「所有的模型都是錯的,但有些仍然有用。」— George Box,1978 年
雖然統計技術非常強大,但也有其限制。瞭解這些限制有助於研究人員避免失言和不準確的陳述,例如 BF Skinner 斷言莎士比亞並未使用比隨機性更頻繁的疊字。(Skinner 的研究缺乏統計力。1)
不確定性和誤差範圍
請務必在分析中指定不確定性。同樣重要的是,您也必須量化其他人分析結果中的不確定性。雖然資料點似乎在圖表上繪製出趨勢,但如果誤差範圍重疊,就可能完全沒有任何模式。不確定性也可能過高,無法從特定研究或統計測試中得出實用的結論。如果研究需要地塊層級的準確度,則 +/- 500 公尺的不確定性地理空間資料集,不確定性過高,無法使用。
或者,不確定性等級可能在決策過程中派上用場。若有資料指出特定水處理方式的結果有 20% 的不確定性,可能會建議實施該水處理方式,並持續監控該計畫,以解決不確定性問題。
貝葉斯神經網路可預測值的分布,而非單一值,藉此量化不確定性。
不相關
如前言所述,資料與現實之間總是會有一點差距。機器學習專家應確認資料集是否與問題相關。
Huff 提到,早期的一項民意調查發現,當白人被問到黑人是否容易過上好日子時,他們的回答與對黑人的同情程度呈現正相關和負相關。隨著種族敵意增加,對預期經濟機會的回應也越來越樂觀。這可能會被誤解為進展的跡象。不過,這項研究無法顯示當時美國黑人實際擁有的經濟機會,也不適合用來得出關於就業市場現實的結論,只能提供問卷調查受訪者的意見。收集到的資料其實與就業市場狀況無關。2
您可以根據上述的問卷調查資料訓練模型,實際上,輸出內容會評估「樂觀度」而非「商機」。不過,由於預測商機與實際商機無關,如果您聲稱模型可預測實際商機,就會誤導模型預測結果。
干擾因素
干擾變數、干擾或共變數是指未在研究中,但會影響研究中變數並可能扭曲結果的變數。舉例來說,假設有個機器學習模型,可根據公共衛生政策特徵,預測輸入國家/地區的死亡率。假設平均年齡不是特徵。再假設某些國家/地區的人口年齡較高。由於忽略了中位年齡的混淆變數,這個模型可能會預測出錯誤的死亡率。
在美國,種族通常與社會經濟階層密切相關,但死亡率資料只會記錄種族,而不會記錄階層。與階級相關的混淆因素 (例如醫療照護、營養、危險工作和安全住房的取得方式),可能會比種族更影響死亡率,但由於這些因素未納入資料集,因此容易遭到忽略3。如要建立實用的模型並得出有意義且準確的結論,就必須找出並控制這些混淆因素。
如果模型是根據現有的死亡率資料進行訓練,其中包含種族但不包含階級,則模型可能會根據種族預測死亡率,即使階級是更準確的死亡率預測指標也一樣。這可能會導致關於因果關係的錯誤假設,以及關於病患死亡率的錯誤預測。機器學習專家應詢問資料中是否存在混淆因素,以及資料集可能缺少哪些有意義的變數。
1985 年,哈佛醫學院和哈佛公共衛生學院進行的護理師健康研究 (Nurses' Health Study) 是一份觀察性世代研究,發現與從未服用雌激素的世代成員相比,服用雌激素替代療法的世代成員心臟病發作發生率較低。因此,醫師在數十年來都會為更年期和停經後的患者開立雌激素處方箋,直到 2002 年一項臨床研究指出長期使用雌激素療法可能帶來的健康風險。不過,這種為停經後女性開立雌激素的做法已停止,但據估計,這項做法已造成數萬人過早死亡。
這可能與多種混淆因素有關。流行病學家發現,與不接受荷爾蒙替代療法的女性相比,接受療法的女性通常體型較瘦、受教育程度較高、較富有、較注重健康,也較常運動。在不同的研究中,教育和財富都被發現有助於降低心臟病風險。這些影響會混淆雌激素療法與心肌梗塞之間的明顯關聯。4
含有負數的百分比
出現負數時,請避免使用百分比5,因為這可能會掩蓋所有有意義的收益和損失。為了簡化計算,假設餐飲業有 200 萬個職缺。如果餐飲業在 2020 年 3 月底失去 100 萬個工作機會,且在接下來的 10 個月內沒有淨變化,並在 2021 年 2 月初回復 900,000 個工作機會,那麼在 2021 年 3 月初進行的年度比較,就會顯示餐飲業僅損失 5% 的工作機會。假設沒有其他變化,2021 年 4 月底的年度比較結果顯示餐廳工作增加了 90%,但實際情況並非如此。
請盡量使用實際數字,並視情況進行標準化。詳情請參閱「使用數值資料」。
事後諸葛亮和不可靠的相關性
事後謬誤是指假設事件 A 發生後,事件 B 也隨之發生,因此事件 A 導致事件 B。簡單來說,這類錯誤是假設不存在的因果關係。更簡單地說:關聯性並不能證明因果關係。
除了明確的因果關係外,相關性也可能來自下列因素:
- 純粹是偶然 (請參閱 Tyler Vigen 的Spurious correlations,其中說明瞭緬因州離婚率與人造奶油消費量之間的強烈關聯)。
- 兩個變數之間的實際關係,但目前尚不清楚哪個變數是起因,哪個是受影響的變數。
- 第三個獨立原因會影響兩個變數,但相關變數彼此不相關。舉例來說,全球通貨膨脹會導致遊艇和芹菜的價格上漲。6
同樣地,推斷超出現有資料的關聯也存在風險。Huff 指出,適量的降雨會改善作物,但過多的降雨會損害作物;降雨與作物結果之間的關係是非線性的7。如要進一步瞭解非線性關係,請參閱接下來兩個章節。Jones 指出,世界充滿許多無法預測的事件 (例如戰爭和饑荒),因此時間序列資料的未來預測結果會受到極大不確定性影響。8
此外,即使是基於因果關係的真實關聯性,也未必有助於做出決策。舉例來說,Huff 指出 1950 年代婚姻可能性與大學教育之間的關聯。上過大學的女性較不容易結婚,但也可能是上過大學的女性一開始就比較不想結婚。如果是這種情況,大學教育就不會影響他們結婚的可能性。9
如果分析偵測到資料集中兩個變數之間的關聯性,請問:
- 這是什麼類型的關聯:因果關係、虛假關係、不明關係,還是由第三個變數造成的關係?
- 從資料推論的風險有多高?對於不在訓練資料集中的資料,每個模型預測結果實際上都是從資料進行插補或外推。
- 這項相關性是否可用於做出實用的決策?舉例來說,樂觀主義可能與薪資上漲有強烈的相關性,但對某些大量文字資料 (例如特定國家/地區使用者在社群媒體上的貼文) 進行情緒分析,並不會有助於預測該國家/地區的薪資上漲情形。
訓練模型時,機器學習專家通常會尋找與標籤高度相關的特徵。如果您不清楚特徵和標籤之間的關係,就可能導致本節所述的問題,包括建立以虛假相關性為基礎的模型,以及假設歷史趨勢會持續存在 (但實際上並非如此) 的模型。
線性偏誤
在「在非線性世界中進行線性思考」一文中,Bart de Langhe、Stefano Puntoni 和 Richard Larrick 將線性偏誤定義為人腦傾向於預期和尋找線性關係,儘管許多現象都是非線性的。舉例來說,人類態度與行為之間的關係是凸曲線,而不是直線。在 2007 年由 de Langhe 等人引用的《消費者政策期刊》論文中,Jenny van Doorn 等人模擬了問卷調查對象對環境的關注程度,以及他們購買有機產品的關係。對環境最為關切的受訪者購買有機產品的比例較高,但其他受訪者之間的差異不大。
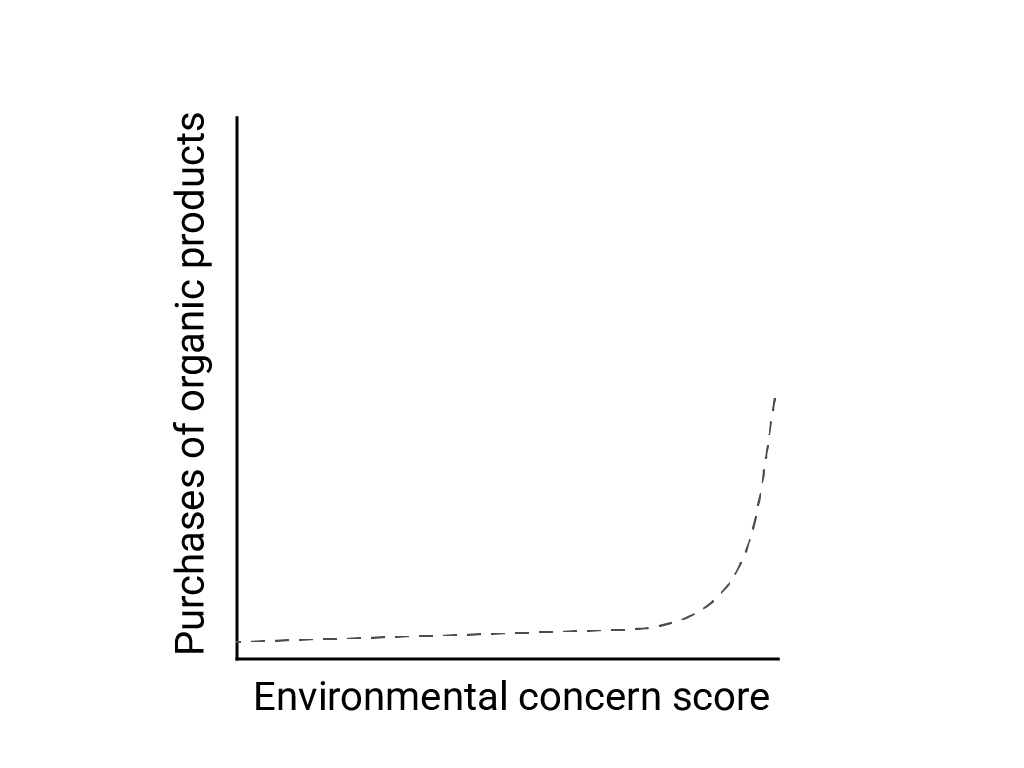
設計模型或研究時,請考慮非線性關係的可能性。由於A/B 測試可能會遺漏非線性關係,因此建議您同時測試第三個中間條件 C。另外,請考量初始行為是否會持續呈現線性,或是未來的資料是否可能顯示更多對數或其他非線性行為。
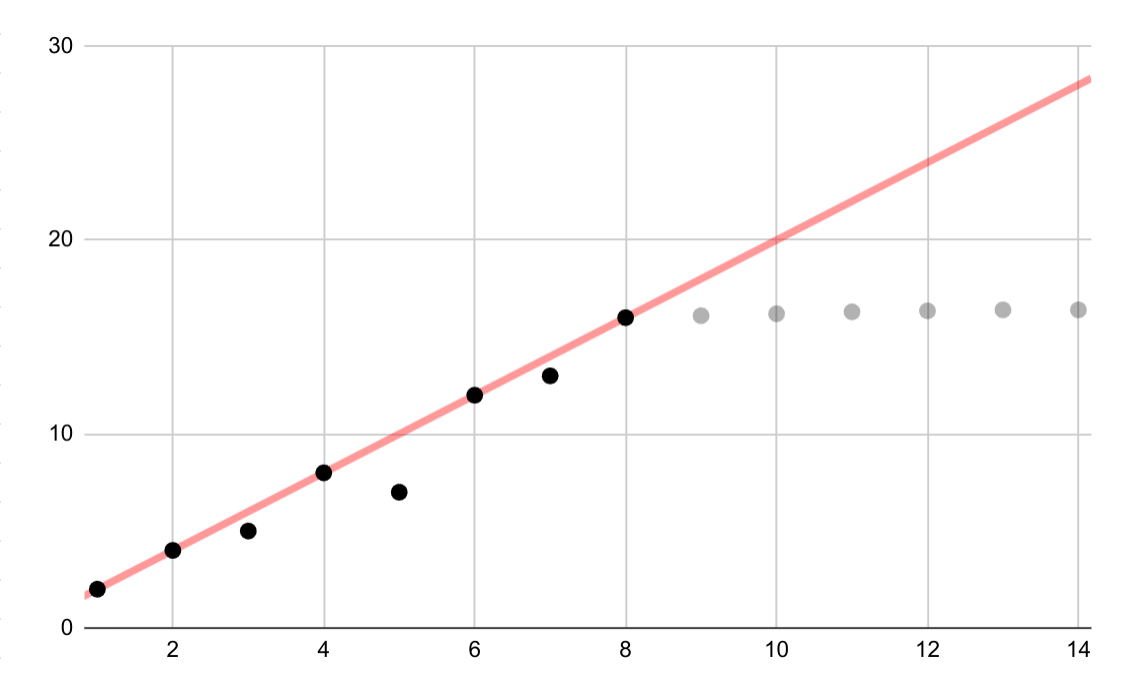
這個假設範例顯示對對數資料進行線性擬合時的錯誤。如果只有前幾個資料點,假設變數之間存在持續的線性關係,既誘人又不正確。
線性插值
請檢查資料點之間的插補情形,因為插補會引入虛構點,而實際測量值之間的間隔可能會出現有意義的波動。舉例來說,請看以下以線性內插連結四個資料點的示意圖:

接著,請參考以下範例,瞭解線性內插會如何消除資料點之間的波動:
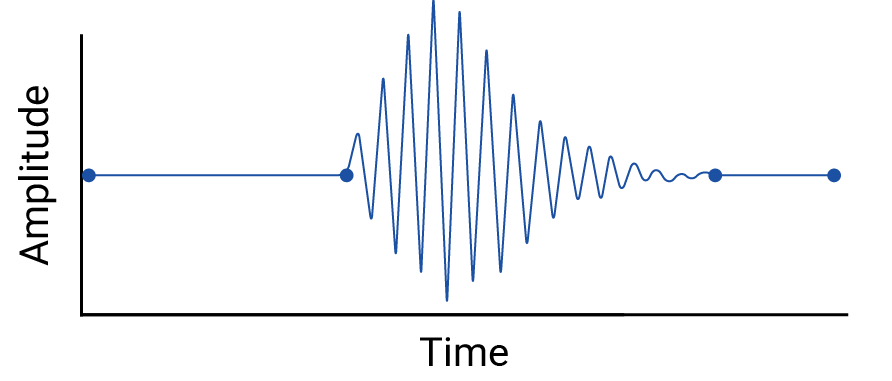
這個例子是人為設計的,因為地震儀會收集連續資料,因此不會錯過這場地震。不過,這有助於說明插補所做的假設,以及資料從業人員可能遺漏的實際現象。
Runge 現象
Runge 現象,也稱為「多項式擺動」,是指線性插補和線性偏差的反向問題。當您將多項式內插法套用至資料時,可能會使用程度過高的多項式 (程度或次數是多項式方程中最高次方的指數)。這會在邊緣產生奇怪的擺動。舉例來說,如果將 11 次方多項式插補法套用至大致線性的資料,也就是多項式方程式中最高階的項為 \(x^{11}\),會導致在資料範圍的開頭和結尾出現明顯不準確的預測結果:
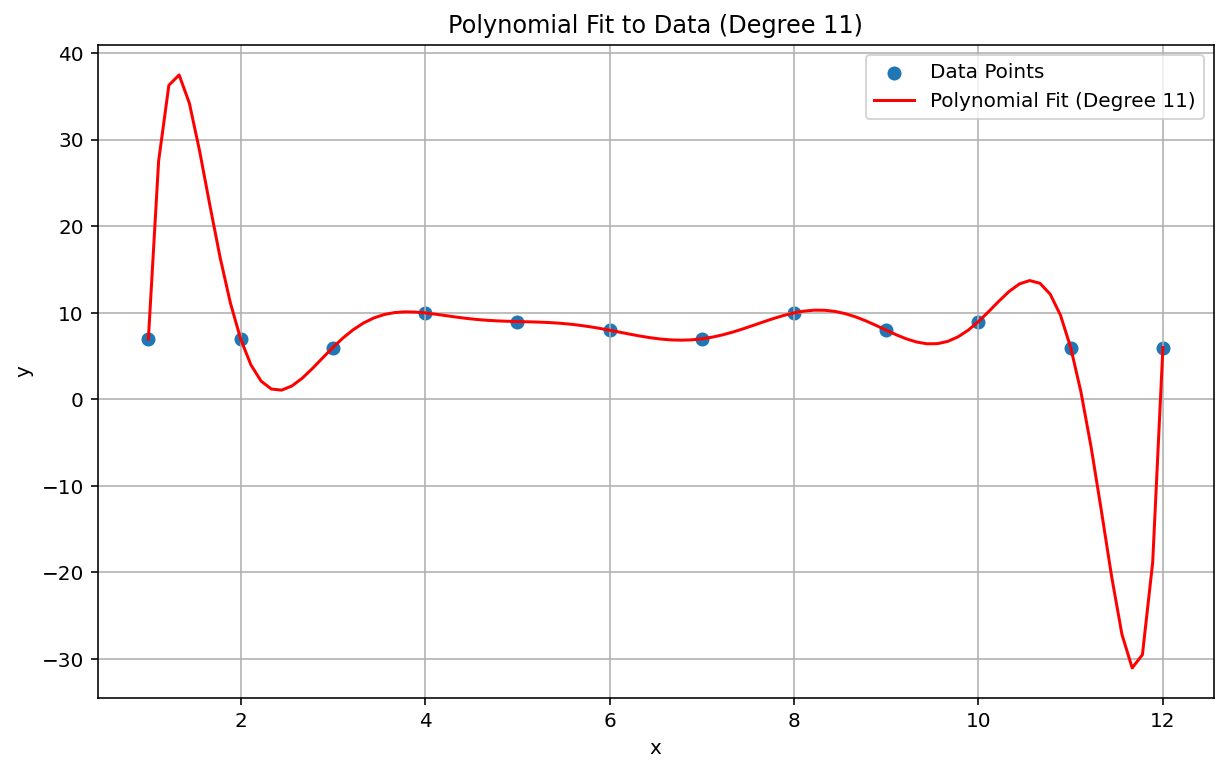
在機器學習的情況下,類似的現象就是過度擬合。
統計資料偵測失敗
有時統計測試可能太弱,無法偵測微小效果。統計分析的效能越低,正確識別真實事件的機率就越低,因此偽陰性的機率就越高。Katherine Button 等人曾在 Nature 上寫道:「如果某個領域的研究設計具有 20% 的效力,表示如果該領域有 100 個真正的非零效應需要發現,這些研究預計只會發現其中 20 個。」增加樣本數有時有助於解決這個問題,謹慎的實驗設計也是如此。
在機器學習中,類似的情況是分類問題,以及選擇分類門檻。選擇較高的門檻,偽陽性會減少,偽陰性會增加;選擇較低的門檻,偽陽性會增加,偽陰性會減少。
除了統計效力問題之外,由於關聯性設計用於偵測線性關係,因此可能會遺漏變數之間的非線性關聯性。同樣地,變數之間可能彼此相關,但在統計上並無關聯。變數也可能呈現負相關,但完全不相關,這就是所謂的「Berkson 悖論」或「Berkson 謬誤」。伯克森謬誤的經典例子,是當我們觀察住院病患 (相較於一般大眾) 時,任何風險因素與嚴重疾病之間的負相關性,這會因選取過程 (嚴重到需要住院的病情) 而產生。
請思考是否有下列任一情況。
過時的模型和無效的假設
即使是優質模型,隨著行為 (以及整個世界) 的變化,也可能會隨著時間而劣化。隨著 Netflix 的客戶群從年輕的科技迷轉變為一般大眾,他們的早期預測模型就必須退役10。
模型也可能包含無聲且不準確的假設,這些假設可能會一直隱藏,直到模型發生重大故障 (例如 2008 年市場崩盤) 為止。金融產業的風險價值 (VaR) 模型聲稱可精確估算任何交易員的投資組合最大損失,例如在 99% 的時間內,預期最大損失為 $100,000 美元。但在異常的崩潰情況下,預期最大損失為 $100,000 的投資組合,有時會損失 $1,000,000 美元以上。
VaR 模型是根據錯誤的假設建立,包括:
- 過去的市場變化可預測未來的市場變化。
- 預測報酬的基礎是常態 (薄尾,因此可預測) 分布。
事實上,底層分布是肥尾、"野生"或分形,也就是說,相較於常態分布預測的結果,發生長尾、極端和據信罕見事件的風險更高。實際分布的肥尾特性眾所皆知,但並未採取行動。但較少人知道的是,各種現象的複雜程度和緊密結合程度,包括以電腦為基礎的交易和自動賣出。11
匯總問題
匯總資料 (包括大多數客層和流行病學資料) 會受到特定陷阱的影響。辛普森悖論 (或稱合併悖論) 是指匯總資料中,當資料在不同層級匯總時,由於混淆因素和誤解的因果關係,導致明顯趨勢消失或反轉。
生態學謬誤是指在一個匯總層級,將某個族群的資訊錯誤推論至另一個匯總層級,而這項說法可能並非有效。某個省份有 40% 的農業工人罹患某種疾病,但在更廣大的人口中,這種疾病的盛行率可能不盡相同。該省內也極有可能有孤立的農場或農村,其疾病盛行率不會出現類似的激增。假設這些較不受影響的地方也出現 40% 的盛行率,這麼做是錯誤的。
可修改區域單位問題 (MAUP) 是地理空間資料中眾所皆知的問題,Stan Openshaw 於 1984 年在 CATMOG 38 中描述了這個問題。地理空間資料專家可以根據用於匯總資料的區域形狀和大小,在資料中的變數之間建立任何相關性。繪製偏袒某政黨的選區就是 MAUP 的例子。
所有這些情況都涉及從一個匯總層級推斷至另一個匯總層級的不當推論。不同層級的分析作業可能需要不同的匯總,甚至是完全不同的資料集。12
請注意,基於隱私權考量,普查、人口統計和流行病學資料通常會按區域匯總,而這些區域通常是隨機劃分,也就是不以實際有意義的邊界為依據。使用這類資料時,機器學習專家應檢查模型效能和預測結果是否會因所選區域的大小和形狀或匯總層級而有所變化,如果有變化,則應檢查模型預測結果是否受到其中一個匯總問題的影響。
參考資料
Button, Katharine et al. "Power failure: why small sample size undermines the reliability of neuroscience." Nature Reviews Neuroscience 卷 14 (2013 年),365–376 頁。DOI:https://doi.org/10.1038/nrn3475
Cairo, Alberto。How Charts Lie: Getting Smarter about Visual Information. NY: W.W. Norton, 2019。
Davenport, Thomas H. 「預測分析入門」。見 HBR Guide to Data Analytics Basics for Managers (波士頓:HBR Press,2018 年) 81-86 頁。
De Langhe, Bart, Stefano Puntoni, 和 Richard Larrick。「在非線性世界中進行線性思考」。見 HBR 經理人資料分析基礎指南 (波士頓:HBR Press,2018 年) 131-154 頁。
Ellenberg, Jordan. How Not to Be Wrong: The Power of Mathematical ThinkingNY: Penguin,2014 年。
Huff, Darrell. 如何利用統計資料說謊NY: W.W. Norton, 1954.
Jones, Ben. 避免資料陷阱:Hoboken, NJ: Wiley, 2020。
Openshaw,Stan。「The Modifiable Areal Unit Problem」(可修改面積單位的問題),CATMOG 38 (Norwich, England: Geo Books 1984) 37。
The Risks of Financial Modeling: VaR and the Economic Meltdown,第 111 屆國會 (2009 年) (Nassim N. Taleb 和 Richard Bookstaber)。
Ritter, David. 「何時應採取行動,何時不應採取行動」。見 HBR Guide to for Managers (Boston: HBR Press, 2018) 103-109。
Tulchinsky, Theodore H. and Elena A. Varavikova。「Chapter 3: Measuring, Monitoring, and Evaluating the Health of a Population」(「第 3 章:評估、監控和評估人口健康」),摘自The New Public Health(新公共衛生),第 3 版,San Diego: Academic Press,2014 年,第 91 至 147 頁。DOI:https://doi.org/10.1016/B978-0-12-415766-8.00003-3。
Van Doorn, Jenny, Peter C. Verhoef,以及 Tammo H. A. Bijmolt。「在政策研究中,態度和行為之間的非線性關係的重要性。」Journal of Consumer Policy 30 (2007) 75–90. DOI:https://doi.org/10.1007/s10603-007-9028-3
圖片參考資料
根據「Von Mises Distribution」 Rainald62,2018 年。資料來源
{kind=link}
-
Ellenberg 125。 ↩
-
Huff 77-79。哈夫引用了普林斯頓大學的公共意見研究辦公室,但他可能指的是丹佛大學國家意見研究中心於 1944 年 4 月的報告。↩
-
Tulchinsky 和 Varavikova。 ↩
-
Gary Taubes, Do We Really Know What Makes Us Healthy?" in The New York Times Magazine, Sep 16, 2007.↩
-
Ellenberg 78. ↩
-
Huff 91-92。 ↩
-
哈夫 93。 ↩
-
Jones 157-167。 ↩
-
Huff 95。 ↩
-
Davenport 84。 ↩
-
請參閱 Nassim N. Taleb 和 Richard Bookstaber 在 The Risks of Financial Modeling: VaR and the Economic Meltdown 中指出,第 111 屆國會 (2009 年) 11-67 頁。↩
-
Cairo 155, 162。 ↩