"Cho vào rác, ra rác."
— Tục ngữ lập trình sớm
Bên dưới mỗi mô hình học máy, mọi phép tính về mối tương quan và mọi mô hình dựa trên dữ liệu đề xuất chính sách là một hoặc nhiều tập dữ liệu thô. Cho dù đẹp như thế nào gây ấn tượng hoặc thuyết phục cho sản phẩm cuối cùng nếu dữ liệu cơ bản là mô hình bị lỗi, được thu thập không đúng cách hoặc có chất lượng thấp, thông tin dự đoán, hình ảnh hoặc kết luận cũng sẽ có điểm thấp chất lượng. Bất cứ ai trực quan hoá, phân tích và huấn luyện mô hình trên nên đặt câu hỏi khó về nguồn dữ liệu.
Thiết bị thu thập dữ liệu có thể hoạt động không đúng cách hoặc bị hiệu chỉnh sai. Con người thu thập dữ liệu có thể mệt mỏi, tinh nghịch, không nhất quán hoặc kém hiệu quả được đào tạo. Mọi người có thể phạm sai lầm và những người khác nhau cũng có thể không đồng tình một cách hợp lý về việc phân loại tín hiệu không rõ ràng. Do đó, chất lượng và tính hợp lệ của dữ liệu có thể bị ảnh hưởng và dữ liệu có thể không phản ánh thực tế. Ben Jones, tác giả của tác phẩm Tránh dùng dữ liệu Thách thức, gọi đây là khoảng cách giữa dữ liệu và thực tế, nhắc người đọc: "Đó không phải là tội phạm, mà đó là hành vi phạm tội bị báo cáo. Đó không phải là đó là số lần va chạm sao băng được ghi nhận."
Ví dụ về sự thiếu hụt dữ liệu thực tế:
Đồ thị Jones tăng đột biến trong các phép đo thời gian ở khoảng thời gian 5 phút và đo trọng lượng trong khoảng 5 pound, không phải do các điểm tăng đột biến như vậy tồn tại trong dữ liệu, nhưng vì trình thu thập dữ liệu của con người (không giống như công cụ) thường có xu hướng để làm tròn các số của chúng đến số 0 hoặc 5 gần nhất.1
Năm 1985, Joe Farman, Brian Gardiner và Jonathan Shanklin, làm việc cho Khảo sát Nam Cực của Anh (BAS), cho thấy các phép đo của họ cho thấy lỗ hổng theo mùa trong tầng ozone ở Nam bán cầu. Chiến dịch này trái ngược với dữ liệu của NASA, trong đó không ghi nhận lỗ hổng nào như vậy. Nhà vật lý Richard của NASA Stolarski đã điều tra và nhận thấy rằng phần mềm xử lý dữ liệu của NASA được thiết kế với giả định rằng nồng độ ozone không bao giờ giảm xuống một lượng nồng độ nhất định và chỉ số ozone rất thấp đã được phát hiện tự động bị loại bỏ như là các điểm ngoại lai vô nghĩa.2
Công cụ trải qua nhiều chế độ lỗi, đôi khi vẫn còn đang thu thập dữ liệu. Adam Ringler và cộng sự cung cấp thư viện địa chấn các lượt đọc do các lỗi của công cụ (và các lỗi tương ứng) trong bài viết "Vì sao các hình vẽ nguệch ngoạc của tôi trông hài hước?" năm 20213 Hoạt động trong Chỉ số ví dụ không tương ứng với hoạt động địa chấn thực tế.
Đối với chuyên viên công nghệ học máy, điều quan trọng là bạn phải hiểu:
- Người thu thập dữ liệu
- Cách thức và thời điểm thu thập dữ liệu và trong điều kiện cụ thể
- Độ nhạy và trạng thái của thiết bị đo
- Các lỗi của thiết bị và lỗi do con người có thể xảy ra trong một bối cảnh
- Xu hướng của con người trong việc làm tròn các con số và đưa ra câu trả lời phù hợp
Hầu như lúc nào cũng có sự khác biệt nhỏ giữa dữ liệu và thực tế, còn được gọi là thông tin thực tế. Giải thích cho sự khác biệt đó là chìa khoá để rút ra kết luận hợp lý và đưa ra đó là những quyết định hợp lý. Điều này bao gồm việc quyết định:
- vấn đề nào có thể và nên giải quyết bằng công nghệ học máy.
- những vấn đề không được giải quyết tốt nhất bằng công nghệ học máy.
- những bài tập chưa có đủ dữ liệu chất lượng cao để giải bằng công nghệ học máy.
Hỏi: Dữ liệu truyền đạt thông tin gì, theo nghĩa chặt chẽ nhất và theo nghĩa đen nhất? Một điều cũng quan trọng không kém là dữ liệu không truyền đạt thông tin gì?
Bẩn trong dữ liệu
Ngoài việc điều tra các điều kiện của việc thu thập dữ liệu, tập dữ liệu có thể chứa những khoảng trống, lỗi và giá trị rỗng hoặc không hợp lệ (chẳng hạn như các phép đo âm về nồng độ). Dữ liệu do cộng đồng đóng góp có thể đặc biệt lộn xộn. Khi bạn sử dụng một tập dữ liệu có chất lượng không xác định, kết quả có thể không chính xác.
Các vấn đề thường gặp gồm có:
- Lỗi chính tả trong các giá trị chuỗi, chẳng hạn như địa điểm, loài hoặc tên thương hiệu
- Lượt chuyển đổi đơn vị, đơn vị hoặc loại đối tượng không chính xác
- Thiếu giá trị
- Liên tục phân loại sai hoặc gắn nhãn sai
- Các chữ số có nghĩa còn lại từ các phép toán vượt quá độ nhạy thực tế của một công cụ
Việc dọn dẹp một tập dữ liệu thường liên quan đến các lựa chọn về giá trị rỗng và bị thiếu (cho dù để giữ chúng là giá trị rỗng, bỏ chúng hoặc thay thế số 0), sửa cách viết thành phiên bản đơn lẻ, sửa đơn vị và lượt chuyển đổi, v.v. Nâng cao hơn là áp dụng các giá trị còn thiếu, được mô tả trong Đặc điểm dữ liệu trong Khoá học nhanh về máy học.
Lấy mẫu, độ sai lệch so với khả năng sinh tồn và vấn đề điểm cuối thay thế
Thống kê cho phép phép ngoại suy hợp lệ và chính xác các kết quả từ một mẫu ngẫu nhiên hoàn toàn cho tập hợp lớn hơn. Độ dễ vỡ chưa được kiểm tra của giả định này, cùng với thông tin đầu vào huấn luyện không cân bằng và không đầy đủ, đã dẫn đến đến các lỗi nổi bật của nhiều ứng dụng học máy, bao gồm các mô hình dùng cho tiếp tục xem xét và xử lý. Điều này cũng dẫn đến các lỗi thăm dò ý kiến kết luận sai lầm về các nhóm nhân khẩu học. Trong hầu hết các bối cảnh bên ngoài dữ liệu nhân tạo do máy tính tạo, các mẫu hoàn toàn ngẫu nhiên cũng vậy đắt đỏ và quá khó để có được. Nhiều giải pháp khác với giá cả phải chăng thay vào đó sử dụng proxy, vốn giới thiệu các nguồn khác nhau thiên vị.
Ví dụ: để sử dụng phương pháp lấy mẫu được phân tầng, bạn phải biết tỷ lệ phổ biến của từng tầng được lấy mẫu trong quần thể lớn hơn. Nếu bạn giả định mà thực sự không chính xác, thì kết quả của bạn sẽ không chính xác. Tương tự, cuộc thăm dò ý kiến trực tuyến hiếm khi là mẫu ngẫu nhiên toàn bộ dân số quốc gia, mà còn là một nhóm nhân viên có kết nối Internet (thường là người ở nhiều quốc gia) nhìn thấy và sẵn sàng tham gia khảo sát. Nhóm này có thể khác với một mẫu ngẫu nhiên thực sự. Các câu hỏi trong là một mẫu gồm các câu hỏi tiềm năng. Các câu trả lời cho các câu hỏi thăm dò ý kiến đó là không phải một mẫu ngẫu nhiên những người trả lời ý kiến thực tế, mà là một mẫu ý kiến mà người trả lời cảm thấy thoải mái đưa ra, có thể khác với ý kiến của họ ý kiến thực tế.
Các nhà nghiên cứu sức khoẻ lâm sàng gặp phải một vấn đề tương tự, được gọi là trường hợp thay thế thiết bị đầu cuối. Vì mất quá nhiều thời gian để kiểm tra tác dụng của một loại thuốc tuổi thọ của bệnh nhân, các nhà nghiên cứu sử dụng dấu ấn sinh học proxy được giả định là liên quan đến tuổi thọ, nhưng có thể không liên quan đến chúng. Nồng độ cholesterol được sử dụng làm chất thay thế điểm cuối của các cơn đau tim và tử vong do các vấn đề về tim mạch: nếu một loại thuốc làm giảm nồng độ cholesterol, chất này được xem là cũng giúp giảm nguy cơ gặp các vấn đề về tim. Tuy nhiên, chuỗi tương quan đó có thể không hợp lệ, hoặc nếu không, thứ tự của quan hệ nhân quả có thể khác với những gì nhà nghiên cứu giả định. Xem Weintraub và cộng sự, "Những mối nguy hiểm của thiết bị đầu cuối thay thế", để xem thêm ví dụ và thông tin chi tiết. Tình huống tương tự trong công nghệ học máy là nhãn proxy.
Nhà toán học Abraham Thay thế nổi tiếng với một vấn đề lấy mẫu dữ liệu hiện đã được biết là thiên vị sinh tồn. Máy bay chiến đấu đang quay trở lại với những lỗ đạn nằm trong các vị trí cụ thể và không ở những vị trí khác. Quân đội Hoa Kỳ muốn thêm áo giáp nữa tới các máy bay ở khu vực có nhiều lỗ đạn nhất, nhưng nhóm nghiên cứu của Wid thay vào đó, bạn nên thêm áo giáp vào các khu vực không có lỗ đạn. Họ suy luận chính xác rằng mẫu dữ liệu của họ bị lệch vì máy bay bắn vào những khu vực đó đã bị thiệt hại nghiêm trọng đến mức không thể quay trở lại căn cứ.
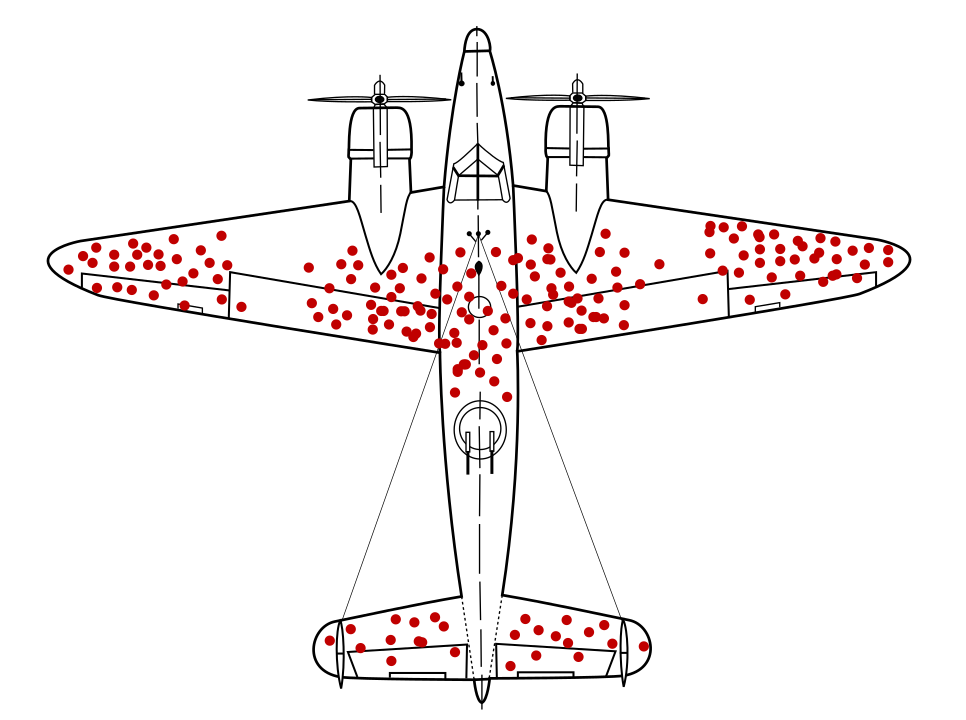
Có một mô hình đề xuất áo giáp được huấn luyện chỉ dựa trên sơ đồ trả về mà không có sự thấu hiểu về thiên kiến sinh tồn trong dữ liệu, mô hình đó sẽ đề xuất gia cố các khu vực có nhiều lỗ đạn hơn.
Thành kiến tự chọn có thể phát sinh từ những đối tượng là con người tình nguyện tham gia vào một nghiên cứu. Các phạm nhân bị thúc đẩy để đăng ký giảm tái phạm có thể đại diện cho nhóm người dùng ít có khả năng cam kết số tội phạm trong tương lai so với dân số tù chung. Điều này sẽ làm sai lệch kết quả.4
Một vấn đề tinh vi hơn về lấy mẫu là sự thiên lệch, liên quan đến tính dễ uốn của con người bộ nhớ. Năm 1993, Edward Giovanncao đã hỏi một nhóm tuổi phù hợp phụ nữ, một số người được chẩn đoán mắc ung thư, về chế độ ăn uống trước đây của họ một vài thói quen. Nhóm phụ nữ này cũng tham gia một cuộc khảo sát về thói quen ăn uống trước khi chẩn đoán ung thư. Điều Giovanncao phát hiện ra là phụ nữ không bị ung thư chẩn đoán nhớ lại chế độ ăn uống của họ một cách chính xác, nhưng phụ nữ bị ung thư vú lại báo cáo tiêu thụ nhiều chất béo hơn mức chúng được báo cáo trước đó—một cách vô thức đưa ra lời giải thích khả thi (mặc dù không chính xác) về căn bệnh ung thư của họ.5
Trả lời câu hỏi:
- Lấy mẫu tập dữ liệu trên thực tế là gì?
- Có bao nhiêu cấp lấy mẫu?
- Thành kiến nào có thể được đưa vào ở mỗi cấp độ lấy mẫu?
- Phương pháp đo lường proxy có được sử dụng không (cho dù là dấu ấn sinh học, cuộc thăm dò ý kiến trực tuyến hay dấu đầu dòng lỗ hổng) cho thấy mối tương quan hay quan hệ nhân quả thực tế?
- Mẫu và phương pháp lấy mẫu có thể còn thiếu những gì?
Mô-đun Sự công bằng trong Khoá học nhanh về học máy bao gồm nhiều cách đánh giá và giảm thiểu các nguồn sai lệch khác trong tập dữ liệu nhân khẩu học.
Định nghĩa và thứ hạng
Định nghĩa các thuật ngữ một cách rõ ràng và chính xác, hoặc hỏi về định nghĩa rõ ràng và chính xác. Việc này là cần thiết để biết được những tính năng dữ liệu nào đang được xem xét và chính xác những gì được dự đoán hoặc xác nhận quyền sở hữu. Charles Wheelan, trong NakedThống kê, đưa ra "tình trạng sức khoẻ của Hoa Kỳ sản xuất" làm ví dụ về một thuật ngữ không rõ ràng. Liệu khu vực sản xuất của Hoa Kỳ có "lành mạnh" hoặc không phụ thuộc hoàn toàn vào cách thuật ngữ được định nghĩa. của Greg Ip Bài viết vào tháng 3 năm 2011 trên The Economist minh hoạ cho sự không rõ ràng này. Nếu chỉ số cho "sức khoẻ" là "sản xuất đầu ra," thì vào năm 2011, hoạt động sản xuất tại Hoa Kỳ ngày càng lành mạnh. Nếu "sức khoẻ" chỉ số được định nghĩa là "việc làm trong ngành sản xuất", tuy nhiên, hoạt động sản xuất của Hoa Kỳ có chiều hướng giảm.6
Thứ hạng thường gặp phải các vấn đề tương tự, bao gồm cả những vấn đề bị che khuất hoặc vô nghĩa trọng số cho các thành phần khác nhau của bảng xếp hạng, sự không nhất quán và tuỳ chọn không hợp lệ. Malcolm Luxewell, viết bài trên The New Yorker, đề cập đến một Chánh án toà án tối cao Michigan, Thomas Brennan, người đã từng gửi một cuộc khảo sát tới hàng trăm luật sư đề nghị họ xếp hạng mười trường luật theo chất lượng, một số trường luật nổi tiếng, một số thì không. Các luật sư đó đã xếp hạng trường luật của Penn State vào khoảng thứ 5 mặc dù vào thời điểm khảo sát, bang Penn chưa có luật trường học.7 Nhiều bảng xếp hạng nổi tiếng cũng có yếu tố chủ quan tương tự danh tiếng. Hỏi xem thành phần nào sẽ xuất hiện trong một thứ hạng và tại sao những thành phần đó các thành phần được gán trọng số cụ thể của chúng.
Số nhỏ và hiệu ứng lớn
Không có gì đáng ngạc nhiên khi bạn tung ra đồng xu 100% đầu hoặc 100% đuôi 2 lần. Cũng không có gì đáng ngạc nhiên khi bạn tung được đồng xu lên 25% sau khi tung đồng xu bốn lần. thì 75% đầu cho 4 lần lật tiếp theo, mặc dù điều đó thể hiện rõ ràng mức tăng rất lớn (có thể nhầm lẫn là do bạn đã ăn bánh sandwich giữa các lần tung đồng xu hoặc bất kỳ yếu tố giả nào khác). Nhưng như số liệu số lần tung đồng xu tăng lên, chẳng hạn như 1.000 hoặc 2.000, phần trăm chênh lệch lớn so với con số dự kiến 50% đó trở nên khó có thể biến mất.
Số lượng phép đo hoặc đối tượng thử nghiệm trong một nghiên cứu thường được gọi là thành N. Thay đổi lớn theo tỷ lệ thuận do cơ hội có nhiều khả năng xảy ra trong các tập dữ liệu và mẫu có N thấp.
Khi tiến hành phân tích hoặc ghi chép một tập dữ liệu trong Thẻ dữ liệu, hãy nêu rõ N, để người khác có thể cân nhắc ảnh hưởng của tiếng ồn và tính ngẫu nhiên.
Vì chất lượng mô hình có xu hướng mở rộng dựa trên số lượng ví dụ, nên một tập dữ liệu có N thấp thường dẫn đến các mô hình chất lượng thấp.
Hồi quy về giá trị trung bình
Tương tự, bất kỳ đo lường nào có một số ảnh hưởng từ tình cờ đều phải chịu sự ảnh hưởng của hiệu ứng còn được gọi là trở về giá trị trung bình. Nội dung này mô tả cách đo sau lần đo cực kỳ đặc biệt là, trung bình, có thể ít cực đoan hơn hoặc gần trung bình hơn, do cách khả năng đo cực trị không xảy ra ngay từ đầu. Chiến lược phát hành đĩa đơn hiệu quả rõ ràng hơn nếu một nhóm đặc biệt trên trung bình hoặc dưới trung bình được chọn để quan sát, xem nhóm đó có phải là những người cao nhất trong một nhóm dân số, vận động viên kém nhất trong một đội hoặc những người có nguy cơ đột quỵ cao nhất. Chiến lược phát hành đĩa đơn thì con cái của những người cao nhất trung bình có khả năng thấp hơn con của họ các bậc cha mẹ, các vận động viên kém nhất có thể hoạt động tốt hơn sau một khoảng thời gian đặc biệt mùa xấu và những người có nguy cơ đột quỵ cao nhất có nguy cơ giảm sau bất kỳ can thiệp hoặc điều trị nào, không phải do các yếu tố nguyên nhân mà là vì tính chất và xác suất của ngẫu nhiên.
Một biện pháp giảm thiểu tác động của sự hồi quy về giá trị trung bình, khi khám phá các biện pháp can thiệp hoặc điều trị cho một nhóm trên trung bình hoặc dưới trung bình là chia các đối tượng thành một nhóm nghiên cứu và một nhóm đối chứng để tách riêng các tác động nhân quả. Trong bối cảnh học máy, hiện tượng này cho thấy bạn phải trả thêm tiền hãy chú ý đến bất kỳ mô hình nào dự đoán các giá trị ngoại lệ hoặc ngoại lệ, chẳng hạn như:
- thời tiết hoặc nhiệt độ khắc nghiệt
- cửa hàng hoặc vận động viên có hiệu suất tốt nhất
- những video phổ biến nhất trên một trang web
Nếu dự đoán liên tục của mô hình về những các giá trị đặc biệt theo thời gian không phù hợp với thực tế, ví dụ: dự đoán rằng video hoặc cửa hàng rất thành công sẽ tiếp tục thành công trên thực tế không, hãy đặt câu hỏi:
- Liệu sự hồi quy có thể trở về mức trung bình không?
- Các đối tượng có trọng số cao nhất có thực sự mang tính dự đoán cao hơn không so với các tính năng có trọng số thấp hơn?
- Việc thu thập dữ liệu có giá trị cơ sở cho những tính năng đó, thường bằng 0 (có hiệu quả là nhóm đối chứng) thay đổi dự đoán của mô hình không?
Tài liệu tham khảo
Hừm, Darrell. Cách nói dối với số liệu thống kê. New York: W.W. Norton, 1954.
Jones, Ben. Tránh các cạm bẫy dữ liệu. Hoboken, New Jersey: Wiley, năm 2020.
O'Connor, Cailin và James Owen Weatherall. Thời gian xuất hiện thông tin sai lệch. New haven: Yale UP, năm 2019.
Ringler, Adam, David Mason, Gabi Laske và Mary Templeton. "Vì sao các hình ảnh ngoằn ngoèo của tôi trông hài hước? Một thư viện tín hiệu địa chấn bị xâm phạm." Thư nghiên cứu địa chất học 92 số 6 (tháng 7 năm 2021). DOI: 10.1785/0220210094
Weintraub, William S, Thomas F. Lüscher và EDU Pocock. "Những mối nguy hiểm của thiết bị đầu cuối thay thế." Tạp chí Tim mạch Châu Âu 36 số. Ngày 33 (Tháng 9 năm 2015): 2212–2218. DOI: 10.1093/eurheartj/ehv164
Wheelan, Charles. Thống kê không rõ ràng: Loại bỏ dữ liệu đáng sợ khỏi dữ liệu. New York: W.W. Norton, 2013
Tham chiếu hình ảnh
"Thành kiến về sự sống còn." Martin Grandjean, McGeddon và Cameron Moll 2021. CC BY-SA 4.0. Nguồn
{kind=link}
-
Jones 25-29 tuổi. ↩
-
O'Connor và Weatherall 22-3. ↩
-
Ringling và đồng sự ↩
-
Bánh xe 120. ↩
-
Siddhartha Mukherjee, "Điện thoại di động có gây ung thư não không?" trên The New York Times, ngày 13 tháng 4 năm 2011. Trích dẫn trong Wheelan 122.↩
-
Bánh xe 39-40. ↩
-
Malcolm Vlowell, "Thứ tự của vạn vật", trên The New Yorker, ngày 14 tháng 2 năm 2011. Được trích dẫn trong Wheelan 56. ↩