Một công nghệ mới hơn, mô hình ngôn ngữ lớn (LLM) dự đoán một mã thông báo hoặc chuỗi mã thông báo, đôi khi là nhiều đoạn văn bản có giá trị mã thông báo được dự đoán. Hãy nhớ rằng mã thông báo có thể là một từ, một từ phụ (một tập hợp con của một từ) hoặc thậm chí là một ký tự đơn. LLM dự đoán chính xác hơn nhiều so với mô hình ngôn ngữ N-gram hoặc mạng nơ-ron hồi quy vì:
- LLM chứa nhiều tham số hơn so với các mô hình lặp lại.
- LLM thu thập nhiều ngữ cảnh hơn.
Phần này giới thiệu kiến trúc thành công và được sử dụng rộng rãi nhất để xây dựng LLM: Transformer.
Transformer là gì?
Mô hình Transformer là kiến trúc hiện đại cho nhiều ứng dụng mô hình ngôn ngữ, chẳng hạn như dịch:

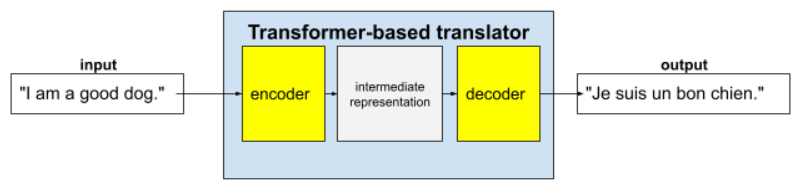
Transformer đầy đủ bao gồm một bộ mã hoá và một bộ giải mã:
- Bộ mã hoá chuyển đổi văn bản đầu vào thành một biểu diễn trung gian. Bộ mã hoá là một mạng nơron khổng lồ.
- Bộ giải mã sẽ chuyển đổi biểu thức trung gian đó thành văn bản hữu ích. Bộ giải mã cũng là một mạng nơ-ron khổng lồ.
Ví dụ: trong một trình dịch:
- Bộ mã hoá xử lý văn bản đầu vào (ví dụ: một câu tiếng Anh) thành một số biểu diễn trung gian.
- Bộ giải mã sẽ chuyển đổi biểu thị trung gian đó thành văn bản đầu ra (ví dụ: câu tiếng Pháp tương đương).
Cơ chế tự chú ý là gì?
Để tăng cường ngữ cảnh, Transformer dựa nhiều vào một khái niệm gọi là cơ chế tự chú ý. Về cơ bản, thay mặt cho mỗi mã thông báo đầu vào, cơ chế tự chú ý sẽ đặt câu hỏi sau:
"Mỗi mã thông báo đầu vào khác ảnh hưởng như thế nào đến việc diễn giải mã thông báo này?"
"Tự" trong "cơ chế tự chú ý" đề cập đến chuỗi đầu vào. Một số cơ chế chú ý cân nhắc mối quan hệ giữa các mã thông báo đầu vào với các mã thông báo trong một chuỗi đầu ra (chẳng hạn như bản dịch) hoặc với các mã thông báo trong một số chuỗi khác. Nhưng cơ chế chú ý tự chỉ đánh giá tầm quan trọng của mối quan hệ giữa các mã thông báo trong chuỗi đầu vào.
Để đơn giản hoá vấn đề, hãy giả sử rằng mỗi mã thông báo là một từ và ngữ cảnh hoàn chỉnh chỉ là một câu. Hãy xem xét câu sau:
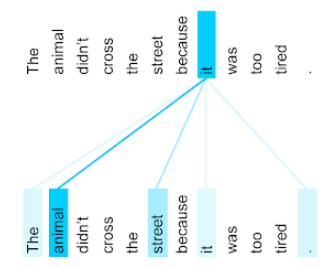
The animal didn't cross the street because it was too tired.
Câu trước đó có 11 từ. Mỗi từ trong số 11 từ này đều chú ý đến 10 từ còn lại, tự hỏi mức độ quan trọng của mỗi từ trong số 10 từ đó đối với chính nó. Ví dụ: hãy lưu ý rằng câu này có chứa đại từ it (nó). Đại từ thường không rõ ràng. Đại từ it thường đề cập đến một danh từ hoặc cụm danh từ gần đây, nhưng trong câu ví dụ, it đề cập đến danh từ gần đây nào – con vật hay đường phố?
Cơ chế tự chú ý xác định mức độ liên quan của mỗi từ lân cận với đại từ nó. Hình 3 cho thấy kết quả – đường càng xanh, từ đó càng quan trọng đối với đại từ it (nó). Tức là animal (động vật) quan trọng hơn street (đường phố) đối với đại từ it (nó).
Ngược lại, giả sử từ cuối cùng trong câu thay đổi như sau:
The animal didn't cross the street because it was too wide.
Trong câu đã sửa đổi này, cơ chế tự chú ý hy vọng sẽ đánh giá đường phố là phù hợp hơn động vật đối với đại từ nó.
Một số cơ chế tự chú ý là hai chiều, nghĩa là chúng tính toán điểm số mức độ liên quan cho các mã thông báo trước và sau từ đang được chú ý. Ví dụ: trong Hình 3, hãy lưu ý rằng các từ ở cả hai bên của it đều được kiểm tra. Vì vậy, cơ chế tự chú ý hai chiều có thể thu thập ngữ cảnh từ các từ ở hai bên của từ đang được chú ý. Ngược lại, cơ chế tự chú ý một chiều chỉ có thể thu thập ngữ cảnh từ các từ ở một phía của từ đang được chú ý. Cơ chế tự chú ý hai chiều đặc biệt hữu ích để tạo biểu diễn cho toàn bộ chuỗi, trong khi các ứng dụng tạo chuỗi theo từng mã thông báo yêu cầu cơ chế tự chú ý một chiều. Vì lý do này, bộ mã hoá sử dụng cơ chế tự chú ý hai chiều, trong khi bộ giải mã sử dụng cơ chế một chiều.
Cơ chế tự chú ý nhiều lớp và nhiều đầu là gì?
Mỗi lớp cơ chế tự chú ý thường bao gồm nhiều đầu cơ chế tự chú ý. Đầu ra của một lớp là một phép toán (ví dụ: trung bình có trọng số hoặc tích vô hướng) của đầu ra của các đầu khác nhau.
Vì các tham số của mỗi tiêu đề được khởi tạo thành các giá trị ngẫu nhiên, nên các tiêu đề khác nhau có thể tìm hiểu các mối quan hệ khác nhau giữa mỗi từ được chú ý và các từ lân cận. Ví dụ: đầu cơ chế tự chú ý được mô tả trong phần trước tập trung vào việc xác định danh từ mà đại từ it đề cập đến. Tuy nhiên, các đầu tự chú ý khác trong cùng một lớp có thể tìm hiểu mức độ liên quan về ngữ pháp của từng từ với mọi từ khác hoặc tìm hiểu các tương tác khác.
Một mô hình biến đổi hoàn chỉnh sẽ xếp nhiều lớp tự chú ý chồng lên nhau. Đầu ra của lớp trước sẽ trở thành đầu vào cho lớp tiếp theo. Việc xếp chồng này cho phép mô hình xây dựng các kiến thức ngày càng phức tạp và trừu tượng hơn về văn bản. Mặc dù các lớp trước đó có thể tập trung vào cú pháp cơ bản, nhưng các lớp sâu hơn có thể tích hợp thông tin đó để nắm bắt các khái niệm tinh tế hơn như tình cảm, bối cảnh và các mối liên kết theo chủ đề trên toàn bộ dữ liệu đầu vào.
Tại sao Transformers lại có kích thước lớn như vậy?
Mô hình Transformer chứa hàng trăm tỷ hoặc thậm chí hàng nghìn tỷ tham số. Khoá học này thường đề xuất xây dựng các mô hình có ít tham số hơn so với các mô hình có nhiều tham số hơn. Sau cùng, một mô hình có số lượng tham số nhỏ hơn sẽ sử dụng ít tài nguyên hơn để đưa ra dự đoán so với một mô hình có số lượng tham số lớn hơn. Tuy nhiên, nghiên cứu cho thấy rằng Transformer có nhiều tham số hơn luôn hoạt động hiệu quả hơn Transformer có ít tham số hơn.
Nhưng làm cách nào để một LLM tạo văn bản?
Bạn đã thấy cách các nhà nghiên cứu huấn luyện LLM để dự đoán một hoặc hai từ bị thiếu và có thể bạn không mấy ấn tượng. Sau tất cả, việc dự đoán một hoặc hai từ về cơ bản là tính năng tự động hoàn thành được tích hợp trong nhiều phần mềm văn bản, email và soạn thảo. Có lẽ bạn đang thắc mắc làm thế nào các LLM có thể tạo ra các câu, đoạn văn hoặc bài thơ haiku về hoạt động kinh doanh chênh lệch giá.
Trên thực tế, LLM về cơ bản là cơ chế tự động hoàn thành có thể tự động dự đoán (hoàn thành) hàng nghìn mã thông báo. Ví dụ: hãy xem xét một câu theo sau là một câu bị che:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
LLM có thể tạo ra xác suất cho câu bị che, bao gồm:
| Xác suất | Từ |
|---|---|
| 3,1% | Ví dụ: chú cún có thể ngồi, nằm yên và lật người. |
| 2,9% | Ví dụ: chú cún biết cách ngồi, nằm yên và lật người. |
Một LLM đủ lớn có thể tạo ra xác suất cho các đoạn văn và toàn bộ bài luận. Bạn có thể coi câu hỏi của người dùng đối với một LLM là câu "đã cho" theo sau là một mặt nạ tưởng tượng. Ví dụ:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
LLM tạo ra xác suất cho nhiều câu trả lời có thể có.
Một ví dụ khác là LLM được huấn luyện trên một số lượng lớn "bài toán có lời văn" có thể cho thấy khả năng suy luận toán học phức tạp. Tuy nhiên, về cơ bản, các LLM đó chỉ tự động hoàn thành một câu hỏi toán học.
Lợi ích của LLM
LLM có thể tạo văn bản rõ ràng, dễ hiểu cho nhiều đối tượng mục tiêu. LLM có thể dự đoán các nhiệm vụ mà chúng được huấn luyện một cách rõ ràng. Một số nhà nghiên cứu cho rằng LLM cũng có thể đưa ra dự đoán cho dữ liệu đầu vào mà chúng không được huấn luyện một cách rõ ràng, nhưng những nhà nghiên cứu khác đã bác bỏ tuyên bố này.
Vấn đề với các LLM
Huấn luyện một LLM sẽ gặp phải nhiều vấn đề, bao gồm:
- Thu thập một tập dữ liệu huấn luyện khổng lồ.
- Tiêu thụ nhiều tháng và nguồn tài nguyên điện toán khổng lồ và điện năng.
- Giải quyết các thách thức về tính song song.
Việc sử dụng LLM để suy luận dự đoán gây ra các vấn đề sau:
- LLM ảo tưởng, tức là các dự đoán của LLM thường chứa lỗi.
- Các LLM tiêu thụ một lượng lớn tài nguyên điện toán và điện năng. Việc huấn luyện LLM trên các tập dữ liệu lớn hơn thường làm giảm lượng tài nguyên cần thiết cho suy luận, mặc dù các tập huấn luyện lớn hơn sẽ tiêu tốn nhiều tài nguyên huấn luyện hơn.
- Giống như mọi mô hình học máy, LLM có thể thể hiện mọi loại thiên kiến.