"Todos os modelos estão errados, mas alguns são úteis". — George Box, 1978
Embora poderosas, as técnicas estatísticas têm limitações. A compreensão dessas limitações pode ajudar um pesquisador a evitar gafes e afirmações imprecisas, como a afirmação de BF Skinner de que Shakespeare não usava aliteração mais do que a aleatoriedade permitiria. O estudo de Skinner foi subpotenciado.1
Barras de incerteza e erro
É importante especificar a incerteza na sua análise. Também é importante quantificar a incerteza nas análises de outras pessoas. Pontos de dados que parecem mostrar uma tendência em um gráfico, mas têm barras de erro sobrepostas, podem não indicar nenhum padrão. A incerteza também pode ser muito alta para tirar conclusões úteis de um estudo ou teste estatístico específico. Se um estudo de pesquisa exige precisão no nível do lote, um conjunto de dados geoespaciais com +/- 500 m de incerteza tem muita incerteza para ser usado.
Como alternativa, os níveis de incerteza podem ser úteis durante os processos de tomada de decisão. Dados que apoiam um tratamento de água específico com 20% de incerteza nos resultados podem levar a uma recomendação para a implementação desse tratamento com monitoramento contínuo do programa para lidar com essa incerteza.
As redes neurais bayesianas podem quantificar a incerteza prevendo distribuições de valores em vez de valores únicos.
Irrlevância
Como discutido na introdução, sempre há pelo menos uma pequena lacuna entre os dados e a realidade. O profissional de ML astuto precisa estabelecer se o conjunto de dados é relevante para a pergunta que está sendo feita.
Huff descreve um estudo de opinião pública inicial que descobriu que as respostas dos americanos brancos à pergunta sobre a facilidade com que os negros americanos ganham a vida estavam diretamente e inversamente relacionadas ao nível de empatia em relação aos negros americanos. À medida que a animosidade racial aumentava, as respostas sobre as oportunidades econômicas esperadas se tornavam cada vez mais otimistas. Isso pode ter sido interpretado como um sinal de progresso. No entanto, o estudo não mostrou nada sobre as oportunidades econômicas reais disponíveis para os negros americanos na época e não foi adequado para tirar conclusões sobre a realidade do mercado de trabalho, apenas as opiniões dos participantes da pesquisa. Os dados coletados eram irrelevantes para o estado do mercado de trabalho.2
Você pode treinar um modelo com dados de pesquisa como o descrito acima, em que a saída mede otimismo em vez de oportunidade. No entanto, como as oportunidades previstas são irrelevantes para as oportunidades reais, se você afirmar que o modelo está prevendo oportunidades reais, você estará falsificando o que o modelo prevê.
Confusão
Uma variável de confusão, confusão ou coeficiente é uma variável que não está em estudo e influencia as variáveis que estão em estudo e pode distorcer os resultados. Por exemplo, considere um modelo de ML que prevê as taxas de mortalidade de um país de entrada com base em recursos de políticas de saúde pública. Suponha que a idade mediana não seja um recurso. Suponha ainda que alguns países têm uma população mais velha do que outros. Ao ignorar a variável de confusão da idade média, esse modelo pode prever taxas de mortalidade incorretas.
Nos Estados Unidos, a raça é frequentemente fortemente correlacionada com a classe socioeconômica, embora apenas a raça, e não a classe, seja registrada com dados de mortalidade. Confusão de classe, como acesso a cuidados de saúde, nutrição, trabalho perigoso e moradia segura, pode ter uma influência maior nas taxas de mortalidade do que a raça, mas pode ser negligenciada porque não está incluída nos conjuntos de dados.3 Identificar e controlar essas confusões é fundamental para criar modelos úteis e extrair conclusões significativas e precisas.
Se um modelo for treinado com dados de mortalidade atuais, que incluem raça, mas não classe, ele poderá prever a mortalidade com base na raça, mesmo que a classe seja um preditor mais forte de mortalidade. Isso pode levar a suposições imprecisas sobre causalidade e previsões imprecisas sobre a mortalidade do paciente. Os profissionais de ML precisam perguntar se há variáveis de confusão nos dados e quais variáveis importantes podem estar faltando no conjunto de dados.
Em 1985, o Nurses' Health Study, um estudo de coorte observacional da Harvard Medical School e da Harvard School of Public Health, descobriu que os membros do grupo que fizeram terapia de reposição de estrogênio tiveram uma incidência menor de ataques cardíacos em comparação com os membros do grupo que nunca tomaram estrogênio. Como resultado, os médicos prescreviam estrogênio para pacientes menopáusicas e pós-menopáusicas por décadas, até que um estudo clínico em 2002 identificou riscos à saúde criados pela terapia de estrogênio a longo prazo. A prática de receitar estrogênio para mulheres na pós-menopausa foi interrompida, mas não antes de causar cerca de dezenas de milhares de mortes prematuras.
Vários fatores de confusão podem ter causado a associação. Epidemiologistas descobriram que as mulheres que fazem terapia de reposição hormonal, em comparação com as que não fazem, tendem a ser mais magras, mais instruídas, mais ricas, mais conscientes da saúde e mais propensas a se exercitar. Em diferentes estudos, a educação e a riqueza foram encontradas para reduzir o risco de doenças cardíacas. Esses efeitos teriam confundido a aparente correlação entre a terapia com estrogênio e os ataques cardíacos.4
Porcentagens com números negativos
Evite usar porcentagens quando houver números negativos,5 porque todos os tipos de ganhos e perdas significativos podem ser obscurecidos. Para fins de cálculo simples, suponha que o setor de restaurantes tenha 2 milhões de empregos. Se o setor perder 1 milhão desses empregos no final de março de 2020, não tiver mudanças líquidas por dez meses e ganhar 900.000 empregos no início de fevereiro de 2021, uma comparação anual no início de março de 2021 sugeriria apenas uma perda de 5% dos empregos em restaurantes. Supondo que não haja outras mudanças, uma comparação anual no final de abril de 2021 sugeriria um aumento de 90% nos empregos em restaurantes, o que é uma imagem muito diferente da realidade.
Prefira números reais, normalizados conforme apropriado. Consulte Como trabalhar com dados numéricos para saber mais.
Falácia post hoc e correlações inúteis
A falácia pós-fato é a suposição de que, como o evento A foi seguido pelo evento B, o evento A causou o evento B. Simplificando, ele pressupõe uma relação de causa e efeito que não existe. Mais simples ainda: as correlações não provam a causalidade.
Além de uma relação clara de causa e efeito, as correlações também podem surgir de:
- Pura coincidência (confira as correlações espúrias de Tyler Vigen para ver exemplos, incluindo uma forte correlação entre a taxa de divórcio no Maine e o consumo de margarina).
- Uma relação real entre duas variáveis, embora não esteja claro qual variável é causadora e qual é afetada.
- Uma terceira causa separada que influencia as duas variáveis, embora as variáveis correlacionadas não tenham relação entre si. A inflação global, por exemplo, pode aumentar os preços de iates e de aipo.6
Também é arriscado extrapolar uma correlação além dos dados atuais. Huff aponta que um pouco de chuva melhora as safras, mas muita chuva as danifica. A relação entre chuva e safras não é linear.7 (Consulte as duas próximas seções para saber mais sobre relações não lineares.) Jones observa que o mundo está cheio de eventos imprevisíveis, como guerras e fome, que sujeitam as previsões futuras de dados de séries temporais a enormes quantidades de incerteza.8
Além disso, mesmo uma correlação genuína baseada em causa e efeito pode não ser útil para tomar decisões. Huff dá, como exemplo, a correlação entre a capacidade de se casar e a educação universitária na década de 1950. As mulheres que fizeram faculdade tinham menos probabilidade de se casar, mas poderia ser o caso de as mulheres que fizeram faculdade terem menos inclinação para se casar desde o início. Se esse for o caso, uma educação universitária não muda a probabilidade de se casar.9
Se uma análise detectar uma correlação entre duas variáveis em um conjunto de dados, pergunte:
- Que tipo de correlação é essa: relação causal, espúria, desconhecida ou causada por uma terceira variável?
- Qual é o risco da extrapolação dos dados? Cada previsão de modelo sobre dados que não estão no conjunto de dados de treinamento é, na verdade, uma interpolação ou extrapolação dos dados.
- A correlação pode ser usada para tomar decisões úteis? Por exemplo, o otimismo pode estar fortemente correlacionado com o aumento dos salários, mas a análise de sentimento de um grande corpus de dados de texto, como postagens de mídias sociais feitas por usuários em um país específico, não seria útil para prever aumentos salariais nesse país.
Ao treinar um modelo, os profissionais de ML geralmente procuram recursos que tenham uma forte correlação com o rótulo. Se a relação entre os recursos e o rótulo não for bem compreendida, isso poderá levar aos problemas descritos nesta seção, incluindo modelos baseados em correlações espúrias e modelos que assumem que as tendências históricas vão continuar no futuro, quando, na verdade, elas não vão.
Viés linear
Em "Pensamento linear em um mundo não linear", Bart de Langhe, Stefano Puntoni e Richard Larrick descrevem o viés linear como a tendência do cérebro humano de esperar e procurar relações lineares, embora muitos fenômenos sejam não lineares. A relação entre atitudes e comportamentos humanos, por exemplo, é uma curva convexa, e não uma linha. Em um artigo de 2007 do Journal of Consumer Policy citado por de Langhe et al., Jenny van Doorn et al. modelaram a relação entre a preocupação dos participantes da pesquisa com o meio ambiente e as compras de produtos orgânicos. As pessoas com as preocupações mais extremas sobre o meio ambiente compraram mais produtos orgânicos, mas houve pouca diferença entre todos os outros entrevistados.
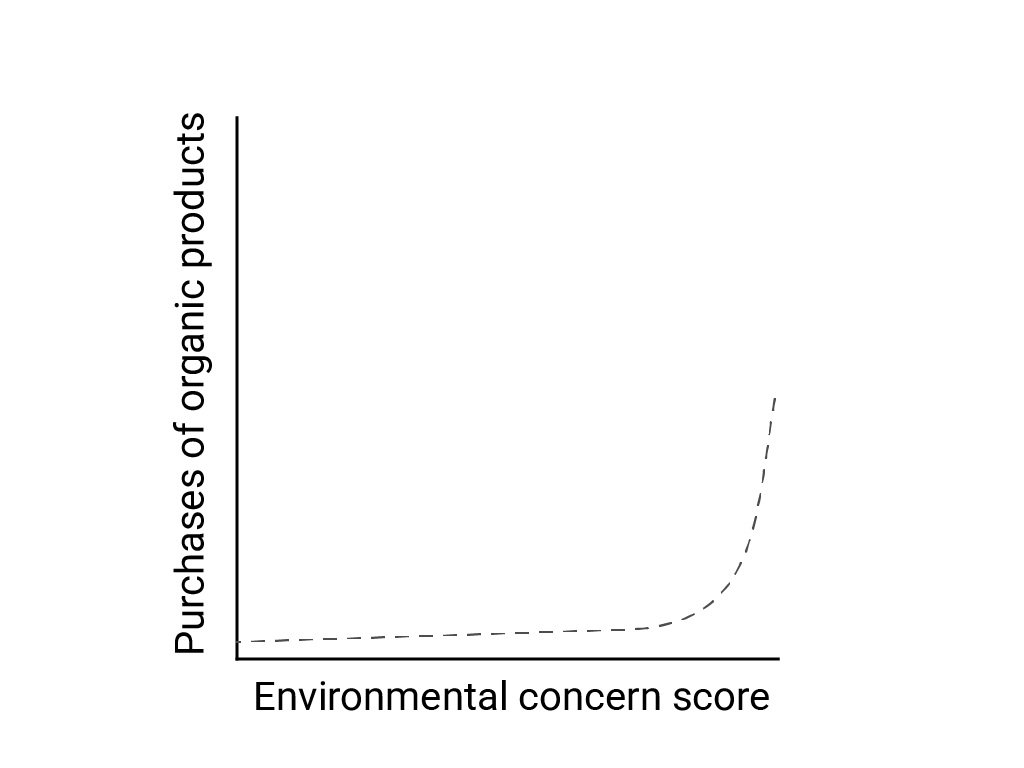
Ao projetar modelos ou estudos, considere a possibilidade de relações não lineares. Como o teste A/B pode perder relações não lineares, considere também testar uma terceira condição intermediária, C. Considere também se o comportamento inicial que parece linear vai continuar sendo linear ou se os dados futuros podem mostrar um comportamento mais logarítmico ou outro comportamento não linear.
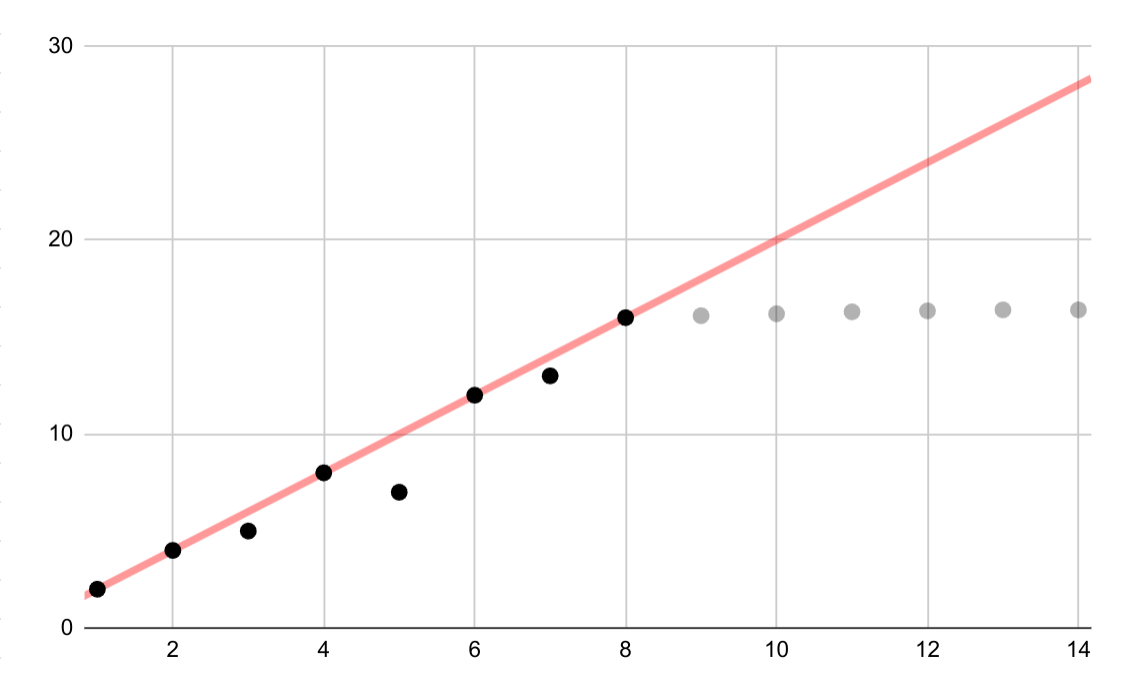
Este exemplo hipotético mostra um ajuste linear incorreto para dados logarítmicos. Se apenas os primeiros pontos de dados estivessem disponíveis, seria tentador e incorreto presumir uma relação linear contínua entre as variáveis.
Interpolação linear
Examine qualquer interpolação entre pontos de dados, porque a interpolação introduz pontos fictícios, e os intervalos entre medições reais podem conter flutuações significativas. Como exemplo, considere a seguinte visualização de quatro pontos de dados conectados com interpolações lineares:

Em seguida, considere este exemplo de flutuações entre pontos de dados que são apagados por uma interpolação linear:
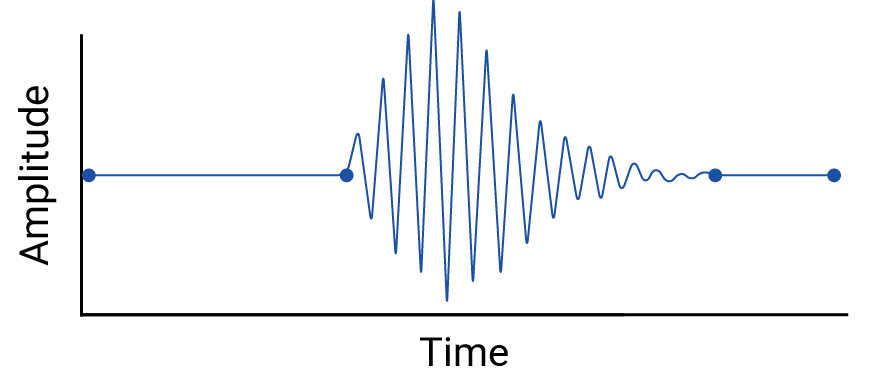
O exemplo é artificial porque os sismógrafos coletam dados contínuos, e, portanto, esse terremoto não seria ignorado. Mas é útil para ilustrar as suposições feitas por interpolações e os fenômenos reais que os profissionais de dados podem perder.
Fenômeno de Runge
O fenômeno de Runge, também conhecido como "movimento polinomial", é um problema no extremo oposto do espectro da interpolação linear e da inclinação linear. Ao ajustar uma interpolação polinomial a dados, é possível usar um polinômio com um grau muito alto (grau ou ordem, sendo o expoente mais alto na equação polinomial). Isso produz oscilações estranhas nas bordas. Por exemplo, aplicar uma interpolação polinomial de grau 11, o que significa que o termo de ordem mais alta na equação polinomial tem \(x^{11}\), a dados aproximadamente lineares, resulta em previsões notavelmente ruins no início e no final do intervalo de dados:
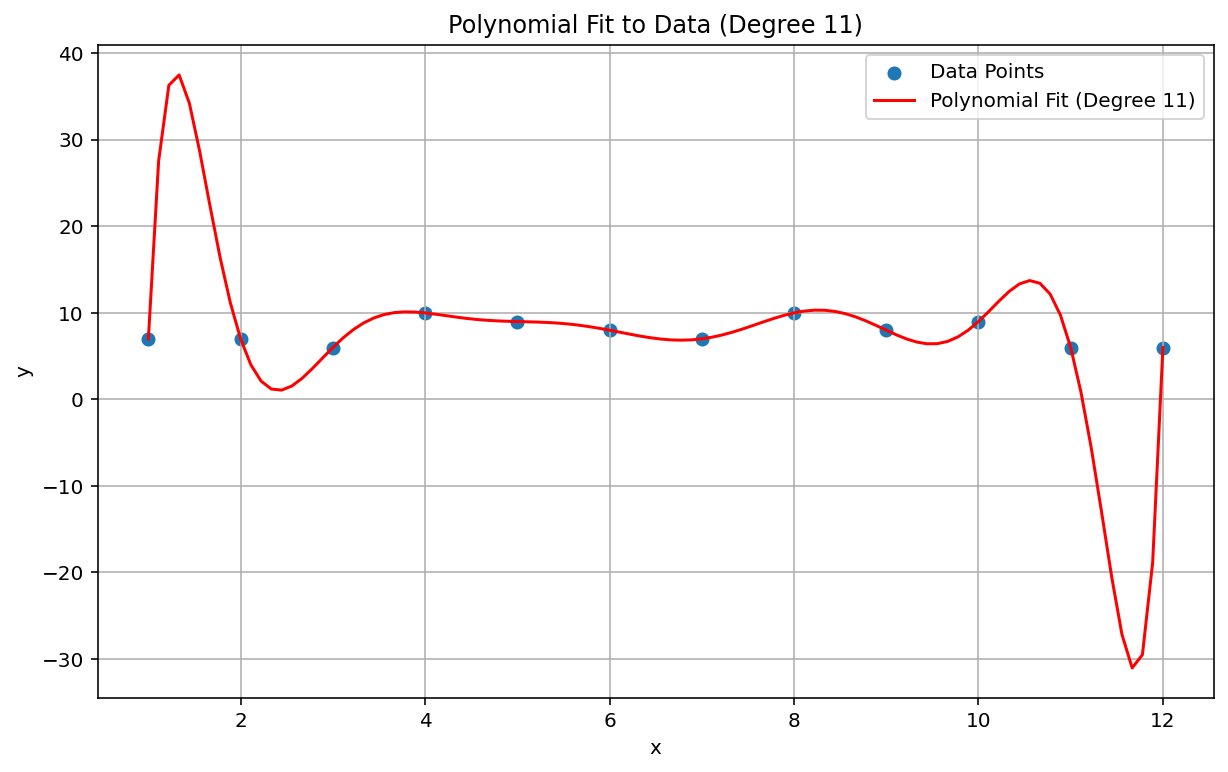
No contexto de ML, um fenômeno análogo é o ajuste excessivo.
Falhas estatísticas a serem detectadas
Às vezes, um teste estatístico pode ser fraco demais para detectar um pequeno efeito. A baixa potência na análise estatística significa uma baixa probabilidade de identificar corretamente eventos reais e, portanto, uma alta probabilidade de falsos negativos. Katherine Button et al. escreveram na Nature: "Quando os estudos em um determinado campo são projetados com uma potência de 20%, isso significa que, se houver 100 efeitos não nulos genuíneos a serem descobertos nesse campo, esses estudos devem descobrir apenas 20 deles". Às vezes, aumentar o tamanho da amostra pode ajudar, assim como um design de estudo cuidadoso.
Uma situação análoga no ML é o problema da classificação e a escolha de um limite de classificação. A escolha de um limite maior resulta em menos falsos positivos e mais falsos negativos, enquanto um limite menor resulta em mais falsos positivos e menos falsos negativos.
Além de problemas com a potência estatística, como a correlação é projetada para detectar relações lineares, as correlações não lineares entre as variáveis podem ser perdidas. Da mesma forma, as variáveis podem estar relacionadas entre si, mas não estar estatisticamente correlacionadas. As variáveis também podem ser correlacionadas negativamente, mas completamente não relacionadas, no que é conhecido como paradoxo de Berkson ou falácia de Berkson. O exemplo clássico do viés de Berkson é a correlação negativa espúria entre qualquer fator de risco e doença grave ao analisar uma população de pacientes internados (em comparação com a população geral), que surge do processo de seleção (uma condição grave o suficiente para exigir internação hospitalar).
Considere se alguma dessas situações se aplica.
Modelos desatualizados e suposições inválidas
Mesmo modelos bons podem se degradar ao longo do tempo porque o comportamento (e o mundo, aliás) pode mudar. Os primeiros modelos preditivos da Netflix precisaram ser aposentados, já que a base de clientes mudou de usuários jovens e com conhecimento de tecnologia para a população em geral.10
Os modelos também podem conter suposições silenciosas e imprecisas que podem permanecer ocultas até a falha catastrófica do modelo, como no colapso do mercado de 2008. Os modelos de valor em risco (VaR, na sigla em inglês) do setor financeiro estimavam com precisão a perda máxima no portfólio de qualquer trader, por exemplo, uma perda máxima de US$ 100.000 esperada 99% do tempo. No entanto, nas condições anormais do crash, um portfólio com uma perda máxima esperada de US$100.000 às vezes perdia US$1.000.000 ou mais.
Os modelos de VaR foram baseados em suposições incorretas, incluindo as seguintes:
- As mudanças do mercado no passado são preditivas para as mudanças futuras.
- Uma distribuição normal (de cauda fina e, portanto, previsível) foi a base dos retornos previstos.
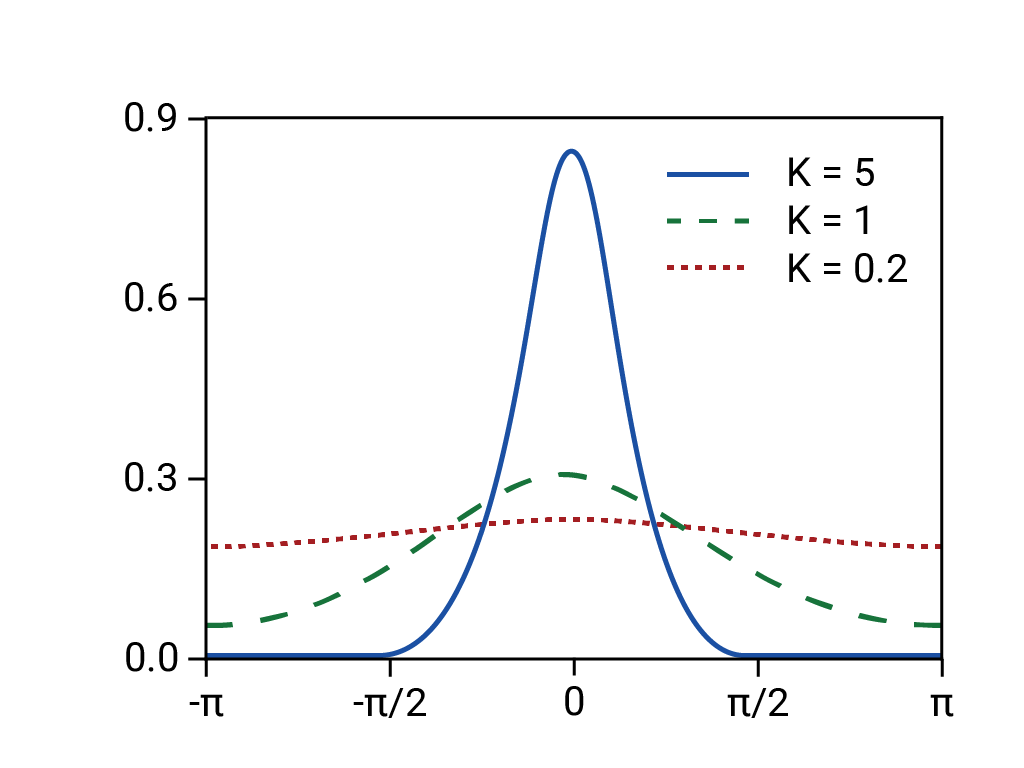
Na verdade, a distribuição subjacente era de cauda longa, "selvagem" ou fractal, o que significa que havia um risco muito maior de eventos raros, extremos e de cauda longa do que uma distribuição normal poderia prever. A natureza de cauda longa da distribuição real era bem conhecida, mas não foi usada. O que era menos conhecido era o quão complexos e intimamente acoplados eram vários fenômenos, incluindo negociações baseadas em computadores com vendas automáticas.11
Problemas de agregação
Os dados agregados, que incluem a maioria dos dados demográficos e epidemiológicos, estão sujeitos a um conjunto específico de armadilhas. O paradoxo de Simpson ou o paradoxo de agregação ocorre em dados agregados em que tendências aparentes desaparecem ou se invertem quando os dados são agregados em um nível diferente devido a fatores de confusão e relações causais mal interpretadas.
A falácia ecológica envolve extrapolar erroneamente informações sobre uma população em um nível de agregação para outro, em que a declaração pode não ser válida. Uma doença que afeta 40% dos trabalhadores agrícolas em uma província pode não estar presente na mesma prevalência na população maior. Também é muito provável que haja fazendas isoladas ou cidades agrícolas nessa província que não estão com uma prevalência semelhantemente alta dessa doença. Seria enganoso supor uma prevalência de 40% nesses lugares menos afetados.
O problema de unidade areal modificável (MAUP, na sigla em inglês) é um problema conhecido em dados geoespaciais, descrito por Stan Openshaw em 1984 na CATMOG 38. Dependendo das formas e dos tamanhos das áreas usadas para agregar dados, um profissional de dados geoespaciais pode estabelecer quase qualquer correlação entre as variáveis. Desenhar distritos eleitorais que favorecem um partido ou outro é um exemplo de MAUP.
Todas essas situações envolvem extrapolação inadequada de um nível de agregação para outro. Diferentes níveis de análise podem exigir agregações diferentes ou até mesmo conjuntos de dados totalmente diferentes.12
Os dados de censo, demográficos e epidemiológicos geralmente são agregados por zonas por motivos de privacidade, e essas zonas geralmente são arbitrárias, ou seja, não são baseadas em limites reais significativos. Ao trabalhar com esses tipos de dados, os profissionais de ML precisam verificar se o desempenho e as previsões do modelo mudam dependendo do tamanho e da forma das zonas selecionadas ou do nível de agregação. Se sim, verifique se as previsões do modelo são afetadas por um desses problemas de agregação.
Referências
Button, Katharine et al. "Power failure: why small sample size undermines the reliability of neuroscience." Nature Reviews Neuroscience vol 14 (2013), 365–376. DOI: https://doi.org/10.1038/nrn3475
Cairo, Alberto. How Charts Lie: Getting Smarter about Visual Information. NY: W.W. Norton, 2019.
Davenport, Thomas H. "A Predictive Analytics Primer" (em inglês). In HBR Guide to Data Analytics Basics for Managers (Boston: HBR Press, 2018) 81-86.
De Langhe, Bart, Stefano Puntoni e Richard Larrick. "Pensamento linear em um mundo não linear". In HBR Guide to Data Analytics Basics for Managers (Boston: HBR Press, 2018) 131-154.
Ellenberg, Jordan. How Not to Be Wrong: The Power of Mathematical Thinking. NY: Penguin, 2014.
Huff, Darrell. Como mentir com estatísticas. NY: W.W. Norton, 1954.
Jones, Ben. Como evitar armadilhas de dados. Hoboken, NJ: Wiley, 2020.
Openshaw, Stan. "The Modifiable Areal Unit Problem", CATMOG 38 (Norwich, England: Geo Books 1984) 37.
The Risks of Financial Modeling: VaR and the Economic Meltdown, 111th Congress (2009) (testimonies of Nassim N. Taleb e Richard Bookstaber).
Ritter, David. "When to Act on a Correlation, and When Not To" (Quando agir em relação a uma correlação e quando não agir). In HBR Guide to Data Analytics Basics for Managers (Boston: HBR Press, 2018) 103-109.
Tulchinsky, Theodore H. e Elena A. Varavikova. "Capítulo 3: Medição, monitoramento e avaliação da saúde de uma população" em The New Public Health, 3ª ed. San Diego: Academic Press, 2014, pp 91-147. DOI: https://doi.org/10.1016/B978-0-12-415766-8.00003-3.
Van Doorn, Jenny, Peter C. Verhoef e Tammo H. A. Bijmolt. "A importância das relações não lineares entre atitude e comportamento na pesquisa de políticas". Journal of Consumer Policy 30 (2007) 75–90. DOI: https://doi.org/10.1007/s10603-007-9028-3
Referência de imagem
Com base na "Distribuição de Von Mises". Rainald62, 2018. Origem
{kind=link}
-
Ellenberg 125. ↩
-
Huff 77-79. Huff cita o escritório de pesquisa de opinião pública de Princeton, mas ele pode ter pensado no relatório de abril de 1944 do National Opinion Research Center da Universidade de Denver. ↩
-
Tulchinsky e Varavikova. ↩
-
Gary Taubes, Do We Really Know What Makes Us Healthy?" em The New York Times Magazine, 16 de setembro de 2007. ↩
-
Ellenberg 78. ↩
-
Huff 91-92. ↩
-
Huff 93. ↩
-
Jones 157-167. ↩
-
Huff 95. ↩
-
Davenport 84. ↩
-
Confira o depoimento de Nassim N. no Congresso. Taleb e Richard Bookstaber em The Risks of Financial Modeling: VaR and the Economic Meltdown, 111th Congress (2009) 11-67. ↩
-
Cairo 155, 162. ↩