"Les ordures ménagères sont arrivées.
– Proverbe des débuts de la programmation
Au-dessous de chaque modèle de ML, de chaque calcul de corrélation et de chaque la stratégie recommandée concerne un ou plusieurs ensembles de données bruts. Peu importe la beauté ou frappent ou persuasifs les produits finaux sont, si les données sous-jacentes étaient erroné, mal collecté ou de mauvaise qualité, le modèle qui en résulte la prédiction, la visualisation ou la conclusion sera également qualité. Toute personne qui visualise, analyse et entraîne des modèles jeux de données doivent poser des questions difficiles sur la source de leurs données.
Les instruments de collecte de données peuvent présenter des dysfonctionnements ou être mal calibrés. Les humains qui collectent des données peuvent être fatigués, espiègles, incohérents ou mal entraîné. Certaines personnes font des erreurs et peuvent raisonnablement être en désaccord sur la classification des signaux ambigus. En conséquence, la qualité et la validité des données peut en souffrir et celles-ci peuvent ne pas refléter la réalité. Ben Jones, auteur du livre Expecting Data les pièges, c'est ce que l'on appelle lac de réalité des données, pour rappeler au lecteur : "Ce n'est pas un crime, mais un crime signalé. Il ne s'agit pas il s'agit du nombre d'attaques de météores enregistrées."
Exemples de données manquantes:
Les graphiques de Jones font des pics dans les mesures de temps à intervalles de 5 minutes, et mesures de poids à des intervalles de 2,5 kg, non pas parce que de tels pics existent mais comme les collecteurs de données humains, contrairement aux instruments, pour arrondir leurs nombres à la valeur 0 ou 5 la plus proche1.
En 1985, Joe Farman, Brian Gardiner et Jonathan Shanklin travaillent pour le La British Antarctic Survey (BAS) a révélé que les mesures trou saisonnier dans la couche d'ozone au-dessus de l'hémisphère sud. Ce contredit les données de la NASA, qui n'ont enregistré aucun trou de ce type. Richard, physicien de la NASA Stolarski a enquêté et découvert que le logiciel de traitement des données de la NASA conçu en supposant que les niveaux d'ozone ne pourraient jamais descendre en dessous d'une une certaine quantité et les relevés très, très faibles d'ozone détectés étaient automatiquement considérées comme des anomalies absurdes2.
Les instruments présentent divers modes de défaillance, parfois même s'ils ne sont pas la collecte de données. Adam Ringler et al. une galerie de sismographes les lectures résultant d'échecs d'instrumentation (et les échecs correspondants) ; dans l'article de 2021 "Why Do My Squiggles Look Funny?"3. L'activité du cours d'exemples de lectures ne correspond pas à l'activité sismique réelle.
Les professionnels du ML doivent impérativement comprendre:
- Qui a collecté les données
- Comment et quand les données ont été collectées, et dans quelles conditions
- Sensibilité et état des instruments de mesure
- À quoi peuvent ressembler les défaillances d'instrument et les erreurs humaines dans un le contexte
- Tendance humaine à arrondir les nombres et à fournir des réponses souhaitables
Il existe presque toujours au moins une petite différence entre les données et la réalité, également appelée vérité terrain. La prise en compte de cette différence est la clé pour tirer de bonnes conclusions et tirer décisions éclairées. Cela inclut les décisions suivantes:
- quels problèmes peuvent et doivent être résolus par le ML.
- quels problèmes ne sont pas mieux résolus par le ML.
- pour lesquels il n'y a pas encore suffisamment de données de haute qualité pour que le ML puisse les résoudre.
Demandez: Qu'est-ce, au sens le plus strict et le plus littéral, qui est communiqué par les données ? Plus important encore, qu'est-ce qui n'est pas communiqué par les données ?
Les données sont sales
En plus d'examiner les conditions de la collecte des données, le jeu de données peut contenir des blessures, des erreurs et des valeurs nulles ou non valides (comme (mesures de concentration négatives). Les données provenant de la foule peuvent être particulièrement désordonné. Travailler avec un jeu de données de qualité inconnue peut conduire à des résultats inexacts.
Voici quelques problèmes courants :
- Fautes d'orthographe des valeurs de chaîne, comme des lieux, des espèces ou des noms de marques
- Conversions d'unités, unités ou types d'objets incorrects
- Valeurs manquantes
- Erreurs de classification ou d'étiquetage récurrentes
- Les chiffres significatifs restants parmi les opérations mathématiques qui dépassent la sensibilité réelle d'un instrument
Le nettoyage d'un jeu de données implique souvent des choix concernant les valeurs Null et manquantes (que ce soit pour les garder nulles, les supprimer ou substituer des 0), corriger les fautes d'orthographe dans un une seule version, corriger les unités et les conversions, etc. Une interface plus avancée consiste à imputer les valeurs manquantes, comme décrit dans Caractéristiques des données du cours d'initiation au machine learning.
Échantillonnage, biais de survie et problème du point de terminaison de substitution
Les statistiques permettent d'extrapoler de façon valide et précise les résultats d'une un échantillon purement aléatoire à une population plus large. La fragilité non examinée des cette hypothèse, ainsi que les entrées d'entraînement déséquilibrées et incomplètes, a conduit aux défaillances majeures de nombreuses applications de ML, y compris les modèles utilisés les examens de CV et la police. Cela a également entraîné des échecs de scrutation et d'autres des conclusions erronées concernant des groupes démographiques. Dans la plupart des contextes en dehors de les données artificielles générées par ordinateur, les échantillons purement aléatoires coûteux et trop difficiles à acquérir. Plusieurs solutions de contournement et un prix abordable des proxys sont utilisés à la place, qui introduisent différentes sources de biais.
Pour utiliser la méthode d'échantillonnage stratifié, par exemple, vous devez connaître la prévalence de chaque strate échantillonnée dans la population plus large. Si vous supposez une prévalence incorrecte, vos résultats seront inexacts. De même, les sondages en ligne constituent rarement un échantillon aléatoire d'une population nationale, mais un échantillon de la population connectée à Internet (souvent provenant de plusieurs pays) qui voit et accepte de répondre à l'enquête. Ce groupe est susceptible de différer d'un échantillon aléatoire réel. Les questions de la section sont des exemples de questions possibles. Les réponses à ces questions de sondage sont : Encore une fois, il ne s'agit pas d'un échantillon aléatoire des opinions réelles, mais un échantillon de opinions que la personne interrogée est disposée à fournir, qui peuvent différer de leurs des opinions réelles.
Les chercheurs en santé clinique sont confrontés à un problème similaire : le substitut problème lié aux points de terminaison. Parce qu'il faut beaucoup trop de temps pour vérifier l'effet d'un médicament sur sur la durée de vie des patients, les chercheurs utilisent des biomarqueurs proxy liés à la durée de vie, mais peut-être pas. Les taux de cholestérol sont utilisés comme substituts point de terminaison pour les crises cardiaques et les décès dus à des problèmes cardiovasculaires: si un médicament réduit le taux de cholestérol, on suppose qu'il réduit également le risque de problèmes cardiaques. Toutefois, cette chaîne de corrélation peut ne pas être valide, ou l'ordre de causalité peut être différent de ce que le chercheur suppose. Voir Weintraub et al., "Les dangers des points de terminaison de substitution", pour obtenir plus d'exemples et de détails. La situation équivalente en ML est celle étiquettes de proxy.
Le mathématicien Abraham Wald a célèbre un problème d'échantillonnage des données maintenant connu que le biais de survie. Les avions de guerre revenaient avec des balles lancées des lieux particuliers et pas dans d'autres. L'armée américaine voulait ajouter une armure aux avions dans les zones où il y a le plus de balles, mais le groupe de recherche Il est recommandé d'ajouter le blindage dans les zones sans trous de balle. Elle a correctement déduit que son échantillon de données était biaisé, car des avions ont été abattus ces zones ont été si gravement endommagées qu'elles n'ont pas pu retourner à la base.
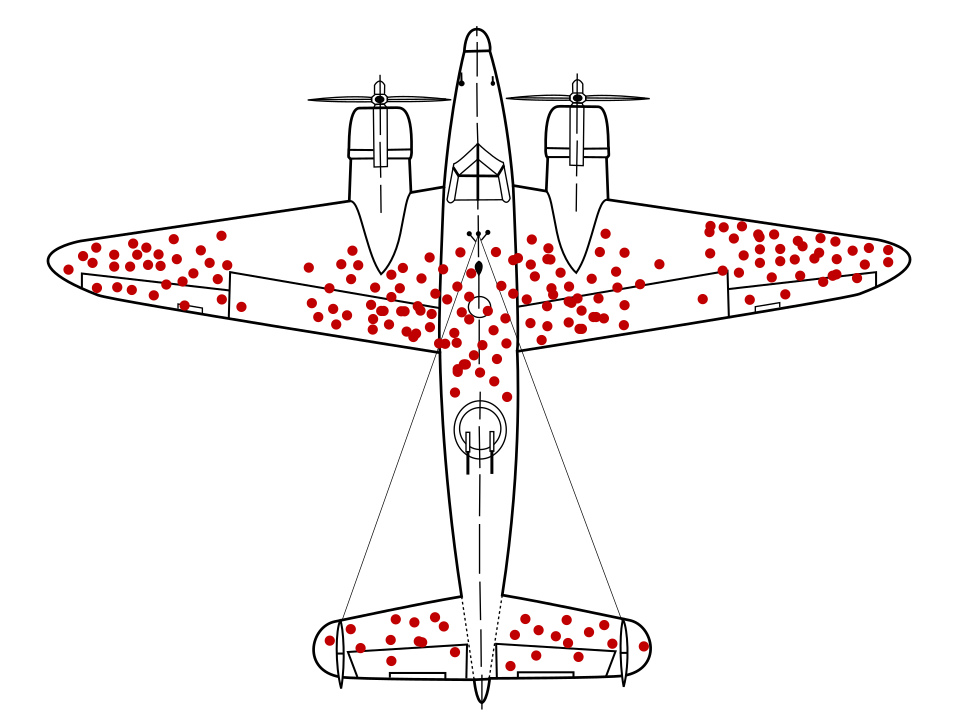
Un modèle recommandant des armures a-t-il été entraîné uniquement sur des diagrammes de retours des avions militaires, sans comprendre le biais de survie présent dans les données, ce modèle aurait recommandé de renforcer les zones avec plus de balles.
Le biais d'auto-sélection peut provenir de sujets humains qui se portent volontaires pour à participer à une étude. Détenus motivés à s'inscrire à un programme de lutte contre la récidive programme, par exemple, peut représenter une population moins susceptible de s'engager de crimes que la population générale de prisonniers. Cela fausserait les résultats4.
Un problème d'échantillonnage plus subtil est le biais de rappel, qui implique la malléabilité des souvenirs des sujets humains. En 1993, Edward Giovannucci a demandé à un groupe d'âge correspondant des femmes, dont certaines avaient reçu un cancer, à propos de leur alimentation habitudes. Les mêmes femmes avaient répondu à une enquête sur leurs habitudes alimentaires avant leur les diagnostics de cancer. Ce que Giovannucci a découvert, c'est que les femmes sans cancer les personnes atteintes d'un cancer du sein ont signalé consommant plus de lipides qu'avant, inconsciemment en fournissant une explication possible (bien que inexactes) de leur cancer5.
Question :
- Qu'est-ce qu'un ensemble de données échantillonne ?
- Combien de niveaux d'échantillonnage sont disponibles ?
- Quel biais peut être introduit à chaque niveau d'échantillonnage ?
- La mesure intermédiaire est-elle utilisée (à savoir un biomarqueur, un sondage en ligne ou une liste à puces). trou) montrant une corrélation ou une causalité réelles ?
- Qu'est-ce qui pourrait manquer dans l'échantillon et la méthode d'échantillonnage ?
Le module Équité du cours d'initiation au machine learning explique comment évaluer et atténuer sources de biais supplémentaires dans les ensembles de données démographiques.
Définitions et classements
Définissez les termes de manière claire et précise, ou demandez des définitions claires et précises. Cela est nécessaire pour comprendre quelles fonctionnalités de données sont envisagées et ce qui est prédit ou revendiqué. Charles Wheelan, dans Naked Statistics, explique "la santé des États-Unis "Fabrication" comme exemple de terme ambigu. Que la fabrication aux États-Unis "sain" dépend entièrement ou non de la définition du terme. Greg Ip Article de mars 2011 dans The Economist illustre bien cette ambiguïté. Si la métrique "santé" est "l'industrie manufacturière sortie ». Ensuite, en 2011, la fabrication aux États-Unis est devenue de plus en plus saine. Si le "santé" est définie comme "emplois dans le secteur de la fabrication", Toutefois, la fabrication aux États-Unis était en baisse6.
Les classements présentent souvent des problèmes similaires, y compris des éléments masqués ou absurdes les pondérations accordées aux différents éléments du classement, d'incohérences et options non valides. Malcolm Gladwell, qui écrit dans The New Yorker, mentionne juge en chef de la Cour suprême du Michigan, Thomas Brennan, qui a déjà envoyé un sondage au une centaine d'avocats leur demandant de classer dix facultés de droit par qualité, certaines célèbres, d'autres non. Ces avocats ont classé la faculté de droit de Penn State à la cinquième place lieu, bien qu'au moment de l'enquête, Penn State n'avait pas de loi scolaire7.De nombreux classements bien connus incluent une ligne subjective de réputation. Demandez quels éléments sont pris en compte dans le classement et pourquoi les composants se sont vu attribuer leurs pondérations particulières.
Petits nombres et grands effets
Ce n'est pas surprenant d'obtenir 100% de faces ou 100% de piles si vous lancez une pièce deux fois. Il n'est pas non plus surprenant d'obtenir 25% de têtes après avoir lancé quatre fois une pièce, puis 75% pour les quatre tours suivants, bien que cela démontre une augmentation considérable (qui pourrait être attribuée à tort à un sandwich entre les séries de tirages à pile ou face, ou tout autre facteur factice). Mais comme le nombre de tirs à pile ou face augmente, par exemple jusqu'à 1 000 ou 2 000, un écart important en pourcentage les 50% attendus deviennent extrêmement improbables.
Le nombre de mesures ou de sujets expérimentaux dans une étude est souvent désigné par N. Les changements proportionnels importants dus au hasard sont beaucoup plus susceptibles de apparaissent dans des ensembles de données et des échantillons dont le N est faible.
Lorsque vous effectuez une analyse ou documentez un jeu de données dans une fiche de données, spécifiez N afin que d'autres personnes puissent prendre en compte l'influence du bruit et du caractère aléatoire.
Étant donné que la qualité du modèle a tendance à évoluer avec le nombre d'exemples, un ensemble de données si la valeur N est faible, les modèles sont généralement de mauvaise qualité.
Régression à la moyenne
De même, toute mesure ayant une certaine influence par le hasard est soumise à une d'effet connu sous le nom de régression à la moyenne. Il s'agit de la manière dont une mesure après une mesure particulièrement extrême est, en moyenne, susceptible d'être moins extrême, ou plus proche de la moyenne, en raison de la façon dont il est peu probable que la mesure extrême se produise en premier lieu. La l'effet est plus prononcé si un groupe particulièrement au-dessus ou en dessous de la moyenne a été sélectionné pour observer, déterminer si ce groupe est la personne la plus grande dans un la population, les pires athlètes d'une équipe ou les personnes les plus à risque d'accident vasculaire cérébral. Les enfants des personnes les plus grandes sont en moyenne susceptibles d'être plus petits que leurs parents, les athlètes les moins performants sont susceptibles de mieux performer après une saison exceptionnellement mauvaise, et les personnes les plus à risque d'accident vasculaire cérébral sont susceptibles de voir leur risque réduit après n'importe quelle intervention ou traitement, non pas en raison de facteurs causaux, mais en raison des propriétés et des probabilités de hasard.
L'un des moyens d'atténuer les effets de la régression sur la moyenne, en explorant d'interventions ou de traitements pour un groupe au-dessus ou en dessous de la moyenne, diviser les sujets en un groupe d'étude et un groupe de contrôle afin d'isoler les effets causatifs. Dans le contexte du ML, ce phénomène suggère qu'il faut payer plus prêtez attention aux modèles qui prédisent des valeurs exceptionnelles ou aberrantes, par exemple:
- températures ou conditions météorologiques extrêmes
- magasins ou athlètes les plus performants
- les vidéos les plus populaires sur un site Web
Si les prédictions continues d'un modèle des valeurs exceptionnelles dans le temps ne correspondent pas à la réalité, par exemple en prédisant qu'un ou les vidéos les plus populaires continueront d'enregistrer de bons résultats, n’est pas, demandez:
- Une régression vers la moyenne pourrait-elle être le problème ?
- Les caractéristiques présentant les pondérations les plus élevées sont-elles plus prédictives ? par rapport aux caractéristiques dont les pondérations sont plus faibles ?
- Est-ce que nous collectons des données qui ont la valeur de référence pour ces caractéristiques souvent zéro (en réalité un groupe de contrôle) modifie-t-il les prédictions du modèle ?
Références
Huff, Darrell. Comment exploiter les statistiques ? NY: W.W. Norton, 1954.
Jones, Ben. Évitez les pièges liés aux données. Hoboken, New Jersey: Wiley, 2020.
O'Connor, Cailin et James Owen Weatherall. L'ère de la désinformation. New Haven : Yale UP, 2019.
Ringler, Adam, David Mason, Gabi Laske et Mary Templeton. "Pourquoi mes gribouillages sont-ils bizarres ? A Gallery of Compromized Seismic Signals." Seismological Research Letters, vol. 92, n° 6 (juillet 2021). DOI: 10.1785/0220210094
Weintraub, William S, Thomas F. Lüscher et Stuart Pocock. "Les dangers des points de terminaison de substitution." European Heart Journal 36 n° 3 33 (sept. 2015): 2212-2218. DOI: 10.1093/eurheartj/ehv164
Wheelan, Charles. Naked Statistics: Supprimer la peur des données. NY: W.W. Norton, 2013
Référence d'image
« Le préjugé de survie. » Martin Grandjean, McGeddon et Cameron Moll 2021. CC BY-SA 4.0. Source
{kind=link}
-
Jones 25-29. ↩
-
O'Connor et Weatherall 22-3. ↩
-
Ringling et al. ↩
-
Wheelan 120. ↩
-
Siddhartha Mukherjee, "Do Cellphones Cause Brain Cancer?" (Les téléphones portables provoquent-ils le cancer du cerveau ?) dans The New York Times, 13 avril 2011. Cité dans Wheelan 122. ↩
-
Wheelan, de 39 à 40 ans. ↩
-
Malcolm Gladwell, "The Order of Things" (L'ordre des choses), dans The New Yorker, 14 février 2011. Cité dans Wheelan 56. ↩