Python có một lớp chuỗi tích hợp sẵn tên là "str" có nhiều tính năng tiện lợi (có một mô-đun cũ hơn tên là "string" mà bạn không nên sử dụng). Hằng chuỗi có thể được đưa vào trong dấu nháy kép hoặc dấu nháy đơn, mặc dù dấu nháy đơn thường được dùng hơn. Các ký tự thoát dấu gạch chéo ngược hoạt động theo cách thông thường trong cả giá trị cố định đơn và ngoặc kép – ví dụ: \n\n \". Chuỗi trích dẫn kép có thể chứa dấu nháy đơn mà không có gì phiền toái (ví dụ: "Tôi không làm") và tương tự, chuỗi trích dẫn đơn có thể chứa dấu ngoặc kép. Giá trị cố định kiểu chuỗi có thể kéo dài nhiều dòng, nhưng phải có dấu gạch chéo ngược \ ở cuối mỗi dòng để thoát khỏi dòng mới. Chuỗi ký tự trong dấu ngoặc kép, """ hoặc ''', có thể kéo dài nhiều dòng văn bản.
Chuỗi Python là "không thể thay đổi" có nghĩa là bạn không thể thay đổi chúng sau khi tạo (các chuỗi Java cũng sử dụng kiểu bất biến này). Vì các chuỗi không thể thay đổi được, nên chúng ta sẽ tạo các chuỗi *mới* trong quá trình biểu thị các giá trị đã tính. Chẳng hạn, biểu thức ('hello' + 'here') nhận 2 chuỗi 'hello' và 'ở đó' và tạo một chuỗi mới "hellothe".
Các ký tự trong chuỗi có thể truy cập được bằng cú pháp [ ] chuẩn và giống như Java và C++, Python sử dụng chỉ mục dựa trên 0, vì vậy, nếu s là 'hello' s[1] là "e". Nếu chỉ mục nằm ngoài giới hạn của chuỗi, Python sẽ đưa ra thông báo lỗi. Kiểu Python (không giống như Perl) sẽ tạm dừng nếu không thể biết cần làm gì, thay vì chỉ tạo một giá trị mặc định. "Lát cắt" tiện lợi cú pháp (bên dưới) cũng dùng để trích xuất chuỗi con bất kỳ từ chuỗi. Hàm len(string) trả về độ dài của một chuỗi. Cú pháp [ ] và hàm len() thực sự hoạt động trên bất kỳ loại trình tự nào -- chuỗi, danh sách, v.v. Python cố gắng đảm bảo các thao tác hoạt động nhất quán trên nhiều loại. dành cho người mới sử dụng Python: không dùng "len" làm tên biến để tránh chặn hàm len(). Dấu "+" toán tử có thể nối hai chuỗi. Lưu ý trong mã bên dưới rằng các biến không được khai báo trước – chỉ cần chỉ định cho các biến đó và tiếp tục.
s = 'hi' print(s[1]) ## i print(len(s)) ## 2 print(s + ' there') ## hi there
Không giống như Java, dấu '+' không tự động chuyển đổi số hoặc các loại khác thành dạng chuỗi. Hàm str() chuyển đổi các giá trị thành dạng chuỗi để các giá trị này có thể được kết hợp với các chuỗi khác.
pi = 3.14 ##text = 'The value of pi is ' + pi ## NO, does not work text = 'The value of pi is ' + str(pi) ## yes
Đối với số, các toán tử chuẩn, +, /, * hoạt động theo cách thông thường. Không có toán tử ++ nhưng có hoạt động +=, -=, v. v. Nếu bạn muốn phân chia số nguyên, hãy sử dụng 2 dấu gạch chéo -- ví dụ: 6 // 5 là 1
"In" thường in một hoặc nhiều mục python theo sau là một dòng mới. Trạng thái "thô" giá trị cố định kiểu chuỗi có tiền tố là "r" và chuyển tất cả ký tự mà không đặc biệt xử lý dấu gạch chéo ngược, vì vậy r'x\nx' cho kết quả là chuỗi có độ dài 4 là "x\nx". "in" có thể thực hiện một số đối số để thay đổi cách nó in nội dung (xem định nghĩa hàm print python.org), chẳng hạn như đặt "kết thúc" thành "" để không in dòng mới sau khi in xong tất cả các mục.
raw = r'this\t\n and that' # this\t\n and that print(raw) multi = """It was the best of times. It was the worst of times.""" # It was the best of times. # It was the worst of times. print(multi)
Phương thức chuỗi
Dưới đây là một số phương thức chuỗi phổ biến nhất. Một phương thức giống như một hàm, nhưng chạy "on" (bật) một đối tượng. Nếu biến s là một chuỗi, thì mã s.lower() sẽ chạy phương thức lower() trên đối tượng chuỗi đó và trả về kết quả (ý tưởng này về một phương thức chạy trên một đối tượng là một trong những ý tưởng cơ bản tạo nên Lập trình hướng đối tượng, OOP). Dưới đây là một số phương thức chuỗi phổ biến nhất:
- s.lower(), s.upper() -- trả về phiên bản chữ thường hoặc chữ hoa của chuỗi
- s.strip() – trả về một chuỗi có khoảng trắng bị xoá ở đầu và cuối
- s.isalpha()/s.isdigit()/s.isspace()... -- kiểm tra xem tất cả các ký tự chuỗi có nằm trong các lớp ký tự khác nhau hay không
- s.startswith('other'), s.endswith('other') -- kiểm tra xem chuỗi bắt đầu hoặc kết thúc bằng chuỗi khác đã cho
- s.find('other') -- tìm kiếm chuỗi khác đã cho (không phải biểu thức chính quy) trong s và trả về chỉ mục đầu tiên khi chuỗi bắt đầu hoặc -1 nếu không tìm thấy
- s.replace('old', 'new') -- trả về một chuỗi trong đó tất cả các lần xuất hiện của 'old' đã được thay thế bằng "mới"
- s.Split('delim') -- trả về danh sách chuỗi con được phân tách bằng dấu phân tách đã cho. Dấu phân cách không phải là một biểu thức chính quy mà chỉ là văn bản. 'aaa,bbb,cpc'.Split(',') -> ['aaa', 'bbb', 'cpc']. Dưới dạng trường hợp đặc biệt thuận tiện s.Split() (không có đối số) phân tách trên tất cả ký tự khoảng trắng.
- s.join(list) – đối diện với Split(), kết hợp các phần tử trong danh sách cho trước bằng cách sử dụng chuỗi làm dấu phân tách. ví dụ: '---'.join(['aaa', 'bbb', 'cpc']) -> aaa---bbb---ccc
Tìm kiếm "python str" trên Google sẽ đưa bạn đến phương thức chuỗi python.org chính thức. Phương thức này liệt kê tất cả các phương thức str.
Python không có một loại ký tự riêng biệt. Thay vào đó, một biểu thức như s[8] trả về một string-length-1 chứa ký tự đó. Với string-length-1 đó, các toán tử ==, <=, ... đều hoạt động như mong đợi, vì vậy, hầu hết bạn không cần phải biết rằng Python không có "char" vô hướng riêng biệt loại.
Lát cắt chuỗi
"Lát cắt" là một cách thuận tiện để tham chiếu đến các phần phụ của trình tự – thường là chuỗi và danh sách. Lát cắt s[start:end] là các phần tử bắt đầu từ điểm bắt đầu và kéo dài đến nhưng không bao gồm điểm kết thúc. Giả sử chúng ta có s = "Xin chào"
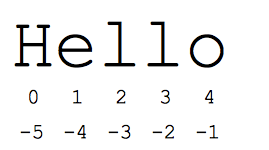
- s[1:4] là 'ell' -- các ký tự bắt đầu từ chỉ mục 1 và mở rộng đến nhưng không bao gồm chỉ mục 4
- s[1:] là "ello" -- bỏ qua chỉ mục mặc định là đầu hoặc cuối chuỗi
- s[:] là 'Xin chào' -- bỏ qua cả hai sẽ luôn mang lại cho chúng ta bản sao của toàn bộ nội dung (đây là cáchpythonic để sao chép một chuỗi như chuỗi hoặc danh sách)
- s[1:100] là "ello" -- chỉ mục quá lớn bị cắt bớt xuống độ dài chuỗi
Số chỉ mục chuẩn dựa trên số 0 giúp dễ dàng truy cập vào các ký tự gần đầu chuỗi. Thay vào đó, Python sử dụng các số âm để dễ dàng truy cập vào các ký tự ở cuối chuỗi: s[-1] là ký tự cuối cùng 'o', s[-2] là 'l' ký tự kế tiếp kế tiếp, v.v. Số chỉ mục âm sẽ đếm ngược trở lại từ cuối chuỗi:
- s[-1] là "o" -- ký tự cuối cùng (thứ nhất tính từ cuối)
- s[-4] là 'e' -- thứ 4 tính từ cuối
- s[:-3] là 'Anh ấy' -- tối đa nhưng không bao gồm 3 ký tự cuối cùng.
- s[-3:] là 'llo' -- bắt đầu bằng ký tự thứ 3 từ cuối chuỗi và kéo dài đến cuối chuỗi.
Đây là dữ liệu ngắn gọn của các lát cắt cho chỉ mục n, s[:n] + s[n:] == s. Hàm này hoạt động ngay cả với n âm hoặc nằm ngoài giới hạn. Hoặc đặt theo cách khác, s[:n] và s[n:] luôn phân vùng chuỗi thành hai phần chuỗi, bảo toàn tất cả các ký tự. Như chúng ta sẽ thấy trong phần danh sách sau này, các lát cắt cũng hoạt động với danh sách.
Định dạng chuỗi
Một việc gọn gàng mà trăn có thể làm là tự động chuyển đổi các đối tượng thành một chuỗi phù hợp để in. Hai cách có sẵn để thực hiện việc này là định dạng chuỗi cố định, còn được gọi là "f-strings" và gọi str.format().
Hằng chuỗi được định dạng
Bạn thường thấy giá trị cố định kiểu chuỗi được định dạng được sử dụng trong các trường hợp như:
value = 2.791514 print(f'approximate value = {value:.2f}') # approximate value = 2.79 car = {'tires':4, 'doors':2} print(f'car = {car}') # car = {'tires': 4, 'doors': 2}
Một chuỗi ký tự được định dạng có tiền tố là 'f' (như tiền tố 'r' được sử dụng cho các chuỗi thô). Bất kỳ văn bản nào bên ngoài dấu ngoặc nhọn '{}' được in trực tiếp. Biểu thức có trong '{}' là được in ra theo thông số kỹ thuật định dạng được mô tả trong quy cách định dạng. Bạn có thể thực hiện rất nhiều thao tác gọn gàng với định dạng bao gồm cắt bớt và chuyển đổi sang ký hiệu khoa học và căn chỉnh trái/phải/giữa.
Các chuỗi f rất hữu ích khi bạn muốn in một bảng các đối tượng và muốn các cột đại diện cho các thuộc tính khác nhau của đối tượng cần được căn chỉnh như
address_book = [{'name':'N.X.', 'addr':'15 Jones St', 'bonus': 70}, {'name':'J.P.', 'addr':'1005 5th St', 'bonus': 400}, {'name':'A.A.', 'addr':'200001 Bdwy', 'bonus': 5},] for person in address_book: print(f'{person["name"]:8} || {person["addr"]:20} || {person["bonus"]:>5}') # N.X. || 15 Jones St || 70 # J.P. || 1005 5th St || 400 # A.A. || 200001 Bdwy || 5
Chuỗi %
Python cũng có một phương thức cũ giống như printf() để tập hợp một chuỗi. Toán tử % lấy chuỗi định dạng kiểu printf ở bên trái (chuỗi %d int, %s, dấu phẩy động %f/%g) và các giá trị khớp trong một bộ dữ liệu ở bên phải (một bộ dữ liệu được tạo từ các giá trị được phân tách bằng dấu phẩy, thường được nhóm bên trong dấu ngoặc đơn):
# % operator text = "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house')
Dòng ở trên hơi dài -- giả sử bạn muốn chia thành các dòng riêng biệt. Bạn không thể tách dòng sau '%' như đối với các ngôn ngữ khác, vì theo mặc định, Python coi mỗi dòng là một câu lệnh riêng (ở bên cộng, đây là lý do chúng ta không cần nhập dấu chấm phẩy trên mỗi dòng). Để khắc phục vấn đề này, hãy đặt toàn bộ biểu thức trong bộ dấu ngoặc đơn bên ngoài -- sau đó biểu thức được phép kéo dài nhiều dòng. Kỹ thuật dòng mã này hoạt động với nhiều cấu trúc nhóm khác nhau được nêu chi tiết bên dưới: ( ), [ ], { }.
# Add parentheses to make the long line work: text = ( "%d little pigs come out, or I'll %s, and I'll %s, and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
Như vậy tốt hơn, nhưng đường này vẫn còn hơi dài. Python cho phép bạn cắt một đường thẳng thành các đoạn rồi tự động nối các đoạn này. Vì vậy, để rút ngắn dòng này, chúng ta có thể làm như sau:
# Split the line into chunks, which are concatenated automatically by Python text = ( "%d little pigs come out, " "or I'll %s, and I'll %s, " "and I'll blow your %s down." % (3, 'huff', 'puff', 'house'))
Chuỗi (Unicode so với byte)
Các chuỗi Python thông thường là Unicode.
Python cũng hỗ trợ các chuỗi bao gồm các byte thuần tuý (được biểu thị bằng tiền tố "b" trước một giá trị cố định kiểu chuỗi) như:
> byte_string = b'A byte string' > byte_string b'A byte string'
Chuỗi Unicode là một loại đối tượng khác với một chuỗi byte nhưng có nhiều thư viện, chẳng hạn như biểu thức chính quy hoạt động chính xác nếu được chuyển một trong hai loại chuỗi.
Để chuyển đổi một chuỗi Python thông thường thành byte, hãy gọi phương thức encode() trên chuỗi. Đi theo hướng khác, phương thức giải mã chuỗi byte() sẽ chuyển đổi các byte thuần tuý được mã hoá thành một chuỗi unicode:
> ustring = 'A unicode \u018e string \xf1' > b = ustring.encode('utf-8') > b b'A unicode \xc6\x8e string \xc3\xb1' ## bytes of utf-8 encoding. Note the b-prefix. > t = b.decode('utf-8') ## Convert bytes back to a unicode string > t == ustring ## It's the same as the original, yay!True
Trong phần đọc tệp, có một ví dụ cho thấy cách mở một tệp văn bản bằng một số phương thức mã hoá và đọc to các chuỗi Unicode.
Câu lệnh If
Python không sử dụng { } để đóng các khối mã cho if/vòng/hàm, v.v. Thay vào đó, Python sử dụng dấu hai chấm (:) và dấu thụt đầu dòng/khoảng trắng để nhóm các câu lệnh. Kiểm thử boolean cho một if không cần đặt trong ngoặc đơn (khác biệt lớn so với C++/Java) và nó có thể có mệnh đề *elif* và *else* (ghi nhớ: từ "elif" có cùng độ dài với từ "else").
Có thể dùng giá trị bất kỳ làm hàm if-test. "Số 0" tất cả giá trị đều được tính là false: Không có, 0, chuỗi trống, danh sách trống, từ điển trống. Ngoài ra còn có loại Boolean có hai giá trị: True và False (được chuyển đổi thành int, các giá trị này là 1 và 0). Python có các thao tác so sánh thông thường: ==, !=, <, <=, >, >=. Không giống như Java và C, == bị quá tải để hoạt động chính xác với các chuỗi. Toán tử boolean là các từ được viết ra *and*, *or*, *not* (Python không sử dụng kiểu C && || !). Dưới đây là ví dụ về mã mà một ứng dụng sức khoẻ đưa ra đề xuất về thức uống suốt cả ngày – hãy chú ý đến cách mỗi khối câu lệnh then/else bắt đầu bằng : và các câu lệnh được nhóm theo mức thụt lề của chúng:
if time_hour >= 0 and time_hour <= 24: print('Suggesting a drink option...') if mood == 'sleepy' and time_hour < 10: print('coffee') elif mood == 'thirsty' or time_hour < 2: print('lemonade') else: print('water')
Tôi thấy rằng bỏ qua ":" là lỗi cú pháp phổ biến nhất của tôi khi nhập loại mã ở trên, có thể vì đó là một nội dung bổ sung để nhập so với thói quen C++/Java của tôi. Ngoài ra, đừng đặt phép kiểm thử boolean trong dấu ngoặc đơn – đó là thói quen C/Java. Nếu mã ngắn, bạn có thể đặt mã trên cùng một dòng sau ":", như thế này (điều này cũng áp dụng cho các hàm, vòng lặp, v.v.), mặc dù một số người cảm thấy dễ đọc hơn khi đặt mọi thứ trên các dòng riêng biệt.
if time_hour < 10: print('coffee') else: print('water')
Bài tập: string1.py
Để thực hành tài liệu trong phần này, hãy thử làm bài tập string1.py trong Bài tập cơ bản.