"Se entra lixo, sai lixo."
— Provérbio sobre programação inicial
Abaixo de cada modelo de ML, cada cálculo de correlação e cada tipo de dado recomendação de política reside em um ou mais conjuntos de dados brutos. Não importa quão bonita ou surpreendentes ou persuasivos são os produtos finais, se os dados subjacentes foram o modelo resultante incorreto, mal coletado ou de baixa qualidade, previsão, visualização ou conclusão também serão de baixa de qualidade. Qualquer pessoa que visualiza, analisa e treina modelos conjuntos de dados devem fazer perguntas difíceis sobre a fonte dos dados.
Os instrumentos de coleta de dados podem não funcionar corretamente ou estar mal calibrados. Seres humanos que coletam dados podem estar cansados, travessos, inconsistentes ou mal para o codificador que treinamos. As pessoas cometem erros, e pessoas diferentes também podem discordar razoavelmente sobre a classificação de sinais ambíguos. Como resultado, a qualidade a validade dos dados pode ser afetada e os dados podem não refletir a realidade. Ben Jones, autor de Como evitar dados "Armadilhas", chama isso de lacuna de realidade de dados, lembrar ao leitor: "Não é crime, é denúncia. Não é o número de batidas de meteoros, é o número de ataques de meteoros registrados."
Exemplos de lacuna de realidade de dados:
Jones cria gráficos de picos nas medições de tempo em intervalos de cinco minutos, e medições de peso em intervalos de 5 lb, não porque esses picos existem mas como os coletores de dados humanos, ao contrário dos instrumentos, têm uma tendência para arredondar os números para a casa decimal mais próxima de 0 ou 5.1
Em 1985, Joe Farman, Brian Gardiner e Jonathan Shanklin, trabalhando para a British Antarctic Survey (BAS), descobriu que suas medições indicaram buraco sazonal na camada de ozônio no hemisfério sul. Isso contradiziam os dados da NASA, que não registraram esse buraco. Richard, físico da NASA Stolarski investigou e descobriu que o software de processamento de dados da NASA projetado com a suposição de que os níveis de ozônio jamais poderão ficar abaixo de determinada quantidade e em leituras muito baixas de ozônio que foram detectadas foram automaticamente descartados como outliers sem sentido.2
Os instrumentos têm diversos modos de falha, às vezes a coleta de dados. Adam Ringler e outros fornecer uma galeria de sismógrafos leituras resultantes de falhas de instrumentos (e as falhas correspondentes) no artigo de 2021 "Why Do My Squiggles Look Funny?"3 A atividade do curso as leituras de exemplo não correspondem à atividade sísmica real.
Os profissionais de ML precisam entender:
- Quem coletou os dados
- Como e quando os dados foram coletados e em que condições
- Sensibilidade e estado dos instrumentos de medição
- Como podem ocorrer falhas de instrumentos e erros humanos em um determinado contexto
- Tendências humanas de arredondar números e dar respostas desejáveis
Quase sempre, há pelo menos uma pequena diferença entre dados e realidade, também conhecidas como informações empíricas. Considerar essa diferença é fundamental para tirar boas conclusões e tomar decisões fundamentadas. Isso inclui decidir:
- quais problemas podem e precisam ser resolvidos pelo ML.
- quais problemas não são bem resolvidos pelo ML.
- quais problemas ainda não têm dados de alta qualidade suficientes para serem resolvidos pelo ML.
Pergunte: o que, do modo mais estrito e literal, os dados comunicam? Também é importante saber o que os dados não comunicam?
Sujeira nos dados
Além de investigar as condições de coleta de dados, o conjunto de dados em si pode conter erros, erros e valores nulos ou inválidos (como medições negativas de concentração). Os dados coletados pela comunidade podem ser especialmente bagunçada. Trabalhar com um conjunto de dados de qualidade desconhecida pode gerar resultados imprecisos.
Exemplos de problemas comuns:
- Erros ortográficos de valores de string, como lugar, espécie ou nome de marca
- Conversões de unidade, unidades ou tipos de objeto incorretos
- Valores ausentes
- Classificações incorretas ou rotineiras consistentes
- Dígitos significativos deixados pelas operações matemáticas que excedem o sensibilidade real de um instrumento
A limpeza de um conjunto de dados geralmente envolve escolhas sobre valores nulos e ausentes (se para mantê-las como nulas, eliminá-las ou substituí-las por 0s), corrigindo a ortografia de única versão, correção de unidades e conversões etc. Um modelo mais avançado técnica é imputar valores ausentes, que é descrita em Características dos dados no curso intensivo de machine learning.
Amostragem, viés de sobrevivência e o problema de endpoint alternativo
As estatísticas permitem a extrapolação válida e precisa de resultados de uma amostra puramente aleatória para a população maior. A fragilidade indiscutível dos essa suposição, junto com entradas de treinamento desequilibradas e incompletas, levou a falhas importantes de diversas aplicações de ML, incluindo modelos usados para para retomar as análises e o policiamento. Isso também causou falhas na sondagem e outras conclusões errôneas sobre grupos demográficos. Na maioria dos contextos, dados artificiais gerados por computador, amostras puramente aleatórias também caros e difíceis de adquirir. Várias soluções alternativas e acessíveis proxies são usados no lugar, introduzindo diferentes fontes viés.
Para usar o método de amostragem estratificada, por exemplo, você precisa conhecer prevalência de cada estrato amostrado na população maior. Se você presumir uma prevalência que está realmente incorreta, seus resultados serão imprecisos. Da mesma forma, as pesquisas online raramente são uma amostra aleatória de uma população nacional, mas uma amostra da população conectada à Internet (geralmente de vários países) que vê e está disposto a participar da pesquisa. É provável que esse grupo seja diferente de uma amostra aleatória real. As perguntas da seção de pesquisa são um exemplo de possíveis perguntas. As respostas a essas perguntas da enquete são: de novo, não uma amostra aleatória dos entrevistados de opiniões reais, mas uma amostra opiniões que os entrevistados se sentem à vontade para dar, que podem ser diferentes das de opiniões reais.
Pesquisadores de saúde clínicas encontram um problema semelhante conhecido como alternativo em um endpoint de machine learning. Como leva muito tempo para verificar o efeito de um medicamento tempo de vida do paciente, os pesquisadores usam biomarcadores substitutos relacionados à vida útil, mas podem não estar. Os níveis de colesterol são usados como um alternativo para ataques cardíacos e mortes causadas por problemas cardiovasculares: se um medicamento reduz os níveis de colesterol, também reduz o risco de problemas cardíacos. No entanto, essa cadeia de correlação pode não ser válida, ou a ordem a causalidade pode ser diferente do que o pesquisador supõe. Vide Weintraub et al., "Os perigos dos endpoints alternativos", para mais exemplos e detalhes. A situação equivalente no ML é a marcadores de proxy.
O matemático Abraham Wald identificou um problema de amostragem de dados conhecido como viés de sobrevivência. Aviões de guerra estavam retornando com buracos de balas locais específicos e não em outros. Os militares dos EUA queriam adicionar mais armaduras. aos aviões nas áreas com mais buracos, mas o grupo de pesquisa do Wald recomendamos adicionar a armadura a áreas sem buracos. Ele deduziu corretamente que a amostra de dados foi distorcida porque os aviões dispararam essas áreas foram tão danificadas que não puderam voltar à base.
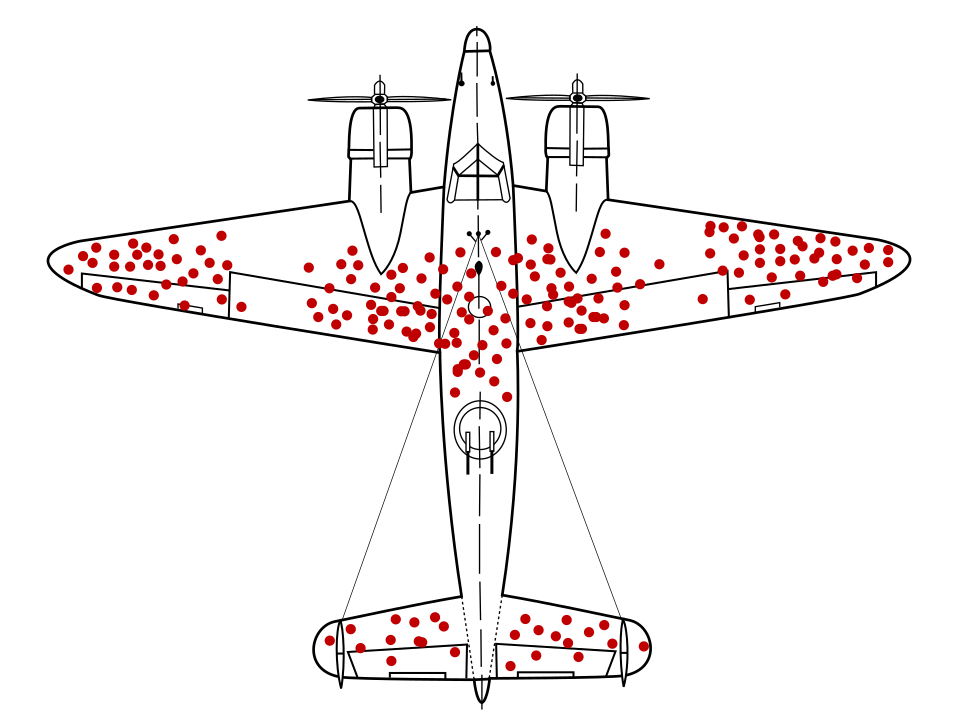
Teria um modelo de recomendação de armaduras treinado exclusivamente com diagramas de retorno aviões de guerra, sem insights sobre o viés de sobrevivência presente nos dados, esse modelo recomendaria reforçar as áreas com mais buracos.
O viés de autoseleção pode surgir de seres humanos que se voluntariaram para de participar de um estudo. Presidiários motivados a se inscreverem em um programa de redução da reincidência por exemplo, pode representar uma população com menor probabilidade de se comprometer crimes futuros do que a população internada em geral. Isso distorceria os resultados.4
Um problema de amostragem mais sutil é o viés de recall, que envolve a maleabilidade da seres humanos memórias. Em 1993, Edward Giovannucci pediu a um grupo de idade das mulheres, algumas das quais foram diagnosticadas com câncer, sobre as tendências alimentares hábitos de consumo. As mesmas mulheres fizeram uma pesquisa sobre hábitos alimentares antes do diagnósticos de câncer. Giovannucci descobriu que mulheres sem câncer diagnósticos lembram sua dieta com precisão, mas mulheres com câncer de mama relataram consumindo mais gorduras do que relataram anteriormente, inconscientemente fornecendo uma explicação possível (embora imprecisa) para a doença.5
Pergunte:
- O que é uma amostragem de conjunto de dados?
- Quantos níveis de amostragem estão presentes?
- Qual viés pode ser introduzido em cada nível de amostragem?
- A medição de proxy é usada (seja biomarcador, enquete on-line ou marcador? buraco) mostrando correlação ou causalidade real?
- O que pode estar faltando na amostra e no método de amostragem?
O módulo imparcialidade do curso intensivo de machine learning aborda maneiras de avaliar e mitigar fontes adicionais de viés em conjuntos de dados demográficos.
Definições e classificações
Defina os termos de forma clara e precisa ou pergunte sobre definições claras e precisas. Isso é necessário para entender quais recursos de dados estão em consideração e o que exatamente está sendo previsto ou reivindicado. Charles Wheelan, no site Naked Statistics, fala "a saúde dos EUA manufatura" como exemplo de um termo ambíguo. Se a manufatura dos EUA "saudável" depende totalmente de como o termo é definido. de Greg Ip Artigo de março de 2011 no The Economist ilustra essa ambiguidade. Se a métrica para "health" é “fabricar saída", Em seguida, em 2011, a fabricação dos EUA estava cada vez mais saudável. Se o "saúde" é definida como "empregos na indústria", No entanto, as empresas de manufatura dos EUA estava em declínio.6
As classificações geralmente sofrem de problemas semelhantes, incluindo questões ocultas ou sem sentido pesos dados a vários componentes da classificação, os pontos inconsistências e opções inválidas. Malcolm Gladwell, em The New Yorker, menciona uma O presidente do Supremo Tribunal de Michigan, Thomas Brennan, que enviou uma vez uma pesquisa a centenas de advogados pedindo para classificar dez faculdades de direito por qualidade, algumas famosas, outros não. Esses advogados classificaram a faculdade de direito da Penn State em aproximadamente cinco local. No entanto, na época da pesquisa, a Penn State não tinha uma lei escola.7 Muitas classificações bem conhecidas incluem uma abordagem subjetiva o componente da reputação. Pergunte quais componentes fazem parte de uma classificação e por que eles componentes receberam pesos específicos.
Números pequenos e efeitos grandes
Não surpreende que você receba 100% cara ou coroa ao jogar uma moeda duas vezes. Também não é surpreendente receber 25% de cara depois de jogar uma moeda quatro vezes, então 75% de cara para os próximos quatro saltos, embora isso demonstre uma aumento enorme (que poderia ser erroneamente atribuído ao sanduíche consumido entre jogadas de moedas ou qualquer outro fator falso). Mas, como o número de cara ou coroa aumenta, digamos, para 1.000 ou 2.000, grandes desvios percentuais os 50% esperados se tornam improváveis.
O número de medições ou participantes experimentais em um estudo é frequentemente mencionado como N. Grandes mudanças proporcionais devido ao acaso têm muito mais probabilidade de ocorrer em conjuntos de dados e amostras com um N baixo.
Ao realizar uma análise ou documentar um conjunto de dados em um cartão de dados, especifique N, para que outras pessoas possam considerar a influência do ruído e da aleatoriedade.
Como a qualidade do modelo tende a crescer com o número de exemplos, um conjunto de dados um N baixo tende a resultar em modelos de baixa qualidade.
Regressão para a média
Da mesma forma, qualquer medição que tenha alguma influência do acaso está sujeita a um efeito conhecido como regressão à média. Descreve como a medição após uma medição particularmente extrema é, em média, provavelmente menos extrema ou mais próxima da média, devido à improvável que a medição extrema ocorresse inicialmente. O o efeito será mais pronunciado se um grupo particularmente acima ou abaixo da média foi selecionado para observação, se esse grupo é as pessoas mais altas em um os piores atletas de uma equipe ou aqueles com maior risco de derrame. O os filhos das pessoas mais altas têm, em média, mais probabilidade de serem menores do que pais, os piores atletas provavelmente terão um desempenho melhor após um período época ruim, e aqueles com maior risco de derrame provavelmente apresentam risco reduzido após qualquer intervenção ou tratamento, não por causa de fatores causativos, mas por causa das propriedades e probabilidades de aleatoriedade.
Uma mitigação para os efeitos da regressão à média, ao analisar intervenções ou tratamentos para um grupo acima ou abaixo da média, é dividir os participantes em um grupo de estudo e um grupo de controle para isolar efeitos causativos. No contexto de ML, esse fenômeno sugere pagar mais atenção a qualquer modelo que preveja valores excepcionais ou atípicos, como:
- clima ou temperaturas extremas
- lojas ou atletas com melhor desempenho
- vídeos mais populares em um site
Se as previsões contínuas desse modelo valores excepcionais ao longo do tempo não correspondem à realidade, por exemplo, prevendo que um loja ou vídeo de sucesso continuará tendo sucesso quando, na verdade, não for, pergunte:
- O problema pode estar em regressão à média?
- Os atributos com os pesos mais altos são, na verdade, mais preditivos? do que atributos com pesos menores?
- A coleta de dados que têm o valor de referência para esses atributos muitas vezes zero (efetivamente um grupo de controle) altera as previsões do modelo?
Referências
Huff, Darrell. Como mentir com estatísticas. NY: W.W. Norton, 1954.
Jonas, Ben. Como evitar armadilhas de dados. Hoboken, Nova Jersey: Wiley, 2020.
O'Connor, Cailin e James Owen Weatherall. A era da desinformação. New Haven: Yale, UN, 2019.
Ringler, Adam, David Mason, Gabi Laske e Mary Templeton. "Por que meus rabiscos parecem engraçados? A Gallery of Compromised Sísmic Signals." Seismological Research Letters 92 no. 6 (julho de 2021). DOI: 10.1785/0220210094
Weintraub, William S, Thomas F. Lüscher e Stuart Pocock. "Os perigos dos endpoints alternativos." European Heart Journal 36 no 33 (setembro de 2015): 2212–2218. DOI: 10.1093/eurheartj/ehv164
Wheelan, Charles. Naked Statistics: removendo o Dread dos dados. Nova York: W.W. Norton, 2013
Referência de imagem
"Viés de sobrevivência". Martin Grandjean, McGeddon e Cameron Moll, 2021. CC BY-SA 4.0 Origem
{kind=link}
-
Jonas 25 a 29. ↩
-
O'Connor e Weatherall 22 e 3. ↩
-
Ringling e outros ↩
-
Wheelan 120. ↩
-
Siddhartha Mukherjee, "Os celulares causam câncer cerebral?" no The New York Times, 13 de abril de 2011. Citado em Wheelan 122. ↩
-
Wheelan 39 a 40. ↩
-
Malcolm Gladwell, "A Ordem das Coisas", no The New Yorker 14 de fevereiro de 2011. Citado em Wheelan 56. ↩