大型語言模型 (LLM) 是較新的技術,可預測符記或符記序列,有時預測的符記可達數段文字。請注意,權杖可以是單字、子字 (單字的一部分),甚至是單一字元。LLM 的預測效果遠優於 N 元語言模型或循環類神經網路,原因如下:
- 大型語言模型包含的參數遠多於遞迴模型。
- 大型語言模型會收集更多脈絡資訊。
本節將介紹最成功且廣泛使用的 LLM 建構架構:Transformer。
什麼是 Transformer?
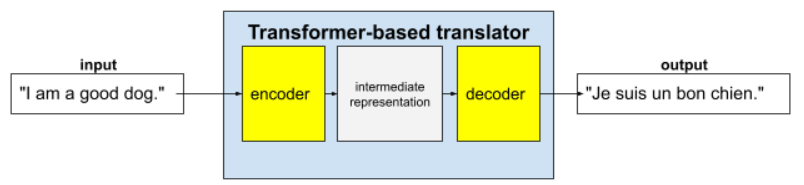
Transformer 是最先進的架構,適用於各種語言模型應用程式,例如翻譯:

完整的 Transformer 包含編碼器和解碼器:
舉例來說,在翻譯人員的案例中:
- 編碼器會將輸入文字 (例如英文句子) 處理成某種中間表示法。
- 解碼器會將該中繼表示法轉換為輸出文字 (例如對等的法文句子)。
什麼是自注意機制?
為強化背景資訊,Transformer 大量採用稱為「自注意力」的概念。實際上,自注意力機制會代表每個輸入權杖提出下列問題:
「輸入內容中的每個其他符記,對這個符記的解讀有何影響?」
「自注意」中的「自」是指輸入序列。有些注意力機制會權衡輸入權杖與輸出序列 (例如翻譯) 或其他序列中權杖的關係。但自注意力只會評估輸入序列中符記之間關係的重要性。
為簡化流程,假設每個符記都是一個字,而完整脈絡只有一個句子。請參考以下句子:
The animal didn't cross the street because it was too tired.
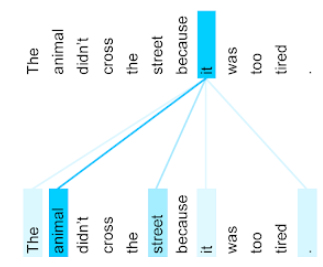
前一句包含十一個字。這十一個字詞會彼此關注,想知道其他十個字詞對自己有多重要。舉例來說,請注意句子中含有代名詞「it」。代名詞通常模稜兩可。代名詞「it」通常是指最近出現的名詞或名詞片語,但在例句中,「it」是指動物還是街道?
自注意力機制會判斷附近每個字詞與代名詞「it」的關聯性。圖 3 顯示結果,線條越藍,代表該字詞對代名詞「it」越重要。也就是說,對代名詞「it」而言,「animal」比「street」更重要。
反之,假設句子中的最後一個字詞變更如下:
The animal didn't cross the street because it was too wide.
在經過修訂的句子中,自注意力機制會將「street」評為比「animal」更符合代名詞「it」。
部分自我注意力機制是雙向的,也就是說,這類機制會計算所關注字詞前後的權杖相關分數。舉例來說,在圖 3 中,請注意 it 兩側的字詞都會經過檢查。因此,雙向自注意機制可以從所注意字詞兩側的字詞收集語境。相較之下,單向自注意機制只能從所注意字詞的一側收集字詞的語境。雙向自我注意機制特別適合用來產生整個序列的表示法,而逐一產生序列符記的應用程式則需要單向自我注意機制。因此,編碼器會使用雙向自我注意力機制,解碼器則使用單向。
什麼是多頭多層自注意力機制?
每個自注意層通常由多個自注意頭組成。層的輸出內容是不同頭部輸出內容的數學運算 (例如加權平均或點積)。
由於每個注意力機制的參數都會初始化為隨機值,因此不同的注意力機制可以學習所關注字詞與附近字詞之間的不同關係。舉例來說,上一節說明的自我注意力機制著重於判斷代名詞「it」所指的對象。不過,同一層中的其他自注意力頭可能會學習每個字詞與其他字詞的文法關聯性,或是學習其他互動。
完整的 Transformer 模型會將多個自注意力層堆疊在一起。前一層的輸出會成為下一層的輸入。 透過這種堆疊方式,模型可以逐步建構對文字的理解,從簡單到複雜,從具體到抽象。雖然較早的層級可能著重於基本語法,但更深層的層級可以整合這些資訊,掌握更細微的概念,例如整個輸入內容的情緒、背景和主題連結。
為什麼 Transformer 模型這麼龐大?
Transformer 包含數千億甚至數兆個參數。本課程通常建議使用參數較少的模型,而非參數較多的模型。畢竟,與參數較多的模型相比,參數較少的模型在進行預測時使用的資源較少。不過,研究顯示,參數較多的 Transformer 一致優於參數較少的 Transformer。
但大型語言模型是如何生成文字的呢?
您已瞭解研究人員如何訓練 LLM 預測一兩個缺漏的字詞,但可能覺得這沒什麼了不起。畢竟,預測一兩個字本質上就是各種文字、電子郵件和撰寫軟體內建的自動完成功能。您可能想知道大型語言模型如何生成有關套利的文章、段落或俳句。
事實上,LLM 本質上是自動完成機制,可自動預測 (完成) 數千個權杖。舉例來說,假設句子後面接著遮蓋句子:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
LLM 可以為遮蓋的句子生成機率,包括:
| 機率 | 字詞 |
|---|---|
| 3.1% | 例如坐下、等待和翻滾。 |
| 2.9% | 例如:坐下、等待和翻滾。 |
只要 LLM 夠大,就能為段落和整篇文章生成機率。您可以將使用者向 LLM 提出的問題視為「給定」句子,後面接著想像中的遮罩。例如:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
LLM 會針對各種可能的回覆生成機率。
舉例來說,如果 LLM 接受大量數學「文字問題」訓練,就能展現出複雜的數學推理能力。不過,這些 LLM 基本上只是自動完成文字問題提示。
大型語言模型的優點
大型語言模型可為各種目標對象生成清楚易懂的文字。LLM 可預測明確訓練過的任務,部分研究人員聲稱,LLM 也能針對未明確訓練的輸入內容進行預測,但其他研究人員已駁斥這項說法。
大型語言模型的問題
訓練 LLM 會遇到許多問題,包括:
- 收集龐大的訓練集。
- 耗費數月時間、大量運算資源和電力。
- 解決平行處理挑戰。
使用 LLM「推斷」預測結果會導致下列問題:
- LLM 會產生幻覺,也就是預測結果經常有誤。
- LLM 會消耗大量運算資源和電力。 使用較大的資料集訓練 LLM 通常會減少推論所需的資源量,但較大的訓練集會耗用更多訓練資源。
- 與所有機器學習模型一樣,大型語言模型也可能出現各種偏誤。