá phần đó của danh sách và xoá các mục nhập khỏi từ điển.
var = 6 del var # var no more! list = ['a', 'b', 'c', 'd'] del list[0] ## Delete first element del list[-2:] ## Delete last two elements print(list) ## ['b'] dict = {'a':1, 'b':2, 'c':3} del dict['b'] ## Delete 'b' entry print(dict) ## {'a':1, 'c':3}
Files
Hàm open() mở và trả về một tay cầm tệp có thể dùng để đọc hoặc ghi tệp theo cách thông thường. Mã f = open('name', 'r') mở tệp trong biến f, sẵn sàng cho các thao tác đọc và sử dụng f.close() khi hoàn tất. Thay vì sử dụng 'r', hãy sử dụng 'w' để viết và "a" để nối. Tiêu chuẩn cho vòng lặp hoạt động đối với các tệp văn bản, lặp lại qua các dòng của tệp (điều này chỉ áp dụng cho các tệp văn bản, không áp dụng cho tệp nhị phân). Kỹ thuật vòng lặp for là một cách đơn giản và hiệu quả để xem tất cả các dòng trong một tệp văn bản:
# Echo the contents of a text file f = open('foo.txt', 'rt', encoding='utf-8') for line in f: ## iterates over the lines of the file print(line, end='') ## end='' so print does not add an end-of-line char ## since 'line' already includes the end-of-line. f.close()
Đọc từng dòng một có chất lượng tốt mà không phải tất cả các tệp đều cần vừa với bộ nhớ cùng một lúc - hữu ích nếu bạn muốn xem mọi dòng trong tệp 10 gigabyte mà không cần sử dụng 10 gigabyte bộ nhớ. Phương thức f.readlines() đọc toàn bộ tệp vào bộ nhớ và trả về nội dung dưới dạng danh sách các dòng. Phương thức f.read() sẽ đọc toàn bộ tệp thành một chuỗi duy nhất. Đây có thể là cách thuận tiện để xử lý toàn bộ văn bản cùng một lúc, chẳng hạn như với các biểu thức chính quy mà chúng ta sẽ thấy ở phần sau.
Để ghi, phương thức f.write(string) là cách dễ nhất để ghi dữ liệu vào một tệp đầu ra đang mở. Hoặc bạn có thể dùng "in" bằng một tệp mở như "print(string, file=f)".
Tệp Unicode
Để đọc và ghi các tệp được mã hoá Unicode, hãy sử dụng chế độ "'t" và chỉ định rõ chế độ mã hoá:
with open('foo.txt', 'rt', encoding='utf-8') as f: for line in f: # here line is a *unicode* string with open('write_test', encoding='utf-8', mode='wt') as f: f.write('\u20ACunicode\u20AC\n') # €unicode€ # AKA print('\u20ACunicode\u20AC', file=f) ## which auto-adds end='\n'
Thực hành phát triển gia tăng
Khi xây dựng một chương trình Python, bạn không nên viết toàn bộ trong một bước. Thay vào đó, chỉ xác định một mốc quan trọng đầu tiên, ví dụ: "bước đầu tiên là trích xuất danh sách các từ". Viết mã để đến mốc đó và chỉ in cấu trúc dữ liệu của bạn tại thời điểm đó, sau đó bạn có thể thực hiện sys.exit(0) để chương trình không chạy tiếp theo các phần chưa hoàn thành. Sau khi mã mốc quan trọng hoạt động, bạn có thể xử lý mã cho mốc quan trọng tiếp theo. Việc có thể xem kết quả của các biến ở một trạng thái có thể giúp bạn suy nghĩ về cách bạn cần chuyển đổi những biến đó để chuyển sang trạng thái tiếp theo. Python hoạt động rất nhanh với mẫu này, cho phép bạn thay đổi một chút rồi chạy chương trình để xem cách thức hoạt động. Tận dụng thời gian quay vòng nhanh chóng đó để xây dựng chương trình của bạn chỉ bằng vài bước.
Bài tập: wordcount.py
Kết hợp tất cả tài liệu Python cơ bản – chuỗi, danh sách, lệnh chính tả, bộ dữ liệu, tệp – hãy thử làm bài tập tóm tắt wordcount.py trong Bài tập cơ bản.