Halaman ini berisi istilah glosarium Dasar-Dasar ML. Untuk semua istilah glosarium, klik di sini.
A
akurasi
Jumlah prediksi klasifikasi yang benar dibagi dengan jumlah total prediksi. Definisinya yaitu:
Misalnya, model yang membuat 40 prediksi yang benar dan 10 prediksi yang salah akan memiliki akurasi:
Klasifikasi biner memberikan nama tertentu untuk berbagai kategori prediksi yang benar dan prediksi yang salah. Jadi, rumus akurasi untuk klasifikasi biner adalah sebagai berikut:
dengan:
- TP adalah jumlah positif benar (prediksi yang benar).
- TN adalah jumlah negatif benar (prediksi yang benar).
- FP adalah jumlah positif palsu (prediksi yang salah).
- FN adalah jumlah negatif palsu (prediksi yang salah).
Bandingkan dan bedakan akurasi dengan presisi dan perolehan.
Lihat Klasifikasi: Akurasi, perolehan, presisi, dan metrik terkait di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
fungsi aktivasi
Fungsi yang memungkinkan jaringan neural mempelajari hubungan non-linear (kompleks) antara fitur dan label.
Fungsi aktivasi populer meliputi:
Plot fungsi aktivasi tidak pernah berupa garis lurus tunggal. Misalnya, plot fungsi aktivasi ReLU terdiri dari dua garis lurus:

Plot fungsi aktivasi sigmoid akan terlihat seperti berikut:

Klik ikon untuk melihat contoh.
Dalam jaringan saraf, fungsi aktivasi memanipulasi jumlah tertimbang dari semua input ke neuron. Untuk menghitung jumlah tertimbang, neuron menjumlahkan produk dari nilai dan bobot yang relevan. Misalnya, anggap saja input yang relevan ke neuron terdiri dari hal berikut:
| nilai input | berat masukan |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
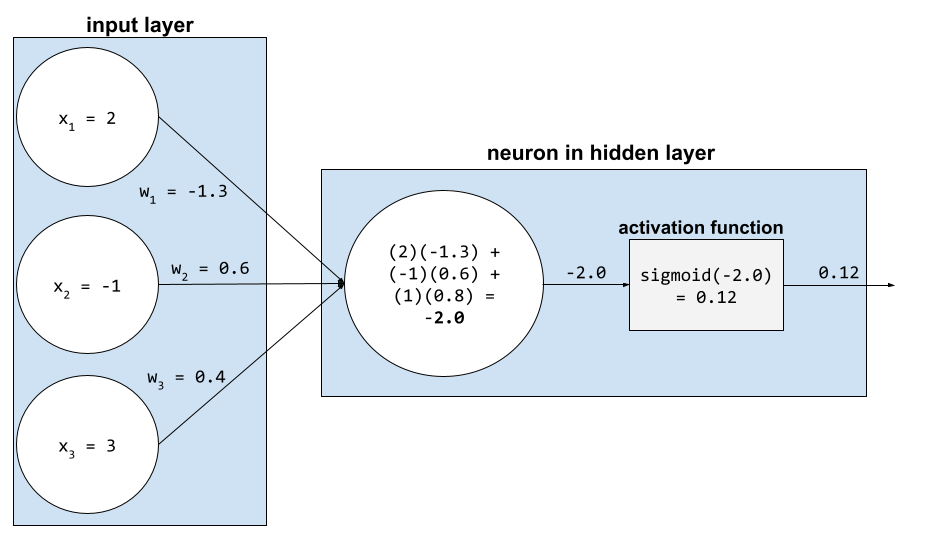
Lihat Jaringan neural: Fungsi aktivasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
kecerdasan buatan
Program atau model non-manusia yang dapat menyelesaikan tugas-tugas rumit. Misalnya, program atau model yang menerjemahkan teks atau program atau model yang mengidentifikasi penyakit dari gambar radiologi keduanya menunjukkan kecerdasan buatan.
Secara formal, machine learning adalah subbidang kecerdasan buatan. Namun, dalam beberapa tahun terakhir, beberapa organisasi mulai menggunakan istilah kecerdasan buatan dan machine learning secara bergantian.
AUC (Area di bawah kurva ROC)
Angka antara 0,0 dan 1,0 yang merepresentasikan kemampuan model klasifikasi biner untuk memisahkan kelas positif dari kelas negatif. Semakin dekat AUC ke 1,0, semakin baik kemampuan model untuk memisahkan kelas satu sama lain.
Misalnya, ilustrasi berikut menunjukkan model klasifikasi yang memisahkan kelas positif (oval hijau) dari kelas negatif (persegi panjang ungu) dengan sempurna. Model yang sempurna secara tidak realistis ini memiliki AUC 1,0:

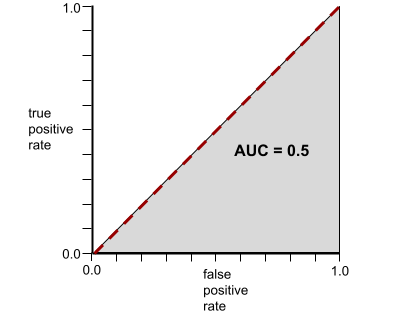
Sebaliknya, ilustrasi berikut menunjukkan hasil untuk model klasifikasi yang menghasilkan hasil acak. Model ini memiliki AUC 0,5:

Ya, model sebelumnya memiliki AUC 0,5, bukan 0,0.
Sebagian besar model berada di antara kedua ekstrem tersebut. Misalnya, model berikut memisahkan positif dari negatif, dan oleh karena itu memiliki AUC antara 0,5 dan 1,0:

AUC mengabaikan nilai apa pun yang Anda tetapkan untuk nilai minimum klasifikasi. Sebagai gantinya, AUC mempertimbangkan semua kemungkinan batas klasifikasi.
Klik ikon untuk mempelajari hubungan antara AUC dan kurva ROC.
AUC merepresentasikan area di bawah kurva ROC. Misalnya, kurva ROC untuk model yang memisahkan positif dari negatif dengan sempurna terlihat seperti berikut:
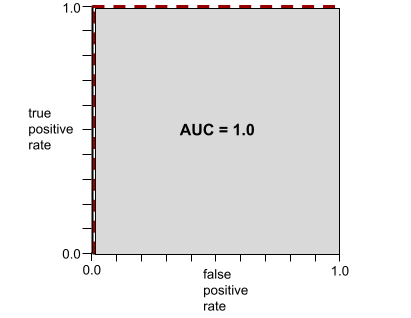
AUC adalah area wilayah abu-abu dalam ilustrasi sebelumnya. Dalam kasus yang tidak biasa ini, area tersebut hanyalah panjang area abu-abu (1.0) dikalikan dengan lebar area abu-abu (1.0). Jadi, hasil kali 1,0 dan 1,0 menghasilkan AUC tepat 1,0, yang merupakan skor AUC tertinggi yang mungkin.
Sebaliknya, kurva ROC untuk model klasifikasi yang tidak dapat memisahkan kelas sama sekali adalah sebagai berikut. Area abu-abu ini adalah 0,5.
Kurva ROC yang lebih umum terlihat kira-kira seperti berikut:
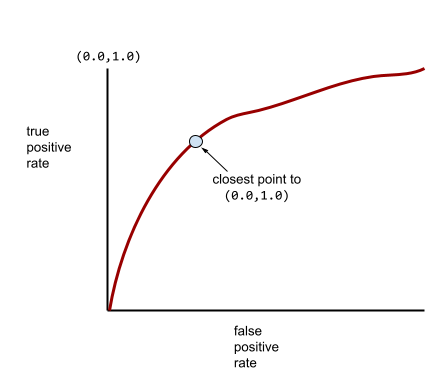
Akan sangat sulit untuk menghitung luas area di bawah kurva ini secara manual, itulah sebabnya program biasanya menghitung sebagian besar nilai AUC.
Lihat Klasifikasi: KOP dan ABK di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
B
propagasi mundur
Algoritma yang menerapkan penurunan gradien dalam jaringan neural.
Pelatihan jaringan neural melibatkan banyak iterasi dari siklus dua tahap berikut:
- Selama forward pass, sistem memproses batch contoh untuk menghasilkan prediksi. Sistem membandingkan setiap prediksi dengan setiap nilai label. Perbedaan antara prediksi dan nilai label adalah kerugian untuk contoh tersebut. Sistem menggabungkan kerugian untuk semua contoh guna menghitung total kerugian untuk batch saat ini.
- Selama backward pass (backpropagation), sistem mengurangi kerugian dengan menyesuaikan bobot semua neuron di semua lapisan tersembunyi.
Jaringan neural sering kali berisi banyak neuron di banyak lapisan tersembunyi. Setiap neuron tersebut berkontribusi pada kerugian keseluruhan dengan cara yang berbeda. Backpropagation menentukan apakah akan menambah atau mengurangi bobot yang diterapkan pada neuron tertentu.
Learning rate adalah pengganda yang mengontrol tingkat kenaikan atau penurunan setiap bobot di setiap operasi backward. Kecepatan pembelajaran yang besar akan menaikkan atau menurunkan setiap bobot lebih banyak daripada kecepatan pembelajaran yang kecil.
Dalam istilah kalkulus, backpropagation menerapkan aturan rantai. dari kalkulus. Artinya, backpropagation menghitung turunan parsial dari error yang terkait dengan setiap parameter.
Beberapa tahun lalu, praktisi ML harus menulis kode untuk menerapkan backpropagation. API ML modern seperti Keras kini menerapkan backpropagation untuk Anda. Fiuh!
Lihat Jaringan neural di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
batch
Kumpulan contoh yang digunakan dalam satu iterasi pelatihan. Ukuran batch menentukan jumlah contoh dalam batch.
Lihat epoch untuk penjelasan tentang hubungan batch dengan epoch.
Lihat Regresi linear: Hyperparameter di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
ukuran batch
Jumlah contoh dalam batch. Misalnya, jika ukuran batch adalah 100, model akan memproses 100 contoh per iterasi.
Berikut adalah strategi ukuran batch yang populer:
- Penurunan Gradien Stokastik (SGD), dengan ukuran tumpukan 1.
- Batch penuh, dengan ukuran batch adalah jumlah contoh dalam set pelatihan secara keseluruhan. Misalnya, jika set pelatihan berisi satu juta contoh, maka ukuran batchnya adalah satu juta contoh. Batch penuh biasanya merupakan strategi yang tidak efisien.
- Tumpukan mini dengan ukuran tumpukan biasanya antara 10 dan 1.000. Tumpukan mini biasanya merupakan strategi yang paling efisien.
Lihat informasi selengkapnya di sini:
- Sistem ML produksi: Inferensi statis versus dinamis dalam Kursus Singkat Machine Learning.
- Deep Learning Tuning Playbook.
bias (etika/keadilan)
1. Stereotip, prasangka, atau preferensi terhadap beberapa hal, orang, atau kelompok dibandingkan yang lain. Bias ini dapat memengaruhi pengumpulan dan interpretasi data, desain sistem, dan cara pengguna berinteraksi dengan sistem. Bentuk bias jenis ini meliputi:
- bias otomatisasi
- bias konfirmasi
- bias pelaku eksperimen
- bias atribusi kelompok
- bias implisit
- bias dalam golongan
- bias kehomogenan luar golongan
2. Error sistematis yang disebabkan oleh prosedur sampling atau pelaporan. Bentuk bias jenis ini meliputi:
Harap bedakan dengan istilah bias dalam model machine learning atau bias prediksi.
Lihat Fairness: Types of bias di Machine Learning Crash Course untuk mengetahui informasi selengkapnya.
bias (matematika) atau istilah bias
Intersep atau ofset dari asal. Bias adalah parameter dalam model machine learning, yang disimbolkan oleh salah satu dari berikut ini:
- b
- w0
Misalnya, bias bernilai b dalam formula berikut:
Dalam garis dua dimensi sederhana, bias hanya berarti "intersep y". Misalnya, bias garis dalam ilustrasi berikut adalah 2.
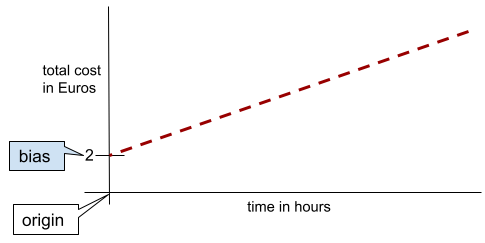
Bias ada karena tidak semua model dimulai dari titik asal (0,0). Misalnya, anggaplah biaya masuk taman hiburan adalah 2 Euro dan biaya tambahan 0,5 Euro untuk setiap jam pelanggan berada di sana. Oleh karena itu, model yang memetakan total biaya memiliki bias 2 karena biaya terendah adalah 2 Euro.
Bias tidak boleh disamakan dengan bias dalam etika dan fairness atau bias prediksi.
Lihat Regresi Linear di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
klasifikasi biner
Jenis tugas klasifikasi yang memprediksi salah satu dari dua kelas yang saling eksklusif:
Misalnya, dua model machine learning berikut masing-masing melakukan klasifikasi biner:
- Model yang menentukan apakah pesan email adalah spam (kelas positif) atau bukan spam (kelas negatif).
- Model yang mengevaluasi gejala medis untuk menentukan apakah seseorang menderita penyakit tertentu (kelas positif) atau tidak menderita penyakit tersebut (kelas negatif).
Berbeda dengan klasifikasi multikelas.
Lihat juga regresi logistik dan nilai minimum klasifikasi.
Lihat Klasifikasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
pengelompokan
Mengonversi satu fitur menjadi beberapa fitur biner yang disebut bucket atau bin, biasanya berdasarkan rentang nilai. Fitur yang dipotong biasanya merupakan fitur berkelanjutan.
Misalnya, alih-alih merepresentasikan suhu sebagai satu fitur floating point berkelanjutan, Anda dapat membagi rentang suhu ke dalam bucket diskrit, seperti:
- <= 10 derajat Celsius akan menjadi bucket "dingin".
- 11 - 24 derajat Celsius akan menjadi kelompok "sedang".
- >= 25 derajat Celsius akan menjadi kategori "hangat".
Model akan memperlakukan setiap nilai dalam bucket yang sama secara identik. Misalnya, nilai 13 dan 22 keduanya berada dalam bucket sedang, sehingga model memperlakukan kedua nilai tersebut secara identik.
Lihat Data numerik: Pengelompokan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
C
data kategorik
Fitur yang memiliki set kemungkinan nilai tertentu. Misalnya, pertimbangkan fitur kategoris bernama traffic-light-state, yang hanya dapat memiliki salah satu dari tiga kemungkinan nilai berikut:
redyellowgreen
Dengan merepresentasikan traffic-light-state sebagai fitur kategoris,
model dapat mempelajari
dampak yang berbeda dari red, green, dan yellow pada perilaku pengemudi.
Fitur kategorik terkadang disebut fitur diskrit.
Berbeda dengan data numerik.
Lihat Bekerja dengan data kategoris di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
class
Kategori yang dapat dimiliki oleh label. Contoh:
- Dalam model klasifikasi biner yang mendeteksi spam, dua kelasnya mungkin adalah spam dan bukan spam.
- Dalam model klasifikasi multi-kelas yang mengidentifikasi ras, kelasnya mungkin pudel, beagle, pug, dan sebagainya.
Model klasifikasi memprediksi kelas. Sebaliknya, model regresi memprediksi angka, bukan kelas.
Lihat Klasifikasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
model klasifikasi
Model yang prediksinya adalah class. Misalnya, berikut adalah semua model klasifikasi:
- Model yang memprediksi bahasa kalimat input (Prancis? Spanyol? Italia?).
- Model yang memprediksi spesies pohon (Maple? Oak? Baobab?).
- Model yang memprediksi kelas positif atau negatif untuk kondisi medis tertentu.
Sebaliknya, model regresi memprediksi angka, bukan kelas.
Dua jenis model klasifikasi yang umum adalah:
nilai minimum klasifikasi
Dalam klasifikasi biner, angka antara 0 dan 1 yang mengonversi output mentah model regresi logistik menjadi prediksi kelas positif atau kelas negatif. Perhatikan bahwa nilai minimum klasifikasi adalah nilai yang dipilih oleh manusia, bukan nilai yang dipilih oleh pelatihan model.
Model regresi logistik menghasilkan nilai mentah antara 0 dan 1. Lalu:
- Jika nilai mentah ini lebih besar dari nilai minimum klasifikasi, maka kelas positif diprediksi.
- Jika nilai mentah ini kurang dari nilai minimum klasifikasi, maka kelas negatif diprediksi.
Misalnya, anggap batas klasifikasi adalah 0,8. Jika nilai mentahnya adalah 0,9, model memprediksi kelas positif. Jika nilai mentahnya adalah 0,7, model memprediksi kelas negatif.
Pilihan batas klasifikasi sangat memengaruhi jumlah positif palsu dan negatif palsu.
Lihat Nilai minimum dan matriks kebingungan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
pengklasifikasi
Istilah umum untuk model klasifikasi.
set data kelas tidak seimbang
Set data untuk klasifikasi dengan jumlah total label setiap kelas berbeda secara signifikan. Misalnya, pertimbangkan set data klasifikasi biner yang dua labelnya dibagi sebagai berikut:
- 1.000.000 label negatif
- 10 label positif
Rasio label negatif terhadap positif adalah 100.000 banding 1, jadi ini adalah set data kelas tidak seimbang.
Sebaliknya, set data berikut seimbang menurut kelas karena rasio label negatif terhadap label positif relatif mendekati 1:
- 517 label negatif
- 483 label positif
Set data multikelas juga dapat memiliki kelas yang tidak seimbang. Misalnya, set data klasifikasi multi-kelas berikut juga tidak seimbang karena satu label memiliki lebih banyak contoh daripada dua label lainnya:
- 1.000.000 label dengan class "hijau"
- 200 label dengan class "ungu"
- 350 label dengan class "orange"
Melatih set data kelas tidak seimbang dapat menimbulkan tantangan khusus. Lihat Kumpulan data yang tidak seimbang di Kursus Singkat Machine Learning untuk mengetahui detailnya.
Lihat juga entropi, kelas mayoritas, dan kelas minoritas.
kliping
Teknik untuk menangani pencilan dengan melakukan salah satu atau kedua hal berikut:
- Mengurangi nilai fitur yang lebih besar dari nilai maksimum hingga ke nilai maksimum tersebut.
- Meningkatkan nilai fitur yang kurang dari nilai minimum hingga nilai minimum tersebut.
Misalnya, anggaplah <0,5% nilai untuk fitur tertentu berada di luar rentang 40–60. Dalam hal ini, Anda dapat melakukan hal berikut:
- Klip semua nilai di atas 60 (nilai maksimum) menjadi tepat 60.
- Klip semua nilai di bawah 40 (nilai minimum) menjadi tepat 40.
Pencilan dapat merusak model, terkadang menyebabkan bobot meluap selama pelatihan. Beberapa pencilan juga dapat merusak metrik seperti akurasi secara drastis. Pemangkasan adalah teknik umum untuk membatasi kerusakan.
Pengekangan gradien memaksa nilai gradien dalam rentang yang ditentukan selama pelatihan.
Lihat Data numerik: Normalisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
matriks konfusi
Tabel NxN yang merangkum jumlah prediksi benar dan salah yang dibuat oleh model klasifikasi. Misalnya, perhatikan matriks kebingungan berikut untuk model klasifikasi biner:
| Tumor (diprediksi) | Non-Tumor (prediksi) | |
|---|---|---|
| Tumor (kebenaran nyata) | 18 (TP) | 1 (FN) |
| Non-Tumor (kebenaran nyata) | 6 (FP) | 452 (TN) |
Matriks konfusi di atas menunjukkan hal berikut:
- Dari 19 prediksi yang kebenaran nyatanya adalah Tumor, model mengklasifikasikan 18 dengan benar dan 1 dengan salah.
- Dari 458 prediksi yang kebenaran nyatanya adalah Non-Tumor, model mengklasifikasikan 452 dengan benar dan 6 dengan salah.
Matriks kebingungan untuk masalah klasifikasi multi-kelas dapat membantu Anda mengidentifikasi pola kesalahan. Misalnya, pertimbangkan matriks kebingungan berikut untuk model klasifikasi multikelas 3 kelas yang mengategorikan tiga jenis iris yang berbeda (Virginica, Versicolor, dan Setosa). Saat kebenaran dasarnya adalah Virginica, matriks kebingungan menunjukkan bahwa model jauh lebih mungkin keliru memprediksi Versicolor daripada Setosa:
| Setosa (prediksi) | Versicolor (prediksi) | Virginica (diprediksi) | |
|---|---|---|---|
| Setosa (kebenaran dasar) | 88 | 12 | 0 |
| Versicolor (kebenaran nyata) | 6 | 141 | 7 |
| Virginica (kebenaran dasar) | 2 | 27 | 109 |
Sebagai contoh lain, matriks konfusi dapat mengungkapkan bahwa model yang dilatih untuk mengenali digit tulisan tangan cenderung salah memprediksi 9 bukannya 4, atau salah memprediksi 1 bukannya 7.
Matriks kebingungan berisi informasi yang cukup untuk menghitung berbagai metrik performa, termasuk presisi dan perolehan.
fitur berkelanjutan
Fitur floating point dengan rentang nilai tak terhingga yang mungkin, seperti suhu atau berat.
Berbeda dengan fitur diskrit.
konvergensi
Status yang dicapai saat nilai loss hanya sedikit berubah atau tidak berubah sama sekali dengan setiap iterasi. Misalnya, kurva kerugian berikut menunjukkan konvergensi pada sekitar 700 iterasi:
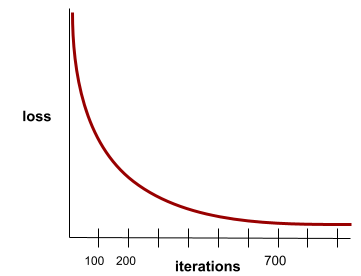
Model berkonvergensi saat pelatihan tambahan tidak akan meningkatkan kualitas model.
Dalam deep learning, nilai kerugian terkadang tetap konstan atau hampir konstan selama banyak iterasi sebelum akhirnya menurun. Selama periode panjang nilai kerugian yang konstan, Anda mungkin untuk sementara mendapatkan rasa konvergensi yang salah.
Lihat juga penghentian awal.
Lihat Konvergensi model dan kurva kerugian di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
D
DataFrame
Jenis data pandas yang populer untuk merepresentasikan set data dalam memori.
DataFrame dapat dianalogikan dengan tabel atau spreadsheet. Setiap kolom DataFrame memiliki nama (header), dan setiap baris diidentifikasi oleh angka unik.
Setiap kolom dalam DataFrame disusun seperti array 2D, kecuali setiap kolom dapat ditetapkan jenis datanya sendiri.
Lihat juga halaman pandas.DataFrame reference page resmi.
kumpulan data atau set data (data set atau dataset)
Kumpulan data mentah, biasanya (tetapi tidak secara eksklusif) disusun dalam salah satu format berikut:
- spreadsheet
- file dalam format CSV (nilai yang dipisahkan koma)
deep model
Jaringan neural yang berisi lebih dari satu lapisan tersembunyi.
Model dalam juga disebut deep neural network.
Berbeda dengan model lebar.
fitur padat
Fitur yang sebagian besar atau semua nilainya bukan nol, biasanya Tensor nilai floating point. Misalnya, Tensor 10 elemen berikut bersifat padat karena 9 nilainya bukan nol:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
Berbeda dengan fitur renggang.
kedalaman
Jumlah berikut dalam jaringan neural:
- jumlah lapisan tersembunyi
- jumlah lapisan output, yang biasanya 1
- jumlah lapisan embedding
Misalnya, jaringan neural dengan lima lapisan tersembunyi dan satu lapisan keluaran memiliki kedalaman 6.
Perhatikan bahwa lapisan input tidak memengaruhi kedalaman.
fitur diskret
Fitur dengan set kemungkinan nilai yang terbatas. Misalnya, fitur yang nilainya hanya dapat berupa hewan, sayuran, atau mineral adalah fitur diskrit (atau kategoris).
Berbeda dengan fitur berkelanjutan.
dinamis
Sesuatu yang dilakukan sering atau terus-menerus. Istilah dinamis dan online merupakan sinonim dalam machine learning. Berikut adalah penggunaan umum dinamis dan online dalam machine learning:
- Model dinamis (atau model online) adalah model yang dilatih ulang secara sering atau terus-menerus.
- Pelatihan dinamis (atau pelatihan online) adalah proses pelatihan secara sering atau berkelanjutan.
- Inferensi dinamis (atau inferensi online) adalah proses membuat prediksi sesuai permintaan.
model dinamis
Model yang sering (bahkan mungkin terus-menerus) dilatih ulang. Model dinamis adalah "pembelajar seumur hidup" yang terus beradaptasi dengan data yang terus berkembang. Model dinamis juga dikenal sebagai model online.
Berbeda dengan model statis.
E
penghentian awal
Metode regularisasi yang melibatkan pengakhiran pelatihan sebelum kerugian pelatihan selesai menurun. Dalam penghentian awal, Anda sengaja menghentikan pelatihan model saat kerugian pada set data validasi mulai meningkat; yaitu, saat performa generalisasi memburuk.
Berbeda dengan keluar lebih awal.
lapisan penyematan
Hidden layer khusus yang dilatih pada fitur kategoris berdimensi tinggi untuk mempelajari vektor embedding berdimensi lebih rendah secara bertahap. Lapisan penyematan memungkinkan jaringan neural dilatih secara jauh lebih efisien daripada pelatihan hanya pada fitur kategoris berdimensi tinggi.
Misalnya, saat ini Bumi mendukung sekitar 73.000 spesies pohon. Misalkan
spesies pohon adalah fitur dalam model Anda, sehingga lapisan
input model Anda mencakup vektor one-hot sepanjang 73.000 elemen.
Misalnya, baobab mungkin ditampilkan seperti ini:

Array dengan 73.000 elemen sangat panjang. Jika Anda tidak menambahkan lapisan embedding ke model, pelatihan akan sangat memakan waktu karena mengalikan 72.999 angka nol. Mungkin Anda memilih lapisan penyematan yang terdiri dari 12 dimensi. Oleh karena itu, lapisan embedding akan secara bertahap mempelajari vektor embedding baru untuk setiap spesies pohon.
Dalam situasi tertentu, hashing adalah alternatif yang wajar untuk lapisan penyematan.
Lihat Penyematan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
epoch
Pass pelatihan penuh pada seluruh set pelatihan sehingga setiap contoh telah diproses satu kali.
Epoch mewakili N/iterasi pelatihan ukuran tumpukan, dengan N adalah
jumlah total contoh.
Misalnya, anggap saja hal berikut:
- Set data terdiri dari 1.000 contoh.
- Ukuran batch adalah 50 contoh.
Oleh karena itu, satu epoch memerlukan 20 iterasi:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
Lihat Regresi linear: Hyperparameter di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
contoh
Nilai satu baris fitur dan mungkin label. Contoh dalam supervised learning terbagi dalam dua kategori umum:
- Contoh berlabel terdiri dari satu atau beberapa fitur dan satu label. Contoh berlabel digunakan selama pelatihan.
- Contoh tidak berlabel terdiri dari satu atau beberapa fitur, tetapi tidak memiliki label. Contoh tak berlabel digunakan selama inferensi.
Misalnya, Anda melatih model untuk menentukan pengaruh kondisi cuaca terhadap nilai ujian siswa. Berikut tiga contoh berlabel:
| Fitur | Label | ||
|---|---|---|---|
| Suhu | Kelembapan | Tekanan | Skor pengujian |
| 15 | 47 | 998 | Baik |
| 19 | 34 | 1020 | Luar biasa |
| 18 | 92 | 1012 | Buruk |
Berikut adalah tiga contoh yang tidak berlabel:
| Suhu | Kelembapan | Tekanan | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
Baris set data biasanya merupakan sumber mentah untuk contoh. Artinya, contoh biasanya terdiri dari subset kolom dalam set data. Selain itu, fitur dalam contoh juga dapat mencakup fitur sintetis, seperti persilangan fitur.
Lihat Supervised Learning di kursus Introduction to Machine Learning untuk mengetahui informasi selengkapnya.
F
negatif palsu (NP)
Contoh yang mana model salah memprediksi kelas negatif. Misalnya, model memprediksi bahwa pesan email tertentu bukan spam (kelas negatif), tetapi pesan email tersebut sebenarnya adalah spam.
positif palsu (PP)
Contoh yang mana model salah memprediksi kelas positif. Misalnya, model memprediksi bahwa pesan email tertentu adalah spam (kelas positif), tetapi pesan email tersebut sebenarnya bukan spam.
Lihat Nilai minimum dan matriks kebingungan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
rasio positif palsu (FPR)
Proporsi contoh negatif sebenarnya yang mana model salah memprediksi kelas positif. Formula berikut menghitung rasio positif palsu:
Rasio positif palsu adalah sumbu x dalam kurva ROC.
Lihat Klasifikasi: KOP dan ABK di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
fitur
Variabel input ke model machine learning. Contoh terdiri dari satu atau beberapa fitur. Misalnya, Anda melatih model untuk menentukan pengaruh kondisi cuaca terhadap nilai ujian siswa. Tabel berikut menunjukkan tiga contoh, yang masing-masing berisi tiga fitur dan satu label:
| Fitur | Label | ||
|---|---|---|---|
| Suhu | Kelembapan | Tekanan | Skor pengujian |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
Berbeda dengan label.
Lihat Supervised Learning di kursus Introduction to Machine Learning untuk mengetahui informasi selengkapnya.
persilangan fitur
Fitur sintetis yang dibentuk dengan "menyilangkan" fitur kategoris atau fitur yang dikelompokkan.
Misalnya, pertimbangkan model "perkiraan suasana hati" yang merepresentasikan suhu dalam salah satu dari empat bucket berikut:
freezingchillytemperatewarm
Dan mewakili kecepatan angin dalam salah satu dari tiga bucket berikut:
stilllightwindy
Tanpa persilangan fitur, model linear dilatih secara independen pada masing-masing
tujuh bucket yang berbeda sebelumnya. Jadi, model dilatih, misalnya,
freezing secara terpisah dari pelatihan, misalnya,
windy.
Atau, Anda dapat membuat persilangan fitur suhu dan kecepatan angin. Fitur sintetis ini akan memiliki 12 kemungkinan nilai berikut:
freezing-stillfreezing-lightfreezing-windychilly-stillchilly-lightchilly-windytemperate-stilltemperate-lighttemperate-windywarm-stillwarm-lightwarm-windy
Berkat persilangan fitur, model dapat mempelajari perbedaan mood
antara hari freezing-windy dan hari freezing-still.
Jika Anda membuat fitur sintetis dari dua fitur yang masing-masing memiliki banyak bucket berbeda, persilangan fitur yang dihasilkan akan memiliki sejumlah besar kemungkinan kombinasi. Misalnya, jika satu fitur memiliki 1.000 bucket dan fitur lainnya memiliki 2.000 bucket, persilangan fitur yang dihasilkan memiliki 2.000.000 bucket.
Secara formal, persilangan adalah produk Kartesius.
Persilangan fitur sebagian besar digunakan dengan model linier dan jarang digunakan dengan jaringan saraf tiruan.
Lihat Data kategoris: Persilangan fitur di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
rekayasa fitur
Proses yang melibatkan langkah-langkah berikut:
- Menentukan fitur mana yang mungkin berguna dalam melatih model.
- Mengonversi data mentah dari set data menjadi versi fitur yang efisien.
Misalnya, Anda dapat menentukan bahwa temperature mungkin merupakan fitur yang berguna. Kemudian, Anda dapat bereksperimen dengan pengelompokan
untuk mengoptimalkan apa yang dapat dipelajari model dari berbagai rentang temperature.
Rekayasa fitur terkadang disebut ekstraksi fitur atau featurisasi.
Lihat Data numerik: Cara model menyerap data menggunakan vektor fitur di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
set fitur
Grup fitur tempat model machine learning dilatih. Misalnya, set fitur sederhana untuk model yang memprediksi harga rumah dapat terdiri dari kode pos, ukuran properti, dan kondisi properti.
vektor fitur
Array nilai fitur yang terdiri dari contoh. Vektor fitur dimasukkan selama pelatihan dan selama inferensi. Misalnya, vektor fitur untuk model dengan dua fitur diskrit mungkin adalah:
[0.92, 0.56]
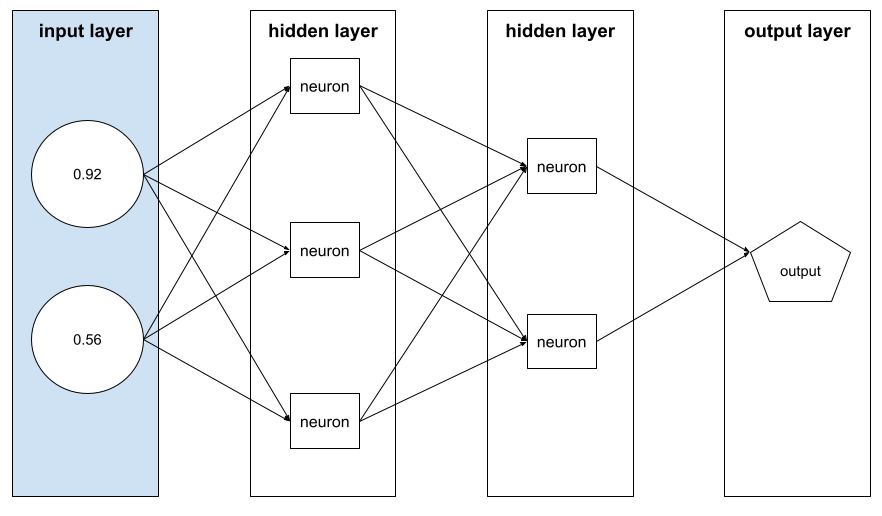
Setiap contoh memberikan nilai yang berbeda untuk vektor fitur, sehingga vektor fitur untuk contoh berikutnya dapat berupa:
[0.73, 0.49]
Rekayasa fitur menentukan cara merepresentasikan fitur dalam vektor fitur. Misalnya, fitur kategoris biner dengan lima kemungkinan nilai dapat direpresentasikan dengan enkode one-hot. Dalam hal ini, bagian vektor fitur untuk contoh tertentu akan terdiri dari empat nol dan satu 1,0 di posisi ketiga, sebagai berikut:
[0.0, 0.0, 1.0, 0.0, 0.0]
Sebagai contoh lain, misalkan model Anda terdiri dari tiga fitur:
- fitur kategorikal biner dengan lima kemungkinan nilai yang direpresentasikan dengan
encoding satu kali; misalnya:
[0.0, 1.0, 0.0, 0.0, 0.0] - fitur kategorikal biner lain dengan tiga kemungkinan nilai yang direpresentasikan
dengan encoding one-hot; misalnya:
[0.0, 0.0, 1.0] - fitur floating point; misalnya:
8.3.
Dalam hal ini, vektor fitur untuk setiap contoh akan direpresentasikan oleh sembilan nilai. Dengan nilai contoh dalam daftar sebelumnya, vektor fitur akan menjadi:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
Lihat Data numerik: Cara model menyerap data menggunakan vektor fitur di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
feedback loop
Dalam machine learning, situasi saat prediksi model memengaruhi data pelatihan untuk model yang sama atau model lain. Misalnya, model yang merekomendasikan film akan memengaruhi film yang dilihat orang, yang kemudian akan memengaruhi model rekomendasi film berikutnya.
Lihat Sistem ML produksi: Pertanyaan yang harus diajukan di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
G
generalisasi
Kemampuan model untuk membuat prediksi yang benar terkait data baru yang sebelumnya tidak terlihat. Model yang dapat melakukan generalisasi adalah kebalikan dari model yang overfitting.
Lihat Generalisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
kurva generalisasi
Plot kerugian pelatihan dan kerugian validasi sebagai fungsi dari jumlah iterasi.
Kurva generalisasi dapat membantu Anda mendeteksi kemungkinan overfitting. Misalnya, kurva generalisasi berikut menunjukkan overfitting karena kerugian validasi pada akhirnya menjadi jauh lebih tinggi daripada kerugian pelatihan.
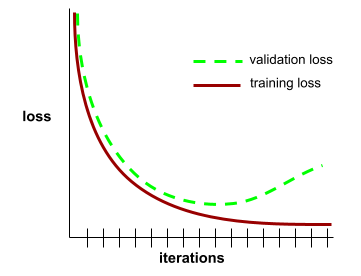
Lihat Generalisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
penurunan gradien
Teknik matematika untuk meminimalkan kerugian. Penurunan gradien menyesuaikan bobot dan bias secara berulang, yang secara bertahap menemukan kombinasi terbaik untuk meminimalkan kerugian.
Penurunan gradien lebih lama—jauh lebih lama—daripada machine learning.
Lihat Regresi linear: Penurunan gradien di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
kebenaran dasar
Realitas.
Hal yang sebenarnya terjadi.
Misalnya, pertimbangkan model klasifikasi biner yang memprediksi apakah seorang mahasiswa tahun pertama di universitas akan lulus dalam waktu enam tahun. Kebenaran dasar untuk model ini adalah apakah siswa tersebut benar-benar lulus dalam waktu enam tahun atau tidak.
H
lapisan tersembunyi
Lapisan dalam jaringan neural antara lapisan input (fitur) dan lapisan output (prediksi). Setiap lapisan tersembunyi terdiri dari satu atau beberapa neuron. Misalnya, jaringan neural berikut berisi dua lapisan tersembunyi, yang pertama dengan tiga neuron dan yang kedua dengan dua neuron:
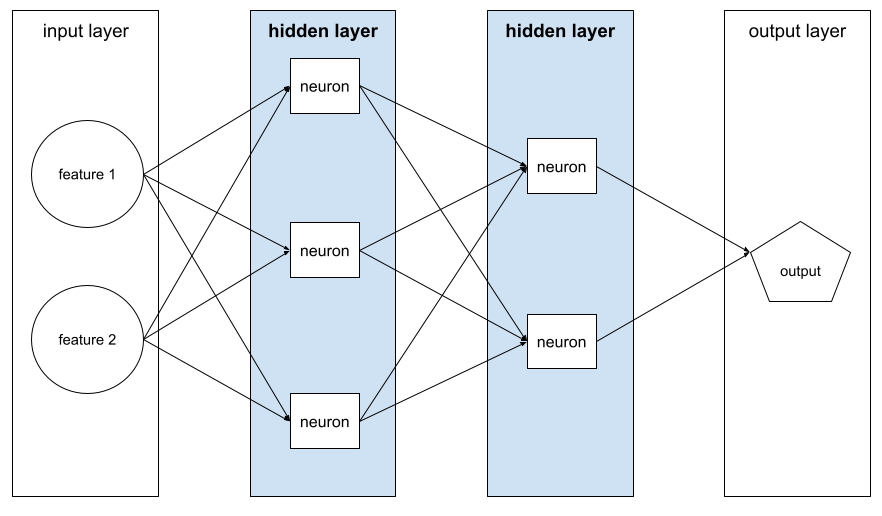
Jaringan neural dalam berisi lebih dari satu lapisan tersembunyi. Misalnya, ilustrasi sebelumnya adalah jaringan neural dalam karena model berisi dua lapisan tersembunyi.
Lihat Jaringan neural: Node dan lapisan tersembunyi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
hyperparameter
Variabel yang Anda atau layanan penyesuaian hyperparameter sesuaikan selama menjalankan pelatihan model berturut-turut. Misalnya, kecepatan pembelajaran adalah hyperparameter. Anda dapat menetapkan laju pembelajaran ke 0,01 sebelum satu sesi pelatihan. Jika Anda menentukan bahwa 0,01 terlalu tinggi, Anda dapat menetapkan kecepatan pembelajaran ke 0,003 untuk sesi pelatihan berikutnya.
Sebaliknya, parameter adalah berbagai bobot dan bias yang dipelajari model selama pelatihan.
Lihat Regresi linear: Hyperparameter di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
I
terdistribusi secara independen dan identik (i.i.d)
Data yang diambil dari distribusi yang tidak berubah, dan setiap nilai yang diambil tidak bergantung pada nilai yang telah diambil sebelumnya. i.i.d. adalah gas ideal machine learning—konstruksi matematis yang berguna, tetapi hampir tidak pernah ditemukan secara persis di dunia nyata. Misalnya, distribusi pengunjung halaman web mungkin terdistribusi secara independen dan identik selama jendela waktu yang singkat; artinya, distribusi tidak berubah selama jendela waktu tersebut dan kunjungan satu orang umumnya tidak bergantung pada kunjungan orang lain. Namun, jika Anda memperluas jangka waktu tersebut, perbedaan musiman pada pengunjung halaman web mungkin muncul.
Lihat juga nonstasioneritas.
model
Dalam machine learning tradisional, proses pembuatan prediksi dengan menerapkan model terlatih ke contoh tak berlabel. Lihat Supervised Learning dalam kursus Pengantar ML untuk mempelajari lebih lanjut.
Dalam model bahasa besar, inferensi adalah proses penggunaan model terlatih untuk menghasilkan respons terhadap perintah input.
Inferensi memiliki arti yang agak berbeda dalam statistik. Lihat artikel Wikipedia tentang inferensi statistik untuk mengetahui detailnya.
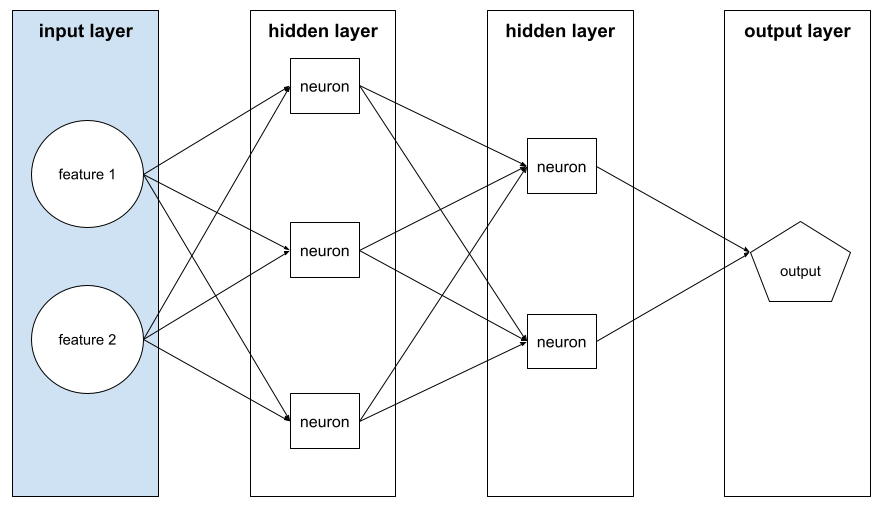
lapisan input
Lapisan jaringan neural yang berisi vektor fitur. Artinya, lapisan input menyediakan contoh untuk pelatihan atau inferensi. Misalnya, lapisan input dalam jaringan neural berikut terdiri dari dua fitur:
dapat ditafsirkan
Kemampuan untuk menjelaskan atau mempresentasikan alasan model ML dalam istilah yang dapat dipahami oleh manusia.
Sebagian besar model regresi linear, misalnya, sangat mudah ditafsirkan. (Anda hanya perlu melihat bobot terlatih untuk setiap fitur.) Hutan keputusan juga sangat mudah ditafsirkan. Namun, beberapa model memerlukan visualisasi yang rumit agar dapat ditafsirkan.
Anda dapat menggunakan Learning Interpretability Tool (LIT) untuk menafsirkan model ML.
iterasi
Satu pembaruan parameter model—bobot dan bias model—selama pelatihan. Ukuran tumpukan menentukan jumlah contoh yang diproses model dalam satu iterasi. Misalnya, jika ukuran batch adalah 20, model akan memproses 20 contoh sebelum menyesuaikan parameter.
Saat melatih jaringan neural, satu iterasi melibatkan dua proses berikut:
- Penerusan maju untuk mengevaluasi kerugian pada satu batch.
- Penerusan mundur (backpropagation) untuk menyesuaikan parameter model berdasarkan kerugian dan kecepatan pembelajaran.
Lihat Penurunan gradien di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
L
Regularisasi L0
Jenis regularisasi yang mengurangi jumlah total bobot bukan nol dalam model. Misalnya, model yang memiliki 11 bobot bukan nol akan dikenai penalti lebih besar daripada model serupa yang memiliki 10 bobot bukan nol.
Regularisasi L0 terkadang disebut regularisasi norma L0.
Kerugian L1
Fungsi kerugian yang menghitung nilai absolut dari perbedaan antara nilai label aktual dan nilai yang diprediksi oleh model. Misalnya, berikut adalah penghitungan kerugian L1 untuk batch lima contoh:
| Nilai sebenarnya contoh | Nilai yang diprediksi model | Nilai absolut delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = kerugian L1 | ||
Kerugian L1 kurang sensitif terhadap pencilan daripada kerugian L2.
Rataan Galat Mutlak adalah rata-rata kerugian L1 per contoh.
Lihat Regresi linear: Loss di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Regularisasi L1
Jenis regularisasi yang mengganjar bobot sesuai dengan jumlah nilai absolut dari bobot. Regularisasi L1 membantu mendorong bobot fitur yang tidak relevan atau hampir tidak relevan menjadi persis 0. Fitur dengan bobot 0 akan dihapus secara efektif dari model.
Berbeda dengan regularisasi L2.
Kerugian L2
Fungsi kerugian yang menghitung kuadrat perbedaan antara nilai label aktual dan nilai yang diprediksi oleh model. Misalnya, berikut adalah penghitungan kerugian L2 untuk batch lima contoh:
| Nilai sebenarnya contoh | Nilai yang diprediksi model | Kuadrat delta |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = kerugian L2 | ||
Karena adanya kuadrat, kerugian L2 memperkuat pengaruh pencilan. Artinya, kerugian L2 bereaksi lebih kuat terhadap prediksi yang buruk daripada kerugian L1. Misalnya, kerugian L1 untuk batch sebelumnya adalah 8, bukan 16. Perhatikan bahwa satu pencilan menyumbang 9 dari 16.
Model regresi biasanya menggunakan kerugian L2 sebagai fungsi kerugian.
Rataan Kuadrat Galat adalah rata-rata kerugian L2 per contoh. Kerugian kuadrat adalah nama lain untuk kerugian L2.
Lihat Regresi logistik: Loss dan regularisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Regularisasi L2
Jenis regularisasi yang mengganjar bobot sesuai dengan jumlah kuadrat bobot. Regularisasi L2 membantu mendorong bobot pencilan (bobot dengan nilai positif tinggi atau negatif rendah) lebih dekat ke 0, tetapi tidak benar-benar 0. Fitur dengan nilai yang sangat mendekati 0 tetap ada dalam model, tetapi tidak terlalu memengaruhi prediksi model.
Regularisasi L2 selalu meningkatkan generalisasi dalam model linear.
Berbeda dengan regularisasi L1.
Lihat Overfitting: Regularisasi L2 di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
label
Dalam supervised machine learning, bagian "jawaban" atau "hasil" dari contoh.
Setiap contoh berlabel terdiri dari satu atau beberapa fitur dan satu label. Misalnya, dalam set data deteksi spam, labelnya mungkin berupa "spam" atau "bukan spam". Dalam set data curah hujan, labelnya mungkin berupa jumlah hujan yang turun selama periode tertentu.
Lihat Supervised Learning di Pengantar Machine Learning untuk mengetahui informasi selengkapnya.
contoh berlabel
Contoh yang berisi satu atau beberapa fitur dan label. Misalnya, tabel berikut menunjukkan tiga contoh berlabel dari model penilaian rumah, yang masing-masing memiliki tiga fitur dan satu label:
| Jumlah kamar | Jumlah kamar mandi | Usia rumah | Harga rumah (label) |
|---|---|---|---|
| 3 | 2 | 15 | $345.000 |
| 2 | 1 | 72 | $179.000 |
| 4 | 2 | 34 | $392.000 |
Dalam supervised machine learning, model dilatih pada contoh berlabel dan membuat prediksi pada contoh tak berlabel.
Bandingkan contoh berlabel dengan contoh yang tidak berlabel.
Lihat Supervised Learning di Pengantar Machine Learning untuk mengetahui informasi selengkapnya.
lambda
Sinonim dari derajat regularisasi.
Lambda adalah istilah yang kelebihan muatan. Di sini kita berfokus pada definisi istilah dalam regularisasi.
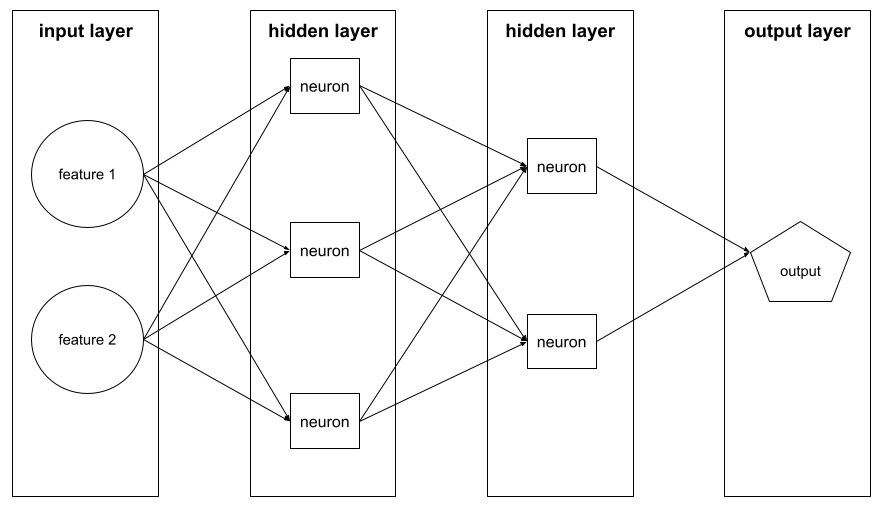
lapisan
Sekumpulan neuron dalam jaringan neural. Tiga jenis lapisan umum adalah sebagai berikut:
- Lapisan input, yang memberikan nilai untuk semua fitur.
- Satu atau beberapa lapisan tersembunyi, yang menemukan hubungan non-linear antara fitur dan label.
- Lapisan output, yang memberikan prediksi.
Misalnya, ilustrasi berikut menunjukkan jaringan neural dengan satu lapisan input, dua lapisan tersembunyi, dan satu lapisan output:
Di TensorFlow, lapisan juga merupakan fungsi Python yang menggunakan Tensor dan opsi konfigurasi sebagai input dan menghasilkan tensor lain sebagai output.
kecepatan pembelajaran
Angka floating point yang memberi tahu algoritma penurunan gradien seberapa kuat bobot dan bias harus disesuaikan pada setiap iterasi. Misalnya, kecepatan pembelajaran 0,3 akan menyesuaikan bobot dan bias tiga kali lebih kuat daripada kecepatan pembelajaran 0,1.
Kecepatan pembelajaran adalah hyperparameter utama. Jika Anda menyetel kecepatan pembelajaran terlalu rendah, pelatihan akan memakan waktu terlalu lama. Jika Anda menetapkan laju pembelajaran terlalu tinggi, penurunan gradien sering kali kesulitan mencapai konvergensi.
Lihat Regresi linear: Hyperparameter di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
linier
Hubungan antara dua variabel atau lebih yang dapat direpresentasikan hanya melalui penjumlahan dan perkalian.
Plot hubungan linear adalah garis.
Berbeda dengan nonlinier.
model linear
Model yang menetapkan satu bobot per fitur untuk membuat prediksi. (Model linear juga menggabungkan bias.) Sebaliknya, hubungan fitur dengan prediksi dalam model dalam umumnya non-linear.
Model linear biasanya lebih mudah dilatih dan lebih dapat ditafsirkan daripada model dalam. Namun, model deep dapat mempelajari hubungan yang kompleks antar fitur.
Regresi linear dan regresi logistik adalah dua jenis model linear.
regresi linear
Jenis model machine learning yang memenuhi kedua kondisi berikut:
- Modelnya adalah model linear.
- Prediksi adalah nilai floating-point. (Ini adalah bagian regresi dari regresi linear.)
Bandingkan regresi linear dengan regresi logistik. Selain itu, bandingkan regresi dengan klasifikasi.
Lihat Regresi linear di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
regresi logistik
Jenis model regresi yang memprediksi probabilitas. Model regresi logistik memiliki karakteristik berikut:
- Labelnya adalah categorical. Istilah regresi logistik biasanya mengacu pada regresi logistik biner, yaitu, pada model yang menghitung probabilitas untuk label dengan dua kemungkinan nilai. Varian yang kurang umum, regresi logistik multinomial, menghitung probabilitas untuk label dengan lebih dari dua kemungkinan nilai.
- Fungsi kerugian selama pelatihan adalah Kerugian Log. (Beberapa unit Log Loss dapat ditempatkan secara paralel untuk label dengan lebih dari dua kemungkinan nilai.)
- Model memiliki arsitektur linear, bukan deep neural network. Namun, bagian lain dari definisi ini juga berlaku untuk model dalam yang memprediksi probabilitas untuk label kategoris.
Misalnya, pertimbangkan model regresi logistik yang menghitung probabilitas email input sebagai spam atau bukan spam. Selama inferensi, misalkan model memprediksi 0,72. Oleh karena itu, model memperkirakan:
- Peluang email tersebut adalah spam sebesar 72%.
- Peluang 28% bahwa email tersebut bukan spam.
Model regresi logistik menggunakan arsitektur dua langkah berikut:
- Model menghasilkan prediksi mentah (y') dengan menerapkan fungsi linear fitur input.
- Model menggunakan prediksi mentah tersebut sebagai input ke fungsi sigmoid, yang mengonversi prediksi mentah menjadi nilai antara 0 dan 1, secara eksklusif.
Seperti model regresi lainnya, model regresi logistik memprediksi angka. Namun, angka ini biasanya menjadi bagian dari model klasifikasi biner sebagai berikut:
- Jika angka yang diprediksi lebih besar daripada nilai minimum klasifikasi, model klasifikasi biner memprediksi kelas positif.
- Jika angka yang diprediksi kurang dari nilai minimum klasifikasi, model klasifikasi biner memprediksi kelas negatif.
Lihat Regresi logistik di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
Kerugian Log
Fungsi kerugian yang digunakan dalam regresi logistik biner.
Lihat Regresi logistik: Loss dan regularisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
log-peluang
Logaritma peluang suatu peristiwa.
kekalahan
Selama pelatihan model yang diawasi, ukuran seberapa jauh prediksi model dari labelnya.
Fungsi kerugian menghitung kerugian.
Lihat Regresi linear: Loss di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
kurva kerugian
Plot loss sebagai fungsi jumlah iterasi pelatihan. Plot berikut menunjukkan kurva kerugian yang umum:
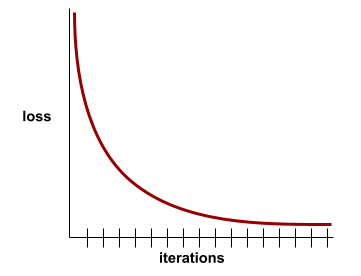
Kurva kerugian dapat membantu Anda menentukan kapan model Anda berkonvergensi atau overfitting.
Kurva kerugian dapat memetakan semua jenis kerugian berikut:
Lihat juga kurva generalisasi.
Lihat Overfitting: Menafsirkan kurva kerugian di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
fungsi kerugian
Selama pelatihan atau pengujian, fungsi matematika yang menghitung kerugian pada batch contoh. Fungsi kerugian menampilkan kerugian yang lebih rendah untuk model yang membuat prediksi baik daripada model yang membuat prediksi buruk.
Tujuan pelatihan biasanya adalah untuk meminimalkan kerugian yang dihasilkan oleh fungsi kerugian.
Ada berbagai jenis fungsi kerugian. Pilih fungsi kerugian yang sesuai untuk jenis model yang Anda buat. Contoh:
- Kerugian L2 (atau Rataan Kuadrat Galat) adalah fungsi kerugian untuk regresi linear.
- Kerugian Log adalah fungsi kerugian untuk regresi logistik.
M
machine learning
Program atau sistem yang melatih model dari data input. Model terlatih dapat menghasilkan prediksi yang bermanfaat dari data baru (yang belum pernah dilihat sebelumnya) yang diambil dari distribusi yang sama dengan yang digunakan untuk melatih model.
Machine learning juga merujuk pada bidang studi yang berkaitan dengan program atau sistem ini.
Lihat kursus Pengantar Machine Learning untuk mengetahui informasi selengkapnya.
kelas mayoritas
Label yang lebih umum dalam set data kelas tidak seimbang. Misalnya, dalam set data yang berisi 99% label negatif dan 1% label positif, label negatif adalah kelas mayoritas.
Berbeda dengan kelas minoritas.
Lihat Set data: Set data tidak seimbang di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
tumpukan mini
Subset kecil yang dipilih secara acak dari batch yang diproses dalam satu iterasi. Ukuran tumpukan dari tumpukan mini biasanya antara 10 dan 1.000 contoh.
Misalnya, anggap saja seluruh set pelatihan (batch penuh) terdiri dari 1.000 contoh. Selanjutnya, misalkan Anda menetapkan ukuran tumpukan setiap tumpukan mini menjadi 20. Oleh karena itu, setiap iterasi menentukan kerugian pada 20 contoh acak dari 1.000 contoh,lalu menyesuaikan bobot dan bias yang sesuai.
Menghitung kerugian pada mini-batch jauh lebih efisien daripada kerugian pada semua contoh dalam batch penuh.
Lihat Regresi linear: Hyperparameter di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
kelas minoritas
Label yang kurang umum dalam set data kelas tidak seimbang. Misalnya, dalam set data yang berisi 99% label negatif dan 1% label positif, label positif adalah kelas minoritas.
Berbeda dengan kelas mayoritas.
Lihat Set data: Set data tidak seimbang di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
model
Secara umum, konstruksi matematika apa pun yang memproses data input dan menampilkan output. Dengan kata lain, model adalah kumpulan parameter dan struktur yang diperlukan agar sistem dapat membuat prediksi. Dalam supervised machine learning, model mengambil contoh sebagai input dan menyimpulkan prediksi sebagai output. Dalam machine learning yang diawasi, model agak berbeda. Contoh:
- Model regresi linear terdiri dari serangkaian bobot dan bias.
- Model jaringan neural terdiri dari:
- Kumpulan lapisan tersembunyi, yang masing-masing berisi satu neuron atau lebih.
- Bobot dan bias yang terkait dengan setiap neuron.
- Model pohon keputusan terdiri dari:
- Bentuk hierarki; yaitu, pola yang menghubungkan kondisi dan leaf.
- Kondisi dan daun.
Anda dapat menyimpan, memulihkan, atau membuat salinan model.
Unsupervised machine learning juga menghasilkan model, biasanya berupa fungsi yang dapat memetakan contoh input ke kelompok yang paling sesuai.
klasifikasi multi-kelas
Dalam supervised learning, masalah klasifikasi dengan set data yang berisi lebih dari dua kelas label. Misalnya, label dalam set data Iris harus berupa salah satu dari tiga kelas berikut:
- Iris setosa
- Iris virginica
- Iris versicolor
Model yang dilatih pada set data Iris yang memprediksi jenis Iris pada contoh baru melakukan klasifikasi multi-class.
Sebaliknya, masalah klasifikasi yang membedakan antara tepat dua kelas adalah model klasifikasi biner. Misalnya, model email yang memprediksi spam atau bukan spam adalah model klasifikasi biner.
Dalam masalah pengelompokan, klasifikasi multikelas mengacu pada lebih dari dua kelompok.
Lihat Jaringan neural: Klasifikasi multi-kelas di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
T
kelas negatif
Dalam klasifikasi biner, satu kelas disebut positif dan kelas lainnya disebut negatif. Kelas positif adalah hal atau peristiwa yang diuji oleh model dan kelas negatif adalah kemungkinan lainnya. Contoh:
- Kelas negatif dalam tes medis dapat berupa "bukan tumor".
- Kelas negatif dalam model klasifikasi email dapat berupa "bukan spam".
Berbeda dengan kelas positif.
alur maju
Model yang berisi setidaknya satu lapisan tersembunyi. Jaringan neural dalam adalah jenis jaringan neural yang berisi lebih dari satu lapisan tersembunyi. Misalnya, diagram berikut menunjukkan jaringan neural dalam yang berisi dua lapisan tersembunyi.
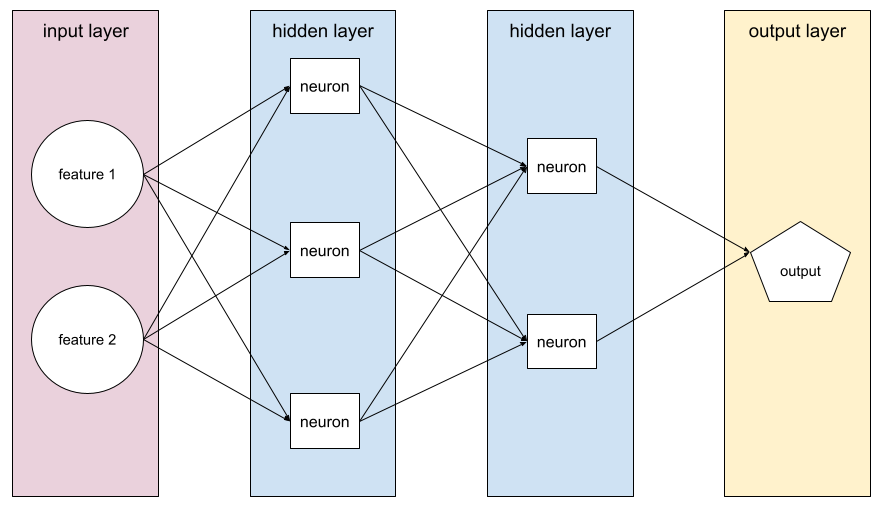
Setiap neuron dalam jaringan neural terhubung ke semua node di lapisan berikutnya. Misalnya, dalam diagram sebelumnya, perhatikan bahwa setiap tiga neuron di lapisan tersembunyi pertama terhubung secara terpisah ke kedua neuron di lapisan tersembunyi kedua.
Jaringan neural yang diterapkan di komputer terkadang disebut jaringan neural buatan untuk membedakannya dari jaringan neural yang ditemukan di otak dan sistem saraf lainnya.
Beberapa jaringan neural dapat meniru hubungan nonlinier yang sangat kompleks antara berbagai fitur dan label.
Lihat juga jaringan neural konvolusional dan jaringan neural berulang.
Lihat Jaringan neural di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
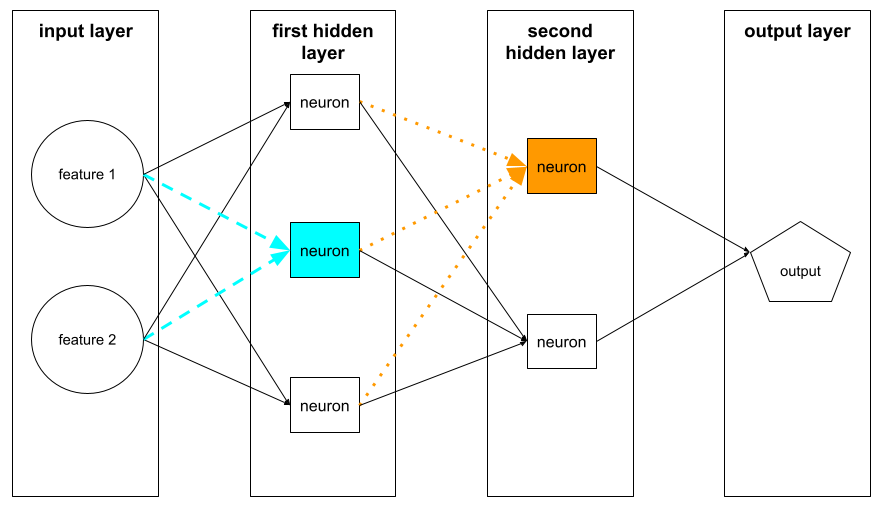
neuron
Dalam machine learning, unit yang berbeda dalam lapisan tersembunyi dari jaringan neural. Setiap neuron melakukan tindakan dua langkah berikut:
- Menghitung jumlah tertimbang dari nilai input yang dikalikan dengan bobot yang sesuai.
- Meneruskan jumlah terbobot sebagai input ke fungsi aktivasi.
Neuron di lapisan tersembunyi pertama menerima input dari nilai fitur di lapisan input. Neuron di lapisan tersembunyi mana pun di luar lapisan pertama menerima input dari neuron di lapisan tersembunyi sebelumnya. Misalnya, neuron di lapisan tersembunyi kedua menerima input dari neuron di lapisan tersembunyi pertama.
Ilustrasi berikut menyoroti dua neuron dan inputnya.
Neuron dalam jaringan neural meniru perilaku neuron dalam otak dan bagian lain sistem saraf.
simpul (jaringan neural)
Neuron di lapisan tersembunyi.
Lihat Jaringan Neural di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
nonlinier
Hubungan antara dua variabel atau lebih yang tidak dapat direpresentasikan hanya melalui penambahan dan perkalian. Hubungan linear dapat direpresentasikan sebagai garis; hubungan nonlinear tidak dapat direpresentasikan sebagai garis. Misalnya, pertimbangkan dua model yang masing-masing menghubungkan satu fitur dengan satu label. Model di sebelah kiri bersifat linear dan model di sebelah kanan bersifat non-linear:

Lihat Jaringan neural: Node dan lapisan tersembunyi di Kursus Singkat Machine Learning untuk bereksperimen dengan berbagai jenis fungsi nonlinier.
nonstasioneritas
Fitur yang nilainya berubah di satu atau beberapa dimensi, biasanya waktu. Misalnya, perhatikan contoh nonstasioneritas berikut:
- Jumlah pakaian renang yang terjual di toko tertentu bervariasi sesuai musim.
- Jumlah buah tertentu yang dipanen di wilayah tertentu adalah nol selama sebagian besar tahun, tetapi besar untuk jangka waktu singkat.
- Akibat perubahan iklim, suhu rata-rata tahunan berubah.
Berbeda dengan stasioneritas.
normalisasi
Secara umum, proses mengonversi rentang nilai sebenarnya variabel menjadi rentang nilai standar, seperti:
- -1 hingga +1
- 0 hingga 1
- Skor Z (kira-kira, -3 hingga +3)
Misalnya, rentang nilai sebenarnya dari fitur tertentu adalah 800 hingga 2.400. Sebagai bagian dari rekayasa fitur, Anda dapat menormalisasi nilai sebenarnya ke rentang standar, seperti -1 hingga +1.
Normalisasi adalah tugas umum dalam rekayasa fitur. Model biasanya dilatih lebih cepat (dan menghasilkan prediksi yang lebih baik) jika setiap fitur numerik dalam vektor fitur memiliki rentang yang hampir sama.
Lihat juga Normalisasi skor Z.
Lihat Data Numerik: Normalisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
data numerik
Fitur yang direpresentasikan sebagai bilangan bulat atau bilangan real-bernilai. Misalnya, model penilaian rumah mungkin merepresentasikan ukuran rumah (dalam kaki persegi atau meter persegi) sebagai data numerik. Merepresentasikan fitur sebagai data numerik menunjukkan bahwa nilai fitur memiliki hubungan matematis dengan label. Artinya, jumlah meter persegi di rumah mungkin memiliki hubungan matematika dengan nilai rumah tersebut.
Tidak semua data bilangan bulat harus direpresentasikan sebagai data numerik. Misalnya,
kode pos di beberapa belahan dunia adalah bilangan bulat; namun, kode pos
bilangan bulat tidak boleh direpresentasikan sebagai data numerik dalam model. Hal ini karena kode pos 20000 tidak dua kali (atau setengah) lebih efektif daripada kode pos 10000. Selain itu, meskipun kode pos yang berbeda berkorelasi dengan nilai properti yang berbeda, kita tidak dapat mengasumsikan bahwa nilai properti di kode pos 20000 dua kali lebih berharga daripada nilai properti di kode pos 10000.
Kode pos sebaiknya direpresentasikan sebagai data kategorik.
Fitur numerik terkadang disebut fitur berkelanjutan.
Lihat Bekerja dengan data numerik di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
O
offline
Sinonim untuk statis.
inferensi offline
Proses model menghasilkan batch prediksi lalu melakukan caching (menyimpan) prediksi tersebut. Aplikasi kemudian dapat mengakses prediksi yang disimpulkan dari cache, bukan menjalankan ulang model.
Misalnya, pertimbangkan model yang membuat perkiraan cuaca lokal (prediksi) sekali setiap empat jam. Setelah setiap sesi model berjalan, sistem akan meng-cache semua perkiraan cuaca lokal. Aplikasi cuaca mengambil perkiraan dari cache.
Inferensi offline juga disebut inferensi statis.
Berbeda dengan inferensi online. Lihat Sistem ML produksi: Inferensi statis versus dinamis di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
enkode one-hot
Merepresentasikan data kategoris sebagai vektor yang:
- Satu elemen disetel ke 1.
- Semua elemen lainnya ditetapkan ke 0.
Enkode one-hot biasanya digunakan untuk merepresentasikan string atau ID yang memiliki kemungkinan set nilai yang terbatas.
Misalnya, anggaplah fitur kategoris tertentu bernama
Scandinavia memiliki lima kemungkinan nilai:
- "Denmark"
- "Swedia"
- "Norwegia"
- "Finlandia"
- "Islandia"
Enkode one-hot dapat merepresentasikan setiap lima nilai sebagai berikut:
| Negara | Vektor | ||||
|---|---|---|---|---|---|
| "Denmark" | 1 | 0 | 0 | 0 | 0 |
| "Swedia" | 0 | 1 | 0 | 0 | 0 |
| "Norwegia" | 0 | 0 | 1 | 0 | 0 |
| "Finlandia" | 0 | 0 | 0 | 1 | 0 |
| "Islandia" | 0 | 0 | 0 | 0 | 1 |
Berkat encoding one-hot, model dapat mempelajari berbagai koneksi berdasarkan masing-masing dari lima negara.
Merepresentasikan fitur sebagai data numerik adalah alternatif untuk enkode one-hot. Sayangnya, merepresentasikan negara-negara Skandinavia secara numerik bukanlah pilihan yang baik. Misalnya, perhatikan representasi numerik berikut:
- "Denmark" adalah 0
- "Swedia" adalah 1
- "Norwegia" adalah 2
- "Finlandia" adalah 3
- "Islandia" adalah 4
Dengan encoding numerik, model akan menafsirkan angka mentah secara matematis dan akan mencoba melatih angka tersebut. Namun, Islandia sebenarnya tidak dua kali lebih banyak (atau setengah lebih banyak) dari sesuatu seperti Norwegia, sehingga model akan sampai pada beberapa kesimpulan yang aneh.
Lihat Data kategoris: Kosakata dan encoding one-hot di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
satu vs. semua
Dalam masalah klasifikasi dengan N kelas, solusi yang terdiri dari N model klasifikasi biner terpisah—satu model klasifikasi biner untuk setiap kemungkinan hasil. Misalnya, dengan model yang mengklasifikasikan contoh sebagai hewan, tumbuhan, atau mineral, solusi satu vs. semua akan memberikan tiga model klasifikasi biner terpisah berikut:
- hewan versus bukan hewan
- sayuran versus bukan sayuran
- mineral versus bukan mineral
online
Sinonim untuk dinamis.
inferensi online
Menghasilkan prediksi sesuai permintaan. Misalnya, anggaplah aplikasi meneruskan input ke model dan mengeluarkan permintaan untuk prediksi. Sistem yang menggunakan inferensi online merespons permintaan dengan menjalankan model (dan menampilkan prediksi ke aplikasi).
Berbeda dengan inferensi offline.
Lihat Sistem ML produksi: Inferensi statis versus dinamis di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
lapisan output
Lapisan "akhir" jaringan neural. Lapisan output berisi prediksi.
Ilustrasi berikut menunjukkan jaringan neural dalam kecil dengan lapisan input, dua lapisan tersembunyi, dan lapisan output:
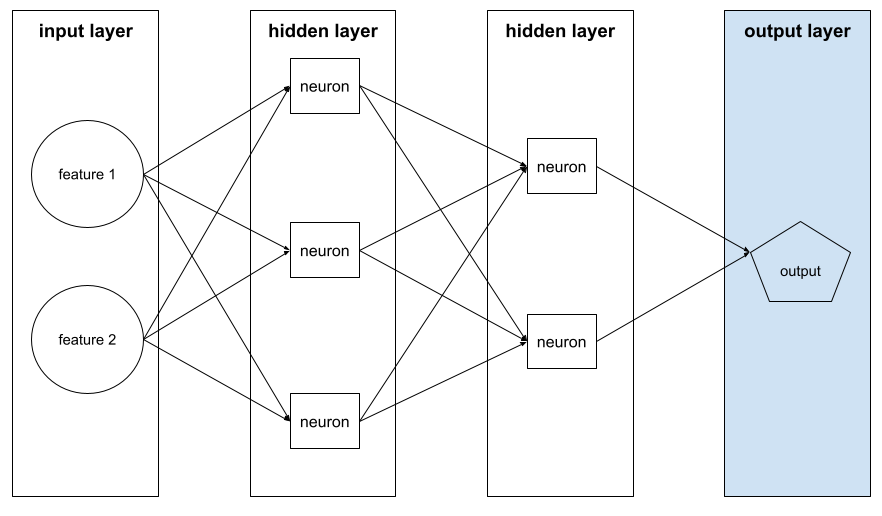
overfitting
Membuat model yang sangat cocok dengan data pelatihan sehingga model gagal membuat prediksi yang benar pada data baru.
Regularisasi dapat mengurangi overfitting. Pelatihan pada set pelatihan yang besar dan beragam juga dapat mengurangi overfitting.
Lihat Overfitting di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
P
pandas
API analisis data berorientasi kolom yang dibangun di atas numpy. Banyak framework machine learning, termasuk TensorFlow, mendukung struktur data pandas sebagai input. Untuk mengetahui detailnya, lihat dokumentasi pandas.
parameter
Bobot dan bias yang dipelajari model selama pelatihan. Misalnya, dalam model regresi linear, parameter terdiri dari bias (b) dan semua bobot (w1, w2, dan seterusnya) dalam formula berikut:
Sebaliknya, hyperparameter adalah nilai yang Anda (atau layanan penyesuaian hyperparameter) berikan ke model. Misalnya, kecepatan pembelajaran adalah hyperparameter.
kelas positif
Kelas yang Anda uji.
Misalnya, kelas positif dalam model kanker dapat berupa "tumor". Kelas positif dalam model klasifikasi email dapat berupa "spam".
Berbeda dengan kelas negatif.
pasca-pemrosesan
Menyesuaikan output model setelah model dijalankan. Pemrosesan pasca dapat digunakan untuk menerapkan batasan keadilan tanpa memodifikasi model itu sendiri.
Misalnya, seseorang dapat menerapkan pasca-pemrosesan ke model klasifikasi biner dengan menetapkan nilai minimum klasifikasi sehingga kesetaraan peluang dipertahankan untuk beberapa atribut dengan memeriksa bahwa rasio positif benar sama untuk semua nilai atribut tersebut.
presisi
Metrik untuk model klasifikasi yang menjawab pertanyaan berikut:
Saat model memprediksi kelas positif, berapa persentase prediksi yang benar?
Berikut rumusnya:
dengan:
- positif benar berarti model dengan benar memprediksi kelas positif.
- positif palsu berarti model salah memprediksi kelas positif.
Misalnya, anggaplah model membuat 200 prediksi positif. Dari 200 prediksi positif ini:
- 150 di antaranya adalah positif benar.
- 50 di antaranya adalah positif palsu.
Dalam hal ini:
Berbeda dengan akurasi dan perolehan.
Lihat Klasifikasi: Akurasi, perolehan, presisi, dan metrik terkait di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
prediksi
Output model. Contoh:
- Prediksi model klasifikasi biner adalah kelas positif atau kelas negatif.
- Prediksi model klasifikasi multi-class adalah satu kelas.
- Prediksi model regresi linear adalah angka.
label proxy
Data yang digunakan untuk memperkirakan label yang tidak tersedia secara langsung dalam set data.
Misalnya, Anda harus melatih model untuk memprediksi tingkat stres karyawan. Dataset Anda berisi banyak fitur prediktif, tetapi tidak berisi label bernama tingkat stres. Tanpa gentar, Anda memilih "kecelakaan di tempat kerja" sebagai label proxy untuk tingkat stres. Bagaimanapun juga, karyawan yang mengalami stres berat lebih sering mengalami kecelakaan daripada karyawan yang tenang. Atau tidak? Mungkin kecelakaan di tempat kerja sebenarnya meningkat dan menurun karena berbagai alasan.
Sebagai contoh kedua, misalkan Anda ingin apakah sedang hujan? menjadi label Boolean untuk set data Anda, tetapi set data Anda tidak berisi data hujan. Jika foto tersedia, Anda mungkin membuat foto orang yang membawa payung sebagai label proxy untuk apakah hujan? Apakah itu label proxy yang bagus? Mungkin, tetapi orang di beberapa budaya mungkin lebih cenderung membawa payung untuk melindungi diri dari sinar matahari daripada hujan.
Label proksi sering kali tidak sempurna. Jika memungkinkan, pilih label sebenarnya daripada label proxy. Namun, jika label sebenarnya tidak ada, pilih label pengganti dengan sangat hati-hati, dengan memilih kandidat label pengganti yang paling tidak buruk.
Lihat Set Data: Label di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
R
RAG
Singkatan dari retrieval-augmented generation.
pemberi rating
Tenaga profesional yang memberikan label untuk contoh. "Anotator" adalah nama lain untuk pemberi rating.
Lihat Data kategoris: Masalah umum di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
ingatan
Metrik untuk model klasifikasi yang menjawab pertanyaan berikut:
Jika kebenaran dasar adalah kelas positif, berapa persentase prediksi yang diidentifikasi model dengan benar sebagai kelas positif?
Berikut rumusnya:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
dengan:
- positif benar berarti model dengan benar memprediksi kelas positif.
- negatif palsu berarti model salah memprediksi kelas negatif.
Misalnya, model Anda membuat 200 prediksi pada contoh yang kebenaran nyatanya adalah kelas positif. Dari 200 prediksi ini:
- 180 di antaranya adalah positif benar.
- 20 adalah negatif palsu.
Dalam hal ini:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Lihat Klasifikasi: Akurasi, perolehan, presisi, dan metrik terkait untuk mengetahui informasi selengkapnya.
Unit Linear Terarah (ReLU)
Fungsi aktivasi dengan perilaku berikut:
- Jika input negatif atau nol, maka outputnya adalah 0.
- Jika input positif, output sama dengan input.
Contoh:
- Jika inputnya adalah -3, maka outputnya adalah 0.
- Jika inputnya adalah +3, maka outputnya adalah 3.0.
Berikut adalah plot ReLU:
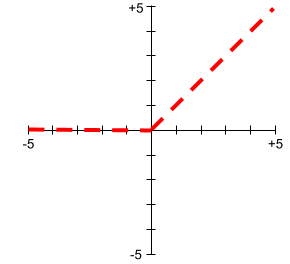
ReLU adalah fungsi aktivasi yang sangat populer. Meskipun perilakunya sederhana, ReLU tetap memungkinkan jaringan neural mempelajari hubungan nonlinier antara fitur dan label.
model regresi
Secara informal, model yang menghasilkan prediksi numerik. (Sebaliknya, model klasifikasi menghasilkan prediksi kelas.) Misalnya, berikut adalah semua model regresi:
- Model yang memprediksi nilai rumah tertentu dalam Euro, seperti 423.000.
- Model yang memprediksi harapan hidup pohon tertentu dalam tahun, seperti 23,2.
- Model yang memprediksi jumlah hujan dalam inci yang akan turun di kota tertentu selama enam jam ke depan, seperti 0,18.
Dua jenis model regresi yang umum adalah:
- Regresi linear, yang menemukan garis yang paling sesuai dengan nilai label ke fitur.
- Regresi logistik, yang menghasilkan probabilitas antara 0,0 dan 1,0 yang biasanya dipetakan oleh sistem ke prediksi kelas.
Tidak semua model yang menghasilkan prediksi numerik adalah model regresi. Dalam beberapa kasus, prediksi numerik sebenarnya hanyalah model klasifikasi yang kebetulan memiliki nama kelas numerik. Misalnya, model yang memprediksi kode pos numerik adalah model klasifikasi, bukan model regresi.
regularisasi
Mekanisme apa pun yang mengurangi overfitting. Jenis regularisasi yang populer meliputi:
- Regularisasi L1
- Regularisasi L2
- regularisasi dengan pelolosan
- penghentian awal (ini bukan metode regularisasi formal, tetapi dapat membatasi overfitting secara efektif)
Regularisasi juga dapat ditentukan sebagai penalti atas kompleksitas model.
Lihat Overfitting: Kompleksitas model di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
tingkat regularisasi
Angka yang menentukan tingkat kepentingan relatif regularisasi selama pelatihan. Meningkatkan tingkat regularisasi akan mengurangi overfitting, tetapi dapat mengurangi kemampuan prediksi model. Sebaliknya, mengurangi atau menghilangkan tingkat regularisasi akan meningkatkan overfitting.
Lihat Overfitting: Regularisasi L2 di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
ReLU
Singkatan dari Rectified Linear Unit.
Retrieval-Augmented Generation (RAG)
Teknik untuk meningkatkan kualitas output model bahasa besar (LLM) dengan meng-grounding-nya menggunakan sumber pengetahuan yang diambil setelah model dilatih. RAG meningkatkan akurasi respons LLM dengan memberi LLM yang dilatih akses ke informasi yang diambil dari pusat informasi atau dokumen tepercaya.
Motivasi umum untuk menggunakan retrieval-augmented generation meliputi:
- Meningkatkan akurasi faktual respons yang dihasilkan model.
- Memberi model akses ke pengetahuan yang tidak digunakan untuk melatihnya.
- Mengubah pengetahuan yang digunakan model.
- Memungkinkan model mengutip sumber.
Misalnya, anggaplah aplikasi kimia menggunakan PaLM API untuk membuat ringkasan yang terkait dengan kueri pengguna. Saat backend aplikasi menerima kueri, backend akan:
- Menelusuri ("mengambil") data yang relevan dengan kueri pengguna.
- Menambahkan ("melengkapi") data kimia yang relevan ke kueri pengguna.
- Memberi petunjuk kepada LLM untuk membuat ringkasan berdasarkan data yang ditambahkan.
Kurva ROC (receiver operating characteristic)
Grafik rasio positif benar versus rasio positif palsu untuk berbagai ambang batas klasifikasi dalam klasifikasi biner.
Bentuk kurva ROC menunjukkan kemampuan model klasifikasi biner untuk memisahkan kelas positif dari kelas negatif. Misalnya, model klasifikasi biner memisahkan semua kelas negatif dengan sempurna dari semua kelas positif:
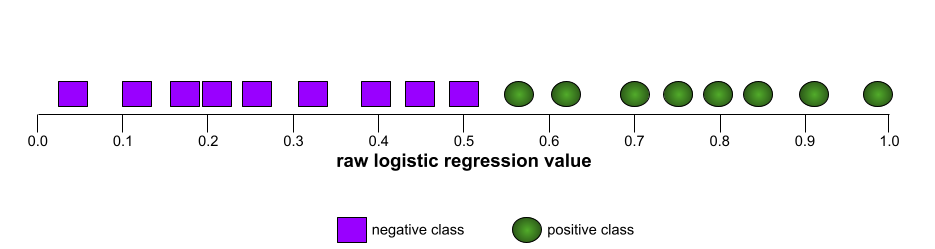
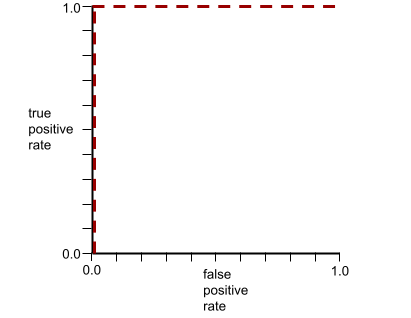
Kurva ROC untuk model sebelumnya terlihat seperti berikut:
Sebaliknya, ilustrasi berikut menggambarkan nilai regresi logistik mentah untuk model yang buruk dan tidak dapat memisahkan kelas negatif dari kelas positif sama sekali:
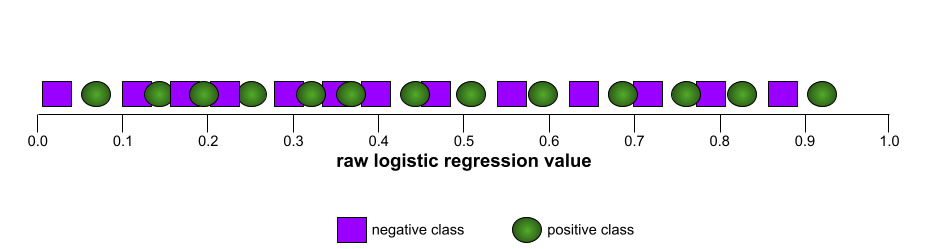
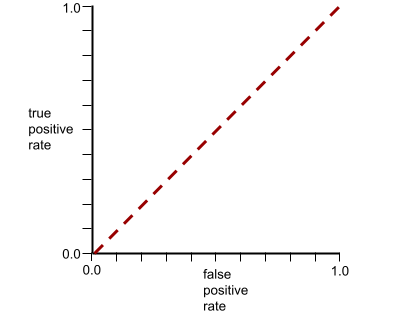
Kurva ROC untuk model ini terlihat seperti berikut:
Sementara itu, kembali ke dunia nyata, sebagian besar model klasifikasi biner memisahkan kelas positif dan negatif sampai batas tertentu, tetapi biasanya tidak sempurna. Jadi, kurva ROC yang umum berada di antara dua titik ekstrem:
Titik pada kurva ROC yang paling dekat dengan (0,0,1,0) secara teoretis mengidentifikasi batas klasifikasi yang ideal. Namun, beberapa masalah dunia nyata lainnya memengaruhi pemilihan nilai minimum klasifikasi yang ideal. Misalnya, negatif palsu mungkin menyebabkan lebih banyak masalah daripada positif palsu.
Metrik numerik yang disebut AUC meringkas kurva ROC menjadi satu nilai floating point.
Galat Akar Rataan Kuadrat (RMSE)
Akar kuadrat dari Rataan Kuadrat Galat.
S
fungsi sigmoid
Fungsi matematika yang "memadatkan" nilai input ke dalam rentang terbatas, biasanya 0 hingga 1 atau -1 hingga +1. Artinya, Anda dapat meneruskan angka apa pun (dua, satu juta, minus satu miliar, apa pun) ke sigmoid dan outputnya akan tetap berada dalam rentang yang dibatasi. Plot fungsi aktivasi sigmoid akan terlihat seperti berikut:
Fungsi sigmoid memiliki beberapa kegunaan dalam machine learning, termasuk:
- Mengonversi output mentah model regresi logistik atau regresi multinomial menjadi probabilitas.
- Bertindak sebagai fungsi aktivasi di beberapa jaringan saraf.
softmax
Fungsi yang menentukan probabilitas untuk setiap kemungkinan kelas dalam model klasifikasi multi-kelas. Jumlah probabilitasnya adalah 1,0. Misalnya, tabel berikut menunjukkan cara softmax mendistribusikan berbagai probabilitas:
| Gambar adalah... | Probability |
|---|---|
| anjing | 0,85 |
| kucing | .13 |
| kuda | .02 |
Softmax juga disebut softmax penuh.
Berbeda dengan sampling kandidat.
Lihat Jaringan neural: Klasifikasi multi-kelas di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
fitur renggang
Fitur yang sebagian besar nilainya nol atau kosong. Misalnya, fitur yang berisi satu nilai 1 dan satu juta nilai 0 adalah jarang. Sebaliknya, fitur padat memiliki nilai yang sebagian besar bukan nol atau kosong.
Dalam machine learning, sejumlah besar fitur adalah fitur jarang. Fitur kategoris biasanya merupakan fitur renggang. Misalnya, dari 300 kemungkinan spesies pohon di hutan, satu contoh mungkin hanya mengidentifikasi pohon maple. Atau, dari jutaan kemungkinan video dalam koleksi video, satu contoh dapat mengidentifikasi hanya "Casablanca".
Dalam model, Anda biasanya merepresentasikan fitur renggang dengan enkode one-hot. Jika enkode one-hot berukuran besar, Anda dapat menempatkan lapisan penyematan di atas enkode one-hot untuk efisiensi yang lebih besar.
representasi renggang
Menyimpan hanya posisi elemen bukan nol dalam fitur jarang.
Misalnya, anggaplah fitur kategoris bernama species mengidentifikasi 36 spesies pohon di hutan tertentu. Selanjutnya, asumsikan bahwa setiap
contoh hanya mengidentifikasi satu spesies.
Anda dapat menggunakan vektor one-hot untuk merepresentasikan spesies pohon dalam setiap contoh.
Vektor one-hot akan berisi satu 1 (untuk merepresentasikan
spesies pohon tertentu dalam contoh tersebut) dan 35 0 (untuk merepresentasikan
35 spesies pohon yang tidak ada dalam contoh tersebut). Jadi, representasi one-hot
dari maple mungkin terlihat seperti berikut:

Atau, representasi jarang hanya akan mengidentifikasi posisi spesies tertentu. Jika maple berada di posisi 24, representasi jarang
dari maple cukup berupa:
24
Perhatikan bahwa representasi renggang jauh lebih ringkas daripada representasi one-hot.
Klik ikon untuk melihat contoh yang sedikit lebih kompleks.
Misalkan setiap contoh dalam model Anda harus merepresentasikan kata-kata—tetapi bukan urutan kata-kata tersebut—dalam kalimat bahasa Inggris. Bahasa Inggris terdiri dari sekitar 170.000 kata, sehingga bahasa Inggris adalah fitur kategoris dengan sekitar 170.000 elemen. Sebagian besar kalimat dalam bahasa Inggris menggunakan sebagian kecil dari 170.000 kata tersebut, sehingga kumpulan kata dalam satu contoh hampir pasti akan menjadi data jarang.
Pertimbangkan kalimat berikut:
My dog is a great dog
Anda dapat menggunakan varian vektor one-hot untuk merepresentasikan kata-kata dalam kalimat ini. Dalam varian ini, beberapa sel dalam vektor dapat berisi nilai bukan nol. Selain itu, dalam varian ini, sel dapat berisi bilangan bulat selain satu. Meskipun kata "my", "is", "a", dan "great" hanya muncul sekali dalam kalimat, kata "dog" muncul dua kali. Menggunakan vektor one-hot ini untuk merepresentasikan kata-kata dalam kalimat ini akan menghasilkan vektor 170.000 elemen berikut:

Representasi jarang dari kalimat yang sama cukup berupa:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
Lihat Menggunakan data kategorik di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
vektor renggang
Vektor yang sebagian besar nilainya adalah nol. Lihat juga fitur renggang dan kerenggangan.
kerugian kuadrat
Sinonim untuk L2 loss.
static
Sesuatu yang dilakukan sekali, bukan terus-menerus. Istilah statis dan offline adalah sinonim. Berikut adalah penggunaan umum statis dan offline dalam machine learning:
- Model statis (atau model offline) adalah model yang dilatih satu kali, lalu digunakan untuk jangka waktu tertentu.
- Pelatihan statis (atau pelatihan offline) adalah proses pelatihan model statis.
- Inferensi statis (atau inferensi offline) adalah proses saat model menghasilkan batch prediksi sekaligus.
Berbeda dengan dinamis.
inferensi statis
Sinonim untuk inferensi offline.
stasioneritas
Fitur yang nilainya tidak berubah di satu atau beberapa dimensi, biasanya waktu. Misalnya, fitur yang nilainya terlihat hampir sama pada tahun 2021 dan 2023 menunjukkan stasioneritas.
Di dunia nyata, hanya ada sedikit fitur yang menunjukkan stasioneritas. Bahkan fitur yang identik dengan stabilitas (seperti permukaan laut) berubah seiring waktu.
Berbeda dengan nonstasioneritas.
penurunan gradien stokastik (SGD)
Algoritma penurunan gradien yang mana ukuran tumpukan bernilai satu. Dengan kata lain, SGD melatih satu contoh yang dipilih secara seragam dan acak dari set pelatihan.
Lihat Regresi linear: Hyperparameter di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
supervised machine learning
Melatih model dari fitur dan label yang sesuai. Supervised machine learning dianalogikan dengan mempelajari subjek dengan mempelajari serangkaian pertanyaan dan jawabannya yang sesuai. Setelah menguasai pemetaan antara pertanyaan dan jawaban, siswa kemudian dapat memberikan jawaban untuk pertanyaan baru (yang belum pernah dilihat sebelumnya) tentang topik yang sama.
Bandingkan dengan unsupervised machine learning.
Lihat Supervised Learning dalam kursus Introduction to ML untuk mengetahui informasi selengkapnya.
fitur sintetis
Fitur yang tidak ada di antara fitur masukan, tetapi dirakit dari satu atau beberapa fitur masukan. Metode untuk membuat fitur sintetis mencakup hal berikut:
- Mengelompokkan fitur berkelanjutan ke dalam bin rentang.
- Membuat persilangan fitur.
- Mengalikan (atau membagi) satu nilai fitur dengan nilai fitur lainnya
atau dengan nilai fitur itu sendiri. Misalnya, jika
adanbadalah fitur input, maka berikut adalah contoh fitur sintetis:- ab
- a2
- Menerapkan fungsi transendental ke nilai fitur. Misalnya, jika
cadalah fitur input, maka berikut adalah contoh fitur sintetis:- sin(c)
- ln(c)
Fitur yang dibuat dengan menormalisasi atau menskalakan saja tidak dianggap sebagai fitur sintetis.
T
kerugian pengujian
Metrik yang merepresentasikan loss model terhadap set pengujian. Saat membuat model, Anda biasanya mencoba meminimalkan kerugian pengujian. Hal ini karena kerugian pengujian yang rendah adalah sinyal kualitas yang lebih kuat daripada kerugian pelatihan yang rendah atau kerugian validasi yang rendah.
Perbedaan besar antara kerugian pengujian dan kerugian pelatihan atau kerugian validasi terkadang menunjukkan bahwa Anda perlu meningkatkan tingkat regularisasi.
pelatihan
Proses penentuan parameter ideal (bobot dan bias) yang membentuk model. Selama pelatihan, sistem membaca contoh dan secara bertahap menyesuaikan parameter. Pelatihan menggunakan setiap contoh dari beberapa kali hingga miliaran kali.
Lihat Supervised Learning dalam kursus Introduction to ML untuk mengetahui informasi selengkapnya.
kerugian pelatihan
Metrik yang merepresentasikan kerugian model selama iterasi pelatihan tertentu. Misalnya, anggap fungsi kerugiannya adalah Rataan Kuadrat Galat (RKG). Mungkin kerugian pelatihan (Mean Squared Error) untuk iterasi ke-10 adalah 2,2, dan kerugian pelatihan untuk iterasi ke-100 adalah 1,9.
Kurva kerugian memetakan kerugian pelatihan versus jumlah iterasi. Kurva kerugian memberikan petunjuk berikut tentang pelatihan:
- Kemiringan ke bawah menunjukkan bahwa model meningkat.
- Kemiringan ke atas menunjukkan bahwa model semakin buruk.
- Lereng datar menunjukkan bahwa model telah mencapai konvergensi.
Misalnya, kurva kerugian yang agak ideal berikut menunjukkan:
- Lereng menurun yang curam selama iterasi awal, yang menyiratkan peningkatan model yang cepat.
- Lereng yang berangsur-angsur mendatar (tetapi masih menurun) hingga mendekati akhir pelatihan, yang menyiratkan peningkatan model yang berkelanjutan dengan kecepatan yang agak lebih lambat daripada selama iterasi awal.
- Lereng datar di akhir pelatihan, yang menunjukkan konvergensi.
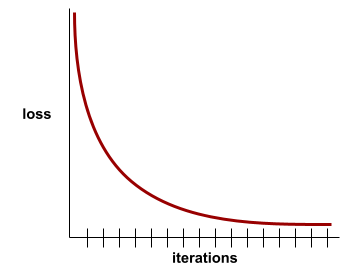
Meskipun kerugian pelatihan penting, lihat juga generalisasi.
diferensiasi performa pelatihan dan penayangan
Perbedaan antara performa model selama pelatihan dan performa model yang sama selama penayangan.
set pelatihan
Subset set data yang digunakan untuk melatih model.
Biasanya, contoh dalam set data dibagi menjadi tiga subset berbeda berikut:
- set pelatihan
- set validasi
- set pengujian
Idealnya, setiap contoh dalam set data hanya boleh termasuk dalam salah satu subkumpulan di atas. Misalnya, satu contoh tidak boleh termasuk dalam set pelatihan dan set validasi.
Lihat Set data: Membagi set data asli di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
negatif benar (TN)
Contoh yang mana model dengan benar memprediksi kelas negatif. Misalnya, model menyimpulkan bahwa pesan email tertentu bukan spam, dan pesan email tersebut memang bukan spam.
positif benar (TP)
Contoh yang mana model dengan benar memprediksi kelas positif. Misalnya, model menyimpulkan bahwa pesan email tertentu adalah spam, dan pesan email tersebut memang spam.
rasio positif benar (TPR)
Sinonim untuk perolehan. Definisinya yaitu:
Rasio positif benar adalah sumbu y dalam kurva ROC.
U
underfitting
Menghasilkan model dengan kemampuan prediksi yang buruk karena model belum sepenuhnya memahami kompleksitas data pelatihan. Banyak masalah yang dapat menyebabkan kurang cocok (underfitting), termasuk:
- Melatih model dengan set fitur yang salah.
- Pelatihan untuk epoch yang terlalu sedikit atau dengan kecepatan pembelajaran yang terlalu rendah.
- Melakukan pelatihan dengan tingkat regularisasi yang terlalu tinggi.
- Menyediakan terlalu sedikit lapisan tersembunyi dalam jaringan neural dalam.
Lihat Overfitting di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
contoh tak berlabel
Contoh yang berisi fitur, tetapi tidak ada label. Misalnya, tabel berikut menunjukkan tiga contoh tidak berlabel dari model penilaian rumah, masing-masing dengan tiga fitur, tetapi tanpa nilai rumah:
| Jumlah kamar | Jumlah kamar mandi | Usia rumah |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
Dalam supervised machine learning, model dilatih pada contoh berlabel dan membuat prediksi pada contoh tak berlabel.
Dalam semi-supervised dan unsupervised learning, contoh tak berlabel digunakan selama pelatihan.
Membedakan contoh tak berlabel dengan contoh berlabel.
unsupervised machine learning
Melatih model untuk menemukan pola dalam set data, biasanya set data tak berlabel.
Penggunaan unsupervised machine learning yang paling umum adalah untuk mengelompokkan data ke dalam beberapa kelompok contoh yang serupa. Misalnya, algoritma machine learning tanpa pengawasan dapat mengelompokkan lagu berdasarkan berbagai properti musik. Cluster yang dihasilkan dapat menjadi input untuk algoritma machine learning lainnya (misalnya, untuk layanan rekomendasi musik). Pengelompokan dapat membantu saat label yang berguna langka atau tidak ada. Misalnya, dalam domain seperti anti-penyalahgunaan dan penipuan, kluster dapat membantu manusia untuk lebih memahami data.
Berbeda dengan supervised machine learning.
Lihat Apa itu Machine Learning? di kursus Pengantar ML untuk mengetahui informasi selengkapnya.
V
validasi
Evaluasi awal kualitas model. Validasi memeriksa kualitas prediksi model terhadap set validasi.
Karena set validasi berbeda dengan set pelatihan, validasi membantu mencegah overfitting.
Anda dapat menganggap evaluasi model terhadap set validasi sebagai putaran pertama pengujian dan evaluasi model terhadap set pengujian sebagai putaran kedua pengujian.
kerugian validasi
Metrik yang merepresentasikan kerugian model pada set validasi selama iterasi pelatihan tertentu.
Lihat juga kurva generalisasi.
set validasi
Subset set data yang melakukan evaluasi awal terhadap model terlatih. Biasanya, Anda mengevaluasi model terlatih terhadap set validasi beberapa kali sebelum mengevaluasi model terhadap set pengujian.
Biasanya, Anda membagi contoh dalam set data menjadi tiga subset berbeda berikut:
- set pelatihan
- set validasi
- set pengujian
Idealnya, setiap contoh dalam set data hanya boleh termasuk dalam salah satu subkumpulan di atas. Misalnya, satu contoh tidak boleh termasuk dalam set pelatihan dan set validasi.
Lihat Set data: Membagi set data asli di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
W
bobot
Nilai yang dikalikan model dengan nilai lain. Pelatihan adalah proses penentuan bobot ideal model; inferensi adalah proses penggunaan bobot yang telah dipelajari tersebut untuk membuat prediksi.
Lihat Regresi linear di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.
jumlah tertimbang
Jumlah semua nilai input yang relevan dikalikan dengan bobot yang sesuai. Misalnya, anggap saja input yang relevan terdiri dari berikut ini:
| nilai input | berat masukan |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
Oleh karena itu, jumlah tertimbang adalah:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Jumlah terbobot adalah argumen input ke fungsi aktivasi.
Z
Normalisasi skor Z
Teknik penskalaan yang mengganti nilai fitur mentah dengan nilai floating point yang merepresentasikan jumlah standar deviasi dari rata-rata fitur tersebut. Misalnya, pertimbangkan fitur yang memiliki rata-rata 800 dan standar deviasi 100. Tabel berikut menunjukkan cara normalisasi skor Z memetakan nilai mentah ke skor Z-nya:
| Nilai mentah | Z-score |
|---|---|
| 800 | 0 |
| 950 | +1,5 |
| 575 | -2,25 |
Model machine learning kemudian dilatih pada skor Z untuk fitur tersebut, bukan pada nilai mentah.
Lihat Data numerik: Normalisasi di Kursus Singkat Machine Learning untuk mengetahui informasi selengkapnya.