"सभी मॉडल गलत होते हैं, लेकिन कुछ काम के होते हैं." — जॉर्ज बॉक्स, 1978
हालांकि, आंकड़ों से जुड़ी तकनीकें काफ़ी असरदार होती हैं, लेकिन इनकी कुछ सीमाएं भी होती हैं. इन सीमाओं को समझने से, किसी शोधकर्ता को गलतफ़हमियों और गलत दावों से बचने में मदद मिल सकती है. जैसे, बीएफ़ स्किनर का यह दावा कि शेक्सपियर ने अलिटरेशन का इस्तेमाल, रैंडम तरीके से होने वाले इस्तेमाल से ज़्यादा नहीं किया. (स्किनर की स्टडी में ज़रूरत के मुताबिक डेटा नहीं था.1)
अनिश्चितता और गड़बड़ी के बार
अपने विश्लेषण में अनिश्चितता की जानकारी देना ज़रूरी है. अन्य लोगों के विश्लेषण में मौजूद अनिश्चितता को मेज़र करना भी उतना ही ज़रूरी है. ग्राफ़ पर किसी रुझान को प्लॉट करने के लिए दिखने वाले डेटा पॉइंट, हो सकता है कि कोई पैटर्न न दिखाएं. ऐसा तब होता है, जब गड़बड़ी के बार ओवरलैप होते हैं. किसी खास स्टडी या आंकड़ों के आधार पर फ़ैसला लेने के लिए, अनिश्चितता का स्तर बहुत ज़्यादा हो सकता है. अगर किसी रिसर्च स्टडी के लिए, बहुत सटीक डेटा की ज़रूरत है, तो +/- 500 मीटर की अनिश्चितता वाले जियोस्पेशल डेटासेट का इस्तेमाल नहीं किया जा सकता.
इसके अलावा, फ़ैसले लेने की प्रोसेस के दौरान, अनिश्चितता के लेवल का इस्तेमाल किया जा सकता है. अगर किसी खास तरह के पानी के इलाज के नतीजों में 20% अनिश्चितता है, तो उस पानी के इलाज को लागू करने का सुझाव दिया जा सकता है. साथ ही, उस अनिश्चितता को दूर करने के लिए, प्रोग्राम की लगातार निगरानी की जा सकती है.
बेयसियन न्यूरल नेटवर्क, एक वैल्यू के बजाय वैल्यू के डिस्ट्रिब्यूशन का अनुमान लगाकर, अनिश्चितता का आकलन कर सकते हैं.
काम का न होना
जैसा कि शुरुआत में बताया गया है, डेटा और असल वैल्यू के बीच हमेशा कम से कम थोड़ा अंतर होता है. एमएल के जानकार को यह पता लगाना चाहिए कि डेटासेट, पूछे गए सवाल के हिसाब से काम का है या नहीं.
हफ़ ने सार्वजनिक राय से जुड़ी एक शुरुआती स्टडी के बारे में बताया है. इसमें पता चला था कि अमेरिकन श्वेतों के इस सवाल के जवाब कि अमेरिकन अश्वेतों के लिए अच्छा जीवन जीना कितना आसान है, सीधे तौर पर और उलटे तौर पर, अमेरिकन अश्वेतों के लिए उनकी सहानुभूति के लेवल से जुड़े थे. नस्ल के आधार पर होने वाले विरोध के बढ़ने के साथ-साथ, आर्थिक अवसरों के बारे में उम्मीदें भी बढ़ती गईं. इसे गलत तरीके से, प्रगति के संकेत के तौर पर समझा जा सकता था. हालांकि, इस अध्ययन से उस समय अमेरिकी मूल के अश्वेत लोगों के लिए उपलब्ध आर्थिक अवसरों के बारे में कुछ नहीं पता चल पाया. साथ ही, नौकरी के बाजार की सच्चाई के बारे में कोई नतीजा निकालने के लिए, यह अध्ययन सही नहीं था. इसमें सिर्फ़ सर्वे में हिस्सा लेने वाले लोगों की राय शामिल थी. इकट्ठा किया गया डेटा, नौकरी के बाज़ार की स्थिति के हिसाब से काम का नहीं था.2
ऊपर बताए गए सर्वे डेटा की मदद से, मॉडल को ट्रेन किया जा सकता है. इस डेटा से, आउटपुट में अवसर के बजाय आशावाद का पता चलता है. हालांकि, असल अवसरों के लिए, अनुमानित अवसरों का कोई मतलब नहीं है. इसलिए, अगर आपने दावा किया कि मॉडल, असल अवसरों का अनुमान लगा रहा है, तो आपने मॉडल के अनुमान को गलत तरीके से पेश किया होगा.
Confounds
कन्फ़ाउन्डिंग वैरिएबल, कन्फ़ाउन्ड या कोफ़ैक्टर ऐसा वैरिएबल होता है जिस पर स्टडी नहीं की जाती है. यह उन वैरिएबल पर असर डालता है जिन पर स्टडी की जाती है और नतीजों को गलत बना सकता है. उदाहरण के लिए, एक ऐसा एमएल मॉडल लें जो सार्वजनिक स्वास्थ्य नीति की सुविधाओं के आधार पर, किसी देश में होने वाली मौतों की दर का अनुमान लगाता है. मान लें कि औसत उम्र की सुविधा उपलब्ध नहीं है. मान लें कि कुछ देशों में, दूसरे देशों की तुलना में ज़्यादा उम्र के लोगों की संख्या है. औसत उम्र के कंफ़्यूज़िंग वैरिएबल को अनदेखा करने पर, यह मॉडल मृत्यु दर का गलत अनुमान लगा सकता है.
अमेरिका में, जाति अक्सर सामाजिक-आर्थिक स्थिति से जुड़ी होती है. हालांकि, मृत्यु दर के डेटा में सिर्फ़ जाति को रिकॉर्ड किया जाता है, न कि सामाजिक-आर्थिक स्थिति को. जाति के मुकाबले, स्वास्थ्य सेवा, पोषण, खतरनाक काम, और सुरक्षित आवास जैसे वर्ग से जुड़े कॉन्फ़ंड की वजह से, मृत्यु दर पर ज़्यादा असर पड़ सकता है. हालांकि, इन कॉन्फ़ंड को डेटासेट में शामिल न किए जाने की वजह से, इनकी अनदेखी की जा सकती है.3 काम के मॉडल बनाने और काम के और सटीक नतीजे पाने के लिए, इन कॉन्फ़ंड की पहचान करना और उन्हें कंट्रोल करना ज़रूरी है.
अगर किसी मॉडल को मृत्यु दर के मौजूदा डेटा पर ट्रेन किया जाता है, जिसमें नस्ल शामिल है, लेकिन वर्ग नहीं है, तो वह नस्ल के आधार पर मृत्यु दर का अनुमान लगा सकता है. भले ही, वर्ग, मृत्यु दर का बेहतर अनुमान लगाने वाला हो. इससे, बीमारी के कारण के बारे में गलत अनुमान लगाए जा सकते हैं. साथ ही, मरीज़ की मृत्यु के बारे में गलत अनुमान लगाए जा सकते हैं. एमएल के विशेषज्ञों को यह पता लगाना चाहिए कि उनके डेटा में कोई गड़बड़ी है या नहीं. साथ ही, यह भी पता लगाना चाहिए कि उनके डेटासेट में कौनसे अहम वैरिएबल मौजूद नहीं हैं.
साल 1985 में, हार्वर्ड मेडिकल स्कूल और हार्वर्ड स्कूल ऑफ़ पब्लिक हेल्थ की ऑब्ज़र्वेशनल कोहॉर्ट स्टडी, नर्स हेल्थ स्टडी में पता चला कि एस्ट्रोजन रिप्लेसमेंट थेरेपी (ईआरटी) लेने वाले कोहॉर्ट के सदस्यों को, कभी भी एस्ट्रोजन न लेने वाले कोहॉर्ट के सदस्यों की तुलना में दिल का दौरा कम पड़ता है. इस वजह से, डॉक्टरों ने कई दशकों तक अपने ज़्यादा उम्र की महिलाओं और पोस्टमेनोपॉज़ल महिलाओं को एस्ट्रोजन का प्रिस्क्रिप्शन दिया. हालांकि, साल 2002 में हुई एक क्लीनिकल स्टडी में पता चला कि लंबे समय तक एस्ट्रोजन थेरेपी लेने से, स्वास्थ्य से जुड़े जोखिम पैदा हो सकते हैं. इसके बाद, पोस्ट-मेनोपॉज़ल महिलाओं को एस्ट्रोजन प्रिस्क्राइब करने की प्रथा बंद कर दी गई. हालांकि, इससे पहले ही अनुमानित तौर पर 10 हज़ार से ज़्यादा लोगों की मौत हो चुकी थी.
कई गड़बड़ियों की वजह से, यह असोसिएशन हो सकता है. महामारी विज्ञानियों ने पाया है कि हार्मोन रिप्लेसमेंट थेरेपी लेने वाली महिलाएं, उन महिलाओं की तुलना में ज़्यादा पतली, ज़्यादा पढ़ी-लिखी, ज़्यादा अमीर, और अपनी सेहत के बारे में ज़्यादा सचेत होती हैं. साथ ही, वे ज़्यादा व्यायाम करती हैं. अलग-अलग स्टडी में यह पता चला है कि शिक्षा और धन से, दिल की बीमारी का खतरा कम होता है. इन असर की वजह से, एस्ट्रोजेन थेरेपी और दिल के दौरे के बीच के संबंध को समझना मुश्किल हो जाता.4
नेगेटिव संख्याओं के साथ प्रतिशत
अगर गलत संख्याएं मौजूद हैं, तो5 प्रतिशत का इस्तेमाल करने से बचें. ऐसा इसलिए, क्योंकि इससे सभी तरह के अहम फ़ायदे और नुकसान छिप सकते हैं. आसान हिसाब लगाने के लिए, मान लें कि रेस्टोरेंट इंडस्ट्री में दो करोड़ नौकरियां हैं. अगर मार्च 2020 के आखिर में, रेस्टोरेंट इंडस्ट्री में एक करोड़ नौकरी छिन जाती हैं, 10 महीनों तक कोई बदलाव नहीं होता, और फ़रवरी 2021 की शुरुआत में 9 लाख नौकरियां वापस आ जाती हैं, तो मार्च 2021 की शुरुआत में साल-दर-साल की तुलना करने पर, रेस्टोरेंट में नौकरियों में सिर्फ़ 5% की कमी दिखेगी. अगर कोई और बदलाव नहीं होता है, तो अप्रैल 2021 के आखिर में साल-दर-साल की तुलना करने पर, रेस्टोरेंट में नौकरियों में 90% की बढ़ोतरी का पता चलता है. हालांकि, असल स्थिति इससे काफ़ी अलग है.
ज़रूरत के हिसाब से सामान्य की गई असल संख्याओं का इस्तेमाल करें. ज़्यादा जानकारी के लिए, संख्या वाले डेटा के साथ काम करना देखें.
पोस्ट-होक गलतफ़हमी और काम न आने वाले कोरिलेशन
पोस्ट-होक फ़ॉलसी यह अनुमान है कि इवेंट A के बाद इवेंट B हुआ, इसलिए इवेंट A की वजह से इवेंट B हुआ. आसान शब्दों में कहें, तो यह ऐसी वजह और असर के बीच संबंध को मानता है जो मौजूद नहीं है. और भी आसान शब्दों में: कोरिलेशन से यह साबित नहीं होता कि कोई घटना किसी दूसरी घटना की वजह से हुई है.
वजह और असर के साफ़ तौर पर दिखने वाले संबंध के अलावा, इन वजहों से भी संबंध बन सकते हैं:
- पूरी तरह से संयोग (इलस्ट्रेशन के लिए, टायलर विगन का गलत संबंध देखें. इसमें मेन में तलाक की दर और मार्जरीन के इस्तेमाल के बीच का गहरा संबंध शामिल है).
- दो वैरिएबल के बीच का असल संबंध. हालांकि, यह साफ़ तौर पर नहीं पता चलता कि कौनसा वैरिएबल वजह है और किस पर असर पड़ा है.
- तीसरा, अलग कारण, जो दोनों वैरिएबल पर असर डालता है. हालांकि, आपस में जुड़े वैरिएबल एक-दूसरे से अलग होते हैं. उदाहरण के लिए, वैश्विक महंगाई की वजह से, नौका और सेलरी, दोनों की कीमतें बढ़ सकती हैं.6
मौजूदा डेटा के बाद के डेटा के लिए, सहसंबंध का अनुमान लगाना भी जोखिम भरा है. हफ़ ने बताया कि थोड़ी बारिश से फ़सलों की पैदावार बढ़ेगी, लेकिन ज़्यादा बारिश से उनमें नुकसान होगा. बारिश और फ़सल के नतीजों के बीच का संबंध नॉनलाइनियर होता है.7 (नॉनलाइनियर संबंधों के बारे में ज़्यादा जानने के लिए, अगले दो सेक्शन देखें.) जॉन्स ने बताया कि दुनिया में अचानक होने वाली कई घटनाएं होती हैं. जैसे, युद्ध और अकाल. इनसे टाइम सीरीज़ डेटा के आधार पर, आने वाले समय के अनुमान में काफ़ी अनिश्चितता होती है.8
इसके अलावा, हो सकता है कि वजह और असर के आधार पर सही संबंध होने के बावजूद, फ़ैसले लेने में मदद न मिले. उदाहरण के लिए, हफ़ ने 1950 के दशक में, शादी करने की संभावना और कॉलेज की शिक्षा के बीच के संबंध के बारे में बताया है. कॉलेज जाने वाली महिलाओं के शादी करने की संभावना कम थी. हालांकि, ऐसा हो सकता है कि कॉलेज जाने वाली महिलाएं पहले से ही शादी करने में कम दिलचस्पी रखती हों. अगर ऐसा था, तो कॉलेज की शिक्षा लेने से, उनकी शादी होने की संभावना पर कोई असर नहीं पड़ा.9
अगर किसी विश्लेषण से पता चलता है कि डेटासेट में दो वैरिएबल के बीच संबंध है, तो पूछें:
- यह किस तरह का संबंध है: 'कारण और असर', गलत, अज्ञात संबंध या तीसरे वैरिएबल की वजह से?
- डेटा से एक्सट्रपलेशन करना कितना जोखिम भरा है? ट्रेनिंग डेटासेट में मौजूद डेटा के आधार पर, मॉडल का हर अनुमान, डेटा से इंटरपोलेशन या एक्सट्रापोलेशन होता है.
- क्या काम के फ़ैसले लेने के लिए, कोरिलेशन का इस्तेमाल किया जा सकता है? उदाहरण के लिए, किसी देश में लोगों का भरोसा, वहां की बढ़ती मजदूरी से काफ़ी हद तक जुड़ा हो सकता है. हालांकि, किसी देश के लोगों की सोशल मीडिया पोस्ट जैसे टेक्स्ट डेटा के बड़े कॉर्पस का सेंटिमेंट विश्लेषण, उस देश में मजदूरी में होने वाली बढ़ोतरी का अनुमान लगाने के लिए काम का नहीं होगा.
किसी मॉडल को ट्रेनिंग देते समय, एमएल विशेषज्ञ आम तौर पर ऐसी सुविधाओं को ढूंढते हैं जो लेबल से काफ़ी मिलती-जुलती हों. अगर एट्रिब्यूट और लेबल के बीच के संबंध को अच्छी तरह से समझा नहीं जाता है, तो इस सेक्शन में बताई गई समस्याएं हो सकती हैं. इनमें, गलत संबंधों पर आधारित मॉडल और ऐसे मॉडल शामिल हैं जो यह मानते हैं कि पुराने रुझान आने वाले समय में भी जारी रहेंगे, जबकि ऐसा नहीं होता.
लीनियर बायस
"नॉनलाइनर दुनिया में लीनियर थिंकिंग" में, बार्ट डी लैंग, स्टेफानो पोंटोनी, और रिचर्ड लारिक ने लीनियर बायस को, मानव मस्तिष्क के लीनियर रिलेशनशिप की उम्मीद और खोज के तौर पर बताया है. हालांकि, कई चीज़ें नॉनलाइनर होती हैं. उदाहरण के लिए, मानवीय व्यवहार और भावनाओं के बीच का संबंध, एक रेखा नहीं बल्कि उत्तल कर्व होता है. डी लैंगहे और अन्य लोगों ने 2007 के Journal of consumer policy पेपर में बताया है कि, जेनी वैन डोरन और अन्य लोगों ने, सर्वे में हिस्सा लेने वाले लोगों की पर्यावरण के बारे में चिंता और ऑर्गैनिक प्रॉडक्ट की खरीदारी के बीच के संबंध का मॉडल बनाया. जिन लोगों को पर्यावरण के बारे में सबसे ज़्यादा चिंता थी उन्होंने ज़्यादा ऑर्गैनिक प्रॉडक्ट खरीदे. हालांकि, अन्य सभी लोगों के बीच काफ़ी कम अंतर था.
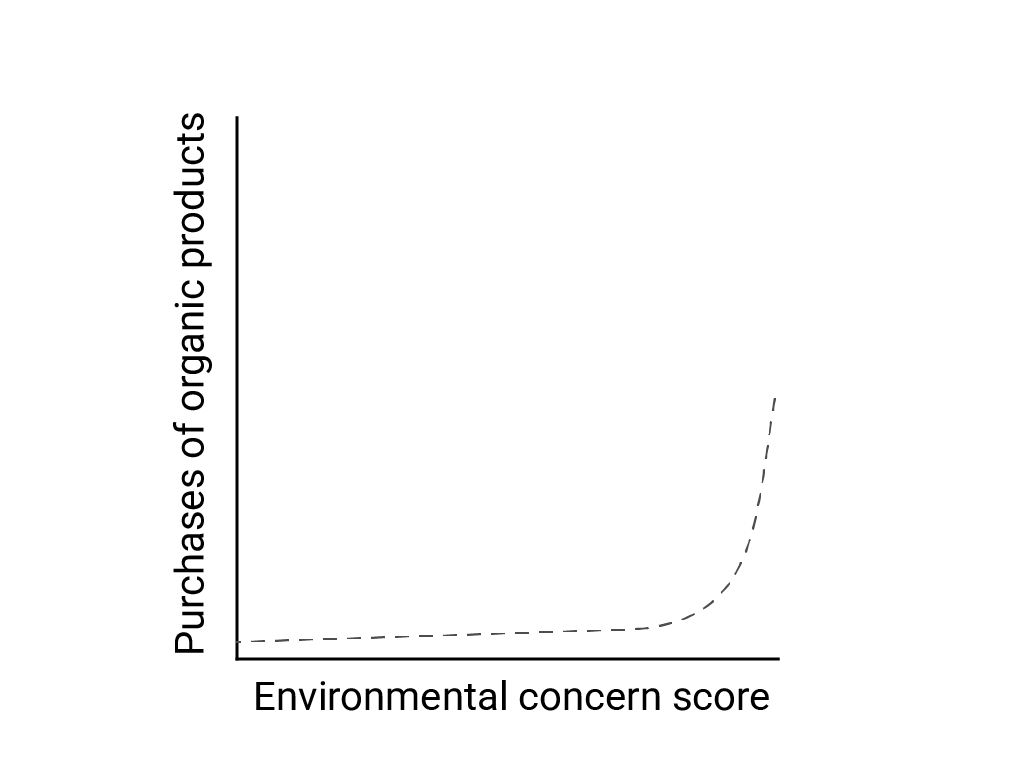
मॉडल या स्टडी डिज़ाइन करते समय, नॉनलाइनियर संबंधों की संभावना पर विचार करें. A/B टेस्टिंग से, नॉन-लाइनर रिलेशनशिप का पता नहीं चल सकता. इसलिए, तीसरे और बीच की स्थिति, C की भी जांच करें. यह भी देखें कि क्या शुरुआती व्यवहार, रेखीय बना रहेगा या आने वाले समय में डेटा, लॉगरिदमिक या अन्य नॉन-लिनियर व्यवहार दिखा सकता है.
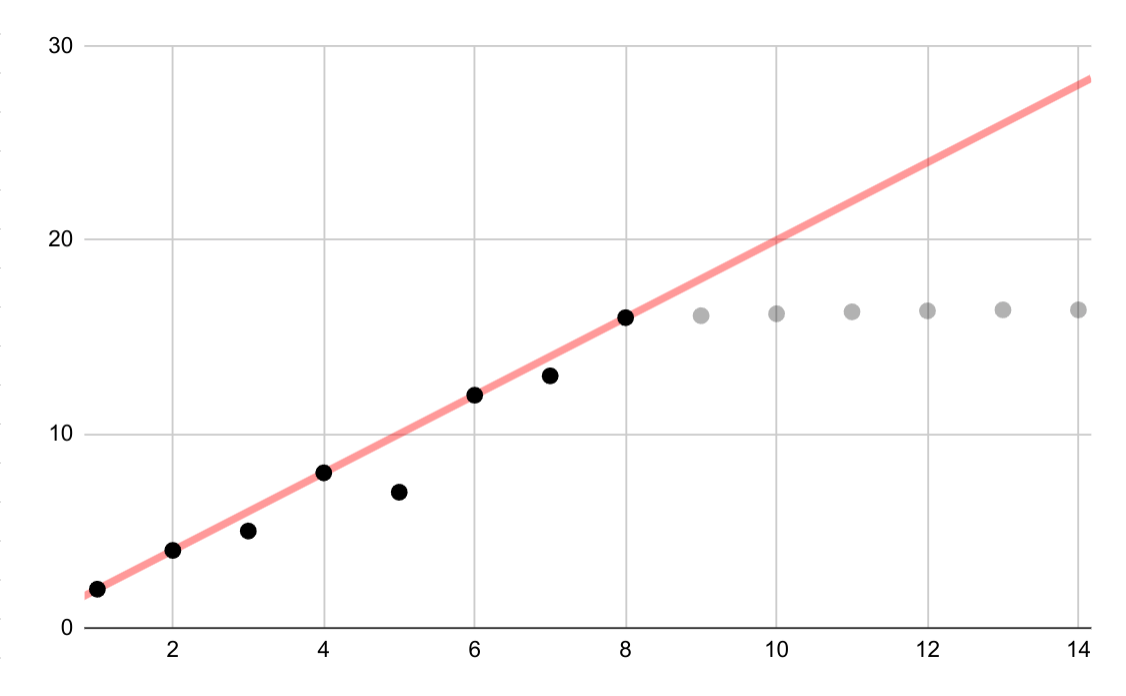
इस काल्पनिक उदाहरण में, लॉगरिदमिक डेटा के लिए गलत लीनियर फ़िट दिखाया गया है. अगर सिर्फ़ शुरुआती कुछ डेटा पॉइंट उपलब्ध होते, तो वैरिएबल के बीच मौजूद रेखीय संबंध को मानना, एक साथ आकर्षक और गलत होता.
लीनियर इंटरपोलेशन
डेटा पॉइंट के बीच के किसी भी इंटरपोलेशन की जांच करें, क्योंकि इंटरपोलेशन से काल्पनिक पॉइंट जुड़ते हैं. साथ ही, असल मेज़रमेंट के बीच के इंटरवल में, अहम उतार-चढ़ाव हो सकते हैं. उदाहरण के लिए, लीनियर इंटरपोलेशन से जुड़े चार डेटा पॉइंट के विज़ुअलाइज़ेशन को देखें:

इसके बाद, डेटा पॉइंट के बीच उतार-चढ़ाव के इस उदाहरण पर ध्यान दें, जिन्हें लीनियर इंटरपोलेशन की मदद से मिटा दिया जाता है:
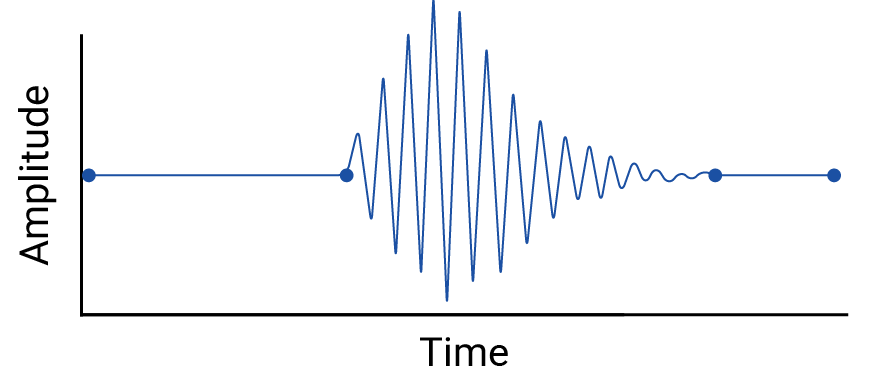
यह उदाहरण बनावटी है, क्योंकि सीस्मोग्राफ़ लगातार डेटा इकट्ठा करते हैं. इसलिए, यह भूकंप रिकार्ड नहीं किया जा सकता. हालांकि, यह इंटरपोलेशन से की गई अनुमानितताओं और डेटा विशेषज्ञों को न दिखने वाले असली फ़ेनोमेना को दिखाने के लिए मददगार है.
रनगे का फ़िनॉमेनन
रंगे का फ़ेनोमेन, जिसे "पॉलीनोमीयल विगल" भी कहा जाता है, एक ऐसी समस्या है जो लीनियर इंटरपोलेशन और लीनियर बायस से बिलकुल अलग है. डेटा में पॉलीनोम इंटरपोलेशन फ़िट करते समय, बहुत ज़्यादा डिग्री वाले पॉलीनोम का इस्तेमाल किया जा सकता है. डिग्री या ऑर्डर, पॉलीनोम समीकरण में सबसे ज़्यादा एक्सपोनेंट होता है. इससे, किनारों पर अजीब उतार-चढ़ाव होते हैं. उदाहरण के लिए, 11 डिग्री का पॉलीनोमियल इंटरपोलेशन लागू करना. इसका मतलब है कि पॉलीनोमियल इक्वेशन में सबसे ज़्यादा ऑर्डर वाला शब्द \(x^{11}\)है. इसे करीब-करीब लीनियर डेटा पर लागू करने से, डेटा की रेंज की शुरुआत और आखिर में काफ़ी खराब अनुमान मिलते हैं:
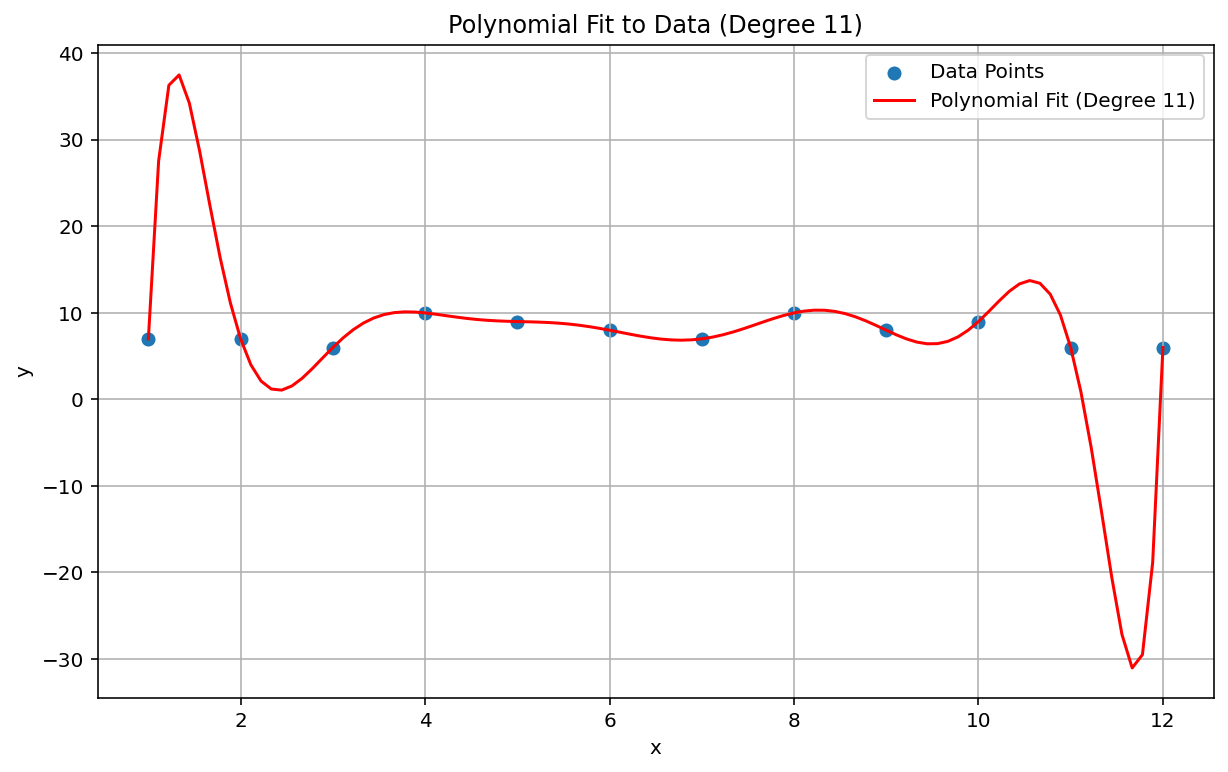
एमएल के संदर्भ में, एक मिलती-जुलती घटना ओवरफ़िटिंग है.
आंकड़ों से पता चलने वाली गड़बड़ियां
कभी-कभी, आंकड़ों के आधार पर किया जाने वाला टेस्ट, छोटे असर का पता लगाने के लिए ज़रूरत के मुताबिक नहीं होता. आंकड़ों के विश्लेषण में कम क्षमता का मतलब है कि सही इवेंट की सही तरीके से पहचान करने की संभावना कम होती है. इसलिए, फ़ॉल्स नेगेटिव की संभावना ज़्यादा होती है. कैथरीन बटन और अन्य लोगों ने Nature में लिखा है: "जब किसी फ़ील्ड में अध्ययनों को 20% की क्षमता के साथ डिज़ाइन किया जाता है, तो इसका मतलब है कि अगर उस फ़ील्ड में 100 असली नॉन-नल इफ़ेक्ट खोजे जाने हैं, तो इन अध्ययनों से उनमें से सिर्फ़ 20 का पता चल सकता है." कभी-कभी सैंपल साइज़ बढ़ाने से मदद मिल सकती है. साथ ही, स्टडी को ध्यान से डिज़ाइन करने से भी मदद मिल सकती है.
एमएल में एक मिलती-जुलती स्थिति, कैटगरी तय करने और कैटगरी तय करने के थ्रेशोल्ड को चुनने की समस्या है. ज़्यादा थ्रेशोल्ड चुनने पर, फ़ॉल्स पॉज़िटिव कम और फ़ॉल्स नेगेटिव ज़्यादा होते हैं. वहीं, कम थ्रेशोल्ड चुनने पर, फ़ॉल्स पॉज़िटिव ज़्यादा और फ़ॉल्स नेगेटिव कम होते हैं.
आंकड़ों से जुड़ी समस्याओं के अलावा, कोरिलेशन को लीनियर रिलेशनशिप का पता लगाने के लिए डिज़ाइन किया गया है. इसलिए, वैरिएबल के बीच नॉन-लीनियर कोरिलेशन का पता नहीं चल सकता. इसी तरह, वैरिएबल एक-दूसरे से जुड़े हो सकते हैं, लेकिन आंकड़ों के हिसाब से उनका आपस में कोई संबंध नहीं हो सकता. वैरिएबल का एक-दूसरे से नेगेटिव संबंध भी हो सकता है, लेकिन वे एक-दूसरे से पूरी तरह से अलग भी हो सकते हैं. इसे बर्क्सन का विरोधाभास या बर्क्सन की गलतफ़हमी कहा जाता है. सामान्य लोगों की तुलना में, अस्पताल में भर्ती मरीजों की संख्या को देखते समय, किसी भी जोखिम वाले फ़ैक्टर और गंभीर बीमारी के बीच गलत निगेटिव संबंध होना, बर्स्कॉन के गलतफ़हमी का सबसे अच्छा उदाहरण है. यह गलतफ़हमी, चुनने की प्रोसेस (अस्पताल में भर्ती होने के लिए ज़रूरी गंभीर स्थिति) की वजह से होती है.
देखें कि इनमें से कोई स्थिति आप पर लागू होती है या नहीं.
पुराने मॉडल और अमान्य अनुमान
समय के साथ, अच्छे मॉडल भी खराब हो सकते हैं. इसकी वजह यह है कि व्यवहार (और दुनिया) बदल सकता है. Netflix के शुरुआती अनुमानित मॉडल को बंद करना पड़ा, क्योंकि उनके ग्राहक आधार में बदलाव आया. यह बदलाव, टेक्नोलॉजी के बारे में जानने वाले युवा उपयोगकर्ताओं से आम लोगों में हुआ.10
मॉडल में ऐसी गलत और अनजान जानकारी भी शामिल हो सकती है जो मॉडल के पूरी तरह से काम न करने तक छिपी रह सकती है. जैसे, 2008 में हुए मार्केट क्रैश के दौरान. वित्तीय उद्योग के वैल्यू ऐट रिस्क (VaR) मॉडल का दावा है कि वे किसी भी ट्रेडर के पोर्टफ़ोलियो में होने वाले ज़्यादा से ज़्यादा नुकसान का सटीक अनुमान लगाते हैं. उदाहरण के लिए, 99% समय में $1,00,000 का ज़्यादा से ज़्यादा नुकसान होने की उम्मीद है. हालांकि, क्रैश की असामान्य स्थितियों में,1,00,000 डॉलर या उससे ज़्यादा का नुकसान हो सकता है.
VaR मॉडल, गलत मान्यताओं पर आधारित थे. इनमें ये शामिल हैं:
- बाज़ार में पहले हुए बदलावों से, आने वाले समय में होने वाले बदलावों का अनुमान लगाया जा सकता है.
- अनुमानित रिटर्न के लिए, नॉर्मल (थिन-टेल्ड, इसलिए अनुमानित) डिस्ट्रिब्यूशन का इस्तेमाल किया गया था.
असल में, डेटा का डिस्ट्रिब्यूशन फ़ैट-टेल, "वाइल्ड" या फ़्रैक्टल था. इसका मतलब है कि सामान्य डिस्ट्रिब्यूशन के अनुमान के मुकाबले, लॉन्ग-टेल, एक्सट्रीम, और ऐसी घटनाओं का जोखिम काफ़ी ज़्यादा था जो शायद कभी न कभी हो. असल डिस्ट्रिब्यूशन के फ़ैट-टेल वाले नेचर के बारे में काफ़ी जानकारी थी, लेकिन इस पर कोई कार्रवाई नहीं की गई. हालांकि, यह बात कम लोगों को पता थी कि अलग-अलग तरह की घटनाएं कितनी जटिल और आपस में जुड़ी हुई हैं. इनमें, ऑटोमेटेड सेलऑफ़ के साथ कंप्यूटर पर आधारित ट्रेडिंग भी शामिल है.11
एग्रीगेशन से जुड़ी समस्याएं
इकट्ठा किया गया डेटा, जिसमें ज़्यादातर डेमोग्राफ़िक और महामारी से जुड़ा डेटा शामिल होता है, वह कुछ खास तरह के ट्रैप के दायरे में आता है. सिम्पसन का विरोधाभास या एगलमेशन पैराडॉक्स, एग्रीगेट किए गए डेटा में तब होता है, जब डेटा को किसी दूसरे लेवल पर एग्रीगेट करने पर, दिखने वाले रुझान गायब हो जाते हैं या उलट जाते हैं. ऐसा, ग़लत फ़ैक्टर और गलत तरीके से समझे गए असर के संबंधों की वजह से होता है.
इकोलॉजिकल फ़ॉलसी में, एक एग्रीगेशन लेवल पर किसी पॉप्युलेशन के बारे में गलत जानकारी को दूसरे एग्रीगेशन लेवल पर एक्सट्रापोलेट किया जाता है. ऐसा तब किया जाता है, जब दावा मान्य न हो. ऐसा हो सकता है कि किसी प्रांत में 40% कृषि श्रमिकों को होने वाली बीमारी, ज़्यादा आबादी में उतनी ही संख्या में न हो. इस बात की भी बहुत संभावना है कि उस प्रांत में कुछ ऐसे फ़ार्म या कृषि वाले ऐसे शहर होंगे जहां इस बीमारी का प्रकोप नहीं है. कम असर वाली जगहों पर भी 40% की दर का अनुमान लगाना गलत होगा.
बदली जा सकने वाली क्षेत्रीय इकाई की समस्या (MAUP), भौगोलिक डेटा में एक आम समस्या है. इस बारे में स्टैन ओपनशॉ ने 1984 में CATMOG 38 में बताया था. डेटा इकट्ठा करने के लिए इस्तेमाल किए गए इलाकों के आकार और साइज़ के आधार पर, जियोस्पेशल डेटा विशेषज्ञ, डेटा में वैरिएबल के बीच लगभग कोई भी संबंध स्थापित कर सकता है. किसी एक राजनैतिक दल के पक्ष में मतदान वाले ज़िलों को बांटना, एमएयूपी का एक उदाहरण है.
इन सभी स्थितियों में, एग्रीगेशन के एक लेवल से दूसरे लेवल पर अनुमान लगाने का गलत तरीका अपनाया जाता है. विश्लेषण के अलग-अलग लेवल के लिए, अलग-अलग एग्रीगेशन या पूरी तरह से अलग डेटासेट की ज़रूरत पड़ सकती है.12
ध्यान दें कि निजता की वजहों से, जनगणना, डेमोग्राफ़िक, और महामारी से जुड़े डेटा को आम तौर पर ज़ोन के हिसाब से इकट्ठा किया जाता है. साथ ही, ये ज़ोन अक्सर मनमुताबिक होते हैं. इसका मतलब है कि ये ज़ोन, असल दुनिया की सीमाओं के हिसाब से नहीं होते. इस तरह के डेटा के साथ काम करते समय, एमएल विशेषज्ञों को यह देखना चाहिए कि चुने गए ज़ोन के साइज़ और आकार या एग्रीगेशन के लेवल के आधार पर, मॉडल की परफ़ॉर्मेंस और अनुमानों में बदलाव होता है या नहीं. अगर ऐसा होता है, तो यह भी देखना चाहिए कि एग्रीगेशन से जुड़ी इन समस्याओं में से किसी एक से मॉडल के अनुमानों पर असर पड़ता है या नहीं.
रेफ़रंस
बटन, कैथरीन वगैरह. "पावर फ़ॉल्ट: छोटा सैंपल साइज़, न्यूरोसाइंस की भरोसेमंदता को क्यों कम करता है." Nature Reviews Neuroscience vol 14 (2013), 365–376. डीओआई: https://doi.org/10.1038/nrn3475
कैरो, अल्बर्टो. चार्ट कैसे गुमराह करते हैं: विज़ुअल जानकारी के बारे में ज़्यादा जानना. न्यूयॉर्क: W.W. Norton, 2019.
डेवनपोर्ट, थॉमस एच. "प्रेडिकटिव ऐनलिटिक्स के बारे में बुनियादी जानकारी." मैनेजर के लिए डेटा विश्लेषण की बुनियादी बातों के बारे में HBR गाइड (बोस्टन: HBR Press, 2018) 81-86 में.
डी लांगे, बार्ट, स्टेफ़ानो पुंटोनी, और रिचर्ड लारिक. "नॉन-लाइनर दुनिया में लीनियर थिंकिंग." मैनेजर के लिए डेटा विश्लेषण के बुनियादी सिद्धांतों की HBR गाइड (बोस्टन: HBR Press, 2018) के पेज 131 से 154 पर.
एलेनबर्ग, जॉर्डन. गलत न होने का तरीका: गणितीय सोच की शक्ति. NY: Penguin, 2014.
हफ़, डैरिल. आंकड़ों का गलत इस्तेमाल करके झूठ कैसे बोलें. न्यूयॉर्क: W.W. Norton, 1954.
जोन्स, बेन. डेटा से जुड़ी समस्याओं से बचना. होबोकेन, न्यू जर्सी: Wiley, 2020.
ओपनशॉ, स्टैन. "The Modifiable Areal Unit Problem," CATMOG 38 (Norwich, England: Geo Books 1984) 37.
वित्तीय मॉडलिंग के जोखिम: वैर और आर्थिक मंदी, 111वां कॉन्ग्रेशन (2009) (नासिम एन. Taleb और रिचर्ड बुकस्टैबर).
रिटर, डेविड. "किस समय किसी कनेक्शन पर कार्रवाई करनी है और किस समय नहीं." मैनेजर के लिए डेटा ऐनलिटिक्स की बुनियादी बातों के बारे में HBR गाइड (बोस्टन: HBR Press, 2018) 103-109 में.
Tulchinsky, Theodore H. and Elena A. Varavikova. "तीसरा चैप्टर: किसी देश/इलाके के लोगों की सेहत का आकलन, निगरानी, और मेज़रमेंट करना", नया पब्लिक हेल्थ, तीसरा संस्करण. सैन डिएगो: Academic Press, 2014, pp 91-147. DOI: https://doi.org/10.1016/B978-0-12-415766-8.00003-3.
Van Doorn, Jenny, Peter C. Verhoef, and Tammo H. A. Bijmolt. "नीति से जुड़ी रिसर्च में, रवैया और व्यवहार के बीच नॉन-लीनियर रिलेशनशिप की अहमियत." Journal of Consumer Policy 30 (2007) 75–90. डीओआई: https://doi.org/10.1007/s10603-007-9028-3
इमेज का रेफ़रंस
"वॉन मिसेस डिस्ट्रिब्यूशन" पर आधारित. Rainald62, 2018. सोर्स
{kind=link}
-
एलेनबर्ग 125. ↩
-
हफ़ 77-79. हफ़ ने प्रिंसटन के ऑफ़िस ऑफ़ पब्लिक ओपिनियन रिसर्च का हवाला दिया है. हालांकि, हो सकता है कि वह डेनवर यूनिवर्सिटी के नैशनल ओपिनियन रिसर्च सेंटर की अप्रैल 1944 की रिपोर्ट के बारे में सोच रहे हों. ↩
-
Tulchinsky और Varavikova. ↩
-
गैरी टॉब्स, The New York Times Magazine में 16 सितंबर, 2007 को लिखा था कि क्या हमें वाकई पता है कि हमें सेहतमंद कौनसी चीज़ें बनाती हैं?" ↩
-
एलेनबर्ग 78. ↩
-
हफ़ 91-92. ↩
-
Huff 93. ↩
-
जोंस 157-167. ↩
-
हफ़ 95. ↩
-
डेवनपोर्ट 84. ↩
-
नसीम एन. की कांग्रेस के सामने दी गई गवाही देखें Taleb and Richard Bookstaber in The Risks of Financial Modeling: VaR and the Economic Meltdown, 111th Congress (2009) 11-67. ↩
-
काहिरा 155, 162. ↩