"कचरा फ़ेंकना हो और कचरा फेंकना हो."
अभी तक किसी भी व्यक्ति ने चेक इन नहीं किया है — शुरुआती कॉन्टेंट की कहानियाँ
हर एमएल मॉडल के नीचे, कोरिलेशन का हर कैलकुलेशन, और हर डेटा-आधारित नीति के सुझाव में एक या एक से ज़्यादा रॉ डेटासेट होते हैं. भले ही, आखिर में मिले प्रॉडक्ट कितने भी खूबसूरत, शानदार या भरोसेमंद हों, अगर डेटा गलत है, खराब तरीके से इकट्ठा किया गया है या उसकी क्वालिटी खराब है, तो मॉडल, अनुमान, विज़ुअलाइज़ेशन या नतीजा भी खराब क्वालिटी का होगा. मॉडल को विज़ुअलाइज़ करने वाला, उसका विश्लेषण करने, और उसे ट्रेनिंग देने वाला कोई भी व्यक्ति डेटासेट में डेटा के सोर्स के बारे में मुश्किल सवाल पूछे जाने चाहिए.
डेटा इकट्ठा करने वाले उपकरण खराब हो सकते हैं या उन्हें सही तरीके से कैलिब्रेट नहीं किया गया हो. डेटा इकट्ठा करने वाले लोग थके हुए, शरारती, और एक जैसे काम करने वाले हो सकते हैं. इसके अलावा, वे काम भी नहीं कर सकते ट्रेनिंग दी गई. लोग गलतियां करते हैं. साथ ही, अलग-अलग लोग, अस्पष्ट सिग्नल की कैटगरी तय करने के बारे में, सही तरीके से सहमत नहीं हो सकते. इस वजह से, डेटा की वैधता पर असर पड़ सकता है. साथ ही, हो सकता है कि डेटा में असल जानकारी न दिखे. डेटा से जुड़ी समस्याओं से बचना के लेखक बेन जोन्स इसे डेटा और असल स्थिति के बीच का अंतर कहते हैं. साथ ही, वे पाठकों को याद दिलाते हैं: "यह अपराध नहीं है, यह रिपोर्ट किया गया अपराध है. यह उल्कापिंड के टकराव की संख्या नहीं है, बल्कि रिकॉर्ड किए गए उल्कापिंड के टकराव की संख्या है."
डेटा-रिएलिटी गैप के उदाहरण:
जॉन्स, समय के डेटा को पांच मिनट के अंतराल पर और वज़न के डेटा को पांच पाउंड के अंतराल पर दिखाते हैं. ऐसा इसलिए नहीं है, क्योंकि डेटा में ऐसे स्पाइक मौजूद हैं, बल्कि इसलिए है, क्योंकि इंस्ट्रूमेंट के उलट, डेटा इकट्ठा करने वाले लोग अपने डेटा को 0 या 5 के आस-पास के अंकों पर राउंड ऑफ़ करते हैं.1
साल 1985 में, जो फ़ार्मन, ब्रायन गार्डिनर, और जोनाथन शंकलिन, ब्रिटिश अंटार्कटिक सर्वे (बीएएस) ने पाया कि उनके माप से दक्षिणी गोलार्ध में ओज़ोन लेयर में सीज़न के हिसाब से छेद. यह जानकारी, नासा के डेटा से मेल नहीं खाती. नासा के डेटा में ऐसा कोई छेद नहीं दर्ज किया गया है. नासा के भौतिक वैज्ञानिक रिचर्ड स्टोलर्स्की ने जांच की और पाया कि नासा का डेटा-प्रोसेसिंग सॉफ़्टवेयर इसे यह मानकर डिज़ाइन किया गया है कि ओज़ोन लेवल कभी भी ओज़ोन की मात्रा का पता चला है और ओज़ोन की मात्रा बहुत कम है उन्हें अपने-आप बेतुके आउटलायर के तौर पर हटा दिया जाता था.2
इस वाद्ययंत्र में कई तरह के काम करने के दौरान नाकाम होने वाले मोड होते हैं. कभी-कभी स्थिर होने के बाद भी, डेटा इकट्ठा कर रहा है. एडम रिंगलर और अन्य सीस्मोग्राफ़ की एक गैलरी उपलब्ध कराएँ इंस्ट्रुमेंट के काम न करने (और उनसे जुड़े अपडेट) की वजह से मिलने वाली रीडिंग साल 2021 के पेपर में "माय स्क्विगल्स मज़ेदार क्यों दिखती हैं?"3 उदाहरण के तौर पर दिए गए रीडआउट, असल भूकंप से जुड़ी गतिविधि के बारे में नहीं हैं.
मशीन लर्निंग का इस्तेमाल करने वाले लोगों के लिए, इन बातों को समझना बहुत ज़रूरी है:
- डेटा किसने इकट्ठा किया
- डेटा कब और कैसे इकट्ठा किया गया था और किन शर्तों के तहत
- मापने वाले उपकरणों की संवेदनशीलता और स्थिति
- किसी खास डिवाइस में कोई गड़बड़ी और मानवीय गड़बड़ी कैसी दिख सकती है कॉन्टेक्स्ट
- मानवीय संख्याओं को पूर्णांक बनाने और अपने हिसाब से जवाब देने की आदत होती है
ज़्यादातर मामलों में, डेटा और असल स्थिति के बीच कम से कम थोड़ा अंतर होता है. इसे ग्राउंड ट्रूथ भी कहा जाता है. अच्छे नतीजे पाने और सही फ़ैसला लेने के लिए, अंतर को ध्यान में रखना बेहद ज़रूरी है सही फ़ैसले लेने में मदद मिलती है. इसमें यह तय करना शामिल है:
- एमएल की मदद से किन सवालों को हल किया जा सकता है और किन सवालों को हल करना चाहिए.
- कौनसी समस्याएं एमएल से सबसे अच्छी तरह से हल नहीं होती हैं.
- ऐसे सवाल जिन्हें मशीन लर्निंग की मदद से हल करने के लिए अभी तक काफ़ी अच्छी क्वालिटी का डेटा नहीं मिला.
पूछें: डेटा से, सटीक और सबसे सही तरीके से क्या पता चलता है? यह भी ज़रूरी है कि डेटा में क्या नहीं बताया गया है?
डेटा में गड़बड़ी
डेटा इकट्ठा करने की शर्तों की जांच करने के अलावा, डेटासेट में गड़बड़ियां, गलतियां, और शून्य या अमान्य वैल्यू हो सकती हैं. जैसे, कॉन्संट्रेशन की नेगेटिव मेज़रमेंट. क्राउड सोर्स किया गया डेटा, खास तौर पर गड़बड़ हो सकता है. अज्ञात क्वालिटी के डेटासेट के साथ काम करने से गलत नतीजे मिल सकते हैं.
ये कुछ सामान्य समस्याएं हो सकती हैं:
- जगह, प्रजाति या ब्रैंड के नाम जैसी स्ट्रिंग वैल्यू की गलत वर्तनी
- गलत यूनिट कन्वर्ज़न, यूनिट या ऑब्जेक्ट टाइप
- वैल्यू मौजूद नहीं हैं
- लगातार गलत कैटगरी या गलत लेबल का इस्तेमाल करना
- गणितीय संक्रियाओं के बचे हुए महत्वपूर्ण अंक जो किसी इंस्ट्रुमेंट की असल संवेदनशीलता
डेटासेट को साफ़ करने के लिए, अक्सर शून्य और गैर-मौजूद वैल्यू से जुड़े विकल्प शामिल होते हैं (चाहे उन्हें शून्य या खाली छोड़ने या 0s बदलने के लिए), स्पेलिंग ठीक करके एक वर्शन है, यूनिट और कन्वर्ज़न ठीक करना वगैरह. ज़्यादा बेहतर तकनीक, गायब वैल्यू को इंप्रेशन के तौर पर लागू करती है. इस प्रोसेस के बारे में डेटा की विशेषताएं मशीन लर्निंग क्रैश कोर्स में शामिल हैं.
सैंपलिंग, सर्वाइवरशिप बायस, और सर्वोगाते एंडपॉइंट की समस्या
आंकड़ों की सहायता से बड़ी आबादी के लिए पूरी तरह से रैंडम सैंपल. इसकी भंगुरता ट्रेनिंग के इस असंतुलित और अधूरे इनपुट की वजह से, कई ML ऐप्लिकेशन की हाई-प्रोफ़ाइल विफलताओं के लिए किया गया है, जिनमें समीक्षा और पुलिसिंग फिर से शुरू कर सकें. इसकी वजह से पोलिंग फ़ेल हुए और डेमोग्राफ़िक (उम्र, लिंग, आय, शिक्षा वगैरह) ग्रुप के बारे में गलत नतीजे. ज़्यादातर मामलों में कंप्यूटर से जनरेट किया गया आर्टिफ़िशियल डेटा, पूरी तरह से रैंडम सैंपल भी हैं महंगा और उसे हासिल करना बहुत मुश्किल है. अलग-अलग समाधान और किफ़ायती इसके बजाय, प्रॉक्सी का इस्तेमाल किया जाता है, जो अलग-अलग सोर्स से जानकारी देते हैं पक्षपात.
उदाहरण के लिए, अलग-अलग ग्रुप में बांटकर सैंपलिंग करने के तरीके का इस्तेमाल करने के लिए, आपको बड़ी जनसंख्या में सैंपल किए गए हर ग्रुप की संख्या का पता होना चाहिए. अगर आपको लगता है कि कोई ऐसी व्यापक जानकारी है जो वास्तव में गलत है, तो आपके परिणाम गलत होंगे. इसी तरह, ऑनलाइन पोलिंग शायद ही किसी राष्ट्रीय जनसंख्या का कोई सैंपल हो, लेकिन इंटरनेट से कनेक्ट होने वाली जनसंख्या का एक (अक्सर कई देशों से) सर्वे को देखता है और उसमें हिस्सा लेना चाहता है. यह ग्रुप, किसी भी रैंडम सैंपल से अलग हो सकता है. पोल में मौजूद सवाल, संभावित सवालों के सैंपल हैं. पोल से जुड़े उन सवालों के जवाब हैं, फिर से, जवाब देने वालों का कोई रैंडम सैंपल नहीं वास्तविक राय, लेकिन जो जवाब देने वालों ने सहजता से अपनी राय दी है, जो उनकी राय से अलग हो सकती हैं के बारे में बताएँगे.
क्लिनिकल हेल्थ रिसर्चर को एक ऐसी ही समस्या का सामना करना पड़ता है जिसे सरोगेट कहते हैं एंडपॉइंट से जुड़ी समस्या के बारे में ज़्यादा जानें. किसी दवा के असर को मरीज़ की उम्र से जुड़ी जानकारी के आधार पर पता लगाने में काफ़ी समय लगता है. इसलिए, रिसर्चर प्रॉक्सी बायोमार्कर का इस्तेमाल करते हैं. ऐसा माना जाता है कि ये बायोमार्कर, उम्र से जुड़े होते हैं. हालांकि, ऐसा ज़रूरी नहीं है. कोलेस्ट्रॉल लेवल का इस्तेमाल, सरोगेट की तरह किया जाता है हृदय संबंधी समस्याओं की वजह से दिल के दौरे और मौत का एंडपॉइंट: अगर कोई दवा कोलेस्ट्रॉल के स्तर को कम करता है, यह हृदय संबंधी समस्याओं के जोखिम को भी कम माना जाता है. हालांकि, हो सकता है कि यह कनेक्शन सही न हो या फिर नतीजे के लिए वजह का क्रम, शोधकर्ता के अनुमान से अलग हो. वेंट्रॉब और अन्य देखें, "सरोगेट एंडपॉइंट के खतरे", पढ़ें. ML की ऐसी ही स्थिति है प्रॉक्सी लेबल.
गणितज्ञ अब्राहम वाल्ड ने डेटा सैंपलिंग की एक समस्या की पहचान की थी जो अब तक काफ़ी मशहूर है बताया गया भेदभाव के तौर पर मार्क किया गया. वापस जा रहे लड़ाकू हवाई जहाज़ों पर, गोली होल के साथ अन्य जगहों पर नहीं. अमेरिकी सेना, उन जगहों पर ज़्यादा कवच जोड़ना चाहती थी जहां सबसे ज़्यादा गोली के छेद थे. हालांकि, वाल्ड के रिसर्च ग्रुप ने इसके बजाय, उन जगहों पर कवच जोड़ने का सुझाव दिया जहां गोली के छेद नहीं थे. उन्होंने सही अनुमान लगाया कि हवाई जहाज़ों से उड़ान भरने की वजह से उनका डेटा टेढ़ा-मेढ़ा था वे इलाके इतने खराब हो गए थे कि वे बेस पर वापस नहीं आ पा रहे थे.
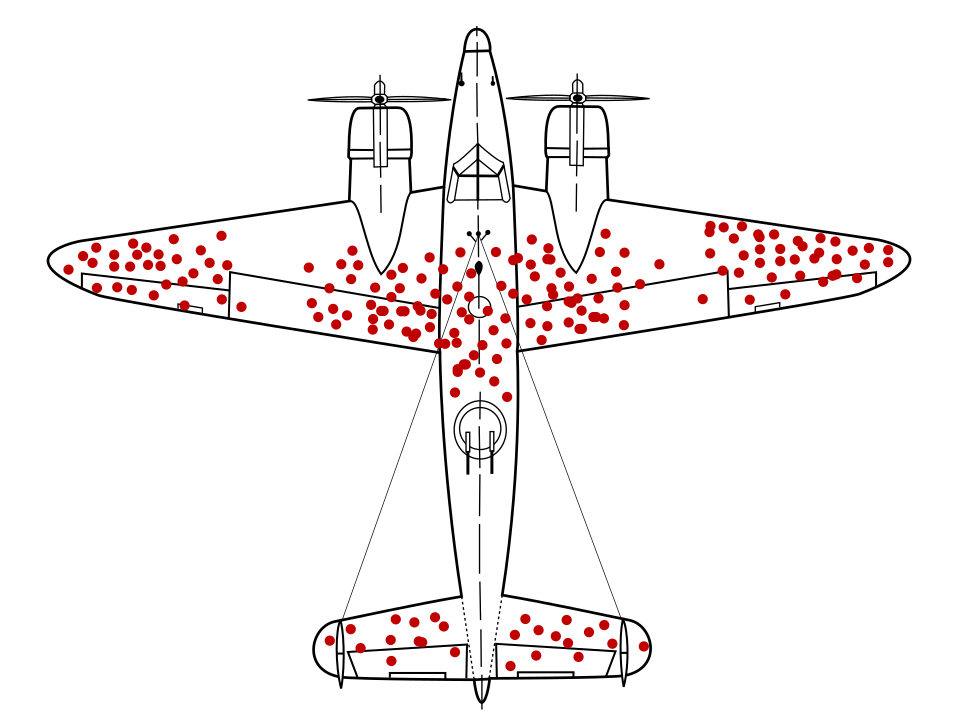
ऐसा हो सकता है कि किसी कवच का सुझाव देने वाले मॉडल को, सिर्फ़ लौटने के डायग्राम के हिसाब से ट्रेनिंग दी गई हो ऐसे युद्ध-प्लेन, जिनमें डेटा में मौजूद सर्वाइवरशिप बायस के बारे में अहम जानकारी मौजूद नहीं है. उस मॉडल में ज़्यादा बुलेट छेद वाले इलाकों को और मज़बूत बनाने का सुझाव दिया जाता.
खुद को चुनने से जुड़ी गड़बड़ी तब हो सकती है, जब लोग किसी स्टडी में हिस्सा लेने के लिए अपनी इच्छा से शामिल होते हैं. आत्मनिर्भरता कम करने के लिए साइन अप करने वाले कैदियों जैसे, यह प्रोग्राम ऐसे लोगों के लिए बना सकता है जिनकी Google Workspace सदस्यता में कैदियों की संख्या की तुलना में, आने वाले समय में होने वाले अपराधों की संख्या को कम किया जा सकता है. इससे नतीजों पर बुरा असर पड़ सकता है.4
रीकॉल पूर्वाग्रह की एक और सूक्ष्म नमूनाकरण समस्या है, जिसमें लोगों की जानकारी यादें. 1993 में, एडवर्ड जोवान्नुची ने एक आयु-मेल वाले समूह से जिनमें से कुछ महिलाओं को कैंसर हो चुका है, लेकिन वे अपने खान-पान पर पिछले आदतें. इन महिलाओं ने अपने शुरुआती दौर में खान-पान से जुड़ी आदतों पर एक सर्वे कैंसर का पता लगाना. जियोवन्नुकी ने पाया कि जिन महिलाओं को कैंसर का पता नहीं चला था उन्होंने अपने खान-पान के बारे में सही जानकारी दी. वहीं, स्तन कैंसर से पीड़ित महिलाओं ने बताया कि वे पहले की तुलना में ज़्यादा वसा का इस्तेमाल कर रही हैं. इससे, अनजाने में ही कैंसर की वजह का पता चलता है. हालांकि, यह वजह पूरी तरह सही नहीं है.5
सवाल:
- डेटासेट असल में सैंपलिंग क्या है?
- सैंपलिंग के कितने लेवल मौजूद हैं?
- सैंपलिंग के हर लेवल पर किस तरह के पूर्वाग्रह हो सकते हैं?
- क्या प्रॉक्सी मेज़रमेंट का इस्तेमाल किया गया है (बायोमार्कर, ऑनलाइन पोल या बुलेट) होल) असल संबंध या कार्य-कारण दिखा रहा है?
- सैंपल और सैंपलिंग के तरीके में क्या जानकारी मौजूद नहीं है?
फ़ेयरनेस मॉड्यूल में मशीन लर्निंग क्रैश कोर्स में, क्रैश का आकलन करने और उसे कम करने के तरीकों के बारे में बताया गया है डेमोग्राफ़िक डेटासेट में पक्षपात के अतिरिक्त सोर्स शामिल किए जा सकते हैं.
परिभाषाएं और रैंकिंग
शब्दों को साफ़ तौर पर और सटीक तरीके से परिभाषित करें. इसके अलावा, उनसे साफ़ तौर पर और सटीक परिभाषाएं बताने के लिए भी कहा जा सकता है. यह समझना ज़रूरी है कि डेटा से जुड़ी किन सुविधाओं पर विचार किया जा रहा है और किस चीज़ का अनुमान लगाया गया है या किस पर दावा किया गया है. चार्ल्स व्हीलन, नेकेड स्टैटिस्टिक्स में "अमेरिका के लोगों की सेहत के बारे में जानकारी देते हैं" मैन्युफ़ैक्चरिंग" . अमेरिका में मैन्युफ़ैक्चरिंग "बेहतर" है या नहीं, यह इस बात पर निर्भर करता है कि इस शब्द को कैसे परिभाषित किया गया है. ग्रेग आईप के The Economist में मार्च 2011 में पब्लिश किए गए लेख में इस बारे में बताया गया है. अगर "स्वास्थ्य" मेट्रिक यानी "मैन्युफ़ैक्चरिंग" आउटपुट," तब 2011 में, अमेरिका में मैन्युफ़ैक्चरिंग क्षेत्र की स्थिति बेहतर होती जा रही थी. अगर "स्वास्थ्य" मेट्रिक को "मैन्युफ़ैक्चरिंग जॉब" कहा जाता है. हालांकि, यू.एस. मैन्युफ़ैक्चरिंग में गिरावट आई थी.6
रैंकिंग में अक्सर मिलती-जुलती समस्याएं होती हैं. इनमें धुंधली या बेतुकी समस्याएं शामिल होती हैं रैंकिंग के अलग-अलग कॉम्पोनेंट को दिया जाता है, रैंकर का में अंतर होता है और अमान्य विकल्प. द न्यूयॉर्कर में लिखते हुए, मैल्कम ग्लैडवेल ने मिशिगन सुप्रीम कोर्ट के मुख्य न्यायाधीश थॉमस ब्रेनन के बारे में बताया है. उन्होंने एक बार सौ वकीलों को एक सर्वे भेजा था. इसमें उनसे क्वालिटी के हिसाब से 10 लॉ स्कूलों को रैंक करने के लिए कहा गया था. इनमें कुछ मशहूर लॉ स्कूल थे और कुछ नहीं. उन वकीलों ने पेन स्टेट के लॉ स्कूल को करीब पांचवें स्थान पर रखा, हालांकि सर्वे के समय पेन स्टेट में लॉ स्कूल नहीं था.7 कई मशहूर रैंकिंग में, इसी तरह की व्यक्तिगत रैंकिंग शामिल होती है. जानें कि किन कॉम्पोनेंट की रैंकिंग की जाती है और वे क्यों कॉम्पोनेंट को उनके खास वेट असाइन किए गए थे.
छोटी संख्याएं और बड़े असर
सिक्का उछालने पर, 100% हेड या 100% टेल पाना कोई हैरानी की बात नहीं है दो बार. यह भी कोई हैरानी की बात नहीं है कि सिक्का चार बार उछालने पर 25% बार चित आए और अगले चार बार उछालने पर 75% बार चित आए. हालांकि, इसमें चित आने की संख्या में काफ़ी बढ़ोतरी हुई है. इसकी वजह यह हो सकती है कि सिक्का उछालने के बीच में सैंडविच खाया गया हो या कोई और ग़लत वजह हो. हालांकि, जैसे-जैसे सिक्का उछालने की संख्या बढ़ती है, जैसे कि 1,000 या 2,000 तक, उम्मीद के मुताबिक 50% से बड़े प्रतिशत के अंतर की संभावना कम हो जाती है.
किसी अध्ययन में मापों या प्रायोगिक विषयों की संख्या को अक्सर N करें. संभावना के कारण बड़े समानुपातिक परिवर्तन की संभावना डेटासेट और सैंपल में, N कम होता है.
डेटा कार्ड में डेटासेट का विश्लेषण करते समय या उसका दस्तावेज़ बनाते समय, N की वैल्यू डालें, ताकि दूसरे लोग नॉइज़ और रैंडमनेस के असर को समझ सकें.
मॉडल की क्वालिटी, उदाहरणों की संख्या के हिसाब से होती है. इसलिए, डेटासेट के साथ कम N होने की वजह से, खराब क्वालिटी वाले मॉडल मिलते हैं.
मीन तक प्रतिगमन (रिग्रेशन)
इसी तरह, संयोग से कुछ असर डालने वाले किसी भी मेज़रमेंट के लिए इफ़ेक्ट को इस नाम से जाना जाता है मीन के हिसाब से रिग्रेशन. इससे पता चलता है कि किसी बहुत ज़्यादा माप के बाद, किस तरह से मेज़रमेंट किया जाता है औसतन, बहुत मुश्किल या मीन के करीब होती है. इसकी वजह पहले स्थान पर सबसे गंभीर माप के होने की संभावना नहीं थी. अगर निगरानी के लिए, औसत से ज़्यादा या औसत से कम के किसी ग्रुप को चुना गया है, तो इसका असर ज़्यादा होता है. भले ही, वह ग्रुप किसी आबादी में सबसे लंबे लोगों का हो, टीम में सबसे खराब खिलाड़ियों का हो या स्ट्रोक का सबसे ज़्यादा खतरा जिनमें हो. कॉन्टेंट बनाने सबसे ऊंचे लोगों के बच्चों के बच्चों की उम्र उनके बच्चों से छोटी होने की औसतन संभावना है अपवाद के बाद, सबसे खराब एथलीट की परफ़ॉर्मेंस बेहतर होने की संभावना रहती है मौसम खराब है और जिन्हें स्ट्रोक का खतरा सबसे ज़्यादा होता है, उनमें जोखिम कम हो सकता है किसी समस्या के समाधान के बाद, न कि किसी समस्या की वजह से, लेकिन क्योंकि इसमें कभी-कभी बदलाव आ जाता है.
औसत से ज़्यादा या औसत से कम ग्रुप के लिए, इंटरवेंशन या इलाज के तरीकों को एक्सप्लोर करते समय, मीन रेग्रेसन के असर को कम करने के लिए, विषयों को स्टडी ग्रुप और कंट्रोल ग्रुप में बांटें. इससे, असर डालने वाले वैरिएबल को अलग किया जा सकता है. एमएल (मशीन लर्निंग) के हिसाब से, इस तरीके से पता चलता है कि ज़्यादा पैसे खर्च करने हैं. ऐसे किसी भी मॉडल पर ध्यान दें जो असामान्य या बाहरी वैल्यू का अनुमान लगाता है, जैसे:
- खराब मौसम या तापमान
- सबसे अच्छा परफ़ॉर्म करने वाले स्टोर या एथलीट
- किसी वेबसाइट पर सबसे लोकप्रिय वीडियो
अगर किसी मॉडल के इन रुझानों का पता लगाया जाता है समय के साथ अपवाद के तौर पर सेट की गई वैल्यू, हकीकत से मेल नहीं खातीं. उदाहरण के लिए, यह अनुमान लगाना कि बेहद सफल स्टोर या वीडियो तब तक सफल रहेंगे, जब तक असल में वे ऐसा करते हैं नहीं है, तो पूछें:
- क्या औसत पर प्रतिगमन (रिग्रेशन) की वजह से समस्या हो सकती है?
- क्या सबसे ज़्यादा वेट वाली सुविधाओं का अनुमान लगाने के लिए, कम वज़न वाली सुविधाओं की तुलना में कम है?
- क्या ऐसा डेटा इकट्ठा किया जाता है जिसमें उन सुविधाओं की बेसलाइन वैल्यू होती है, अक्सर शून्य (कंट्रोल ग्रुप असरदार तरीके से) है, तो मॉडल के अनुमान बदलते हैं?
रेफ़रंस
हफ़, डैरिल. आंकड़ों का गलत इस्तेमाल करके झूठ कैसे बोलें. न्यूयॉर्क: डब्ल्यू॰डब्ल्यू॰ नॉर्टन, 1954.
जोन्स, बेन. डेटा में होने वाली समस्याओं से बचना. होबोकेन, न्यू जर्सी: Wiley, 2020.
ओ'कॉनर, कैलिन, और जेम्स ओवेन वेदरॉल. गलत जानकारी को फैलने से रोकने वाला युग. न्यू हेवन: येल यूपी, 2019.
रिंगलर, एडम, डेविड मेसन, गाबी लास्क, और मैरी टेंपलटन. "मेरे स्क्विगल अजीब क्यों दिखते हैं? हैक किए गए भूकंप के सिग्नल की गैलरी." Seismological Research Letters 92 no. 6 (जुलाई 2021). DOI: 10.1785/0220210094
वाइनट्रब, विलियम एस, थॉमस एफ़॰ Lüscher, और स्टुअर्ट पोकॉक. "सरोगेट एंडपॉइंट के खतरे." यूरोपियन हार्ट जर्नल 36 नंबर 33 (सितंबर 2015): 2212–2218. DOI: 10.1093/eurHeartj/ahv164
व्हीलन, चार्ल्स. छिपे हुए आंकड़े: डेटा से डर को दूर करना. न्यूयॉर्क: W.W. नॉर्टन, 2013
इमेज का रेफ़रंस
"सर्वाइवरशिप बायस." मार्टिन ग्रैंडजीन, मैकगेडन, और कैमरन मोल 2021. CC BY-SA 4.0. सोर्स
{kind=link}
-
जोन्स 25-29. ↩
-
ओ'कॉनर और वेदरॉल 22-3.↩
-
Ringling et al. ↩
-
Wheelan 120. ↩
-
सिद्धार्थ मुखर्जी, "क्या सेलफ़ोन से दिमाग का कैंसर होता है?" द न्यूयॉर्क टाइम्स में,13 अप्रैल, 2011 को हुआ था. व्हीलन 122 में बताया गया.↩
-
व्हीलन 39-40. ↩
-
मैलकम ग्लैडवेल, "द ऑर्डर ऑफ़ थिंग्स", द न्यू यॉर्कर में 14 फ़रवरी, 2011 को. व्हीलन 56 में बताया गया.↩