Ta strona zawiera definicje terminów z glosariusza oceny językowej. Aby poznać wszystkie terminy z glosariusza, kliknij tutaj.
A
uwaga
Mechanizm używany w sieci neuronowej, który wskazuje znaczenie danego słowa lub jego części. Uwaga kompresuje ilość informacji, których model potrzebuje do przewidywania następnego tokena lub słowa. Typowe mechanizmy uwagi mogą składać się z ważonej sumy zbioru danych wejściowych, gdzie waga dla każdego wejścia jest obliczana przez inną część sieci neuronowej.
Zapoznaj się też z konceptami samouczenia uwagi i samouczenia uwagi z wieloma głowami, które są elementami składowymi transformacji.
Więcej informacji o samouczeniu znajdziesz w artykule LLM: czym są duże modele językowe? z cyklu „Szkolenie z systemów uczących się”.
autoencoder
System, który uczy się wyodrębniać najważniejsze informacje z danych wejściowych. Autoenkodery to połączenie enkodera i dekodera. Autoenkodery działają w ramach następującego dwuetapowego procesu:
- Koder mapuje dane wejściowe na (zazwyczaj) stratny format o mniejszej wymiarowości (pośredni).
- Dekoder tworzy wersję pierwotnego wejścia z utratą jakości, mapując format o niższej wymiarowości na pierwotny format wejściowy o wyższej wymiarowości.
Autoenkodery są trenowane kompleksowo, a dekodery próbują odtworzyć oryginalne dane wejściowe z pośredniego formatu kodowania w jak najwierniejszy sposób. Ponieważ format pośredni jest mniejszy (ma mniejszą wymiarność) niż format oryginalny, autoencoder musi się nauczyć, które informacje wejściowe są niezbędne, a wyjście nie będzie dokładnie takie samo jak dane wejściowe.
Na przykład:
- Jeśli dane wejściowe to grafika, kopia nieścisła będzie podobna do oryginalnej grafiki, ale nieco zmodyfikowana. Być może kopia niepełna usuwa szum z pierwotnej grafiki lub wypełnia brakujące piksele.
- Jeśli dane wejściowe to tekst, autoencoder wygeneruje nowy tekst, który będzie naśladował (ale nie będzie identyczny) z oryginałem.
Zobacz też wariacyjne autoenkodery.
automatyczna ocena
Korzystanie z oprogramowania do oceny jakości danych wyjściowych modelu.
Gdy dane wyjściowe modelu są stosunkowo proste, skrypt lub program może porównać je z złotą odpowiedzią. Ten typ automatycznej oceny jest czasem nazywany automatyczną oceną. Dane takie jak ROUGE lub BLEU są często przydatne do automatycznej oceny.
Gdy dane wyjściowe modelu są złożone lub nie ma jednej prawidłowej odpowiedzi, automatyczną ocenę czasami wykonuje oddzielny program ML o nazwie autorater.
Porównaj z weryfikacją manualną.
autorater evaluation
Hybrydowy mechanizm oceny jakości danych wyjściowych generatywnej AI, który łączy ocenę manualną z oceną automatyczną. Autor tekstów to model ML trenowany na podstawie danych utworzonych przez ludzi. W idealnej sytuacji narzędzie automatyczne uczy się naśladować ludzkiego weryfikatora.Dostępne są gotowe autory, ale najlepsze autory są dopasowywane do konkretnego zadania, które oceniasz.
model autoregresyjny
model, który wyprowadza prognozę na podstawie swoich poprzednich prognoz. Na przykład autoregresyjne modele językowe przewidują następny token na podstawie wcześniej przewidzianych tokenów. Wszystkie duże modele językowe oparte na transformerach są autoregresyjne.
Z kolei modele obrazów oparte na GAN zwykle nie są autoregresywne, ponieważ generują obraz w jednym przejęciu do przodu, a nie w kolejnych krokach. Niektóre modele do generowania obrazów są autoregresyjne, ponieważ generują obraz krok po kroku.
średnia precyzja w k
Dane podsumowujące skuteczność modelu w przypadku pojedynczego promptu, który generuje wyniki w postaci rankingu, np. ponumerowaną listę rekomendacji książek. Średnia precyzja k to średnia precyzji dla każdego odpowiedniego wyniku. Wzór na średnią precyzję w przypadku k:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
gdzie:
- \(n\) to liczba odpowiednich elementów na liście.
Porównaj z przypomnieniem na poziomie k.
B
,bag of words
reprezentacja słów w wyrażeniu lub fragmencie tekstu, niezależnie od ich kolejności. Na przykład torebka słów identycznie reprezentuje te 3 wyrażenia:
- pies skacze
- skacze na psa
- pies skacze
Każde słowo jest mapowane na indeks w rzadkim wektorze, który zawiera indeks dla każdego słowa w słowniku. Na przykład wyrażenie pies skacze jest mapowane na wektor cech z wartościami innymi niż 0 w 3 indeksach odpowiadających słowom the, dog i jumps. Wartość różna od 0 może być dowolna:
- 1, aby wskazać obecność słowa.
- Liczba wystąpień danego słowa w worku. Jeśli na przykład wyrażenie brzmiałoby the maroon dog is a dog with maroon fur, zarówno maroon, jak i dog miałyby wartość 2, a pozostałe słowa – wartość 1.
- inną wartość, np. logarytm z liczby wystąpień słowa w worku.
BERT (Bidirectional Encoder Representations from Transformers)
Architektura modelu do reprezentowania tekstu. Wytrenowany model BERT może być częścią większego modelu do klasyfikacji tekstu lub innych zadań uczenia maszynowego.
BERT ma te cechy:
- Korzysta z architektury Transformer, a zatem opiera się na samouczeniu.
- Korzysta z części enkodera w modelu Transformer. Zadaniem kodera jest tworzenie dobrych reprezentacji tekstu, a nie wykonywanie konkretnych zadań, takich jak klasyfikacja.
- Jest dwukierunkowy.
- Używa maskowania do treningu nienadzorowanego.
Dostępne warianty BERT:
Aby zapoznać się z modelem BERT, przeczytaj artykuł Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing (Wstęp do BERT: wstępne trenowanie modelu BERT do przetwarzania języka naturalnego).
dwukierunkowy
Termin używany do opisania systemu, który ocenia tekst zarówno poprzedzający, jak i następujący docelowy fragment tekstu. Natomiast jednokierunkowy system analizuje tylko tekst, który poprzedza docelowy fragment tekstu.
Weźmy na przykład zamaskowany model językowy, który musi określić prawdopodobieństwa dla słowa lub słów reprezentowanych przez podkreślenie w takim pytaniu:
Co jest dla Ciebie ważne?
Model językowy jednokierunkowy musiałby opierać swoje prawdopodobieństwa tylko na kontekście określonym przez słowa „co”, „jest” i „to”. Natomiast dwukierunkowy model językowy może uzyskać kontekst z wyrażeń „z” i „ty”, co może pomóc w generowaniu lepszych prognoz.
dwukierunkowy model językowy
model językowy, który określa prawdopodobieństwo wystąpienia danego tokena w danej lokalizacji w wyciągu z tekstu na podstawie poprzedniego i następnego tekstu.
bigram
N-gram, w którym N=2.
BLEU (Bilingual Evaluation Understudy)
Dane o zakresie od 0,0 do 1,0 służące do oceny tłumaczeń maszynowych, np. z hiszpańskiego na japoński.
Aby obliczyć wynik, BLEU zwykle porównuje tłumaczenie modelu ML (tekst wygenerowany) z tłumaczeniem eksperta (tekst referencyjny). Wynik BLEU zależy od stopnia podobieństwa n-gramów w wygenerowanym tekście i tekście referencyjnym.
Pierwotny artykuł na temat tego wskaźnika to BLEU: a Method for Automatic Evaluation of Machine Translation (BLEU: metoda automatycznej oceny tłumaczenia maszynowego).
Zobacz też BLEURT.
BLEURT (Bilingual Evaluation Understudy from Transformers)
Wskaźnik służący do oceny tłumaczeń maszynowych z jednego języka na inny, zwłaszcza z i na język angielski.
W przypadku tłumaczeń z języka angielskiego i na angielski BLEURT jest bardziej zbliżony do ocen nadawanych przez ludzi niż BLEU. W przeciwieństwie do BLEU BLEURT podkreśla podobieństwa semantyczne (znaczeniowe) i może uwzględniać parafrazowanie.
BLEURT korzysta z wstępnie wytrenowanych dużych modeli językowych (dokładnie BERT), które są następnie dostrojone na podstawie tekstu od ludzkich tłumaczy.
Pierwotny artykuł na temat tego wskaźnika to BLEURT: Learning Robust Metrics for Text Generation.
C
przyczynowy model językowy
Synonim jednokierunkowego modelu językowego.
Zapoznaj się z artykułem Dwukierunkowa model języka, aby poznać różne podejścia do modelowania języka.
wykorzystanie w prompcie łańcucha myśli
Technika zastosowania prompta, która zachęca duży model językowy (LLM) do wyjaśnienia swojego rozumowania krok po kroku. Weź pod uwagę ten prompt, zwracając szczególną uwagę na drugie zdanie:
Ile g kierowca odczuwa w samochodzie, który przyspiesza z 0 do 60 mil na godzinę w 7 sekundach? W odpowiedzi pokaż wszystkie istotne obliczenia.
Odpowiedź LLM:
- Pokaż sekwencję wzorów fizycznych, podając w odpowiednich miejscach wartości 0, 60 i 7.
- Wyjaśnij, dlaczego wybrano te formuły i co oznaczają poszczególne zmienne.
Prompty z łańcuchem myśli zmuszają LLM do wykonania wszystkich obliczeń, co może prowadzić do bardziej prawidłowej odpowiedzi. Ponadto prompt łańcucha myśli umożliwia użytkownikowi sprawdzenie kroków LLM, aby określić, czy odpowiedź ma sens.
czat
Treść dialogu z systemem ML, zwykle z dużym modelem językowym. Poprzednia interakcja w czacie (to, co wpisano i jak zareagował duży model językowy) staje się kontekstem dla kolejnych części czatu.
Czatbot to aplikacja wykorzystująca duży model językowy.
konfabulacja
Synonim halucynacji.
Konfabulacja jest prawdopodobnie bardziej poprawnym terminem technicznym niż halucynacja. Jednak najpierw popularność zyskała halucynacja.
analizowanie okręgów wyborczych
Dzielenie zdania na mniejsze struktury gramatyczne („elementy składowe”). Późniejsza część systemu ML, np. model rozumienia języka naturalnego, może analizować składniki z większą łatwością niż oryginalne zdania. Weź pod uwagę na przykład takie zdanie:
Mój przyjaciel adoptował 2 koty.
Analizator składowych może podzielić to zdanie na 2 składniki:
- Mój przyjaciel to wyrażenie rzeczownikowe.
- adopt two cats to wyrażenie zawierające czasownik.
Te składniki można dalej dzielić na mniejsze składniki. Na przykład czasownik
adoptował 2 koty
można podzielić na:
- adopted to czasownik.
- dwa koty to kolejne wyrażenie rzeczownikowe.
kontekstowy wektor dystrybucyjny języka
Wpisanie, które zbliża się do „rozumienia” słów i wyrażeń w sposób podobny do tego, w jaki robią to płynnie mówiący ludzie. Umieszczanie w kontekście za pomocą wektorów uczenia głębokiego może pomóc w rozumieniu złożonej składni, semantyki i kontekstu.
Rozważmy na przykład wektory zastępcze słowa cow (ang. „krowa”). Starsze wektory zanurzeniowe, takie jak word2vec, mogą reprezentować angielskie słowa w taki sposób, że odległość w przestrzeni wektorów zanurzeniowych od cow do bull jest podobna do odległości od ewe do ram (samiec owcy) lub od female do male (samiec). Umieszczanie w kontekście zasobów danych językowych może być jeszcze bardziej przydatne, ponieważ pozwala rozpoznać, że użytkownicy języka angielskiego czasami używają słowa cow (krowa) w oznaczaniu zarówno krowy, jak i byka.
okno kontekstu
Liczba tokenów, które model może przetworzyć w danym promptzie. Im większe okno kontekstu, tym więcej informacji może wykorzystać model, aby udzielić spójnych i konsekwentnych odpowiedzi na prompt.
crash blossom
zdanie lub wyrażenie o niejednoznacznym znaczeniu; Crash blossoms stanowią poważny problem w rozumieniu języka naturalnego. Na przykład nagłówek Nadmiarkowa biurokracja blokuje wieżowiec to kwintesencja crash blossom, ponieważ model NLU może interpretować nagłówek dosłownie lub przenośnie.
D
dekoder
Ogólnie chodzi o dowolny system ML, który przekształca przetworzoną, gęstą lub wewnętrzną reprezentację w nieprzetworzoną, rzadką lub zewnętrzną reprezentację.
Dekodery są często elementem większego modelu, w którym często są sparowane z enkoderem.
W zadaniach sekwencja–sekwencja dekoder zaczyna od stanu wewnętrznego wygenerowanego przez koder, aby przewidzieć następną sekwencję.
Definicję dekodera w ramach architektury transformera znajdziesz w artykule Transformer.
Więcej informacji znajdziesz w sekcji Duże modele językowe w Szybkim szkoleniu z uczenia maszynowego.
usuwanie szumów
Typowe podejście do samokontrolowanego uczenia się:
Denoising umożliwia uczenie się na nieoznaczonych przykładach. Pierwotny zbiór danych służy jako docel lub etykieta, a zaszumione dane są wejściem.
Niektóre zamaskowane modele językowe używają funkcji redukcji szumów w ten sposób:
- Do nieoznaczonego zdania dodawany jest sztucznie szum przez zamaskowanie niektórych tokenów.
- Model próbuje przewidzieć oryginalne tokeny.
bezpośrednie prompty
Synonim promptów „zero-shot”.
E
edytuj odległość
Pomiar podobieństwa 2 ciągów tekstowych. W systemach uczących się odległość edytowania jest przydatna z tych powodów:
- Odległość edytowania jest łatwa do obliczenia.
- Odległość edycji umożliwia porównanie 2 ciągów, które są do siebie podobne.
- Odległość edycji może określać stopień podobieństwa różnych ciągów znaków do danego ciągu znaków.
Istnieje kilka definicji odległości edycji, z których każda wykorzystuje inne operacje na ciągach znaków. Przykładem jest odległość Levenshteina.
warstwa wstawiania
Specjalny warstw ukryty, który trenuje na podstawie cechy kategorialnej o wysokiej wymiarowości, aby stopniowo uczyć się wektora zanurzonego o niższej wymiarowości. Warstwę embeddingu można wykorzystać do trenowania sieci neuronowej w znacznie bardziej wydajny sposób niż przy użyciu tylko cechy wielowymiarowej.
Na przykład Earth obsługuje obecnie około 73 tys. gatunków drzew. Załóżmy, że gatunek drzewa jest atrybutem w Twoim modelu,więc warstwa wejściowa modelu zawiera wektor typu „jeden-gorący o długości 73 000 elementów.
Na przykład baobab będzie wyglądać tak:

Tablica o 73 tys. elementach jest bardzo długa. Jeśli nie dodasz do modelu warstwy embeddingu, trenowanie zajmie bardzo dużo czasu z powodu mnożenia 72 999 zer. Możesz wybrać warstwę z 12 wymiarami. W konsekwencji warstwa embeddingu będzie stopniowo uczyć się nowego wektora embeddingu dla każdego gatunku drzewa.
W niektórych sytuacjach zaszyfrowanie jest odpowiednią alternatywą dla warstwy umieszczania.
Więcej informacji znajdziesz w sekcji Embeddings w szybkim szkoleniu z uczenia maszynowego.
przestrzeń do wklejania
D-wymiarowa przestrzeń wektorowa, do której mapowane są cechy z wyższej wymiarowości. Przestrzeń do wklejania jest trenowana w celu przechwytywania struktury, która jest istotna dla danego zastosowania.
Iloczyn skalarny 2 wewnętrznych obiektów jest miarą ich podobieństwa.
wektor dystrybucyjny
Ogólnie mówiąc, tablica liczb zmiennoprzecinkowych pobranych z dowolnego ukrytego warstwy, które opisują dane wejściowe tej ukrytej warstwy. Często wektor ten jest tablicą liczb zmiennoprzecinkowych wytrenowanych w warstwie embeddingu. Załóżmy na przykład, że warstwa embeddingu musi nauczyć się wektora embeddingu dla każdego z 73 tys. gatunków drzew na Ziemi. Być może następująca tablica jest wektorem dystrybucyjnym baobabu:

Wektor dystrybucyjny to nie zbiór losowych liczb. Warstwę wbudowania określają te wartości podczas trenowania, podobnie jak sieć neuronowa uczy się innych wag podczas trenowania. Każdy element tablicy to ocena pewnej cechy gatunku drzewa. Który element reprezentuje którą cechę gatunku drzew? Jest to bardzo trudne do określenia przez ludzi.
Matematycznie niezwykłą cechą wektora dystrybucyjnego jest to, że podobne elementy mają podobne zbiory liczb zmiennoprzecinkowych. Na przykład podobne gatunki drzew mają bardziej podobny zestaw liczb zmiennoprzecinkowych niż niepodobna do siebie grupa gatunków drzew. Sekwoje i sekwojedy mają podobne gatunki drzew, więc będą miały bardziej podobny zestaw liczb zmiennoprzecinkowych niż sekwoje i palmy kokosowe. Liczby w wektorze zastępczym będą się zmieniać za każdym razem, gdy ponownie przeszkolisz model, nawet jeśli będziesz to robić z identycznymi danymi wejściowymi.
koder
Ogólnie chodzi o dowolny system ML, który przekształca dane w postaci nieprzetworzonej, rzadkiej lub zewnętrznej w postać bardziej przetworzoną, gęstszą lub bardziej wewnętrzną.
Enkodery są często elementem większego modelu, w którym często są połączone z dekoderem. Niektóre transformery łączą kodery z dekoderami, ale inne używają tylko kodera lub tylko dekodera.
Niektóre systemy używają danych wyjściowych kodera jako danych wejściowych do sieci klasyfikacyjnej lub regresyjnej.
W zadaniach sekwencja–sekwencja enkoder przyjmuje sekwencję wejściową i zwraca stan wewnętrzny (wektory). Następnie dekoder używa tego stanu wewnętrznego do przewidywania następnej sekwencji.
Definicję enkodera w architekturze Transformer znajdziesz w artykule Transformer.
Więcej informacji znajdziesz w części LLMs: What's a large language model (Duże modele językowe: co to jest duży model językowy) w sekcji Szybkie szkolenie z systemów uczących się.
evals
Jest to głównie skrót od oceny LLM. Ogólnie rzecz biorąc, evals to skrót od dowolnej formy oceny.
ocena
Proces pomiaru jakości modelu lub porównywania różnych modeli.
Aby ocenić nadzorowany model uczenia maszynowego, zwykle porównujemy go z zestawami walidacyjnym i testowym. Ocena modelu LLMzazwyczaj obejmuje szerszą ocenę jakości i bezpieczeństwa.
F
prompty „few-shot”
prompt zawierający więcej niż 1 (czyli „kilka”) przykładów pokazujących, jak duży model językowy powinien odpowiadać. Na przykład ten długi prompt zawiera 2 przykłady, które pokazują dużemu modelowi językowemu, jak odpowiadać na zapytanie.
| Części jednego promptu | Uwagi |
|---|---|
| Jaka jest oficjalna waluta w wybranym kraju? | Pytanie, na które chcesz uzyskać odpowiedź od modelu LLM. |
| Francja: EUR | Przykład: |
| Wielka Brytania: GBP | Inny przykład |
| Indie: | Faktyczne zapytanie. |
Prompty „few-shot” zwykle przynoszą lepsze wyniki niż prompty „zero-shot” i „one-shot”. Prompty „few-shot” wymagają jednak dłuższego promptu.
Prompty „few-shot” to forma uczenia się typu „few-shot”, stosowana w uczeniu się na podstawie promptów.
Więcej informacji znajdziesz w sekcji Projektowanie promptów w szybkim szkoleniu z uczenia maszynowego.
Skrzypce
Biblioteka konfiguracyjna napisana głównie w Pythonie, która ustawia wartości funkcji i klas bez konieczności stosowania inwazyjnego kodu lub infrastruktury. W przypadku Pax i innych baz kodu ML te funkcje i klasy reprezentują modele i trenowanie parametry hiperzmiennych.
Fiddle zakłada, że kody baz danych systemów uczących się są zwykle podzielone na:
- kod biblioteki, który definiuje warstwy i optymalizatory;
- kod „klejący” zbiór danych, który wywołuje biblioteki i połącza wszystko ze sobą.
Fiddle rejestruje strukturę wywołań kodu pośredniczącego w nieocenionej i zmiennej formie.
dostrojenie
Drugi przejazd treningowy, który jest wykonywany na wytrenowanym wcześniej modelu w celu dostosowania jego parametrów do konkretnego zastosowania. Przykładowa pełna sekwencja trenowania niektórych dużych modeli językowych:
- Wstępne trenowanie: trenowanie dużego modelu językowego na ogromnym ogólnym zbiorze danych, takim jak wszystkie strony Wikipedii w języku angielskim.
- Dostosowywanie: wytrenowanie wstępnie wytrenowanego modelu do wykonywania konkretnego zadania, np. odpowiadania na pytania medyczne. Dostrojenie polega zwykle na wykorzystaniu setek lub tysięcy przykładów dotyczących konkretnego zadania.
Innym przykładem jest pełna sekwencja trenowania dużego modelu obrazu:
- Wstępne trenowanie: trenowanie dużego modelu obrazów na olbrzymim ogólnym zbiorze danych, takim jak wszystkie obrazy w Wikimedia Commons.
- Dostrojenie: wytrenowanie wstępnie przeszkolonego modelu do wykonywania konkretnego zadania, np. generowania obrazów orek.
Dostosowanie dokładne może obejmować dowolną kombinację tych strategii:
- zmodyfikować wszystkie istniejące parametry wytrenowanego wcześniej modelu; Czasami nazywa się to pełnym dostrojeniem.
- Modyfikowanie tylko niektórych dotychczasowych parametrów w modelu wstępnie wytrenowanym (zazwyczaj warstw najbliżej warstwy wyjściowej), przy zachowaniu innych dotychczasowych parametrów (zazwyczaj warstw najbliżej wejściowej warstwy). Zobacz dostrajanie z uwzględnieniem wydajności.
- Dodawanie kolejnych warstw, zwykle na wierzchu istniejących warstw najbliżej warstwy wyjściowej.
Dostrojenie to forma uczenia się przez przenoszenie. W ramach dostrojenia można użyć innej funkcji utraty lub innego typu modelu niż te, które zostały użyte do trenowania wstępnie wytrenowanego modelu. Możesz na przykład dostosować wstępnie wytrenowany model dużych obrazów, aby uzyskać model regresji zwracający liczbę ptaków na obrazie wejściowym.
Porównaj dostosowanie do tych terminów:
Więcej informacji znajdziesz w części Dostrojenie w Szybkim szkoleniu z uczenia maszynowego.
Len
Wysokowydajna biblioteka open source do uczenia głębokiego oparta na JAX. Flax udostępnia funkcje treningu sieci neuronowych oraz metody oceny ich wydajności.
Flaxformer
Biblioteka Transformer oparta na Flaxie, przeznaczona głównie do przetwarzania języka naturalnego i badania multimodalnego.
G
Gemini
Ekosystem obejmujący najbardziej zaawansowaną AI od Google. Elementy tego ekosystemu:
- Różne modele Gemini.
- Interaktywny interfejs konwersacyjny do modelu Gemini. Użytkownicy wpisują prompty, a Gemini na nie odpowiada.
- różne interfejsy Gemini API.
- różne usługi biznesowe oparte na modelach Gemini, np. Gemini dla Google Cloud.
Modele Gemini
Najnowocześniejsze modele multimodalne oparte na Transformerze od Google. Modele Gemini zostały zaprojektowane specjalnie do integracji z agentami.
Użytkownicy mogą wchodzić w interakcje z modelami Gemini na różne sposoby, m.in. za pomocą interaktywnego interfejsu dialogowego i pakietów SDK.
wygenerowany tekst
Ogólnie tekst generowany przez model ML. Podczas oceny dużych modeli językowych niektóre dane porównują wygenerowany tekst z tekstem referencyjnym. Załóżmy na przykład, że chcesz sprawdzić, jak skutecznie model ML tłumaczy z języka francuskiego na holenderski. W tym przypadku:
- Wygenerowany tekst to tłumaczenie na język niderlandzki, które generuje model uczenia maszynowego.
- Tekst referencyjny to tłumaczenie na język niderlandzki, które zostało utworzone przez tłumacza (lub oprogramowanie).
Pamiętaj, że niektóre strategie oceny nie uwzględniają tekstu odniesienia.
generatywnej AI
Nowe, rewolucyjne pole, które nie ma formalnej definicji. Większość ekspertów zgadza się jednak, że modele generatywnej AI mogą tworzyć („generować”) treści, które:
- złożone
- spójny
- oryginał
Na przykład model generatywnej AI może tworzyć zaawansowane eseje lub obrazy.
Niektóre starsze technologie, w tym sieci LSTM i sieci RNN, również mogą generować oryginalne i spójne treści. Niektórzy eksperci uważają, że te wcześniejsze technologie są generatywną AI, podczas gdy inni uważają, że prawdziwa generatywna AI wymaga bardziej złożonego wyjścia niż te wcześniejsze technologie.
W przeciwieństwie do systemów ML prognozujących.
złota odpowiedź
Odpowiedź, która jest dobra. Na przykład w przypadku tego prompta:
2 + 2
Najlepszą odpowiedzią jest:
4
GPT (generatywna, wstępnie wytrenowana sieć Transformer)
Rodzina dużych modeli językowych opartych na architekturze Transformer opracowanych przez OpenAI.
Warianty GPT mogą dotyczyć wielu modalności, w tym:
- generowanie obrazów (np. ImageGPT);
- generowanie obrazu na podstawie tekstu (np. DALL-E).
H
halucynacja
wygenerowanie przez generatywną AI wiarygodnie wyglądającego, ale nieprawdziwego wyniku, który ma stanowić twierdzenie o rzeczywistym świecie. Na przykład model generatywnej AI, który twierdzi, że Barack Obama zmarł w 1865 r., halucynuje.
sprawdzenie przez weryfikatora
Proces, w którym ludzie oceniają jakość danych wyjściowych modelu AI; na przykład osoby dwujęzyczne oceniają jakość tłumaczenia maszynowego. Weryfikacja manualna jest szczególnie przydatna do oceny modeli, które nie mają jednej prawidłowej odpowiedzi.
Porównaj z automatyczną oceną i ocenianiem przez automatyczny program.
I
uczenie się w kontekście
Synonim promptów „few-shot”.
L
LaMDA (Language Model for Dialogue Applications)
Transformer duży model językowy opracowany przez Google na podstawie dużego zbioru danych dialogowych, który może generować realistyczne odpowiedzi w formie konwersacji.
LaMDA – nasza rewolucyjna technologia konwersacyjna zawiera omówienie.
model językowy
Model, który szacuje prawdopodobieństwo wystąpienia tokena lub sekwencji tokenów w dłuższej sekwencji tokenów.
Więcej informacji znajdziesz w części Co to jest model językowy? w Szybkim szkoleniu z uczenia maszynowego.
duży model językowy
Minimalnie model językowy o bardzo dużej liczbie parametrów. Nieformalnie: dowolny model językowy oparty na Transformerze, np. Gemini lub GPT.
Więcej informacji znajdziesz w sekcji Duże modele językowe (LLM) w szybkim szkoleniu z uczenia maszynowego.
przestrzeń ukryta
Synonim przestrzeni wektorów dystrybucyjnych.
odległość Levenshteina,
Wskaźnik odległość edycji, który oblicza najmniejszą liczbę operacji usuwania, wstawiania i zastępowania niezbędnych do zamiany jednego słowa na drugie. Na przykład odległość Levenshteina między słowami „serce” i „rzutki” wynosi 3, ponieważ te 3 zmiany wymagają najmniejszej liczby modyfikacji, aby jedno słowo zamienić na drugie:
- heart → deart (zastąp „h” przez „d”)
- deart → dart (usuń „e”)
- dart → darts (insert "s")
Powyższa sekwencja nie jest jedyną ścieżką z 3 edycjami.
LLM
Skrót od duży model językowy.
Oceny LLM (evals)
Zestaw danych i punktów odniesienia do oceny skuteczności dużych modeli językowych (LLM). Ogólnie oceny LLM:
- Pomagać badaczom w określaniu obszarów, w których modele LLM wymagają poprawy.
- przydają się do porównywania różnych modeli LLM i określania, który z nich najlepiej nadaje się do danego zadania;
- pomagać w zapewnieniu bezpieczeństwa i zgody z zasadami etycznymi w przypadku modeli LLM.
Aby dowiedzieć się więcej, zapoznaj się z sekcją Duże modele językowe (LLM) w Szybkim szkoleniu z uczenia maszynowego.
LoRA
Skrót od Low-Rank Adaptation.
Adaptacja niskiego rzędu (LoRA)
Techniczne zagadnienia związane z parametrami dotyczące dokładnego dostrojenia, które polega na „zamrożeniu” wstępnie wytrenowanych wag modelu (aby nie można ich było już modyfikować), a następnie wstawianiu do modelu małego zbioru wag do trenowania. Ten zbiór trenowanych wag (zwany też „macierzami aktualizacji”) jest znacznie mniejszy niż model podstawowy, a więc jego trenowanie przebiega znacznie szybciej.
LoRA zapewnia te korzyści:
- Poprawia jakość prognoz modelu w przypadku domeny, w której zastosowano dostrajanie.
- Szybciej dostosowuje model niż techniki, które wymagają dostosowania wszystkich jego parametrów.
- Zmniejsza koszt obliczeń wywnioskowania przez umożliwienie jednoczesnego obsługiwania wielu wyspecjalizowanych modeli, które mają ten sam model podstawowy.
M
zamaskowany model językowy
model językowy, który przewiduje prawdopodobieństwo, że tokeny kandydatów wypełnią puste miejsca w sekwencji. Na przykład zamaskowana model języka może obliczyć prawdopodobieństwa dla słów kandydujących, aby zastąpić podkreślenie w tym zdaniu:
Z czapki wróciła do mnie ta sama osoba.
W dokumentacji zamiast podkreślenia zwykle używany jest ciąg „MASK”. Na przykład:
Maska w kapeluszu wróciła.
Większość współczesnych zamaskowanych modeli językowych jest dwukierunkowa.
średnia średnia precyzja w k (mAP@k)
Statystyczna średnia wszystkich wyników średniej precyzji na k w przypadku zbioru danych do weryfikacji. Średnia średnia dokładność w k służy m.in. do oceny jakości rekomendacji generowanych przez system rekomendacji.
Chociaż wyrażenie „średnia średnia” brzmi niepotrzebnie, nazwa tego wskaźnika jest odpowiednia. Ten wskaźnik oblicza średnią średnią dokładność w przypadku k wartości.
metauczenie się
Podzbiór systemów uczących się, który wykrywa lub ulepsza algorytm uczenia się. System metanauki może też dążyć do wytrenowania modelu, aby szybko uczyć się nowego zadania na podstawie niewielkiej ilości danych lub doświadczenia zdobytego podczas wykonywania poprzednich zadań. Algorytmy metauczenia się zazwyczaj próbują osiągnąć te cele:
- Ulepszać lub uczyć się funkcji ręcznie zaprojektowanych (takich jak inicjalizator czy optymalizator).
- oszczędność danych i zasobów obliczeniowych;
- poprawa uogólniania;
Metanauka jest powiązana z nauką typu few-shot.
mieszanka ekspertów
Schemat zwiększania wydajności sieci neuronowej przez wykorzystanie tylko podzbioru jej parametrów (zwanego ekspertem) do przetwarzania danego wejściowego tokena lub przykładu. Gating network kieruje każdy token wejściowy lub przykład do odpowiednich ekspertów.
Szczegółowe informacje znajdziesz w tych artykułach:
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Mieszanie ekspertów z opcją wyboru eksperta (Routing)
MMIT
Skrót od multimodal instruction-tuned.
modalność
Ogólna kategoria danych. Na przykład liczby, tekst, obrazy, filmy i dźwięk to 5 różnych modalności.
model równoległości
Sposób skalowania treningu lub wnioskowania, który polega na umieszczeniu różnych części jednego modelu na różnych urządzeniach. Modelowanie równoległe umożliwia tworzenie modeli, które są zbyt duże, aby zmieścić się na jednym urządzeniu.
Aby wdrożyć równoległość modelu, system zwykle wykonuje te czynności:
- Dzieli model na mniejsze części.
- Rozprowadza szkolenie tych mniejszych części na wiele procesorów. Każdy procesor trenuje inną część modelu.
- Łączy wyniki, aby utworzyć jeden model.
Równoległe wykonywanie działań przez model spowalnia trenowanie.
Zobacz też równoległość danych.
MOE
Skrót od mixture of experts.
wieloczęściowa samouwaga
Rozszerzenie samouczenia, które stosuje mechanizm samouczenia wielokrotnie w przypadku każdej pozycji w sekwencji wejściowej.
Transformery wprowadziły wielogłowe mechanizmy samouczenia.
multimodal instruction-tuned
Model dostosowany do instrukcji, który może przetwarzać dane wejściowe inne niż tekst, np. obrazy, filmy i dźwięk.
model multimodalny
Model, którego dane wejściowe, dane wyjściowe lub oba te elementy obejmują więcej niż jedną modalność. Weźmy na przykład model, który jako cechy przyjmuje obraz i tekstowy podpis (2 modalności) i wydaje wynik wskazujący, na ile tekstowy podpis jest odpowiedni do obrazu. Dane wejściowe tego modelu są multimodalne, a dane wyjściowe – unimodalne.
N
przetwarzanie języka naturalnego
Nauka komputerów przetwarzania wypowiedzi lub wpisów użytkownika za pomocą reguł językowych. Prawie wszystkie współczesne systemy przetwarzania języka naturalnego opierają się na uczeniu maszynowym.rozumienie języka naturalnego
Podzbiór przetwarzania języka naturalnego, który określa zamiary wypowiedzi lub wpisów. Rozumienie języka naturalnego może wykraczać poza przetwarzanie języka naturalnego i uwzględniać złożone aspekty języka, takie jak kontekst, sarkazm i nastawienie.
N-gram
Uporządkowana sekwencja N słów. Na przykład truly madly to 2-gram. Ponieważ kolejność jest istotna, madly truly to inny 2-gram niż truly madly.
| N | Nazwa(y) tego typu N-gramu | Przykłady |
|---|---|---|
| 2 | bigram lub 2-gram | go, go to, eat lunch, eat dinner |
| 3 | trigram lub 3-gram | ate too much, happily ever after, the bell tolls |
| 4 | 4-gram | walk in the park, dust in the wind, the boy ate lentils |
Wiele modeli rozumiejących język naturalny korzysta z gramów N-gramów, aby przewidywać kolejne słowo, które użytkownik wpisze lub powie. Załóżmy na przykład, że użytkownik wpisał happily ever. Model NLU oparty na trigramach najprawdopodobniej przewidzi, że użytkownik wpisze słowo after.
Kontrastuj N-gramy z teczką słów, która jest nieuporządkowanym zbiorem słów.
Więcej informacji znajdziesz w sekcji Duże modele językowe w Szybkim szkoleniu z uczenia maszynowego.
NLP
Skrót od przetwarzania języka naturalnego.
NLU
Skrót od rozumienia języka naturalnego.
no one right answer (NORA)
prompt z kilkoma odpowiednimi odpowiedziami. Na przykład ten prompt nie ma jednej prawidłowej odpowiedzi:
Opowiedz mi dowcip o słoniach.
Ocenianie promptów bez jednoznacznej odpowiedzi może być trudne.
NORA
Skrót od brak prawidłowej odpowiedzi.
O
prompty „one-shot”
prompt zawierający jeden przykład pokazujący, jak duży model językowy powinien odpowiadać. Na przykład poniższy prompt zawiera jeden przykład pokazujący dużemu modelowi językowemu, jak ma odpowiedzieć na zapytanie.
| Części jednego promptu | Uwagi |
|---|---|
| Jaka jest oficjalna waluta w wybranym kraju? | Pytanie, na które chcesz uzyskać odpowiedź od modelu LLM. |
| Francja: EUR | Przykład: |
| Indie: | Faktyczne zapytanie. |
Porównaj promptowanie jednorazowe z tymi terminami:
P
dostrajanie z optymalnym wykorzystaniem parametrów
Zestaw technik dostrajania dużego wstępnie wytrenowanego modelu językowego (PLM) w bardziej efektywny sposób niż pełne dostrajanie. Dostrajanie konkretnych parametrów zwykle dotyczy znacznie mniejszej liczby parametrów niż pełne dostrajanie, ale zazwyczaj powoduje powstanie dużego modelu językowego, który działa tak samo dobrze (lub prawie tak samo dobrze) jak duży model językowy utworzony na podstawie pełnego dostrajania.
Porównaj dostrajanie z uwzględnieniem wydajności parametrów z:
Dostrajanie z uwzględnieniem wydajności parametrów to także dostrajanie z uwzględnieniem wydajności parametrów.
przetwarzanie w potoku
Forma paralelizowania modelu, w której przetwarzanie modelu jest dzielone na kolejne etapy, a każdy z nich jest wykonywany na innym urządzeniu. Podczas przetwarzania jednej partii przez jeden etap poprzedni etap może pracować nad kolejną partią.
Zobacz też szkolenie w etapach.
PLM
Skrót od wytrenowanego modelu językowego.
kodowanie pozycyjne
Technika polegająca na dodawaniu informacji o pozycji tokena w sekwencji do jego zanurzania. Modele typu transformer korzystają z kodowania pozycyjnego, aby lepiej zrozumieć zależność między różnymi częściami sekwencji.
Typowa implementacja kodowania pozycyjnego używa funkcji sinusoidalnej. (W szczególności częstotliwość i amplituda funkcji sinusoidalnej są określane przez pozycję tokena w sekwencji). Ta technika umożliwia modelowi Transformer uczenie się zwracania uwagi na różne części sekwencji na podstawie ich pozycji.
model po trenowaniu
Luźno zdefiniowany termin, który zwykle odnosi się do wytrenowanego modelu, który przeszedł pewien proces przetwarzania, np. jeden z tych:
dokładność k (precision@k)
Dane służące do oceny uszeregowanej (posortowanej) listy elementów. Dokładność na poziomie k określa ułamek pierwszych k elementów na liście, które są „odpowiednie”. Czyli:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
Wartość parametru k musi być mniejsza lub równa długości zwracanej listy. Pamiętaj, że długość zwróconej listy nie jest uwzględniana w obliczeniach.
Odpowiednie treści są często subiektywną kwestią. Nawet eksperci oceniacze często nie zgadzają się co do tego, które treści są odpowiednie.
Porównaj z:
wytrenowany model
Zwykle jest to model, który został już wytrenowany. Termin ten może też oznaczać wcześniej wytrenowany wektor zanurzeniowy.
Termin wstępnie wytrenowany model językowy zwykle odnosi się do już wytrenowanych dużych modeli językowych.
przed treningiem
Wstępne trenowanie modelu na dużym zbiorze danych. Niektóre wytrenowane wstępnie modele są niezgrabnymi olbrzymami i zwykle trzeba je dopracować, przeprowadzając dodatkowe szkolenie. Na przykład eksperci od uczenia maszynowego mogą wstępnie wytrenować duży model językowy na podstawie ogromnego zbioru danych tekstowych, takiego jak wszystkie strony w języku angielskim w Wikipedii. Po wstępnym trenowaniu model może zostać dopracowany za pomocą jednej z tych technik:
- distillation
- dokładne dopasowanie,
- dostrajanie instrukcji
- dostrajanie z optymalnym wykorzystaniem parametrów
- prompt-tuning
prompt
dowolny tekst wprowadzony jako dane wejściowe do dużego modelu językowego, aby model zachowywał się w określony sposób. Prompty mogą być krótkie (wyrażenie) lub dowolnie długie (np. cały tekst powieści). Prompty dzielą się na kilka kategorii, m.in. te wymienione w tabeli poniżej:
| Kategoria promptu | Przykład | Uwagi |
|---|---|---|
| Pytanie | Jak szybko potrafi latać gołąb? | |
| Instrukcja | Napisz zabawny wiersz o arbitrażu. | Prompt, który prosi duży model językowy o coś zrobienie. |
| Przykład | Przekształcaj kod Markdown w kod HTML. Na przykład: Markdown: * element listy HTML: <ul> <li>element listy</li> </ul> |
Pierwsze zdanie w tym przykładowym promptu to instrukcja. Pozostała część promptu to przykład. |
| Rola | Wyjaśnij, dlaczego zstępowanie ku gradientowi jest używane w treningu uczenia maszynowego w przypadku osoby z doktoratem z fizyki. | Pierwsza część zdania to instrukcja, a wyrażenie „doktorat z fizyki” to część dotycząca roli. |
| Częściowe dane wejściowe do uzupełnienia przez model | Premier Wielkiej Brytanii mieszka pod adresem | Prompt dotyczący częściowego wprowadzania danych może kończyć się nagle (jak w tym przykładzie) lub podkreśleniem. |
Model generatywnej AI może odpowiadać na prompt tekstem, kodem, obrazami, embeddingami, filmami... prawie wszystkim.
nauka oparta na promptach,
Umiejętność niektórych modeli, która umożliwia im dostosowanie ich zachowania w odpowiedzi na dowolny tekst wejściowy (prompty). W typowej paradygmacie uczenia się na podstawie promptów duży model językowy odpowiada na prompt, generując tekst. Załóżmy na przykład, że użytkownik wpisuje ten prompt:
Opisz trzecią zasadę dynamiki Newtona.
Model zdolny do uczenia się na podstawie promptów nie jest specjalnie trenowany do odpowiadania na poprzedni prompt. Model „zna” wiele faktów z fizyki, wiele o ogólnych regułach językowych i wiele o tym, co stanowi ogólnie przydatne odpowiedzi. Te informacje wystarczą, aby udzielić (miejmy nadzieję) przydatnej odpowiedzi. Dodatkowe opinie użytkowników („Ta odpowiedź była zbyt skomplikowana” lub „Jaka jest Twoja reakcja?”) umożliwiają niektórym systemom uczącym się na podstawie promptów stopniowe polepszanie przydatności odpowiedzi.
projektowanie promptów
Synonim tworzenia promptów.
tworzenie promptów
Sztuka tworzenia promptów, które wywołują pożądane odpowiedzi dużych modeli językowych. prompty są tworzone przez ludzi; Pisanie dobrze sformatowanych promptów jest kluczowe, aby uzyskać przydatne odpowiedzi od dużego modelu językowego. Projektowanie promptów zależy od wielu czynników, w tym:
- Zbiór danych użyty do wstępnego trenowania i ewentualnego dostrajania dużego modelu językowego.
- temperaturę i inne parametry dekodowania, których model używa do generowania odpowiedzi.
Projektowanie promptów to synonim tworzenia promptów.
Więcej informacji o tworzeniu przydatnych promptów znajdziesz w artykule Wprowadzenie do projektowania promptów.
dostrajanie promptów
Mechanizm skutecznego doboru parametrów, który uczy się „prefiksu”, który system dołącza do rzeczywistego prompta.
Jednym z wariantów dostosowania promptu – czasami nazywanego dostosowywaniem prefiksu – jest dodawanie prefiksu do każdej warstwy. Większość ustawień prompta dodaje tylko prefiks do warstwy wejściowej.
R
współczynnik czułości k (recall@k)
Dane służące do oceny systemów, które zwracają uporządkowaną listę elementów. Odsetek przy k określa ułamek odpowiednich elementów w pierwszych k elementach na liście spośród łącznej liczby zwróconych odpowiednich elementów.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Porównaj z precyzją w k.
tekst referencyjny
odpowiedź eksperta na prompt. Na przykład:
Przetłumacz pytanie „Jak masz na imię?” z angielskiego na francuski.
Odpowiedź eksperta może wyglądać tak:
Comment vous appelez-vous?
Różne dane (np. ROUGE) mierzą stopień, w jaki tekst referencyjny pasuje do tekstu wygenerowanego przez model AI.
prompty dotyczące ról
Opcjonalna część promptu, która identyfikuje docelową grupę odbiorców odpowiedzi modelu generatywnej AI. Bez promptu duży model językowy podaje odpowiedź, która może być przydatna dla osoby zadającej pytanie, a może nie. Za pomocą prompta roli duży model językowy może udzielać odpowiedzi w sposób bardziej odpowiedni i przydatny dla konkretnej grupy odbiorców. Na przykład w tych promptach pogrubiliśmy fragmenty dotyczące ról:
- Streść ten dokument dla osoby z doktoratem z ekonomii.
- Opisz, jak działają pływy dziecku w wieku 10 lat.
- Wyjaśnij kryzys finansowy z 2008 r. Mów tak, jak do małego dziecka lub złotego retrievera.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Rodzina wskaźników, które oceniają automatyczne streszczenia i modele tłumaczeń maszynowych. Dane ROUGE określają, w jakim stopniu tekst referencyjny pokrywa się z tekstem wygenerowanym przez model ML. Każdy z elementów rodziny ROUGE różni się od siebie sposobem nakładanie się pomiarów. Wyższe wyniki ROUGE wskazują na większe podobieństwo tekstu referencyjnego do wygenerowanego niż niższe wyniki ROUGE.
Każdy element rodziny ROUGE generuje zwykle te dane:
- Precyzja
- Czułość
- F1
Szczegółowe informacje i przykłady znajdziesz w tych artykułach:
ROUGE-L
Jest to element z rodziny ROUGE, który skupia się na długości najdłuższego wspólnego podciągu w tekście referencyjnym i tekście wygenerowanym. Te formuły obliczają czułość i precyzję w przypadku ROUGE-L:
Następnie możesz użyć F1, aby zsumować czułość ROUGE-L i dokładność ROUGE-L w jednym wskaźniku:
ROUGE-L ignoruje wszystkie znaki końca wiersza w tekście referencyjnym i wygenerowanym, więc najdłuższa wspólna podciąg znaków może obejmować kilka zdań. Gdy tekst referencyjny i wygenerowany tekst zawierają kilka zdań, lepszym wskaźnikiem jest zazwyczaj wariant ROUGE-L o nazwie ROUGE-Lsum. ROUGE-Lsum określa najdłuższy wspólny podciąg w każdej frazie w fragmentach tekstu, a następnie oblicza średnią z tych najdłuższych wspólnych podciągów.
ROUGE-N
Zestaw wskaźników z rodziny ROUGE, który porównuje wspólne N-gramy o określonym rozmiarze w tekście referencyjnym i tekście wygenerowanym. Na przykład:
- ROUGE-1 mierzy liczbę wspólnych tokenów w tekście referencyjnym i wygenerowanym.
- ROUGE-2 mierzy liczbę wspólnych bigramów (2-gramów) w tekście referencyjnym i wygenerowanym.
- ROUGE-3 mierzy liczbę wspólnych trójgramów (3-gramów) w tekście referencyjnym i wygenerowanym.
Aby obliczyć ROUGE-N i ROUGE-N dla dowolnego elementu z rodziny ROUGE-N, użyj tych wzorów:
Następnie możesz użyć F1, aby zsumować czułość ROUGE-N i precyzję ROUGE-N w jednym wskaźniku:
ROUGE-S
To łagodna forma ROUGE-N, która umożliwia dopasowanie skip-gram. Oznacza to, że ROUGE-N zlicza tylko n-gramy, które dokładnie pasują, ale ROUGE-S zlicza też n-gramy rozdzielone co najmniej 1 słowem. Na przykład:
- Tekst referencyjny: Białe chmury
- Wygenerowany tekst: Białe kłębiaste chmury
Podczas obliczania ROUGE-N 2-gram White clouds nie pasuje do White billowing clouds. Jednak podczas obliczania ROUGE-S White clouds pasuje do White billowing clouds.
S
samouwaga (nazywana też warstwą samouwagi)
Warstw sieci neuronowej, która przekształca sekwencję wektorów zastępczych (np. wektorów zastępczych tokenów) w inną sekwencję wektorów zastępczych. Każde wbudowanie w sekwencji wyjściowej jest tworzone przez integrację informacji z elementów sekwencji wejściowej za pomocą mechanizmu uwagi.
Część self w self-attention odnosi się do sekwencji, która zwraca uwagę na siebie, a nie na inny kontekst. Samouwaga jest jednym z głównych elementów składowych transformacji i korzysta z terminologii wyszukiwania w słowniku, takiej jak „zapytanie”, „klucz” i „wartość”.
Warstwę samouczenia rozpoczyna sekwencja wejść, po jednym dla każdego słowa. Dane wejściowe odpowiadające słowu mogą być prostym w ramach embeddingiem. W przypadku każdego słowa w sekwencji wejściowej sieć ocenia trafność słowa w odniesieniu do wszystkich elementów w całej sekwencji słów. Wyniki trafności określają, w jak dużym stopniu ostateczne przedstawienie słowa uwzględnia przedstawienia innych słów.
Weź pod uwagę na przykład takie zdanie:
Zwierzę nie mogło przejść przez ulicę, ponieważ było zbyt zmęczone.
Ilustracja poniżej (z artykułu Transformer: nowatorska architektura sieci neuronowych na potrzeby rozumienia języka) przedstawia wzór uwagi warstwy samouczenia w przypadku zaimka to. Im ciemniejszy jest dany wiersz, tym większy wkład ma on w reprezentację:
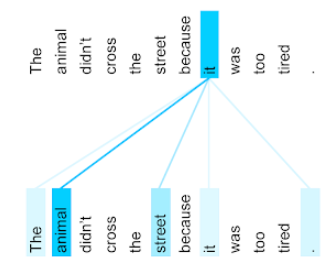
Warstwę samouczenia wyróżnia słowa, które są istotne dla „it”. W tym przypadku warstwa uwagi nauczyła się wyróżniać słowa, które może odnosić się do on, przypisując najwyższą wagę słowu zwierzę.
W przypadku sekwencji n tokenów transformacja samouczenia działa n razy, po jednym razie na każdą pozycję w sekwencji.
Zapoznaj się też z konceptem uwagi i samouwagi na wielu głowach.
analiza nastawienia
Korzystanie z algorytmów statystycznych lub systemów uczących się do określania ogólnego nastawienia grupy (pozytywnego lub negatywnego) wobec usługi, produktu, organizacji lub tematu. Na przykład za pomocą rozumienia języka naturalnego algorytm mógłby przeprowadzić analizę nastawienia na podstawie tekstowych opinii z kursu uniwersyteckiego, aby określić, na ile ogólnie studenci lubią ten kurs.
Więcej informacji znajdziesz w przewodniku dotyczącym klasyfikacji tekstu.
zadanie sekwencja-sekwencja
Zadanie, które konwertuje sekwencję wejściową tokenów na wyjściową sekwencję tokenów. Na przykład 2 popularne rodzaje zadań sekwencyjnych to:
- Tłumacze:
- Przykładowa sekwencja wejściowa: „Kocham Cię”.
- Przykładowa sekwencja danych wyjściowych: „Je t'aime”.
- Odpowiadanie na pytania:
- Przykładowa sekwencja danych wejściowych: „Czy potrzebuję samochodu w Nowym Jorku?”
- Przykładowa sekwencja danych wyjściowych: „Nie. Pozostaw samochód w domu”.
skip-gram
n-gram, który może pomijać (czyli „przeskakiwać”) słowa z pierwotnego kontekstu, co oznacza, że słowa N niekoniecznie muszą być pierwotnie sąsiadujące. Dokładniej rzecz biorąc, „k-skok-n-gram” to n-gram, w którym może zostać pominięty maksymalnie k słów.
Na przykład wyrażenie „szybka brązowa lisica” zawiera te możliwe 2-gramy:
- „the quick”
- „quick brown”
- „brown fox”
„1-skip-2-gram” to para słów, między którymi jest maksymalnie 1 słowo. Dlatego wyrażenie „szybka brązowa lisica” ma następujące 2-gramy z 1 przeskokiem:
- „brązowy”
- „quick fox”
Ponadto wszystkie dwugramy są również jednowyrazowymi dwugramami, ponieważ nie można pominąć mniej niż jednego słowa.
Skip-gramy są przydatne do zrozumienia szerszego kontekstu danego słowa. W tym przykładzie słowo „fox” było bezpośrednio powiązane ze słowem „quick” w zbiorze 1-skip-2-gramów, ale nie w zbiorze 2-gramów.
Modele skip-gram pomagają trenować modele word embedding.
dostosowanie promptów,
Technika dostosowywania dużego modelu językowego do konkretnego zadania bez korzystania z wielu zasobów w ramach dokładnego dostrajania. Zamiast ponownego trenowania wszystkich wag w modelu, dostrajanie za pomocą promptów miękkich automatycznie dostosowuje prompt, aby osiągnąć ten sam cel.
W przypadku promptu tekstowego dostosowanie promptu miękkiego zwykle dodaje do promptu dodatkowe kodowania tokenów i korzysta z wstecznego propagowania, aby zoptymalizować dane wejściowe.
„Twardy” prompt zawiera tokeny zamiast ich zaszyfrowanych wersji.
rozproszona cecha
Cecha, której wartości są w większości równe 0 lub puste. Na przykład cecha zawierająca pojedynczą wartość 1 i milion wartości 0 jest rzadka. Natomiast gęsta cecha ma wartości, które w większości nie są równe 0 ani puste.
W uczeniu maszynowym zaskakująco wiele cech to rzadkie cechy. Funkcje kategorialne są zwykle rzadkie. Na przykład z 300 możliwych gatunków drzew w lesie pojedynczy przykład może zidentyfikować tylko klon. Albo spośród milionów filmów w bibliotece filmów jeden może być oznaczony jako „Casablanca”.
W modelu rzadkie cechy są zwykle reprezentowane za pomocą kodowania 1-hot. Jeśli kodowanie jednobitowe jest duże, możesz umieścić na nim warstwę zanurzeniową, aby zwiększyć wydajność.
rzadka reprezentacja
przechowywanie tylko pozycji elementów o wartości niezerowej w funkcji rzadkiej;
Załóżmy na przykład, że zmienna jakościowa o nazwie species identyfikuje 36 gatunków drzew w danym lesie. Załóżmy też, że każdy przykład dotyczy tylko jednego gatunku.
W każdym przykładzie gatunek drzewa można reprezentować za pomocą wektora typu one-hot.
Wektor jednoelementowy zawierałby 1 element 1 (reprezentujący dany gatunek drzewa w tym przykładzie) i 35 elementów 0 (reprezentujących 35 gatunków drzew nie w tym przykładzie). Reprezentacja jednoelementowa maple może wyglądać tak:

Inną możliwością jest rzadka reprezentacja, która po prostu wskazuje pozycję danego gatunku. Jeśli maple znajduje się w pozycji 24, rzadka reprezentacja maple będzie wyglądać tak:
24
Zwróć uwagę, że rzadka reprezentacja jest znacznie bardziej zwarta niż reprezentacja jednoelementowa.
Kliknij ikonę, aby wyświetlić nieco bardziej złożony przykład.
Załóżmy, że każdy przykład w modelu musi reprezentować słowa w zdarzeniu w języku angielskim (ale nie ich kolejność). Język angielski składa się z około 170 tys. słów, więc jest to cecha kategorialna z około 170 tys. elementów. Większość zdań w języku angielskim używa bardzo małej części tych 170 tys. słów, więc zbiór słów w pojedynczym przykładzie z pewnością będzie rzadki.
Rozważ zdanie:
My dog is a great dog
Do reprezentowania słów w tym zdaniu możesz użyć wariantu wektora one-hot. W tym wariancie wiele komórek wektora może zawierać wartość różną od 0. Ponadto w tym wariancie komórka może zawierać liczbę całkowitą inną niż 1. Chociaż słowa „mój”, „jest”, „a” i „świetny” występują tylko raz w tym zdaniu, słowo „pies” występuje 2 razy. Użycie tej wersji wektorów typu one-hot do reprezentowania słów w tym zdaniu daje wektor o 170 tys. elementach:

Rozrzedzielcza reprezentacja tego samego zdania wyglądałaby tak:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
Więcej informacji znajdziesz w sekcji Praca z danymi kategorialnymi w Kursie intensywnym z systemów uczących się.
stopniowe szkolenie
Strategia trenowania modelu w kolejności oddzielnych etapów. Celem może być przyspieszenie procesu uczenia się lub poprawa jakości modelu.
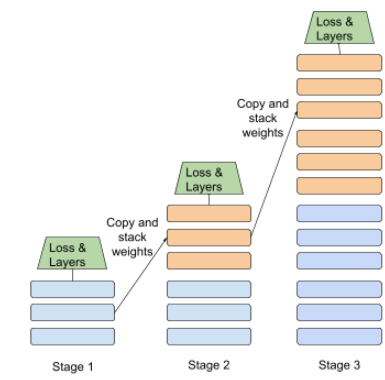
Poniżej przedstawiamy ilustrację progresywnego układania:
- Etap 1 zawiera 3 ukryte warstwy, etap 2 – 6 ukrytych warstw, a etap 3 – 12 ukrytych warstw.
- Etap 2 rozpoczyna się od uczenia się wag na podstawie 3 ukrytych warstw z etapu 1. Etap 3 rozpoczyna się od uczenia się wag wyuczonych na 6 ukrytych warstwach w etapie 2.
Zobacz też przetwarzanie w sekwencji.
token podsłowa
W modelach językowych token to podciąg słówka, który może być całym słowem.
Na przykład słowo „itemize” może zostać podzielone na części „item” (wyraz podstawowy) i „ize” (przyrostek), z których każdy jest reprezentowany przez własny token. Dzielenie nietypowych słów na takie elementy, zwane podsłowami, pozwala modelom językowym działać na bardziej typowych częściach składowych słowa, takim jak przedrosty i przyrostki.
Z drugiej strony, częste słowa, takie jak „going”, mogą nie być dzielone i reprezentowane przez pojedynczy element.
T
T5
Model uczenia się przez przenoszenie tekst-tekst, który został wprowadzony przez Google AI w 2020 r. T5 to model enkodera-dekodera oparty na architekturze Transformer, wytrenowany na bardzo dużym zbiorze danych. Jest on skuteczny w rozwiązywaniu różnych zadań związanych z przetwarzaniem języka naturalnego, takich jak generowanie tekstu, tłumaczenie języków i odpowiadanie na pytania w sposób konwersacyjny.
Nazwa T5 pochodzi od 5 liter w nazwie „Text-to-Text Transfer Transformer”.
T5X
Platforma open source uczenia maszynowego, która umożliwia tworzenie i trenowanie dużych modeli przetwarzania języka naturalnego (NLP). T5 jest implementowany w bazie kodu T5X (zbudowanej na podstawie JAX i Flax).
temperatura
Hiperparametr, który kontroluje stopień losowości danych wyjściowych modelu. Wyższe temperatury powodują bardziej losowe wyniki, a niższe – mniej losowe.
Wybór najlepszej temperatury zależy od konkretnego zastosowania i preferowanych właściwości wyników modelu. Na przykład prawdopodobnie podniesiesz temperaturę, gdy tworzysz aplikację, która generuje kreacje. Z kolei, aby zwiększyć dokładność i spójność modelu, który klasyfikuje obrazy lub tekst, prawdopodobnie obniżysz temperaturę.
Temperatura jest często używana z softmaxem.
element tekstowy
Zakres indeksu tablicy powiązany z określonym podzbiorem ciągu tekstowego.
Na przykład słowo good w ciągu tekstowym Pythona s="Be good now" zajmuje zakres znaków od 3 do 6.
token
W modelu językowym jest to element atomowy, na podstawie którego model się uczy i wydaje prognozy. Token to zwykle jeden z tych elementów:
- słowo – np. wyrażenie „psy lubią koty” składa się z 3 słów: „psy”, „lubią” i „koty”.
- znaku – na przykład wyrażenie „bike fish” składa się z 9 znaków. (pamiętaj, że spacje są liczone jako jeden token).
- podsłowach – w których pojedyncze słowo może być pojedynczym tokenem lub wieloma tokenami. Podsłowo składa się z rdzenia, prefiksu lub sufiksu. Na przykład model językowy, który używa podsłow jako tokenów, może traktować słowo „psy” jako 2 tokeny (podstawowe słowo „pies” i przyrostek liczby mnogiej „y”). Ten sam model językowy może traktować pojedyncze słowo „wyższy” jako 2 podsłowa (podstawowe słowo „wysoki” i przyrostek „szy”).
W domenach innych niż modele językowe tokeny mogą reprezentować inne rodzaje jednostek atomowych. Na przykład w przypadku widzenia komputerowego tokenem może być podzbiór obrazu.
Więcej informacji znajdziesz w sekcji Duże modele językowe w Szybkim szkoleniu z uczenia maszynowego.
dokładność top-k
Odsetek wystąpień „oznacznika docelowego” na pierwszych kpozycjach wygenerowanych list. Mogą to być spersonalizowane rekomendacje lub lista elementów uporządkowana według softmaxa.
Dokładność top-k jest też nazywana dokładnością w k-treściach.
toksyczne
stopień, w jakim treści są obraźliwe, zawierają groźby lub są nękające; Wiele modeli systemów uczących się może wykrywać i mierzyć toksyczność. Większość z nich identyfikuje toksyczność na podstawie wielu parametrów, takich jak poziom obraźliwego języka i poziom języka groźnego.
Transformator
Architektura sieci neuronowej opracowana w Google, która korzysta z mechanizmów samouczenia do przekształcania sekwencji wejść w sekwencję wyjść bez korzystania z zawijania ani sieci neuronowych z powtarzającymi się połączeniami. Sieć Transformer można traktować jako zestaw warstw samouczenia.
Transformator może zawierać:
Koderek przekształca sekwencję zatopień w nową sekwencję o tej samej długości. Koder zawiera N identycznych warstw, z których każda zawiera 2 podwarstwy. Te 2 podwarstwy są stosowane w każdej pozycji sekwencji embeddingu wejściowego, przekształcając każdy element sekwencji w nowy embedding. Pierwszy podwarstwowy koder agreguje informacje z całości sekwencji wejściowej. Druga warstwa podrzędna kodera przekształca zagregowane informacje w embedding wyjściowy.
Dekodery przekształcają sekwencję wejść w sekwencję wyjść, która może mieć inną długość. Dekoder zawiera też N identycznych warstw z 3 podwarstwami, z których 2 są podobne do podwarstw kodera. Trzeci podwarstw decodera pobiera dane wyjściowe z enkodera i za pomocą mechanizmu samouczenia zbiera z nich informacje.
W poście na blogu Transformer: nowatorska architektura sieci neuronowych na potrzeby rozumienia języka znajdziesz dobre wprowadzenie do transformacji.
Więcej informacji znajdziesz w artykule LLMs: What's a large language model? (Duże modele językowe: czym są duże modele językowe?) w ramach Szybkiego szkolenia z systemów uczących się.
trygram
N-gram, w którym N=3.
U
jednokierunkowy
System, który ocenia tylko tekst poprzedzający docelowy fragment tekstu. System dwukierunkowy analizuje zarówno tekst poprzedzający, jak i następujący wybrany fragment tekstu. Więcej informacji znajdziesz w sekcji dwukierunkowy.
jednokierunkowy model językowy
Model językowy, który określa prawdopodobieństwa tylko na podstawie tokenów pojawiających się przed, a nie po tokenach docelowych. W odróżnieniu od dwukierunkowego modelu językowego.
V
autoenkoder wariancyjny (VAE)
Rodzaj autoenkodera, który wykorzystuje rozbieżność między danymi wejściowymi a danymi wyjściowymi do generowania zmodyfikowanych wersji danych wejściowych. Autokodeki wariancyjne są przydatne w generatywnej AI.
VAE opiera się na wnioskowaniu wariancjalnym, czyli metodzie szacowania parametrów modelu prawdopodobieństwa.
W
wektor dystrybucyjny słowa
Reprezentowanie każdego słowa w zbiorze słów za pomocą wektora zanurzeniowego, czyli reprezentowanie każdego słowa za pomocą wektora wartości zmiennoprzecinkowych z zakresu od 0,0 do 1,0. Słowa o podobnym znaczeniu mają bardziej podobne reprezentacje niż słowa o różnym znaczeniu. Na przykład marchew, seler i ogórek miałyby podobne reprezentacje, które różniłyby się od reprezentacji samolotu, okularów i pasty do zębów.
Z
prompty „zero-shot”
prompt, który nie zawiera przykładu tego, jak chcesz, aby duży model językowy odpowiadał. Na przykład:
| Części jednego promptu | Uwagi |
|---|---|
| Jaka jest oficjalna waluta w wybranym kraju? | Pytanie, na które chcesz uzyskać odpowiedź od modelu LLM. |
| Indie: | Faktyczne zapytanie. |
Duży model językowy może odpowiedzieć:
- Rupia
- INR
- ₹
- Rupia indyjska
- Rupia
- rupia indyjska,
Wszystkie odpowiedzi są prawidłowe, ale możesz preferować określony format.
Porównaj promptowanie bez przykładów z tymi pojęciami: