Cách dễ nhất để sắp xếp là dùng hàm được sắp xếp(danh sách). Hàm này sẽ nhận một danh sách và trả về một danh sách mới chứa các phần tử đó theo thứ tự được sắp xếp. Danh sách ban đầu vẫn giữ nguyên.
a = [5, 1, 4, 3] print(sorted(a)) ## [1, 3, 4, 5] print(a) ## [5, 1, 4, 3]
Thường thì bạn nên truyền một danh sách vào hàm được sắp xếp(), nhưng trên thực tế, danh sách này có thể dùng làm dữ liệu đầu vào cho bất kỳ bộ sưu tập có thể lặp lại nào. Phương thức list.sort() cũ là phương thức thay thế được nêu chi tiết dưới đây. Hàm sắp xếp() có vẻ dễ dùng hơn so với hàm sắp xếp(), vì vậy bạn nên sử dụng hàm sắp xếp().
Bạn có thể tuỳ chỉnh hàm được sắp xếp thông qua các đối số không bắt buộc. Đối số tùy chọn được sắp xếp() đảo ngược=True, ví dụ: sắp xếp(danh sách, đảo ngược=Đúng), làm cho nó sắp xếp ngược lại.
strs = ['aa', 'BB', 'zz', 'CC'] print(sorted(strs)) ## ['BB', 'CC', 'aa', 'zz'] (case sensitive) print(sorted(strs, reverse=True)) ## ['zz', 'aa', 'CC', 'BB']
Sắp xếp tuỳ chỉnh bằng khoá=
Đối với cách sắp xếp tuỳ chỉnh phức tạp hơn, Sắp xếp() sẽ lấy một "key=" tuỳ chọn chỉ định một "khoá" biến đổi từng phần tử trước khi so sánh. Hàm chính nhận 1 giá trị và trả về 1 giá trị, cùng với "proxy" được trả về giá trị được dùng cho các phép so sánh trong sắp xếp.
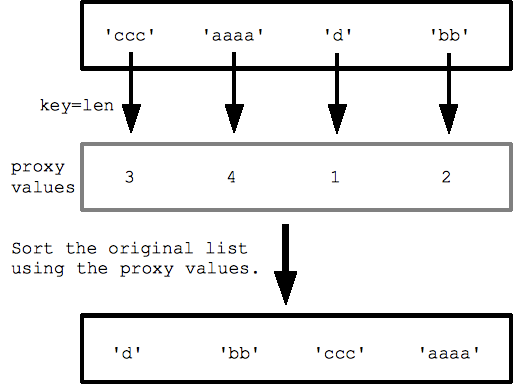
Ví dụ: với danh sách chuỗi, việc chỉ định key=len (hàm len() tích hợp sẵn) sẽ sắp xếp các chuỗi theo độ dài, từ ngắn nhất đến dài nhất. Thao tác sắp xếp này sẽ gọi len() cho mỗi chuỗi để lấy danh sách các giá trị độ dài proxy rồi sắp xếp theo các giá trị proxy đó.
strs = ['ccc', 'aaaa', 'd', 'bb'] print(sorted(strs, key=len)) ## ['d', 'bb', 'ccc', 'aaaa']
Một ví dụ khác là việc chỉ định "str.lower" vì hàm chính là một cách để buộc sắp xếp xử lý chữ hoa và chữ thường giống nhau:
## "key" argument specifying str.lower function to use for sorting print(sorted(strs, key=str.lower)) ## ['aa', 'BB', 'CC', 'zz']
Bạn cũng có thể truyền vào MyFn của riêng mình dưới dạng hàm chính, như sau:
## Say we have a list of strings we want to sort by the last letter of the string. strs = ['xc', 'zb', 'yd' ,'wa'] ## Write a little function that takes a string, and returns its last letter. ## This will be the key function (takes in 1 value, returns 1 value). def MyFn(s): return s[-1] ## Now pass key=MyFn to sorted() to sort by the last letter: print(sorted(strs, key=MyFn)) ## ['wa', 'zb', 'xc', 'yd']
Để sắp xếp phức tạp hơn, chẳng hạn như sắp xếp theo họ, sau đó theo tên, bạn có thể dùng các hàm itemgetter hoặc attrgetter như:
from operator import itemgetter # (first name, last name, score) tuples grade = [('Freddy', 'Frank', 3), ('Anil', 'Frank', 100), ('Anil', 'Wang', 24)] sorted(grade, key=itemgetter(1,0)) # [('Anil', 'Frank', 100), ('Freddy', 'Frank', 3), ('Anil', 'Wang', 24)] sorted(grade, key=itemgetter(0,-1)) #[('Anil', 'Wang', 24), ('Anil', 'Frank', 100), ('Freddy', 'Frank', 3)]
phương thức sắp xếp()
Thay vì sắp xếp(), phương thứcsort() trên danh sách sẽ sắp xếp danh sách đó theo thứ tự tăng dần, ví dụ: list.sort(). Phương thứcsort() thay đổi danh sách cơ bản và trả về Không có, vì vậy hãy sử dụng như sau:
alist.sort() ## correct alist = blist.sort() ## Incorrect. sort() returns None
Trên đây là một hiểu lầm rất phổ biến vớisort() -- phương thức này *không trả về* danh sách được sắp xếp. Phương thức Sort() phải được gọi trên một danh sách; nó không hoạt động trên bất kỳ tập hợp có thể liệt kê nào (nhưng hàm được sắp xếp() ở trên hoạt động trên bất kỳ thứ gì). Phương thức sắp xếp() này chạy trước hàm được sắp xếp, vì vậy, bạn có thể sẽ thấy phương thức này trong mã cũ hơn. Phương thức Sort() không cần tạo danh sách mới, vì vậy, phương thức này có thể nhanh hơn một chút trong trường hợp các phần tử cần sắp xếp đã có trong danh sách.
Bộ đôi
Bộ dữ liệu là một nhóm các phần tử có kích thước cố định, chẳng hạn như toạ độ (x, y). Bộ dữ liệu giống như danh sách, ngoại trừ việc chúng không thể thay đổi và không thay đổi kích thước (bộ dữ liệu không hoàn toàn bất biến vì một trong các phần tử được chứa có thể thay đổi được). Các bộ đôi phát một loại "cấu trúc" vai trò trong Python -- một cách thuận tiện để truyền gói giá trị nhỏ có kích thước cố định, hợp lý. Một hàm cần trả về nhiều giá trị chỉ có thể trả về một bộ dữ liệu giá trị. Ví dụ: nếu tôi muốn có một danh sách các toạ độ 3-d, biểu diễn python tự nhiên sẽ là một danh sách các bộ dữ liệu, trong đó mỗi bộ dữ liệu có kích thước 3 chứa một nhóm (x, y, z).
Để tạo một bộ dữ liệu, chỉ cần liệt kê các giá trị trong dấu ngoặc đơn được phân tách bằng dấu phẩy. Trường "trống" bộ dữ liệu chỉ là một cặp dấu ngoặc đơn trống. Việc truy cập các phần tử trong một bộ dữ liệu cũng giống như một danh sách – len(), [ ], for, in, v.v. đều hoạt động như nhau.
tuple = (1, 2, 'hi') print(len(tuple)) ## 3 print(tuple[2]) ## hi tuple[2] = 'bye' ## NO, tuples cannot be changed tuple = (1, 2, 'bye') ## this works
Để tạo một bộ dữ liệu kích thước 1, bạn phải theo sau phần tử đơn lẻ đó bằng dấu phẩy.
tuple = ('hi',) ## size-1 tuple
Đây là một trường hợp hài hước về cú pháp, nhưng dấu phẩy là cần thiết để phân biệt bộ dữ liệu với trường hợp thông thường của việc đặt một biểu thức trong dấu ngoặc đơn. Trong một số trường hợp, bạn có thể bỏ qua dấu ngoặc đơn và Python sẽ thấy từ dấu phẩy mà bạn dự định dùng để tạo bộ nguồn.
Việc chỉ định một bộ dữ liệu cho một bộ dữ liệu tên biến có kích thước bằng nhau sẽ chỉ định tất cả các giá trị tương ứng. Nếu các bộ dữ liệu không cùng kích thước, hệ thống sẽ báo lỗi. Tính năng này cũng áp dụng cho danh sách.
(x, y, z) = (42, 13, "hike") print(z) ## hike (err_string, err_code) = Foo() ## Foo() returns a length-2 tuple
Mức độ hiểu danh sách (không bắt buộc)
Đọc hiểu danh sách là một tính năng nâng cao hơn. Tính năng này rất hữu ích với một số trường hợp nhưng không cần thiết cho các bài tập và không phải là điều bạn cần phải học lúc đầu (tức là bạn có thể bỏ qua phần này). Mức hiểu danh sách là một cách gọn nhẹ để viết một biểu thức mở rộng thành toàn bộ danh sách. Giả sử chúng ta có một danh sách các số [1, 2, 3, 4], đây là mức hiểu danh sách để tính toán danh sách các bình phương của chúng [1, 4, 9, 16]:
nums = [1, 2, 3, 4] squares = [ n * n for n in nums ] ## [1, 4, 9, 16]
Cú pháp là [ expr for var in list ] -- for var in list trông giống như một vòng lặp thông thường, nhưng không có dấu hai chấm (:). expr ở bên trái được đánh giá một lần cho mỗi phần tử để cung cấp các giá trị cho danh sách mới. Dưới đây là ví dụ về các chuỗi, trong đó mỗi chuỗi được thay đổi thành chữ hoa với '!!!' được thêm vào:
strs = ['hello', 'and', 'goodbye'] shouting = [ s.upper() + '!!!' for s in strs ] ## ['HELLO!!!', 'AND!!!', 'GOODBYE!!!']
Bạn có thể thêm phép thử if ở bên phải của vòng lặp for để thu hẹp kết quả. Kiểm thử nếu được đánh giá cho từng phần tử, chỉ bao gồm các phần tử mà kiểm thử là đúng.
## Select values <= 2 nums = [2, 8, 1, 6] small = [ n for n in nums if n <= 2 ] ## [2, 1] ## Select fruits containing 'a', change to upper case fruits = ['apple', 'cherry', 'banana', 'lemon'] afruits = [ s.upper() for s in fruits if 'a' in s ] ## ['APPLE', 'BANANA']
Bài tập: list1.py
Để thực hành tài liệu trong phần này, hãy thử các bài toán sau trong list1.py có sử dụng tính năng sắp xếp và bộ dữ liệu (trong Bài tập cơ bản).