لأغراض هذا المستند:
الهدف النهائي من تطوير تعلُّم الآلة هو زيادة فائدة النموذج الذي تم نشره إلى أقصى حدّ.
يمكنك عادةً استخدام الخطوات والمبادئ الأساسية نفسها الواردة في هذا القسم لأي مشكلة تتعلّق بالتعلم الآلي.
يفترض هذا القسم ما يلي:
- لديك حاليًا مسار تدريب يعمل بشكل كامل بالإضافة إلى إعدادات تحقّق نتائج معقولة.
- لديك موارد حسابية كافية لإجراء تجارب ضبط ذات مغزى وتشغيل عدة مهام تدريبية على الأقل بالتوازي.
استراتيجية الضبط التدريجي
اقتراح: ابدأ بإعداد بسيط. بعد ذلك، يمكنك إجراء تحسينات تدريجية مع جمع معلومات حول المشكلة. تأكَّد من أنّ أي تحسين يستند إلى أدلة قوية.
نفترض أنّ هدفك هو العثور على إعداد يحقّق الحدّ الأقصى من أداء النموذج. في بعض الأحيان، يكون هدفك هو تحقيق الحد الأقصى من التحسينات على النموذج بحلول موعد نهائي ثابت. في حالات أخرى، يمكنك مواصلة تحسين النموذج إلى أجل غير مسمى، مثل التحسين المستمر لنموذج مستخدَم في الإنتاج.
من حيث المبدأ، يمكنك تحقيق أفضل أداء من خلال استخدام خوارزمية للبحث تلقائيًا في المساحة الكاملة للإعدادات المحتملة، ولكن هذا ليس خيارًا عمليًا. مساحة الإعدادات المحتملة كبيرة جدًا، ولا تتوفّر حاليًا أي خوارزميات متطورة بما يكفي للبحث في هذه المساحة بكفاءة بدون توجيه من الإنسان. تعتمد معظم خوارزميات البحث الآلية على مساحة بحث مصمَّمة يدويًا تحدّد مجموعة الإعدادات التي سيتم البحث فيها، ويمكن أن تكون مساحات البحث هذه مهمة جدًا.
إنّ الطريقة الأكثر فعالية لتحقيق أقصى قدر من الأداء هي البدء بإعداد بسيط وإضافة الميزات وإجراء التحسينات بشكل تدريجي أثناء جمع معلومات حول المشكلة.
ننصحك باستخدام خوارزميات البحث المبرمَجة في كل جولة من عمليات الضبط وتعديل مساحات البحث باستمرار مع زيادة فهمك. أثناء استكشافك، ستعثر بشكل طبيعي على إعدادات أفضل وأفضل، وبالتالي سيتحسّن نموذجك "الأفضل" باستمرار.
يشير مصطلح "الإطلاق" إلى تعديل على أفضل إعداداتنا (التي قد تتوافق أو لا تتوافق مع إطلاق نموذج إنتاج فعلي). في كل عملية "إطلاق"، يجب التأكّد من أنّ التغيير يستند إلى دليل قوي، وليس إلى فرصة عشوائية استنادًا إلى إعدادات محظوظة، وذلك لتجنُّب إضافة تعقيد غير ضروري إلى مسار التدريب.
بشكل عام، تتضمّن استراتيجية الضبط التدريجي تكرار الخطوات الأربع التالية:
- اختَر هدفًا للجولة التالية من التجارب. تأكَّد من تحديد نطاق الهدف بشكل مناسب.
- تصميم المجموعة التالية من التجارب: تصميم مجموعة من التجارب وتنفيذها للتقدّم نحو تحقيق هذا الهدف
- الاستفادة من النتائج التجريبية: تقييم التجربة استنادًا إلى قائمة التحقّق
- تحديد ما إذا كان سيتم اعتماد التغيير المقترَح
يقدّم الجزء المتبقّي من هذا القسم تفاصيل حول هذه الاستراتيجية.
اختيار هدف للجولة التالية من التجارب
إذا حاولت إضافة ميزات متعددة أو الإجابة عن أسئلة متعددة في الوقت نفسه، قد لا تتمكّن من فصل التأثيرات المختلفة على النتائج. تشمل الأمثلة على الأهداف ما يلي:
- جرِّب تحسينًا محتملاً لخطوات المعالجة (على سبيل المثال، أداة تسوية جديدة، أو خيار معالجة مسبقة، وما إلى ذلك).
- فهم تأثير مَعلم فائق معيّن للنموذج (على سبيل المثال، دالة التنشيط)
- تقليل خطأ التحقّق من الصحة
إعطاء الأولوية للتقدّم على المدى الطويل بدلاً من التحسينات على المدى القصير في أخطاء التحقّق
الملخّص: في معظم الأحيان، يكون هدفك الأساسي هو الحصول على إحصاءات حول مشكلة الضبط.
ننصحك بقضاء معظم وقتك في فهم المشكلة وقضاء وقت أقل نسبيًا في التركيز على تحقيق أقصى أداء ممكن في مجموعة التحقّق. بعبارة أخرى، يجب أن تقضي معظم وقتك في "الاستكشاف" وجزءًا صغيرًا فقط في "الاستغلال". يُعدّ فهم المشكلة أمرًا بالغ الأهمية لتحقيق أفضل أداء نهائي. يساعد التركيز على الرؤى بدلاً من المكاسب القصيرة الأجل في:
- تجنَّب طرح تغييرات غير ضرورية حدثت في عمليات تنفيذ جيدة الأداء بمحض الصدفة.
- تحديد المعلَمات الفائقة التي يكون خطأ التحقّق أكثر حساسية لها، وتحديد المعلَمات الفائقة التي تتفاعل مع بعضها البعض بشكل أكبر وبالتالي يجب إعادة ضبطها معًا، وتحديد المعلَمات الفائقة التي تكون أقل حساسية للتغييرات الأخرى وبالتالي يمكن إصلاحها في التجارب المستقبلية
- اقتراح ميزات جديدة محتملة لتجربتها، مثل أدوات تسوية جديدة عند حدوث مشكلة في التكيّف الزائد
- تحديد الميزات التي لا تساعد وبالتالي يمكن إزالتها، ما يقلّل من تعقيد التجارب المستقبلية
- التعرّف على الحالات التي من المحتمل أن تكون فيها التحسينات الناتجة عن ضبط المعلَمة الفائقة قد وصلت إلى الحدّ الأقصى.
- تضييق مساحات البحث حول القيمة المثالية لتحسين كفاءة الضبط
في النهاية، ستفهم المشكلة. بعد ذلك، يمكنك التركيز فقط على خطأ التحقّق من الصحة حتى إذا لم تكن التجارب تقدّم معلومات كافية حول بنية مشكلة الضبط.
تصميم المجموعة التالية من التجارب
ملخّص: حدِّد المَعلمات الفائقة العلمية والمزعجة والثابتة للهدف التجريبي. أنشئ تسلسلاً من الدراسات لمقارنة القيم المختلفة للمعلمات الفائقة العلمية مع تحسين المعلمات الفائقة المزعجة. اختَر مساحة البحث الخاصة بالمعلمات الفائقة المزعجة لتحقيق التوازن بين تكاليف الموارد والقيمة العلمية.
تحديد المعلمات الفائقة العلمية والمزعجة والثابتة
بالنسبة إلى هدف معيّن، تندرج جميع المَعلمات الفائقة ضمن إحدى الفئات التالية:
- المَعلمات الفائقة العلمية هي تلك التي تحاول قياس تأثيرها في أداء النموذج.
- المَعلمات الفائقة المزعجة هي تلك التي يجب تحسينها من أجل مقارنة القيم المختلفة للمَعلمات الفائقة العلمية بشكل عادل. تتشابه المعلمات الفائقة المزعجة مع المعلمات المزعجة في الإحصاء.
- تحتوي المَعلمات الفائقة الثابتة على قيم ثابتة في الجولة الحالية من التجارب. يجب ألا تتغير قيم المعلمات الفائقة الثابتة عند مقارنة قيم مختلفة للمعلمات الفائقة العلمية. من خلال إصلاح بعض المَعلمات الفائقة لمجموعة من التجارب، عليك قبول أنّ الاستنتاجات المستخلَصة من التجارب قد لا تكون صالحة لإعدادات أخرى للمَعلمات الفائقة الثابتة. بعبارة أخرى، تؤدي المعلمات الفائقة الثابتة إلى ظهور تحذيرات بشأن أي استنتاجات تستخلصها من التجارب.
على سبيل المثال، لنفترض أنّ هدفك هو كما يلي:
تحديد ما إذا كان النموذج الذي يتضمّن المزيد من الطبقات المخفية لديه خطأ تحقّق أقل
في هذه الحالة:
- معدّل التعلّم هو وسيط فائق مزعج لأنّه لا يمكنك مقارنة النماذج التي تتضمّن أعدادًا مختلفة من الطبقات المخفية بشكل عادل إلا إذا تم ضبط معدّل التعلّم بشكل منفصل لكل عدد من الطبقات المخفية. (يعتمد معدّل التعلّم الأمثل بشكل عام على بنية النموذج).
- يمكن أن تكون دالة التنشيط معلَمة فائقة ثابتة إذا تبيّن لك من خلال التجارب السابقة أنّ أفضل دالة تنشيط لا تتأثر بعمق النموذج. أو إذا كنت على استعداد للحدّ من استنتاجاتك بشأن عدد الطبقات المخفية لتغطية وظيفة التنشيط هذه. بدلاً من ذلك، يمكن أن يكون معلمة فائقة مزعجة إذا كنت مستعدًا لضبطها بشكل منفصل لكل عدد من الطبقات المخفية.
يمكن أن تكون المعلَمة الفائقة المحدّدة معلَمة فائقة علمية أو معلَمة فائقة مزعجة أو معلَمة فائقة ثابتة، ويتغيّر تصنيف المعلَمة الفائقة حسب الهدف التجريبي. على سبيل المثال، يمكن أن تكون دالة التنشيط أيًا مما يلي:
- المَعلم الفائق العلمي: هل دالة ReLU أو دالة الظل الزائدي هي الخيار الأفضل لمشكلتنا؟
- المَعلمة الفائقة المزعجة: هل النموذج الأفضل المكوّن من خمس طبقات أفضل من النموذج الأفضل المكوّن من ست طبقات عند السماح بعدة دوال تنشيط مختلفة محتملة؟
- المَعلم الفائق الثابت: بالنسبة إلى شبكات ReLU، هل تساعد إضافة تسوية الدفعات في موضع معيّن؟
عند تصميم مجموعة جديدة من التجارب:
- تحديد المَعلمات الفائقة العلمية لهدف التجربة (في هذه المرحلة، يمكنك اعتبار جميع المعلمات الفائقة الأخرى معلمات فائقة غير مهمة).
- تحويل بعض المَعلمات الفائقة المزعجة إلى مَعلمات فائقة ثابتة
في حال توفّر موارد غير محدودة، يمكنك ترك جميع المَعلمات الفائقة غير العلمية كمَعلمات فائقة غير ضرورية، وذلك لضمان أنّ الاستنتاجات التي تستخلصها من تجاربك لا تتضمّن أي تحذيرات بشأن قيم المَعلمات الفائقة الثابتة. ومع ذلك، كلما حاولت ضبط عدد أكبر من المَعلمات الفائقة المزعجة، زادت احتمالية عدم ضبطها بشكل جيد بما يكفي لكل إعداد من إعدادات المَعلمات الفائقة العلمية، وبالتالي التوصّل إلى استنتاجات خاطئة من تجاربك. كما هو موضّح في قسم لاحق، يمكنك مواجهة هذا الخطر من خلال زيادة ميزانية الحوسبة. ومع ذلك، غالبًا ما يكون الحد الأقصى لميزانية الموارد أقل من الحد المطلوب لضبط جميع المعلمات الفائقة غير العلمية.
ننصح بتحويل المعلمات الفائقة غير المهمة إلى معلمات فائقة ثابتة عندما تكون التحذيرات التي يتم تقديمها عند تثبيتها أقل عبئًا من تكلفة تضمينها كمعلمات فائقة غير مهمة. كلّما زاد تفاعل المَعلمة الفائقة المزعجة مع المَعلمات الفائقة العلمية، زاد الضرر الناتج عن تحديد قيمتها. على سبيل المثال، يعتمد أفضل قيمة لقوة انخفاض الوزن عادةً على حجم النموذج، لذا لن تكون مقارنة أحجام النماذج المختلفة بافتراض قيمة واحدة محددة لانخفاض الوزن مفيدة جدًا.
بعض مَعلمات المحسِّن
بشكل عام، بعض المَعلمات الفائقة للمحسِّن (مثل معدّل التعلّم، والزخم، ومَعلمات جدول معدّل التعلّم، ومعاملات بيتا في خوارزمية Adam، وما إلى ذلك) هي مَعلمات فائقة مزعجة لأنّها تتفاعل بشكل كبير مع التغييرات الأخرى. ونادرًا ما تكون هذه المَعلمات الفائقة للمحسِّن مَعلمات فائقة علمية، لأنّ هدفًا مثل "ما هو أفضل معدّل تعلّم للمسار الحالي؟" لا يقدّم الكثير من المعلومات. ففي النهاية، قد يتغير الإعداد الأفضل مع أي تغيير في مسار العرض.
قد تحتاج إلى إصلاح بعض المَعلمات الفائقة الخاصة بأداة التحسين في بعض الأحيان بسبب قيود الموارد أو بسبب توفّر دليل قوي بشكل خاص على أنّها لا تتفاعل مع المَعلمات العلمية. ومع ذلك، يجب أن تفترض بشكل عام أنّه عليك ضبط المعلمات الفائقة الخاصة بمحسِّن الأداء بشكل منفصل لإجراء مقارنات عادلة بين الإعدادات المختلفة للمعلمات الفائقة العلمية، وبالتالي لا يجب أن تكون ثابتة. علاوةً على ذلك، ليس هناك سبب مسبق لتفضيل قيمة معينة لمعلَمة فائقة خاصة بمحسِّن على قيمة أخرى، فمثلاً، لا تؤثر قيم المَعلمات الفائقة الخاصة بالمحسِّن عادةً في التكلفة الحسابية لعمليات التمرير الأمامي أو التدرجات بأي شكل من الأشكال.
اختيار أداة التحسين
عادةً، يكون اختيار أداة التحسين إما:
- مَعلمة فائقة علمية
- مَعلمة فائقة ثابتة
يكون المحسِّن عبارة عن وسيط فائق علمي إذا كان هدفك التجريبي يتضمّن إجراء مقارنات عادلة بين محسِّنَين أو أكثر. على سبيل المثال:
تحديد أداة التحسين التي تنتج أقل خطأ في التحقّق من الصحة خلال عدد محدّد من الخطوات
بدلاً من ذلك، يمكنك جعل المحسِّن معلَمة فائقة ثابتة لعدة أسباب، بما في ذلك:
- تشير التجارب السابقة إلى أنّ أفضل أداة لتحسين عملية الضبط لا تتأثر بالمعلمات الفائقة العلمية الحالية.
- أنت تفضّل مقارنة قيم المعلمات الفائقة العلمية باستخدام أداة التحسين هذه لأنّه يسهل فهم منحنيات التدريب الخاصة بها.
- تفضّل استخدام أداة التحسين هذه لأنّها تستهلك مساحة أقل من الذاكرة مقارنةً بالبدائل.
المعلَمات الفائقة للتسوية
المعلَمات الفائقة التي تقدّمها إحدى تقنيات التسوية هي عادةً معلَمات فائقة غير مرغوب فيها. ومع ذلك، فإنّ اختيار ما إذا كان سيتم تضمين تقنية التسوية على الإطلاق هو إما معلَمة فائقة علمية أو ثابتة.
على سبيل المثال، تؤدي عملية التسوية إلى زيادة تعقيد الرمز. لذلك، عند تحديد ما إذا كان يجب تضمين التسوية باستخدام التسرب، يمكنك اعتبار "عدم استخدام التسرب" مقابل "استخدام التسرب" معلَمة فائقة علمية، ولكن معدل التسرب معلَمة فائقة مزعجة. إذا قررت إضافة تسوية التسرب إلى مسار المعالجة استنادًا إلى هذه التجربة، سيصبح معدل التسرب معلَمة فائقة مزعجة في التجارب المستقبلية.
المعلَمات الفائقة المعمارية
غالبًا ما تكون المعلمات الفائقة المعمارية علمية أو ثابتة، لأنّ تغييرات البنية يمكن أن تؤثّر في تكاليف العرض والتدريب ووقت الاستجابة ومتطلبات الذاكرة. على سبيل المثال، يكون عدد الطبقات عادةً معلَمة فائقة علمية أو ثابتة، لأنّها تميل إلى أن يكون لها تأثير كبير على سرعة التدريب واستخدام الذاكرة.
التبعيات على المعلَمات الفائقة العلمية
في بعض الحالات، تعتمد مجموعات المعلَمات الفائقة المزعجة والثابتة على قيم المعلَمات الفائقة العلمية. على سبيل المثال، لنفترض أنّك تحاول تحديد المحسِّن الذي يحقّق أقل خطأ في التحقّق في Nesterov momentum وAdam. في هذه الحالة:
- المَعلمة الفائقة العلمية هي المحسِّن، الذي يأخذ القيم
{"Nesterov_momentum", "Adam"} - تُدخل القيمة
optimizer="Nesterov_momentum"المعلمات الفائقة{learning_rate, momentum}، والتي قد تكون إما معلمات فائقة مزعجة أو ثابتة. - تُدخل القيمة
optimizer="Adam"المعلمات الفائقة{learning_rate, beta1, beta2, epsilon}، والتي قد تكون إما معلمات فائقة ثابتة أو مزعجة.
تُسمّى المعلَمات الفائقة التي لا تظهر إلا لقيم معيّنة من المعلَمات الفائقة العلمية المعلَمات الفائقة الشرطية.
لا تفترض أنّ مَعلمتَين فائقتَين شرطيتَين متطابقتان لمجرّد أنّهما تحملان الاسم نفسه. في المثال السابق، المعلمة الفائقة الشرطية المسماة learning_rate هي معلمة فائقة مختلفة لكل من optimizer="Nesterov_momentum" وoptimizer="Adam". ويتشابه دورها (وإن لم يكن متطابقًا) في الخوارزميتين، ولكن يختلف نطاق القيم التي تعمل بشكل جيد في كل من أداتَي التحسين عادةً بعدة مراتب من حيث الحجم.
إنشاء مجموعة من الدراسات
بعد تحديد المعلمات الفائقة العلمية والمعطِلة، عليك تصميم دراسة أو سلسلة من الدراسات لتحقيق تقدّم نحو الهدف التجريبي. تحدّد الدراسة مجموعة من إعدادات المَعلمات الفائقة التي سيتم تنفيذها لإجراء التحليل اللاحق. يُطلق على كل إعداد اسم تجربة. يتضمّن إنشاء دراسة عادةً اختيار ما يلي:
- المعلَمات الفائقة التي تختلف باختلاف التجارب
- القيم التي يمكن أن تأخذها هذه المَعلمات الفائقة (مساحة البحث)
- عدد المحاولات
- خوارزمية بحث مبرمَجة لأخذ عيّنات من هذا العدد الكبير من التجارب من مساحة البحث
بدلاً من ذلك، يمكنك إنشاء دراسة من خلال تحديد مجموعة إعدادات المعلمات الفائقة يدويًا.
تهدف الدراسات إلى تحقيق ما يلي في الوقت نفسه:
- تشغيل خط الأنابيب بقيم مختلفة للمعلمات الفائقة العلمية
- "تحسين" (أو "تحسين أكثر من") المعلمات الفائقة المزعجة، وذلك لإجراء مقارنات عادلة قدر الإمكان بين القيم المختلفة للمعلمات الفائقة العلمية.
في أبسط الحالات، يمكنك إجراء دراسة منفصلة لكل إعداد من الإعدادات الخاصة بالمعلمات العلمية، حيث يتم ضبط كل دراسة على المعلمات الفائقة الخاصة بالمعلمات المزعجة. على سبيل المثال، إذا كان هدفك هو اختيار أفضل أداة تحسين من بين Nesterov momentum وAdam، يمكنك إنشاء دراستَين:
- إحدى الدراسات التي تكون فيها
optimizer="Nesterov_momentum"والمعلمات الفائقة المزعجة{learning_rate, momentum} - دراسة أخرى يكون فيها
optimizer="Adam"والمعلمات الفائقة المزعجة{learning_rate, beta1, beta2, epsilon}.
يمكنك مقارنة أداتَي التحسين من خلال اختيار أفضل تجربة من كل دراسة.
يمكنك استخدام أي خوارزمية تحسين بدون تدرّج، بما في ذلك طرق مثل التحسين البايزي أو الخوارزميات التطورية، لتحسين المعلمات الفائقة المزعجة. ومع ذلك، نفضل استخدام البحث شبه العشوائي في مرحلة الاستكشاف من عملية الضبط بسبب المزايا المتعدّدة التي يوفّرها في هذا الإعداد. بعد انتهاء الاستكشاف، ننصحك باستخدام برنامج حديث لتحسين بايزي (إذا كان متاحًا).
لنفترض حالة أكثر تعقيدًا تريد فيها مقارنة عدد كبير من قيم المعلمات الفائقة العلمية، ولكن من غير العملي إجراء هذا العدد الكبير من الدراسات المستقلة. في هذه الحالة، يمكنك إجراء ما يلي:
- أدرِج المَعلمات العلمية في مساحة البحث نفسها التي تتضمّن المَعلمات الفائقة المزعجة.
- استخدِم خوارزمية بحث لأخذ عيّنات من قيم كلّ من المَعلمات الفائقة العلمية والمزعجة في دراسة واحدة.
عند اتّباع هذا النهج، يمكن أن تتسبّب المَعلمات الفائقة الشرطية في حدوث مشاكل. فمن الصعب تحديد مساحة بحث ما لم تكن مجموعة المعلمات الفائقة المزعجة هي نفسها لجميع قيم المعلمات الفائقة العلمية. في هذه الحالة، يزداد تفضيلنا لاستخدام البحث شبه العشوائي على أدوات التحسين الأكثر تعقيدًا ذات الصندوق الأسود، لأنّه يضمن أخذ عينات من قيم مختلفة للمعلمات الفائقة العلمية بشكل موحّد. بغض النظر عن خوارزمية البحث، احرص على أن تبحث عن المعلمات العلمية بشكل موحّد.
تحقيق التوازن بين التجارب الغنية بالمعلومات والتجارب ذات التكلفة المعقولة
عند تصميم دراسة أو سلسلة من الدراسات، خصِّص ميزانية محدودة لتحقيق الأهداف الثلاثة التالية بشكل مناسب:
- مقارنة قيم مختلفة كافية للمعلمات الفائقة العلمية
- ضبط المَعلمات الفائقة المزعجة على مساحة بحث كبيرة بما يكفي
- أخذ عيّنات من مساحة البحث عن المَعلمات الفائقة المزعجة بكثافة كافية
وكلما تمكّنت من تحقيق هذه الأهداف الثلاثة بشكل أفضل، زادت الإحصاءات التي يمكنك استخلاصها من التجربة. تؤدي مقارنة أكبر عدد ممكن من قيم المعلمات الفائقة العلمية إلى توسيع نطاق الإحصاءات التي تحصل عليها من التجربة.
يؤدي تضمين أكبر عدد ممكن من المَعلمات الفائقة المزعجة والسماح لكل مَعلمة فائقة مزعجة بالتفاوت على أوسع نطاق ممكن إلى زيادة الثقة في توفّر قيمة "جيدة" للمَعلمات الفائقة المزعجة في مساحة البحث لكل إعداد من إعدادات المَعلمات الفائقة العلمية. وإلا، قد تجري مقارنات غير عادلة بين قيم المعلمات الفائقة العلمية من خلال عدم البحث في المناطق المحتملة لمساحة المعلمات الفائقة المزعجة التي قد تتضمّن قيمًا أفضل لبعض قيم المعلمات العلمية.
اختيار عيّنات من مساحة البحث عن المعلمات الفائقة المزعجة بأكبر قدر ممكن من الكثافة ويؤدي ذلك إلى زيادة الثقة في أنّ إجراء البحث سيجد أي إعدادات جيدة للمعلمات الفائقة المزعجة التي قد تكون موجودة في مساحة البحث. وإلا، قد تجري مقارنات غير عادلة بين قيم المَعلمات العلمية بسبب أنّ بعض القيم قد تكون أكثر حظًا في أخذ عيّنات من المَعلمات الفائقة المزعجة.
للأسف، تتطلّب التحسينات في أيّ من هذه الجوانب الثلاثة أحد الإجراءَين التاليَين:
- زيادة عدد المحاولات، وبالتالي زيادة تكلفة الموارد
- إيجاد طريقة لحفظ الموارد في أحد الأبعاد الأخرى
لكل مشكلة خصائصها وقيودها الحسابية، لذا يتطلّب تخصيص الموارد لتحقيق هذه الأهداف الثلاثة مستوى معيّنًا من المعرفة بالمجال. بعد إجراء دراسة، حاوِل دائمًا معرفة ما إذا كانت الدراسة قد ضبطت المعلمات الفائقة المزعجة بشكل جيد بما فيه الكفاية. أي أنّ الدراسة بحثت في مساحة كبيرة بما يكفي وبشكل شامل بما يكفي لإجراء مقارنة عادلة بين المعلمات الفائقة العلمية (كما هو موضّح بمزيد من التفصيل في القسم التالي).
الاستفادة من النتائج التجريبية
اقتراح: بالإضافة إلى محاولة تحقيق الهدف العلمي الأصلي لكل مجموعة من التجارب، راجِع قائمة أسئلة إضافية. إذا اكتشفت مشاكل، راجِع التجارب وأعِد تنفيذها.
في النهاية، يكون لكل مجموعة من التجارب هدف محدّد. عليك تقييم الأدلة التي تقدّمها التجارب لتحقيق هذا الهدف. ومع ذلك، إذا طرحت الأسئلة الصحيحة، يمكنك غالبًا العثور على مشاكل لتصحيحها قبل أن تتمكّن مجموعة معيّنة من التجارب من إحراز تقدّم نحو هدفها الأصلي. إذا لم تطرح هذه الأسئلة، قد تتوصل إلى استنتاجات غير صحيحة.
بما أنّ إجراء التجارب قد يكون مكلفًا، عليك أيضًا استخلاص إحصاءات مفيدة أخرى من كل مجموعة من التجارب، حتى إذا لم تكن هذه الإحصاءات ذات صلة مباشرة بالهدف الحالي.
قبل تحليل مجموعة معيّنة من التجارب لإحراز تقدّم نحو الهدف الأصلي، اطرح على نفسك الأسئلة الإضافية التالية:
- هل مساحة البحث كبيرة بما يكفي؟ إذا كانت النقطة المثالية من إحدى الدراسات قريبة من حدود مساحة البحث في بُعد واحد أو أكثر، من المحتمل أنّ البحث ليس واسع النطاق بما يكفي. في هذه الحالة، عليك إجراء دراسة أخرى تتضمّن مساحة بحث موسّعة.
- هل أخذت عيّنات كافية من النقاط من مساحة البحث؟ إذا لم يكن الأمر كذلك، يمكنك تشغيل المزيد من النقاط أو أن تكون أقل طموحًا في أهداف الضبط.
- ما هو جزء التجارب غير المجدية في كل دراسة؟ أيّ التجارب تنحرف أو تحصل على قيم خسارة سيئة للغاية أو لا يتم تشغيلها على الإطلاق لأنّها تنتهك بعض القيود الضمنية؟ عندما يكون جزء كبير جدًا من النقاط في إحدى الدراسات غير قابل للتطبيق، عدِّل مساحة البحث لتجنُّب أخذ عيّنات من هذه النقاط، الأمر الذي يتطلّب أحيانًا إعادة تحديد معلمات مساحة البحث. في بعض الحالات، قد يشير العدد الكبير من النقاط غير المجدية إلى خطأ في رمز التدريب.
- هل يواجه النموذج مشاكل في التحسين؟
- ما الذي يمكن تعلّمه من منحنيات التدريب الخاصة بأفضل التجارب؟ على سبيل المثال، هل تتضمّن أفضل التجارب منحنيات تدريب تتوافق مع مشكلة الإفراط في التكيّف؟
إذا لزم الأمر، استنادًا إلى الإجابات عن الأسئلة السابقة، حسِّن الدراسة الأخيرة أو مجموعة الدراسات لتحسين مساحة البحث و/أو أخذ عيّنات من المزيد من التجارب، أو اتّخاذ إجراء تصحيحي آخر.
بعد الإجابة عن الأسئلة السابقة، يمكنك تقييم الأدلة التي تقدّمها التجارب لتحقيق هدفك الأصلي، مثل تقييم ما إذا كان التغيير مفيدًا.
تحديد حدود مساحة البحث غير الصالحة
تكون مساحة البحث مشبوهة إذا كانت أفضل نقطة تم أخذ عيّنة منها قريبة من حدودها. قد تجد نقطة أفضل إذا وسّعت نطاق البحث في هذا الاتجاه.
للتحقّق من حدود مساحة البحث، ننصحك برسم التجارب المكتملة على ما نسمّيه مخططات محاور المعلمات الفائقة الأساسية. في هذه الرسومات البيانية، نرسم قيمة هدف التحقّق من الصحة مقابل أحد المَعلمات الفائقة (على سبيل المثال، معدّل التعلّم). تتوافق كل نقطة على الرسم البياني مع تجربة واحدة.
يجب أن تكون قيمة هدف التحقّق لكل تجربة عادةً هي أفضل قيمة تم تحقيقها خلال فترة التدريب.
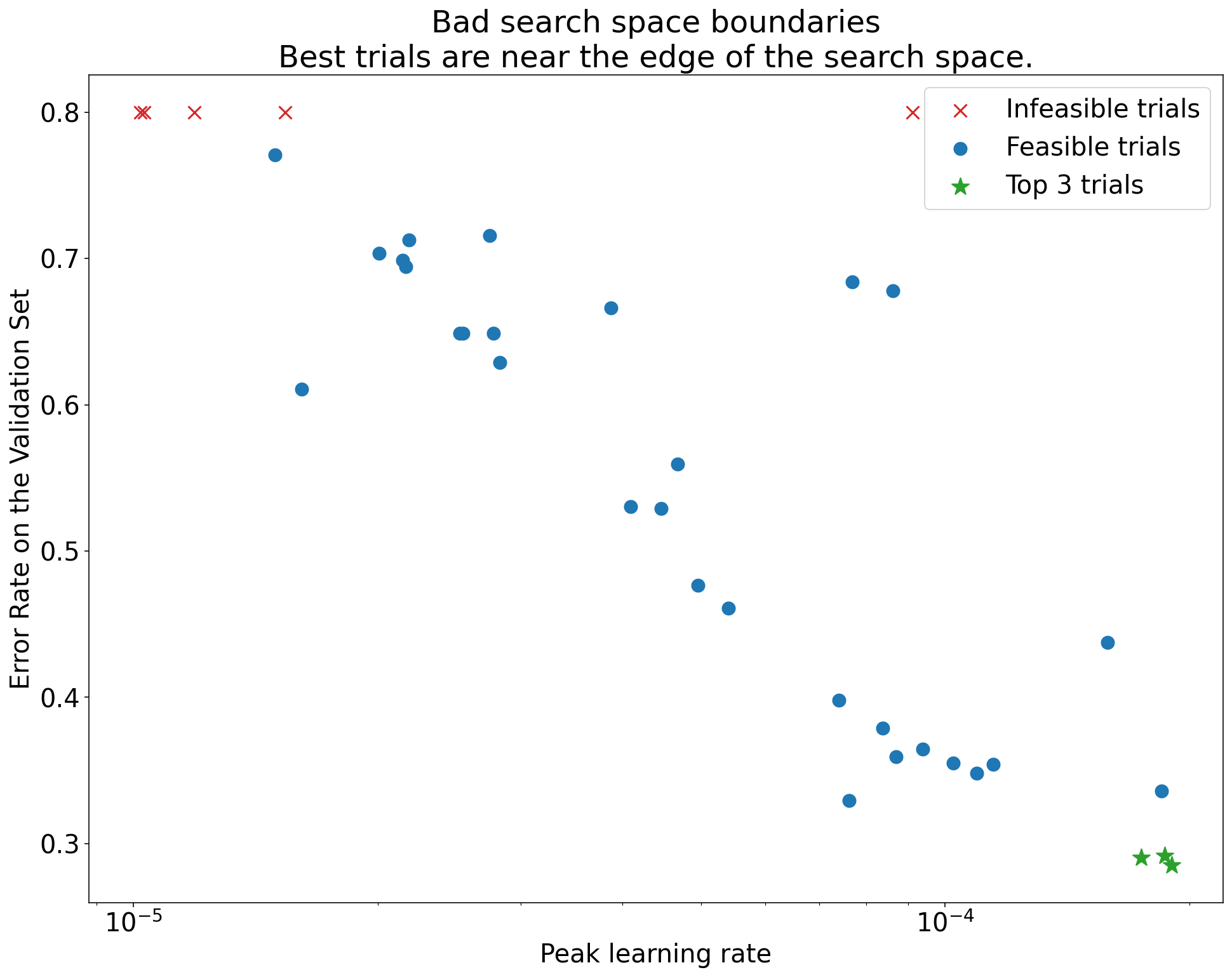
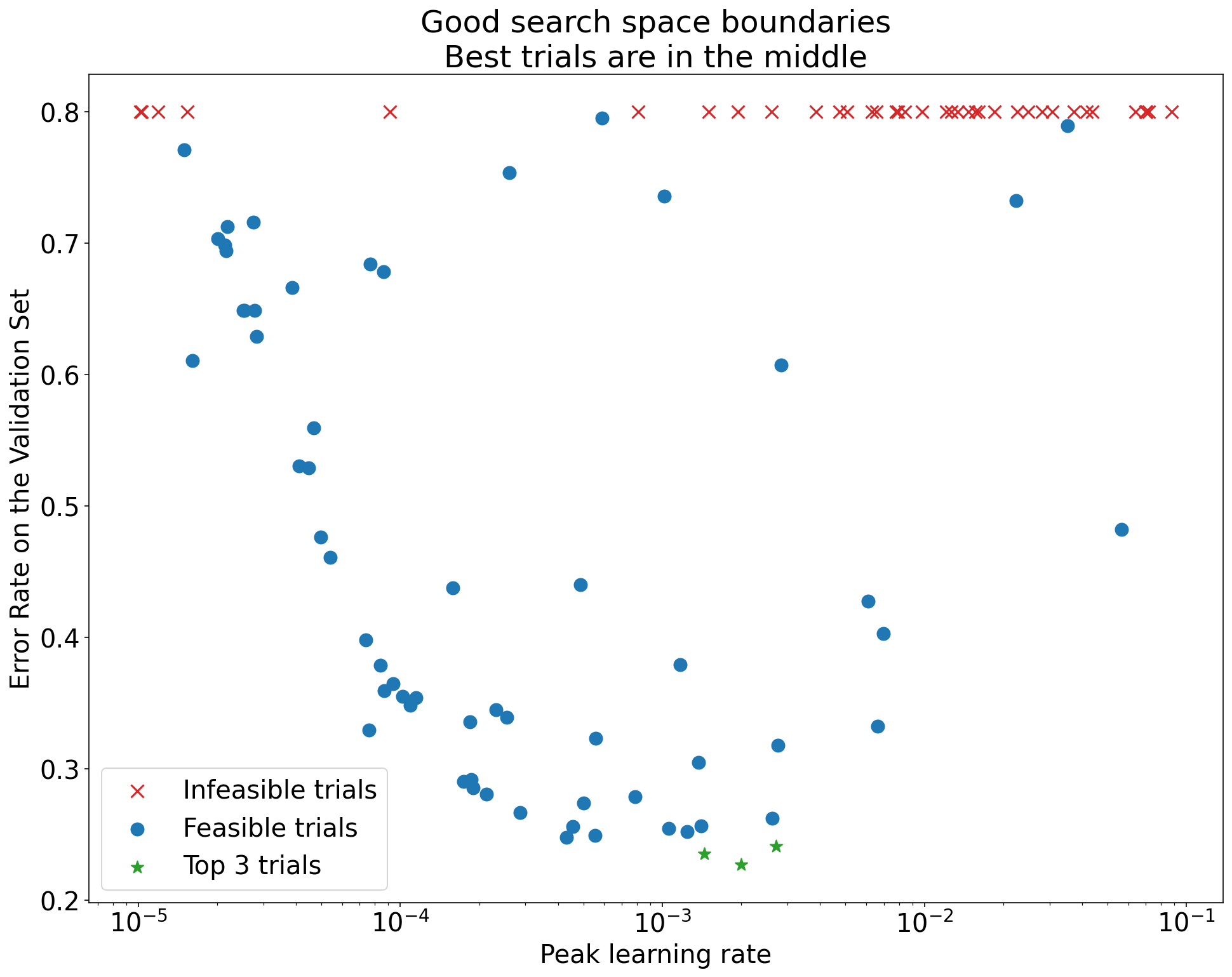
الشكل 1: أمثلة على حدود مساحة البحث غير المقبولة وحدود مساحة البحث المقبولة
تعرض الرسومات البيانية في الشكل 1 معدّل الخطأ (كلما كان أقل كان أفضل) مقابل معدّل التعلّم الأولي. إذا كانت أفضل النقاط تتجمّع بالقرب من حافة مساحة البحث (في بعض السمات)، قد تحتاج إلى توسيع حدود مساحة البحث إلى أن تصبح أفضل نقطة مرصودة بعيدة عن الحافة.
في كثير من الأحيان، تتضمّن الدراسة تجارب "غير ممكنة" تنحرف أو تسفر عن نتائج سيئة جدًا (يتم تمييزها بعلامات X حمراء في الشكل 1). إذا كانت جميع التجارب غير ممكنة لمعدّلات التعلّم الأكبر من قيمة حدّ معيّن، وإذا كانت أفضل التجارب أداءً تتضمّن معدّلات تعلّم على حافة تلك المنطقة، قد يعاني النموذج من مشاكل في الثبات تمنعه من الوصول إلى معدّلات تعلّم أعلى.
عدم أخذ عيّنات كافية من النقاط في مساحة البحث
بشكل عام، قد يكون من الصعب جدًا معرفة ما إذا تم أخذ عينات من مساحة البحث بشكل كافٍ. 🤖 إنّ إجراء المزيد من التجارب أفضل من إجراء عدد أقل منها، ولكنّ إجراء المزيد من التجارب يؤدي إلى تكلفة إضافية واضحة.
بما أنّه من الصعب معرفة الوقت الذي تكون فيه قد أخذت عيّنات كافية، ننصحك بما يلي:
- تذوُّق ما يمكنك تحمّل تكلفته
- معايرة مستوى الثقة الحدسي من خلال النظر بشكل متكرر إلى مخططات محاور مختلفة للمعلمات الفائقة ومحاولة استيعاب عدد النقاط الموجودة في المنطقة "الجيدة" من مساحة البحث
فحص منحنيات التدريب
ملخّص: يُعدّ فحص منحنيات الخسارة طريقة سهلة لتحديد أوضاع الأعطال الشائعة ويمكن أن يساعدك في تحديد أولويات الإجراءات المحتملة التالية.
في حالات كثيرة، لا يتطلّب الهدف الأساسي لتجاربك سوى النظر في خطأ التحقّق لكل تجربة. ومع ذلك، يجب توخّي الحذر عند اختصار كل تجربة إلى رقم واحد لأنّ هذا التركيز قد يخفي تفاصيل مهمة حول ما يحدث تحت السطح. بالنسبة إلى كل دراسة، ننصحك بشدة بالاطّلاع على منحنيات الخسارة لأفضل المحاولات القليلة على الأقل. حتى إذا لم يكن ذلك ضروريًا لتحقيق الهدف الأساسي للتجربة، فإنّ فحص منحنيات الخسارة (بما في ذلك خسارة التدريب وخسارة التحقّق) هو طريقة جيدة لتحديد أوضاع الأعطال الشائعة ويمكن أن يساعدك في تحديد أولويات الإجراءات التي يجب اتّخاذها بعد ذلك.
عند فحص منحنيات الخسارة، ركِّز على الأسئلة التالية:
هل هناك أي تجارب تظهر فيها مشكلة الإفراط في التكيّف؟ يحدث الإفراط في التخصيص الإشكالي عندما يبدأ خطأ التحقّق في الزيادة أثناء التدريب. في الإعدادات التجريبية التي تعمل فيها على تحسين المعلمات الفائقة المزعجة من خلال اختيار التجربة "الأفضل" لكل إعداد من إعدادات المعلمات الفائقة العلمية، تحقَّق من حدوث فرط ملائمة إشكالي في كل من أفضل التجارب على الأقل التي تتوافق مع إعدادات المعلمات الفائقة العلمية التي تقارنها. إذا أظهرت أي من أفضل التجارب ملاءمة مفرطة إشكالية، يمكنك إجراء أيّ من الإجراءَين التاليَين أو كليهما:
- إعادة تنفيذ التجربة باستخدام تقنيات تسوية إضافية
- أعِد ضبط معلَمات التسوية الحالية قبل مقارنة قيم المَعلمات الفائقة العلمية. قد لا ينطبق ذلك إذا كانت المعلمات الفائقة العلمية تتضمّن معلمات تسوية، لأنّه لن يكون من المستغرب أن تؤدي الإعدادات المنخفضة القوة لمعلمات التسوية هذه إلى الإفراط في التكيّف مع البيانات.
يمكن غالبًا تقليل التكيّف الزائد بسهولة باستخدام تقنيات التسوية الشائعة التي تضيف الحد الأدنى من تعقيد الرمز أو العمليات الحسابية الإضافية (على سبيل المثال، تسوية التسرب، وتسوية التنعيم، وتضاؤل الوزن). لذلك، من السهل عادةً إضافة واحدة أو أكثر من هذه المقاييس إلى الجولة التالية من التجارب. على سبيل المثال، إذا كانت المعلمة الفائقة العلمية هي "عدد الطبقات المخفية"، وكانت أفضل تجربة تستخدم أكبر عدد من الطبقات المخفية تعاني من فرط التجهيز، ننصحك بإعادة المحاولة مع إضافة تسوية بدلاً من اختيار عدد أقل من الطبقات المخفية على الفور.
حتى إذا لم تُظهر أي من التجارب "الأفضل" أي فرط في التكيّف، قد تظل هناك مشكلة إذا حدث ذلك في أي من التجارب. يؤدي اختيار أفضل تجربة إلى إيقاف الإعدادات التي تعرض ملاءمة مفرطة إشكالية، وتفضيل الإعدادات التي لا تعرضها. بعبارة أخرى، يؤدي اختيار أفضل تجربة إلى تفضيل الإعدادات التي تتضمّن المزيد من التسوية. ومع ذلك، يمكن أن يعمل أي شيء يؤدي إلى تفاقم التدريب كأداة تسوية، حتى إذا لم يكن الغرض منه ذلك. على سبيل المثال، يمكن أن يؤدي اختيار معدّل تعلّم أصغر إلى تنظيم التدريب من خلال إعاقة عملية التحسين، ولكننا لا نريد عادةً اختيار معدّل التعلّم بهذه الطريقة. يُرجى العِلم أنّه قد يتم اختيار "أفضل" تجربة لكل إعداد من إعدادات المعلمات الفائقة العلمية بطريقة تفضّل القيم "السيئة" لبعض المعلمات الفائقة العلمية أو غير المهمة.
هل هناك تباين كبير بين الخطوات في خطأ التدريب أو التحقّق في مرحلة متأخرة من التدريب؟ في هذه الحالة، قد يؤدي ذلك إلى حدوث مشاكل في ما يلي:
- قدرتك على مقارنة القيم المختلفة للمعلمات الفائقة العلمية ويرجع ذلك إلى أنّ كل تجربة تنتهي عشوائيًا في خطوة "محظوظة" أو "غير محظوظة".
- قدرتك على إعادة إنتاج نتيجة أفضل تجربة في مرحلة الإنتاج ويرجع ذلك إلى أنّ نموذج الإنتاج قد لا ينتهي بالخطوة "المحظوظة" نفسها كما في الدراسة.
في ما يلي الأسباب الأكثر احتمالاً للتباين بين الخطوات:
- تباين الدُفعات بسبب أخذ عيّنات عشوائية من مجموعة التدريب لكل دفعة
- مجموعات التحقّق الصغيرة
- استخدام معدّل تعلّم مرتفع جدًا في مرحلة متأخرة من التدريب
تشمل الحلول المحتملة ما يلي:
- زيادة حجم الدفعة
- الحصول على المزيد من بيانات التحقّق
- استخدام انخفاض معدّل التعلّم
- استخدام طريقة Polyak averaging
هل لا تزال التجارب تتحسّن في نهاية التدريب؟ إذا كان الأمر كذلك، فأنت في وضع "العمليات الحسابية المكثّفة"، ويمكنك الاستفادة من زيادة عدد خطوات التدريب أو تغيير جدول معدّل التعلّم.
هل تشبّع الأداء في مجموعتَي التدريب والتحقّق قبل وقت طويل من خطوة التدريب النهائية؟ في هذه الحالة، يشير ذلك إلى أنّك في وضع "غير مرتبط بالعمليات الحسابية"، وقد تتمكّن من تقليل عدد خطوات التدريب.
بالإضافة إلى هذه القائمة، يمكن أن تظهر العديد من السلوكيات الإضافية عند فحص منحنيات الفقدان. على سبيل المثال، يشير ارتفاع خسارة التدريب أثناء التدريب عادةً إلى وجود خطأ في مسار التدريب.
تحديد ما إذا كان التغيير مفيدًا باستخدام مخططات العزل
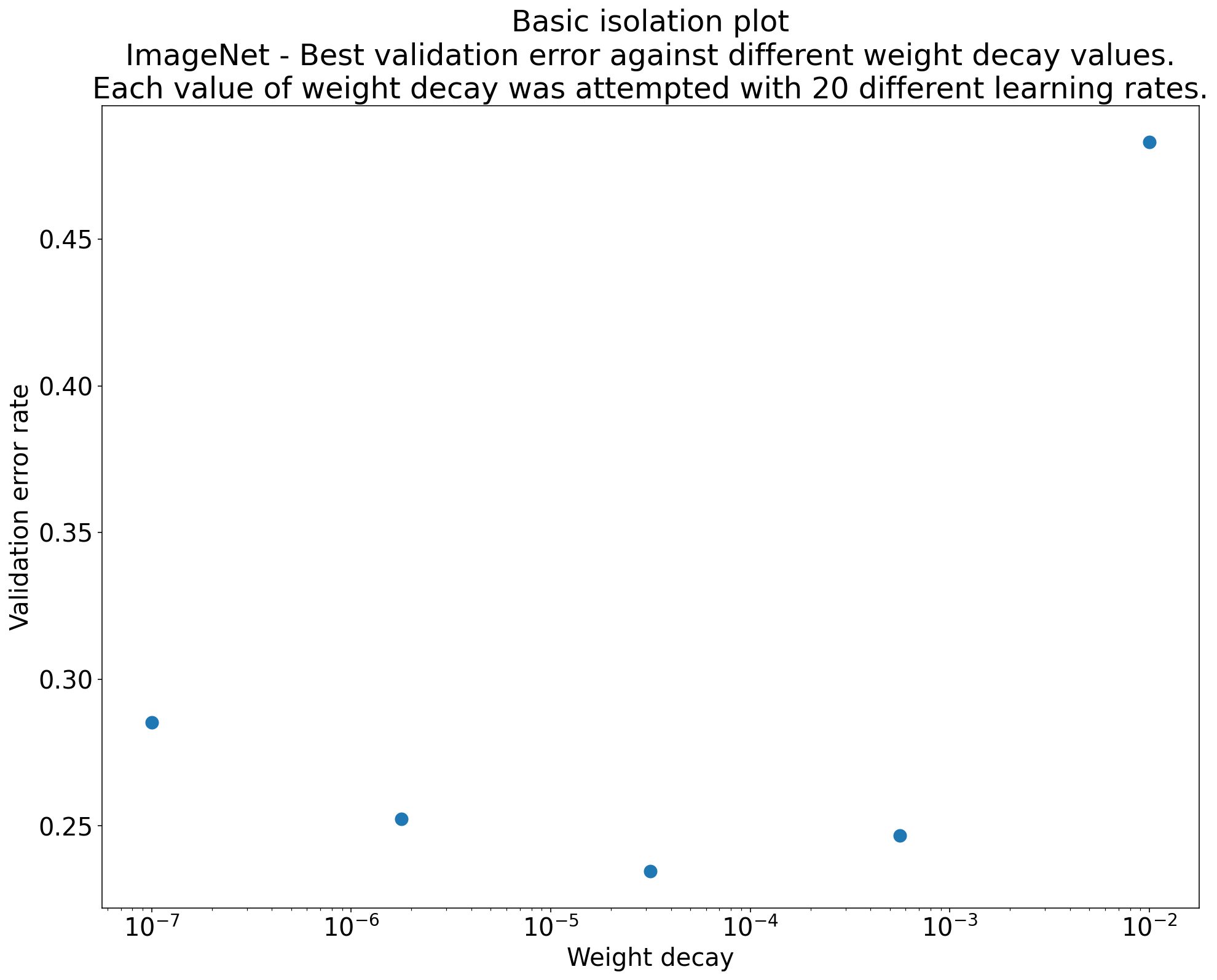
الشكل 2: رسم بياني للعزل يستكشف أفضل قيمة لتضاؤل الوزن بالنسبة إلى شبكة ResNet-50 التي تم تدريبها على ImageNet.
في كثير من الأحيان، يكون الهدف من مجموعة من التجارب هو مقارنة قيم مختلفة لمعلَمة فائقة علمية. على سبيل المثال، لنفترض أنّك تريد تحديد قيمة انخفاض الوزن التي تؤدي إلى أفضل خطأ في التحقّق. مخطّط العزل هو حالة خاصة من مخطط محور المعلمات الفائقة الأساسي. تتوافق كل نقطة في الرسم البياني للعزل مع أداء أفضل تجربة على مستوى بعض (أو كل) المعلمات الفائقة المزعجة. بعبارة أخرى، ارسم أداء النموذج بعد "تحسين" المعلمات الفائقة غير المرغوب فيها.
يبسّط مخطط العزل إجراء مقارنة متكافئة بين القيم المختلفة للمعلمة الفائقة العلمية. على سبيل المثال، يكشف الرسم البياني للعزل في الشكل 2 عن قيمة انخفاض الوزن التي تؤدي إلى أفضل أداء للتحقّق من الصحة لإعداد معيّن من ResNet-50 تم تدريبه على ImageNet.
إذا كان الهدف هو تحديد ما إذا كان يجب تضمين انخفاض أهمية البيانات القديمة على الإطلاق، قارِن أفضل نقطة من هذا الرسم البياني بخط الأساس الذي لا يشمل انخفاض أهمية البيانات القديمة. لإجراء مقارنة عادلة، يجب أيضًا أن يكون معدّل التعلّم في خط الأساس مضبوطًا بشكل جيد.
عندما تتوفّر لديك بيانات تم إنشاؤها من خلال البحث العشوائي (شبه العشوائي) وتفكر في استخدام مَعلمة فائقة مستمرة لرسم بياني للعزل، يمكنك تقريب الرسم البياني للعزل من خلال تقسيم قيم المحور x للرسم البياني الأساسي للمَعلمة الفائقة إلى مجموعات، ثم اختيار أفضل تجربة في كل شريحة عمودية محدّدة بواسطة المجموعات.
إنشاء رسومات بيانية مفيدة بشكل عام آليًا
وكلما زاد الجهد المطلوب لإنشاء الرسوم البيانية، قلّ احتمال الاطّلاع عليها بالقدر المطلوب. لذلك، ننصحك بإعداد البنية الأساسية لإنتاج أكبر عدد ممكن من الرسوم البيانية تلقائيًا. ننصحك على الأقل بإنشاء رسومات بيانية أساسية لمحاور المعلمات الفائقة تلقائيًا لجميع المعلمات الفائقة التي تغيّرها في التجربة.
بالإضافة إلى ذلك، ننصح بإنشاء منحنيات الخسارة تلقائيًا لجميع التجارب. بالإضافة إلى ذلك، ننصحك بتسهيل العثور على أفضل بضع تجارب لكل دراسة وفحص منحنيات الخسارة الخاصة بها.
يمكنك إضافة العديد من الرسومات البيانية والعروض المرئية المحتملة المفيدة الأخرى. فيما يلي اقتباس من جيفري هينتون:
في كل مرة ترسم فيها شيئًا جديدًا، تتعلم شيئًا جديدًا.
تحديد ما إذا كنت تريد اعتماد التغيير المقترَح
الملخّص: عند اتّخاذ قرار بشأن إجراء تغيير على النموذج أو إجراءات التدريب أو اعتماد إعداد جديد للمعلمات الفائقة، يجب الانتباه إلى مصادر التغيّر المختلفة في نتائجك.
عند محاولة تحسين نموذج، قد يحقّق تغيير مرشّح معيّن في البداية خطأ تحقّق أفضل مقارنةً بإعدادات حالية. ومع ذلك، قد لا تُظهر إعادة التجربة أي ميزة ثابتة. بشكل غير رسمي، يمكن تجميع أهم مصادر النتائج غير المتسقة في الفئات العامة التالية:
- تباين إجراء التدريب أو تباين إعادة التدريب أو تباين التجربة: هو التباين بين عمليات التدريب التي تستخدم المعلمات الفائقة نفسها ولكن قيم عشوائية مختلفة. على سبيل المثال، يمكن أن تكون عمليات التهيئة العشوائية المختلفة، وعمليات تبديل ترتيب بيانات التدريب، وأقنعة التسرب، وأنماط عمليات زيادة البيانات، وترتيب العمليات الحسابية المتوازية، كلها مصادر محتملة للتباين في التجارب.
- تباين البحث عن المعلَمات الفائقة أو تباين الدراسة: هو التباين في النتائج الناتج عن الإجراء الذي نتّبعه لاختيار المعلَمات الفائقة. على سبيل المثال، يمكنك إجراء التجربة نفسها باستخدام مساحة بحث معيّنة ولكن مع قيمتَي بداية مختلفتَين للبحث شبه العشوائي، وفي النهاية، يمكنك اختيار قيم مختلفة للمَعلمات الفائقة.
- جمع البيانات وتباين العيّنات: التباين الناتج عن أي نوع من التقسيم العشوائي إلى بيانات تدريب وتحقّق واختبار، أو التباين الناتج عن عملية إنشاء بيانات التدريب بشكل عام.
صحيح، يمكنك مقارنة معدّلات خطأ التحقّق المقدّرة في مجموعة تحقّق محدودة باستخدام اختبارات إحصائية دقيقة. ومع ذلك، غالبًا ما يمكن أن يؤدي التباين التجريبي وحده إلى اختلافات كبيرة إحصائيًا بين نموذجين مختلفين تم تدريبهما باستخدام إعدادات المعلمات الفائقة نفسها.
نحن نهتمّ بشكل خاص بتباين الدراسة عند محاولة استخلاص استنتاجات تتجاوز مستوى نقطة فردية في مساحة المعلمات الفائقة. يعتمد تباين الدراسة على عدد المحاولات ومساحة البحث. لقد لاحظنا حالات يكون فيها التباين في الدراسة أكبر من التباين في التجربة، وحالات يكون فيها التباين في الدراسة أصغر بكثير. لذلك، قبل اعتماد تغيير مرشّح، ننصحك بإجراء أفضل تجربة N مرّة لتحديد التباين بين التجارب. عادةً، يمكنك الاكتفاء بإعادة تحديد خصائص التباين التجريبي بعد إجراء تغييرات كبيرة على مسار الإعداد، ولكن قد تحتاج إلى تقديرات أحدث في بعض الحالات. في تطبيقات أخرى، يكون تحديد خصائص تباين العينة مكلفًا جدًا ولا يستحق ذلك.
على الرغم من أنّك تريد فقط اعتماد التغييرات (بما في ذلك إعدادات المعلمات الفائقة الجديدة) التي تؤدي إلى تحسينات حقيقية، إلا أنّ طلب التأكّد تمامًا من أنّ تغييرًا معيّنًا يساعد ليس هو الحلّ الصحيح أيضًا. لذلك، إذا حقّقت نقطة جديدة في المعلمات الفائقة (أو تغيير آخر) نتيجة أفضل من خط الأساس (مع الأخذ في الاعتبار تباين إعادة التدريب لكل من النقطة الجديدة وخط الأساس بأفضل ما يمكنك)، من المحتمل أن يكون عليك اعتمادها كخط أساس جديد للمقارنات المستقبلية. ومع ذلك، ننصحك بعدم اعتماد أي تغييرات إلا إذا كانت تؤدي إلى تحسينات تفوق أي تعقيد قد تضيفه.
بعد انتهاء الاستكشاف
ملخّص: أدوات التحسين المستند إلى الإحصاء البايزي هي خيار مقنع بعد الانتهاء من البحث عن مساحات بحث جيدة وتحديد المعلمات الفائقة التي تستحق الضبط.
في النهاية، ستنتقل أولوياتك من التعرّف أكثر على مشكلة الضبط إلى إنتاج أفضل إعداد واحد لإطلاقه أو استخدامه بطريقة أخرى. في هذه المرحلة، يجب أن تكون هناك مساحة بحث محسّنة تحتوي بشكل مريح على المنطقة المحلية حول أفضل تجربة تمت ملاحظتها وتم أخذ عينات منها بشكل كافٍ. من المفترض أن يكون عملك الاستكشافي قد كشف عن أهم المعلمات الفائقة التي يجب ضبطها ونطاقاتها المعقولة التي يمكنك استخدامها لإنشاء مساحة بحث لدراسة ضبط تلقائي نهائية باستخدام أكبر ميزانية ضبط ممكنة.
بما أنّك لم تعُد مهتمًا بتحقيق أقصى استفادة من المعلومات حول مشكلة الضبط، لم يعُد العديد من مزايا البحث شبه العشوائي ينطبق. لذلك، عليك استخدام أدوات التحسين المستند إلى الإحصاء البايزي للعثور تلقائيًا على أفضل إعدادات للمَعلمات الفائقة. تنفّذ Vizier مفتوحة المصدر مجموعة متنوعة من الخوارزميات المتطورة لضبط نماذج تعلُّم الآلة، بما في ذلك خوارزميات التحسين المستند إلى بايز.
لنفترض أنّ مساحة البحث تحتوي على عدد كبير من النقاط المتباينة، أي النقاط التي تؤدي إلى فقدان بيانات التدريب أو حتى فقدان بيانات التدريب بشكل أسوأ من المتوسط بعدة انحرافات معيارية. في هذه الحالة، ننصح باستخدام أدوات تحسين الصندوق الأسود التي تتعامل بشكل صحيح مع التجارب التي تختلف. (يمكنك الاطّلاع على التحسين المستند إلى الإحصاء البايزي مع القيود غير المعروفة للتعرّف على طريقة ممتازة للتعامل مع هذه المشكلة). يتوافق Vizier المفتوح المصدر مع تحديد النقاط المتباينة من خلال وضع علامة على التجارب باعتبارها غير قابلة للتطبيق، على الرغم من أنّه قد لا يستخدم الأسلوب المفضّل لدينا من Gelbart et al.، وذلك حسب طريقة إعداده.
بعد انتهاء الاستكشاف، ننصحك بالتحقّق من الأداء في مجموعة الاختبار. من حيث المبدأ، يمكنك حتى دمج مجموعة التحقّق في مجموعة التدريب وإعادة تدريب أفضل إعداد تم العثور عليه باستخدام التحسين البايزي. ومع ذلك، لا يكون هذا الإجراء مناسبًا إلا إذا لم يكن من المتوقّع إطلاق عمليات نشر مستقبلية باستخدام عبء العمل المحدّد هذا (على سبيل المثال، مسابقة Kaggle لمرة واحدة).