
コミュニティ コネクタを作成する場合、スキーマに定義する各フィールドにはデータ型が必要です。データ型は、BOOLEAN、STRING、NUMBER などのフィールドのプリミティブ型を定義します。
Looker Studio では、データ型に加えてセマンティック型も使用します。セマンティック型は、データが表す情報の種類を記述することができます。たとえば、NUMBER データ型のフィールドでは意味的に通貨額や割合を表したり、STRING データ型のフィールドでは意味的に都市を表したりすることができます。利用可能なセマンティック型を確認するには、セマンティック型に関するドキュメントをご覧ください。
コミュニティ コネクタのスキーマと Looker Studio のフィールド
コミュニティ コネクタのスキーマを定義する際は、各フィールドのさまざまなプロパティによって、Looker Studio でのフィールドの表現方法と使用方法が決まります。例:
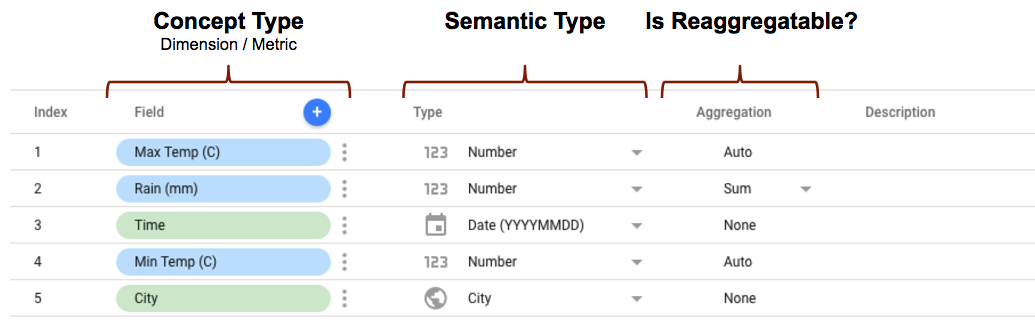
- conceptTypeconceptType は、
conceptTypeプロパティを使用してコネクタ スキーマで定義されます。このプロパティによって、フィールドをディメンションとして扱うか指標として扱うかが決まります。 指標とディメンションの違いについては、ディメンションと指標をご覧ください。 - セマンティック型は、コネクタ スキーマで定義できます。また、コネクタで定義されたデータ型プロパティとコネクタから返されるデータ値に基づいて Looker Studio で自動的に検出することもできます。この仕組みの詳細については、自動セマンティック型検出をご覧ください。
- 集計タイプによって、指標値(ディメンションは無視されます)を再集計できるかどうかが決まります。
semantics.isReaggregatableプロパティをtrueに設定すると、デフォルトでSUM集計になります。それ以外の場合は、Autoに設定されます。defaultAggregationTypeプロパティを使用すると、再集計可能なフィールドのデフォルトの集計型を手動で設定することもできます。
Looker Studio のコネクタを使用して構成と接続を行うと、フィールド エディタに、上記のプロパティの定義に基づいてコネクタの完全なスキーマが表示されます。セマンティック型を含めている場合は、定義したとおりに表示されます。自動セマンティック型検出を使用している場合は、検出されたとおりにフィールドが表示されます。
セマンティック情報の設定
セマンティック情報を設定する方法は 2 つあります。フィールド セマンティクスは、手動で設定することも、Looker Studio で自動的に検出することもできます。
たとえば、意味的に米ドルを表す数値がある場合、Looker Studio ではこのセマンティック型を自動的に検出できません。また、自動セマンティック検出では、Looker Studio がスキーマの各フィールドに対してデータ取得呼び出しを行う必要があります。代わりにスキーマを手動で指定すると、データ取得の呼び出しは行われません。データのセマンティック型(通貨、割合、日付など)がわかっている場合は、精度とパフォーマンス上の理由からスキーマにセマンティック型を明示的に設定することをおすすめします。
セマンティック型の手動設定(推奨)
セマンティック型がわかっている場合は、各スキーマ フィールドの semantics を手動で定義できます。利用可能なプロパティについて詳しくは、フィールドのリファレンス ページをご覧ください。手動セマンティック型を定義する場合は、すべてのフィールドに対して semanticType と semanticGroup を定義することをおすすめします。これらのプロパティを手動で指定すると、自動セマンティック型検出プロセスは実行されません。一部のフィールドのみを手動で設定した場合、指定していないフィールドは、そのフィールドに指定された dataType に応じて、デフォルトで Text、Number、または Boolean に設定されます。
セマンティック型を手動で設定する単純なスキーマの例を次に示します。Income は通貨として設定され、Filing Year は日付として設定されます。
手動セマンティック型のトラブルシューティング
基になるデータに対してセマンティック型を正しく設定していない場合、データが適切に表示されません。テストで問題を特定するのは難しい場合がありますが、以下のヒントを参考にしてください。
- データからすべての行ではなく 2、3 行を返し、手動で検査します。
- Looker Studio で、チェックするフィールドのみを使用するテーブルを作成します。
- 形式が厳密な
GeoフィールドとDateフィールドは、特に注意して確認してください。
自動セマンティック型検出
スキーマでセマンティック型を定義していない場合、Looker Studio は、データ型プロパティとコネクタから返されるデータ値の形式に基づいて、セマンティック型を自動的に検出しようとします。
自動検出のプロセスは次のとおりです。
- コミュニティ コネクタの
getSchema関数を実行してスキーマをリクエストします。 - コネクタ スキーマで定義されている一連のフィールドを反復処理し、フィールドに対して
getDataリクエストを発行します。getDataリクエストは、sampleExtractionパラメータがtrueに設定されて実行されます。これは、データ リクエストがセマンティック検出を目的としていることを示します。 - フィールド データ型と
getDataリクエストから返された値の形式に基づいて、フィールドのセマンティック型を識別します。
自動セマンティック型検出を制御するオプション
Looker Studio がセマンティック検出を目的としてコミュニティ コネクタの getData 関数を実行すると、受信リクエストには、true に設定された sampleExtraction プロパティが含まれます。コネクタから返されるデータは、フィールドのセマンティック型を Looker Studio が識別するためにのみ使用されます。この値は他の目的には使用されないため、外部ソースからの実際のデータは必要ありません。
コードでセマンティック型検出を改善するには、次のようないくつかの方法があります。
推奨: 事前定義された値を渡す
フィールドのセマンティック型を最もよく表し、Looker Studio で正しく検出できることが確認されている、各フィールドの事前定義された値を返します。たとえば、フィールドのセマンティック型が Country の場合、イタリアを表すITなどの値を返します。データを取得するためにサードパーティ サービスに対して HTTP リクエストを行う必要がないため、この方法には検出プロセスを高速化できるという利点もあります。nn 個のレコードのみを返す
データを取得するサードパーティのサービスがデータのリクエスト時に行数制限をサポートしている場合は、完全なデータセットではなく、行の小さなサブセットを Looker Studio に返します。これにより、セマンティック検出リクエストごとに Looker Studio に渡す必要があるデータの量が制限されます。すべての列をリクエストし、レスポンスをキャッシュに保存する
データの取得元であるサードパーティ サービスのすべての列をリクエストできる場合、Looker Studio から受信した最初のセマンティック検出リクエストで、すべての列が取得され、結果がキャッシュに保存されます。それ以降のセマンティック検出リクエストでは、サードパーティ サービスに対して追加の HTTP リクエストを行わずにキャッシュから列の値を取得します。特に何もしない
sampleExtractionがtrueに設定されているリクエストに対して具体的な対処を実装しないことを選択できます。これにより、Looker Studio はセマンティック検出プロセスのためにすべてのデータを取得する必要があるため、セマンティック検出プロセスの速度が低下します。また、多くのセマンティック検出リクエストが並行して実行されるため、外部データソースへのリクエスト率にも影響があります。
自動セマンティック型検出で認識される形式
日時
YYYY/MM/DD-HH:MM:SSYYYY-MM-DD [HH:MM:SS[.uuuuuu]]YYYY/MM/DD [HH:MM:SS[.uuuuuu]]YYYYMMDD [HH:MM:SS[.uuuuuu]]Sat, 24 May 2008 20:09:47 GMT2008-05-24T20:09:47Z- 時間: 秒、マイクロ秒、ミリ秒、ナノ秒のエポック。
地域
- 大陸名またはコード
- 亜大陸名またはコード
- 地域名またはコード
- 国名またはコード。ISO_3166-1 もご覧ください。
- 市町村名
- カンマ区切りの緯度と経度の値
- 指定マーケット エリア(DMA)名とコード