"Không có mô hình nào chính xác, nhưng có một số mô hình hữu ích". – George Box, 1978
Mặc dù rất mạnh mẽ, nhưng các kỹ thuật thống kê cũng có những hạn chế. Việc hiểu rõ những hạn chế này có thể giúp nhà nghiên cứu tránh được những sai lầm và tuyên bố không chính xác, chẳng hạn như khẳng định của BF Skinner rằng Shakespeare không sử dụng cách điệp âm nhiều hơn dự đoán ngẫu nhiên. (Nghiên cứu của Skinner không đủ mạnh.1)
Độ không chắc chắn và thanh lỗi
Bạn cần chỉ định mức độ không chắc chắn trong phân tích. Điều quan trọng không kém là việc định lượng mức độ không chắc chắn trong các phân tích của người khác. Các điểm dữ liệu có vẻ như vẽ một xu hướng trên biểu đồ, nhưng có các thanh lỗi chồng chéo, có thể không cho biết bất kỳ mẫu nào. Mức độ không chắc chắn cũng có thể quá cao để rút ra kết luận hữu ích từ một nghiên cứu hoặc kiểm thử thống kê cụ thể. Nếu một nghiên cứu yêu cầu độ chính xác ở cấp lô, thì tập dữ liệu không gian địa lý có độ không chắc chắn +/- 500 m sẽ có độ không chắc chắn quá lớn để có thể sử dụng.
Ngoài ra, các mức độ không chắc chắn có thể hữu ích trong quá trình đưa ra quyết định. Dữ liệu hỗ trợ một phương pháp xử lý nước cụ thể với 20% kết quả không chắc chắn có thể dẫn đến đề xuất triển khai phương pháp xử lý nước đó cùng với việc tiếp tục theo dõi chương trình để giải quyết sự không chắc chắn đó.
Mạng nơron Bayesian có thể định lượng mức độ không chắc chắn bằng cách dự đoán phân phối các giá trị thay vì các giá trị đơn lẻ.
Không liên quan
Như đã thảo luận trong phần giới thiệu, luôn có ít nhất một khoảng trống nhỏ giữa dữ liệu và thực tế. Người thực hành ML tinh ranh nên xác định xem tập dữ liệu có liên quan đến câu hỏi đang được đặt hay không.
Huff mô tả một nghiên cứu ban đầu về dư luận cho thấy rằng câu trả lời của người Mỹ da trắng đối với câu hỏi về mức độ dễ dàng để người Mỹ da đen có được cuộc sống tốt có mối quan hệ trực tiếp và nghịch đảo với mức độ đồng cảm của họ đối với người Mỹ da đen. Khi sự thù địch chủng tộc gia tăng, các câu trả lời về cơ hội kinh tế dự kiến ngày càng trở nên lạc quan. Điều này có thể bị hiểu nhầm là dấu hiệu của sự tiến bộ. Tuy nhiên, nghiên cứu này không thể cho biết điều gì về cơ hội kinh tế thực tế mà người Mỹ gốc Phi có được vào thời điểm đó và không phù hợp để đưa ra kết luận về thực tế của thị trường việc làm – chỉ là ý kiến của những người trả lời cuộc khảo sát. Dữ liệu được thu thập thực tế không liên quan đến tình trạng của thị trường việc làm.2
Bạn có thể huấn luyện mô hình trên dữ liệu khảo sát như mô tả ở trên, trong đó kết quả thực sự đo lường thái độ lạc quan thay vì cơ hội. Tuy nhiên, vì cơ hội dự đoán không liên quan đến cơ hội thực tế, nên nếu bạn cho rằng mô hình đang dự đoán cơ hội thực tế, thì bạn sẽ trình bày sai nội dung mà mô hình dự đoán.
Biến gây nhiễu
Biến gây nhiễu, biến nhiễu hoặc hệ số phụ là một biến không được nghiên cứu nhưng ảnh hưởng đến các biến đang được nghiên cứu và có thể làm sai lệch kết quả. Ví dụ: hãy xem xét một mô hình học máy dự đoán tỷ lệ tử vong cho một quốc gia đầu vào dựa trên các đặc điểm chính sách y tế công cộng. Giả sử độ tuổi trung bình không phải là một tính năng. Giả sử thêm rằng một số quốc gia có dân số lớn tuổi hơn so với các quốc gia khác. Khi bỏ qua biến gây nhiễu là tuổi trung bình, mô hình này có thể dự đoán sai tỷ lệ tử vong.
Ở Hoa Kỳ, chủng tộc thường có mối tương quan chặt chẽ với tầng lớp kinh tế xã hội, mặc dù chỉ có chủng tộc chứ không phải tầng lớp được ghi nhận bằng dữ liệu về tỷ lệ tử vong. Các yếu tố gây nhiễu liên quan đến giai cấp, chẳng hạn như khả năng tiếp cận dịch vụ y tế, dinh dưỡng, công việc nguy hiểm và nhà ở an toàn, có thể ảnh hưởng nhiều hơn đến tỷ lệ tử vong so với chủng tộc, nhưng lại bị bỏ qua vì không có trong tập dữ liệu.3 Việc xác định và kiểm soát các yếu tố gây nhiễu này là rất quan trọng để xây dựng các mô hình hữu ích và rút ra kết luận có ý nghĩa và chính xác.
Nếu được huấn luyện dựa trên dữ liệu hiện có về tỷ lệ tử vong, bao gồm cả chủng tộc nhưng không bao gồm lớp, thì mô hình có thể dự đoán tỷ lệ tử vong dựa trên chủng tộc, ngay cả khi lớp là yếu tố dự đoán tỷ lệ tử vong mạnh hơn. Điều này có thể dẫn đến các giả định không chính xác về mối quan hệ nhân quả và dự đoán không chính xác về tỷ lệ tử vong của bệnh nhân. Những người thực hành học máy nên hỏi xem liệu có yếu tố gây nhiễu trong dữ liệu của họ hay không, cũng như những biến có ý nghĩa nào có thể bị thiếu trong tập dữ liệu của họ.
Năm 1985, Nghiên cứu sức khoẻ của nữ y tá, một nghiên cứu thuần tập quan sát từ Trường Y Harvard và Trường Y tế công cộng Harvard, cho thấy rằng những thành viên trong nhóm thuần tập dùng liệu pháp thay thế estrogen có tỷ lệ mắc bệnh tim thấp hơn so với những thành viên trong nhóm thuần tập chưa từng dùng estrogen. Do đó, các bác sĩ đã kê toa estrogen cho bệnh nhân mãn kinh và sau mãn kinh trong nhiều thập kỷ, cho đến khi một nghiên cứu lâm sàng vào năm 2002 xác định được các nguy cơ sức khoẻ do liệu pháp estrogen dài hạn gây ra. Việc kê toa estrogen cho phụ nữ sau mãn kinh đã dừng lại, nhưng không phải trước khi gây ra hàng chục nghìn trường hợp tử vong sớm.
Có thể có nhiều yếu tố gây nhiễu đã gây ra mối liên kết này. Các nhà dịch tễ học nhận thấy rằng so với những phụ nữ không dùng liệu pháp thay thế hormone, những phụ nữ dùng liệu pháp này có xu hướng gầy hơn, có trình độ học vấn cao hơn, giàu có hơn, có ý thức hơn về sức khoẻ và có nhiều khả năng tập thể dục hơn. Trong nhiều nghiên cứu, người ta nhận thấy rằng trình độ học vấn và tài sản giúp giảm nguy cơ mắc bệnh tim. Những tác động đó sẽ làm rối loạn mối tương quan rõ ràng giữa liệu pháp estrogen và các cơn đau tim.4
Tỷ lệ phần trăm có số âm
Tránh sử dụng tỷ lệ phần trăm khi có số âm,5 vì tất cả các loại lãi và lỗ có ý nghĩa đều có thể bị che khuất. Giả sử, để đơn giản hoá phép tính, ngành nhà hàng có 2 triệu việc làm. Nếu ngành này mất 1 triệu công việc trong số đó vào cuối tháng 3 năm 2020, không có thay đổi nào về tổng số công việc trong 10 tháng và có lại 900.000 công việc vào đầu tháng 2 năm 2021, thì so sánh giữa các năm vào đầu tháng 3 năm 2021 sẽ cho thấy chỉ có 5% số lượng công việc trong nhà hàng bị mất. Giả sử không có thay đổi nào khác, thì kết quả so sánh giữa các năm vào cuối tháng 4 năm 2021 cho thấy số lượng việc làm tại nhà hàng tăng 90%. Đây là một bức tranh rất khác so với thực tế.
Ưu tiên số thực, được chuẩn hoá cho phù hợp. Hãy xem phần Xử lý dữ liệu số để biết thêm thông tin.
Lỗi ngụy biện sau đó và mối tương quan không sử dụng được
Sự ngộ nhận sau khi xảy ra sự kiện là giả định rằng, vì sự kiện A theo sau là sự kiện B, nên sự kiện A đã gây ra sự kiện B. Nói một cách đơn giản hơn, đó là giả định một mối quan hệ nhân quả không tồn tại. Nói một cách đơn giản hơn: mối tương quan không chứng minh được mối quan hệ nhân quả.
Ngoài mối quan hệ nhân quả rõ ràng, mối tương quan cũng có thể phát sinh từ:
- Tình cờ thuần tuý (xem bài viết Mối tương quan giả mạo của Tyler Vigen để biết ví dụ minh hoạ, bao gồm cả mối tương quan chặt chẽ giữa tỷ lệ ly hôn ở Maine và mức tiêu thụ bơ thực vật).
- Một mối quan hệ thực tế giữa hai biến, mặc dù vẫn chưa rõ biến nào là nguyên nhân và biến nào chịu ảnh hưởng.
- Một nguyên nhân thứ ba, riêng biệt ảnh hưởng đến cả hai biến, mặc dù các biến có liên quan không liên quan đến nhau. Ví dụ: lạm phát toàn cầu có thể làm tăng giá cả của cả du thuyền và cần tây.6
Việc ngoại suy mối tương quan ngoài dữ liệu hiện có cũng có rủi ro. Huff chỉ ra rằng một lượng mưa vừa phải sẽ cải thiện cây trồng, nhưng quá nhiều mưa sẽ làm hỏng cây trồng; mối quan hệ giữa lượng mưa và kết quả cây trồng là phi tuyến tính.7 (Xem hai phần tiếp theo để biết thêm về mối quan hệ phi tuyến tính.) Jones lưu ý rằng thế giới đầy những sự kiện không thể dự đoán, chẳng hạn như chiến tranh và nạn đói, khiến các dự báo trong tương lai về dữ liệu chuỗi thời gian phải chịu rất nhiều sự không chắc chắn.8
Hơn nữa, ngay cả mối tương quan thực sự dựa trên nguyên nhân và kết quả cũng có thể không giúp ích gì cho việc đưa ra quyết định. Huff đưa ra ví dụ về mối tương quan giữa khả năng kết hôn và giáo dục đại học trong những năm 1950. Những phụ nữ học đại học ít có khả năng kết hôn, nhưng có thể những phụ nữ học đại học ngay từ đầu đã ít có xu hướng kết hôn. Nếu vậy, việc học đại học sẽ không làm thay đổi khả năng kết hôn của họ.9
Nếu một số liệu phân tích phát hiện mối tương quan giữa hai biến trong một tập dữ liệu, hãy hỏi:
- Đó là loại tương quan nào: nguyên nhân và kết quả, giả tạo, mối quan hệ không xác định hay do một biến thứ ba gây ra?
- Việc ngoại suy từ dữ liệu có rủi ro như thế nào? Mọi dự đoán của mô hình về dữ liệu không có trong tập dữ liệu huấn luyện đều là nội suy hoặc ngoại suy từ dữ liệu.
- Có thể sử dụng mối tương quan này để đưa ra quyết định hữu ích không? Ví dụ: sự lạc quan có thể có mối tương quan mạnh mẽ với việc tăng lương, nhưng việc phân tích cảm xúc của một số tập hợp dữ liệu văn bản lớn, chẳng hạn như bài đăng trên mạng xã hội của người dùng ở một quốc gia cụ thể, sẽ không hữu ích để dự đoán mức tăng lương ở quốc gia đó.
Khi huấn luyện mô hình, các nhà thực hành học máy thường tìm kiếm các đặc điểm có liên quan chặt chẽ với nhãn. Nếu bạn không hiểu rõ mối quan hệ giữa các đặc điểm và nhãn, điều này có thể dẫn đến các vấn đề được mô tả trong phần này, bao gồm cả các mô hình dựa trên mối tương quan giả mạo và các mô hình giả định rằng xu hướng trong quá khứ sẽ tiếp tục trong tương lai, trong khi thực tế thì không.
Thiên kiến tuyến tính
Trong bài viết "Tư duy tuyến tính trong thế giới phi tuyến tính", Bart de Langhe, Stefano Puntoni và Richard Larrick mô tả thiên kiến tuyến tính là xu hướng của não bộ con người trong việc mong đợi và tìm kiếm mối quan hệ tuyến tính, mặc dù nhiều hiện tượng là phi tuyến tính. Ví dụ: mối quan hệ giữa thái độ và hành vi của con người là một đường cong lồi chứ không phải một đường thẳng. Trong một bài báo trên Tạp chí chính sách tiêu dùng năm 2007 do de Langhe và cộng sự trích dẫn, Jenny van Doorn và cộng sự đã lập mô hình mối quan hệ giữa mối lo ngại của người trả lời cuộc khảo sát về môi trường và việc người trả lời mua sản phẩm hữu cơ. Những người có mối lo ngại nghiêm trọng nhất về môi trường đã mua nhiều sản phẩm hữu cơ hơn, nhưng giữa tất cả những người trả lời khác thì có rất ít sự khác biệt.
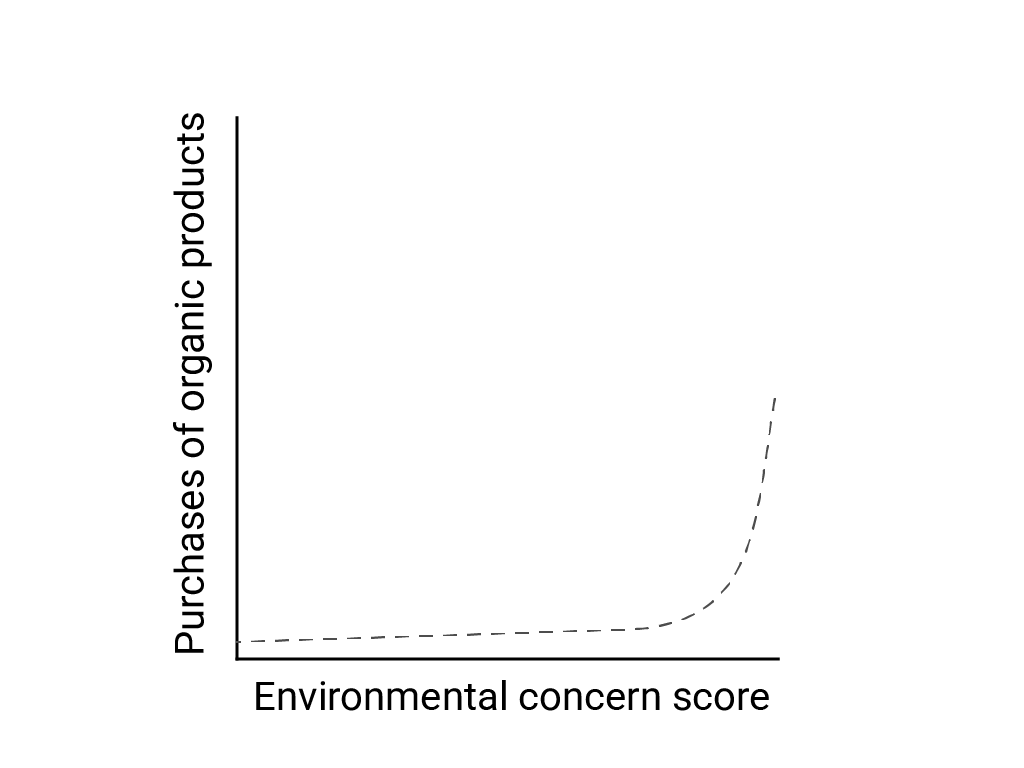
Khi thiết kế mô hình hoặc nghiên cứu, hãy cân nhắc khả năng có mối quan hệ phi tuyến tính. Vì thử nghiệm A/B có thể bỏ lỡ các mối quan hệ phi tuyến tính, nên bạn cũng nên cân nhắc thử nghiệm một điều kiện thứ ba, trung gian, là C. Ngoài ra, hãy cân nhắc xem hành vi ban đầu có vẻ tuyến tính có tiếp tục tuyến tính hay không, hoặc liệu dữ liệu trong tương lai có thể cho thấy hành vi logarit hoặc hành vi phi tuyến tính khác hay không.
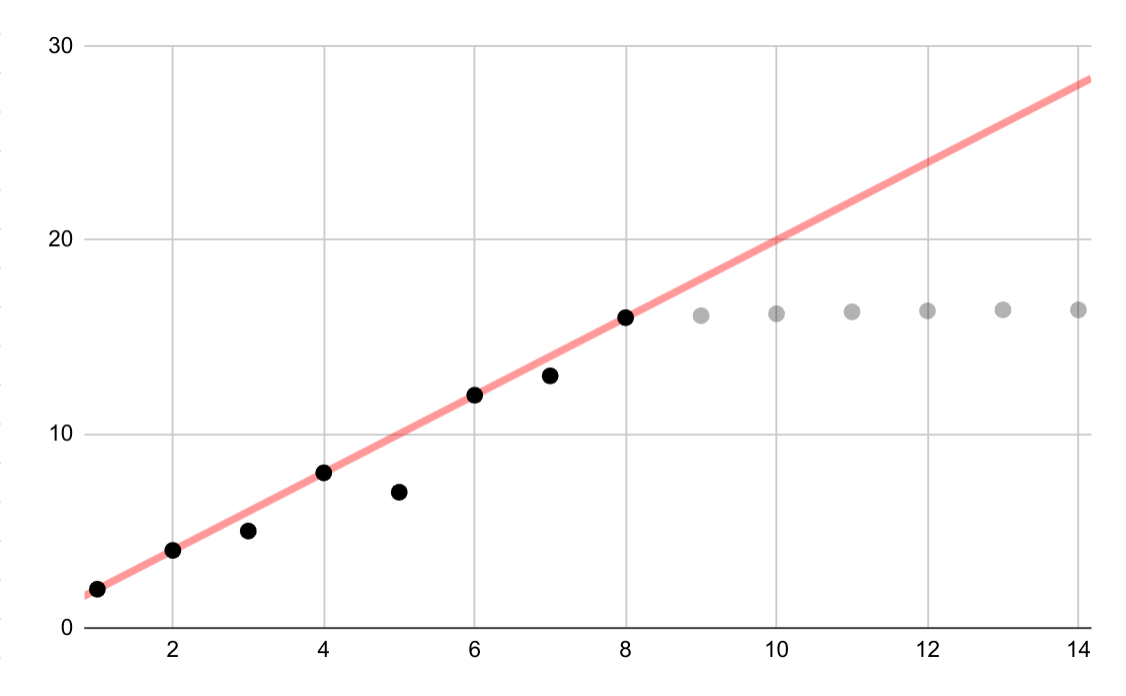
Ví dụ giả định này cho thấy một đường phù hợp tuyến tính không chính xác cho dữ liệu logarit. Nếu chỉ có một vài điểm dữ liệu đầu tiên, bạn sẽ có xu hướng giả định mối quan hệ tuyến tính liên tục giữa các biến, nhưng điều này là không chính xác.
Nội suy tuyến tính
Kiểm tra mọi nội suy giữa các điểm dữ liệu, vì nội suy sẽ đưa ra các điểm hư cấu và khoảng thời gian giữa các phép đo thực tế có thể chứa các biến động có ý nghĩa. Ví dụ: hãy xem xét hình ảnh trực quan sau đây về bốn điểm dữ liệu được kết nối bằng phép nội suy tuyến tính:

Sau đó, hãy xem xét ví dụ sau về sự biến động giữa các điểm dữ liệu bị xoá bằng phép nội suy tuyến tính:
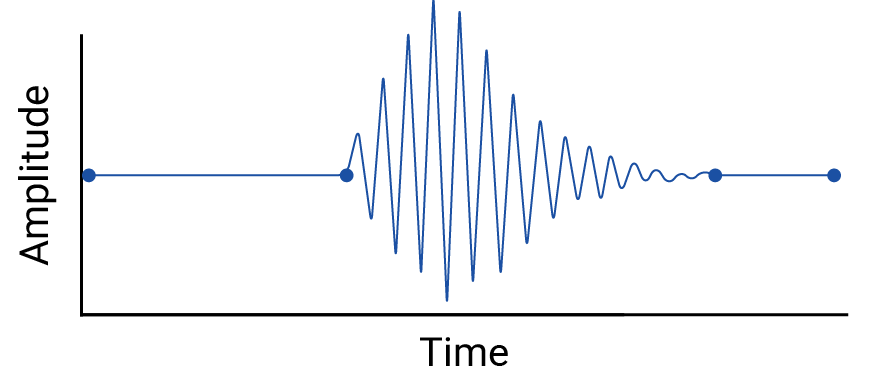
Ví dụ này được tạo ra vì máy đo địa chấn thu thập dữ liệu liên tục, do đó, sẽ không bỏ lỡ trận động đất này. Tuy nhiên, phương pháp này hữu ích để minh hoạ các giả định được thực hiện bằng nội suy và các hiện tượng thực tế mà các nhà thực hành dữ liệu có thể bỏ lỡ.
Hiện tượng Runge
Hiện tượng Runge, còn được gọi là "độ nhấp nháy đa thức", là một vấn đề ở đầu đối diện của phổ từ nội suy tuyến tính và độ lệch tuyến tính. Khi điều chỉnh một nội suy đa thức cho dữ liệu, bạn có thể sử dụng một đa thức có bậc quá cao (bậc hoặc thứ tự là số mũ cao nhất trong phương trình đa thức). Điều này tạo ra các dao động kỳ lạ ở các cạnh. Ví dụ: áp dụng phép nội suy đa thức bậc 11, nghĩa là hạng cao nhất trong phương trình đa thức có \(x^{11}\), cho dữ liệu gần như tuyến tính, dẫn đến kết quả dự đoán rất kém ở đầu và cuối phạm vi dữ liệu:
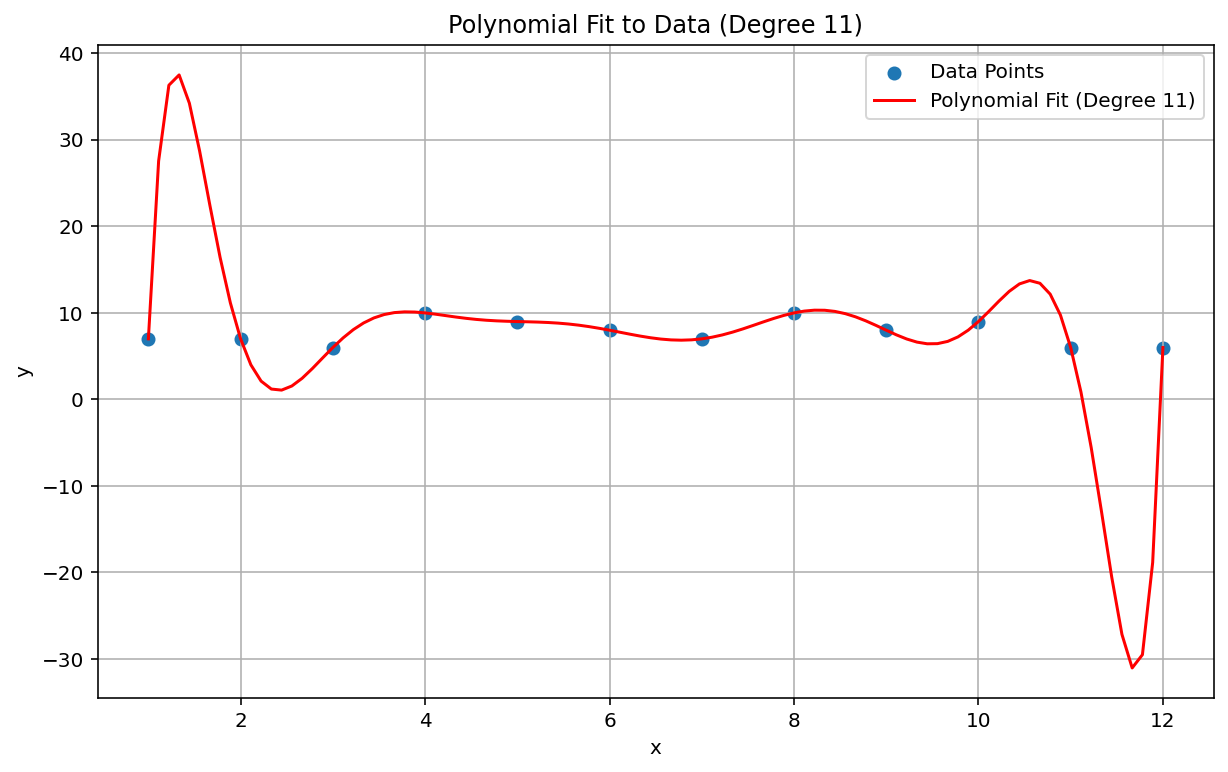
Trong bối cảnh học máy, một hiện tượng tương tự là quá thích ứng.
Không phát hiện được lỗi thống kê
Đôi khi, một kiểm thử thống kê có thể quá yếu để phát hiện một hiệu ứng nhỏ. Mức độ hiệu quả thấp trong phân tích thống kê có nghĩa là khả năng xác định chính xác các sự kiện thực tế thấp, do đó, khả năng âm tính giả cao. Katherine Button và cộng sự đã viết trong Nature: "Khi các nghiên cứu trong một lĩnh vực nhất định được thiết kế với sức mạnh là 20%, điều đó có nghĩa là nếu có 100 hiệu ứng không rỗng thực sự cần được phát hiện trong lĩnh vực đó, thì các nghiên cứu này dự kiến sẽ chỉ phát hiện được 20 hiệu ứng trong số đó". Đôi khi, việc tăng cỡ mẫu cũng có thể giúp ích, cũng như việc thiết kế nghiên cứu một cách cẩn thận.
Một tình huống tương tự trong ML là vấn đề phân loại và lựa chọn ngưỡng phân loại. Việc chọn ngưỡng cao hơn sẽ dẫn đến ít kết quả dương tính giả hơn và nhiều kết quả âm tính giả hơn, trong khi ngưỡng thấp hơn sẽ dẫn đến nhiều kết quả dương tính giả hơn và ít kết quả âm tính giả hơn.
Ngoài các vấn đề về sức mạnh thống kê, vì hệ số tương quan được thiết kế để phát hiện mối quan hệ tuyến tính, nên có thể bỏ lỡ các mối quan hệ phi tuyến tính giữa các biến. Tương tự, các biến có thể liên quan đến nhau nhưng không có mối tương quan thống kê. Các biến cũng có thể có mối tương quan âm nhưng hoàn toàn không liên quan, được gọi là nghịch lý Berkson hoặc sai lầm Berkson. Ví dụ kinh điển về lỗi Berkson là mối tương quan âm giả tạo giữa bất kỳ yếu tố nguy cơ nào và bệnh nặng khi xem xét một nhóm bệnh nhân nội trú tại bệnh viện (so với dân số nói chung), điều này phát sinh từ quá trình lựa chọn (một tình trạng đủ nghiêm trọng để yêu cầu nhập viện).
Hãy cân nhắc xem bạn có gặp phải trường hợp nào trong số này không.
Mô hình đã lỗi thời và giả định không hợp lệ
Ngay cả các mô hình tốt cũng có thể giảm hiệu suất theo thời gian vì hành vi (và thế giới, đối với vấn đề đó) có thể thay đổi. Netflix đã phải ngừng sử dụng các mô hình dự đoán ban đầu vì cơ sở khách hàng của họ đã thay đổi từ những người dùng trẻ, am hiểu công nghệ thành cộng đồng nói chung.10
Mô hình cũng có thể chứa các giả định ẩn và không chính xác có thể vẫn bị ẩn cho đến khi mô hình gặp sự cố nghiêm trọng, như trong sự cố thị trường năm 2008. Các mô hình Giá trị rủi ro (VaR) của ngành tài chính tuyên bố ước tính chính xác mức lỗ tối đa trong danh mục đầu tư của bất kỳ nhà giao dịch nào, giả sử mức lỗ tối đa là 100.000 đô la Mỹ trong 99% trường hợp. Tuy nhiên, trong điều kiện bất thường của sự cố, một danh mục đầu tư có mức lỗ tối đa dự kiến là $100.000 đôi khi mất $1.000.000 trở lên.
Các mô hình VaR dựa trên các giả định không chính xác, bao gồm:
- Những thay đổi trước đây của thị trường có thể dự đoán những thay đổi trong tương lai của thị trường.
- Phân phối chuẩn (đuôi mỏng và do đó có thể dự đoán) là cơ sở của lợi tức dự đoán.
Trên thực tế, phân phối cơ bản là đuôi béo, "ngẫu nhiên" hoặc fractal, nghĩa là có nguy cơ cao hơn nhiều về các sự kiện đuôi dài, cực đoan và được cho là hiếm hơn so với dự đoán của phân phối chuẩn. Bản chất đuôi béo của phân phối thực tế đã được biết đến rộng rãi, nhưng không được áp dụng. Điều ít được biết đến là mức độ phức tạp và liên kết chặt chẽ của nhiều hiện tượng, bao gồm cả giao dịch dựa trên máy tính với các hoạt động bán tự động.11
Vấn đề về dữ liệu tổng hợp
Dữ liệu được tổng hợp, bao gồm hầu hết dữ liệu nhân khẩu học và dịch tễ học, phải tuân theo một bộ bẫy cụ thể. Tình huống nghịch lý của Simpson, hay tình huống nghịch lý của sự hợp nhất, xảy ra trong dữ liệu tổng hợp, trong đó các xu hướng rõ ràng biến mất hoặc đảo ngược khi dữ liệu được tổng hợp ở một cấp khác, do các yếu tố gây nhiễu và mối quan hệ nhân quả bị hiểu lầm.
Sai lầm về sinh thái liên quan đến việc ngoại suy nhầm thông tin về một quần thể ở một cấp độ tổng hợp sang một cấp độ tổng hợp khác, trong đó tuyên bố có thể không hợp lệ. Một căn bệnh ảnh hưởng đến 40% người lao động nông nghiệp ở một tỉnh có thể không có cùng mức độ phổ biến trong dân số lớn hơn. Cũng rất có thể sẽ có những trang trại hoặc thị trấn nông nghiệp biệt lập trong tỉnh đó không có tỷ lệ mắc bệnh tương tự. Việc giả định tỷ lệ mắc bệnh là 40% ở những nơi ít bị ảnh hưởng cũng là một sai lầm.
Vấn đề về đơn vị diện tích có thể sửa đổi (MAUP) là một vấn đề nổi tiếng trong dữ liệu không gian địa lý, do Stan Openshaw mô tả vào năm 1984 trong CATMOG 38. Tuỳ thuộc vào hình dạng và kích thước của các khu vực dùng để tổng hợp dữ liệu, người thực hành dữ liệu không gian địa lý có thể thiết lập hầu hết mọi mối tương quan giữa các biến trong dữ liệu. Việc vẽ các khu vực bỏ phiếu có lợi cho một đảng phái hoặc đảng phái khác là một ví dụ về MAUP.
Tất cả các trường hợp này đều liên quan đến việc ngoại suy không phù hợp từ một cấp độ tổng hợp sang cấp độ tổng hợp khác. Các cấp độ phân tích khác nhau có thể yêu cầu các phương thức tổng hợp khác nhau hoặc thậm chí là các tập dữ liệu hoàn toàn khác nhau.12
Xin lưu ý rằng dữ liệu điều tra dân số, nhân khẩu học và dịch tễ học thường được tổng hợp theo khu vực vì lý do bảo vệ quyền riêng tư. Các khu vực này thường là tuỳ ý, tức là không dựa trên các ranh giới có ý nghĩa trong thực tế. Khi làm việc với các loại dữ liệu này, người thực hành học máy nên kiểm tra xem hiệu suất và dự đoán của mô hình có thay đổi tuỳ thuộc vào kích thước và hình dạng của các vùng được chọn hay mức độ tổng hợp hay không, và nếu có, liệu dự đoán của mô hình có bị ảnh hưởng bởi một trong những vấn đề tổng hợp này hay không.
Tài liệu tham khảo
Button, Katharine và cộng sự. "Lỗi nguồn: lý do kích thước mẫu nhỏ làm giảm độ tin cậy của khoa học thần kinh". Nature Reviews Neuroscience, tập 14 (2013), 365–376. DOI: https://doi.org/10.1038/nrn3475
Cairo, Alberto. How Charts Lie: Getting Smarter about Visual Information (Biểu đồ nói dối: Tìm hiểu thông tin trực quan một cách thông minh hơn). NY: W.W. Norton, 2019.
Davenport, Thomas H. "A Predictive Analytics Primer" (Giới thiệu về số liệu phân tích dự đoán). Trong HBR Guide to Data Analytics Basics for Managers (Hướng dẫn của HBR về Kiến thức cơ bản về phân tích dữ liệu dành cho nhà quản lý) (Boston: HBR Press, 2018) 81-86.
De Langhe, Bart, Stefano Puntoni và Richard Larrick. "Tư duy tuyến tính trong một thế giới phi tuyến tính". Trong HBR Guide to Data Analytics Basics for Managers (Hướng dẫn của HBR về kiến thức cơ bản về phân tích dữ liệu dành cho nhà quản lý) (Boston: HBR Press, 2018) trang 131-154.
Ellenberg, Jordan. How Not to Be Wrong: The Power of Mathematical Thinking (Cách không sai lầm: Sức mạnh của tư duy toán học). New York: Penguin, 2014.
Huff, Darrell. Cách nói dối bằng số liệu thống kê. NY: W.W. Norton, 1954.
Jones, Ben. Tránh các cạm bẫy về dữ liệu. Hoboken, NJ: Wiley, 2020.
Openshaw, Stan. "The Modifiable Areal Unit Problem" (Vấn đề về đơn vị diện tích có thể sửa đổi), CATMOG 38 (Norwich, Anh: Geo Books 1984) 37.
Rủi ro của mô hình tài chính: VaR và sự sụp đổ kinh tế, Đại hội lần thứ 111 (2009) (tuyên bố của Nassim N. Taleb và Richard Bookstaber).
Ritter, David. "Thời điểm nên và không nên hành động dựa trên mối tương quan". Trong HBR Guide to Data Analytics Basics for Managers (Hướng dẫn của HBR về Kiến thức cơ bản về phân tích dữ liệu dành cho nhà quản lý) (Boston: HBR Press, 2018) 103-109.
Tulchinsky, Theodore H. và Elena A. Varavikova. "Chương 3: Đo lường, theo dõi và đánh giá sức khoẻ của một cộng đồng" trong The New Public Health (Công tác y tế công cộng mới), ấn bản thứ 3. San Diego: Academic Press, 2014, trang 91-147. DOI: https://doi.org/10.1016/B978-0-12-415766-8.00003-3.
Van Doorn, Jenny, Peter C. Verhoef và Tammo H. A. Bijmolt. "Tầm quan trọng của mối quan hệ phi tuyến tính giữa thái độ và hành vi trong nghiên cứu chính sách". Journal of Consumer Policy 30 (2007) 75–90. DOI: https://doi.org/10.1007/s10603-007-9028-3
Hình ảnh tham khảo
Dựa trên "Phân phối Von Mises". Rainald62, 2018. Nguồn
{kind=link}
-
Ellenberg 125. ↩
-
Huff 77-79. Huff trích dẫn Văn phòng Nghiên cứu dư luận công chúng của Đại học Princeton, nhưng có thể ông đang nghĩ đến báo cáo tháng 4 năm 1944 của Trung tâm Nghiên cứu dư luận quốc gia tại Đại học Denver. ↩
-
Tulchinsky và Varavikova. ↩
-
Gary Taubes, Chúng ta có thực sự biết điều gì giúp chúng ta khỏe mạnh không?" trên The New York Times Magazine, ngày 16 tháng 9 năm 2007. ↩
-
Ellenberg 78. ↩
-
Huff 91-92. ↩
-
Huff 93. ↩
-
Jones 157-167. ↩
-
Huff 95. ↩
-
Davenport 84. ↩
-
Xem lời khai của Nassim N. trước Quốc hội Taleb và Richard Bookstaber trong The Risks of Financial Modeling: VaR and the Economic Meltdown (Rủi ro của mô hình tài chính: VaR và sự sụp đổ kinh tế), Quốc hội thứ 111 (2009) 11-67. ↩
-
Cairo 155, 162. ↩