"I rifiuti, i rifiuti."
— Proverbio sulla programmazione iniziale
Sotto ogni modello ML, ogni calcolo di correlazione, e ogni modello ML il suggerimento sui criteri include uno o più set di dati non elaborati. Non importa quanto sia bella persuadere o impressionare i prodotti finali, se i dati sottostanti erano il modello risultante è errato, raccolto in modo scorretto o di bassa qualità. previsione, visualizzazione o conclusione avranno anch'essi un qualità. Chiunque visualizzi, analizzi e addestra i modelli dei set di dati devono porre domande dettagliate sull'origine dei dati.
Gli strumenti di raccolta dati possono non funzionare correttamente o essere calibrati male. Gli esseri umani che raccolgono dati possono essere stanchi, dispettosi, incoerenti o male addestrato. Le persone commettono errori e persone diverse possono anche ragionevolmente non essere d'accordo sulla classificazione di indicatori ambigui. Di conseguenza, la qualità e la validità dei dati può risentirne e questi potrebbero non riflettere la realtà. Ben Jones, autore di Evita dati Problemi, che vengono chiamati divario nella realtà nei dati Ricordare al lettore: "Non è crimine, è un reato segnalato. Non è il numero di impatti di meteoriti, è il numero di impatti di meteoriti registrati."
Esempi di divario nella realtà tra dati:
Jones traccia picchi nelle misurazioni del tempo a intervalli di 5 minuti e nelle misurazioni del peso a intervalli di 2,27 kg, non perché questi picchi esistano nei dati, ma perché i raccoglitori di dati umani, a differenza degli strumenti, hanno la tendenza a arrotondare i numeri al numero intero più vicino 0 o 5.1
Nel 1985, Joe Farman, Brian Gardiner e Jonathan Shanklin lavorano per il Britannico Antartide (BAS), ha rilevato che le loro misurazioni indicano una buco stagionale nello strato di ozono nell'emisfero australe. Questo in contraddizione con i dati della NASA, che non hanno rilevato simili errori. Il fisico della NASA Richard Stolarski ha studiato e ha scoperto che il software di elaborazione dei dati della NASA era progettate in base al presupposto che i livelli di ozono non potrebbero mai scendere al di sotto di una certa quantità e le letture molto, molto basse di ozono rilevate sono stati automaticamente lanciati come outlier incomprensibili.2
Gli strumenti riscontrano diverse modalità di errore, a volte pur raccogliendo dati. Adam Ringler et al. una galleria di immagini sismografiche letture derivanti da guasti dello strumento (e dai corrispondenti guasti) nell'articolo del 2021 "Why Do My Squiggles Look Funny?"3 L'attività nel le letture di esempio non corrispondono all'attività sismica effettiva.
Per i professionisti di ML, è fondamentale comprendere:
- Chi ha raccolto i dati
- Come e quando sono stati raccolti i dati e in quali condizioni
- La sensibilità e lo stato degli strumenti di misura
- Come potrebbero presentarsi i guasti degli strumenti e l'errore umano in un determinato contesto
- Le tendenze umane a arrotondare i numeri e fornire risposte desiderabili
Quasi sempre, c'è almeno una piccola differenza tra dati e realtà, noto anche come dati empirici reali. Tenere conto di questa differenza è fondamentale per trarre conclusioni efficaci e trarre prendere decisioni ponderate. Ciò include decidere:
- quali problemi possono e devono essere risolti con l'ML.
- quali problemi non sono risolti al meglio con l'ML.
- problemi che non dispongono ancora di dati di alta qualità sufficienti per essere risolti con l'ML.
Chiedi: cosa viene comunicato dai dati nel senso più stretto e letterale? E, cosa ancora più importante, cosa non viene comunicato dai dati?
Dati sporchi
Oltre a indagare sulle condizioni della raccolta dei dati, il set di dati a sua volta può contenere errori, errori e valori nulli o non validi (come misurazioni negative della concentrazione). I dati provenienti dal crowdsourcing possono essere particolarmente disordinato. L'utilizzo di un set di dati di qualità sconosciuta può portare a risultati imprecisi.
Tra i problemi più comuni sono inclusi i seguenti:
- Errori ortografici di valori di stringa, come luogo, specie o nomi di brand.
- Conversioni di unità, unità o tipi di oggetti errati
- Valori mancanti
- Classificazioni o etichette errate coerenti
- Cifre significative rimaste da operazioni matematiche che superano sensibilità effettiva di uno strumento
La pulizia di un set di dati spesso comporta la scelta di valori nulli e mancanti (sia per mantenerli null, rilasciarli o sostituire 0), correggendo l'ortografia in un versione singola, con la correzione di unità e conversioni e così via. Un modo più avanzato è l'attribuzione di valori mancanti, descritto in Caratteristiche dei dati in Machine Learning Crash Course.
Campionamento, bias di sopravvivenza e problema dell'endpoint surrogato
La statistica consente l'estrapolazione valida e accurata dei risultati da un campione puramente casuale alla popolazione più ampia. La fragilità non esaminata di questa ipotesi, insieme a input di addestramento sbilanciati e incompleti, ha portato a fallimenti di alto profilo di molte applicazioni di ML, inclusi i modelli utilizzati per le revisioni e il controllo dei curriculum. Inoltre, ha causato errori di polling e altre conclusioni errate sui gruppi demografici. Nella maggior parte dei contesti al di fuori dati artificiali generati al computer, anche i campioni puramente casuali sono costose e troppo difficili da acquisire. Varie soluzioni alternative e a prezzi accessibili che introducono origini diverse bias.
Per utilizzare il metodo di campionamento stratificato, ad esempio, devi conoscere il prevalenza di ogni strato campionato nella popolazione più ampia. Se presupponi una prevalenza effettivamente errata, i risultati saranno imprecisi. Allo stesso modo, i sondaggi online sono raramente un campione casuale di una popolazione nazionale, ma un campione della popolazione connessa a internet (spesso da più paesi) che vede il sondaggio ed è disposto a farlo. È probabile che questo gruppo sia diverso da un vero campione casuale. Le domande nel sondaggio sono un campione di possibili domande. Le risposte alle domande del sondaggio sono: ancora una volta, non un campione casuale di intervistati opinioni reali, ma un campione opinioni che i partecipanti si sentono a proprio agio nel fornire, che possono differire dalle loro opinioni reali.
I ricercatori in materia di salute clinica riscontrano un problema simile noto come surrogato dell'endpoint. Perché ci vuole troppo tempo per controllare gli effetti di un farmaco della vita di un paziente, i ricercatori utilizzano i biomarcatori proxy che si presume siano ma potrebbe non esserlo. I livelli di colesterolo vengono utilizzati come endpoint surrogato per gli attacchi di cuore e le morti causate da problemi cardiovascolari: se un farmaco riduce i livelli di colesterolo, si presume che riduca anche il rischio di problemi cardiaci. Tuttavia, questa catena di correlazione potrebbe non essere valida, altrimenti l'ordine di causale può essere diversa da quella ipotizzata dal ricercatore. Vedi Weintraub et al., "I pericoli degli endpoint surrogati", per altri esempi e dettagli. La situazione equivalente nell'apprendimento automatico è quella delle etichette proxy.
Il matematico Abraham Wald ha identificato un problema di campionamento dei dati ora noto come bias di sopravvivenza. Gli aerei da guerra tornavano con fori di proiettile in determinate località e non in altre. L'esercito americano voleva aggiungere altre armature agli aerei nelle aree con più fori di proiettili, ma il gruppo di ricerca di Wally è consigliabile aggiungere l'armatura ad aree senza fori di proiettile. Hanno dedotto correttamente che il campione di dati era distorto perché gli aerei hanno sparato quelle aree erano così gravemente danneggiate che non è stato possibile tornare alla base.
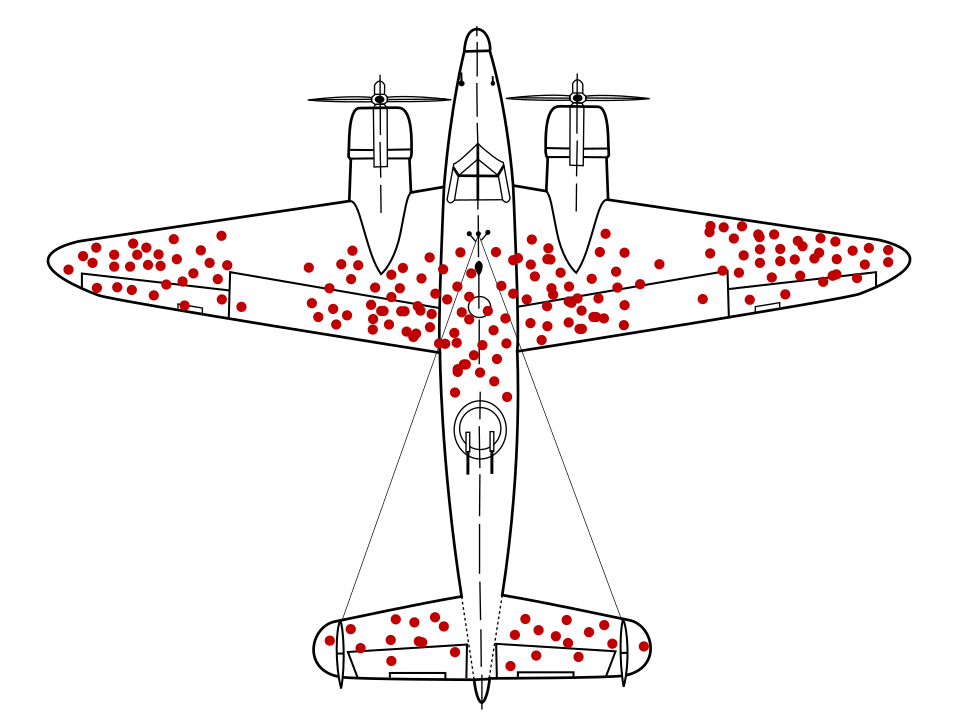
Avere un modello di raccomandazione dell'armatura addestrato esclusivamente su diagrammi di aerei da guerra, senza insight sui pregiudizi di sopravvivenza presenti nei dati, il modello avrebbe consigliato di rinforzare le aree con più fori di proiettile.
I bias di autoselezione possono derivare dal volontariato di soggetti umani per partecipare a uno studio. Ad esempio, i detenuti motivati a partecipare a un programma per la riduzione della recidiva potrebbero rappresentare una popolazione meno propensa a commettere reati futuri rispetto alla popolazione generale dei detenuti. Ciò potrebbe alterare i risultati.4
Un problema di campionamento più sottile è il bias di ricordo, che coinvolge la malleabilità dei ricordi dei soggetti umani. Nel 1993, Edward Giovannucci fece una domanda a un gruppo di persone della stessa età delle donne, ad alcune delle quali è stato diagnosticato un cancro, in merito alla loro precedente alimentazione abitudini sane. Le stesse donne avevano effettuato un sondaggio sulle abitudini alimentari prima di le diagnosi di tumore. Ciò che Giovannucci scoprì fu che le donne senza cancro le diagnosi ricordavano la dieta in modo accurato, ma le donne affette da tumore al seno hanno riportato consumare più grassi rispetto a quanto registrato in precedenza, inconsapevolmente fornendo una possibile (anche se imprecisa) spiegazione per il loro tumore.5
Chiedi:
- Che cos'è effettivamente il campionamento di un set di dati?
- Quanti livelli di campionamento sono presenti?
- Quale bias potrebbe essere introdotto a ogni livello di campionamento?
- Viene utilizzata la misurazione del proxy (che si tratti di biomarcatori, sondaggi online o punti elenco) foro) che mostrano una correlazione o una causa?
- Cosa potrebbe mancare nel campione e nel metodo di campionamento?
Il modulo Equità in Machine Learning Crash Course illustra come valutare e mitigare ulteriori fonti di bias nei set di dati demografici.
Definizioni e classifiche
Definisci i termini in modo chiaro e preciso oppure chiedi definizioni chiare e precise. Questa operazione è necessaria per capire quali caratteristiche dei dati vengono prese in considerazione e che cosa viene previsto o rivendicato esattamente. Charles Wheelan, in Naked Statistics, offre "la salute degli Stati Uniti produzione" un esempio di termine ambiguo. Se il settore manifatturiero negli Stati Uniti è "sano" dipende interamente da come viene definito il termine. Greg Ip Articolo di marzo 2011 su The Economist illustra questa ambiguità. Se la metrica per "salute" è "manifatturiero "output" poi nel 2011 la produzione americana era sempre più sana. Tuttavia, se la metrica "salute" è definita come "posti di lavoro nel settore manifatturiero", l'attività manifatturiera negli Stati Uniti era in calo.6
Spesso i ranking presentano problemi simili, ad esempio quelli oscurati o privi di senso ponderate assegnate a vari componenti della classifica, incoerenza e opzioni non valide. Malcolm Gladwell, scrivendo su The New Yorker, menziona il primo giudice della Corte Suprema del Michigan, Thomas Brennan, che una volta ha inviato un sondaggio a cento avvocati chiedendo loro di classificare dieci scuole di diritto in base alla qualità, alcune famose, altre meno. Questi avvocati hanno classificato la facoltà di legge della Penn State all'incirca al quinto posto benché al momento del sondaggio, la Penn State non aveva una legge di scuola.7 Molte classifiche note includono un approccio soggettivo il componente reputazionale. Chiedi quali sono i componenti che entrano in un ranking e perché ai componenti sono stati assegnati i loro pesi specifici.
Piccoli numeri ed effetti grandi
Non è sorprendente ottenere il 100% di teste o il 100% di croci se lanci una moneta due volte. Né è sorprendente ottenere il 25% di teste dopo aver lanciato una moneta quattro volte, seguito dal 75% di teste per i quattro lanci successivi, anche se questo dimostra un aumento apparentemente enorme (che potrebbe essere erroneamente attribuito a un panino mangiato tra le serie di lanci di monete o a qualsiasi altro fattore spurio). Tuttavia, man mano che il numero di lanci di monete aumenta, ad esempio fino a 1000 o 2000, le deviazioni percentuali elevate rispetto al 50% previsto diventano estremamente improbabili.
Spesso si fa riferimento al numero di misurazioni o di soggetti sperimentali in uno studio fino a N. Cambiamenti proporzionali di grandi dimensioni dovuti al caso hanno maggiori probabilità di si verificano in set di dati e campioni con un valore N basso.
Quando esegui un'analisi o documenti un set di dati in una scheda di dati, specifica N, in modo che altre persone possano prendere in considerazione l'influenza del rumore e della casualità.
Poiché la qualità del modello tende ad aumentare con il numero di esempi, un set di dati con un valore di N basso tende a produrre modelli di bassa qualità.
Regressione alla media
Analogamente, ogni misurazione che ha una qualche influenza per caso è soggetta a un noto come regressione alla media. Descrive come la misurazione dopo una misurazione particolarmente estrema potrebbe essere, in media, meno estrema o più vicina alla media, a causa di come era improbabile che la misurazione estrema si verificasse in primo luogo. La è più pronunciato se un gruppo particolarmente sopra la media o sotto la media è stato selezionato per l'osservazione, per vedere se il gruppo è la persona più alta in una della popolazione, i peggiori atleti di una squadra o quelli più a rischio di ictus. La i bambini delle persone più alte hanno in media più probabilità di essere più bassi dei loro genitori, è probabile che i peggiori atleti abbiano un rendimento migliore dopo un stagione cattiva e le persone più a rischio di ictus hanno probabilità di mostrare un rischio ridotto dopo qualsiasi intervento o trattamento, non a causa di fattori causali, grazie alle proprietà e alle probabilità della casualità.
Una mitigazione degli effetti della regressione alla media, quando si esplora interventi o trattamenti per un gruppo superiore o inferiore alla media, è dividere i soggetti in un gruppo di studio e un gruppo di controllo per isolare causali. Nel contesto dell'ML, questo fenomeno suggerisce di pagare su qualsiasi modello che prevede valori eccezionali o outlier, come:
- condizioni meteorologiche o temperature estreme
- negozi o atleti con il rendimento migliore
- video più popolari su un sito web
Se le previsioni in corso di un modello di questi valori eccezionali nel tempo non corrispondono alla realtà, ad esempio la previsione che un negozio o un video di grande successo continuerà ad avere successo, non è, chiedi:
- Il problema potrebbe essere la regressione alla media?
- Le funzionalità con i pesi più elevati sono in effetti più predittive rispetto a quelle con pesi inferiori?
- La raccolta di dati con il valore di riferimento per queste funzionalità, spesso pari a zero (in pratica un gruppo di controllo), influisce sulle previsioni del modello?
Riferimenti
Uff, Darrell. Come mentire con le statistiche. NY: W.W. Norton, 1954.
Jones, Ben. Evitare insidie relative ai dati. Hoboken, NJ: Wiley, 2020.
O'Connor, Cailin e James Owen Weatherall. L'era della disinformazione. Nuovo porto: Yale UP, 2019.
Ringler, Adam, David Mason, Gabi Laske e Mary Templeton. "Perché i miei scarafaggi hanno un aspetto divertente? Una galleria di indicatori sismici compromessi". Seismological Research Letter 92 n. 6 (luglio 2021). DOI: 10.1785/0220210094
Weintraub, William S, Thomas F. Lüscher e Stuart Pocock. "I pericoli degli endpoint surrogati." European Heart Journal 36 n. 33 (settembre 2015): 2212–2218. DOI: 10,1093/eurheartj/ehv164
Wheelan, Carlo. Statistiche nude: elimina i dati dal terrore. Roma: W.W. Norton, 2013
Riferimento immagine
"Pregiudizi di sopravvivenza." Martin Grandjean, McGeddon e Cameron Moll, 2021. CC BY-SA 4.0. Origine
{kind=link}
-
Jones 25-29. ↩
-
O'Connor e Weatherall 22-3. ↩
-
Ringling et al. ↩
-
Wheelan 120. ↩
-
Siddhartha Mukherjee "I cellulari causano il cancro al cervello?" su The New York Times, 13 aprile 2011. Citato in Wheelan 122.↩
-
Wheelan 39-40. ↩
-
Malcolm Gladwell "L'ordine delle cose", su The New Yorker, 14 febbraio 2011. Citato in Wheelan 56. ↩