本頁面包含 Language Evaluation 字典術語。如要查看所有詞彙表術語,請按這裡。
A
注意力
神經網路中使用的機制,用於指出特定字詞或字詞的某個部分的重要性。注意力機制會壓縮模型預測下一個符記/字詞所需的資訊量。典型的注意力機制可能包含一組輸入值的加權總和,其中每個輸入值的權重是由神經網路的另一個部分計算而得。
請參閱自我注意力 和多頭自我注意力,這兩者是 Transformer 的構建元件。
如要進一步瞭解自我注意力,請參閱機器學習速成課程中的「LLM:大型語言模型是什麼?」一文。
自動編碼器
系統會學習從輸入內容中擷取最重要的資訊。自動編碼器是編碼器和解碼器的組合。自動編碼器會採用下列兩步驟程序:
- 編碼器會將輸入內容對應至 (通常) 有損的低維 (中介) 格式。
- 解碼器會將較低維度的格式對應至原始較高維度的輸入格式,藉此建立原始輸入內容的損失版本。
自動編碼器會透過解碼器嘗試盡可能從編碼器的中間格式,重建原始輸入內容,進行端對端訓練。由於中間格式比原始格式小 (維度較低),因此自動編碼器會強制學習輸入內容中哪些資訊是必要的,且輸出內容不會與輸入內容完全相同。
例如:
- 如果輸入資料是圖形,非精確複製的圖形會與原始圖形相似,但會稍微修改。非精確複製的圖片可能會移除原始圖片的雜訊,或填入一些缺少的像素。
- 如果輸入資料是文字,自動編碼器會產生模仿原始文字的新文字 (但不會完全相同)。
另請參閱變分自動編碼器。
自動評估
使用軟體判斷模型輸出內容的品質。
如果模型輸出內容相對簡單,指令碼或程式可以將模型輸出內容與黃金回應進行比較。這類自動評估有時也稱為程式評估。ROUGE 或 BLEU 等指標通常可用於程式評估。
如果模型輸出內容複雜,或沒有單一正確答案,系統有時會使用稱為自動評分器的獨立機器學習程式自動評估。
請參閱人工評估。
自動產生器評估
混合機制,結合人工評估和自動評估,用於評估生成式 AI 模型輸出的品質。自動撰寫器是一種機器學習模型,會根據人工評估所建立的資料進行訓練。理想情況下,自動評分工具會學習模仿人類評估人員。您可以使用預先建構的自動回覆器,但最佳的自動回覆器會根據您要評估的工作進行精細調整。
自動迴歸模型
模型:根據先前的預測結果推斷預測結果。舉例來說,自動迴歸語言模型會根據先前預測的符記,預測下一個符記。所有以 Transformer 為基礎的大型語言模型都是自動迴歸模型。
相較之下,以 GAN 為基礎的圖像模型通常不是自動迴歸模型,因為它們會在單一前向傳遞中產生圖像,而不是在步驟中逐漸產生圖像。不過,某些圖像產生模型是自動迴歸模型,因為它們會分步驟產生圖像。
k 的平均精確度
這項指標用於總結模型在單一提示 (產生排名結果,例如書籍推薦書的編號清單) 上的成效。k 的平均精確度是每個相關結果的精確度在 k 處值的平均值。因此,k 的平均精確度計算公式為:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
其中:
- \(n\) 是清單中的相關項目數量。
請比較recall at k。
B
字詞袋
表示詞組或段落中字詞的形式,不論順序為何。舉例來說,字詞袋可用來表示下列三個詞組:
- 狗跳躍
- 跳躍的狗
- 狗跳躍
每個字詞都會對應至稀疏向量中的索引,其中向量會為詞彙中的每個字詞提供索引。舉例來說,字詞「the dog jumps」會對應至特徵向量,其中三個索引的值皆不為零,分別對應至「the」、「dog」和「jumps」。非零值可以是下列任一項目:
- 1 代表字詞存在。
- 字詞在袋子中出現的次數。舉例來說,如果詞組是「the maroon dog is a dog with maroon fur」,則「maroon」和「dog」會分別以 2 和 1 代表,其他字則以 1 代表。
- 其他值,例如字詞在袋子中出現次數的對數。
BERT (基於變換器的雙向編碼器表示技術)
文字表示法的模型架構。經過訓練的 BERT 模型可用於文字分類或其他機器學習工作,做為更大型模型的一部分。
BERT 具有下列特性:
- 使用 Transformer 架構,因此仰賴自我注意力。
- 使用 Transformer 的 encoder 部分。編碼器的工作是產生良好的文字表示法,而不是執行分類等特定工作。
- 是否為雙向。
- 使用遮蔽功能進行非監督式訓練。
BERT 的變化版本包括:
如需 BERT 的總覽資訊,請參閱「開放原始碼 BERT:自然語言處理最先進的預先訓練技術」。
雙向
用來描述系統評估文字時,會同時評估目標文字區塊前後的文字。相反地,單向系統只會評估目標文字段落前面的文字。
舉例來說,請考慮以下問題中,遮罩語言模型必須判斷代表下列問題中底線的字詞或字串的機率:
你有什麼 _____ 嗎?
單向語言模型必須根據「What」、「is」和「the」等字詞提供的背景資訊,計算機率。相較之下,雙向語言模型也可以從「with」和「you」取得上下文,這可能有助於模型產生更準確的預測結果。
雙向語言模型
語言模型:根據前面和後面的文字,判斷在文字摘錄中指定符號出現在指定位置的可能性。
bigram
N=2 的 N-gram。
BLEU (雙語評估研究)
評估機器翻譯 (例如從西班牙文翻譯成日文) 的 0.0 到 1.0 之間指標。
為了計算分數,BLEU 通常會將 ML 模型的翻譯內容 (產生的文字) 與人工專家翻譯內容 (參考文字) 進行比較。產生文字和參考文字中 N-grams 相符的程度,決定了 BLEU 分數。
這個指標的原始論文為「BLEU:一種自動評估機器翻譯的方法」。
另請參閱 BLEURT。
BLEURT (Transformer 的雙語評估研究)
評估機器翻譯的指標,特別是從一種語言翻譯成另一種語言的翻譯結果,尤其是從英文翻譯成英文。
對於從英文翻譯成英文的翻譯,BLEURT 比 BLEU 更能與人類評分一致。與 BLEU 不同,BLEURT 強調語意相似性,並可容納改寫內容。
BLEURT 會使用預先訓練的大型語言模型 (具體來說是 BERT),然後根據人類翻譯的文字進行微調。
這項指標的原始論文為 BLEURT:Learning Robust Metrics for Text Generation。
C
因果語言模型
單向語言模型的同義詞。
請參閱雙向語言模型,瞭解語言建模中的不同方向方法。
思維鏈提示
提示工程技巧,可讓大型語言模型 (LLM) 逐步說明其推理方式。舉例來說,請參考下列提示,並特別留意第二句:
如果車輛在 7 秒內從 0 加速到每小時 60 英里,駕駛者會感受到多少 g 力?在答案中顯示所有相關計算。
LLM 的回應可能會:
- 顯示一連串物理公式,並在適當位置插入 0、60 和 7 的值。
- 說明為何選擇這些公式,以及各種變數的含義。
思維鏈提示會強制 LLM 執行所有計算,因此可能會產生更準確的答案。此外,思維鏈結提示可讓使用者檢查 LLM 的步驟,判斷答案是否合理。
對話
與機器學習系統 (通常是大型語言模型) 進行一來一往對話的內容。聊天中的先前互動內容 (您輸入的內容和大型語言模型的回應方式) 會成為後續聊天內容的脈絡。
聊天機器人是大型語言模型的應用程式。
虛構
幻覺的同義詞。
與其說是幻覺,不如說是編造比較準確。不過,幻覺一開始就很受歡迎。
選區剖析
將句子分割成較小的文法結構 (「成分」)。相較於原始句子,機器學習系統的後續部分 (例如自然語言理解模型) 更容易剖析構成要素。例如,請考慮下列句子:
我的朋友收養了兩隻貓咪。
詞組解析器可將這句話分為下列兩個詞組:
- 「My friend」是名詞片語。
- 「adopted two cats」是動詞片語。
這些元素可進一步細分為更小的元素。例如動詞片語
收養了兩隻貓
可進一步細分為:
- 「adopted」是動詞。
- 兩隻貓是另一個名詞片語。
依情境設定的語言嵌入
嵌入,可讓系統以類似於母語人士的方式「理解」字詞和詞組。情境化語言嵌入可理解複雜的語法、語意和情境。
舉例來說,請考慮英文單字「cow」的嵌入。較舊的嵌入資料 (例如 word2vec) 可以代表英文單字,以便在嵌入資料空間中,從母牛到公牛的距離與從母羊到公羊或從女性到男性的距離相似。在這種情況下,如果使用者輸入「cow」一詞,系統會知道這是指「牛」或「牛市」,進而進一步瞭解這項資訊。
上下文視窗
模型可在特定提示中處理的符記數量。脈絡窗口越大,模型就能使用越多資訊,為提示提供連貫一致的回覆。
當機圖示
含義不明確的句子或詞組。崩潰綻放是自然語言理解中的重要問題。舉例來說,「Red Tape Holds Up Skyscraper」是個失敗的花招,因為 NLU 模型可能會以字面或比喻的方式解讀標題。
D
解碼器
一般來說,任何從經過處理、密集或內部表示法轉換為較原始、稀疏或外部表示法的 ML 系統。
解碼器通常是較大模型的元件,經常與編碼器配對。
在序列對序列任務中,解碼器會從編碼器產生的內部狀態開始,預測下一個序列。
如要瞭解 Transformer 架構中的解碼器定義,請參閱 Transformer。
如需更多資訊,請參閱機器學習速成課程中的「大型語言模型」一文。
去雜訊
自監督式學習的常見方法:
去噪處理可讓模型從未標示的範例學習。原始資料集可做為目標或標記,雜訊資料則可做為輸入內容。
部分掩碼語言模型會使用以下去雜訊方法:
- 系統會透過遮蓋部分符記,在未標記的句子中人為加入雜訊。
- 模型會嘗試預測原始符記。
直接提示
與「零樣本提示」同義。
E
編輯距離
用於評估兩個字串的相似程度。在機器學習中,編輯距離有以下用途:
- 編輯距離很容易計算。
- 編輯距離可比較兩個已知相似的字串。
- 編輯距離可判斷不同字串與特定字串的相似程度。
編輯距離有幾種定義,每種定義都使用不同的字串運算。請參閱Levenshtein 距離,瞭解相關範例。
嵌入層
特殊的隱藏層,可針對高維度類別特徵進行訓練,逐步學習較低維度的嵌入向量。嵌入層可讓類神經網路以更有效率的方式進行訓練,而非只訓練高維類別特徵。
舉例來說,地球目前支援約 73,000 種樹木。假設樹種是模型中的特徵,因此模型的輸入層會包含長度為 73,000 個元素的一熱向量。舉例來說,baobab 可能會以以下方式表示:

73,000 個元素的陣列非常長。如果您未在模型中加入嵌入層,由於要乘以 72,999 個零,訓練作業會非常耗時。假設您選擇的嵌入層包含 12 個維度,因此,嵌入層會逐漸學習每種樹木的新嵌入向量。
在某些情況下,雜湊是嵌入層的合理替代方案。
詳情請參閱機器學習速成課程中的「嵌入」一節。
嵌入空間
從高維向量空間對應的 d 維向量空間。在理想情況下,嵌入空間會包含可產生有意義的數學結果的結構;舉例來說,在理想的嵌入空間中,嵌入值的加法和減法運算可解決字詞類比任務。
兩個嵌入資料的內積是衡量相似度的指標。
嵌入向量
一般來說,這個陣列是從任何 隱藏層取得的浮點數陣列,用於描述該隱藏層的輸入內容。通常,嵌入向量是訓練在嵌入層中的浮點數陣列。舉例來說,假設嵌入層必須為地球上 73,000 種樹木學習嵌入向量。以下陣列可能是猴麵包樹的嵌入向量:

嵌入向量並非一堆隨機數字,嵌入層會透過訓練來判斷這些值,類似於神經網路在訓練期間學習其他權重的方式。陣列的每個元素都是樹種的某些特徵評分。哪個元素代表哪種樹種的特徵?這對人類來說很難判斷。
從數學角度來看,嵌入向量最值得注意的部分是,相似項目具有相似的浮點數組。舉例來說,相似的樹種浮點數組合會比不相似的樹種更相似。紅木和巨杉是相關的樹種,因此它們會比紅木和椰子樹擁有更相似的浮點數組。每次重新訓練模型時,嵌入向量中的數字都會變更,即使您使用相同的輸入內容重新訓練模型也是如此。
編碼器
一般來說,任何從原始、稀疏或外部表示法轉換為經過處理、更密集或更內部表示法的機器學習系統。
編碼器通常是較大模型的元件,經常與解碼器配對。有些Transformers 會將編碼器與解碼器配對,但其他 Transformers 只會使用編碼器或解碼器。
部分系統會將編碼器的輸出內容做為分類或迴歸網路的輸入內容。
在序列對序列任務中,編碼器會擷取輸入序列,並傳回內部狀態 (向量)。接著,解碼器會使用該內部狀態來預測下一個序列。
如要瞭解 Transformer 架構中編碼器的定義,請參閱 Transformer。
詳情請參閱機器學習速成課程中的「LLM:什麼是大型語言模型」。
evals
主要用於縮寫大型語言模型評估。更廣義來說,evals 是任何形式的評估的縮寫。
評估版
評估模型品質或比較不同模型的程序。
如要評估監督式機器學習模型,通常會根據驗證集和測試集來評估。評估 LLM 通常會涉及更廣泛的品質和安全評估。
F
少量樣本提示
提示:包含多個 (「幾個」) 示例,說明大型語言模型應如何回應。舉例來說,以下長篇提示包含兩個範例,說明大型語言模型如何回答查詢。
| 提示的部分 | 附註 |
|---|---|
| 指定國家/地區的官方貨幣為何? | 要讓 LLM 回答的問題。 |
| 法國:歐元 | 舉例來說。 |
| 英國:英鎊 | 另一個例子。 |
| 印度: | 實際查詢。 |
與零樣本提示和單樣本提示相比,少量樣本提示通常可產生更理想的結果。不過,少量樣本提示需要較長的提示。
少量樣本提示是一種少量樣本學習,可套用至以提示為基礎的學習。
如需詳細資訊,請參閱機器學習速成課程中的「提示工程」一節。
小提琴
以 Python 為優先的設定程式庫,可設定函式和類別的值,且不會影響程式碼或基礎架構。就 Pax 和其他 ML 程式碼集而言,這些函式和類別代表模型和訓練 超參數。
Fiddle 會假設機器學習程式碼集通常分為以下類別:
- 定義層和最佳化器的程式庫程式碼。
- 資料集「黏著劑」程式碼,會呼叫程式庫並將所有項目連接在一起。
Fiddle 會以未評估且可變動的形式,擷取黏合程式碼的呼叫結構。
微調
在預先訓練的模型上執行第二次專門針對工作訓練,以便針對特定用途微調參數。舉例來說,部分大型語言模型的完整訓練序列如下:
- 預先訓練:使用大量一般資料集 (例如所有英文版 Wikipedia 網頁) 訓練大型語言模型。
- 微調:訓練預先訓練模型,以執行特定任務,例如回應醫療查詢。精細調整通常會使用數百或數千個專注於特定任務的範例。
舉另一個例子來說,大型圖片模型的完整訓練序列如下:
- 預先訓練:使用大量一般圖片資料集 (例如 Wikimedia Commons 中的所有圖片) 訓練大型圖片模型。
- 微調:訓練預先訓練模型,以執行特定任務,例如產生虎鯨圖片。
微調可採用下列任意組合策略:
- 修改預先訓練模型的所有參數。這也稱為「完整微調」。
- 只修改預先訓練模型的部分現有參數 (通常是離 輸出層 最近的層),其他現有參數則保持不變 (通常是離 輸入層 最近的層)。請參閱高效參數調整。
- 新增更多圖層,通常是在最靠近輸出圖層的現有圖層上方。
微調是一種遷移學習。因此,精修可能會使用與訓練預先訓練模型時不同的損失函式或模型類型。舉例來說,您可以微調預先訓練的大型圖像模型,產生回傳輸入圖像中鳥類數量的迴歸模型。
請比較並對照精細調整與下列術語:
亞麻色
這是以 JAX 為基礎建立的高效能開放原始碼 程式庫,專門用於深度學習。Flax 提供訓練 神經網路的函式,以及評估其效能的方法。
Flaxformer
開放原始碼 Transformer 程式庫,建構於 Flax 之上,主要設計用於自然語言處理和多模態研究。
G
Gemini
這個生態系統包含 Google 最先進的 AI 技術。這個生態系統的元素包括:
- 各種 Gemini 模型。
- Gemini 模型的互動式對話介面。使用者輸入提示,Gemini 回應這些提示。
- 各種 Gemini API。
- 各種以 Gemini 模型為基礎的業務產品,例如 Gemini 版 Google Cloud。
Gemini 模型
Google 最先進的Transformer 型多模態模型。Gemini 模型專門用於整合代理程式。
使用者可以透過多種方式與 Gemini 模型互動,包括透過互動式對話介面和 SDK。
系統生成的文字
一般來說,機器學習模型輸出的文字。評估大型語言模型時,部分指標會將產生的文字與參考文字進行比較。舉例來說,假設您想判斷機器學習模型從法文翻譯成荷蘭文的效率。在這種情況下:
- 「產生的文字」是機器學習模型輸出的荷蘭文翻譯。
- 「參考文字」是指人工翻譯 (或軟體) 所建立的荷蘭文翻譯。
請注意,部分評估策略不含參照文字。
生成式 AI
這項新興的轉型領域尚未有正式定義。不過,大多數專家都認為,生成式 AI 模型可以創建 (「生成」) 下列所有內容:
- 複雜
- 一致
- 原始圖片
舉例來說,生成式 AI 模型可以產生精緻的文章或圖像。
有些早期的技術,包括 LSTM 和 RNN,也能產生原創且連貫的內容。有些專家認為這些早期技術就是生成式 AI,但其他專家則認為,真正的生成式 AI 需要比這些早期技術更複雜的輸出內容。
請參閱預測機器學習。
金色回應
已知的正確答案。例如,請參考以下提示:
2 + 2
理想的回覆內容應為:
4
GPT (生成式預先訓練轉換器)
由 OpenAI 開發的一系列Transformer 型大型語言模型。
GPT 變體可套用於多種模態,包括:
- 圖像生成 (例如 ImageGPT)
- 文字轉圖像生成功能 (例如 DALL-E)。
H
幻覺
生成式 AI 模型聲稱要對真實世界做出斷言,但實際上產生看似合理但事實上錯誤的輸出內容。舉例來說,如果生成式 AI 模型聲稱 Barack Obama 於 1865 年去世,就是錯誤擷取資訊。
人工評估
由人類判斷機器學習模型輸出內容的品質,例如由雙語人士判斷機器學習翻譯模型的品質。人工評估特別適合評估沒有正確答案的模型。
請比較自動評估和AutoRater 評估。
I
情境學習
與「少量樣本提示」同義。
L
LaMDA (對話應用程式語言模型)
由 Google 開發的Transformer 技術為基礎的大型語言模型,可產生逼真的對話回覆,並已訓練完成,可從大量對話資料集擷取資訊。
LaMDA:我們的突破性對話技術 提供總覽。
語言模型
大型語言模型
至少有一個語言模型,其參數數量非常高。更非正式的說法是,任何以 Transformer 為基礎的語言模型,例如 Gemini 或 GPT。
潛在空間
嵌入空間的同義詞。
Levenshtein 距離
編輯距離指標,可計算從一個字詞變更為另一個字詞所需的最少刪除、插入和替換作業次數。舉例來說,「heart」和「darts」之間的 Levenshtein 距離為 3,因為下列三個編輯步驟是將一個字轉換為另一個字時所需的最少變更次數:
- heart → deart (將「h」替換為「d」)
- deart → dart (刪除「e」)
- dart → darts (插入「s」)
請注意,上述順序並非三次編輯的唯一路徑。
LLM
大型語言模型的縮寫。
大型語言模型評估 (evals)
一組用於評估大型語言模型 (LLM) 成效的指標和基準。大致來說,LLM 評估有以下功能:
- 協助研究人員找出 LLM 需要改善之處。
- 可用於比較不同的 LLM,並找出特定任務的最佳 LLM。
- 確保 LLM 的使用方式安全且符合道德。
LoRA
低秩適應性的縮寫。
低秩調整 (LoRA)
參數效率高的微調技巧,可「凍結」模型的預先訓練權重 (以便不再修改),然後在模型中插入一小組可訓練的權重。這組可訓練的權重 (也稱為「更新矩陣」) 比基本模型小得多,因此訓練速度也快得多。
LoRA 具備下列優點:
- 改善模型在精細調整所用領域的預測品質。
- 比起需要微調所有模型參數的技術,這項技術可更快速地進行微調。
- 允許同時服務共用相同基礎模型的多個專門模型,藉此降低推論的運算成本。
M
掩碼語言模型
語言模型:預測候選符記填入序列空白的機率。舉例來說,經過遮罩的語言模型可計算候選字詞的機率,以便取代下列句子中的底線:
帽子裡的 ____ 回來了。
相關文獻通常會使用字串「MASK」而非底線。例如:
帽子上的「MASK」字樣又出現了。
大多數的現代遮罩語言模型都是雙向。
k 的平均精確度 (mAP@k)
在驗證資料集中,所有平均精確度 (k) 分數的統計平均值。在 k 處計算平均精確度有一個用途,就是判斷推薦系統產生的推薦內容品質。
雖然「平均平均值」這個詞組聽起來很冗長,但指標名稱是適當的。畢竟,這項指標會找出多個 average precision at k 值的平均值。
元學習
機器學習的子集,用於發現或改善學習演算法。元學習系統也可以訓練模型,讓模型從少量資料或先前任務的經驗中,快速學習新任務。元學習演算法通常會嘗試達成以下目標:
- 改善或學習手動設計的功能 (例如初始化器或最佳化工具)。
- 提高資料和運算效率。
- 改善泛化功能。
元學習與少量樣本學習相關。
專家組合
這項方法只使用神經網路的參數子集 (稱為專家) 來處理特定輸入 符記或示例,藉此提高效率。篩選網路會將每個輸入符記或範例導向適當的專家。
詳情請參閱下列任一論文:
MMIT
多模態指令調整的縮寫。
模態
高層級資料類別。舉例來說,數字、文字、圖片、影片和音訊是五種不同的模式。
模型平行處理
一種擴大訓練或推論的方法,可將一個模型的不同部分放置在不同的裝置上。模型平行處理可讓過大的模型適合在單一裝置上執行。
系統通常會執行下列操作,實作模型並行功能:
- 將模型分割成較小的部分。
- 將這些較小的部分訓練工作分散到多個處理器。每個處理器都會訓練模型的一部分。
- 將結果合併,建立單一模型。
模型平行處理會減慢訓練速度。
另請參閱「資料平行處理」。
MOE
混合專家的縮寫。
多頭自注意力
自我注意力的擴充功能,會針對輸入序列中的每個位置多次套用自我注意力機制。
Transformers 引入了多頭自注意力。
多模態指令調整
指令調整模型,可處理文字以外的輸入內容,例如圖片、影片和音訊。
多模態模型
模型的輸入和/或輸出包含多個模態。舉例來說,假設模型同時將圖片和文字說明 (兩種模式) 做為特徵,並輸出分數,指出文字說明與圖片的適配度。因此,這個模型的輸入內容是多模態,輸出內容則是單模態。
否
自然語言處理
教導電腦如何使用語言規則處理使用者所說或輸入的內容。幾乎所有現代自然語言處理都仰賴機器學習。自然語言理解
自然語言處理的子集,用於判斷所說或所打內容的意圖。自然語言理解技術可超越自然語言處理,考量語言的複雜面向,例如脈絡、嘲諷和情緒。
N 元語法
由 N 個字組成的有序序列。例如「truly madly」就是一個 2 元組。由於順序相關,madly truly 與 truly madly 的 2 元組不同。
| 否 | 這類 N-gram 的名稱 | 範例 |
|---|---|---|
| 2 | 大元音節或 2 元音節 | to go, go to, eat lunch, eat dinner |
| 3 | 三元組或 3 元組 | ate too much, three blind mice, the bell tolls |
| 4 | 4 個字元 | 在公園散步,風中飄揚的灰塵,男孩吃了扁豆 |
許多自然語言理解模型都會使用 N-gram 預測使用者輸入或說出的下一個字詞。舉例來說,假設使用者輸入「three blind」。以三元組為基礎的 NLU 模型可能會預測使用者接下來會輸入「mice」。
請比較 N-gram 與詞袋,後者是未排序的字詞集合。
自然語言處理
自然語言處理的縮寫。
自然語言理解
自然語言理解的縮寫。
沒有唯一正確答案 (NORA)
提示有多個適當的回覆選項。舉例來說,下列提示沒有正確答案:
講個關於大象的笑話。
評估「沒有正確答案」提示可能會很困難。
NORA
沒有正確答案的縮寫。
O
單樣本提示
提示,其中包含一個示例,說明大型語言模型應如何回應。舉例來說,以下提示包含一個範例,說明大型語言模型應如何回答查詢。
| 提示的部分 | 附註 |
|---|---|
| 指定國家/地區的官方貨幣為何? | 要讓 LLM 回答的問題。 |
| 法國:歐元 | 舉例來說。 |
| 印度: | 實際查詢。 |
請比較一次性提示與下列術語:
P
高效參數微調
一組技巧,可微調大型預先訓練語言模型 (PLM),比完整微調更有效率。相較於完整微調,參數效率調整通常會微調的參數會少得多,但通常會產生與完整微調所建立的大型語言模型一樣 (或幾乎一樣) 優異的大型語言模型。
比較具參數運用效率的調整機制與下列項目:
高效參數微調也稱為高效參數微調。
管線
一種模型並行處理形式,其中模型的處理作業會分成連續階段,且每個階段會在不同的裝置上執行。當一個階段處理一個批次時,前一個階段可以處理下一個批次。
另請參閱分階段訓練。
PLM
預先訓練語言模型的縮寫。
位置編碼
一種技巧,可將符號在序列中的位置資訊新增至符號的嵌入資料。Transformer 模型會使用位置編碼,進一步瞭解序列不同部分之間的關係。
位置編碼的常見實作方式是使用正弦函式。(具體來說,正弦函數的頻率和振幅取決於符號在序列中的位置)。這項技術可讓 Transformer 模型學習如何根據位置,關注序列的不同部分。
訓練後模型
這項術語定義較為寬鬆,通常是指經過某些後置處理程序的預先訓練模型,例如下列一或多項:
k 的精確度 (precision@k)
用於評估排名 (排序) 項目清單的指標。k 的精確度可指出清單中前 k 個項目的「相關性」比率。也就是:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
k 的值必須小於或等於傳回清單的長度。請注意,傳回清單的長度並非計算的一部分。
關聯性通常是主觀判斷,即使是專業的人類評估員,也經常對哪些項目具有關聯性有不同意見。
比較時段:
預先訓練模型
「預先訓練的語言模型」一詞通常是指已訓練的大型語言模型。
預先訓練
在大型資料集上初步訓練模型。部分預先訓練模型是笨重的巨人,通常必須透過額外訓練才能精進。舉例來說,機器學習專家可能會在大量文字資料集 (例如 Wikipedia 中的所有英文頁面) 上預先訓練大型語言模型。預先訓練完成後,您可以使用下列任一技術進一步精進產生的模型:
提示
任何輸入至大型語言模型的文字,可讓模型以特定方式運作。提示可以是短短一句話,也可以是任意長度 (例如小說的完整內容)。提示可分為多個類別,包括下表所列:
| 提示類別 | 範例 | 附註 |
|---|---|---|
| 問題 | 鴿子飛得多快? | |
| 操作說明 | 寫一首關於套利的有趣詩。 | 提示,要求大型語言模型執行某項操作。 |
| 範例 | 將 Markdown 程式碼轉換為 HTML。例如:
Markdown:* 清單項目 HTML:<ul> <li>清單項目</li> </ul> |
這個提示範例的第一句話是指示。提示的其餘部分則是範例。 |
| 角色 | 向物理學博士解釋為何在機器學習訓練中使用梯度下降法。 | 句子的前半部是指示,而「物理學博士」是角色部分。 |
| 模型可補完的部分輸入內容 | 英國首相住在 | 部分輸入提示訊息可以突然結束 (如本範例所示),也可以以底線結尾。 |
生成式 AI 模型可根據提示回應文字、程式碼、圖片、嵌入內容和影片等內容。
以提示為基礎的學習
特定模型的功能,可讓模型根據任意文字輸入內容 (提示) 調整行為。在典型的提示式學習模式中,大型語言模型會透過產生文字來回應提示。舉例來說,假設使用者輸入以下提示:
概述牛頓第三運動定律。
具備提示式學習功能的模型並未特別訓練來回答先前的提示。相反地,模型「知道」許多物理學事實、許多一般語言規則,以及許多構成一般實用答案的內容。這項知識足以提供 (希望是) 實用的答案。額外的人為回饋 (「這個答案太複雜了」或「有什麼反應?」) 可讓部分以提示為基礎的學習系統逐步改善答案的實用性。
提示設計
提示工程的同義詞。
提示工程
創造提示的技巧,可從大型語言模型取得所需回應。人類會執行提示工程。撰寫結構良好的提示,是確保大型語言模型提供實用回應的重要環節。提示工程取決於多項因素,包括:
如要進一步瞭解如何撰寫實用的提示,請參閱「提示設計簡介」。
提示設計是提示工程的同義詞。
提示調整
參數效率調整機制,可學習系統在實際提示前端加上的「前置字串」。
提示調整的一種變化版本 (有時稱為「前置字串調整」) 是在每個層級前面加上前置字串。相較之下,大部分的提示調整作業只會在輸入層中加入前置字串。
R
k 時的喚回率 (recall@k)
評估系統輸出排名 (排序) 項目清單的指標。在 k 的回憶率,是指在該清單中,前 k 個項目中,與傳回的相關項目總數相比,相關項目所占的比例。
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
與精確度為 k 形成對比。
參考文字
專家對提示的回應。例如,請參考下列提示:
將問題「What is your name?」從英文翻譯成法文。
專家的回覆可能如下:
Comment vous appelez-vous?
各種指標 (例如 ROUGE) 可評估參考文字與 ML 模型產生的文字的相似程度。
角色提示
提示的選用部分,用於識別生成式 AI 模型回應的目標對象。如果沒有角色提示,大型語言模型提供的答案可能對提問者有用,也可能沒有用。有了角色提示,大型語言模型就能以更適當且更有助於特定目標對象的方式回答問題。例如,下列提示的角色提示部分以粗體顯示:
- 將這篇文章摘要成經濟學博士論文。
- 以十歲兒童為例,說明潮汐的運作方式。
- 解釋 2008 年金融危機。說話時,就像對年幼兒童或金毛尋回犬說話一樣。
ROUGE (喚回度導向的摘要評估研究)
一組用於評估自動摘要和機器翻譯模型的指標。ROUGE 指標可判斷參考文字與機器學習模型產生的文字的相似程度。ROUGE 系列的每個成員都會以不同的方式測量重疊。ROUGE 分數越高,表示參考文字和產生文字的相似度越高。
每個 ROUGE 成員通常會產生下列指標:
- 精確度
- 喚回度
- F1
如需詳細資訊和範例,請參閱:
ROUGE-L
ROUGE 家族成員,專注於參考文字和生成文字 中最長的共同子序列長度。以下公式可計算 ROUGE-L 的召回率和精確度:
接著,您可以使用 F1 將 ROUGE-L 喚回率和 ROUGE-L 精確度匯總為單一指標:
ROUGE-L 會忽略參照文字和產生文字中的任何換行符號,因此最長的共同子序列可能會跨越多個句子。如果參考文字和產生的文字包含多個句子,則通常會使用 ROUGE-L 的變化版本 ROUGE-Lsum 做為指標。ROUGE-Lsum 會判斷段落中每個句子的最長共同子序列,然後計算這些最長共同子序列的平均值。
ROUGE-N
ROUGE 系列中的一組指標,用於比較參考文字和產生文字中特定大小的共用 N-gram。例如:
- ROUGE-1 會評估參考文字和產生文字中共用的符記數量。
- ROUGE-2 會評估參考文字和產生文字中共用的 二元語法 (2-grams) 數量。
- ROUGE-3 會評估參考文字和產生文字中共用的 三元語法 (3-grams) 數量。
您可以使用下列公式,計算 ROUGE-N 系列的任何成員的 ROUGE-N 回溯率和 ROUGE-N 精確度:
接著,您可以使用 F1 將 ROUGE-N 喚回率和 ROUGE-N 精確度匯總為單一指標:
ROUGE-S
這是 ROUGE-N 的寬容形式,可啟用skip-gram 比對。也就是說,ROUGE-N 只會計算與完全相符的N-gram,但 ROUGE-S 也會計算以一或多個字詞分隔的 N-gram。舉例來說,您可以嘗試:
計算 ROUGE-N 時,2 元組「白雲」不符合「白色雲朵」。不過,在計算 ROUGE-S 時,「白雲」與「白色捲雲」相符。
S
自注意 (也稱為自注意層)
神經網路層,可將一系列嵌入資料 (例如 符記嵌入資料) 轉換為另一個嵌入資料序列。輸出序列中的每個嵌入項目,都是透過注意力機制,整合輸入序列元素的資訊而建構而成。
自注意的「自」部分是指序列會關注自身,而非其他內容。自我注意力是 Transformer 的主要構建區塊之一,並使用字典查詢術語,例如「查詢」、「鍵」和「值」。
自注意層會從一連串輸入表示法開始,每個字詞一個。字詞的輸入表示法可以是簡單的嵌入。對於輸入序列中的每個字詞,這個網路會為該字詞與整個字詞序列中每個元素的關聯性評分。相關性分數會決定字詞的最終表示法整合其他字詞的表示法程度。
舉例來說,請看以下句子:
動物太累了,因此沒有過馬路。
下圖 (取自「Transformer:語言理解的全新類神經網路架構」) 顯示了自注意層針對代名詞「it」的注意力模式,每個線條的深淺代表每個字詞對表示方式的貢獻程度:
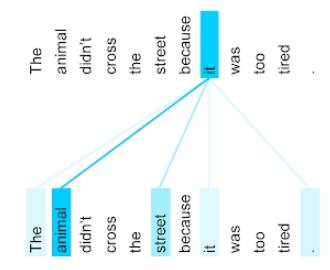
自注意層會標出與「it」相關的字詞。在這種情況下,注意力層會學習突顯「它」可能指涉的字詞,並將最高權重指派給「動物」。
對於 n 個符記的序列,自注意力會將嵌入序列轉換 n 次,在序列的每個位置各轉換一次。
情緒分析
使用統計或機器學習演算法,判斷群組對某項服務、產品、機構或主題的整體態度為正面或負面。舉例來說,演算法可使用自然語言理解技術,對大學課程的文字回饋執行情緒分析,進而判斷學生普遍喜歡或不喜歡該課程的程度。
序列對序列工作
這項任務會將 符記的輸入序列轉換為符記輸出序列。舉例來說,兩種常見的序列對序列任務如下:
- 翻譯人員:
- 輸入序列範例:「我愛你」。
- 輸出內容示例:"Je t'aime."
- 回答問題:
- 輸入範例:"我需要在紐約市使用車輛嗎?"
- 輸出序列範例:「否。請將車輛停在家中。」
skip-gram
n-gram 可能會省略 (或「略過」) 原始上下文中的字詞,也就是說,N 個字詞可能並非原先相鄰。更精確地說,「k 個跳過 n 元語法」是指最多跳過 k 個字詞的 n 元語法。
舉例來說,「the quick brown fox」可能有以下 2 音節:
- 「the quick」
- 「quick brown」
- 「brown fox」
「1-skip-2-gram」是指兩個字詞之間最多相隔 1 個字詞。因此,「the quick brown fox」有以下 1 跳 2 元組:
- 「the brown」
- 「quick fox」
此外,所有 2-gram 也同時是 1-skip-2-gram,因為可能會略過少於一個字。
跳躍式迴歸模型可協助我們進一步瞭解字詞的周遭上下文。在這個範例中,「fox」與「quick」在 1-skip-2-grams 集合中直接相關,但在 2-grams 集合中則不相關。
跳躍式字串有助於訓練字詞嵌入模型。
軟提示調整
一種針對特定工作調整大型語言模型的技術,無需耗用大量資源進行微調。軟式提示調整功能不會重新訓練模型中的所有權重,而是會自動調整提示,以達到相同目標。
在收到文字提示時,軟性提示調整功能通常會在提示中附加額外的符記嵌入,並使用反向傳播來最佳化輸入內容。
「硬式」提示包含實際的符記,而非符記嵌入。
稀疏特徵
特徵的值大多為零或空白。舉例來說,如果特徵包含單一 1 值和百萬個 0 值,就屬於稀疏特徵。相反地,密集特徵的值通常不會是零或空白。
在機器學習中,有許多特徵是稀疏特徵。類別特徵通常是稀疏特徵。舉例來說,在森林中可能有 300 種樹木,但單一示例可能只會識別出楓樹。或者,在影片庫中,有數百萬部影片可供選擇,但單一示例可能只會標示「Casablanca」。
在模型中,您通常會使用one-hot 編碼來表示稀疏特徵。如果 one-hot 編碼很大,您可以將嵌入層置於 one-hot 編碼之上,以提高效率。
稀疏表示法
在稀疏特徵中,只儲存非零元素的位置。
舉例來說,假設名為 species 的類別特徵會識別特定森林中的 36 種樹木。再假設每個示例只識別單一物種。
您可以使用一維向量來代表每個示例中的樹種。單熱向量會包含單一 1 (代表該例中的特定樹種) 和 35 個 0 (代表該例中「不是」的 35 種樹木)。因此,maple 的 one-hot 表示法可能會像以下這樣:

或者,稀疏表示法只會指出特定物種的位置。如果 maple 位於第 24 個位置,maple 的稀疏表示法就會變成:
24
請注意,稀疏表示法比一熱表示法精簡許多。
按一下圖示,查看較複雜的範例。
假設模型中的每個範例都必須代表英文句子中的字詞,但不代表這些字詞的順序。英文約有 170,000 個字,因此英文是包含約 170,000 個元素的分類特徵。大多數的英文句子都只使用這些 170,000 個字詞中的極小部分,因此單一例子中的字詞集合幾乎肯定會是稀疏資料。
請考慮下列句子:
My dog is a great dog
您可以使用單熱向量的變化版本,代表這句話中的字詞。在這個變化版本中,向量中的多個單元格可以包含非零值。此外,在這個變化版本中,單元格可以包含一個以上的整數。雖然「my」、「is」、「a」和「great」這幾個字詞在句子中只出現一次,但「dog」這個字詞出現了兩次。使用這個一熱向量變化版本來表示這句話中的字詞,會產生下列 170,000 個元素的向量:

同一個句子的稀疏表示法如下:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
分階段訓練
在一系列不連續階段中訓練模型的策略。目標可以是加快訓練程序,或是提升模型品質。
以下是漸進式堆疊方法的示意圖:
- 階段 1 包含 3 個隱藏層、階段 2 包含 6 個隱藏層,而階段 3 則包含 12 個隱藏層。
- 階段 2 會開始訓練,使用階段 1 的 3 個隱藏層學到的權重。階段 3 會開始訓練,使用在第 2 階段 6 個隱藏層中學到的權重。
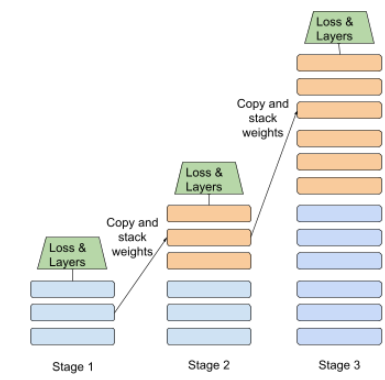
另請參閱管道處理。
子字詞符記
舉例來說,「itemize」這個字詞可能會分成「item」(字根) 和「ize」(字尾) 兩個部分,每個部分都會以專屬的符記表示。將不常見的字詞拆成這類片段 (稱為子字詞),可讓語言模型針對字詞更常見的組成部分 (例如前置詞和後置詞) 運作。
相反地,像「going」這樣的常用字詞可能不會分開,而是以單一符號表示。
T
T5
Google AI 在 2020 年推出的文字轉文字轉移學習 模型。T5 是一種編碼器-解碼器模型,以 Transformer 架構為基礎,並在極大量資料集上進行訓練。這項技術可有效處理各種自然語言處理工作,例如生成文字、翻譯語言,以及以對話方式回答問題。
T5 的名稱源自於「Text-to-Text Transfer Transformer」中的五個 T。
T5X
這個開放原始碼機器學習架構專為建構及訓練大規模自然語言處理 (NLP) 模型而設計。T5 是在 T5X 程式碼集上實作 (該程式碼集是以 JAX 和 Flax 建構而成)。
溫度
超參數,用於控制模型輸出內容的隨機程度。溫度越高,輸出的內容就越隨機,溫度越低,輸出的內容就越不隨機。
選擇最佳溫度時,請考量特定應用程式和模型輸出的偏好屬性。舉例來說,如果您要建立可產生創意輸出的應用程式,可能會提高溫度。反之,如果您要建構分類圖片或文字的模型,則可能會降低溫度,以提高模型的準確度和一致性。
溫度通常會與 softmax 搭配使用。
文字區間
與文字字串的特定子區段相關聯的陣列索引區間。舉例來說,Python 字串 s="Be good now" 中的 good 字詞會佔用 3 到 6 的文字範圍。
token
在語言模型中,模型訓練和預測的基礎單位。權杖通常是下列其中一種:
- 字詞:例如「dogs like cats」這個詞組由三個字詞符記組成:「dogs」、「like」和「cats」。
- 字元,例如「bike fish」這個詞組由九個字元符記組成。(請注意,空格也算作一個符記)。
- 子字詞:單字詞可以是單一符記或多個符記。子字詞由字根、前置字串或後置字串組成。舉例來說,使用子字詞做為符記的語言模型可能會將「dogs」視為兩個符記 (根字詞「dog」和複數字尾「s」)。同樣的語言模型可能會將單字「taller」視為兩個子字 (根字「tall」和後置詞「er」)。
在語言模型以外的網域中,符記可代表其他類型的原子單位。舉例來說,在電腦視覺中,符記可能是圖片的子集。
前 K 項準確度
「目標標籤」出現在產生清單前 k 個位置的百分比。清單可以是個人化推薦內容,或是由 softmax 排序的項目清單。
Top-k 準確度也稱為 k 點準確度。
毒性
內容辱罵、威脅或冒犯的程度。許多機器學習模型都能識別及評估有害內容。這些模型大多會根據多個參數 (例如辱罵性言論和威脅性言論的程度) 來識別有害內容。
Transformer
這是 Google 開發的神經網路架構,可利用自注意力機制,將輸入嵌入資料序列轉換為輸出嵌入資料序列,不必仰賴卷積或迴歸神經網路。Transformer 可視為一組自注意層。
轉換器可包含下列任一項目:
編碼器會將嵌入序列轉換為相同長度的新序列。編碼器包含 N 個相同的層,每個層都包含兩個子層。這兩個子層會套用至輸入嵌入序列的每個位置,將序列的每個元素轉換為新的嵌入。第一個編碼器子層會匯總輸入序列中的資訊。第二個編碼器子層會將匯總資訊轉換為輸出嵌入資料。
解碼器會將輸入嵌入資料序列轉換為輸出嵌入資料序列,長度可能不同。解碼器也包含 N 個相同的層,其中包含三個子層,其中兩個與編碼器子層相似。第三個解碼器子層會採用編碼器的輸出內容,並套用自注意機制,從中收集資訊。
網誌文章「Transformer:語言理解的全新類神經網路架構」提供了 Transformer 的簡介。
三元組
N=3 的 N-gram。
U
單向
系統只會評估目標文字區塊「前面」的文字。相反地,雙向系統會評估目標文字區段「前面」和「後面」的文字。詳情請參閱「雙向」一節。
單向語言模型
語言模型:只根據符記(出現在前面,而非後面) 計算機率,而非目標符記。請參閱雙向語言模型。
V
變分自動編碼器 (VAE)
一種自動編碼器,可利用輸入和輸出之間的差異,產生經過修改的輸入內容。變分自動編碼器可用於生成式 AI。
VAE 是以變異推理為基礎:這是一種用於估算機率模型參數的技術。
W
字詞嵌入
表示字詞集合中的每個字詞,以嵌入向量表示,也就是將每個字詞表示為介於 0.0 和 1.0 之間的浮點值向量。相較於意思不同的字詞,意思相近的字詞會有更多相似的表示法。舉例來說,胡蘿蔔、芹菜和小黃瓜的表示法相似,但與飛機、太陽眼鏡和牙膏的表示法截然不同。
Z
零樣本提示
| 提示的部分 | 附註 |
|---|---|
| 指定國家/地區的官方貨幣為何? | 要讓 LLM 回答的問題。 |
| 印度: | 實際查詢。 |
大型語言模型可能會回覆下列任一內容:
- 盧比符號
- INR
- ₹
- 印度盧比
- 盧比
- 印度盧比
所有答案皆正確,但您可能會偏好特定格式。
請比較零示意提示與下列術語: