Ta strona zawiera terminy z glosariusza danych. Aby wyświetlić wszystkie terminy z glosariusza, kliknij tutaj.
A
dokładność
Liczba prawidłowych prognoz klasyfikacji podzielona przez łączną liczbę prognoz. Czyli:
Na przykład model, który dokonał 40 prawidłowych i 10 nieprawidłowych prognoz, ma dokładność:
Klasyfikacja binarna podaje konkretne nazwy różnych kategorii prawidłowych prognoz i nieprawidłowych prognoz. Wzór na dokładność w przypadku klasyfikacji binarnej jest taki:
gdzie:
- TP to liczba wyników prawdziwie pozytywnych (poprawnych prognoz).
- TN to liczba wyników prawdziwie negatywnych (prawidłowych prognoz).
- FP to liczba fałszywie pozytywnych wyników (nieprawidłowych prognoz).
- FN to liczba wyników fałszywie negatywnych (nieprawidłowych prognoz).
Porównaj dokładność z precyzją i czułością.
Więcej informacji znajdziesz w sekcji Klasyfikacja: dokładność, czułość, precyzja i powiązane dane w kursie Machine Learning Crash Course.
obszar pod krzywą precyzji i czułości,
Zobacz PR AUC (obszar pod krzywą PR).
obszar pod krzywą charakterystyki operacyjnej odbiornika
Zobacz AUC (obszar pod krzywą ROC).
AUC (obszar pod krzywą ROC)
Liczba z zakresu od 0,0 do 1,0 reprezentująca zdolność modelu klasyfikacji binarnej do rozdzielania klas pozytywnych od klas negatywnych. Im bliżej wartości 1,0 jest AUC, tym lepiej model rozróżnia klasy.
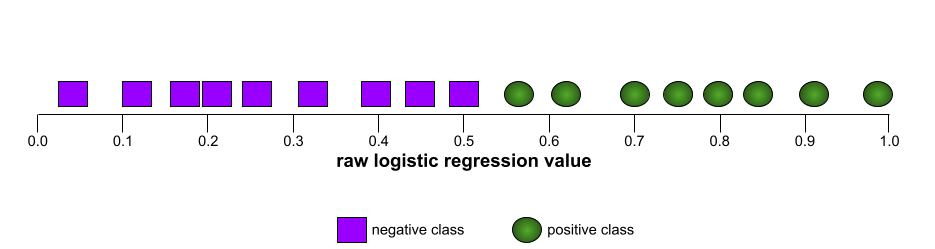
Na przykład poniższa ilustracja przedstawia model klasyfikacji, który doskonale rozdziela klasy pozytywne (zielone owale) od klas negatywnych (fioletowe prostokąty). Ten nierealistycznie doskonały model ma wartość AUC równą 1,0:

Z kolei poniższa ilustracja przedstawia wyniki modelu klasyfikacji, który generował losowe wyniki. Ten model ma wartość AUC 0,5:

Tak, poprzedni model ma wartość AUC 0,5, a nie 0,0.
Większość modeli znajduje się gdzieś pomiędzy tymi dwoma skrajnościami. Na przykład poniższy model w pewnym stopniu rozdziela wartości pozytywne od negatywnych, dlatego ma wartość AUC między 0,5 a 1,0:

AUC ignoruje każdą wartość ustawioną dla progu klasyfikacji. Zamiast tego AUC uwzględnia wszystkie możliwe progi klasyfikacji.
Kliknij ikonę, aby dowiedzieć się więcej o zależności między krzywymi AUC i ROC.
AUC to obszar pod krzywą ROC. Na przykład krzywa ROC modelu, który doskonale rozróżnia wyniki pozytywne od negatywnych, wygląda tak:
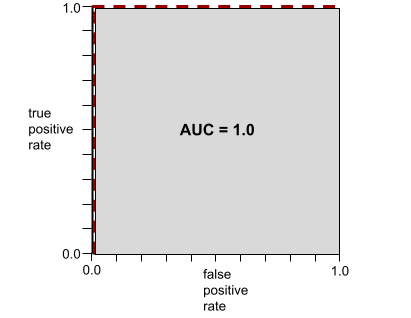
AUC to obszar szarego regionu na poprzedniej ilustracji. W tym nietypowym przypadku pole to po prostu długość szarego obszaru (1,0) pomnożona przez jego szerokość (1,0). Iloczyn 1,0 i 1,0 daje wartość AUC równą dokładnie 1,0, czyli najwyższy możliwy wynik AUC.
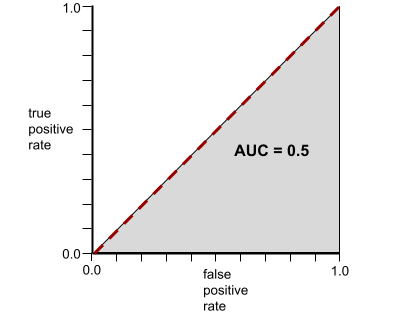
Z kolei krzywa ROC dla modelu klasyfikacji, który w ogóle nie potrafi rozróżniać klas, wygląda tak: Obszar tego szarego regionu wynosi 0,5.
Bardziej typowa krzywa ROC wygląda mniej więcej tak:
Ręczne obliczenie pola pod tą krzywą byłoby bardzo pracochłonne, dlatego większość wartości AUC jest zwykle obliczana przez program.
Więcej informacji znajdziesz w sekcji Klasyfikacja: ROC i AUC w szybkim szkoleniu z uczenia maszynowego.
średnia precyzja przy k
Miara podsumowująca skuteczność modelu w przypadku pojedynczego prompta, który generuje wyniki w postaci listy, np. listy rekomendacji książek. Średnia precyzja przy k to średnia wartości precyzji przy k dla każdego trafnego wyniku. Wzór na średnią precyzję przy k to:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
gdzie:
- \(n\) to liczba odpowiednich elementów na liście.
Porównaj z przypominaniem w momencie k.
B
bazowa
Model używany jako punkt odniesienia do porównywania skuteczności innego modelu (zwykle bardziej złożonego). Na przykład model regresji logistycznej może być dobrym modelem bazowym dla modelu głębokiego.
W przypadku konkretnego problemu wartość bazowa pomaga deweloperom modeli określić minimalną oczekiwaną skuteczność, jaką musi osiągnąć nowy model, aby był przydatny.
Pytania logiczne (BoolQ)
Zbiór danych do oceny umiejętności modelu LLM w zakresie odpowiadania na pytania, na które można odpowiedzieć „tak” lub „nie”. Każde wyzwanie w zbiorze danych składa się z 3 elementów:
- zapytanie,
- Fragment zawierający odpowiedź na zapytanie.
- Prawidłowa odpowiedź, czyli tak lub nie.
Na przykład:
- Zapytanie: czy w stanie Michigan są jakieś elektrownie atomowe?
- Fragment: …trzy elektrownie jądrowe dostarczają do Michigan około 30% energii elektrycznej.
- Prawidłowa odpowiedź: tak
Badacze zebrali pytania z zanonimizowanych i zagregowanych zapytań w wyszukiwarce Google, a następnie wykorzystali strony Wikipedii, aby potwierdzić informacje.
Więcej informacji znajdziesz w artykule BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions (w języku angielskim).
BoolQ to komponent zestawu SuperGLUE.
BoolQ
Skrót od Boolean Questions (pytania logiczne).
C
CB
Skrót od CommitmentBank.
Wynik F1 dla n-gramów znakowych (ChrF)
Wskaźnik służący do oceny modeli tłumaczenia maszynowego. Wynik F-score dla N-gramów znakowych określa stopień, w jakim N-gramy w tekście referencyjnym pokrywają się z N-gramami w wygenerowanym tekście modelu ML.
Wskaźnik F znaków N-gramów jest podobny do wskaźników z rodzin ROUGE i BLEU, z tą różnicą, że:
- Wynik F-score n-gramów znakowych działa na znakowych n-gramach.
- ROUGE i BLEU działają na słowach w postaci n-gramów lub tokenów.
Wybór wiarygodnych alternatyw (COPA)
Zbiór danych do oceny, jak dobrze model LLM potrafi wskazać lepszą z 2 alternatywnych odpowiedzi na założenie. Każde wyzwanie w zbiorze danych składa się z 3 elementów:
- założenie, które zwykle jest stwierdzeniem, po którym następuje pytanie;
- Dwie możliwe odpowiedzi na pytanie postawione w założeniu, z których jedna jest prawidłowa, a druga nieprawidłowa.
- Poprawna odpowiedź
Na przykład:
- Założenie: mężczyzna złamał palec u nogi. Jaka była tego PRZYCZYNA?
- Możliwe odpowiedzi:
- Zrobiła mu się dziura w skarpetce.
- Upuścił młotek na stopę.
- Prawidłowa odpowiedź: 2
COPA jest komponentem zespołu SuperGLUE.
CommitmentBank (CB)
Zbiór danych do oceny umiejętności modelu LLM w określaniu, czy autor fragmentu tekstu wierzy w zdanie docelowe w tym fragmencie. Każdy wpis w zbiorze danych zawiera:
- fragment,
- klauzula docelowa w tym fragmencie,
- Wartość logiczna wskazująca, czy autor fragmentu uważa, że klauzula docelowa
Na przykład:
- Fragment: Jak miło było usłyszeć śmiech Artemidy. Jest bardzo poważnym dzieckiem. Nie wiedziałem, że ma poczucie humoru.
- Klauzula docelowa: she had a sense of humor
- Wartość logiczna: Prawda, co oznacza, że autor uważa, że klauzula docelowa
CommitmentBank jest komponentem zestawu SuperGLUE.
COPA
Skrót od Choice of Plausible Alternatives.
koszt
Synonim słowa strata.
obiektywność kontrfaktyczna,
Miara sprawiedliwości, która sprawdza, czy model klasyfikacji daje ten sam wynik w przypadku 2 osób, z których jedna jest identyczna z drugą, z wyjątkiem co najmniej jednego atrybutu chronionego. Ocena modelu klasyfikacji pod kątem obiektywności kontrfaktycznej to jedna z metod wykrywania potencjalnych źródeł uprzedzeń w modelu.
Więcej informacji znajdziesz w tych artykułach:
- Sprawiedliwość: sprawiedliwość kontrfaktyczna w szybkim szkoleniu z uczenia maszynowego.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness
entropia krzyżowa
Uogólnienie funkcji straty logarytmicznej na problemy z klasyfikacją wieloklasową. Entropia krzyżowa określa różnicę między dwoma rozkładami prawdopodobieństwa. Zobacz też perplexity.
dystrybuanta
Funkcja, która określa częstotliwość próbek mniejszą lub równą wartości docelowej. Rozważmy na przykład rozkład normalny wartości ciągłych. Dystrybuanta informuje, że około 50% próbek powinno być mniejszych lub równych średniej, a około 84% próbek powinno być mniejszych lub równych odchyleniu standardowemu powyżej średniej.
D
parytet demograficzny
Metryka sprawiedliwości, która jest spełniona, jeśli wyniki klasyfikacji modelu nie zależą od danego atrybutu wrażliwego.
Jeśli na przykład zarówno Liliputanie, jak i Brobdingnagianie ubiegają się o przyjęcie na Uniwersytet Glubbdubdrib, równość demograficzna jest osiągana, gdy odsetek przyjętych Liliputanów jest taki sam jak odsetek przyjętych Brobdingnagian, niezależnie od tego, czy jedna grupa jest średnio bardziej wykwalifikowana od drugiej.
Kontrastuje to z wyrównanymi szansami i równością szans, które dopuszczają, aby wyniki klasyfikacji w agregacji zależały od atrybutów wrażliwych, ale nie dopuszczają, aby wyniki klasyfikacji dla określonych etykiet prawdziwych danych zależały od atrybutów wrażliwych. Więcej informacji znajdziesz w artykule „Walka z dyskryminacją za pomocą inteligentniejszych systemów uczących się”, w którym znajdziesz wizualizację przedstawiającą kompromisy przy optymalizacji pod kątem równości demograficznej.
Więcej informacji znajdziesz w sekcji Sprawiedliwość: równość demograficzna w szybkim szkoleniu z uczenia maszynowego.
E
odległość przeniesienia ziemi (EMD)
Miara względnego podobieństwa dwóch rozkładów. Im mniejsza odległość między rozkładami, tym są one bardziej podobne.
odległość edycji,
Miara podobieństwa dwóch ciągów tekstowych. W uczeniu maszynowym odległość edycji jest przydatna z tych powodów:
- Odległość edycji jest łatwa do obliczenia.
- Odległość edycji może porównywać 2 ciągi znaków, o których wiadomo, że są do siebie podobne.
- Odległość edycji może określać stopień podobieństwa różnych ciągów znaków do danego ciągu.
Istnieje kilka definicji odległości edycji, z których każda wykorzystuje inne operacje na ciągach znaków. Przykład znajdziesz w artykule Odległość Levenshteina.
empiryczna dystrybuanta (eCDF lub EDF)
Dystrybuanta na podstawie pomiarów empirycznych z rzeczywistego zbioru danych. Wartość funkcji w dowolnym punkcie osi X to ułamek obserwacji w zbiorze danych, które są mniejsze lub równe określonej wartości.
entropia
W teorii informacji jest to opis tego, jak nieprzewidywalny jest rozkład prawdopodobieństwa. Entropia jest też definiowana jako ilość informacji zawartych w każdym przykładzie. Rozkład ma najwyższą możliwą entropię, gdy wszystkie wartości zmiennej losowej są jednakowo prawdopodobne.
Entropia zbioru z 2 możliwymi wartościami „0” i „1” (np. etykietami w problemie klasyfikacji binarnej) ma następujący wzór:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
gdzie:
- H to entropia.
- p to ułamek przykładów „1”.
- q to ułamek przykładów „0”. Pamiętaj, że q = (1 – p).
- log to zwykle log2. W tym przypadku jednostką entropii jest bit.
Załóżmy na przykład, że:
- 100 przykładów zawiera wartość „1”
- 300 przykładów zawiera wartość „0”
Wartość entropii wynosi więc:
- p = 0,25
- q = 0,75
- H = (-0,25)log2(0,25) - (0,75)log2(0,75) = 0,81 bita na przykład
Zbiór, który jest doskonale zrównoważony (np.200 zer i 200 jedynek), ma entropię 1,0 bita na przykład. W miarę jak zbiór staje się bardziej niezrównoważony, jego entropia zbliża się do 0,0.
W drzewach decyzyjnych entropia pomaga formułować przyrost informacji, aby rozdzielacz mógł wybierać warunki podczas tworzenia drzewa decyzyjnego klasyfikacji.
Porównaj entropię z:
- zanieczyszczenie Giniego
- funkcja straty entropii krzyżowej,
Entropia jest często nazywana entropią Shannona.
Więcej informacji znajdziesz w sekcji Exact splitter for binary classification with numerical features (Dokładny rozdzielacz do klasyfikacji binarnej z cechami numerycznymi) w kursie Decision Forests.
równość szans,
Miara sprawiedliwości, która pozwala ocenić, czy model prognozuje pożądany wynik równie dobrze dla wszystkich wartości wrażliwego atrybutu. Inaczej mówiąc, jeśli pożądanym wynikiem modelu jest klasa pozytywna, celem jest uzyskanie takiej samej liczby prawdziwie pozytywnych wyników we wszystkich grupach.
Równość szans jest związana z wyrównaniem szans, co wymaga, aby zarówno współczynniki wyników prawdziwie pozytywnych, jak i współczynniki wyników fałszywie pozytywnych były takie same dla wszystkich grup.
Załóżmy, że Uniwersytet Glubbdubdrib przyjmuje zarówno Liliputów, jak i Brobdingnagów na wymagający program matematyczny. Szkoły średnie w Lilliput oferują rozbudowany program nauczania matematyki, a większość uczniów kwalifikuje się do programu uniwersyteckiego. W szkołach średnich w Brobdingnagu nie ma zajęć z matematyki, więc znacznie mniej uczniów ma odpowiednie kwalifikacje. Równość szans jest zachowana w przypadku preferowanej etykiety „przyjęty” w odniesieniu do narodowości (Liliput lub Brobdingnag), jeśli kwalifikujący się uczniowie mają takie samo prawdopodobieństwo przyjęcia niezależnie od tego, czy są Liliputami, czy Brobdingnagami.
Załóżmy na przykład, że na Uniwersytet Glubbdubdrib zgłasza się 100 Liliputów i 100 Brobdingnagów, a decyzje o przyjęciu są podejmowane w ten sposób:
Tabela 1. Kandydaci z Lilliput (90% z nich spełnia wymagania)
| Zakwalifikowany | Niezakwalifikowany | |
|---|---|---|
| Admitted | 45 | 3 |
| Odrzucono | 45 | 7 |
| Łącznie | 90 | 10 |
|
Odsetek przyjętych uczniów spełniających kryteria: 45/90 = 50% Odsetek odrzuconych uczniów niespełniających kryteriów: 7/10 = 70% Łączny odsetek przyjętych uczniów z Lilliputu: (45+3)/100 = 48% |
||
Tabela 2. Kandydaci z Brobdingnagu (10% – kwalifikujący się):
| Zakwalifikowany | Niezakwalifikowany | |
|---|---|---|
| Admitted | 5 | 9 |
| Odrzucono | 5 | 81 |
| Łącznie | 10 | 90 |
|
Odsetek przyjętych uczniów spełniających kryteria: 5/10 = 50% Odsetek odrzuconych uczniów niespełniających kryteriów: 81/90 = 90% Łączny odsetek przyjętych uczniów z Brobdingnagu: (5+9)/100 = 14% |
||
Powyższe przykłady spełniają warunek równości szans w zakresie przyjęcia wykwalifikowanych uczniów, ponieważ wykwalifikowani Liliputanie i Brobdingnagianie mają 50% szans na przyjęcie.
Chociaż równość szans jest spełniona, te 2 kryteria obiektywności nie są spełnione:
- równość demograficzna: Liliputanie i Brobdingnagianie są przyjmowani na uniwersytet w różnym tempie: 48% Liliputanów i tylko 14% Brobdingnagianów.
- Równe szanse: chociaż kwalifikujący się uczniowie z Lilliputu i Brobdingnagu mają takie same szanse na przyjęcie, dodatkowe ograniczenie, że niekwalifikujący się uczniowie z Lilliputu i Brobdingnagu mają takie same szanse na odrzucenie, nie jest spełnione. W przypadku osób niekwalifikujących się do kategorii Liliputów odsetek odrzuceń wynosi 70%, a w przypadku osób niekwalifikujących się do kategorii Brobdingnagów – 90%.
Więcej informacji znajdziesz w module Sprawiedliwość: równość szans w kursie Machine Learning Crash Course.
wyrównane szanse
Wskaźnik sprawiedliwości, który pozwala ocenić, czy model prognozuje wyniki równie dobrze dla wszystkich wartości wrażliwego atrybutu w odniesieniu do klasy pozytywnej i klasy negatywnej, a nie tylko jednej z nich. Innymi słowy, zarówno współczynnik wyników prawdziwie dodatnich, jak i współczynnik wyników fałszywie ujemnych powinny być takie same w przypadku wszystkich grup.
Wyrównane szanse są powiązane z równością szans, która koncentruje się tylko na odsetku błędów w przypadku jednej klasy (pozytywnej lub negatywnej).
Załóżmy na przykład, że Uniwersytet Glubbdubdrib przyjmuje do wymagającego programu matematycznego zarówno Liliputów, jak i Brobdingnagów. Szkoły średnie w Lillipucie oferują bogaty program nauczania matematyki, a większość uczniów kwalifikuje się do programu uniwersyteckiego. W szkołach średnich w Brobdingnagu nie ma zajęć z matematyki, więc znacznie mniej uczniów ma odpowiednie kwalifikacje. Warunek wyrównanych szans jest spełniony, jeśli niezależnie od tego, czy kandydat jest Liliputem, czy Brobdingnagiem, jeśli spełnia wymagania, ma takie samo prawdopodobieństwo przyjęcia do programu, a jeśli nie spełnia wymagań, ma takie samo prawdopodobieństwo odrzucenia.
Załóżmy, że 100 Liliputów i 100 Brobdingnagów zgłasza się na Uniwersytet Glubbdubdrib, a decyzje o przyjęciu są podejmowane w ten sposób:
Tabela 3. Kandydaci z Lilliput (90% z nich spełnia wymagania)
| Zakwalifikowany | Niezakwalifikowany | |
|---|---|---|
| Admitted | 45 | 2 |
| Odrzucono | 45 | 8 |
| Łącznie | 90 | 10 |
|
Odsetek przyjętych uczniów spełniających kryteria: 45/90 = 50% Odsetek odrzuconych uczniów niespełniających kryteriów: 8/10 = 80% Łączny odsetek przyjętych uczniów z Lilliputu: (45+2)/100 = 47% |
||
Tabela 4. Kandydaci z Brobdingnagu (10% – kwalifikujący się):
| Zakwalifikowany | Niezakwalifikowany | |
|---|---|---|
| Admitted | 5 | 18 |
| Odrzucono | 5 | 72 |
| Łącznie | 10 | 90 |
|
Odsetek przyjętych uczniów spełniających kryteria: 5/10 = 50% Odsetek odrzuconych uczniów niespełniających kryteriów: 72/90 = 80% Łączny odsetek przyjętych uczniów z Brobdingnagu: (5+18)/100 = 23% |
||
Warunek wyrównanych szans jest spełniony, ponieważ zakwalifikowani studenci z Lilliputu i Brobdingnagu mają 50% szans na przyjęcie, a niezakwalifikowani studenci z Lilliputu i Brobdingnagu mają 80% szans na odrzucenie.
Wyrównane szanse są formalnie zdefiniowane w artykule „Equality of Opportunity in Supervised Learning” w ten sposób: „predyktor Ŷ spełnia warunek wyrównanych szans w odniesieniu do atrybutu chronionego A i wyniku Y, jeśli Ŷ i A są niezależne pod warunkiem Y”.
oceny
Używany głównie jako skrót od ocen modeli LLM. Ogólnie rzecz biorąc, oceny to skrót od dowolnej formy oceny.
ocena
Proces pomiaru jakości modelu lub porównywania różnych modeli ze sobą.
Aby ocenić nadzorowany model uczenia maszynowego, zwykle porównujesz go ze zbiorem walidacyjnym i zbiorem testowym. Ocena LLM zwykle obejmuje szersze oceny jakości i bezpieczeństwa.
dopasowanie dokładne
Wskaźnik typu „wszystko albo nic”, w którym dane wyjściowe modelu są zgodne z danymi podstawowymi lub tekstem referencyjnym albo nie są. Jeśli np. odpowiedź oparta na danych podstawowych to pomarańczowy, jedynym wynikiem modelu, który spełnia kryterium dopasowania ścisłego, jest pomarańczowy.
Dopasowanie ścisłe może też oceniać modele, których dane wyjściowe są sekwencją (listą elementów z określonymi pozycjami). Ogólnie rzecz biorąc, dopasowanie ścisłe wymaga, aby wygenerowana lista rankingowa dokładnie odpowiadała rzeczywistości, tzn. każdy element na obu listach musi być w tej samej kolejności. Jeśli jednak dane referencyjne składają się z wielu prawidłowych sekwencji, dopasowanie ścisłe wymaga, aby dane wyjściowe modelu pasowały do jednej z nich.
Podsumowywanie ekstremalne (xsum)
Zbiór danych do oceny zdolności LLM do podsumowywania pojedynczego dokumentu. Każdy wpis w zbiorze danych składa się z tych elementów:
- Dokument autorstwa British Broadcasting Corporation (BBC).
- Podsumowanie dokumentu w jednym zdaniu.
Więcej informacji znajdziesz w artykule Nie podawaj szczegółów, tylko podsumowanie! Topic-Aware Convolutional Neural Networks for Extreme Summarization.
P
F1
„Złożony” wskaźnik klasyfikacji binarnej, który zależy zarówno od precyzji, jak i od czułości. Oto wzór:
wskaźnik obiektywności,
Matematyczna definicja „obiektywności”, którą można zmierzyć. Do często używanych wskaźników sprawiedliwości należą:
Wiele wskaźników obiektywności wzajemnie się wyklucza. Więcej informacji znajdziesz w sekcji Brak spójnych wskaźników obiektywności.
wynik fałszywie negatywny (FN),
Przykład, w którym model błędnie przewiduje klasę negatywną. Na przykład model przewiduje, że dana wiadomość e-mail nie jest spamem (klasa negatywna), ale w rzeczywistości jest spamem.
współczynnik wyników fałszywie negatywnych,
Odsetek rzeczywistych przykładów pozytywnych, dla których model błędnie przewidział klasę negatywną. Współczynnik fałszywie negatywnych wyników oblicza się według tego wzoru:
Więcej informacji znajdziesz w sekcji Progi i macierz pomyłek w szybkim szkoleniu z uczenia maszynowego.
wynik fałszywie pozytywny (FP),
Przykład, w którym model błędnie przewiduje klasę pozytywną. Na przykład model przewiduje, że dana wiadomość e-mail to spam (klasa pozytywna), ale w rzeczywistości nie jest to spam.
Więcej informacji znajdziesz w sekcji Progi i macierz pomyłek w szybkim szkoleniu z uczenia maszynowego.
współczynnik wyników fałszywie pozytywnych (FPR),
Odsetek rzeczywistych przykładów negatywnych, dla których model błędnie przewidział klasę pozytywną. Współczynnik fałszywie dodatnich wyników oblicza się według tego wzoru:
Współczynnik wyników fałszywie pozytywnych jest osią X na krzywej ROC.
Więcej informacji znajdziesz w sekcji Klasyfikacja: ROC i AUC w szybkim szkoleniu z uczenia maszynowego.
znaczenie cech,
Synonim terminu znaczenie zmiennych.
model podstawowy
Bardzo duży wytrenowany model, który został wytrenowany na ogromnym i zróżnicowanym zbiorze treningowym. Model podstawowy może wykonywać obie te czynności:
- dobrze reagować na szeroki zakres żądań,
- Służyć jako model podstawowy do dodatkowego dostrajania lub innego dostosowywania.
Innymi słowy, model podstawowy jest już bardzo przydatny w ogólnym sensie, ale można go dodatkowo dostosować, aby był jeszcze bardziej przydatny w konkretnym zadaniu.
odsetek sukcesów
Dane do oceny wygenerowanego tekstu przez model ML. Ułamek sukcesów to liczba „udanych” wygenerowanych wyników tekstowych podzielona przez łączną liczbę wygenerowanych wyników tekstowych. Jeśli na przykład duży model językowy wygenerował 10 bloków kodu, z których 5 działało prawidłowo, odsetek udanych prób wyniesie 50%.
Chociaż odsetek sukcesów jest ogólnie przydatny w statystyce, w uczeniu maszynowym ten wskaźnik jest przydatny głównie do pomiaru zadań weryfikowalnych, takich jak generowanie kodu lub rozwiązywanie problemów matematycznych.
G
zanieczyszczenie Giniego,
Dane podobne do entropii. Rozdzielacze używają wartości pochodzących z nieczystości Giniego lub entropii do tworzenia warunków klasyfikacji drzew decyzyjnych. Przyrost informacji jest obliczany na podstawie entropii. Nie ma powszechnie akceptowanego odpowiednika terminu dla danych pochodzących z nieczystości Giniego, ale te nienazwane dane są równie ważne jak przyrost informacji.
Zanieczyszczenie Giniego jest też nazywane wskaźnikiem Giniego lub po prostu gini.
H
funkcja straty hinge
Rodzina funkcji strat do klasyfikacji, która ma na celu znalezienie granicy decyzyjnej jak najdalej od każdego przykładu treningowego, co maksymalizuje margines między przykładami a granicą. KSVM używają funkcji straty zawiasowej (lub powiązanej funkcji, np. kwadratowej funkcji straty zawiasowej). W przypadku klasyfikacji binarnej funkcja straty zawiasowej jest zdefiniowana w ten sposób:
gdzie y to prawdziwa etykieta, czyli -1 lub +1, a y' to surowe dane wyjściowe modelu klasyfikacji:
W związku z tym wykres funkcji straty zawiasowej w zależności od (y * y') wygląda tak:

I
brak spójnych wskaźników obiektywności,
Koncepcja, że niektóre pojęcia obiektywności są wzajemnie niekompatybilne i nie można ich spełnić jednocześnie. Dlatego nie ma jednego uniwersalnego wskaźnika, który można by zastosować do wszystkich problemów związanych z uczeniem maszynowym.
Może to zniechęcać, ale brak spójnych wskaźników obiektywności nie oznacza, że działania na rzecz obiektywności są bezcelowe. Zamiast tego sugeruje, że obiektywność musi być definiowana w kontekście danego problemu ML, aby zapobiegać szkodom związanym z jego przypadkami użycia.
Więcej informacji o braku spójnych wskaźników obiektywności znajdziesz w artykule „(Nie)możliwość obiektywności”.
sprawiedliwość indywidualna,
Miara sprawiedliwości, która sprawdza, czy podobne osoby są klasyfikowane w podobny sposób. Na przykład Akademia Brobdingnagian może chcieć zapewnić sprawiedliwość indywidualną, dbając o to, aby dwóch uczniów z identycznymi ocenami i wynikami testów standaryzowanych miało takie same szanse na przyjęcie.
Pamiętaj, że sprawiedliwość indywidualna zależy całkowicie od tego, jak zdefiniujesz „podobieństwo” (w tym przypadku oceny i wyniki testów). Jeśli Twoje dane dotyczące podobieństwa nie uwzględniają ważnych informacji (np. poziomu trudności programu nauczania), możesz wprowadzić nowe problemy związane ze sprawiedliwością.
Więcej informacji o sprawiedliwości indywidualnej znajdziesz w artykule „Fairness Through Awareness”.
przyrost informacji
W lasach decyzyjnych różnica między entropią węzła a ważoną (według liczby przykładów) sumą entropii jego węzłów podrzędnych. Entropia węzła to entropia przykładów w tym węźle.
Rozważmy na przykład te wartości entropii:
- entropia węzła nadrzędnego = 0,6
- entropia jednego węzła podrzędnego z 16 odpowiednimi przykładami = 0,2.
- entropia innego węzła podrzędnego z 24 odpowiednimi przykładami = 0,1.
40% przykładów znajduje się w jednym węźle podrzędnym, a 60% – w drugim. Dlatego:
- ważona suma entropii węzłów podrzędnych = (0,4 * 0,2) + (0,6 * 0,1) = 0,14
Zysk informacji wynosi więc:
- przyrost informacji = entropia węzła nadrzędnego – ważona suma entropii węzłów podrzędnych.
- przyrost informacji = 0,6 – 0,14 = 0,46
Większość rozdzielaczy dąży do tworzenia warunków, które maksymalizują przyrost informacji.
zgodność ocen
Miara częstotliwości, z jaką weryfikatorzy zgadzają się ze sobą podczas wykonywania zadania. Jeśli oceniający nie zgadzają się ze sobą, może być konieczne ulepszenie instrukcji zadania. Czasami nazywana też zgodnością między oceniającymi lub wiarygodnością między oceniającymi. Zobacz też współczynnik kappa Cohena, który jest jednym z najpopularniejszych wskaźników zgodności ocen.
Więcej informacji znajdziesz w sekcji Dane kategorialne: typowe problemy w kursie Machine Learning Crash Course.
L
Utrata sygnału L1
Funkcja straty, która oblicza wartość bezwzględną różnicy między rzeczywistymi wartościami etykiet a wartościami przewidywanymi przez model. Na przykład poniżej przedstawiamy obliczenia utraty L1 dla partii 5 przykładów:
| Rzeczywista wartość przykładu | Wartość prognozowana przez model | Wartość bezwzględna różnicy |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = utrata L1 | ||
Funkcja straty L1 jest mniej wrażliwa na wartości odstające niż funkcja straty L2.
Średni błąd bezwzględny to średnia strata L1 na przykład.
Więcej informacji znajdziesz w sekcji Regresja liniowa: funkcja straty w kursie Machine Learning Crash Course.
Funkcja straty L2
Funkcja straty, która oblicza kwadrat różnicy między rzeczywistymi wartościami etykiet a wartościami przewidywanymi przez model. Oto przykład obliczania straty L2 dla partii pięciu przykładów:
| Rzeczywista wartość przykładu | Wartość prognozowana przez model | Kwadrat delty |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = przegrana L2 | ||
Ze względu na podnoszenie do kwadratu funkcja straty L2 wzmacnia wpływ wartości odstających. Oznacza to, że funkcja straty L2 reaguje silniej na nieprawidłowe prognozy niż funkcja straty L1. Na przykład funkcja straty L1 dla poprzedniej partii wyniesie 8, a nie 16. Zwróć uwagę, że 1 wartość odstająca odpowiada za 9 z 16 wartości.
Modele regresji zwykle używają funkcji utraty L2.
Błąd średniokwadratowy to średnia strata L2 na przykład. Strata kwadratowa to inna nazwa straty L2.
Więcej informacji znajdziesz w sekcji Regresja logistyczna: funkcja straty i regularyzacja w kursie Machine Learning Crash Course.
Oceny LLM
Zestaw danych i punktów odniesienia do oceny wydajności dużych modeli językowych (LLM). Ogólnie rzecz biorąc, oceny LLM:
- pomagać badaczom w określaniu obszarów, w których modele LLM wymagają ulepszeń;
- Przydają się do porównywania różnych LLM i określania, który z nich najlepiej nadaje się do konkretnego zadania.
- pomagać w zapewnieniu bezpieczeństwa i etycznego charakteru LLM;
Więcej informacji znajdziesz w szybkim szkoleniu z uczenia maszynowego w sekcji Duże modele językowe (LLM).
strata
Podczas trenowania modelu nadzorowanego miara odległości prognozy modelu od jego etykiety.
Funkcja straty oblicza stratę.
Więcej informacji znajdziesz w sekcji Regresja liniowa: funkcja straty w kursie Machine Learning Crash Course.
funkcja straty,
Podczas trenowania lub testowania funkcja matematyczna, która oblicza stratę na partii przykładów. Funkcja straty zwraca mniejszą stratę w przypadku modeli, które generują dobre prognozy, niż w przypadku modeli, które generują złe prognozy.
Celem trenowania jest zwykle minimalizowanie straty zwracanej przez funkcję straty.
Istnieje wiele różnych rodzajów funkcji straty. Wybierz odpowiednią funkcję straty dla rodzaju tworzonego modelu. Na przykład:
- Funkcja straty L2 (lub średnia kwadratowa błędów) to funkcja straty dla regresji liniowej.
- Log Loss to funkcja straty dla regresji logistycznej.
M
rozkład macierzy,
W matematyce mechanizm służący do znajdowania macierzy, których iloczyn skalarny jest zbliżony do macierzy docelowej.
W systemach rekomendacji macierz docelowa często zawiera oceny produktów przez użytkowników. Na przykład macierz docelowa systemu rekomendacji filmów może wyglądać tak, jak poniżej. Liczby całkowite dodatnie to oceny użytkowników, a 0 oznacza, że użytkownik nie ocenił filmu:
| Casablanca | Filadelfijska opowieść | Czarna Pantera | Wonder Woman | Pulp Fiction | |
|---|---|---|---|---|---|
| Użytkownik 1 | 5,0 | 3,0 | 0,0 | 2,0 | 0,0 |
| Użytkownik 2 | 4.0 | 0,0 | 0,0 | 1,0 | 5,0 |
| Użytkownik 3 | 3,0 | 1,0 | 4.0 | 5,0 | 0,0 |
System rekomendacji filmów ma na celu przewidywanie ocen użytkowników dla filmów, które nie zostały jeszcze ocenione. Na przykład czy użytkownik 1 polubi film Czarna Pantera?
Jednym z podejść do systemów rekomendacji jest użycie faktoryzacji macierzy do wygenerowania tych 2 macierzy:
- Macierz użytkowników o wymiarach liczba użytkowników × liczba wymiarów osadzania.
- Macierz elementów o wymiarach liczba wymiarów osadzania × liczba elementów.
Na przykład zastosowanie faktoryzacji macierzy w przypadku 3 użytkowników i 5 produktów może dać te macierze użytkowników i produktów:
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
Iloczyn skalarny macierzy użytkowników i macierzy elementów daje macierz rekomendacji, która zawiera nie tylko pierwotne oceny użytkowników, ale także prognozy dotyczące filmów, których każdy użytkownik nie widział. Na przykład ocena filmu Casablanca przez użytkownika 1 wynosiła 5,0. Produkt odpowiadający tej komórce w macierzy rekomendacji powinien mieć wartość około 5, 0.
(1.1 * 0.9) + (2.3 * 1.7) = 4.9Co ważniejsze, czy użytkownik 1 polubi film Czarna Pantera? Obliczenie iloczynu skalarnego odpowiadającego pierwszemu wierszowi i trzeciej kolumnie daje prognozowaną ocenę 4,3:
(1.1 * 1.4) + (2.3 * 1.2) = 4.3Rozkład macierzy zwykle daje macierz użytkowników i macierz produktów, które razem są znacznie bardziej kompaktowe niż macierz docelowa.
MBPP
Skrót od Mostly Basic Python Problems.
Średni błąd bezwzględny (MAE)
Średnia utrata na przykład, gdy używana jest utrata L1. Średni błąd bezwzględny obliczany jest w ten sposób:
- Obliczanie straty L1 dla partii.
- Podziel utratę L1 przez liczbę przykładów w partii.
Rozważmy na przykład obliczenie funkcji straty L1 na podstawie poniższej partii 5 przykładów:
| Rzeczywista wartość przykładu | Wartość prognozowana przez model | Strata (różnica między wartością rzeczywistą a przewidywaną) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = utrata L1 | ||
W tym przypadku wartość funkcji straty L1 wynosi 8, a liczba przykładów to 5. Średni błąd bezwzględny wynosi więc:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
Porównaj średni błąd bezwzględny z błędem średniokwadratowym i średnią kwadratową błędów.
średnia precyzja przy k (mAP@k),
Średnia statystyczna wszystkich wyników średniej precyzji przy k w zbiorze danych do weryfikacji. Średnia precyzja przy k jest używana do oceny jakości rekomendacji generowanych przez system rekomendacji.
Chociaż wyrażenie „średnia arytmetyczna” brzmi redundantnie, nazwa wskaźnika jest odpowiednia. W końcu ten wskaźnik oblicza średnią z wielu wartości średniej precyzji przy k.
Błąd średniokwadratowy (MSE)
Średnia utrata na przykład, gdy używana jest utrata 2. Oblicz błąd średniokwadratowy w ten sposób:
- Oblicz stratę L2 dla partii.
- Podziel utratę L2 przez liczbę przykładów w partii.
Rozważmy na przykład utratę w przypadku tej partii 5 przykładów:
| Rzeczywista wartość | Prognoza modelu | Strata | Strata kwadratowa |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = przegrana L2 | |||
Dlatego błąd średniokwadratowy wynosi:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
Błąd średniokwadratowy to popularny optymalizator trenowania, szczególnie w przypadku regresji liniowej.
Porównaj błąd średniokwadratowy ze średnim błędem bezwzględnym i średnią kwadratową błędów.
TensorFlow Playground używa średniego błędu kwadratowego do obliczania wartości funkcji straty.
wskaźnik
statystykę, która Cię interesuje;
Cel to wskaźnik, który system uczący się próbuje optymalizować.
Interfejs Metrics API (tf.metrics)
Interfejs TensorFlow API do oceny modeli. Na przykład tf.metrics.accuracy określa, jak często prognozy modelu są zgodne z etykietami.
funkcja straty minimax
Funkcja straty dla generatywnych sieci przeciwstawnych na podstawie entropii krzyżowej między rozkładem wygenerowanych danych a rzeczywistych danych.
W pierwszym artykule opisującym generatywne sieci przeciwstawne użyto funkcji straty minimax.
Więcej informacji znajdziesz w sekcji Funkcje straty w kursie Generative Adversarial Networks.
pojemność modelu,
Złożoność problemów, których model może się nauczyć. Im bardziej złożone problemy model może rozwiązywać, tym większa jest jego pojemność. Pojemność modelu zwykle rośnie wraz z liczbą jego parametrów. Formalną definicję pojemności modelu klasyfikacji znajdziesz w sekcji Wymiar VC.
Wykorzystanie chwili
Zaawansowany algorytm spadku gradientowego, w którym krok uczenia zależy nie tylko od pochodnej w bieżącym kroku, ale także od pochodnych kroków, które bezpośrednio go poprzedzały. Momentum polega na obliczaniu wykładniczo ważonej średniej ruchomej gradientów w czasie, co jest analogiczne do pędu w fizyce. Momentum czasami zapobiega utknięciu uczenia w lokalnych minimach.
Mostly Basic Python Problems (MBPP)
Zbiór danych do oceny umiejętności modelu LLM w generowaniu kodu w Pythonie. Mostly Basic Python Problems zawiera około 1000 problemów programistycznych pochodzących z różnych źródeł. Każdy problem w zbiorze danych zawiera:
- opis zadania,
- Kod rozwiązania
- 3 automatyczne przypadki testowe
N
klasa wyników negatywnych,
W klasyfikacji binarnej jedna klasa jest określana jako pozytywna, a druga jako negatywna. Klasa pozytywna to rzecz lub zdarzenie, które model testuje, a klasa negatywna to inna możliwość. Na przykład:
- Klasa negatywna w teście medycznym może oznaczać „brak guza”.
- Klasa negatywna w modelu klasyfikacji e-maili może być oznaczona jako „nie spam”.
Porównaj z klasą wyników pozytywnych.
O
cel
Wskaźnik, który algorytm próbuje zoptymalizować.
funkcja celu
Formuła matematyczna lub dane, które model ma optymalizować. Na przykład funkcja celu w przypadku regresji liniowej to zwykle średnia kwadratowa strata. Dlatego podczas trenowania modelu regresji liniowej celem jest zminimalizowanie straty średniokwadratowej.
W niektórych przypadkach celem jest maksymalizacja funkcji celu. Jeśli np. funkcja celu to dokładność, celem jest jej maksymalizacja.
Zobacz też utratę.
P
pass at k (pass@k)
Wskaźnik określający jakość kodu (np. w języku Python) generowanego przez duży model językowy. W szczególności wartość k w przypadku testu Pass@k określa prawdopodobieństwo, że co najmniej 1 z k wygenerowanych bloków kodu przejdzie wszystkie testy jednostkowe.
Duże modele językowe często mają trudności z generowaniem dobrego kodu w przypadku złożonych problemów programistycznych. Inżynierowie oprogramowania radzą sobie z tym problemem, prosząc duży model językowy o wygenerowanie wielu (k) rozwiązań tego samego problemu. Następnie inżynierowie oprogramowania testują każde z tych rozwiązań za pomocą testów jednostkowych. Obliczenie wyniku testu na poziomie k zależy od wyników testów jednostkowych:
- Jeśli co najmniej jedno z tych rozwiązań przejdzie test jednostkowy, LLM przejdzie to wyzwanie związane z generowaniem kodu.
- Jeśli żadne z rozwiązań nie przejdzie testu jednostkowego, LLM nie zaliczy tego zadania związanego z generowaniem kodu.
Formuła dla przepustki na poziomie k wygląda tak:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
Ogólnie wyższe wartości k dają wyższe wyniki testu Pass@k, ale wymagają większych zasobów dużego modelu językowego i testów jednostkowych.
występ
Termin o wielu znaczeniach:
- Standardowe znaczenie w inżynierii oprogramowania. Chodzi o to, jak szybko (lub wydajnie) działa to oprogramowanie.
- Znaczenie w uczeniu maszynowym. Skuteczność odpowiada na pytanie: jak dokładny jest ten model? Czyli jak dobre są prognozy modelu?
permutacyjna ważność zmiennych
Rodzaj znaczenia zmiennej, który ocenia wzrost błędu prognozy modelu po przestawieniu wartości cechy. Znaczenie zmiennej permutacji jest niezależnym od modelu wskaźnikiem.
perplexity
Miara tego, jak dobrze model wykonuje swoje zadanie. Załóżmy na przykład, że Twoim zadaniem jest odczytanie kilku pierwszych liter słowa, które użytkownik wpisuje na klawiaturze telefonu, i zaproponowanie listy możliwych słów do dokończenia. Złożoność P w tym przypadku to w przybliżeniu liczba propozycji, które musisz podać, aby na liście znalazło się słowo, które użytkownik próbuje wpisać.
Złożoność jest powiązana z entropią krzyżową w ten sposób:
klasa wyników pozytywnych,
Klasa, dla której przeprowadzasz test.
Na przykład klasą pozytywną w modelu do wykrywania raka może być „guz”. Klasą pozytywną w modelu klasyfikacji e-maili może być „spam”.
Porównaj z klasą wyników negatywnych.
PR AUC (obszar pod krzywą PR)
Obszar pod interpolowaną krzywą precyzji i czułości, uzyskany przez wykreślenie punktów (czułość, precyzja) dla różnych wartości progu klasyfikacji.
precyzja
Miara dla modeli klasyfikacji, która odpowiada na to pytanie:
Gdy model przewidział klasę pozytywną, jaki odsetek prognoz był prawidłowy?
Oto wzór:
gdzie:
- Prawdziwie pozytywny wynik oznacza, że model prawidłowo przewidział klasę pozytywną.
- Fałszywie pozytywny wynik oznacza, że model błędnie przewidział klasę pozytywną.
Załóżmy na przykład, że model wygenerował 200 prognoz pozytywnych. Z tych 200 pozytywnych prognoz:
- 150 z nich to wyniki prawdziwie pozytywne.
- 50 z nich to wyniki fałszywie pozytywne.
W tym przypadku:
Porównaj z dokładnością i czułością.
Więcej informacji znajdziesz w sekcji Klasyfikacja: dokładność, czułość, precyzja i powiązane dane w kursie Machine Learning Crash Course.
precyzja przy k (precision@k)
Rodzaj danych do oceny uporządkowanej listy elementów. Precyzja przy k określa ułamek pierwszych k elementów na liście, które są „trafne”. Czyli:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
Wartość parametru k musi być mniejsza lub równa długości zwróconej listy. Pamiętaj, że długość zwróconej listy nie jest uwzględniana w obliczeniach.
Trafność jest często subiektywna. Nawet ludzie, którzy są ekspertami w ocenianiu, często nie zgadzają się co do tego, które elementy są trafne.
Porównaj z:
krzywej precyzji i czułości
Krzywa precyzji w porównaniu z czułością przy różnych progach klasyfikacji.
błąd prognozy,
Wartość wskazująca, jak bardzo średnia prognoz różni się od średniej etykiet w zbiorze danych.
Nie należy go mylić z wyrazem „bias” w modelach uczenia maszynowego ani z uprzedzeniami w kontekście etyki i bezstronności.
równość prognozowana,
Wskaźnik obiektywności, który sprawdza, czy w przypadku danego modelu klasyfikacji wartości precyzji są równoważne w przypadku rozpatrywanych podgrup.
Na przykład model, który przewiduje przyjęcie do college'u, spełniałby warunek równości predykcyjnej w przypadku narodowości, gdyby jego wskaźnik precyzji był taki sam w przypadku Liliputów i Brobdingnagów.
Równość cen prognozowanych jest czasami nazywana równością cen prognozowanych.
Więcej informacji o równości predykcyjnej znajdziesz w sekcji 3.2.1 artykułu „Wyjaśnienie definicji sprawiedliwości”.
prognozowana równość cen
Inna nazwa równości predykcyjnej.
funkcja gęstości prawdopodobieństwa
Funkcja, która określa częstotliwość występowania próbek danych o dokładnie określonej wartości. Gdy wartości zbioru danych są ciągłymi liczbami zmiennoprzecinkowymi, dokładne dopasowania występują rzadko. Jednak całkowanie funkcji gęstości prawdopodobieństwa od wartości x do wartości y daje oczekiwaną częstotliwość próbek danych między x a y.
Rozważmy na przykład rozkład normalny o średniej 200 i odchyleniu standardowym 30. Aby określić oczekiwaną częstotliwość próbek danych mieszczących się w zakresie od 211,4 do 218,7, możesz scałkować funkcję gęstości prawdopodobieństwa rozkładu normalnego w zakresie od 211,4 do 218,7.
R
Zbiór danych do czytania ze zrozumieniem z wykorzystaniem zdroworozsądkowego rozumowania (ReCoRD)
Zbiór danych do oceny zdolności dużego modelu językowego do wnioskowania opartego na zdrowym rozsądku. Każdy przykład w zbiorze danych zawiera 3 komponenty:
- paragraf lub dwa z artykułu prasowego;
- Zapytanie, w którym jedna z encji wyraźnie lub domyślnie zidentyfikowanych w fragmencie jest zamaskowana.
- Odpowiedź (nazwa elementu, który należy umieścić w masce)
Obszerną listę przykładów znajdziesz w artykule ReCoRD.
ReCoRD jest komponentem zespołu SuperGLUE.
RealToxicityPrompts
Zbiór danych zawierający zestaw początków zdań, które mogą zawierać toksyczne treści. Użyj tego zbioru danych, aby ocenić zdolność modelu LLM do generowania nietoksycznego tekstu uzupełniającego zdanie. Zwykle do określania, jak dobrze LLM wykonał to zadanie, używa się Perspective API.
Więcej informacji znajdziesz w artykule RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models.
wycofanie
Miara dla modeli klasyfikacji, która odpowiada na to pytanie:
Gdy dane podstawowe należały do klasy pozytywnej, jaki odsetek prognoz został przez model prawidłowo zidentyfikowany jako klasa pozytywna?
Oto wzór:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
gdzie:
- Prawdziwie pozytywny wynik oznacza, że model prawidłowo przewidział klasę pozytywną.
- Fałszywie negatywny wynik oznacza, że model błędnie przewidział klasę negatywną.
Załóżmy na przykład, że model dokonał 200 prognoz na podstawie przykładów, w których prawdziwa klasa to klasa pozytywna. Z tych 200 prognoz:
- 180 z nich to wyniki prawdziwie pozytywne.
- 20 z nich to wyniki fałszywie negatywne.
W tym przypadku:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
Więcej informacji znajdziesz w artykule Klasyfikacja: dokładność, czułość, precyzja i powiązane dane.
czułość przy k (recall@k)
Metryka do oceny systemów, które generują uporządkowaną listę elementów. Wartość k w przypadku miary Recall określa odsetek trafnych elementów w pierwszych k elementach na liście w stosunku do łącznej liczby zwróconych trafnych elementów.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Kontrast z precyzją przy progu ufności k.
Rozpoznawanie implikacji tekstowych (RTE)
Zbiór danych do oceny zdolności LLM do określania, czy hipoteza może wynikać (logicznie) z fragmentu tekstu. Każdy przykład w ocenie RTE składa się z 3 części:
- fragment, zwykle z artykułów informacyjnych lub z Wikipedii;
- hipoteza,
- Prawidłowa odpowiedź, która może być:
- Prawda, co oznacza, że hipoteza może wynikać z fragmentu.
- Fałsz, co oznacza, że hipotezy nie można wywnioskować z fragmentu.
Na przykład:
- Fragment: euro jest walutą Unii Europejskiej.
- Hipoteza: Francja używa euro jako waluty.
- Wynikanie: prawda, ponieważ Francja jest częścią Unii Europejskiej.
RTE jest komponentem zespołu SuperGLUE.
ReCoRD
Skrót od Reading Comprehension with Commonsense Reasoning Dataset.
Krzywa charakterystyki operacyjnej odbiornika (ROC)
Wykres przedstawiający odsetek prawdziwie pozytywnych wyników w porównaniu z odsetkiem fałszywie pozytywnych wyników dla różnych progów klasyfikacji w klasyfikacji binarnej.
Kształt krzywej ROC wskazuje na zdolność modelu klasyfikacji binarnej do oddzielania klas pozytywnych od negatywnych. Załóżmy na przykład, że binarny model klasyfikacji doskonale oddziela wszystkie klasy negatywne od wszystkich klas pozytywnych:
Krzywa ROC poprzedniego modelu wygląda tak:
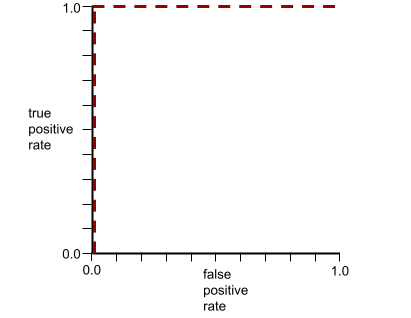
Z kolei na poniższej ilustracji przedstawiono surowe wartości regresji logistycznej w przypadku bardzo słabego modelu, który w ogóle nie potrafi odróżnić klas negatywnych od pozytywnych:
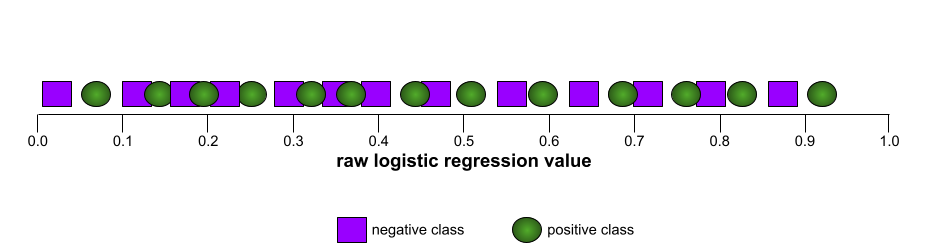
Krzywa ROC tego modelu wygląda tak:
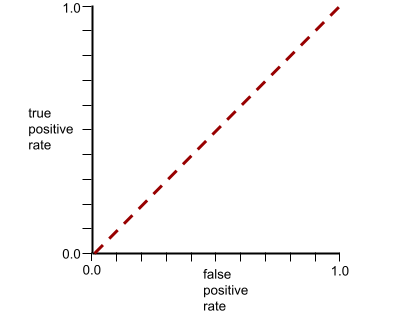
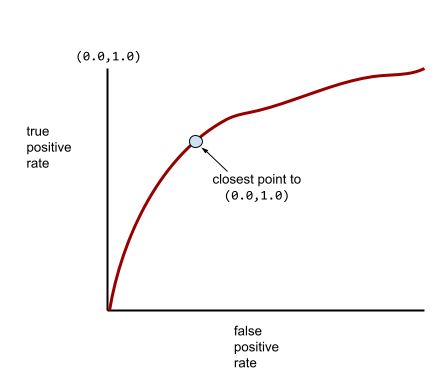
W rzeczywistości większość modeli klasyfikacji binarnej w pewnym stopniu rozdziela klasy pozytywne i negatywne, ale zwykle nie robi tego idealnie. Typowa krzywa ROC znajduje się więc gdzieś pomiędzy tymi dwoma skrajnościami:
Punkt na krzywej ROC najbliższy punktowi (0,0, 1,0) teoretycznie określa idealny próg klasyfikacji. Na wybór idealnego progu klasyfikacji wpływa jednak kilka innych problemów z rzeczywistego świata. Na przykład fałszywe negatywy mogą być znacznie bardziej uciążliwe niż fałszywe pozytywy.
Podsumowaniem krzywej ROC jest wartość liczbowa o nazwie AUC, która jest pojedynczą liczbą zmiennoprzecinkową.
Średnia kwadratowa błędów (RMSE)
Pierwiastek kwadratowy z błędu średniokwadratowego.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
Rodzina wskaźników, które oceniają modele automatycznego podsumowywania i tłumaczenia maszynowego. Wskaźniki ROUGE określają stopień, w jakim tekst referencyjny pokrywa się z wygenerowanym tekstem modelu ML. Każdy element rodziny ROUGE mierzy nakładanie się w inny sposób. Wyższe wyniki ROUGE wskazują na większe podobieństwo między tekstem referencyjnym a wygenerowanym niż niższe wyniki ROUGE.
Każdy element rodziny ROUGE generuje zwykle te dane:
- Precyzja
- Czułość
- F1
Szczegółowe informacje i przykłady znajdziesz w tych artykułach:
ROUGE-L
Wskaźnik z rodziny ROUGE, który koncentruje się na długości najdłuższego wspólnego podciągu w tekście referencyjnym i wygenerowanym tekście. Wartości przywołania i precyzji dla ROUGE-L są obliczane według tych wzorów:
Następnie możesz użyć wskaźnika F1, aby połączyć czułość ROUGE-L i precyzję ROUGE-L w jeden wskaźnik:
ROUGE-L ignoruje znaki nowego wiersza w tekście referencyjnym i wygenerowanym, więc najdłuższy wspólny podciąg może obejmować wiele zdań. Jeśli tekst referencyjny i wygenerowany składają się z wielu zdań, lepszym wskaźnikiem jest zwykle odmiana ROUGE-L o nazwie ROUGE-Lsum. Wskaźnik ROUGE-Lsum określa najdłuższy wspólny podciąg dla każdego zdania w fragmencie, a następnie oblicza średnią tych najdłuższych wspólnych podciągów.
ROUGE-N
Zestaw wskaźników z rodziny ROUGE, który porównuje wspólne n-gramy o określonym rozmiarze w tekście referencyjnym i tekście wygenerowanym. Na przykład:
- ROUGE-1 mierzy liczbę wspólnych tokenów w tekście referencyjnym i wygenerowanym.
- ROUGE-2 mierzy liczbę wspólnych bigramów (2-gramów) w tekście referencyjnym i wygenerowanym.
- ROUGE-3 mierzy liczbę wspólnych trigramów (3-gramów) w tekście referencyjnym i wygenerowanym.
Aby obliczyć wartość ROUGE-N recall i ROUGE-N precision dla dowolnego elementu rodziny ROUGE-N, możesz użyć tych wzorów:
Następnie możesz użyć F1, aby połączyć czułość ROUGE-N i precyzję ROUGE-N w jeden rodzaj danych:
ROUGE-S
Łagodna forma ROUGE-N, która umożliwia dopasowywanie skip-gramów. Oznacza to, że ROUGE-N zlicza tylko n-gramy, które są dokładnie takie same, ale ROUGE-S zlicza też n-gramy oddzielone co najmniej jednym słowem. Na przykład:
- tekst referencyjny: Białe chmury
- wygenerowany tekst: Białe, kłębiące się chmury
Podczas obliczania ROUGE-N 2-gram White clouds nie pasuje do White billowing clouds. Jednak podczas obliczania ROUGE-S fraza White clouds pasuje do frazy White billowing clouds.
R-kwadrat
Rodzaj danych regresji wskazujący, w jakim stopniu zmienność etykiety wynika z pojedynczej cechy lub zestawu cech. Wartość R-kwadrat mieści się w zakresie od 0 do 1 i można ją interpretować w ten sposób:
- Wartość R-kwadrat równa 0 oznacza, że żadna część zmienności etykiety nie jest spowodowana zestawem cech.
- Wartość R-kwadrat równa 1 oznacza, że wszystkie zmiany etykiety są spowodowane zestawem funkcji.
- Wartość R-kwadrat w zakresie od 0 do 1 wskazuje, w jakim stopniu wariancję etykiety można przewidzieć na podstawie konkretnej cechy lub zestawu cech. Na przykład wartość R-kwadrat równa 0,10 oznacza, że 10% wariancji etykiety wynika z zestawu cech, a wartość R-kwadrat równa 0,20 oznacza, że z zestawu cech wynika 20% wariancji etykiety itd.
Wartość R kwadrat to kwadrat współczynnika korelacji Pearsona między wartościami prognozowanymi przez model a danymi podstawowymi.
RTE
Skrót od Recognizing Textual Entailment.
S
ocena
Część systemu rekomendacji, która podaje wartość lub ranking każdego elementu wygenerowanego w fazie generowania kandydatów.
miara podobieństwa,
W algorytmach klastrowania jest to miara używana do określania, jak podobne są do siebie 2 przykłady.
rozproszenie
Liczba elementów ustawionych na zero (lub null) w wektorze lub macierzy podzielona przez łączną liczbę wpisów w tym wektorze lub macierzy. Załóżmy na przykład, że masz macierz ze 100 elementami, w której 98 komórek zawiera zero. Obliczenie rzadkości wygląda następująco:
Rzadkość cech odnosi się do rzadkości wektora cech, a rzadkość modelu – do rzadkości wag modelu.
SQuAD
Akronim od Stanford Question Answering Dataset (zbiór danych do odpowiadania na pytania opracowany przez Uniwersytet Stanforda), wprowadzony w artykule SQuAD: 100,000+ Questions for Machine Comprehension of Text. Pytania w tym zbiorze danych pochodzą od osób, które zadają pytania dotyczące artykułów w Wikipedii. Niektóre pytania w SQuAD mają odpowiedzi, ale inne celowo ich nie mają. Dlatego możesz użyć SQuAD do oceny, czy LLM potrafi:
- Odpowiadaj na pytania, na które można odpowiedzieć.
- Określ pytania, na które nie można odpowiedzieć.
Dopasowanie ścisłe w połączeniu z F1 to najczęstsze dane do oceny LLM w porównaniu z SQuAD.
kwadratowa funkcja straty zawiasu
Kwadrat funkcji straty zawiasowej. Kwadratowa funkcja straty z zawiasem surowiej karze wartości odstające niż zwykła funkcja straty z zawiasem.
strata kwadratowa,
Synonim terminu utrata L2.
SuperGLUE
Zbiór danych do oceny ogólnej zdolności LLM do rozumienia i generowania tekstu. Zespół składa się z tych zbiorów danych:
- Pytania logiczne (BoolQ)
- CommitmentBank (CB)
- Choice of Plausible Alternatives (COPA)
- Multi-sentence Reading Comprehension (MultiRC)
- Reading Comprehension with Commonsense Reasoning Dataset (ReCoRD)
- Rozpoznawanie implikacji tekstowych (RTE)
- Słowa w kontekście (WiC)
- Winograd Schema Challenge (WSC)
Więcej informacji znajdziesz w artykule SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems.
T
strata testowa
Wartość reprezentująca stratę modelu w odniesieniu do zbioru testowego. Podczas tworzenia modelu zwykle starasz się zminimalizować utratę w teście. Dzieje się tak, ponieważ niski błąd testowy jest silniejszym sygnałem jakości niż niski błąd trenowania lub niski błąd weryfikacji.
Duża różnica między stratą na zbiorze testowym a stratą na zbiorze treningowym lub walidacyjnym może sugerować, że musisz zwiększyć współczynnik regularyzacji.
dokładność top-k,
Odsetek przypadków, w których „etykieta docelowa” pojawia się na pierwszych k pozycjach wygenerowanych list. Listy mogą zawierać spersonalizowane rekomendacje lub listę produktów uporządkowanych według funkcji softmax.
Dokładność top-k jest też nazywana dokładnością przy k.
toksyczne
stopień, w jakim treści są obraźliwe, zawierają groźby lub są w inny sposób nieodpowiednie; Wiele modeli uczenia maszynowego może identyfikować, mierzyć i klasyfikować toksyczność. Większość tych modeli identyfikuje toksyczność na podstawie wielu parametrów, takich jak poziom obraźliwego języka i poziom języka zagrażającego.
strata podczas trenowania,
Wskaźnik reprezentujący stratę modelu podczas konkretnej iteracji trenowania. Załóżmy na przykład, że funkcja straty to błąd średniokwadratowy. Załóżmy, że strata treningowa (średni błąd kwadratowy) w 10 iteracji wynosi 2,2, a w 100 iteracji – 1,9.
Krzywa straty przedstawia stratę podczas trenowania w zależności od liczby iteracji. Krzywa straty zawiera następujące wskazówki dotyczące trenowania:
- Spadek oznacza, że model się poprawia.
- Wznosząca się linia oznacza, że model się pogarsza.
- Płaska krzywa oznacza, że model osiągnął zbieżność.
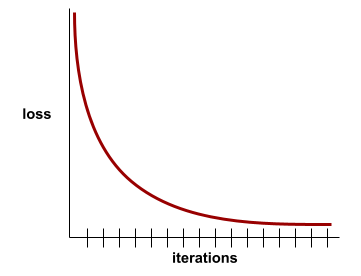
Na przykład poniższa nieco wyidealizowana krzywa strat pokazuje:
- Strome nachylenie w dół w początkowych iteracjach, co oznacza szybką poprawę modelu.
- Stopniowo spłaszczająca się (ale nadal opadająca) krzywa aż do końca trenowania, co oznacza dalsze ulepszanie modelu w nieco wolniejszym tempie niż w początkowych iteracjach.
- Płaski spadek pod koniec szkolenia, co sugeruje zbieżność.
Chociaż strata podczas trenowania jest ważna, zobacz też uogólnianie.
Odpowiadanie na pytania z zakresu ciekawostek
zbiory danych do oceny zdolności modelu LLM do odpowiadania na pytania dotyczące ciekawostek; Każdy zbiór danych zawiera pary pytań i odpowiedzi przygotowane przez miłośników quizów. Różne zbiory danych są oparte na różnych źródłach, w tym:
- Wyszukiwanie w internecie (TriviaQA)
- Wikipedia (TriviaQA_wiki)
Więcej informacji znajdziesz w artykule TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension (TriviaQA: duży zbiór danych do weryfikacji umiejętności czytania ze zrozumieniem, nadzorowany zdalnie).
wynik prawdziwie negatywny (TN)
Przykład, w którym model prawidłowo przewiduje klasę negatywną. Na przykład model wnioskuje, że dany e-mail nie jest spamem, i rzeczywiście nie jest spamem.
wynik prawdziwie pozytywny (TP),
Przykład, w którym model prawidłowo prognozuje klasę pozytywną. Na przykład model wnioskuje, że dany e-mail to spam, i rzeczywiście tak jest.
współczynnik wyników prawdziwie pozytywnych (TPR)
Synonim słowa wycofanie. Czyli:
Współczynnik wyników prawdziwie pozytywnych jest osią Y na krzywej ROC.
Typologically Diverse Question Answering (TyDi QA)
Duży zbiór danych do oceny umiejętności modelu LLM w zakresie odpowiadania na pytania. Zbiór danych zawiera pary pytań i odpowiedzi w wielu językach.
Więcej informacji znajdziesz w artykule TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages (w języku angielskim).
V
strata weryfikacji,
Metryka reprezentująca stratę modelu w zbiorze weryfikacyjnym podczas konkretnej iteracji trenowania.
Zobacz też krzywą generalizacji.
ważność zmiennych,
Zestaw wyników, który wskazuje względne znaczenie każdej cechy dla modelu.
Weźmy na przykład drzewo decyzyjne, które szacuje ceny domów. Załóżmy, że to drzewo decyzyjne korzysta z 3 cech: rozmiaru, wieku i stylu. Jeśli zestaw ważności zmiennych dla 3 cech wynosi {rozmiar=5,8, wiek=2,5, styl=4,7}, to rozmiar jest ważniejszy dla drzewa decyzyjnego niż wiek czy styl.
Istnieją różne rodzaje danych o znaczeniu zmiennych, które mogą dostarczać ekspertom ds. uczenia maszynowego informacji o różnych aspektach modeli.
W
Funkcja straty Wassensteina
Jedna z funkcji straty powszechnie stosowanych w generatywnych sieciach przeciwstawnych, oparta na odległości między rozkładami wygenerowanych i rzeczywistych danych.
WiC
Skrót od Słowa w kontekście.
WikiLingua (wiki_lingua)
Zbiór danych do oceny umiejętności modelu LLM w zakresie podsumowywania krótkich artykułów. WikiHow to encyklopedia artykułów wyjaśniających, jak wykonać różne zadania. Jest to źródło artykułów i podsumowań napisanych przez ludzi. Każdy wpis w zbiorze danych składa się z tych elementów:
- Artykuł, który powstaje przez dodanie każdego kroku z wersji prozy (akapit) listy numerowanej, z wyjątkiem zdania otwierającego każdego kroku.
- Podsumowanie artykułu składające się z pierwszego zdania każdego kroku na liście numerowanej.
Więcej informacji znajdziesz w artykule WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization (WikiLingua: nowy zbiór danych testowych do wielojęzycznego streszczania abstrakcyjnego).
Winograd Schema Challenge (WSC)
Format (lub zbiór danych zgodny z tym formatem) do oceny zdolności LLM do określania frazy rzeczownikowej, do której odnosi się zaimek.
Każdy wpis w Winograd Schema Challenge składa się z tych elementów:
- Krótki fragment zawierający zaimki docelowe
- zaimek docelowy,
- Kandydackie grupy nominalne, a następnie prawidłowa odpowiedź (wartość logiczna). Jeśli zaimek odnosi się do tego kandydata, odpowiedź to „Prawda”. Jeśli zaimek docelowy nie odnosi się do tego kandydata, odpowiedź to „False”.
Na przykład:
- Fragment: Mark opowiedział Pete’owi wiele kłamstw o sobie, które Pete umieścił w swojej książce. Powinien był mówić więcej prawdy.
- Zaimek docelowy: on
- Kandydackie frazy rzeczownikowe:
- Mark: True, ponieważ zaimek docelowy odnosi się do Marka
- Pete: Fałsz, ponieważ zaimki docelowe nie odnoszą się do Petera.
Wyzwanie Winograd Schema Challenge jest częścią zespołu SuperGLUE.
Words in Context (WiC)
Zbiór danych do oceny, jak dobrze LLM wykorzystuje kontekst do zrozumienia słów, które mają wiele znaczeń. Każdy wpis w zbiorze danych zawiera:
- 2 zdania, z których każde zawiera słowo docelowe.
- słowo docelowe,
- Prawidłowa odpowiedź (wartość logiczna), gdzie:
- „Prawda” oznacza, że słowo docelowe ma takie samo znaczenie w obu zdaniach.
- Fałsz oznacza, że słowo docelowe ma w obu zdaniach inne znaczenie.
Na przykład:
- Dwa zdania:
- Na dnie rzeki jest dużo śmieci.
- Gdy śpię, mam obok łóżka szklankę wody.
- Słowo docelowe: łóżko
- Prawidłowa odpowiedź: fałsz, ponieważ słowo docelowe ma w tych dwóch zdaniach inne znaczenie.
Więcej informacji znajdziesz w artykule WiC: the Word-in-Context Dataset for Evaluating Context-Sensitive Meaning Representations.
Words in Context to komponent zespołu SuperGLUE.
WSC
Skrót od Winograd Schema Challenge.
X
XL-Sum (xlsum)
Zbiór danych do oceny umiejętności modelu LLM w zakresie podsumowywania tekstu. XL-Sum zawiera wpisy w wielu językach. Każdy wpis w zbiorze danych zawiera:
- Artykuł pochodzący z British Broadcasting Company (BBC).
- Podsumowanie artykułu napisane przez jego autora. Pamiętaj, że to podsumowanie może zawierać słowa lub wyrażenia, które nie występują w artykule.
Więcej informacji znajdziesz w artykule XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages (XL-Sum: podsumowywanie abstrakcyjne na dużą skalę w 44 językach).