Trang này chứa các thuật ngữ trong từ điển về Đánh giá ngôn ngữ. Để xem tất cả các thuật ngữ trong từ điển, hãy nhấp vào đây.
A
chú ý
Một cơ chế được dùng trong mạng nơron cho biết tầm quan trọng của một từ hoặc một phần của từ. Tính năng chú ý nén lượng thông tin mà mô hình cần để dự đoán mã thông báo/từ tiếp theo. Một cơ chế chú ý thông thường có thể bao gồm một giá trị tổng trọng số trên một tập hợp đầu vào, trong đó trọng số cho mỗi đầu vào được tính toán bằng một phần khác của mạng nơron.
Hãy tham khảo thêm về tự chú ý và tự chú ý nhiều đầu. Đây là các khối xây dựng của Transformer.
Hãy xem phần LLM: Mô hình ngôn ngữ lớn là gì? trong khoá học Học nhanh về học máy để biết thêm thông tin về tính năng tự chú ý.
bộ tự mã hoá
Một hệ thống học cách trích xuất thông tin quan trọng nhất từ dữ liệu đầu vào. Bộ tự mã hoá là sự kết hợp giữa bộ mã hoá và bộ giải mã. Bộ tự mã hoá dựa trên quy trình hai bước sau:
- Bộ mã hoá ánh xạ đầu vào đến một định dạng (thường) có kích thước thấp hơn (trung gian) bị mất dữ liệu.
- Bộ giải mã tạo một phiên bản có tổn hao của dữ liệu đầu vào ban đầu bằng cách ánh xạ định dạng chiều thấp hơn với định dạng đầu vào chiều cao hơn ban đầu.
Bộ tự mã hoá được huấn luyện toàn diện bằng cách yêu cầu bộ giải mã cố gắng tái tạo dữ liệu đầu vào ban đầu từ định dạng trung gian của bộ mã hoá gần nhất có thể. Vì định dạng trung gian nhỏ hơn (có kích thước thấp hơn) so với định dạng ban đầu, nên bộ tự mã hoá buộc phải tìm hiểu thông tin nào trong dữ liệu đầu vào là cần thiết và dữ liệu đầu ra sẽ không giống hệt với dữ liệu đầu vào.
Ví dụ:
- Nếu dữ liệu đầu vào là đồ hoạ, thì bản sao không chính xác sẽ tương tự như đồ hoạ gốc, nhưng có một chút sửa đổi. Có thể bản sao không chính xác sẽ loại bỏ nhiễu khỏi đồ hoạ gốc hoặc lấp đầy một số pixel bị thiếu.
- Nếu dữ liệu đầu vào là văn bản, thì bộ tự mã hoá sẽ tạo văn bản mới mô phỏng (nhưng không giống với) văn bản gốc.
Xem thêm tự mã hoá biến thiên.
đánh giá tự động
Sử dụng phần mềm để đánh giá chất lượng đầu ra của một mô hình.
Khi đầu ra của mô hình tương đối đơn giản, tập lệnh hoặc chương trình có thể so sánh đầu ra của mô hình với phản hồi chuẩn. Loại hình đánh giá tự động này đôi khi được gọi là đánh giá có lập trình. Các chỉ số như ROUGE hoặc BLEU thường hữu ích cho việc đánh giá theo phương thức lập trình.
Khi đầu ra của mô hình phức tạp hoặc không có câu trả lời đúng, một chương trình ML riêng biệt có tên là trình tự động đánh giá đôi khi sẽ thực hiện việc đánh giá tự động.
Khác với quy trình đánh giá thủ công.
đánh giá trình tự động đánh giá
Cơ chế kết hợp để đánh giá chất lượng của kết quả đầu ra của mô hình AI tạo sinh, kết hợp quy trình đánh giá của con người với quy trình đánh giá tự động. Trình tự động chấm điểm là một mô hình học máy được huấn luyện dựa trên dữ liệu do hoạt động đánh giá của con người tạo ra. Lý tưởng nhất là trình tự động đánh giá sẽ học cách bắt chước một người đánh giá.Bạn có thể sử dụng các trình tự động đánh giá tạo sẵn, nhưng các trình tự động đánh giá tốt nhất được điều chỉnh chính xác cho nhiệm vụ mà bạn đang đánh giá.
mô hình tự hồi quy
Mô hình suy luận một dự đoán dựa trên các dự đoán trước đó của chính mô hình đó. Ví dụ: mô hình ngôn ngữ tự hồi quy dự đoán mã thông báo tiếp theo dựa trên các mã thông báo đã dự đoán trước đó. Tất cả mô hình ngôn ngữ lớn dựa trên Transformer đều tự hồi quy.
Ngược lại, các mô hình hình ảnh dựa trên GAN thường không tự động hồi quy vì các mô hình này tạo hình ảnh trong một lượt truyền tới và không lặp lại theo các bước. Tuy nhiên, một số mô hình tạo hình ảnh là tự hồi quy vì tạo hình ảnh theo từng bước.
độ chính xác trung bình tại k
Một chỉ số để tóm tắt hiệu suất của một mô hình trên một câu lệnh duy nhất tạo ra kết quả được xếp hạng, chẳng hạn như danh sách đánh số các đề xuất sách. Độ chính xác trung bình tại k là trung bình của các giá trị độ chính xác tại k cho mỗi kết quả liên quan. Do đó, công thức tính độ chính xác trung bình tại k là:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
trong đó:
- \(n\) là số lượng mục có liên quan trong danh sách.
Tương phản với lệnh gọi lại tại k.
B
túi từ
Biểu thị các từ trong một cụm từ hoặc đoạn văn, bất kể thứ tự. Ví dụ: túi từ đại diện cho ba cụm từ sau đây giống hệt nhau:
- con chó nhảy
- nhảy lên chó
- chó nhảy
Mỗi từ được liên kết với một chỉ mục trong vectơ thưa, trong đó vectơ có một chỉ mục cho mỗi từ trong từ vựng. Ví dụ: cụm từ the dog jumps (con chó nhảy) được ánh xạ vào một vectơ đặc trưng có giá trị khác 0 tại 3 chỉ mục tương ứng với các từ the (cái), dog (chó) và jumps (nhảy). Giá trị khác 0 có thể là bất kỳ giá trị nào sau đây:
- Số 1 để cho biết có một từ.
- Số lần một từ xuất hiện trong túi. Ví dụ: nếu cụm từ là con chó màu đỏ tía là một con chó có bộ lông màu đỏ tía, thì cả màu đỏ tía và chó sẽ được biểu thị là 2, trong khi các từ khác sẽ được biểu thị là 1.
- Một số giá trị khác, chẳng hạn như logarit của số lần một từ xuất hiện trong túi.
BERT (Biểu diễn Thể hiện Mã hoá Hai chiều từ Transformer)
Cấu trúc mô hình để biểu thị văn bản. Mô hình BERT đã huấn luyện có thể đóng vai trò là một phần của mô hình lớn hơn để phân loại văn bản hoặc các nhiệm vụ khác về máy học.
BERT có các đặc điểm sau:
- Sử dụng cấu trúc Transformer, do đó, dựa vào tự chú ý.
- Sử dụng phần bộ mã hoá của Bộ chuyển đổi. Công việc của bộ mã hoá là tạo ra các bản trình bày văn bản tốt, thay vì thực hiện một tác vụ cụ thể như phân loại.
- Có tính hai chiều.
- Sử dụng tính năng mặt nạ để huấn luyện không giám sát.
Các biến thể của BERT bao gồm:
Hãy xem bài viết BERT nguồn mở: Công nghệ huấn luyện trước tiên tiến để xử lý ngôn ngữ tự nhiên để biết thông tin tổng quan về BERT.
hai chiều
Thuật ngữ dùng để mô tả một hệ thống đánh giá văn bản trước và sau một phần văn bản mục tiêu. Ngược lại, hệ thống một chiều chỉ đánh giá văn bản trước một phần văn bản mục tiêu.
Ví dụ: hãy xem xét một mô hình ngôn ngữ bị che phải xác định xác suất cho từ hoặc các từ đại diện cho dấu gạch dưới trong câu hỏi sau:
_____ của bạn thế nào?
Mô hình ngôn ngữ một chiều sẽ chỉ dựa trên xác suất của ngữ cảnh do các từ "What" (Cái gì), "is" (là) và "the" (cái) cung cấp. Ngược lại, mô hình ngôn ngữ hai chiều cũng có thể lấy ngữ cảnh từ "với" và "bạn", điều này có thể giúp mô hình tạo ra thông tin dự đoán chính xác hơn.
mô hình ngôn ngữ hai chiều
Mô hình ngôn ngữ xác định xác suất một mã thông báo nhất định xuất hiện ở một vị trí nhất định trong một đoạn văn bản dựa trên văn bản trước đó và sau đó.
bigram
N-gram trong đó N=2.
BLEU (Bilingual Evaluation Understudy – Thử nghiệm đánh giá song ngữ)
Một chỉ số từ 0 đến 1 để đánh giá bản dịch máy, ví dụ: từ tiếng Tây Ban Nha sang tiếng Nhật.
Để tính điểm, BLEU thường so sánh bản dịch của một mô hình học máy (văn bản được tạo) với bản dịch của một chuyên gia (văn bản tham chiếu). Mức độ khớp của N-gram trong văn bản được tạo và văn bản đối chiếu sẽ xác định điểm BLEU.
Bài báo gốc về chỉ số này là BLEU: a Method for Automatic Evaluation of Machine Translation (BLEU: Một phương pháp tự động đánh giá bản dịch máy).
Xem thêm BLEURT.
BLEURT (Bilingual Evaluation Understudy from Transformers – Học viên đánh giá song ngữ từ Transformers)
Một chỉ số để đánh giá bản dịch máy từ ngôn ngữ này sang ngôn ngữ khác, đặc biệt là từ và sang tiếng Anh.
Đối với bản dịch sang và từ tiếng Anh, BLEURT phù hợp hơn với điểm xếp hạng của con người so với BLEU. Không giống như BLEU, BLEURT nhấn mạnh các điểm tương đồng về ngữ nghĩa (ý nghĩa) và có thể chấp nhận việc diễn đạt lại.
BLEURT dựa vào một mô hình ngôn ngữ lớn được huấn luyện trước (chính xác là BERT), sau đó được điều chỉnh chi tiết dựa trên văn bản của người dịch.
Bài báo gốc về chỉ số này là BLEURT: Học các chỉ số mạnh mẽ để tạo văn bản.
C
mô hình ngôn ngữ nhân quả
Đồng nghĩa với mô hình ngôn ngữ một chiều.
Hãy xem mô hình ngôn ngữ hai chiều để phân biệt các phương pháp định hướng khác nhau trong mô hình ngôn ngữ.
câu lệnh gợi ý theo chuỗi suy nghĩ
Kỹ thuật kỹ thuật câu lệnh khuyến khích mô hình ngôn ngữ lớn (LLM) giải thích từng bước lý do của nó. Ví dụ: hãy xem xét câu lệnh sau, chú ý đặc biệt đến câu thứ hai:
Tài xế sẽ phải chịu bao nhiêu lực g khi lái một chiếc xe tăng tốc từ 0 lên 60 dặm/giờ trong 7 giây? Trong câu trả lời, hãy trình bày tất cả các phép tính liên quan.
Phản hồi của LLM có thể:
- Hiển thị một chuỗi các công thức vật lý, cắm các giá trị 0, 60 và 7 vào các vị trí thích hợp.
- Giải thích lý do chọn những công thức đó và ý nghĩa của các biến.
Lệnh nhắc theo chuỗi suy nghĩ buộc LLM thực hiện tất cả các phép tính, điều này có thể dẫn đến câu trả lời chính xác hơn. Ngoài ra, lời nhắc chuỗi suy nghĩ cho phép người dùng kiểm tra các bước của LLM để xác định xem câu trả lời có hợp lý hay không.
trò chuyện
Nội dung của cuộc trò chuyện qua lại với một hệ thống học máy, thường là một mô hình ngôn ngữ lớn. Hoạt động tương tác trước đó trong cuộc trò chuyện (những gì bạn đã nhập và cách mô hình ngôn ngữ lớn phản hồi) trở thành ngữ cảnh cho các phần tiếp theo của cuộc trò chuyện.
Chatbot là một ứng dụng của mô hình ngôn ngữ lớn.
hoang tưởng
Từ đồng nghĩa với ảo giác.
Ảo tưởng có thể là một thuật ngữ chính xác hơn về mặt kỹ thuật so với ảo giác. Tuy nhiên, ảo giác đã trở nên phổ biến trước.
phân tích cú pháp khu vực bầu cử
Chia một câu thành các cấu trúc ngữ pháp nhỏ hơn ("thành phần"). Một phần sau của hệ thống học máy, chẳng hạn như mô hình hiểu ngôn ngữ tự nhiên, có thể phân tích cú pháp các thành phần dễ dàng hơn so với câu ban đầu. Ví dụ: hãy xem xét câu sau:
Bạn tôi đã nhận nuôi hai chú mèo.
Trình phân tích cú pháp thành phần có thể chia câu này thành hai thành phần sau:
- My friend (Bạn của tôi) là một cụm danh từ.
- nhận nuôi hai chú mèo là một cụm động từ.
Các thành phần này có thể được chia nhỏ thành các thành phần nhỏ hơn. Ví dụ: cụm động từ
nhận nuôi hai chú mèo
có thể được chia nhỏ thành:
- adopted là động từ.
- hai con mèo là một cụm danh từ khác.
Nhúng ngôn ngữ theo ngữ cảnh
Một mã nhúng gần như "hiểu" các từ và cụm từ theo cách mà người bản địa có thể hiểu. Các phần nhúng ngôn ngữ theo ngữ cảnh có thể hiểu được cú pháp, ngữ nghĩa và ngữ cảnh phức tạp.
Ví dụ: hãy xem xét các phần nhúng của từ tiếng Anh cow. Các phương pháp nhúng cũ hơn như word2vec có thể biểu thị các từ tiếng Anh sao cho khoảng cách trong không gian nhúng từ cow (bò) đến bull (bò đực) tương tự như khoảng cách từ ewe (cừu cái) đến ram (cừu đực) hoặc từ female (nữ) đến male (nam). Tính năng nhúng ngôn ngữ theo ngữ cảnh có thể tiến xa hơn bằng cách nhận ra rằng người nói tiếng Anh đôi khi sử dụng từ cow (bò) để chỉ bò cái hoặc bò đực.
cửa sổ ngữ cảnh
Số lượng mã thông báo mà một mô hình có thể xử lý trong một lời nhắc nhất định. Cửa sổ ngữ cảnh càng lớn, mô hình càng có thể sử dụng nhiều thông tin để đưa ra các phản hồi nhất quán và rõ ràng cho câu lệnh.
sự cố hoa
Một câu hoặc cụm từ có ý nghĩa mơ hồ. Lỗi hoa hồng là một vấn đề đáng kể trong việc hiểu ngôn ngữ tự nhiên. Ví dụ: dòng tiêu đề Red Tape Holds Up Skyscraper (Công việc hành chính làm chậm tiến độ xây dựng toà nhà chọc trời) là một cụm từ hoa mỹ vì mô hình NLU có thể diễn giải dòng tiêu đề theo nghĩa đen hoặc nghĩa bóng.
D
bộ giải mã
Nhìn chung, mọi hệ thống học máy đều chuyển đổi từ một bản trình bày đã xử lý, dày đặc hoặc nội bộ sang một bản trình bày thô, thưa thớt hoặc bên ngoài hơn.
Bộ giải mã thường là một thành phần của một mô hình lớn hơn, trong đó chúng thường được ghép nối với một bộ mã hoá.
Trong các tác vụ từ trình tự đến trình tự, trình giải mã bắt đầu bằng trạng thái nội bộ do bộ mã hoá tạo ra để dự đoán trình tự tiếp theo.
Hãy tham khảo Transformer để biết định nghĩa về bộ giải mã trong cấu trúc Transformer.
Hãy xem phần Mô hình ngôn ngữ lớn trong Khoá học học máy ứng dụng để biết thêm thông tin.
loại bỏ nhiễu
Một phương pháp phổ biến để tự học có giám sát trong đó:
Tính năng loại bỏ tạp âm cho phép học từ các ví dụ chưa được gắn nhãn. Tập dữ liệu ban đầu đóng vai trò là mục tiêu hoặc nhãn và dữ liệu nhiễu đóng vai trò là dữ liệu đầu vào.
Một số mô hình ngôn ngữ bị che sử dụng tính năng loại bỏ tạp âm như sau:
- Độ nhiễu được thêm vào một câu chưa được gắn nhãn một cách nhân tạo bằng cách che một số mã thông báo.
- Mô hình này cố gắng dự đoán các mã thông báo ban đầu.
lời nhắc trực tiếp
Đồng nghĩa với câu lệnh gợi ý không có ví dụ.
E
chỉnh sửa khoảng cách
Một phép đo mức độ tương đồng giữa hai chuỗi văn bản. Trong học máy, khoảng cách chỉnh sửa rất hữu ích vì những lý do sau:
- Dễ dàng tính toán khoảng cách chỉnh sửa.
- Khoảng cách chỉnh sửa có thể so sánh hai chuỗi được biết là tương tự nhau.
- Khoảng cách chỉnh sửa có thể xác định mức độ tương đồng giữa các chuỗi với một chuỗi nhất định.
Có một số định nghĩa về khoảng cách chỉnh sửa, mỗi định nghĩa sử dụng các thao tác chuỗi khác nhau. Hãy xem Khoảng cách Levenshtein để biết ví dụ.
lớp nhúng
Một lớp ẩn đặc biệt huấn luyện trên một tính năng phân loại có nhiều chiều để dần dần học một vectơ nhúng có chiều thấp hơn. Lớp nhúng cho phép mạng nơron huấn luyện hiệu quả hơn nhiều so với việc chỉ huấn luyện trên tính năng phân loại có nhiều chiều.
Ví dụ: Earth hiện hỗ trợ khoảng 73.000 loài cây. Giả sử loài cây là một tính năng trong mô hình của bạn, do đó,lớp đầu vào của mô hình bao gồm một vectơ một chiều dài 73.000 phần tử.
Ví dụ: có thể baobab sẽ được biểu thị như sau:

Mảng 73.000 phần tử rất dài. Nếu bạn không thêm lớp nhúng vào mô hình, quá trình huấn luyện sẽ mất rất nhiều thời gian do phải nhân 72.999 số 0. Có thể bạn chọn lớp nhúng bao gồm 12 phương diện. Do đó, lớp nhúng sẽ dần học được một vectơ nhúng mới cho từng loài cây.
Trong một số trường hợp, hàm băm là một giải pháp thay thế hợp lý cho lớp nhúng.
Hãy xem phần Nội dung nhúng trong khoá học Học máy ứng dụng để biết thêm thông tin.
không gian nhúng
Không gian vectơ d-chiều có các tính năng từ không gian vectơ có chiều cao hơn được liên kết. Lý tưởng nhất là không gian nhúng chứa một cấu trúc mang lại kết quả toán học có ý nghĩa; ví dụ: trong không gian nhúng lý tưởng, việc cộng và trừ các phần nhúng có thể giải quyết các nhiệm vụ liên tưởng từ.
Tích vô hướng của hai nội dung nhúng là một chỉ số về mức độ tương đồng của chúng.
vectơ nhúng
Nói chung, một mảng gồm các số dấu phẩy động được lấy từ bất kỳ lớp ẩn nào mô tả dữ liệu đầu vào cho lớp ẩn đó. Thường thì vectơ nhúng là mảng các số dấu phẩy động được huấn luyện trong lớp nhúng. Ví dụ: giả sử một lớp nhúng phải học một vectơ nhúng cho mỗi trong số 73.000 loài cây trên Trái đất. Có thể mảng sau đây là vectơ nhúng cho cây bao báp:

Vectơ nhúng không phải là một tập hợp các số ngẫu nhiên. Lớp nhúng xác định các giá trị này thông qua quá trình huấn luyện, tương tự như cách mạng nơron học các trọng số khác trong quá trình huấn luyện. Mỗi phần tử của آرایه là một điểm xếp hạng cùng với một số đặc điểm của một loài cây. Phần tử nào đại diện cho đặc điểm của loài cây nào? Con người rất khó xác định điều đó.
Phần đáng chú ý về mặt toán học của một vectơ nhúng là các mục tương tự nhau có các tập hợp số dấu phẩy động tương tự nhau. Ví dụ: các loài cây tương tự nhau có tập hợp số dấu phẩy động tương tự nhau hơn so với các loài cây không tương tự nhau. Cây tuyết tùng và cây sequoia là các loài cây có liên quan, vì vậy, chúng sẽ có tập hợp số dấu phẩy động tương tự nhau hơn so với cây tuyết tùng và cây dừa. Các số trong vectơ nhúng sẽ thay đổi mỗi khi bạn huấn luyện lại mô hình, ngay cả khi bạn huấn luyện lại mô hình bằng dữ liệu đầu vào giống hệt.
bộ mã hóa
Nhìn chung, mọi hệ thống học máy đều chuyển đổi từ một bản trình bày thô, thưa thớt hoặc bên ngoài thành một bản trình bày được xử lý nhiều hơn, dày đặc hơn hoặc nội bộ hơn.
Bộ mã hoá thường là một thành phần của mô hình lớn hơn, trong đó chúng thường được ghép nối với bộ giải mã. Một số Transformer ghép nối bộ mã hoá với bộ giải mã, mặc dù các Transformer khác chỉ sử dụng bộ mã hoá hoặc chỉ sử dụng bộ giải mã.
Một số hệ thống sử dụng đầu ra của bộ mã hoá làm đầu vào cho mạng phân loại hoặc hồi quy.
Trong các tác vụ từ trình tự đến trình tự, bộ mã hoá lấy một trình tự đầu vào và trả về một trạng thái nội bộ (một vectơ). Sau đó, bộ giải mã sẽ sử dụng trạng thái nội bộ đó để dự đoán trình tự tiếp theo.
Hãy tham khảo Transformer để biết định nghĩa về bộ mã hoá trong cấu trúc Transformer.
Hãy xem phần LLM: Mô hình ngôn ngữ lớn là gì trong khoá học Học máy ứng dụng để biết thêm thông tin.
evals
Chủ yếu dùng làm từ viết tắt của các hoạt động đánh giá LLM. Nói rộng ra, evals là viết tắt của mọi hình thức đánh giá.
đánh giá
Quy trình đo lường chất lượng của một mô hình hoặc so sánh các mô hình với nhau.
Để đánh giá mô hình học máy có giám sát, bạn thường đánh giá mô hình đó dựa trên tập hợp dữ liệu xác thực và tập hợp dữ liệu kiểm thử. Việc đánh giá LLM thường liên quan đến các hoạt động đánh giá chất lượng và độ an toàn ở phạm vi rộng hơn.
F
đặt câu lệnh dựa trên một vài ví dụ
Một lệnh gọi chứa nhiều ví dụ ("một vài") minh hoạ cách mô hình ngôn ngữ lớn phản hồi. Ví dụ: câu lệnh dài sau đây chứa hai ví dụ cho thấy một mô hình ngôn ngữ lớn cách trả lời truy vấn.
| Các phần của một câu lệnh | Ghi chú |
|---|---|
| Đơn vị tiền tệ chính thức của quốc gia đã chỉ định là gì? | Câu hỏi mà bạn muốn LLM trả lời. |
| Pháp: EUR | Một ví dụ. |
| Vương quốc Anh: Bảng Anh (GBP) | Một ví dụ khác. |
| Ấn Độ: | Cụm từ tìm kiếm thực tế. |
Lệnh nhắc ít lần thường mang lại kết quả mong muốn hơn so với lệnh nhắc không có lần nào và lệnh nhắc một lần. Tuy nhiên, tính năng đặt câu lệnh dựa trên một vài ví dụ yêu cầu câu lệnh dài hơn.
Đặt câu lệnh dựa trên một vài ví dụ là một hình thức học từ một vài dữ liệu áp dụng cho học dựa trên câu lệnh.
Hãy xem phần Kỹ thuật câu lệnh trong khoá học Học máy ứng dụng để biết thêm thông tin.
Đàn vĩ cầm
Thư viện cấu hình ưu tiên Python giúp đặt giá trị của các hàm và lớp mà không cần mã hoặc cơ sở hạ tầng xâm nhập. Trong trường hợp của Pax và các cơ sở mã học máy khác, các hàm và lớp này đại diện cho mô hình và thông số siêu tham số đào tạo.
Fiddle giả định rằng cơ sở mã học máy thường được chia thành:
- Mã thư viện xác định các lớp và trình tối ưu hoá.
- Mã "keo" của tập dữ liệu, gọi các thư viện và kết nối mọi thứ với nhau.
Fiddle ghi lại cấu trúc lệnh gọi của mã keo ở dạng chưa được đánh giá và có thể thay đổi.
tinh chỉnh
Lần truyền huấn luyện thứ hai, dành riêng cho tác vụ, được thực hiện trên một mô hình được huấn luyện trước để tinh chỉnh các tham số của mô hình cho một trường hợp sử dụng cụ thể. Ví dụ: trình tự huấn luyện đầy đủ cho một số mô hình ngôn ngữ lớn như sau:
- Huấn luyện trước: Huấn luyện một mô hình ngôn ngữ lớn trên một tập dữ liệu chung khổng lồ, chẳng hạn như tất cả các trang Wikipedia bằng tiếng Anh.
- Điều chỉnh chi tiết: Huấn luyện mô hình đã huấn luyện trước để thực hiện một nhiệm vụ cụ thể, chẳng hạn như phản hồi các truy vấn y tế. Việc tinh chỉnh thường liên quan đến hàng trăm hoặc hàng nghìn ví dụ tập trung vào một nhiệm vụ cụ thể.
Ví dụ khác: trình tự huấn luyện đầy đủ cho mô hình hình ảnh lớn như sau:
- Huấn luyện trước: Huấn luyện một mô hình hình ảnh lớn trên một tập dữ liệu hình ảnh chung rộng lớn, chẳng hạn như tất cả hình ảnh trong Wikimedia Commons.
- Điều chỉnh chi tiết: Huấn luyện mô hình đã huấn luyện trước để thực hiện một nhiệm vụ cụ thể, chẳng hạn như tạo hình ảnh cá voi sát thủ.
Việc tinh chỉnh có thể bao gồm bất kỳ tổ hợp nào của các chiến lược sau:
- Sửa đổi tất cả tham số hiện có của mô hình được huấn luyện trước. Đôi khi, quá trình này được gọi là điều chỉnh chi tiết đầy đủ.
- Chỉ sửa đổi một số tham số hiện có của mô hình được huấn luyện trước (thường là các lớp gần nhất với lớp đầu ra), trong khi giữ nguyên các tham số hiện có khác (thường là các lớp gần nhất với lớp đầu vào). Xem phần chỉnh sửa hiệu quả thông số.
- Thêm các lớp khác, thường là trên các lớp hiện có gần nhất với lớp đầu ra.
Điều chỉnh chi tiết là một hình thức học chuyển đổi. Do đó, việc tinh chỉnh có thể sử dụng một hàm tổn thất hoặc loại mô hình khác với những hàm và loại mô hình dùng để huấn luyện mô hình được huấn luyện trước. Ví dụ: bạn có thể điều chỉnh mô hình hình ảnh lớn được huấn luyện trước để tạo mô hình hồi quy trả về số lượng chim trong hình ảnh đầu vào.
So sánh và đối chiếu việc tinh chỉnh với các thuật ngữ sau:
Hãy xem phần Chỉnh sửa chi tiết trong Khoá học học máy ứng dụng để biết thêm thông tin.
Lanh
Một thư viện nguồn mở hiệu suất cao dành cho việc học sâu, được xây dựng dựa trên JAX. Flax cung cấp các hàm để huấn luyện mạng nơron, cũng như các phương thức để đánh giá hiệu suất của mạng nơron.
Flaxformer
Thư viện Transformer nguồn mở, được xây dựng trên Flax, chủ yếu được thiết kế để xử lý ngôn ngữ tự nhiên và nghiên cứu đa phương thức.
G
Gemini
Hệ sinh thái bao gồm AI tiên tiến nhất của Google. Các thành phần của hệ sinh thái này bao gồm:
- Nhiều mô hình Gemini.
- Giao diện trò chuyện tương tác với mô hình Gemini. Người dùng nhập câu lệnh và Gemini sẽ phản hồi các câu lệnh đó.
- Nhiều API Gemini.
- Nhiều sản phẩm dành cho doanh nghiệp dựa trên các mô hình Gemini; ví dụ: Gemini cho Google Cloud.
Mô hình Gemini
Các mô hình đa phương thức dựa trên Transformer tiên tiến của Google. Các mô hình Gemini được thiết kế riêng để tích hợp với các tác nhân.
Người dùng có thể tương tác với các mô hình Gemini theo nhiều cách, bao gồm cả thông qua giao diện hộp thoại tương tác và thông qua SDK.
văn bản được tạo
Nhìn chung, văn bản mà mô hình học máy xuất ra. Khi đánh giá mô hình ngôn ngữ lớn, một số chỉ số sẽ so sánh văn bản được tạo với văn bản tham chiếu. Ví dụ: giả sử bạn đang cố gắng xác định mức độ hiệu quả của một mô hình học máy trong việc dịch từ tiếng Pháp sang tiếng Hà Lan. Trong trường hợp này:
- Văn bản được tạo là bản dịch tiếng Hà Lan mà mô hình học máy trả về.
- Văn bản đối chiếu là bản dịch tiếng Hà Lan do một người dịch (hoặc phần mềm) tạo.
Xin lưu ý rằng một số chiến lược đánh giá không liên quan đến văn bản tham chiếu.
AI tạo sinh
Một lĩnh vực chuyển đổi mới nổi không có định nghĩa chính thức. Tuy nhiên, hầu hết các chuyên gia đều đồng ý rằng các mô hình AI tạo sinh có thể tạo ("tạo") nội dung đáp ứng tất cả các yêu cầu sau:
- phức tạp
- nhất quán
- gốc
Ví dụ: mô hình AI tạo sinh có thể tạo các bài tiểu luận hoặc hình ảnh phức tạp.
Một số công nghệ trước đây, bao gồm cả LSTM và RNN, cũng có thể tạo nội dung nguyên gốc và nhất quán. Một số chuyên gia xem những công nghệ trước đây này là AI tạo sinh, trong khi những người khác lại cho rằng AI tạo sinh thực sự đòi hỏi đầu ra phức tạp hơn so với những công nghệ trước đó có thể tạo ra.
Trái ngược với máy học dự đoán.
câu trả lời vàng
Một câu trả lời được biết là chính xác. Ví dụ: với lời nhắc sau:
2 + 2
Phản hồi vàng hy vọng sẽ là:
4
GPT (Biến đổi tạo sinh được huấn luyện trước)
Một nhóm mô hình ngôn ngữ lớn dựa trên Transformer do OpenAI phát triển.
Các biến thể GPT có thể áp dụng cho nhiều phương thức, bao gồm:
- tạo hình ảnh (ví dụ: ImageGPT)
- tạo văn bản thành hình ảnh (ví dụ: DALL-E).
Cao
ảo giác
Việc tạo ra kết quả có vẻ hợp lý nhưng không chính xác về mặt thực tế bằng mô hình AI tạo sinh, mô hình này có ý định đưa ra một câu nhận định về thế giới thực. Ví dụ: một mô hình AI tạo sinh tuyên bố rằng Barack Obama đã chết vào năm 1865 là ảo giác.
đánh giá thủ công
Một quy trình mà con người đánh giá chất lượng của kết quả của một mô hình học máy; ví dụ: nhờ những người nói hai thứ tiếng đánh giá chất lượng của một mô hình dịch bằng học máy. Việc đánh giá thủ công đặc biệt hữu ích khi đánh giá các mô hình không có câu trả lời đúng.
Khác với quy trình đánh giá tự động và quy trình đánh giá bằng trình tự động đánh giá.
I
học tập theo bối cảnh
Từ đồng nghĩa với câu lệnh dựa trên một vài ví dụ.
L
LaMDA (Mô hình ngôn ngữ cho ứng dụng đối thoại)
Mô hình ngôn ngữ lớn dựa trên Transformer do Google phát triển, được huấn luyện trên một tập dữ liệu đối thoại lớn có thể tạo ra các câu trả lời trò chuyện thực tế.
LaMDA: công nghệ đàm thoại đột phá của chúng tôi cung cấp thông tin tổng quan.
mô hình ngôn ngữ
Mô hình ước tính xác suất một mã thông báo hoặc một chuỗi mã thông báo xuất hiện trong một chuỗi mã thông báo dài hơn.
mô hình ngôn ngữ lớn
Ít nhất, mô hình ngôn ngữ có số lượng rất lớn tham số. Nói một cách không chính thức, mọi mô hình ngôn ngữ dựa trên Transformer, chẳng hạn như Gemini hoặc GPT.
không gian tiềm ẩn
Đồng nghĩa với không gian nhúng.
Khoảng cách Levenshtein
Chỉ số khoảng cách chỉnh sửa tính toán số lượng thao tác xoá, chèn và thay thế ít nhất cần thiết để thay đổi một từ thành một từ khác. Ví dụ: khoảng cách Levenshtein giữa các từ "heart" (trái tim) và "darts" (phi tiêu) là 3 vì 3 lần chỉnh sửa sau đây là ít thay đổi nhất để biến từ này thành từ kia:
- heart → deart (thay thế "h" bằng "d")
- deart → dart (xoá "e")
- dart → darts (chèn "s")
Xin lưu ý rằng trình tự trước đó không phải là lộ trình duy nhất của 3 lần chỉnh sửa.
LLM
Từ viết tắt của mô hình ngôn ngữ lớn.
Đánh giá LLM (evals)
Một bộ chỉ số và điểm chuẩn để đánh giá hiệu suất của mô hình ngôn ngữ lớn (LLM). Nói chung, các hoạt động đánh giá LLM:
- Giúp các nhà nghiên cứu xác định những khía cạnh cần cải thiện đối với LLM.
- Hữu ích trong việc so sánh các LLM khác nhau và xác định LLM tốt nhất cho một tác vụ cụ thể.
- Giúp đảm bảo rằng LLM được sử dụng một cách an toàn và hợp lý.
LoRA
Viết tắt của Khả năng thích ứng cấp thấp.
Khả năng thích ứng cấp thấp (LoRA)
Một kỹ thuật tiết kiệm tham số để điều chỉnh tinh vi, giúp "đóng băng" các trọng số được huấn luyện trước của mô hình (như vậy, các trọng số này không thể sửa đổi được nữa) rồi chèn một tập hợp nhỏ các trọng số có thể huấn luyện vào mô hình. Tập hợp các trọng số có thể huấn luyện này (còn gọi là "matrices cập nhật") nhỏ hơn đáng kể so với mô hình cơ sở và do đó, việc huấn luyện sẽ nhanh hơn nhiều.
LoRA mang lại các lợi ích sau:
- Cải thiện chất lượng dự đoán của mô hình cho miền áp dụng tính năng tinh chỉnh.
- Điều chỉnh chi tiết nhanh hơn so với các kỹ thuật yêu cầu điều chỉnh chi tiết tất cả tham số của mô hình.
- Giảm chi phí tính toán của hoạt động xác suất bằng cách cho phép phân phát đồng thời nhiều mô hình chuyên biệt có cùng một mô hình cơ sở.
M
mô hình ngôn ngữ bị che
Mô hình ngôn ngữ dự đoán xác suất các mã thông báo đề xuất điền vào chỗ trống trong một trình tự. Ví dụ: mô hình ngôn ngữ bị che có thể tính toán xác suất cho(các) từ đề xuất để thay thế dấu gạch dưới trong câu sau:
____ trong chiếc mũ đã quay lại.
Tài liệu thường sử dụng chuỗi "MASK" thay vì gạch dưới. Ví dụ:
"MASK" trong chiếc mũ đã trở lại.
Hầu hết các mô hình ngôn ngữ ẩn hiện đại đều hai chiều.
độ chính xác trung bình tại k (mAP@k)
Giá trị trung bình thống kê của tất cả điểm số độ chính xác trung bình tại k trên một tập dữ liệu xác thực. Một cách sử dụng độ chính xác trung bình tại k là để đánh giá chất lượng của các đề xuất do hệ thống đề xuất tạo ra.
Mặc dù cụm từ "trung bình trung bình" nghe có vẻ thừa thãi, nhưng tên của chỉ số này là phù hợp. Xét cho cùng, chỉ số này tìm giá trị trung bình của nhiều giá trị độ chính xác trung bình tại k.
học siêu việt
Một tập hợp con của công nghệ học máy giúp khám phá hoặc cải thiện thuật toán học. Hệ thống học siêu dữ liệu cũng có thể hướng đến việc huấn luyện một mô hình để nhanh chóng học một nhiệm vụ mới từ một lượng nhỏ dữ liệu hoặc từ kinh nghiệm có được trong các nhiệm vụ trước đó. Các thuật toán học siêu dữ liệu thường cố gắng đạt được những mục tiêu sau:
- Cải thiện hoặc tìm hiểu các tính năng được thiết kế thủ công (chẳng hạn như trình khởi chạy hoặc trình tối ưu hoá).
- Tiết kiệm dữ liệu và hiệu quả tính toán hơn.
- Cải thiện khả năng khái quát.
Học siêu dữ liệu có liên quan đến học từ một vài dữ liệu.
sự kết hợp của các chuyên gia
Một lược đồ để tăng hiệu quả của mạng nơron bằng cách chỉ sử dụng một tập hợp con tham số (được gọi là chuyên gia) để xử lý một mã thông báo đầu vào nhất định hoặc ví dụ. Mạng lọc sẽ định tuyến từng mã thông báo đầu vào hoặc ví dụ đến(các) chuyên gia thích hợp.
Để biết thông tin chi tiết, hãy xem một trong các bài viết sau:
- Mạng nơron khổng lồ: Lớp hỗn hợp chuyên gia có cổng thưa
- Hỗn hợp chuyên gia với tính năng định tuyến lựa chọn của chuyên gia
MMIT
Viết tắt của được điều chỉnh theo hướng dẫn đa phương thức.
phương thức
Danh mục dữ liệu cấp cao. Ví dụ: số, văn bản, hình ảnh, video và âm thanh là 5 phương thức khác nhau.
tính song song của mô hình
Một cách mở rộng quy mô huấn luyện hoặc suy luận, trong đó đặt các phần khác nhau của một mô hình trên các thiết bị khác nhau. Tính năng song song của mô hình cho phép các mô hình quá lớn để vừa với một thiết bị.
Để triển khai tính năng song song mô hình, hệ thống thường thực hiện những việc sau:
- Phân mảnh (chia) mô hình thành các phần nhỏ hơn.
- Phân phối quá trình huấn luyện các phần nhỏ đó trên nhiều bộ xử lý. Mỗi bộ xử lý sẽ huấn luyện phần riêng của mô hình.
- Kết hợp các kết quả để tạo một mô hình duy nhất.
Tính song song của mô hình làm chậm quá trình huấn luyện.
Xem thêm về tính song song dữ liệu.
MOE
Viết tắt của nhóm chuyên gia.
tự chú ý nhiều đầu
Một phần mở rộng của tự chú ý áp dụng cơ chế tự chú ý nhiều lần cho mỗi vị trí trong trình tự đầu vào.
Transformer đã giới thiệu tính năng tự chú ý nhiều đầu.
được điều chỉnh hướng dẫn đa phương thức
Mô hình được điều chỉnh theo hướng dẫn có thể xử lý dữ liệu đầu vào ngoài văn bản, chẳng hạn như hình ảnh, video và âm thanh.
mô hình đa phương thức
Mô hình có đầu vào và/hoặc đầu ra bao gồm nhiều chế độ. Ví dụ: hãy xem xét một mô hình lấy cả hình ảnh và chú thích văn bản (hai phương thức) làm tính năng và xuất ra một điểm số cho biết mức độ phù hợp của chú thích văn bản đối với hình ảnh. Do đó, dữ liệu đầu vào của mô hình này là đa phương thức và dữ liệu đầu ra là đơn phương thức.
Không
xử lý ngôn ngữ tự nhiên
Lĩnh vực dạy máy tính xử lý những gì người dùng nói hoặc nhập bằng các quy tắc ngôn ngữ. Hầu hết các phương pháp xử lý ngôn ngữ tự nhiên hiện đại đều dựa vào học máy.hiểu ngôn ngữ tự nhiên
Một tập hợp con của công nghệ xử lý ngôn ngữ tự nhiên xác định ý định của một câu nói hoặc nội dung được nhập. Khả năng hiểu ngôn ngữ tự nhiên có thể vượt ra ngoài việc xử lý ngôn ngữ tự nhiên để xem xét các khía cạnh phức tạp của ngôn ngữ như ngữ cảnh, lời châm biếm và cảm xúc.
N-gram
Một chuỗi có thứ tự gồm N từ. Ví dụ: truly madly là một từ 2 âm tiết. Vì thứ tự có liên quan, madly truly là một từ 2 gram khác với truly madly.
| Không | (Các) tên của loại N-gram này | Ví dụ |
|---|---|---|
| 2 | bigram hoặc 2-gram | đi, đến, ăn trưa, ăn tối |
| 3 | ba ký tự hoặc 3 ký tự | ate too much, three blind mice, the bell tolls |
| 4 | 4-gram | walk in the park, dust in the wind, the boy ate lentils |
Nhiều mô hình hiểu ngôn ngữ tự nhiên dựa vào N-gram để dự đoán từ tiếp theo mà người dùng sẽ nhập hoặc nói. Ví dụ: giả sử người dùng đã nhập three blind (3 người mù). Mô hình NLU dựa trên trigram có thể dự đoán rằng người dùng sẽ nhập chuột tiếp theo.
So sánh N-gram với túi từ, là các tập hợp từ không theo thứ tự.
xử lý ngôn ngữ tự nhiên (NLP)
Từ viết tắt của xử lý ngôn ngữ tự nhiên.
hiểu ngôn ngữ tự nhiên (NLU)
Từ viết tắt của hiểu ngôn ngữ tự nhiên.
không có câu trả lời đúng (NORA)
Một lời nhắc có nhiều câu trả lời phù hợp. Ví dụ: câu lệnh sau đây không có câu trả lời đúng:
Kể cho tôi nghe một chuyện cười về voi.
Việc đánh giá câu lệnh không có câu trả lời đúng có thể là một thách thức.
NORA
Viết tắt của không có câu trả lời đúng.
O
câu lệnh một lần
Một câu lệnh chứa một ví dụ minh hoạ cách mô hình ngôn ngữ lớn phản hồi. Ví dụ: câu lệnh sau đây chứa một ví dụ cho thấy cách một mô hình ngôn ngữ lớn trả lời truy vấn.
| Các phần của một câu lệnh | Ghi chú |
|---|---|
| Đơn vị tiền tệ chính thức của quốc gia đã chỉ định là gì? | Câu hỏi mà bạn muốn LLM trả lời. |
| Pháp: EUR | Một ví dụ. |
| Ấn Độ: | Cụm từ tìm kiếm thực tế. |
So sánh và đối chiếu lệnh nhắc một lần với các thuật ngữ sau:
Điểm
điều chỉnh hiệu quả theo tham số
Một bộ kỹ thuật để điều chỉnh tinh vi một mô hình ngôn ngữ được huấn luyện trước (PLM) lớn hiệu quả hơn so với việc điều chỉnh tinh vi toàn bộ. Việc điều chỉnh hiệu quả theo tham số thường tinh chỉnh ít tham số hơn so với việc tinh chỉnh đầy đủ, nhưng thường tạo ra một mô hình ngôn ngữ lớn hoạt động tốt (hoặc gần như tốt) như một mô hình ngôn ngữ lớn được tạo từ quá trình tinh chỉnh đầy đủ.
So sánh và đối chiếu việc điều chỉnh hiệu quả tham số với:
Điều chỉnh hiệu quả theo tham số còn được gọi là điều chỉnh tinh vi hiệu quả theo tham số.
quy trình
Một dạng song song mô hình, trong đó quá trình xử lý của mô hình được chia thành các giai đoạn liên tiếp và mỗi giai đoạn được thực thi trên một thiết bị khác nhau. Trong khi một giai đoạn đang xử lý một lô, thì giai đoạn trước đó có thể xử lý lô tiếp theo.
Xem thêm phần đào tạo theo giai đoạn.
PLM
Từ viết tắt của mô hình ngôn ngữ được huấn luyện trước.
mã hoá vị trí
Một kỹ thuật để thêm thông tin về vị trí của một mã thông báo trong một trình tự vào phần nhúng của mã thông báo. Mô hình Transformer sử dụng mã hoá vị trí để hiểu rõ hơn mối quan hệ giữa các phần khác nhau của trình tự.
Một cách triển khai phổ biến của mã hoá vị trí là sử dụng hàm sin. (Cụ thể, tần số và biên độ của hàm sin được xác định bằng vị trí của mã thông báo trong trình tự.) Kỹ thuật này cho phép mô hình Transformer tìm hiểu cách chú ý đến các phần khác nhau của trình tự dựa trên vị trí của các phần đó.
mô hình sau khi huấn luyện
Thuật ngữ được xác định không rõ ràng, thường đề cập đến một mô hình được huấn luyện trước đã trải qua một số quy trình xử lý sau, chẳng hạn như một hoặc nhiều quy trình sau:
độ chính xác tại k (precision@k)
Chỉ số để đánh giá danh sách các mục được xếp hạng (theo thứ tự). Độ chính xác tại k xác định tỷ lệ phần trăm các mục k đầu tiên trong danh sách đó là "liên quan". Đó là:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
Giá trị của k phải nhỏ hơn hoặc bằng độ dài của danh sách được trả về. Xin lưu ý rằng độ dài của danh sách được trả về không thuộc phạm vi tính toán.
Mức độ phù hợp thường mang tính chủ quan; ngay cả người đánh giá là chuyên gia cũng thường không đồng ý về những mục nào là phù hợp.
So với:
mô hình được huấn luyện sẵn
Thông thường, một mô hình đã được huấn luyện. Thuật ngữ này cũng có thể có nghĩa là một vectơ nhúng đã được huấn luyện trước đó.
Thuật ngữ mô hình ngôn ngữ được huấn luyện trước thường đề cập đến một mô hình ngôn ngữ lớn đã được huấn luyện.
huấn luyện trước
Quá trình huấn luyện ban đầu của một mô hình trên một tập dữ liệu lớn. Một số mô hình được huấn luyện trước là những gã khổng lồ vụng về và thường phải được tinh chỉnh thông qua quá trình huấn luyện bổ sung. Ví dụ: các chuyên gia về học máy có thể huấn luyện trước một mô hình ngôn ngữ lớn trên một tập dữ liệu văn bản khổng lồ, chẳng hạn như tất cả các trang tiếng Anh trong Wikipedia. Sau khi huấn luyện trước, mô hình thu được có thể được tinh chỉnh thêm thông qua bất kỳ kỹ thuật nào sau đây:
lời nhắc
Mọi văn bản được nhập làm dữ liệu đầu vào cho một mô hình ngôn ngữ lớn để điều kiện hoá mô hình hoạt động theo một cách nhất định. Lời nhắc có thể ngắn như một cụm từ hoặc dài tuỳ ý (ví dụ: toàn bộ văn bản của một cuốn tiểu thuyết). Lời nhắc thuộc nhiều danh mục, bao gồm cả những lời nhắc trong bảng sau:
| Danh mục câu lệnh | Ví dụ: | Ghi chú |
|---|---|---|
| Câu hỏi | Một con chim bồ câu có thể bay nhanh đến mức nào? | |
| Hướng dẫn | Viết một bài thơ hài hước về hoạt động chênh lệch giá. | Câu lệnh yêu cầu mô hình ngôn ngữ lớn làm một việc gì đó. |
| Ví dụ: | Dịch mã Markdown sang HTML. Ví dụ:
Markdown: * mục danh sách HTML: <ul> <li>mục danh sách</li> </ul> |
Câu đầu tiên trong câu lệnh mẫu này là một hướng dẫn. Phần còn lại của câu lệnh là ví dụ. |
| Vai trò | Giải thích lý do sử dụng phương pháp giảm độ dốc trong quá trình huấn luyện máy học cho một tiến sĩ Vật lý. | Phần đầu tiên của câu là hướng dẫn; cụm từ "đến một tiến sĩ Vật lý" là phần vai trò. |
| Dữ liệu đầu vào một phần để mô hình hoàn tất | Thủ tướng Vương quốc Anh sống tại | Lời nhắc nhập một phần có thể kết thúc đột ngột (như ví dụ này) hoặc kết thúc bằng dấu gạch dưới. |
Mô hình AI tạo sinh có thể phản hồi một câu lệnh bằng văn bản, mã, hình ảnh, nội dung nhúng, video… gần như mọi thứ.
học tập dựa trên câu lệnh
Một khả năng của một số mô hình nhất định cho phép các mô hình đó điều chỉnh hành vi để phản hồi hoạt động nhập văn bản tuỳ ý (lời nhắc). Trong mô hình học tập dựa trên câu lệnh thông thường, mô hình ngôn ngữ lớn sẽ phản hồi câu lệnh bằng cách tạo văn bản. Ví dụ: giả sử người dùng nhập lời nhắc sau:
Tóm tắt Định luật thứ ba của Newton về chuyển động.
Mô hình có khả năng học dựa trên câu lệnh không được huấn luyện cụ thể để trả lời câu lệnh trước đó. Thay vào đó, mô hình "biết" nhiều thông tin thực tế về vật lý, nhiều thông tin về các quy tắc ngôn ngữ chung và nhiều thông tin về những yếu tố tạo nên câu trả lời hữu ích nói chung. Kiến thức đó là đủ để cung cấp một câu trả lời (hy vọng là) hữu ích. Ý kiến phản hồi bổ sung của con người ("Câu trả lời đó quá phức tạp" hoặc "Phản ứng là gì?") cho phép một số hệ thống học dựa trên câu lệnh dần dần cải thiện tính hữu ích của câu trả lời.
thiết kế câu lệnh
Đồng nghĩa với thiết kế câu lệnh.
thiết kế câu lệnh
Nghệ thuật tạo lời nhắc để thu hút các câu trả lời mong muốn từ một mô hình ngôn ngữ lớn. Con người thực hiện kỹ thuật gợi ý. Việc viết câu lệnh có cấu trúc tốt là một phần thiết yếu để đảm bảo nhận được câu trả lời hữu ích từ mô hình ngôn ngữ lớn. Kỹ thuật lời nhắc phụ thuộc vào nhiều yếu tố, bao gồm:
- Tập dữ liệu dùng để huấn luyện trước và có thể điều chỉnh tinh vi mô hình ngôn ngữ lớn.
- Nhiệt độ và các tham số giải mã khác mà mô hình sử dụng để tạo phản hồi.
Hãy xem bài viết Giới thiệu về thiết kế câu lệnh để biết thêm thông tin chi tiết về cách viết câu lệnh hữu ích.
Thiết kế câu lệnh đồng nghĩa với thiết kế câu lệnh.
điều chỉnh nhanh
Cơ chế điều chỉnh tham số hiệu quả giúp tìm hiểu "phần tiền tố" mà hệ thống thêm vào lời nhắc thực tế.
Một biến thể của tính năng điều chỉnh lời nhắc (đôi khi được gọi là điều chỉnh tiền tố) là đặt tiền tố ở mọi lớp. Ngược lại, hầu hết các tuỳ chọn điều chỉnh lời nhắc chỉ thêm một tiền tố vào lớp đầu vào.
Điểm
gọi lại tại k (recall@k)
Chỉ số để đánh giá các hệ thống đưa ra danh sách các mục được xếp hạng (theo thứ tự). Mức độ gợi nhắc tại k xác định tỷ lệ phần trăm các mục có liên quan trong k mục đầu tiên trong danh sách đó trên tổng số mục có liên quan được trả về.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
So sánh với độ chính xác tại k.
văn bản tham chiếu
Câu trả lời của chuyên gia cho một câu lệnh. Ví dụ: với câu lệnh sau:
Dịch câu hỏi "Bạn tên gì?" từ tiếng Anh sang tiếng Pháp.
Câu trả lời của chuyên gia có thể là:
Comment vous appelez-vous?
Nhiều chỉ số (chẳng hạn như ROUGE) đo lường mức độ phù hợp giữa văn bản tham chiếu với văn bản do mô hình học máy tạo.
lời nhắc về vai trò
Một phần không bắt buộc của câu lệnh giúp xác định đối tượng mục tiêu cho phản hồi của mô hình AI tạo sinh. Nếu không có câu lệnh về vai trò, mô hình ngôn ngữ lớn sẽ đưa ra câu trả lời có thể hữu ích hoặc không hữu ích cho người đặt câu hỏi. Với câu lệnh theo vai trò, mô hình ngôn ngữ lớn có thể trả lời theo cách phù hợp và hữu ích hơn cho một đối tượng mục tiêu cụ thể. Ví dụ: phần lời nhắc về vai trò của các lời nhắc sau đây được in đậm:
- Tóm tắt bài viết này cho một tiến sĩ kinh tế.
- Mô tả cách hoạt động của thủy triều cho trẻ 10 tuổi.
- Giải thích về cuộc khủng hoảng tài chính năm 2008. Nói như khi bạn trò chuyện với một đứa trẻ hoặc một chú chó săn mồi.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation – Mô hình đánh giá tóm tắt dựa trên khả năng gợi nhắc)
Một nhóm chỉ số đánh giá các mô hình dịch máy và tóm tắt tự động. Chỉ số ROUGE xác định mức độ trùng lặp giữa văn bản tham chiếu và văn bản do mô hình học máy tạo. Mỗi thành viên trong gia đình ROUGE đo lường mức độ trùng lặp theo một cách khác nhau. Điểm ROUGE cao hơn cho biết mức độ tương đồng giữa văn bản tham chiếu và văn bản được tạo cao hơn so với điểm ROUGE thấp hơn.
Mỗi thành viên trong gia đình ROUGE thường tạo ra các chỉ số sau:
- Chính xác
- Nhớ lại
- F1
Để biết thông tin chi tiết và ví dụ, hãy xem:
ROUGE-L
Một thành viên của gia đình ROUGE tập trung vào độ dài của chuỗi con chung dài nhất trong văn bản tham chiếu và văn bản được tạo. Các công thức sau đây tính toán tỷ lệ thu hồi và độ chính xác cho ROUGE-L:
Sau đó, bạn có thể sử dụng F1 để cuộn lên độ thu hồi ROUGE-L và độ chính xác ROUGE-L thành một chỉ số duy nhất:
ROUGE-L bỏ qua mọi dòng mới trong văn bản tham chiếu và văn bản được tạo, vì vậy, trình tự con chung dài nhất có thể vượt qua nhiều câu. Khi văn bản tham chiếu và văn bản được tạo có nhiều câu, một biến thể của ROUGE-L có tên là ROUGE-Lsum thường là chỉ số tốt hơn. ROUGE-Lsum xác định trình tự con chung dài nhất cho mỗi câu trong một đoạn văn, sau đó tính trung bình của các trình tự con chung dài nhất đó.
ROUGE-N
Một tập hợp các chỉ số trong nhóm ROUGE so sánh các N-gram dùng chung có kích thước nhất định trong văn bản tham chiếu và văn bản được tạo. Ví dụ:
- ROUGE-1 đo lường số lượng mã thông báo được chia sẻ trong văn bản tham chiếu và văn bản được tạo.
- ROUGE-2 đo lường số lượng từ kép (2-gram) được chia sẻ trong văn bản tham chiếu và văn bản được tạo.
- ROUGE-3 đo lường số lượng bộ ba (3-gram) được chia sẻ trong văn bản đối chiếu và văn bản được tạo.
Bạn có thể sử dụng các công thức sau để tính toán độ thu hồi ROUGE-N và độ chính xác ROUGE-N cho bất kỳ thành viên nào trong gia đình ROUGE-N:
Sau đó, bạn có thể sử dụng F1 để tổng hợp giá trị gợi nhắc ROUGE-N và độ chính xác ROUGE-N thành một chỉ số duy nhất:
ROUGE-S
Một dạng ROUGE-N dễ tính cho phép so khớp skip-gram. Tức là ROUGE-N chỉ tính N-gram khớp chính xác, nhưng ROUGE-S cũng tính N-gram được phân tách bằng một hoặc nhiều từ. Ví dụ: hãy cân nhắc những điều sau đây:
- văn bản tham khảo: Mây trắng
- văn bản được tạo: Mây trắng cuồn cuộn
Khi tính toán ROUGE-N, cụm từ 2-gram White clouds (Mây trắng) không khớp với cụm từ White billowing clouds (Mây trắng cuồn cuộn). Tuy nhiên, khi tính toán ROUGE-S, Mây trắng khớp với Mây trắng cuồn cuộn.
S
tự chú ý (còn gọi là lớp tự chú ý)
Một lớp mạng nơron biến đổi một chuỗi các mục nhúng (ví dụ: các mục nhúng mã thông báo) thành một chuỗi các mục nhúng khác. Mỗi phần nhúng trong trình tự đầu ra được tạo bằng cách tích hợp thông tin từ các phần tử của trình tự đầu vào thông qua cơ chế chú ý.
Phần tự trong tự chú ý đề cập đến trình tự chú ý đến chính nó thay vì một ngữ cảnh nào đó. Tự chú ý là một trong những thành phần chính của Transformer và sử dụng thuật ngữ tra cứu từ điển, chẳng hạn như "truy vấn", "khoá" và "giá trị".
Lớp tự chú ý bắt đầu bằng một chuỗi đại diện đầu vào, một đại diện cho mỗi từ. Biểu diễn đầu vào cho một từ có thể là một tính năng nhúng đơn giản. Đối với mỗi từ trong một chuỗi đầu vào, mạng sẽ tính điểm mức độ liên quan của từ đó với mọi phần tử trong toàn bộ chuỗi từ. Điểm liên quan xác định mức độ biểu diễn cuối cùng của từ kết hợp với biểu diễn của các từ khác.
Ví dụ: hãy xem xét câu sau:
Con vật không băng qua đường vì quá mệt.
Hình minh hoạ sau đây (từ bài viết Transformer: A Novel Neural Network Architecture for Language Understanding (Biến đổi: Cấu trúc mạng nơron mới để hiểu ngôn ngữ)) cho thấy mẫu chú ý của lớp tự chú ý cho đại từ nhân xưng it, trong đó độ đậm của mỗi dòng cho biết mức độ đóng góp của mỗi từ vào việc thể hiện:
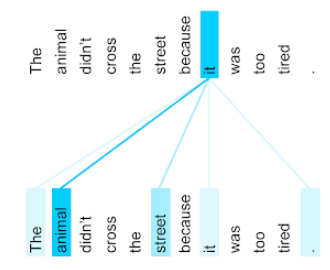
Lớp tự chú ý làm nổi bật những từ có liên quan đến "it". Trong trường hợp này, lớp chú ý đã học cách làm nổi bật những từ mà lớp này có thể đề cập đến, gán trọng số cao nhất cho động vật.
Đối với một chuỗi n mã thông báo, tính năng tự chú ý sẽ biến đổi một chuỗi các mục nhúng n lần riêng biệt, một lần tại mỗi vị trí trong chuỗi.
Ngoài ra, hãy tham khảo tính năng chú ý và tính năng tự chú ý nhiều đầu.
phân tích cảm xúc
Sử dụng thuật toán thống kê hoặc học máy để xác định thái độ tổng thể của một nhóm (tích cực hay tiêu cực) đối với một dịch vụ, sản phẩm, tổ chức hoặc chủ đề. Ví dụ: bằng cách sử dụng tính năng hiểu ngôn ngữ tự nhiên, một thuật toán có thể phân tích cảm xúc trên phản hồi dạng văn bản của một khoá học đại học để xác định mức độ mà học viên thường thích hoặc không thích khoá học đó.
tác vụ trình tự đến trình tự
Một tác vụ chuyển đổi một chuỗi đầu vào gồm mã thông báo thành một chuỗi đầu ra gồm các mã thông báo. Ví dụ: hai loại tác vụ trình tự với trình tự phổ biến là:
- Người dịch:
- Trình tự đầu vào mẫu: "I love you" (Tôi yêu bạn).
- Trình tự đầu ra mẫu: "Je t'aime".
- Trả lời câu hỏi:
- Trình tự đầu vào mẫu: "Tôi có cần xe ở Thành phố New York không?"
- Trình tự đầu ra mẫu: "Không. Vui lòng để xe ở nhà."
skip-gram
N-gram có thể bỏ qua (hoặc "bỏ qua") các từ khỏi ngữ cảnh gốc, nghĩa là các từ N ban đầu có thể không liền kề nhau. Chính xác hơn, "k-skip-n-gram" là một n-gram mà có thể đã bỏ qua tối đa k từ.
Ví dụ: cụm từ "the quick brown fox" có thể có các cụm từ 2-gram sau:
- "the quick"
- "quick brown"
- "chó sói nâu"
"1-skip-2-gram" là một cặp từ có tối đa 1 từ ở giữa. Do đó, cụm từ "the quick brown fox" có các từ 2-gram 1-bỏ qua sau đây:
- "the brown"
- "quick fox"
Ngoài ra, tất cả các từ 2 âm tiết cũng là từ 1 âm tiết bỏ qua 2 âm tiết, vì có thể bỏ qua ít hơn một từ.
Skip-gram rất hữu ích để hiểu rõ hơn về ngữ cảnh xung quanh của một từ. Trong ví dụ này, "fox" được liên kết trực tiếp với "quick" trong tập hợp 1-skip-2-gram, nhưng không có trong tập hợp 2-gram.
Skip-gram giúp huấn luyện các mô hình nhúng từ.
điều chỉnh lời nhắc mềm
Một kỹ thuật để điều chỉnh mô hình ngôn ngữ lớn cho một tác vụ cụ thể mà không cần điều chỉnh tinh vi tốn nhiều tài nguyên. Thay vì huấn luyện lại tất cả trọng số trong mô hình, tính năng điều chỉnh lời nhắc mềm sẽ tự động điều chỉnh lời nhắc để đạt được cùng một mục tiêu.
Với một câu lệnh dạng văn bản, tính năng điều chỉnh câu lệnh mềm thường thêm các phần nhúng mã thông báo bổ sung vào câu lệnh và sử dụng tính năng hồi quy để tối ưu hoá dữ liệu đầu vào.
Lời nhắc "khó" chứa các mã thông báo thực tế thay vì mã thông báo nhúng.
tính năng thưa
Một tính năng có giá trị chủ yếu là 0 hoặc trống. Ví dụ: một đặc điểm chứa một giá trị 1 và một triệu giá trị 0 là thưa thớt. Ngược lại, tính năng dày đặc có các giá trị chủ yếu không phải là 0 hoặc trống.
Trong học máy, có một số lượng đáng ngạc nhiên các đặc điểm là đặc điểm thưa thớt. Các tính năng phân loại thường là các tính năng thưa. Ví dụ: trong số 300 loài cây có thể có trong một khu rừng, một ví dụ duy nhất có thể chỉ xác định được một cây phong. Hoặc trong số hàng triệu video có thể có trong thư viện video, một ví dụ duy nhất có thể chỉ xác định được "Casablanca".
Trong một mô hình, bạn thường biểu thị các tính năng thưa thớt bằng mã hoá one-hot. Nếu mã hoá one-hot có kích thước lớn, bạn có thể đặt lớp nhúng lên trên mã hoá one-hot để tăng hiệu quả.
biểu diễn thưa
Chỉ lưu trữ (các) vị trí của các phần tử khác 0 trong một đặc điểm thưa thớt.
Ví dụ: giả sử một đặc điểm phân loại có tên species xác định 36 loài cây trong một khu rừng cụ thể. Giả sử thêm rằng mỗi ví dụ chỉ xác định một loài.
Bạn có thể sử dụng một vectơ một chiều để biểu thị các loài cây trong mỗi ví dụ.
Một vectơ một chiều sẽ chứa một 1 (để biểu thị một loài cây cụ thể trong ví dụ đó) và 35 0 (để biểu thị 35 loài cây không trong ví dụ đó). Vì vậy, cách biểu thị một nóng của maple có thể có dạng như sau:

Ngoài ra, cách biểu diễn thưa thớt chỉ xác định vị trí của một loài cụ thể. Nếu maple ở vị trí 24, thì cách biểu diễn thưa của maple sẽ chỉ là:
24
Lưu ý rằng cách biểu diễn thưa thớt nhỏ gọn hơn nhiều so với cách biểu diễn một nóng.
Nhấp vào biểu tượng để xem ví dụ phức tạp hơn một chút.
Giả sử mỗi ví dụ trong mô hình của bạn phải thể hiện các từ – nhưng không phải thứ tự của các từ đó – trong một câu tiếng Anh. Tiếng Anh bao gồm khoảng 170.000 từ, vì vậy, tiếng Anh là một tính năng phân loại có khoảng 170.000 phần tử. Hầu hết các câu tiếng Anh đều sử dụng một phần cực nhỏ trong số 170.000 từ đó,vì vậy, tập hợp từ trong một ví dụ gần như chắc chắn sẽ là dữ liệu thưa thớt.
Hãy xem xét câu sau:
My dog is a great dog
Bạn có thể sử dụng một biến thể của vectơ một chiều để biểu thị các từ trong câu này. Trong biến thể này, nhiều ô trong vectơ có thể chứa giá trị khác 0. Hơn nữa, trong biến thể này, một ô có thể chứa một số nguyên khác với 1. Mặc dù các từ "my" (của tôi), "is" (là), "a" (một) và "great" (tuyệt vời) chỉ xuất hiện một lần trong câu, nhưng từ "dog" (chó) xuất hiện hai lần. Việc sử dụng biến thể này của vectơ một chiều để biểu thị các từ trong câu này sẽ tạo ra vectơ có 170.000 phần tử sau:

Biểu diễn thưa của cùng một câu sẽ chỉ là:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
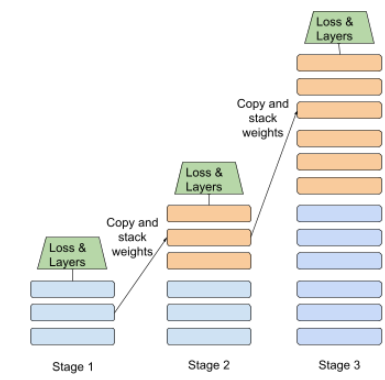
huấn luyện theo giai đoạn
Một chiến thuật huấn luyện mô hình theo trình tự các giai đoạn riêng biệt. Mục tiêu có thể là đẩy nhanh quá trình huấn luyện hoặc đạt được chất lượng mô hình tốt hơn.
Dưới đây là hình minh hoạ phương pháp xếp chồng tiến bộ:
- Giai đoạn 1 chứa 3 lớp ẩn, giai đoạn 2 chứa 6 lớp ẩn và giai đoạn 3 chứa 12 lớp ẩn.
- Giai đoạn 2 bắt đầu huấn luyện bằng các trọng số đã học được trong 3 lớp ẩn của Giai đoạn 1. Giai đoạn 3 bắt đầu huấn luyện bằng các trọng số đã học được trong 6 lớp ẩn của Giai đoạn 2.
Xem thêm về quy trình tạo luồng.
mã thông báo từ phụ
Trong mô hình ngôn ngữ, mã thông báo là một chuỗi con của một từ, có thể là toàn bộ từ.
Ví dụ: một từ như "itemize" có thể được chia thành các phần "item" (từ gốc) và "ize" (hậu tố), mỗi phần được biểu thị bằng một mã thông báo riêng. Việc chia các từ không phổ biến thành các phần như vậy (gọi là từ phụ) cho phép các mô hình ngôn ngữ hoạt động trên các thành phần phổ biến hơn của từ, chẳng hạn như tiền tố và hậu tố.
Ngược lại, các từ phổ biến như "going" (sẽ) có thể không bị chia nhỏ và có thể được biểu thị bằng một mã thông báo duy nhất.
T
T5
Mô hình học chuyển đổi văn bản sang văn bản do AI của Google ra mắt vào năm 2020. T5 là mô hình mã hoá-giải mã, dựa trên cấu trúc Transformer, được huấn luyện trên một tập dữ liệu cực lớn. Công nghệ này hiệu quả trong nhiều nhiệm vụ xử lý ngôn ngữ tự nhiên, chẳng hạn như tạo văn bản, dịch ngôn ngữ và trả lời câu hỏi theo cách trò chuyện.
T5 được đặt tên theo 5 chữ T trong cụm từ "Text-to-Text Transfer Transformer" (Chuyển đổi văn bản sang văn bản).
T5X
Khung học máy nguồn mở được thiết kế để xây dựng và huấn luyện các mô hình xử lý ngôn ngữ tự nhiên (NLP) trên quy mô lớn. T5 được triển khai trên cơ sở mã T5X (được xây dựng trên JAX và Flax).
nhiệt độ
Thông số siêu dữ liệu kiểm soát mức độ ngẫu nhiên của đầu ra của mô hình. Nhiệt độ càng cao thì đầu ra càng ngẫu nhiên, còn nhiệt độ càng thấp thì đầu ra càng ít ngẫu nhiên.
Việc chọn nhiệt độ tốt nhất phụ thuộc vào ứng dụng cụ thể và các thuộc tính ưu tiên của đầu ra của mô hình. Ví dụ: bạn có thể tăng nhiệt độ khi tạo một ứng dụng tạo ra đầu ra mẫu quảng cáo. Ngược lại, bạn có thể giảm nhiệt độ khi xây dựng mô hình phân loại hình ảnh hoặc văn bản để cải thiện độ chính xác và tính nhất quán của mô hình.
Nhiệt độ thường được sử dụng với softmax.
span văn bản
Phạm vi chỉ mục mảng được liên kết với một tiểu mục cụ thể của chuỗi văn bản.
Ví dụ: từ good trong chuỗi Python s="Be good now" chiếm khoảng văn bản từ 3 đến 6.
mã thông báo
Trong mô hình ngôn ngữ, đơn vị nguyên tử mà mô hình đang đào tạo và đưa ra dự đoán. Mã thông báo thường là một trong những loại sau:
- một từ – ví dụ: cụm từ "chó thích mèo" bao gồm 3 mã thông báo từ: "chó", "thích" và "mèo".
- một ký tự – ví dụ: cụm từ "cá xe đạp" bao gồm 9 mã ký tự. (Lưu ý rằng khoảng trắng được tính là một trong các mã thông báo.)
- từ phụ – trong đó một từ có thể là một mã thông báo hoặc nhiều mã thông báo. Từ phụ bao gồm một từ gốc, tiền tố hoặc hậu tố. Ví dụ: mô hình ngôn ngữ sử dụng từ phụ làm mã thông báo có thể xem từ "dogs" (chó) là hai mã thông báo (từ gốc "dog" (chó) và hậu tố số nhiều "s"). Cùng một mô hình ngôn ngữ đó có thể xem từ "taller" (cao hơn) là hai từ phụ (từ gốc "tall" (cao) và hậu tố "er").
Trong các miền bên ngoài mô hình ngôn ngữ, mã thông báo có thể đại diện cho các loại đơn vị nguyên tử khác. Ví dụ: trong thị giác máy tính, mã thông báo có thể là một tập hợp con của hình ảnh.
độ chính xác top-k
Tỷ lệ phần trăm số lần "nhãn mục tiêu" xuất hiện trong k vị trí đầu tiên của danh sách được tạo. Danh sách có thể là các đề xuất được cá nhân hoá hoặc danh sách các mục được sắp xếp theo softmax.
Độ chính xác top-k còn được gọi là độ chính xác tại k.
nội dung độc hại
Mức độ phản cảm, đe doạ hoặc lăng mạ của nội dung. Nhiều mô hình học máy có thể xác định và đo lường nội dung độc hại. Hầu hết các mô hình này xác định nội dung độc hại theo nhiều thông số, chẳng hạn như mức độ ngôn từ xúc phạm và mức độ ngôn từ đe doạ.
Biến áp
Kiến trúc mạng nơron được phát triển tại Google dựa vào cơ chế tự chú ý để chuyển đổi một trình tự nhúng đầu vào thành một trình tự nhúng đầu ra mà không cần dựa vào lớp phủ hoặc mạng nơron tái sinh. Bạn có thể xem một Transformer là một ngăn xếp các lớp tự chú ý.
Một Biến đổi có thể bao gồm bất kỳ thành phần nào sau đây:
- bộ mã hoá
- bộ giải mã
- cả bộ mã hoá và bộ giải mã
Bộ mã hoá chuyển đổi một chuỗi các phần nhúng thành một chuỗi mới có cùng độ dài. Bộ mã hoá bao gồm N lớp giống hệt nhau, mỗi lớp chứa hai lớp phụ. Hai lớp phụ này được áp dụng tại mỗi vị trí của trình tự nhúng đầu vào, biến đổi từng phần tử của trình tự thành một phần nhúng mới. Lớp con bộ mã hoá đầu tiên tổng hợp thông tin từ toàn bộ trình tự đầu vào. Lớp con bộ mã hoá thứ hai chuyển đổi thông tin tổng hợp thành một phần nhúng đầu ra.
Bộ giải mã biến đổi một chuỗi các mục nhúng đầu vào thành một chuỗi các mục nhúng đầu ra, có thể có độ dài khác. Bộ giải mã cũng bao gồm N lớp giống hệt nhau với 3 lớp con, trong đó 2 lớp con tương tự như các lớp con của bộ mã hoá. Lớp con giải mã thứ ba lấy đầu ra của bộ mã hoá và áp dụng cơ chế tự chú ý để thu thập thông tin từ đó.
Bài đăng trên blog Transformer: A Novel Neural Network Architecture for Language Understanding (Transformer: Cấu trúc mạng nơron mới để hiểu ngôn ngữ) cung cấp thông tin giới thiệu hữu ích về Transformer.
ba ký tự
N-gram trong đó N=3.
U
một chiều
Một hệ thống chỉ đánh giá văn bản trước một phần văn bản mục tiêu. Ngược lại, hệ thống hai chiều đánh giá cả văn bản trước và sau một phần văn bản mục tiêu. Hãy xem phần hai chiều để biết thêm chi tiết.
mô hình ngôn ngữ một chiều
Mô hình ngôn ngữ chỉ dựa trên xác suất của các mã thông báo xuất hiện trước, chứ không phải sau, (các) mã thông báo mục tiêu. Tương phản với mô hình ngôn ngữ hai chiều.
V
bộ tự động mã hoá biến thiên (VAE)
Một loại tự động mã hoá tận dụng sự khác biệt giữa dữ liệu đầu vào và đầu ra để tạo các phiên bản sửa đổi của dữ liệu đầu vào. Bộ tự mã hoá biến thiên rất hữu ích cho AI tạo sinh.
VAE dựa trên suy luận biến thiên: một kỹ thuật để ước tính các tham số của mô hình xác suất.
W
nhúng từ
Đại diện cho từng từ trong một tập hợp từ trong một vectơ nhúng; tức là đại diện cho từng từ dưới dạng một vectơ gồm các giá trị dấu phẩy động từ 0 đến 1. Những từ có nghĩa tương tự sẽ có cách biểu thị tương tự hơn so với những từ có nghĩa khác nhau. Ví dụ: cà rốt, rau cần tây và dưa chuột đều có cách thể hiện tương đối giống nhau, rất khác với cách thể hiện máy bay, kính râm và kem đánh răng.
Z
đặt câu lệnh dựa trên không có ví dụ
Lệnh gọi không cung cấp ví dụ về cách bạn muốn mô hình ngôn ngữ lớn phản hồi. Ví dụ:
| Các phần của một câu lệnh | Ghi chú |
|---|---|
| Đơn vị tiền tệ chính thức của quốc gia đã chỉ định là gì? | Câu hỏi mà bạn muốn LLM trả lời. |
| Ấn Độ: | Cụm từ tìm kiếm thực tế. |
Mô hình ngôn ngữ lớn có thể trả lời bằng bất kỳ nội dung nào sau đây:
- Rupee
- INR
- ₹
- Đồng rupi Ấn Độ
- Rupee
- Đồng rupi Ấn Độ
Tất cả các câu trả lời đều đúng, mặc dù bạn có thể muốn một định dạng cụ thể.
So sánh và đối chiếu lệnh nhắc không có ví dụ với các thuật ngữ sau: