"ขยะเข้า ขยะออก"
— สุภาษิตของ Early Programming
ภายใต้โมเดล ML ทั้งหมด การคำนวณสหสัมพันธ์ทั้งหมด และอิงตามข้อมูลทั้งหมด คำแนะนำนโยบายจะมีชุดข้อมูลดิบอย่างน้อย 1 รายการ ไม่ว่าจะสวยงามหรือ ผลิตภัณฑ์ปลายทางที่มีความโดดเด่นหรือโน้มน้าวใจ นั่นคือ หากข้อมูลพื้นฐานคือ โมเดลที่ได้มาอย่างไม่ถูกต้อง รวบรวมมาไม่ดี หรือมีคุณภาพต่ำ การคาดการณ์ การแสดงข้อมูลผ่านภาพ หรือข้อสรุปก็จะอยู่ในระดับต่ำเช่นกัน ของคุณ ผู้ที่แสดงภาพ วิเคราะห์ และฝึกโมเดล ชุดข้อมูลควรถามคำถามที่ตรงประเด็นเกี่ยวกับแหล่งที่มาของข้อมูล
เครื่องมือเก็บรวบรวมข้อมูลอาจทำงานผิดพลาดหรือมีการปรับเทียบที่ไม่ดี มนุษย์นักเก็บรวบรวมข้อมูลอาจเหนื่อย ซุกซน ไม่สอดคล้อง หรือแย่ ผ่านการฝึกอบรมแล้ว คนเราผิดพลาดได้ และแต่ละคนอาจไม่เห็นด้วยพอสมควร ในการจัดประเภทสัญญาณที่คลุมเครือ ด้วยเหตุนี้ คุณภาพและ ความถูกต้องของข้อมูลอาจได้รับผลกระทบ และข้อมูลอาจไม่ได้สะท้อนถึงความเป็นจริง เบน โจนส์ ผู้เขียน การหลีกเลี่ยงข้อมูล กับดัก เรียกสิ่งนี้ว่า ช่องว่างของความเป็นจริงข้อมูล (Data- Reality) ย้ำเตือนผู้อ่านว่า "ไม่ใช่อาชญากรรม แต่เป็นอาชญากรรมที่มีการรายงาน ซึ่งไม่ใช่ จำนวนประกาศเตือนอุกกาบาต ซึ่งก็คือจำนวนประกาศเตือนอุกกาบาตที่บันทึกไว้"
ตัวอย่างของช่องว่างระหว่างความจริงของข้อมูล (Data- Reality)
กราฟของ Jones พุ่งสูงขึ้นในการวัดเวลาช่วง 5 นาที และ การวัดน้ำหนักที่ช่วง 5 ปอนด์ ไม่ใช่เพราะช่วง แต่เนื่องจากผู้เก็บรวบรวมข้อมูลมนุษย์มีแนวโน้มที่จะ เพื่อปัดเศษตัวเลขให้เป็นจำนวนเต็ม 0 หรือ 5 ที่ใกล้ที่สุด1
ในปี 1985 Joe Farman, Brian Gardiner และ Jonathan Shanklin ทำงานให้ทีม British Antarctic Survey (BAS) พบว่าการวัดผลบ่งชี้ถึง ช่องโหว่ตามฤดูกาลในชั้นโอโซนเหนือซีกโลกใต้ ช่วงเวลานี้ ขัดแย้งกับข้อมูลของ NASA ซึ่งไม่มีการบันทึกใดๆ Richard นักฟิสิกส์ของ NASA Stolarski ได้สืบสวนและพบว่าซอฟต์แวร์การประมวลผลข้อมูลของ NASA โดยอยู่ภายใต้สมมติฐานว่าระดับโอโซนต่ำกว่า รวมถึงค่าโอโซนที่อ่านได้ต่ำมากๆ ถูกโยนทิ้งโดยอัตโนมัติว่าเป็นค่าผิดปกติ2
เครื่องดนตรีมีโหมดการทำงานล้มเหลวหลายรูปแบบ บางครั้งในขณะที่อยู่นิ่งๆ กำลังรวบรวมข้อมูล Adam Ringler และคณะ ให้แกลเลอรีแผ่นดินไหว ค่าที่อ่านได้ซึ่งเป็นผลจากเครื่องมือล้มเหลว (และความล้มเหลวที่เกี่ยวข้อง) ในบทความปี 2021 "Why Do My Squiggles Look Funny?"3 กิจกรรมใน ตัวอย่างข้อมูลที่อ่านได้ไม่สอดคล้องกับการเกิดแผ่นดินไหวจริง
สำหรับผู้ปฏิบัติงานด้าน ML เป็นสิ่งสำคัญที่จะต้องทำความเข้าใจสิ่งต่อไปนี้
- ใครเก็บรวบรวมข้อมูล
- วิธีการและเวลาที่มีการรวบรวมข้อมูลและภายใต้เงื่อนไขใด
- ความไวและสถานะของเครื่องมือวัด
- ความล้มเหลวของเครื่องมือและความผิดพลาดของมนุษย์ใน บริบท
- แนวโน้มของมนุษย์ในการปัดเศษตัวเลขและให้คำตอบที่ต้องการ
แทบทุกกรณี อย่างน้อยก็มีความแตกต่างเล็กๆ น้อยๆ ระหว่างข้อมูลและความเป็นจริง หรือที่เรียกว่าข้อมูลจากการสังเกตการณ์โดยตรง การพิจารณาความแตกต่างนี้จึงเป็นกุญแจสำคัญในการหาข้อสรุปที่ดีและการทำให้ การตัดสินใจที่เหมาะสม ซึ่งรวมถึงการตัดสินใจต่อไปนี้
- โจทย์ที่ ML แก้ไขได้และควรแก้ไข
- ปัญหาที่ ML ไม่สามารถแก้ไขได้ดีที่สุด
- ว่าปัญหาใดยังไม่มีข้อมูลคุณภาพสูงเพียงพอที่จะให้ ML แก้ไขได้
ถาม: ข้อมูลที่สื่อสารผ่านข้อมูลที่เป็นการสื่อสารที่เข้มงวดที่สุดและมีความหมายตรงตัวที่สุดคืออะไร และที่สำคัญไม่แพ้กัน สิ่งใดที่ไม่ได้สื่อสารโดยข้อมูล
สิ่งสกปรกในข้อมูล
นอกจากการตรวจสอบเงื่อนไขในการเก็บรวบรวมข้อมูลแล้ว ชุดข้อมูล ตนเองอาจมีความผิดพลาด ข้อผิดพลาด และค่า Null หรือค่าที่ไม่ถูกต้อง (เช่น ผลการวัดความเข้มข้นติดลบ) โดยเฉพาะอย่างยิ่งข้อมูลที่ได้จากมวลชน ไม่เป็นระเบียบ การทำงานกับชุดข้อมูลที่ไม่ทราบคุณภาพอาจทำให้ผลลัพธ์ไม่ถูกต้อง
ปัญหาที่พบได้ทั่วไปมีดังนี้
- การสะกดผิดของค่าสตริง เช่น สถานที่ สายพันธุ์ หรือชื่อแบรนด์
- การแปลงหน่วย หน่วย หรือประเภทออบเจ็กต์ไม่ถูกต้อง
- ไม่มีค่า
- การจัดประเภทที่ไม่ถูกต้องอย่างต่อเนื่องหรือการติดป้ายกำกับที่ไม่ถูกต้อง
- ตัวเลขจำนวนมากที่เหลือจากการคำนวณทางคณิตศาสตร์ที่เกิน ความไวที่แท้จริงของเครื่องมือ
การทำความสะอาดชุดข้อมูลมักจะมีตัวเลือกเกี่ยวกับค่า Null และค่าที่หายไป (เช่น ทำให้เป็นค่าว่าง แทนที่ด้วย 0 หรือแทน 0) การแก้ไขการสะกดเป็น เวอร์ชันเดียว การแก้ไขหน่วยและ Conversion เป็นต้น ขั้นสูงขึ้น เทคนิคนี้ก็คือการป้องกันไม่ให้ค่าที่ขาดไป ซึ่งอธิบายไว้ใน ลักษณะของข้อมูล ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิง
การสุ่มตัวอย่าง ความลำเอียงในการเอาตัวรอด และปัญหาปลายทางของการเป็นตัวแทน
สถิติช่วยให้สามารถประมาณค่าผลลัพธ์จาก กลุ่มตัวอย่างล้วนๆ ไปยังประชากรกลุ่มใหญ่ ความเปราะบางของ สมมติฐานนี้ รวมถึงอินพุตการฝึกที่ไม่สมดุลและไม่สมบูรณ์ ต่อความล้มเหลวที่สำคัญของแอปพลิเคชัน ML จำนวนมาก รวมถึงโมเดลที่ใช้สำหรับ ตรวจสอบและตรวจตราต่อ และยังนำไปสู่การทำโพล ไม่สำเร็จ ข้อสรุปที่ผิดพลาดเกี่ยวกับกลุ่มประชากร ในบริบทส่วนใหญ่ที่ไม่ใช่ ข้อมูลที่คอมพิวเตอร์ประดิษฐ์สร้างขึ้น ตัวอย่างแบบสุ่มเพียงอย่างเดียวนั้น มีราคาแพงและหาได้ยากเกินไป วิธีแก้ปัญหาเบื้องต้นที่หลากหลายและราคาไม่แพง จึงมีการใช้พร็อกซีแทน ซึ่งมีแหล่งที่มาของ อคติ
ตัวอย่างเช่น หากต้องการใช้วิธีการสุ่มตัวอย่างแบบแบ่งเป็นชั้น คุณจะต้องทราบ ความชุกของชั้นเก็บตัวอย่างแต่ละชั้นในประชากรกลุ่มใหญ่ หากคุณสันนิษฐาน แต่เป็นความชุกที่ไม่ถูกต้อง ผลลัพธ์ของคุณก็จะคลาดเคลื่อน ในทำนองเดียวกัน แบบสำรวจออนไลน์มักจะไม่ใช่กลุ่มตัวอย่าง ของประชากรในประเทศ แต่เป็นตัวอย่างของประชากรที่เชื่อมต่อกับอินเทอร์เน็ต (มักมาจากหลายประเทศ) ที่เห็นและยินดีตอบแบบสำรวจ กลุ่มนี้มีแนวโน้มที่จะแตกต่างจากกลุ่มตัวอย่างจริงแบบสุ่ม คำถามใน คือตัวอย่างของคำถามที่เป็นไปได้ คำตอบสำหรับคำถามของแบบสำรวจเหล่านั้นคือ ไม่ใช่กลุ่มตัวอย่างของผู้ตอบแบบสอบถาม ความคิดเห็นจริงของคุณ แต่เป็นตัวอย่าง ความคิดเห็นที่ผู้ตอบแบบสำรวจรู้สึกสบายใจ ซึ่งอาจต่างจาก ความคิดเห็นจริงของคุณ
นักวิจัยสุขภาพทางคลินิกพบปัญหาที่คล้ายกันซึ่งเรียกว่าตัวแทน ปัญหาปลายทาง เนื่องจากการตรวจสอบผลกระทบของยาใช้เวลานานเกินไป อายุขัยของผู้ป่วย นักวิจัยใช้ดัชนีชี้วัดทางชีวภาพพร็อกซีที่สันนิษฐานว่า เกี่ยวข้องกับอายุการใช้งาน แต่อาจไม่เป็นเช่นนั้น ระดับคอเลสเตอรอลใช้เป็นตัวแทน ปลายทางโรคหัวใจวายและการเสียชีวิตเนื่องจากปัญหาเกี่ยวกับหัวใจและหลอดเลือด: หากมียา ช่วยลดระดับคอเลสเตอรอลได้ แต่ก็ถือว่าลดความเสี่ยงของปัญหาเกี่ยวกับหัวใจได้เช่นกัน อย่างไรก็ตาม ห่วงโซ่ความสัมพันธ์อาจไม่ถูกต้อง หรือลำดับของความสัมพันธ์ สาเหตุอาจเป็นสิ่งอื่นนอกเหนือจากที่ผู้วิจัยสันนิษฐาน โปรดดู Weintraub และคณะ, "อันตรายของปลายทางที่เป็นตัวแทน" เพื่อดูตัวอย่างและรายละเอียดเพิ่มเติม สถานการณ์ที่เทียบเท่าใน ML คือ ป้ายกำกับพร็อกซี
นักคณิตศาสตร์อับราฮัม วอลด์ ได้ระบุถึงปัญหาการสุ่มตัวอย่างข้อมูลที่ทราบกันดีในปัจจุบัน อคติจากการอยู่รอด เครื่องบินรบกลับมาโดยมีรูกระสุนใน เฉพาะในบางตำแหน่งเท่านั้น กองทัพสหรัฐฯ ต้องการเพิ่มชุดเกราะ เครื่องบินได้ในบริเวณที่มีรูกระสุนมากที่สุด แต่กลุ่มวิจัยของวสันต์ แนะนำให้ใส่เกราะป้องกันไว้ในส่วนที่ไม่มีรูกระสุนแทน พวกเขาอนุมานได้ถูกต้องว่าตัวอย่างข้อมูลของตนเอียงเนื่องจากเครื่องบินที่ยิง พื้นที่เหล่านั้นได้รับความเสียหายมากจนไม่สามารถจะกลับสู่ฐานทัพได้
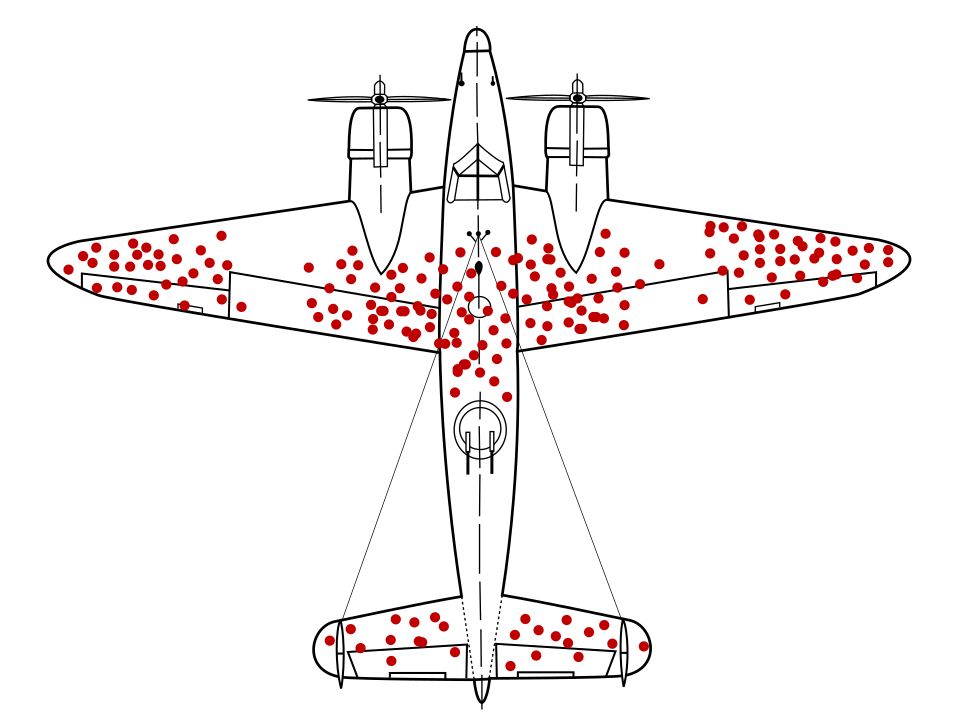
เคยมีการฝึกโมเดลแนะนำชุดเกราะผ่านแผนภาพการส่งคืน เครื่องบินรบโดยไม่มีข้อมูลเชิงลึกเกี่ยวกับอคติในการรอดชีวิตที่อยู่ในข้อมูล โมเดลดังกล่าวจะแนะนำให้เสริมพื้นที่ที่มีรูกระสุนมากขึ้น
อคติในการคัดเลือกตนเองอาจเกิดขึ้นจากการที่มนุษย์อาสาที่จะ เข้าร่วมการศึกษา ผู้ต้องขังที่มีแรงจูงใจให้สมัครขอลดการทำนายจากการกระทำผิดซ้ำ เช่น อาจเป็นตัวแทนของประชากร ที่มีแนวโน้มที่จะมีส่วนร่วม อาชญากรรมในอนาคตที่มากกว่าจำนวนผู้ต้องขังทั่วไป การดำเนินการนี้จะทำให้ผลลัพธ์บิดเบือน4
ปัญหาการสุ่มตัวอย่างที่ละเอียดกว่าคืออคติในการจดจำ ซึ่งเกี่ยวข้องกับความสามารถในการเปลี่ยน เกี่ยวกับมนุษย์ ความทรงจำ ในปี 1993 Edward Giovannucci ได้ถามกลุ่มอายุที่ตรงกับอายุ ของผู้หญิง ซึ่งบางคนเคยได้รับการวินิจฉัยว่าเป็นโรคมะเร็งเกี่ยวกับอาหารการกินที่ผ่านมา จนเป็นนิสัย กลุ่มเดิมของผู้หญิงเคยทำแบบสอบถามเกี่ยวกับพฤติกรรมการรับประทานอาหาร การวินิจฉัยโรคมะเร็งได้ Giovannucci ค้นพบว่าผู้หญิงที่ไม่เป็นมะเร็งนั้น วินิจฉัยกลับมารับประทานอาหารได้ถูกต้อง แต่มีรายงานว่าพบผู้หญิงที่เป็นมะเร็งเต้านม การบริโภคไขมันมากกว่าที่เคยรายงานไว้ ทั้งๆ ที่ไม่รู้ตัว ให้คำอธิบายที่เป็นไปได้ (แต่กลับไม่ถูกต้อง) เกี่ยวกับมะเร็งของตน5
คำถาม:
- ชุดข้อมูลสุ่มตัวอย่างจริงคืออะไร
- มีการสุ่มตัวอย่างกี่ระดับ
- การให้น้ำหนักพิเศษแต่ละระดับอาจมาจากการให้น้ำหนักพิเศษแบบใดบ้าง
- มีการใช้การวัดพร็อกซี (ไม่ว่าจะเป็นดัชนีชี้วัดทางชีวภาพ แบบสำรวจ หรือหัวข้อย่อยออนไลน์) หลุม) ที่แสดงความสัมพันธ์หรือความเป็นเหตุผลที่แท้จริงได้อย่างไร
- สิ่งใดที่อาจขาดหายไปจากตัวอย่างและวิธีการสุ่มตัวอย่าง
โมดูลความยุติธรรม ในหลักสูตรเร่งรัดเกี่ยวกับแมชชีนเลิร์นนิงครอบคลุมถึงวิธีประเมินและลดผลกระทบ แหล่งที่มาของการให้น้ำหนักพิเศษเพิ่มเติมในชุดข้อมูลข้อมูลประชากร
คำจำกัดความและการจัดอันดับ
นิยามคำศัพท์ที่ชัดเจนและแม่นยำ หรือถามเกี่ยวกับคำจำกัดความที่ชัดเจนและแม่นยำ ข้อมูลนี้จําเป็นต่อการทําความเข้าใจฟีเจอร์ข้อมูลที่อยู่ระหว่างการพิจารณา และสิ่งที่คาดการณ์หรืออ้างสิทธิ์ไว้ Charles Wheelan ใน Naked Statistics นำเสนอ "สุขภาพของสหรัฐอเมริกา การผลิต" เป็นตัวอย่างของคำที่กำกวม การผลิตในสหรัฐอเมริกา "สุขภาพ" หรือไม่ขึ้นอยู่กับความหมายของคำนั้น Greg Ip บทความเดือนมีนาคม 2011 ใน The Economist จะแสดงให้เห็นความกำกวมนี้ หากเมตริกสำหรับ "สุขภาพ" คือ "การผลิต เอาต์พุต" จากนั้นในปี 2011 การผลิตในสหรัฐอเมริกามีสุขภาพดีขึ้นเรื่อยๆ หาก "สุขภาพ" คือ "งานการผลิต" แต่การผลิตในสหรัฐอเมริกา ถูกปฏิเสธ6
การจัดอันดับมักมีปัญหาที่คล้ายคลึงกัน รวมถึงถูกบดบังหรือไม่สื่อความหมาย องค์ประกอบต่างๆ ของการจัดอันดับ การจัดอันดับ ความไม่สอดคล้องกัน และ ตัวเลือกที่ไม่ถูกต้อง Malcolm Gladwell เขียนใน The New Yorker กล่าวว่า Thomas Brennan ผู้พิพากษาศาลฎีกาแห่งมิชิแกนผู้เคยส่งแบบสำรวจให้ ทนายความ 100 คนขอให้จัดอันดับโรงเรียนกฎหมาย 10 แห่งตามคุณภาพ บางแห่งมีชื่อเสียง บ้างก็ไม่ใช่ ทนายความเหล่านั้นจัดอันดับโรงเรียนกฎหมายของ Penn State ไว้ที่ประมาณ 5 แม้ว่าในขณะที่ทำการสำรวจ เพนน์สเตตไม่มีกฎหมาย สถานศึกษา7 การจัดอันดับที่เป็นที่รู้จักจํานวนมากมีความเห็นจากความคิดเห็นส่วนตัวที่คล้ายคลึงกัน ซึ่งเป็นองค์ประกอบที่มีชื่อเสียง ถามเกี่ยวกับคอมโพเนนต์ที่มีการจัดอันดับ และเหตุผลที่ องค์ประกอบได้รับการกำหนดน้ำหนักเฉพาะเจาะจง
เอฟเฟกต์จำนวนน้อยแต่มาก
การได้หัว 100% หรือก้อย 100% แม้จะโยนหัวก้อย ก็ไม่น่าแปลกใจเลย 2 ครั้ง ไม่น่าแปลกใจถ้าได้หัว 25% หลังโยนเหรียญไป 4 ครั้ง ก็จะได้หัวถึง 75% สำหรับอีก 4 ตีลังกาถัดไป แต่ก็เห็นได้ชัดว่า เพิ่มขึ้นอย่างมาก (ซึ่งอาจเกิดจากการกินแซนด์วิชอย่างไม่ถูกต้อง ระหว่างรอบการโยนเหรียญหรือตัวประกอบอื่นๆ ที่ไม่ปกติ) แต่เมื่อเป็นตัวเลข ของการโยนเหรียญเพิ่มขึ้น เช่น 1,000 หรือ 2,000 เปอร์เซ็นต์ ความคลาดเคลื่อนจาก ก็คาดว่า 50% นั้นไม่น่าจะหายไปเลย
จำนวนของการวัดผลหรือหัวข้อทดสอบในการศึกษามักอ้างถึง เป็น N การเปลี่ยนแปลงสัดส่วนอย่างมากเนื่องจากมีโอกาส เกิดขึ้นในชุดข้อมูลและตัวอย่างที่มี N ต่ำ
เมื่อดำเนินการวิเคราะห์หรือบันทึกชุดข้อมูลในการ์ดข้อมูล ให้ระบุ N เพื่อให้ผู้อื่นพิจารณาอิทธิพลของเสียงและการสุ่มได้
เนื่องจากคุณภาพของโมเดลมีแนวโน้มจะปรับขึ้นตามจำนวนตัวอย่าง ชุดข้อมูลที่มี N ที่ต่ำมีแนวโน้มจะทำให้โมเดลมีคุณภาพต่ำ
การถดถอยถึงค่าเฉลี่ย
ในทำนองเดียวกัน การวัดใดๆ ที่มีอิทธิพลจากความบังเอิญจะต้องอยู่ภายใต้ เอฟเฟ็กต์ที่เรียกว่า การถดถอยของค่าเฉลี่ย ส่วนนี้อธิบายวิธีการวัดค่าหลังการวัดค่าสุดโต่งเป็นพิเศษ มีแนวโน้มที่จะต่ำที่สุด หรือใกล้เคียงกับค่าเฉลี่ยมากกว่า เนื่องจาก ไม่น่าจะเป็นไปได้ที่จะทำให้การวัด สุดโต่งเกิดขึ้นตั้งแต่แรก จะประกาศชัดเจนขึ้นหากกลุ่มที่สูงกว่าค่าเฉลี่ยหรือต่ำกว่าค่าเฉลี่ยเป็นพิเศษ ได้รับเลือกให้สังเกต ว่ากลุ่มนั้นเป็นผู้ที่สูงที่สุดใน นักกีฬา นักกีฬาที่แย่ที่สุดในทีม หรือผู้ที่เสี่ยงต่อโรคหลอดเลือดสมองมากที่สุด เด็กของผู้ที่สูงที่สุดจะมีแนวโน้มที่จะสั้นกว่า พ่อแม่ นักกีฬาที่เลวร้ายที่สุด มักจะมีโอกาสทำผลงานได้ดีกว่า ฤดูกาลที่ไม่ดี และผู้ที่มีความเสี่ยงมากที่สุดที่จะเป็นโรคหลอดเลือดสมองมีแนวโน้มที่จะมีความเสี่ยงลดลง หลังการแทรกแซงหรือการรักษาใดๆ ไม่ใช่เพราะปัจจัยเชิงสาเหตุ แต่ เนื่องจากสมบัติและความน่าจะเป็นของการสุ่ม
การลดผลกระทบของการถดถอยจนถึงค่าเฉลี่ยเมื่อสำรวจ การฝึกฝนหรือการรักษาสำหรับกลุ่มคนที่สูงกว่าค่าเฉลี่ยหรือต่ำกว่าค่าเฉลี่ยนั้น แบ่งวิชาออกเป็นกลุ่มหนึ่งและกลุ่มควบคุมเพื่อแยกแยะ ผลกระทบเชิงเหตุผล ในบริบท ML ปรากฏการณ์นี้แนะนำให้จ่ายเงินเพิ่ม ความสนใจไปยังโมเดลใดๆ ที่คาดการณ์ค่าที่ผิดปกติหรือค่าผิดปกติ เช่น
- สภาพอากาศหรืออุณหภูมิเลวร้าย
- ร้านค้าหรือนักกีฬาที่มีประสิทธิภาพดีที่สุด
- วิดีโอที่ได้รับความนิยมมากที่สุดในเว็บไซต์
หากโมเดลมีการคาดการณ์ เหล่านี้อย่างต่อเนื่อง ค่าพิเศษต่างๆ เมื่อเวลาผ่านไป ไม่ตรงกับความเป็นจริง เช่น การคาดการณ์ว่า ร้านค้าหรือวิดีโอที่ประสบความสำเร็จอย่างสูงจะ ประสบความสำเร็จต่อไปทั้งๆ ที่จริงๆ แล้ว ไม่ ให้ถามว่า
- ความถดถอยเป็นปัญหาที่แท้จริงได้ไหม
- ฟีเจอร์ที่มีน้ำหนักสูงสุดช่วยคาดการณ์ได้ดีกว่าหรือไม่ เมื่อเทียบกับคุณลักษณะที่มีน้ำหนักน้อยกว่า
- มีการเก็บรวบรวมข้อมูลที่มีค่าเกณฑ์พื้นฐานสำหรับฟีเจอร์เหล่านั้นหรือไม่ มักเป็นศูนย์ (กลุ่มควบคุมที่มีประสิทธิภาพ) เปลี่ยนการคาดการณ์ของโมเดลไหม
ข้อมูลอ้างอิง
ฮัฟฟ์ ดาร์เรลล์ วิธีโกหกกับสถิติ นิวยอร์ก: W.W. Norton, 1954
โจนส์, เบน การหลีกเลี่ยงข้อผิดพลาดด้านข้อมูล Hoboken, NJ: Wiley, 2020
O'Connor, Cailin และ James Owen Weatherall The Misinformation Age นิวเฮเวน: Yale UP, 2019
Ringler, Adam, David Mason, Gabi Laske และ Mary Templeton "ทำไมตัวยึกยือของฉันจึงดูตลก แกลเลอรีสัญญาณแผ่นดินไหวที่ถูกบุกรุก" Seismological Research Letters 92 ฉบับที่ 6 (กรกฎาคม 2021). DOI: 10.1785/0220210094
Weintraub, วิลเลียม เอส., โทมัส เอฟ. Lüscher และ Stuart Pocock "ความเสี่ยงของปลายทางที่เป็นตัวแทน" European Heart Journal 36 ฉบับที่ 33 (ก.ย. 2015): 2212-2218 DOI: 10.1093/eurheartj/ehv164
วีลลัน, ชาร์ลส สถิติเปล่า: กำจัดความน่ากลัวออกจากข้อมูล นิวยอร์ก: W.W. Norton, 2013
การอ้างอิงรูปภาพ
"อคติเรื่องการรอดชีวิต" Martin Grandjean, McGeddon และ Cameron Moll 2021 CC BY-SA 4.0 แหล่งที่มา
{kind=link}
-
Jones 25-29 ↩
-
O'Connor และ Weatherall 22-3 ↩
-
Ringling และคณะ ↩
-
Wheelan 120 ↩
-
Siddhartha Mukherjee "โทรศัพท์มือถือเป็นสาเหตุของโรคมะเร็งสมองใช่ไหม" ใน The New York Times, 13 เมษายน 2011 อ้างถึงใน Wheelan 122 ↩
-
Wheelan 39-40↩
-
Malcolm Gladwell "The Order of Things" ใน The New Yorker 14 ก.พ. 2011 อ้างถึงใน Wheelan 56 ↩