W tym module przedstawiamy koncepcje regresji liniowej.
Regresja liniowa to technika statystyczna służąca do znajdowania zależności między zmiennymi. W kontekście uczenia maszynowego regresja liniowa znajduje zależność między cechami a etykietą.
Załóżmy na przykład, że chcemy przewidzieć zużycie paliwa przez samochód w milach na galon na podstawie jego wagi. Mamy następujący zbiór danych:
| Funty w tysiącach (funkcja) | Mile na galon (etykieta) |
|---|---|
| 3,5 | 18 |
| 3,69 | 15 |
| 3,44 | 18 |
| 3,43 | 16 |
| 4.34 | 15 |
| 4.42 | 14 |
| 2,37 | 24 |
Gdybyśmy nanieśli te punkty na wykres, otrzymalibyśmy:
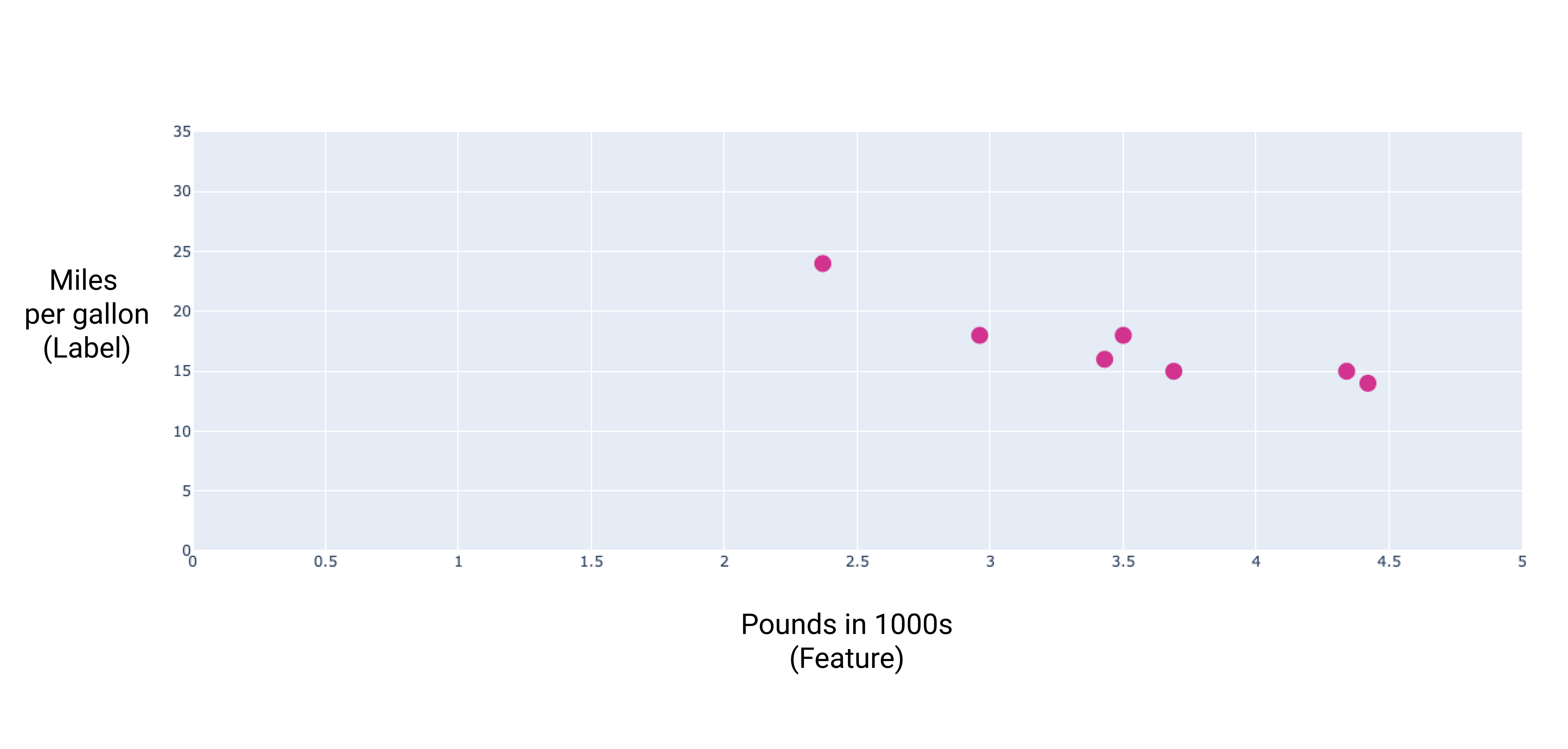
Rysunek 1. Waga samochodu (w funtach) w porównaniu z oceną liczby mil na galon. Im cięższy samochód, tym mniejsza liczba kilometrów, jaką może przejechać na jednym litrze paliwa.
Możemy utworzyć własny model, rysując linię najlepszego dopasowania przez punkty:
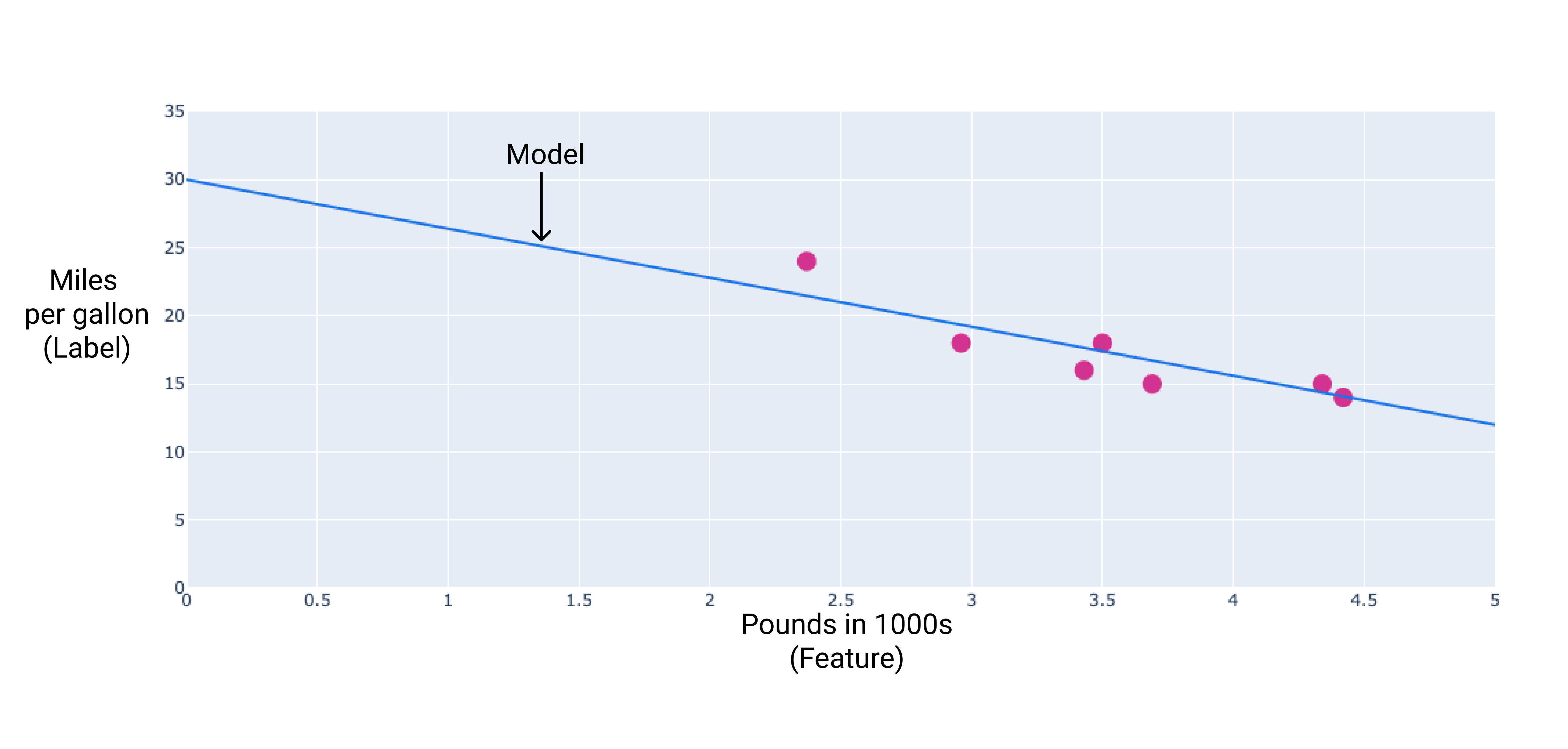
Rysunek 2. Linia najlepszego dopasowania narysowana na podstawie danych z poprzedniego rysunku.
Równanie regresji liniowej
W terminologii algebraicznej model ten można zdefiniować jako $ y = mx + b $, gdzie
- $ y $ to liczba mil na galon – wartość, którą chcemy prognozować.
- $ m $ to nachylenie prostej.
- $ x $ to funty, czyli wartość wejściowa.
- $ b $ to punkt przecięcia z osią Y.
W uczeniu maszynowym równanie modelu regresji liniowej zapisujemy w ten sposób:
gdzie:
- $ y' $ to prognozowana etykieta, czyli dane wyjściowe.
- $ b $ to odchylenie modelu. Odchylenie to ta sama koncepcja co punkt przecięcia z osią Y w równaniu algebraicznym prostej. W uczeniu maszynowym odchylenie jest czasami oznaczane jako $ w_0 $. Odchylenie to parametr modelu, który jest obliczany podczas trenowania.
- $ w_1 $ to waga cechy. Waga to to samo pojęcie co współczynnik kierunkowy $ m $ w równaniu algebraicznym prostej. Waga to parametr modelu, który jest obliczany podczas trenowania.
- $ x_1 $ to cecha, czyli dane wejściowe.
Podczas trenowania model oblicza wagę i odchylenie, które dają najlepszy model.
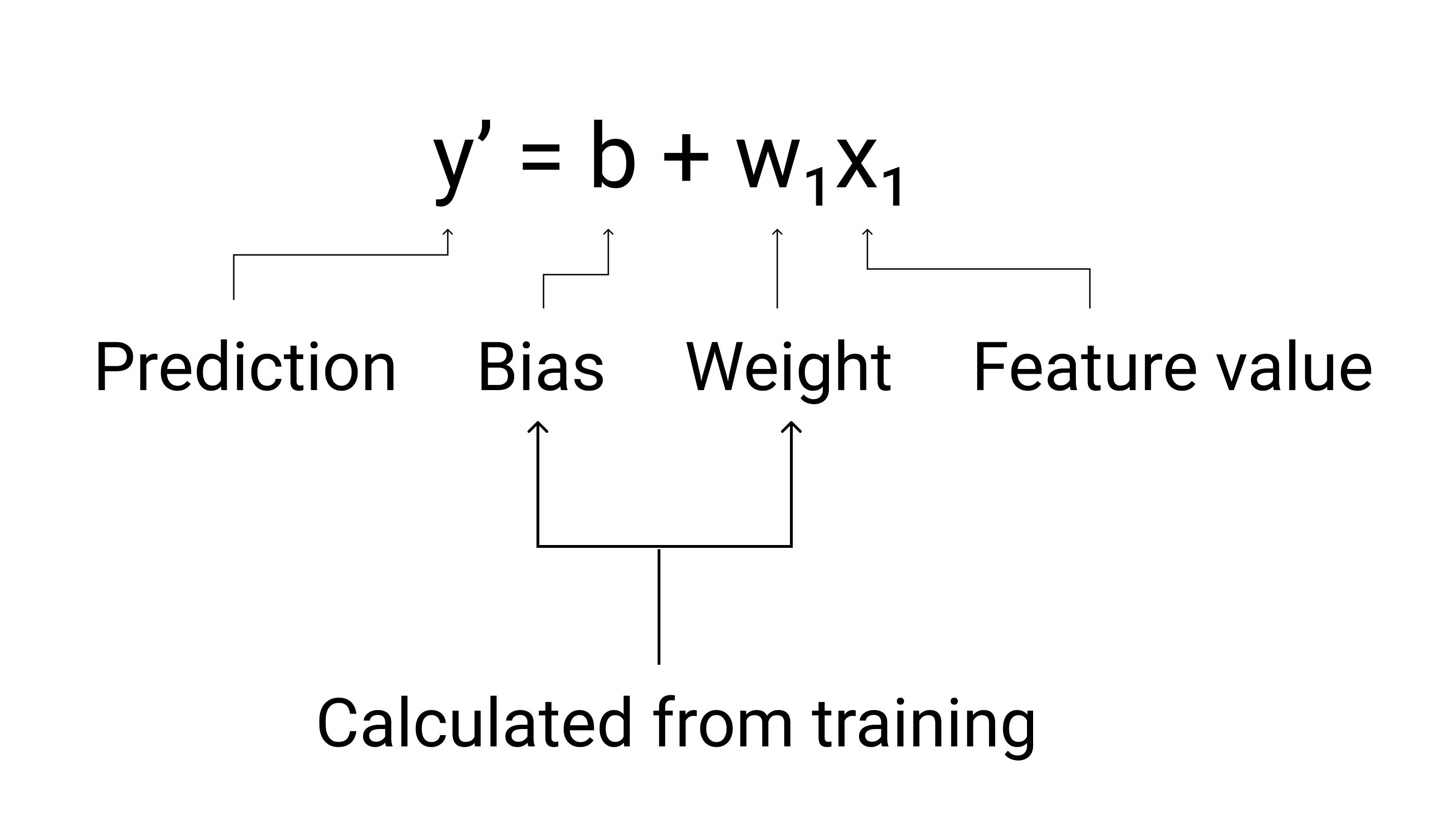
Rysunek 3. Matematyczna reprezentacja modelu liniowego.
W naszym przykładzie obliczymy wagę i odchylenie na podstawie narysowanej linii. Wartość bias wynosi 34 (miejsce przecięcia linii z osią Y), a waga –4,6 (nachylenie linii). Model zostałby zdefiniowany jako $ y' = 34 + (-4.6)(x_1) $, i moglibyśmy go używać do tworzenia prognoz. Na przykład w przypadku samochodu o wadze 4000 funtów model ten prognozuje zużycie paliwa na poziomie 15,6 mili na galon.
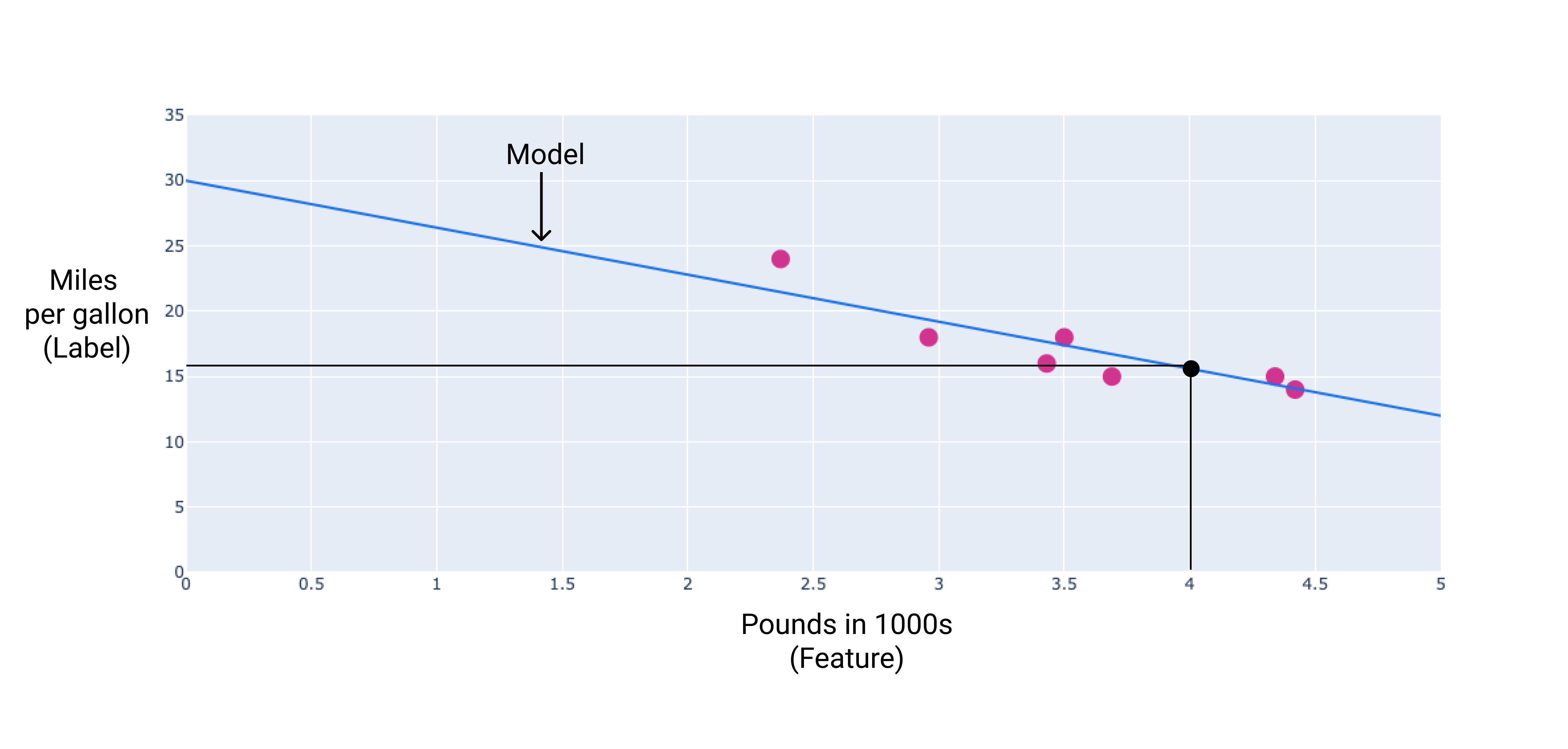
Rysunek 4. Zgodnie z modelem samochód o masie 4000 funtów ma przewidywaną wydajność paliwową na poziomie 15,6 mili na galon.
Modele z wieloma funkcjami
Chociaż w przykładzie w tej sekcji użyto tylko 1 cechy – wagi samochodu – bardziej zaawansowany model może opierać się na wielu cechach, z których każda ma osobną wagę ($ w_1 $, $ w_2 $ itd.). Na przykład model, który korzysta z 5 cech, będzie zapisany w ten sposób:
$ y' = b + w_1x_1 + w_2x_2 + w_3x_3 + w_4x_4 + w_5x_5 $
Na przykład model, który prognozuje zużycie paliwa, może dodatkowo korzystać z tych funkcji:
- Pojemność silnika
- Przyspieszenie
- Liczba cylindrów
- Koń parowy
Ten model wyglądałby tak:
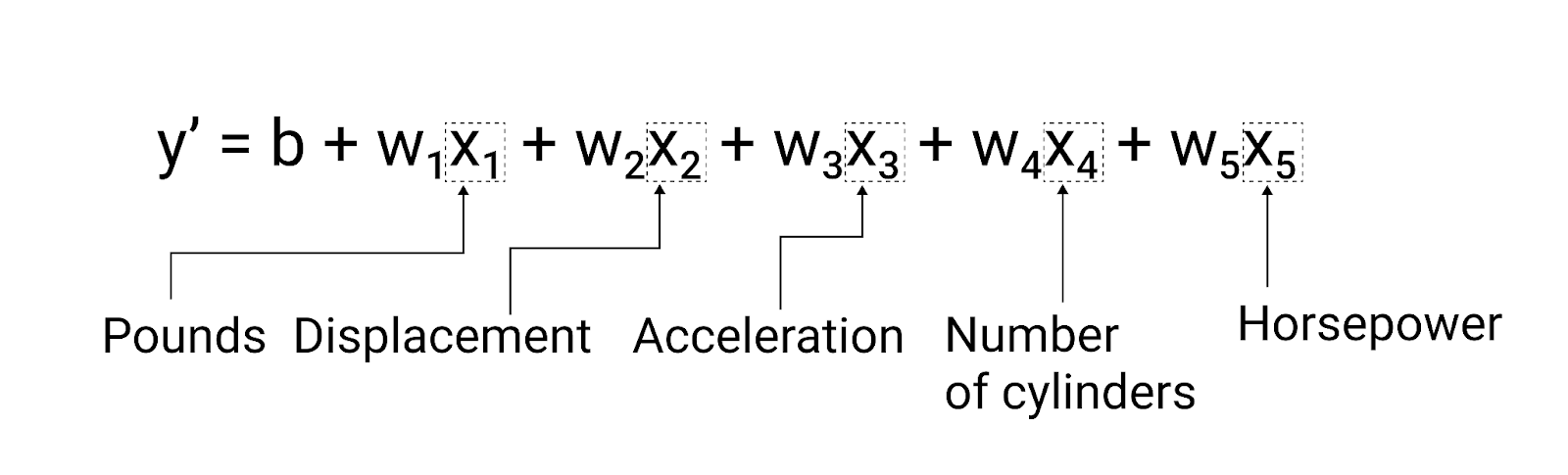
Rysunek 5. Model z 5 cechami do prognozowania zużycia paliwa w milach na galon.
Wykreślając kilka z tych dodatkowych funkcji, możemy zauważyć, że również one mają liniową zależność od etykiety, czyli liczby mil na galon:
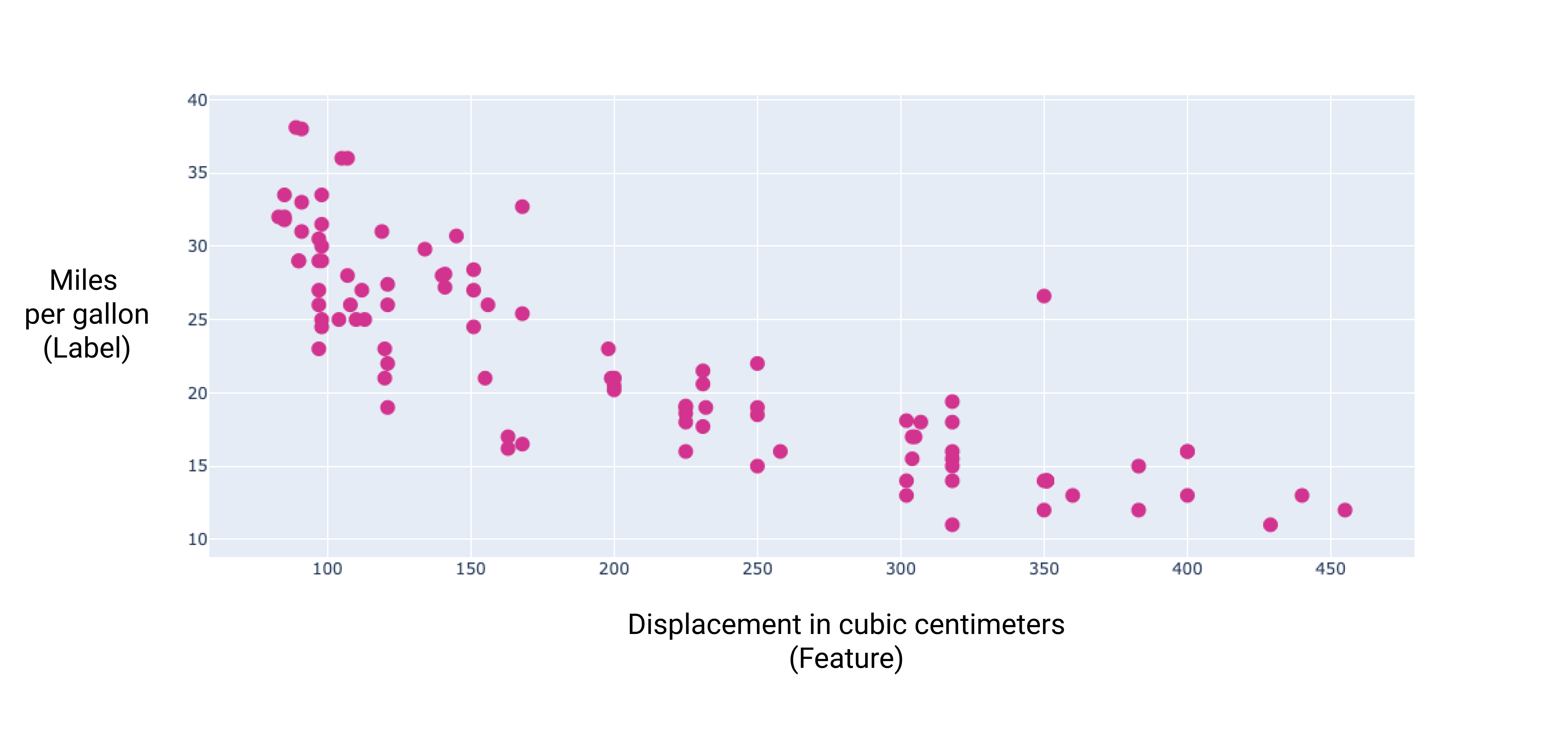
Rysunek 6. Pojemność silnika samochodu w centymetrach sześciennych i jego zużycie paliwa w milach na galon. Wraz ze wzrostem pojemności silnika samochodu liczba kilometrów przejechanych na litrze paliwa zwykle maleje.
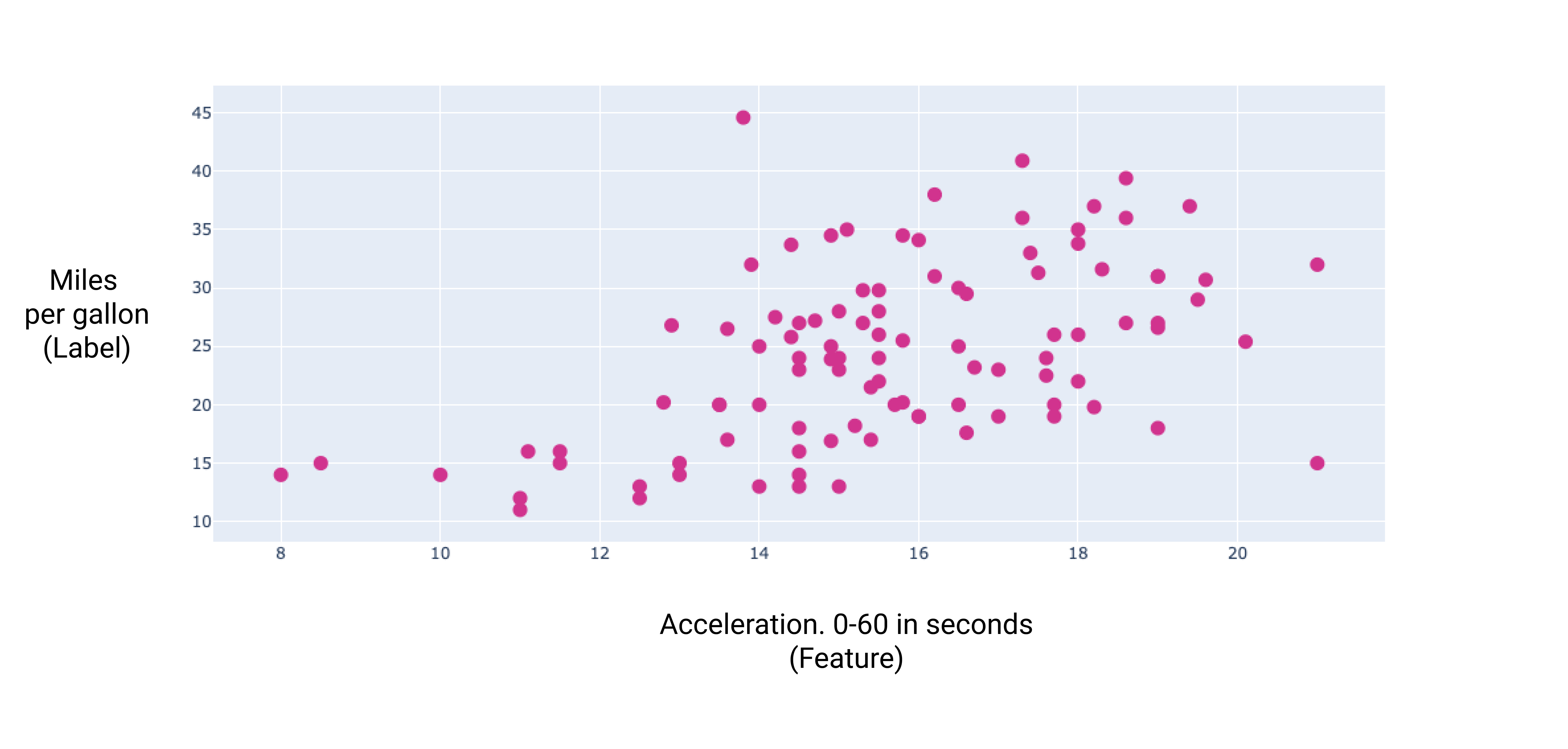
Rysunek 7. przyspieszenie samochodu i jego zużycie paliwa w milach na galon; Im dłużej trwa przyspieszanie samochodu, tym większa jest liczba kilometrów na litr.