本页面包含图片模型术语表中的术语。如需查看所有术语表术语,请点击此处。
A
增强现实
一种技术,可将计算机生成的图像叠加在用户对真实世界的视图上,从而提供合成视图。
自动编码器
一种系统,可学习从输入中提取最重要的信息。自动编码器是编码器和解码器的组合。自动编码器依赖于以下两步流程:
- 编码器会将输入映射到(通常)有损的低维度(中间)格式。
- 解码器通过将低维格式映射到原始的高维输入格式,构建原始输入的损失版本。
自动编码器是通过让解码器尝试尽可能接近地从编码器的中间格式重构原始输入,从而进行端到端训练的。由于中间格式比原始格式小(维度较低),因此自动编码器被迫学习输入中哪些信息是必不可少的,并且输出不会与输入完全相同。
例如:
- 如果输入数据是图形,则非完全相同的副本与原始图形相似,但会经过一些修改。非完全匹配的副本可能移除了原始图形中的噪点,或者填充了一些缺失的像素。
- 如果输入数据是文本,则自动编码器会生成模仿(但不完全相同)原始文本的新文本。
另请参阅变分自编码器。
自回归模型
一种模型,可根据其之前的预测推断出预测结果。例如,自回归语言模型可根据之前预测的令牌预测下一个令牌。所有基于 Transformer 的大语言模型都是自动回归模型。
相比之下,基于 GAN 的图像模型通常不是自回归模型,因为它们在单次前向传递中生成图像,而不是分步迭代生成。不过,某些图片生成模型是自回归模型,因为它们会分步生成图片。
B
边界框
在图片中,围绕感兴趣区域(例如下图中的狗)的矩形的 (x, y) 坐标。

C
卷积
在数学中,粗略地说,就是两个函数的混合。在机器学习中,卷积结合使用卷积过滤器和输入矩阵来训练权重。
如果没有卷积,机器学习算法就需要学习大张量中每个单元各自的权重。例如,在 2K x 2K 图片上训练的机器学习算法将被迫找到 400 万个单独的权重。而使用卷积,机器学习算法只需算出卷积过滤器中每个单元的权重,大大减少了训练模型所需的内存。应用卷积滤波器时,只需将其复制到各个单元格,以便每个单元格都与滤波器相乘。
如需了解详情,请参阅图像分类课程中的卷积神经网络简介。
卷积过滤器
卷积运算中的两个参与方之一。(另一个 actor 是输入矩阵的一个 slice。)卷积过滤器是一种矩阵,其秩与输入矩阵相同,但形状小一些。例如,给定一个 28x28 的输入矩阵,过滤器可以是小于 28x28 的任何二维矩阵。
在照片处理中,卷积滤波中的所有单元通常都设置为 1 和 0 的恒定模式。在机器学习中,卷积过滤器通常使用随机数作为种子,然后网络训练理想值。
如需了解详情,请参阅“图片分类”课程中的卷积。
卷积层
深度神经网络的一个层,卷积过滤器会在其中传递输入矩阵。例如,请考虑以下 3x3 卷积过滤器:
![一个 3x3 矩阵,其中包含以下值:[[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?hl=ur)
以下动画展示了一个卷积层,该层由 9 个卷积运算组成,其中涉及 5x5 的输入矩阵。请注意,每个卷积运算都针对输入矩阵的不同 3x3 切片进行运算。生成的 3x3 矩阵(在右侧)由 9 次卷积运算的结果组成:
![动画:显示两个矩阵。第一个矩阵是 5 x 5 的矩阵:[[128,97,53,201,198], [35,22,25,200,195], [37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].
第二个矩阵是 3 x 3 矩阵:
[[181,303,618], [115,338,605], [169,351,560]].
第二个矩阵是通过对 5x5 矩阵的不同 3x3 子集应用卷积过滤器 [[0, 1, 0], [1, 0, 1], [0, 1, 0]] 计算得出的。](https://developers.google.cn/static/machine-learning/glossary/images/AnimatedConvolution.gif?hl=ur)
如需了解详情,请参阅“图片分类”课程中的全连接层。
卷积神经网络
一种神经网络,其中至少有一层为卷积层。典型的卷积神经网络由以下层的某种组合组成:
卷积神经网络在解决某些类型的问题(例如图像识别)方面取得了巨大成功。
卷积运算
如下所示的两步数学运算:
- 对卷积过滤器和输入矩阵切片执行元素级乘法。(输入矩阵切片与卷积过滤器具有相同的秩和大小。)
- 对生成的积矩阵中的所有值求和。
例如,请考虑以下 5x5 输入矩阵:
![5 x 5 矩阵:[[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?hl=ur)
现在,假设以下 2x2 卷积过滤器:
![2x2 矩阵:[[1, 0], [0, 1]]](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?hl=ur)
每个卷积运算都涉及输入矩阵的单个 2x2 切片。例如,假设我们使用输入矩阵左上角的 2x2 切片。因此,对此 slice 执行的卷积运算如下所示:
![将卷积滤波 [[1, 0], [0, 1]] 应用于输入矩阵的左上角 2x2 部分,即 [[128,97], [35,22]]。
卷积滤波会保留 128 和 22,但会将 97 和 35 设为零。因此,卷积运算的结果为 150(128+22)。](https://developers.google.cn/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?hl=ur)
卷积层由一系列卷积运算组成,每个卷积运算都针对不同的输入矩阵切片。
D
数据增强
通过转换现有示例创建其他示例,人为地增加训练示例的范围和数量。例如,假设图像是其中一个特征,但数据集包含的图像样本不足以供模型学习有用的关系。理想情况下,您需要向数据集添加足够的有标签图像,才能使模型正常训练。如果不可行,则可以通过数据增强旋转、拉伸和翻转每张图像,以生成原始照片的多个变体,这样可能会生成足够的有标签数据来实现很好的训练效果。
深度可分离卷积神经网络 (sepCNN)
一种基于 Inception 的卷积神经网络架构,但 Inception 模块已替换为深度可分离卷积。也称为 Xception。
深度可分离卷积(也简称为可分离卷积)会将标准 3D 卷积分解为两个计算效率更高的单独卷积运算:第一个是深度卷积,深度为 1(n ✕ n ✕ 1),第二个是点卷积,长度和宽度为 1(1 ✕ 1 ✕ n)。
如需了解详情,请参阅 Xception:使用深度可分离卷积的深度学习。
降采样
一个多含义术语,可以理解为下列两种含义之一:
- 减少特征中的信息量,以便更高效地训练模型。例如,在训练图像识别模型之前,将高分辨率图像降采样为分辨率较低的格式。
- 使用占比异常低、得到过度代表的类别样本训练模型,以改进未得到充分代表的类别的模型训练效果。例如,在类别不平衡的数据集中,模型往往会对多数类别有充分的了解,但对少数类别的了解不足。降采样有助于平衡多数类和少数类的训练量。
如需了解详情,请参阅机器学习速成课程中的数据集:不平衡数据集。
F
微调
对预训练模型执行的第二次特定于任务的训练传递,以针对特定用例优化其参数。例如,某些大型语言模型的完整训练序列如下所示:
- 预训练:使用庞大的一般数据集(例如所有英语版维基百科页面)训练大语言模型。
- 微调:训练预训练模型以执行特定任务,例如回答医学查询。微调通常涉及数百或数千个专注于特定任务的示例。
再举一个例子,大型图片模型的完整训练序列如下所示:
- 预训练:在庞大的一般图片数据集(例如 Wikimedia Commons 中的所有图片)上训练大型图片模型。
- 微调:训练预训练模型以执行特定任务,例如生成虎鲸的图片。
微调可以包含以下策略的任意组合:
- 修改预训练模型的所有现有参数。这有时称为完整微调。
- 仅修改预训练模型的部分现有参数(通常是距离输出层最近的层),同时保持其他现有参数不变(通常是距离输入层最近的层)。请参阅参数高效微调。
- 添加更多图层,通常在最靠近输出图层的现有图层之上。
微调是一种迁移学习。因此,与训练预训练模型时使用的损失函数或模型类型相比,微调可能会使用不同的损失函数或模型类型。例如,您可以微调预训练的大型图像模型,以生成一个回归模型,用于返回输入图片中的鸟类数量。
比较和对比微调与以下术语:
如需了解详情,请参阅机器学习速成课程中的微调。
G
Gemini
该生态系统由 Google 最先进的 AI 技术组成。此生态系统的元素包括:
- 各种 Gemini 模型。
- Gemini 模型的交互式对话式界面。 用户输入提示,Gemini 对这些提示做出回应。
- 各种 Gemini API。
- 基于 Gemini 模型的各种商务产品;例如,适用于 Google Cloud 的 Gemini。
Gemini 模型
Google 基于 Transformer 的先进多模态模型。Gemini 模型专为与代理集成而设计。
用户可以通过多种方式与 Gemini 模型互动,包括通过交互式对话框界面和 SDK。
生成式 AI
尚无正式定义的全新变革领域。 尽管如此,大多数专家都认为,生成式 AI 模型可以创作(“生成”)符合以下所有条件的内容:
- 复杂
- 连贯
- 原图
例如,生成式 AI 模型可以创作复杂的散文或图片。
一些早期技术(包括 LSTM 和 RNN)也可以生成原创且连贯的内容。一些专家认为这些早期技术属于生成式 AI,而另一些人则认为,真正的生成式 AI 需要生成比这些早期技术能生成的更复杂的输出。
与预测性机器学习相对。
I
图像识别
对图像中的物体、图案或概念进行分类的过程。 图像识别也称为图像分类。
如需了解详情,请参阅机器学习实践课程:图像分类。
如需了解详情,请参阅机器学习实践课程:图像分类。
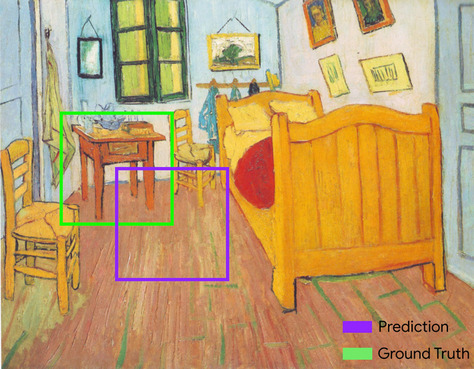
交并比 (IoU)
两个集合的交集除以它们的合集。在机器学习图片检测任务中,IoU 用于衡量模型预测的边界框相对于标准答案边界框的准确性。在这种情况下,两个框的 IoU 是重叠面积与总面积的比率,其值介于 0(预测边界框与标准答案边界框不重叠)到 1(预测边界框与标准答案边界框具有完全相同的坐标)之间。
例如,在下图中:
- 预测的边界框(即模型预测画作中床头柜所在位置的坐标)用紫色勾勒出来。
- 标准答案边界框(限定画作中夜桌实际位置的坐标)用绿色勾勒。
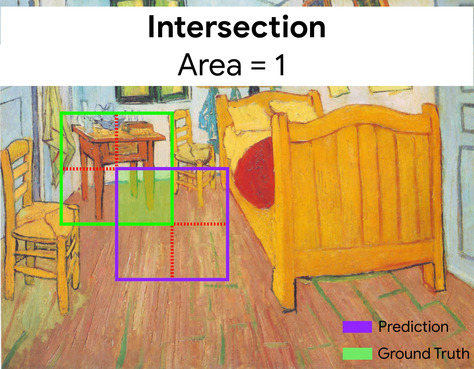
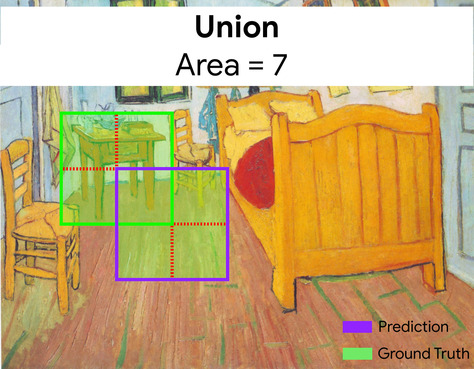
在这里,预测边界框与标准答案边界框的交集(左下)为 1,预测边界框与标准答案边界框的并集(右下)为 7,因此 IoU 为 \(\frac{1}{7}\)。
K
关键点
图片中特定地图项的坐标。例如,对于用于区分花种的图片识别模型,关键点可能是每个花瓣的中心、花茎、花药等。
L
landmarks
与关键点的含义相同。
M
MMIT
多模态指令调优的缩写。
MNIST
由 LeCun、Cortes 和 Burges 编译的公用数据集,其中包含 60,000 张图像,每张图像显示人类如何手动写下从 0 到 9 的特定数字。每张图像存储为 28x28 的整数数组,其中每个整数是 0 到 255(含边界值)之间的灰度值。
MNIST 是机器学习的标准数据集,通常用于测试新的机器学习方法。如需了解详情,请参阅 MNIST 手写数字数据库。
MOE
专家组合的缩写。
P
池化
将一个或多个由前面的卷积层创建的矩阵压缩为较小的矩阵。池化通常涉及取池化区域内的最大值或平均值。例如,假设我们有以下 3x3 矩阵:
![3 x 3 矩阵 [[5,3,1], [8,2,5], [9,4,3]]。](https://developers.google.cn/static/machine-learning/glossary/images/PoolingStart.svg?hl=ur)
池化运算与卷积运算类似:将矩阵分割为多个切片,然后按步长逐个运行卷积运算。例如,假设池化运算将卷积矩阵分割为 2x2 个切片,步长为 1x1。如下图所示,系统会执行四个池化操作。假设每个池化操作都会选择该 slice 中四个值中的最大值:
![输入矩阵为 3x3,值为:[[5,3,1], [8,2,5], [9,4,3]]。
输入矩阵的左上角 2x2 子矩阵为 [[5,3], [8,2]],因此左上角池化运算的结果为 8(即 5、3、8 和 2 中的最大值)。输入矩阵的右上角 2x2 子矩阵为 [[3,1], [2,5]],因此右上角池化运算的结果为 5。输入矩阵的左下角 2x2 子矩阵为 [[8,2], [9,4]],因此左下角池化运算的结果为 9。输入矩阵的右下角 2x2 子矩阵为 [[2,5], [4,3]],因此右下角池化运算的结果为 5。总而言之,池化运算会生成 2x2 矩阵 [[8,5], [9,5]]。](https://developers.google.cn/static/machine-learning/glossary/images/PoolingConvolution.svg?hl=ur)
池化有助于在输入矩阵中实现平移不变性。
用于视觉应用的池化更正式地称为空间池化。时间序列应用通常将池化称为时间池化。在非正式场合,池化通常称为抽样或下采样。
后期训练的模型
这个术语的定义比较宽泛,通常是指经过一些后处理(例如以下一项或多项)的预训练模型:
预训练模型
通常是指已经训练好的模型。该术语还可以指之前训练的嵌入向量。
预训练语言模型一词通常是指已训练的大型语言模型。
预训练
在大型数据集上对模型进行初始训练。有些预训练模型是笨拙的巨人,通常需要通过额外训练进行优化。例如,机器学习专家可能会使用庞大的文本数据集(例如维基百科中的所有英语页面)预训练大语言模型。预训练后,可以通过以下任一技术进一步优化生成的模型:
R
旋转不变性
在图片分类问题中,算法即使在图片的方向发生变化时也能成功分类图片的能力。例如,无论网球拍朝上、朝侧还是朝下,该算法仍然可以识别它。请注意,并非总是希望旋转不变;例如,倒置的“9”不应分类为“9”。
S
缩放不变性
在图片分类问题中,算法即使在图片大小发生变化的情况下也能成功分类的能力。例如,无论猫占用 200 万像素还是 20 万像素,该算法仍然可以识别它。请注意,即使是最好的图像分类算法,在尺寸不变方面也仍然存在实际限制。例如,对于仅以 20 像素呈现的猫图像,算法(或人)不可能正确对其进行分类。
空间 pooling
请参阅共享。
步长
在卷积运算或池化操作中,下一系列输入切片的每个维度的增量。例如,以下动画演示了卷积运算期间的 (1,1) 步长。因此,下一个输入 slice 的起始位置在前一个输入 slice 的右侧。当操作到达右边缘时,下一个 slice 会一直向左移动,但会向下移动一个位置。
上面的示例演示了二维步长。如果输入矩阵为三维,那么步长也将是三维。
下采样
请参阅共享。
T
温度
一种超参数,用于控制模型输出的随机程度。温度越高,输出内容的随机性就越大;温度越低,输出内容的随机性就越小。
选择最佳温度取决于具体应用以及模型输出的首选属性。例如,在创建用于生成富有创意输出的应用时,您可能会提高温度。相反,在构建用于分类图片或文本的模型时,您可能需要降低温度,以提高模型的准确性和一致性。
温度通常与softmax 一起使用。
平移不变性
在图像分类问题中,算法即使在图像中对象的位置发生变化时也能成功分类的能力。例如,无论一只狗位于画面正中央还是画面左侧,该算法仍然可以识别它。