এই নথির উদ্দেশ্যে:
মেশিন লার্নিং ডেভেলপমেন্টের চূড়ান্ত লক্ষ্য হল মোতায়েন করা মডেলের উপযোগিতা সর্বাধিক করা।
আপনি সাধারণত যেকোনো ML সমস্যায় এই বিভাগে একই মৌলিক পদক্ষেপ এবং নীতিগুলি ব্যবহার করতে পারেন।
এই বিভাগটি নিম্নলিখিত অনুমান করে:
- আপনার কাছে ইতিমধ্যেই একটি সম্পূর্ণরূপে চলমান প্রশিক্ষণ পাইপলাইন এবং একটি কনফিগারেশন রয়েছে যা একটি যুক্তিসঙ্গত ফলাফল অর্জন করে।
- অর্থপূর্ণ টিউনিং পরীক্ষা চালানোর জন্য এবং সমান্তরালভাবে অন্তত কয়েকটি প্রশিক্ষণের কাজ চালানোর জন্য আপনার কাছে যথেষ্ট গণনামূলক সংস্থান রয়েছে।
ক্রমবর্ধমান টিউনিং কৌশল
সুপারিশ: একটি সাধারণ কনফিগারেশন দিয়ে শুরু করুন। তারপরে, সমস্যা সম্পর্কে অন্তর্দৃষ্টি তৈরি করার সময় ক্রমবর্ধমান উন্নতি করুন। নিশ্চিত করুন যে কোন উন্নতি শক্তিশালী প্রমাণের উপর ভিত্তি করে।
আমরা ধরে নিই যে আপনার লক্ষ্য হল এমন একটি কনফিগারেশন খুঁজে বের করা যা আপনার মডেলের কর্মক্ষমতা সর্বাধিক করে। কখনও কখনও, আপনার লক্ষ্য একটি নির্দিষ্ট সময়সীমা দ্বারা মডেল উন্নতি সর্বাধিক করা হয়. অন্যান্য ক্ষেত্রে, আপনি অনির্দিষ্টকালের জন্য মডেলের উন্নতি চালিয়ে যেতে পারেন; উদাহরণস্বরূপ, ক্রমাগত উত্পাদনে ব্যবহৃত একটি মডেলের উন্নতি করা।
নীতিগতভাবে, আপনি সম্ভাব্য কনফিগারেশনের সম্পূর্ণ স্থান স্বয়ংক্রিয়ভাবে অনুসন্ধান করতে একটি অ্যালগরিদম ব্যবহার করে কর্মক্ষমতা সর্বাধিক করতে পারেন, তবে এটি একটি বাস্তব বিকল্প নয়। সম্ভাব্য কনফিগারেশনের স্থান অত্যন্ত বড় এবং মানুষের নির্দেশনা ছাড়া এই স্থানটি দক্ষতার সাথে অনুসন্ধান করার জন্য যথেষ্ট পরিশীলিত কোনো অ্যালগরিদম নেই। বেশিরভাগ স্বয়ংক্রিয় অনুসন্ধান অ্যালগরিদমগুলি একটি হাতে ডিজাইন করা অনুসন্ধান স্থানের উপর নির্ভর করে যা অনুসন্ধানের জন্য কনফিগারেশনের সেটকে সংজ্ঞায়িত করে এবং এই অনুসন্ধান স্থানগুলি বেশ কিছুটা গুরুত্বপূর্ণ হতে পারে।
কর্মক্ষমতা সর্বাধিক করার সবচেয়ে কার্যকর উপায় হল একটি সাধারণ কনফিগারেশন দিয়ে শুরু করা এবং ক্রমবর্ধমান বৈশিষ্ট্যগুলি যোগ করা এবং সমস্যার অন্তর্দৃষ্টি তৈরি করার সময় উন্নতি করা।
আমরা টিউনিংয়ের প্রতিটি রাউন্ডে স্বয়ংক্রিয় অনুসন্ধান অ্যালগরিদম ব্যবহার করার পরামর্শ দিই এবং আপনার বোঝার বৃদ্ধির সাথে সাথে সার্চ স্পেসগুলি ক্রমাগত আপডেট করুন৷ আপনি যখন অন্বেষণ করবেন, আপনি স্বাভাবিকভাবেই আরও ভাল এবং আরও ভাল কনফিগারেশন পাবেন এবং সেইজন্য আপনার "সেরা" মডেল ক্রমাগত উন্নতি করবে।
"লঞ্চ" শব্দটি আমাদের সর্বোত্তম কনফিগারেশনের একটি আপডেটকে বোঝায় (যা একটি উত্পাদন মডেলের প্রকৃত লঞ্চের সাথে মিল থাকতে পারে বা নাও হতে পারে)৷ প্রতিটি "লঞ্চ"-এর জন্য আপনাকে অবশ্যই নিশ্চিত করতে হবে যে পরিবর্তনটি শক্তিশালী প্রমাণের উপর ভিত্তি করে করা হয়েছে-শুধু একটি ভাগ্যবান কনফিগারেশনের উপর ভিত্তি করে এলোমেলো সুযোগ নয়-যাতে আপনি প্রশিক্ষণ পাইপলাইনে অপ্রয়োজনীয় জটিলতা যোগ করবেন না।
একটি উচ্চ স্তরে, আমাদের ক্রমবর্ধমান টিউনিং কৌশল নিম্নলিখিত চারটি ধাপের পুনরাবৃত্তি জড়িত:
- পরের রাউন্ডের পরীক্ষার জন্য একটি লক্ষ্য বাছুন। লক্ষ্যটি যথাযথভাবে স্কোপ করা হয়েছে তা নিশ্চিত করুন।
- পরীক্ষার পরবর্তী রাউন্ড ডিজাইন করুন। এই লক্ষ্যের দিকে অগ্রসর হওয়া পরীক্ষাগুলির একটি সেট ডিজাইন এবং কার্যকর করুন।
- পরীক্ষামূলক ফলাফল থেকে শিখুন. একটি চেকলিস্টের বিরুদ্ধে পরীক্ষাটি মূল্যায়ন করুন।
- প্রার্থী পরিবর্তনকে গ্রহণ করবেন কিনা তা নির্ধারণ করুন।
এই বিভাগের বাকি অংশ এই কৌশলটির বিবরণ দেয়।
পরের রাউন্ডের পরীক্ষার জন্য একটি লক্ষ্য বাছুন
আপনি যদি একাধিক বৈশিষ্ট্য যুক্ত করার চেষ্টা করেন বা একসাথে একাধিক প্রশ্নের উত্তর দেন, তাহলে আপনি ফলাফলের উপর পৃথক প্রভাবগুলিকে মীমাংসা করতে পারবেন না। উদাহরণ লক্ষ্য অন্তর্ভুক্ত:
- পাইপলাইনে সম্ভাব্য উন্নতির চেষ্টা করুন (উদাহরণস্বরূপ, একটি নতুন রেগুলার, প্রিপ্রসেসিং পছন্দ, ইত্যাদি)।
- একটি নির্দিষ্ট মডেল হাইপারপ্যারামিটারের প্রভাব বুঝুন (উদাহরণস্বরূপ, অ্যাক্টিভেশন ফাংশন)
- বৈধতা ত্রুটি কম করুন।
স্বল্পমেয়াদী বৈধতা ত্রুটি উন্নতির চেয়ে দীর্ঘমেয়াদী অগ্রগতিকে অগ্রাধিকার দিন
সারাংশ: বেশিরভাগ সময়, আপনার প্রাথমিক লক্ষ্য হল টিউনিং সমস্যা সম্পর্কে অন্তর্দৃষ্টি অর্জন করা।
আমরা সুপারিশ করি যে আপনার বেশিরভাগ সময় সমস্যাটির অন্তর্দৃষ্টি অর্জনের জন্য ব্যয় করুন এবং তুলনামূলকভাবে অল্প সময় লোভের সাথে যাচাইকরণ সেটে সর্বাধিক কর্মক্ষমতা বাড়াতে মনোনিবেশ করুন। অন্য কথায়, আপনার বেশিরভাগ সময় "অন্বেষণ" এ ব্যয় করুন এবং "শোষণে" অল্প পরিমাণে ব্যয় করুন। চূড়ান্ত কর্মক্ষমতা সর্বাধিক করার জন্য সমস্যাটি বোঝা গুরুত্বপূর্ণ। স্বল্পমেয়াদী লাভের উপর অন্তর্দৃষ্টিকে অগ্রাধিকার দেওয়া সাহায্য করে:
- অপ্রয়োজনীয় পরিবর্তনগুলি চালু করা এড়িয়ে চলুন যা শুধুমাত্র ঐতিহাসিক দুর্ঘটনার মাধ্যমে ভাল-পারফর্মিং রানে উপস্থিত হতে পারে।
- যাচাইকরণের ত্রুটিটি কোন হাইপারপ্যারামিটারগুলির প্রতি সবচেয়ে সংবেদনশীল, কোন হাইপারপ্যারামিটারগুলি সবচেয়ে বেশি ইন্টারঅ্যাক্ট করে এবং সেইজন্য একসাথে পুনরায় সংযোজন করা প্রয়োজন এবং কোন হাইপারপ্যারামিটারগুলি অন্যান্য পরিবর্তনের জন্য তুলনামূলকভাবে সংবেদনশীল নয় এবং তাই ভবিষ্যতের পরীক্ষায় ঠিক করা যেতে পারে৷
- চেষ্টা করার জন্য সম্ভাব্য নতুন বৈশিষ্ট্যগুলি সুপারিশ করুন, যেমন নতুন রেগুলারাইজার যখন ওভারফিটিং একটি সমস্যা হয়।
- এমন বৈশিষ্ট্যগুলি সনাক্ত করুন যা সাহায্য করে না এবং সেইজন্য অপসারণ করা যেতে পারে, ভবিষ্যতের পরীক্ষাগুলির জটিলতা হ্রাস করে৷
- হাইপারপ্যারামিটার টিউনিং থেকে উন্নতি কখন সম্পৃক্ত হয়েছে তা সনাক্ত করুন।
- টিউনিং দক্ষতা উন্নত করতে সর্বোত্তম মানের চারপাশে আমাদের অনুসন্ধানের স্থান সংকুচিত করুন।
অবশেষে, আপনি সমস্যাটি বুঝতে পারবেন। তারপরে, টিউনিং সমস্যার গঠন সম্পর্কে পরীক্ষাগুলি সর্বাধিক তথ্যপূর্ণ না হলেও আপনি বৈধতা ত্রুটির উপর সম্পূর্ণরূপে ফোকাস করতে পারেন।
পরীক্ষার পরবর্তী রাউন্ড ডিজাইন করুন
সারাংশ: পরীক্ষামূলক লক্ষ্যের জন্য কোন হাইপারপ্যারামিটারগুলি বৈজ্ঞানিক, উপদ্রব এবং স্থির হাইপারপ্যারামিটারগুলি সনাক্ত করুন। উপদ্রব হাইপারপ্যারামিটারের উপর অপ্টিমাইজ করার সময় বৈজ্ঞানিক হাইপারপ্যারামিটারের বিভিন্ন মান তুলনা করার জন্য অধ্যয়নের একটি ক্রম তৈরি করুন। বৈজ্ঞানিক মূল্যের সাথে রিসোর্স খরচের ভারসাম্য রাখতে উপদ্রব হাইপারপ্যারামিটারের অনুসন্ধানের স্থানটি বেছে নিন।
বৈজ্ঞানিক, উপদ্রব, এবং স্থির হাইপারপ্যারামিটার সনাক্ত করুন
একটি নির্দিষ্ট লক্ষ্যের জন্য, সমস্ত হাইপারপ্যারামিটার নিম্নলিখিত শ্রেণীগুলির মধ্যে একটিতে পড়ে:
- বৈজ্ঞানিক হাইপারপ্যারামিটার হল মডেলের কার্যক্ষমতার উপর যার প্রভাব আপনি পরিমাপ করার চেষ্টা করছেন।
- উপদ্রব হাইপারপ্যারামিটারগুলি হল যেগুলিকে বৈজ্ঞানিক হাইপারপ্যারামিটারের বিভিন্ন মান মোটামুটি তুলনা করার জন্য অপ্টিমাইজ করা প্রয়োজন৷ উপদ্রব হাইপারপ্যারামিটারগুলি পরিসংখ্যানের উপদ্রব পরামিতিগুলির অনুরূপ।
- বর্তমান রাউন্ডের পরীক্ষায় স্থির হাইপারপ্যারামিটারের ধ্রুবক মান রয়েছে। আপনি বৈজ্ঞানিক হাইপারপ্যারামিটারের বিভিন্ন মান তুলনা করার সময় স্থির হাইপারপ্যারামিটারের মান পরিবর্তন করা উচিত নয়। পরীক্ষার একটি সেটের জন্য নির্দিষ্ট হাইপারপ্যারামিটার ঠিক করে, আপনাকে অবশ্যই স্বীকার করতে হবে যে পরীক্ষাগুলি থেকে প্রাপ্ত সিদ্ধান্তগুলি স্থির হাইপারপ্যারামিটারের অন্যান্য সেটিংসের জন্য বৈধ নাও হতে পারে। অন্য কথায়, স্থির হাইপারপ্যারামিটারগুলি পরীক্ষাগুলি থেকে আপনি যে কোনও সিদ্ধান্তে আঁকেন তার জন্য সতর্কতা তৈরি করে।
উদাহরণস্বরূপ, ধরুন আপনার লক্ষ্য নিম্নরূপ:
আরও লুকানো স্তর সহ একটি মডেলের কম বৈধতা ত্রুটি আছে কিনা তা নির্ধারণ করুন৷
এই ক্ষেত্রে:
- শেখার হার একটি উপদ্রব হাইপারপ্যারামিটার কারণ আপনি কেবলমাত্র লুকানো স্তরগুলির বিভিন্ন সংখ্যার সাথে মডেলের তুলনা করতে পারবেন যদি প্রতিটি সংখ্যার লুকানো স্তরগুলির জন্য শেখার হার আলাদাভাবে টিউন করা হয়। (সর্বোত্তম শেখার হার সাধারণত মডেল আর্কিটেকচারের উপর নির্ভর করে)।
- অ্যাক্টিভেশন ফাংশনটি একটি স্থির হাইপারপ্যারামিটার হতে পারে যদি আপনি পূর্বের পরীক্ষায় নির্ধারণ করে থাকেন যে সেরা অ্যাক্টিভেশন ফাংশনটি মডেলের গভীরতার প্রতি সংবেদনশীল নয়। অথবা, আপনি এই অ্যাক্টিভেশন ফাংশনটি কভার করার জন্য লুকানো স্তরগুলির সংখ্যা সম্পর্কে আপনার সিদ্ধান্ত সীমিত করতে ইচ্ছুক। বিকল্পভাবে, এটি একটি উপদ্রব হাইপারপ্যারামিটার হতে পারে যদি আপনি প্রতিটি সংখ্যক লুকানো স্তরের জন্য আলাদাভাবে সুর করার জন্য প্রস্তুত হন।
একটি নির্দিষ্ট হাইপারপ্যারামিটার একটি বৈজ্ঞানিক হাইপারপ্যারামিটার, উপদ্রব হাইপারপ্যারামিটার বা স্থির হাইপারপ্যারামিটার হতে পারে; পরীক্ষামূলক লক্ষ্যের উপর নির্ভর করে হাইপারপ্যারামিটারের উপাধি পরিবর্তিত হয়। উদাহরণস্বরূপ, অ্যাক্টিভেশন ফাংশন নিম্নলিখিত যে কোনো হতে পারে:
- বৈজ্ঞানিক হাইপারপ্যারামিটার: ReLU বা tanh কি আমাদের সমস্যার জন্য একটি ভাল পছন্দ?
- উপদ্রব হাইপারপ্যারামিটার: আপনি যখন বিভিন্ন সম্ভাব্য অ্যাক্টিভেশন ফাংশন অনুমোদন করেন তখন সেরা পাঁচ-স্তর মডেলটি সেরা ছয়-স্তর মডেলের চেয়ে ভাল?
- স্থির হাইপারপ্যারামিটার: ReLU নেটগুলির জন্য, একটি নির্দিষ্ট অবস্থানে ব্যাচ স্বাভাবিককরণ যোগ করা কি সাহায্য করে?
পরীক্ষার একটি নতুন রাউন্ড ডিজাইন করার সময়:
- পরীক্ষামূলক লক্ষ্যের জন্য বৈজ্ঞানিক হাইপারপ্যারামিটারগুলি সনাক্ত করুন। (এই পর্যায়ে, আপনি অন্যান্য সমস্ত হাইপারপ্যারামিটারকে উপদ্রব হাইপারপ্যারামিটার হিসাবে বিবেচনা করতে পারেন।)
- কিছু উপদ্রব হাইপারপ্যারামিটারকে স্থির হাইপারপ্যারামিটারে রূপান্তর করুন।
সীমাহীন সংস্থান সহ, আপনি সমস্ত অ-বৈজ্ঞানিক হাইপারপ্যারামিটারগুলিকে উপদ্রব হাইপারপ্যারামিটার হিসাবে ছেড়ে দেবেন যাতে আপনার পরীক্ষাগুলি থেকে আপনি যে সিদ্ধান্তগুলি আঁকেন তা নির্দিষ্ট হাইপারপ্যারামিটার মান সম্পর্কে সতর্কতা থেকে মুক্ত থাকে। যাইহোক, আপনি যত বেশি উপদ্রব হাইপারপ্যারামিটার টিউন করার চেষ্টা করবেন, বৈজ্ঞানিক হাইপারপ্যারামিটারের প্রতিটি সেটিংয়ের জন্য আপনি সেগুলিকে পর্যাপ্তভাবে টিউন করতে ব্যর্থ হবেন এবং আপনার পরীক্ষা থেকে ভুল সিদ্ধান্তে পৌঁছানোর ঝুঁকি তত বেশি হবে। পরবর্তী বিভাগে বর্ণিত হিসাবে, আপনি গণনামূলক বাজেট বাড়িয়ে এই ঝুঁকি মোকাবেলা করতে পারেন। যাইহোক, আপনার সর্বাধিক সম্পদ বাজেট প্রায়ই সমস্ত অ-বৈজ্ঞানিক হাইপারপ্যারামিটার টিউন করার জন্য প্রয়োজনের চেয়ে কম।
আমরা একটি উপদ্রব হাইপারপ্যারামিটারকে একটি স্থির হাইপারপ্যারামিটারে রূপান্তর করার পরামর্শ দিই যখন এটিকে সংশোধন করার মাধ্যমে প্রবর্তিত সতর্কতাগুলি এটিকে একটি উপদ্রব হাইপারপ্যারামিটার হিসাবে অন্তর্ভুক্ত করার খরচের চেয়ে কম বোঝা। একটি উপদ্রব হাইপারপ্যারামিটার যত বেশি বৈজ্ঞানিক হাইপারপ্যারামিটারের সাথে ইন্টারঅ্যাক্ট করে, তার মান ঠিক করা তত বেশি ক্ষতিকর। উদাহরণস্বরূপ, ওজন ক্ষয়ের শক্তির সর্বোত্তম মান সাধারণত মডেলের আকারের উপর নির্ভর করে, তাই ওজন ক্ষয়ের একটি নির্দিষ্ট মান ধরে নিয়ে বিভিন্ন মডেলের আকারের তুলনা করা খুব অন্তর্দৃষ্টিপূর্ণ হবে না।
কিছু অপ্টিমাইজার পরামিতি
একটি নিয়ম হিসাবে, কিছু অপ্টিমাইজার হাইপারপ্যারামিটার (যেমন শেখার হার, গতিবেগ, শেখার হারের সময়সূচী পরামিতি, অ্যাডাম বেটাস ইত্যাদি) হল উপদ্রব হাইপারপ্যারামিটার কারণ তারা অন্যান্য পরিবর্তনের সাথে সবচেয়ে বেশি ইন্টারঅ্যাক্ট করে। এই অপ্টিমাইজার হাইপারপ্যারামিটারগুলি খুব কমই বৈজ্ঞানিক হাইপারপ্যারামিটার কারণ একটি লক্ষ্য যেমন "বর্তমান পাইপলাইনের জন্য সেরা শেখার হার কী?" অনেক অন্তর্দৃষ্টি প্রদান করে না। সর্বোপরি, পরবর্তী পাইপলাইন পরিবর্তনের সাথে সর্বোত্তম সেটিং পরিবর্তন হতে পারে।
সম্পদের সীমাবদ্ধতার কারণে বা বিশেষ করে শক্তিশালী প্রমাণের কারণে আপনি কিছু অপ্টিমাইজার হাইপারপ্যারামিটার ঠিক করতে পারেন যে তারা বৈজ্ঞানিক পরামিতির সাথে ইন্টারঅ্যাক্ট করে না। যাইহোক, আপনার সাধারণত অনুমান করা উচিত যে বৈজ্ঞানিক হাইপারপ্যারামিটারের বিভিন্ন সেটিংসের মধ্যে ন্যায্য তুলনা করার জন্য আপনাকে অবশ্যই অপ্টিমাইজার হাইপারপ্যারামিটারগুলিকে আলাদাভাবে টিউন করতে হবে এবং এইভাবে ঠিক করা উচিত নয়। তদুপরি, একটি অপ্টিমাইজারের হাইপারপ্যারামিটার মানকে অন্যটির চেয়ে পছন্দ করার কোন অগ্রাধিকার কারণ নেই; উদাহরণস্বরূপ, অপ্টিমাইজার হাইপারপ্যারামিটার মানগুলি সাধারণত ফরোয়ার্ড পাস বা গ্রেডিয়েন্টের কম্পিউটেশনাল খরচকে কোনোভাবেই প্রভাবিত করে না।
অপ্টিমাইজারের পছন্দ
অপ্টিমাইজারের পছন্দ সাধারণত হয়:
- একটি বৈজ্ঞানিক হাইপারপ্যারামিটার
- একটি নির্দিষ্ট হাইপারপ্যারামিটার
একটি অপ্টিমাইজার হল একটি বৈজ্ঞানিক হাইপারপ্যারামিটার যদি আপনার পরীক্ষামূলক লক্ষ্যে দুই বা ততোধিক ভিন্ন অপ্টিমাইজারের মধ্যে ন্যায্য তুলনা করা জড়িত থাকে। যেমন:
কোন অপ্টিমাইজার একটি নির্দিষ্ট সংখ্যক ধাপে সর্বনিম্ন বৈধতা ত্রুটি তৈরি করে তা নির্ধারণ করুন।
বিকল্পভাবে, আপনি বিভিন্ন কারণে অপ্টিমাইজারকে একটি নির্দিষ্ট হাইপারপ্যারামিটার করতে পারেন, যার মধ্যে রয়েছে:
- পূর্বের পরীক্ষাগুলি পরামর্শ দেয় যে আপনার টিউনিং সমস্যার জন্য সেরা অপ্টিমাইজার বর্তমান বৈজ্ঞানিক হাইপারপ্যারামিটারের প্রতি সংবেদনশীল নয়।
- আপনি এই অপ্টিমাইজার ব্যবহার করে বৈজ্ঞানিক হাইপারপ্যারামিটারের মান তুলনা করতে পছন্দ করেন কারণ এর প্রশিক্ষণ বক্ররেখাগুলি সম্পর্কে যুক্তি করা সহজ।
- আপনি এই অপ্টিমাইজারটি ব্যবহার করতে পছন্দ করেন কারণ এটি বিকল্পগুলির তুলনায় কম মেমরি ব্যবহার করে৷
নিয়মিতকরণ হাইপারপ্যারামিটার
একটি নিয়মিতকরণ কৌশল দ্বারা প্রবর্তিত হাইপারপ্যারামিটারগুলি সাধারণত উপদ্রব হাইপারপ্যারামিটার। যাইহোক, রেগুলারাইজেশন কৌশলটি আদৌ অন্তর্ভুক্ত করা যায় কি না তার পছন্দ একটি বৈজ্ঞানিক বা স্থির হাইপারপ্যারামিটার।
উদাহরণস্বরূপ, ড্রপআউট নিয়মিতকরণ কোড জটিলতা যোগ করে। তাই, ড্রপআউট নিয়মিতকরণ অন্তর্ভুক্ত করার সিদ্ধান্ত নেওয়ার সময়, আপনি "নো ড্রপআউট" বনাম "ড্রপআউট" একটি বৈজ্ঞানিক হাইপারপ্যারামিটার কিন্তু ড্রপআউট রেটকে একটি উপদ্রব হাইপারপ্যারামিটার করতে পারেন। আপনি যদি এই পরীক্ষার উপর ভিত্তি করে পাইপলাইনে ড্রপআউট নিয়মিতকরণ যোগ করার সিদ্ধান্ত নেন, তাহলে ড্রপআউট হার ভবিষ্যতের পরীক্ষায় একটি উপদ্রব হাইপারপ্যারামিটার হবে।
আর্কিটেকচারাল হাইপারপ্যারামিটার
আর্কিটেকচারাল হাইপারপ্যারামিটারগুলি প্রায়শই বৈজ্ঞানিক বা স্থির হাইপারপ্যারামিটার হয় কারণ আর্কিটেকচারের পরিবর্তনগুলি পরিবেশন এবং প্রশিক্ষণের খরচ, লেটেন্সি এবং মেমরির প্রয়োজনীয়তাকে প্রভাবিত করতে পারে। উদাহরণস্বরূপ, স্তরগুলির সংখ্যা সাধারণত একটি বৈজ্ঞানিক বা স্থির হাইপারপ্যারামিটার কারণ এটি প্রশিক্ষণের গতি এবং মেমরি ব্যবহারের জন্য নাটকীয় পরিণতি ঘটায়।
বৈজ্ঞানিক হাইপারপ্যারামিটারের উপর নির্ভরতা
কিছু ক্ষেত্রে, উপদ্রব এবং স্থির হাইপারপ্যারামিটারের সেটগুলি বৈজ্ঞানিক হাইপারপ্যারামিটারের মানগুলির উপর নির্ভর করে। উদাহরণ স্বরূপ, ধরুন আপনি নেস্টেরভ মোমেন্টামে কোন অপটিমাইজার নির্ধারণ করার চেষ্টা করছেন এবং অ্যাডাম সর্বনিম্ন বৈধতা ত্রুটিতে উৎপন্ন করে। এই ক্ষেত্রে:
- বৈজ্ঞানিক হাইপারপ্যারামিটার হল অপ্টিমাইজার, যা মান নেয়
{"Nesterov_momentum", "Adam"} - মান
optimizer="Nesterov_momentum"হাইপারপ্যারামিটারগুলি প্রবর্তন করে{learning_rate, momentum}, যা হয় উপদ্রব বা স্থির হাইপারপ্যারামিটার হতে পারে। - মান
optimizer="Adam"হাইপারপ্যারামিটারগুলি প্রবর্তন করে{learning_rate, beta1, beta2, epsilon}, যা হয় উপদ্রব বা স্থির হাইপারপ্যারামিটার হতে পারে।
যে হাইপারপ্যারামিটারগুলি শুধুমাত্র বৈজ্ঞানিক হাইপারপ্যারামিটারের নির্দিষ্ট মানগুলির জন্য উপস্থিত থাকে তাকে শর্তসাপেক্ষ হাইপারপ্যারামিটার বলা হয়। অনুমান করবেন না দুটি শর্তসাপেক্ষ হাইপারপ্যারামিটার একই কারণ তাদের একই নাম রয়েছে! পূর্ববর্তী উদাহরণে, learning_rate নামক শর্তসাপেক্ষ হাইপারপ্যারামিটারটি optimizer="Nesterov_momentum" জন্য optimizer="Adam" এর চেয়ে আলাদা হাইপারপ্যারামিটার। দুটি অ্যালগরিদমে এর ভূমিকা একই রকম (যদিও অভিন্ন নয়), তবে প্রতিটি অপ্টিমাইজারে ভালভাবে কাজ করে এমন মানগুলির পরিসর সাধারণত বিভিন্ন মাত্রার ক্রম অনুসারে আলাদা।
অধ্যয়নের একটি সেট তৈরি করুন
বৈজ্ঞানিক এবং উপদ্রব হাইপারপ্যারামিটারগুলি সনাক্ত করার পরে, পরীক্ষামূলক লক্ষ্যের দিকে অগ্রগতি করার জন্য আপনার একটি অধ্যয়ন বা অধ্যয়নের ক্রম ডিজাইন করা উচিত। একটি গবেষণা পরবর্তী বিশ্লেষণের জন্য চালানোর জন্য হাইপারপ্যারামিটার কনফিগারেশনের একটি সেট নির্দিষ্ট করে। প্রতিটি কনফিগারেশনকে ট্রায়াল বলা হয়। একটি অধ্যয়ন তৈরি করতে সাধারণত নিম্নলিখিতগুলি বেছে নেওয়া হয়:
- ট্রায়াল জুড়ে পরিবর্তিত হাইপারপ্যারামিটার।
- এই হাইপারপ্যারামিটারগুলি যে মানগুলি নিতে পারে ( অনুসন্ধান স্থান )।
- ট্রায়াল সংখ্যা.
- একটি স্বয়ংক্রিয় অনুসন্ধান অ্যালগরিদম নমুনা যা অনুসন্ধান স্থান থেকে অনেক ট্রায়াল.
বিকল্পভাবে, আপনি ম্যানুয়ালি হাইপারপ্যারামিটার কনফিগারেশনের সেট উল্লেখ করে একটি অধ্যয়ন তৈরি করতে পারেন।
অধ্যয়নের উদ্দেশ্য একই সাথে:
- বৈজ্ঞানিক হাইপারপ্যারামিটারের বিভিন্ন মান দিয়ে পাইপলাইন চালান।
- উপদ্রব হাইপারপ্যারামিটারগুলিকে "অপ্টিমাইজ করা" (বা "অপ্টিমাইজ করা") যাতে বৈজ্ঞানিক হাইপারপ্যারামিটারের বিভিন্ন মানের মধ্যে তুলনা যতটা সম্ভব ন্যায্য হয়৷
সবচেয়ে সহজ ক্ষেত্রে, আপনি বৈজ্ঞানিক পরামিতিগুলির প্রতিটি কনফিগারেশনের জন্য একটি পৃথক অধ্যয়ন করবেন, যেখানে প্রতিটি অধ্যয়ন উপদ্রব হাইপারপ্যারামিটারগুলির উপর সুর করে। উদাহরণস্বরূপ, যদি আপনার লক্ষ্য হয় নেস্টেরভ মোমেন্টাম এবং অ্যাডাম থেকে সেরা অপ্টিমাইজার নির্বাচন করা, আপনি দুটি গবেষণা তৈরি করতে পারেন:
- একটি অধ্যয়ন যেখানে
optimizer="Nesterov_momentum"এবং উপদ্রব হাইপারপ্যারামিটারগুলি{learning_rate, momentum} - আরেকটি অধ্যয়ন যেখানে
optimizer="Adam"এবং উপদ্রব হাইপারপ্যারামিটারগুলি হল{learning_rate, beta1, beta2, epsilon}।
আপনি প্রতিটি অধ্যয়ন থেকে সেরা পারফর্মিং ট্রায়াল নির্বাচন করে দুটি অপ্টিমাইজারের তুলনা করবেন।
আপনি যেকোন গ্রেডিয়েন্ট-মুক্ত অপ্টিমাইজেশান অ্যালগরিদম ব্যবহার করতে পারেন, যার মধ্যে বায়েসিয়ান অপ্টিমাইজেশান বা বিবর্তনীয় অ্যালগরিদমের মতো পদ্ধতিগুলি সহ, উপদ্রব হাইপারপ্যারামিটারগুলিকে অপ্টিমাইজ করতে। যাইহোক, আমরা টিউনিংয়ের অন্বেষণ পর্বে আধা-এলোমেলো অনুসন্ধান ব্যবহার করতে পছন্দ করি কারণ এই সেটিংটিতে এটির বিভিন্ন সুবিধা রয়েছে। অন্বেষণ শেষ হওয়ার পরে, আমরা অত্যাধুনিক বায়েসিয়ান অপ্টিমাইজেশান সফ্টওয়্যার ব্যবহার করার পরামর্শ দিই (যদি এটি উপলব্ধ থাকে)।
একটি আরও জটিল কেস বিবেচনা করুন যেখানে আপনি বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির একটি বড় সংখ্যার মান তুলনা করতে চান তবে এটি অনেকগুলি স্বাধীন অধ্যয়ন করা অবাস্তব। এই ক্ষেত্রে, আপনি নিম্নলিখিত করতে পারেন:
- উপদ্রব হাইপারপ্যারামিটারের মতো একই অনুসন্ধানের জায়গায় বৈজ্ঞানিক পরামিতিগুলি অন্তর্ভুক্ত করুন।
- একটি একক গবেষণায় বৈজ্ঞানিক এবং উপদ্রব হাইপারপ্যারামিটার উভয়ের নমুনা মানগুলির জন্য একটি অনুসন্ধান অ্যালগরিদম ব্যবহার করুন।
এই পদ্ধতি গ্রহণ করার সময়, শর্তাধীন হাইপারপ্যারামিটার সমস্যা সৃষ্টি করতে পারে। সর্বোপরি, বৈজ্ঞানিক হাইপারপ্যারামিটারের সমস্ত মানগুলির জন্য উপদ্রব হাইপারপ্যারামিটারের সেট একই না হলে একটি অনুসন্ধান স্থান নির্দিষ্ট করা কঠিন। এই ক্ষেত্রে, ফ্যান্সিয়ার ব্ল্যাক-বক্স অপ্টিমাইজেশান সরঞ্জামগুলির উপর আধা-এলোমেলো অনুসন্ধান ব্যবহার করার জন্য আমাদের পছন্দ আরও শক্তিশালী, কারণ এটি গ্যারান্টি দেয় যে বৈজ্ঞানিক হাইপারপ্যারামিটারের বিভিন্ন মান সমানভাবে নমুনা করা হবে। সার্চ অ্যালগরিদম যাই হোক না কেন, নিশ্চিত করুন যে এটি বৈজ্ঞানিক পরামিতিগুলি সমানভাবে অনুসন্ধান করে৷
তথ্যপূর্ণ এবং সাশ্রয়ী মূল্যের পরীক্ষার মধ্যে ভারসাম্য বজায় রাখুন
একটি অধ্যয়ন বা অধ্যয়নের ক্রম ডিজাইন করার সময়, পর্যাপ্তভাবে নিম্নলিখিত তিনটি লক্ষ্য অর্জনের জন্য একটি সীমিত বাজেট বরাদ্দ করুন:
- বৈজ্ঞানিক হাইপারপ্যারামিটারের পর্যাপ্ত বিভিন্ন মান তুলনা করা।
- যথেষ্ট বড় সার্চ স্পেসের উপর উপদ্রব হাইপারপ্যারামিটার টিউন করা।
- যথেষ্ট ঘনত্বে উপদ্রব হাইপারপ্যারামিটার অনুসন্ধান স্থান নমুনা.
আপনি এই তিনটি লক্ষ্য যত ভালোভাবে অর্জন করতে পারবেন, পরীক্ষা থেকে তত বেশি অন্তর্দৃষ্টি বের করতে পারবেন। যতটা সম্ভব বৈজ্ঞানিক হাইপারপ্যারামিটারের অনেকগুলি মান তুলনা করলে আপনি পরীক্ষা থেকে যে অন্তর্দৃষ্টিগুলি অর্জন করেন তার পরিধি আরও বিস্তৃত করে৷
যতটা সম্ভব উপদ্রব হাইপারপ্যারামিটার অন্তর্ভুক্ত করা এবং প্রতিটি উপদ্রব হাইপারপ্যারামিটারকে যতটা সম্ভব বিস্তৃত পরিসরে পরিবর্তিত হওয়ার অনুমতি দেওয়া আত্মবিশ্বাস বাড়ায় যে বৈজ্ঞানিক হাইপারপ্যারামিটারের প্রতিটি কনফিগারেশনের জন্য অনুসন্ধানের জায়গায় উপদ্রব হাইপারপ্যারামিটারের একটি "ভাল" মান বিদ্যমান। অন্যথায়, আপনি উপদ্রব হাইপারপ্যারামিটার স্থানের সম্ভাব্য অঞ্চলগুলি অনুসন্ধান না করে বৈজ্ঞানিক হাইপারপ্যারামিটারের মানগুলির মধ্যে অন্যায্য তুলনা করতে পারেন যেখানে বৈজ্ঞানিক পরামিতিগুলির কিছু মানগুলির জন্য আরও ভাল মান থাকতে পারে।
যতটা সম্ভব ঘনভাবে উপদ্রব হাইপারপ্যারামিটারের অনুসন্ধানের স্থানের নমুনা নিন। এটি করার ফলে আত্মবিশ্বাস বাড়ে যে অনুসন্ধান পদ্ধতি আপনার অনুসন্ধানের জায়গায় বিদ্যমান উপদ্রব হাইপারপ্যারামিটারগুলির জন্য কোনও ভাল সেটিংস খুঁজে পাবে। অন্যথায়, আপনি বৈজ্ঞানিক পরামিতিগুলির মানগুলির মধ্যে অন্যায্য তুলনা করতে পারেন কারণ কিছু মানগুলি উপদ্রব হাইপারপ্যারামিটারের নমুনা নিয়ে সৌভাগ্যবান হয়৷
দুর্ভাগ্যবশত, এই তিনটি মাত্রার যে কোনো একটির উন্নতির জন্য নিম্নলিখিতগুলির যেকোনো একটির প্রয়োজন হয়:
- ট্রায়াল সংখ্যা বৃদ্ধি, এবং তাই সম্পদ খরচ বৃদ্ধি.
- অন্যান্য মাত্রার একটিতে সম্পদ সংরক্ষণ করার উপায় খুঁজে বের করা।
প্রতিটি সমস্যার নিজস্ব বৈশিষ্ট্য এবং গণনাগত সীমাবদ্ধতা রয়েছে, তাই এই তিনটি লক্ষ্য জুড়ে সংস্থান বরাদ্দ করার জন্য কিছু স্তরের ডোমেন জ্ঞান প্রয়োজন। একটি অধ্যয়ন চালানোর পরে, সর্বদা একটি ধারনা পাওয়ার চেষ্টা করুন যে অধ্যয়নটি উপদ্রব হাইপারপ্যারামিটারগুলিকে যথেষ্ট ভালভাবে টিউন করেছে কিনা। অর্থাৎ, অধ্যয়নটি বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির তুলনা করার জন্য যথেষ্ট পরিমাণে যথেষ্ট বৃহৎ স্থান অনুসন্ধান করেছে (যেমন পরবর্তী বিভাগে আরও বিশদে বর্ণনা করা হয়েছে)।
পরীক্ষামূলক ফলাফল থেকে শিখুন
প্রস্তাবনা: পরীক্ষার প্রতিটি গ্রুপের মূল বৈজ্ঞানিক লক্ষ্য অর্জনের চেষ্টা করার পাশাপাশি, অতিরিক্ত প্রশ্নের একটি চেকলিস্ট দিয়ে যান। আপনি যদি সমস্যাগুলি আবিষ্কার করেন তবে পরীক্ষাগুলি সংশোধন করুন এবং পুনরায় চালান৷
পরিশেষে, পরীক্ষার প্রতিটি গ্রুপের একটি নির্দিষ্ট লক্ষ্য থাকে। পরীক্ষাগুলি সেই লক্ষ্যের দিকে যে প্রমাণগুলি সরবরাহ করে তা আপনার মূল্যায়ন করা উচিত। যাইহোক, যদি আপনি সঠিক প্রশ্ন জিজ্ঞাসা করেন, তাহলে পরীক্ষাগুলির একটি নির্দিষ্ট সেট তাদের আসল লক্ষ্যের দিকে অগ্রসর হওয়ার আগে আপনি প্রায়শই সংশোধন করার জন্য সমস্যাগুলি খুঁজে পেতে পারেন। আপনি যদি এই প্রশ্নগুলি না করেন তবে আপনি ভুল সিদ্ধান্তে আঁকতে পারেন।
যেহেতু চলমান পরীক্ষাগুলি ব্যয়বহুল হতে পারে, তাই আপনাকে পরীক্ষাগুলির প্রতিটি গ্রুপ থেকে অন্যান্য দরকারী অন্তর্দৃষ্টিগুলিও বের করা উচিত, এমনকি যদি এই অন্তর্দৃষ্টিগুলি বর্তমান লক্ষ্যের সাথে অবিলম্বে প্রাসঙ্গিক না হয়।
তাদের আসল লক্ষ্যের দিকে অগ্রগতি করার জন্য প্রদত্ত পরীক্ষার সেট বিশ্লেষণ করার আগে, নিজেকে নিম্নলিখিত অতিরিক্ত প্রশ্নগুলি জিজ্ঞাসা করুন:
- অনুসন্ধান স্থান যথেষ্ট বড়? যদি একটি অধ্যয়নের সর্বোত্তম বিন্দুটি এক বা একাধিক মাত্রায় অনুসন্ধানের স্থানের সীমানার কাছাকাছি হয় তবে অনুসন্ধানটি সম্ভবত যথেষ্ট প্রশস্ত নয়। এই ক্ষেত্রে, একটি প্রসারিত অনুসন্ধান স্থান সহ অন্য গবেষণা চালান।
- আপনি অনুসন্ধান স্থান থেকে যথেষ্ট পয়েন্ট নমুনা আছে? যদি না হয়, আরও পয়েন্ট চালান বা টিউনিং লক্ষ্যে কম উচ্চাভিলাষী হন।
- প্রতিটি গবেষণায় পরীক্ষার কোন ভগ্নাংশ অসম্ভাব্য? অর্থাৎ, কোন ট্রায়ালগুলি বিচ্ছিন্ন হয়ে যায়, সত্যিই খারাপ ক্ষতির মানগুলি পায়, বা তারা কিছু অন্তর্নিহিত সীমাবদ্ধতা লঙ্ঘন করার কারণে মোটেও চালাতে ব্যর্থ হয়? যখন একটি গবেষণায় পয়েন্টগুলির একটি খুব বড় ভগ্নাংশ অসম্ভাব্য হয়, তখন এই ধরনের পয়েন্টের নমুনা এড়াতে অনুসন্ধানের স্থানটি সামঞ্জস্য করুন, যার জন্য কখনও কখনও অনুসন্ধানের স্থান পুনরায় পরিমাপ করা প্রয়োজন। কিছু ক্ষেত্রে, প্রচুর সংখ্যক অসম্ভাব্য পয়েন্ট প্রশিক্ষণ কোডে একটি বাগ নির্দেশ করতে পারে।
- মডেল অপ্টিমাইজেশান সমস্যা প্রদর্শন করে?
- আপনি সেরা পরীক্ষার প্রশিক্ষণ বক্ররেখা থেকে কি শিখতে পারেন? উদাহরণস্বরূপ, সেরা পরীক্ষায় কি সমস্যাযুক্ত ওভারফিটিং এর সাথে সামঞ্জস্যপূর্ণ প্রশিক্ষণ বক্ররেখা আছে?
প্রয়োজনে, পূর্ববর্তী প্রশ্নের উত্তরগুলির উপর ভিত্তি করে, অনুসন্ধানের স্থান এবং/অথবা আরও পরীক্ষার নমুনা উন্নত করতে সাম্প্রতিকতম অধ্যয়ন বা অধ্যয়নের গ্রুপকে পরিমার্জন করুন, বা অন্য কিছু সংশোধনমূলক পদক্ষেপ নিন।
একবার আপনি পূর্ববর্তী প্রশ্নগুলির উত্তর দেওয়ার পরে, আপনি আপনার আসল লক্ষ্যের দিকে পরীক্ষাগুলি যে প্রমাণগুলি প্রদান করে তা মূল্যায়ন করতে পারেন; উদাহরণস্বরূপ, একটি পরিবর্তন দরকারী কিনা তা মূল্যায়ন করা ।
খারাপ অনুসন্ধান স্থান সীমানা চিহ্নিত করুন
একটি অনুসন্ধান স্থান সন্দেহজনক যদি এটি থেকে নমুনাকৃত সেরা বিন্দুটি তার সীমানার কাছাকাছি হয়। আপনি যদি সেই দিকে অনুসন্ধানের পরিসর প্রসারিত করেন তবে আপনি আরও ভাল পয়েন্ট খুঁজে পেতে পারেন।
অনুসন্ধান স্থান সীমানা পরীক্ষা করতে, আমরা মৌলিক হাইপারপ্যারামিটার অক্ষ প্লট যাকে বলি তার উপর সম্পন্ন ট্রায়াল প্লট করার সুপারিশ করি। এর মধ্যে, আমরা হাইপারপ্যারামিটারগুলির একটি (উদাহরণস্বরূপ, শেখার হার) বনাম বৈধকরণের উদ্দেশ্য প্লট করি। প্লটের প্রতিটি পয়েন্ট একটি একক বিচারের সাথে মিলে যায়।
প্রতিটি ট্রায়ালের জন্য বৈধকরণ উদ্দেশ্য মান সাধারণত প্রশিক্ষণের সময় এটি অর্জন করা সর্বোত্তম মান হওয়া উচিত।
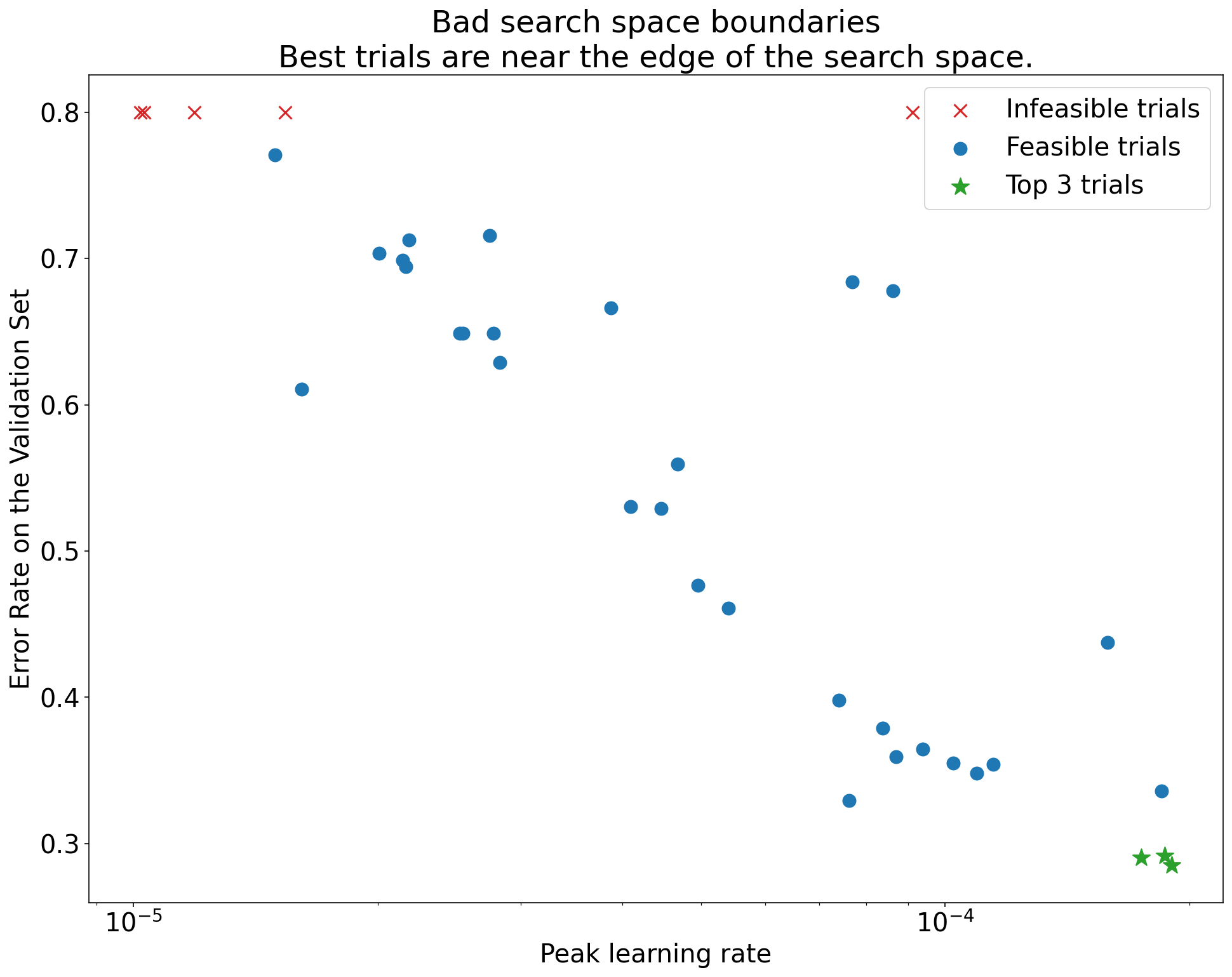
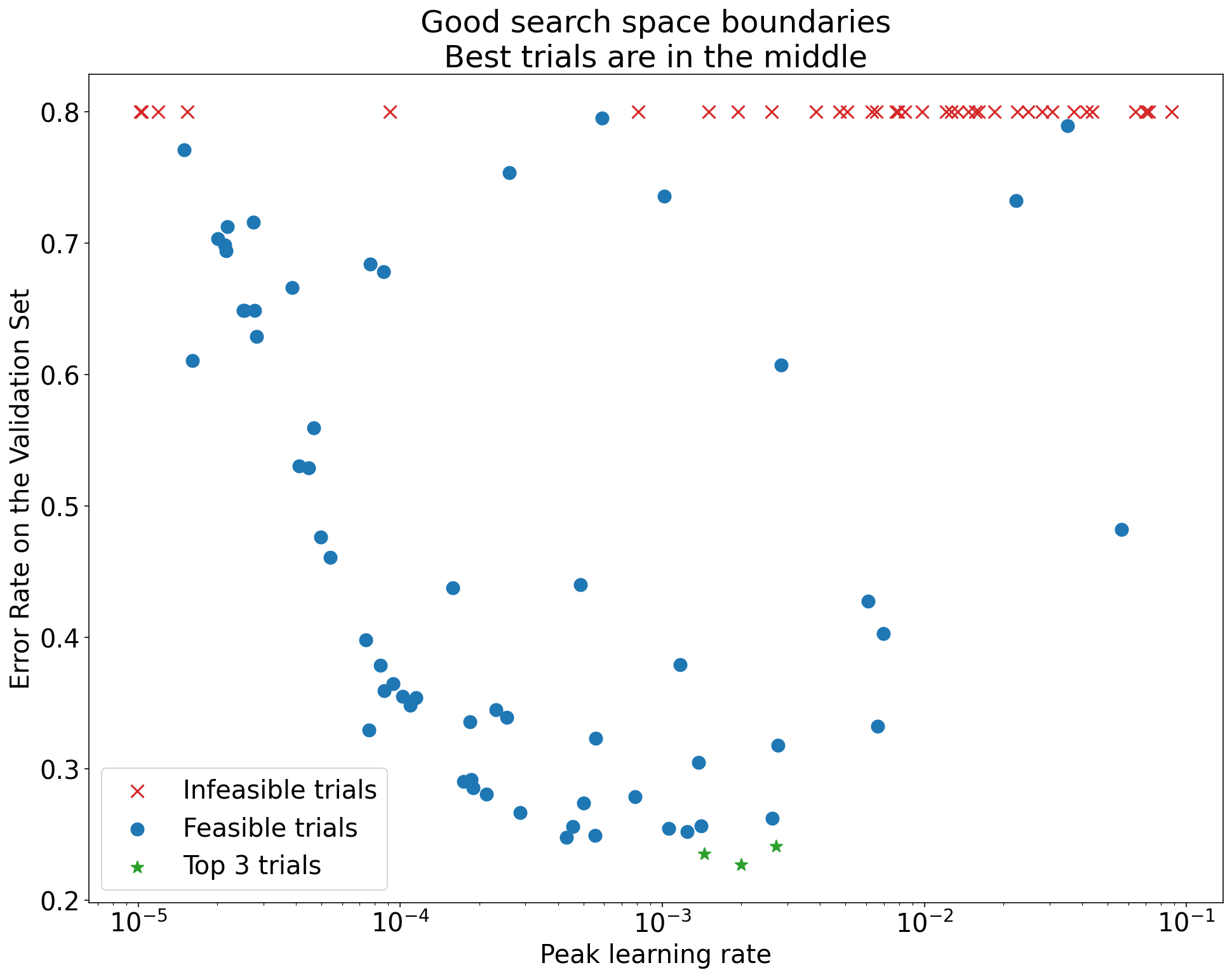
চিত্র 1: খারাপ অনুসন্ধান স্থান সীমানা এবং গ্রহণযোগ্য অনুসন্ধান স্থান সীমানার উদাহরণ।
চিত্র 1-এর প্লটগুলি প্রাথমিক শিক্ষার হারের বিপরীতে ত্রুটির হার (নিম্ন ভাল) দেখায়। যদি সেরা পয়েন্টগুলি একটি অনুসন্ধান স্থানের প্রান্তের দিকে ক্লাস্টার হয় (কিছু মাত্রায়), তাহলে আপনাকে অনুসন্ধান স্থানের সীমানা প্রসারিত করতে হতে পারে যতক্ষণ না সেরা পর্যবেক্ষণ করা বিন্দুটি আর সীমানার কাছাকাছি না হয়।
প্রায়শই, একটি গবেষণায় "অসম্ভাব্য" ট্রায়ালগুলি অন্তর্ভুক্ত থাকে যা বিচ্ছিন্ন হয় বা খুব খারাপ ফলাফল পায় (চিত্র 1-এ লাল Xs দ্বারা চিহ্নিত)। যদি সমস্ত ট্রায়াল কিছু থ্রেশহোল্ড মানের চেয়ে বেশি শেখার হারের জন্য অসম্ভাব্য হয়, এবং যদি সেরা পারফর্মিং ট্রায়ালগুলির সেই অঞ্চলের প্রান্তে শেখার হার থাকে, তাহলে মডেলটি উচ্চ শিক্ষার হার অ্যাক্সেস করতে বাধা দেওয়ার জন্য স্থিতিশীলতার সমস্যায় ভুগতে পারে ।
অনুসন্ধানের জায়গায় পর্যাপ্ত পয়েন্টের নমুনা নেই
সাধারণভাবে, অনুসন্ধানের স্থানটি যথেষ্ট ঘনত্বে নমুনা করা হয়েছে কিনা তা জানা খুব কঠিন হতে পারে । 🤖 কম ট্রায়াল চালানোর চেয়ে বেশি ট্রায়াল চালানো ভালো, কিন্তু বেশি ট্রায়াল একটি সুস্পষ্ট অতিরিক্ত খরচ তৈরি করে।
যেহেতু আপনি যথেষ্ট নমুনা করেছেন তা জানা খুব কঠিন, তাই আমরা সুপারিশ করি:
- আপনি সামর্থ্য কি নমুনা.
- বারবার বিভিন্ন হাইপারপ্যারামিটার অক্ষ প্লটের দিকে তাকানোর থেকে আপনার স্বজ্ঞাত আত্মবিশ্বাসকে ক্যালিব্রেট করা এবং অনুসন্ধানের স্থানের "ভাল" অঞ্চলে কতগুলি পয়েন্ট রয়েছে তা বোঝার চেষ্টা করা।
প্রশিক্ষণ বক্ররেখা পরীক্ষা
সারাংশ: ক্ষতির বক্ররেখাগুলি পরীক্ষা করা সাধারণ ব্যর্থতার মোডগুলি সনাক্ত করার একটি সহজ উপায় এবং এটি আপনাকে সম্ভাব্য পরবর্তী ক্রিয়াগুলিকে অগ্রাধিকার দিতে সহায়তা করতে পারে।
অনেক ক্ষেত্রে, আপনার পরীক্ষার প্রাথমিক উদ্দেশ্য শুধুমাত্র প্রতিটি ট্রায়ালের বৈধতা ত্রুটি বিবেচনা করা প্রয়োজন। যাইহোক, প্রতিটি ট্রায়ালকে একক সংখ্যায় হ্রাস করার সময় সতর্কতা অবলম্বন করুন কারণ সেই ফোকাসটি পৃষ্ঠের নীচে কী ঘটছে সে সম্পর্কে গুরুত্বপূর্ণ বিবরণ লুকিয়ে রাখতে পারে। প্রতিটি অধ্যয়নের জন্য, আমরা দৃঢ়ভাবে অন্তত সেরা কয়েকটি পরীক্ষার ক্ষতির বক্ররেখা দেখার পরামর্শ দিই। প্রাথমিক পরীক্ষামূলক উদ্দেশ্য পূরণের জন্য এটি প্রয়োজনীয় না হলেও, ক্ষতির বক্ররেখাগুলি পরীক্ষা করা (প্রশিক্ষণের ক্ষতি এবং বৈধতা ক্ষতি উভয়ই সহ) সাধারণ ব্যর্থতার মোডগুলি সনাক্ত করার একটি ভাল উপায় এবং পরবর্তীতে কী পদক্ষেপ নিতে হবে তা অগ্রাধিকার দিতে সহায়তা করতে পারে।
ক্ষতির বক্ররেখা পরীক্ষা করার সময়, নিম্নলিখিত প্রশ্নগুলিতে ফোকাস করুন:
কোন ট্রায়াল কি সমস্যাযুক্ত ওভারফিটিং প্রদর্শন করছে? প্রশিক্ষণের সময় যখন বৈধতা ত্রুটি বাড়তে থাকে তখন সমস্যাযুক্ত ওভারফিটিং ঘটে। পরীক্ষামূলক সেটিংসে যেখানে আপনি বৈজ্ঞানিক হাইপারপ্যারামিটারের প্রতিটি সেটিংসের জন্য "সেরা" ট্রায়াল নির্বাচন করে উপদ্রব হাইপারপ্যারামিটারগুলিকে অপ্টিমাইজ করেন, আপনি তুলনা করছেন এমন বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির সেটিংসের সাথে সম্পর্কিত অন্তত প্রতিটি সেরা পরীক্ষায় সমস্যাযুক্ত ওভারফিটিং পরীক্ষা করুন৷ যদি সেরা ট্রায়ালগুলির মধ্যে কোনটি সমস্যাযুক্ত ওভারফিটিং প্রদর্শন করে তবে নিম্নলিখিতগুলির মধ্যে একটি বা উভয়টি করুন:
- অতিরিক্ত নিয়মিতকরণ কৌশল সহ পরীক্ষাটি পুনরায় চালান
- বৈজ্ঞানিক হাইপারপ্যারামিটারের মানগুলির তুলনা করার আগে বিদ্যমান নিয়মিতকরণের পরামিতিগুলিকে পুনরুদ্ধার করুন। এটি প্রযোজ্য নাও হতে পারে যদি বৈজ্ঞানিক হাইপারপ্যারামিটারগুলিতে নিয়মিতকরণের পরামিতিগুলি অন্তর্ভুক্ত থাকে, তারপর থেকে যদি সেই নিয়মিতকরণের পরামিতিগুলির কম-শক্তির সেটিংস সমস্যাযুক্ত ওভারফিটিং এর ফলে এটি আশ্চর্যজনক হবে না।
ওভারফিটিং হ্রাস করা প্রায়শই সাধারণ নিয়মিতকরণ কৌশল ব্যবহার করে সোজা হয় যা ন্যূনতম কোড জটিলতা বা অতিরিক্ত গণনা যোগ করে (উদাহরণস্বরূপ, ড্রপআউট নিয়মিতকরণ, লেবেল স্মুথিং, ওজন ক্ষয়)। অতএব, পরের রাউন্ডের পরীক্ষায় এর মধ্যে এক বা একাধিক যোগ করা সাধারণত তুচ্ছ। উদাহরণস্বরূপ, যদি বৈজ্ঞানিক হাইপারপ্যারামিটার হয় "লুকানো স্তরের সংখ্যা" এবং সবচেয়ে বেশি সংখ্যক লুকানো স্তর ব্যবহার করে এমন সেরা ট্রায়াল সমস্যাযুক্ত ওভারফিটিং প্রদর্শন করে, তাহলে আমরা অবিলম্বে লুকানো স্তরগুলির ছোট সংখ্যক নির্বাচন না করে অতিরিক্ত নিয়মিতকরণের সাথে পুনরায় চেষ্টা করার পরামর্শ দিই।
এমনকি যদি "সেরা" ট্রায়ালগুলির মধ্যে কোনোটিই সমস্যাযুক্ত ওভারফিটিং প্রদর্শন না করে, তবুও কোনো সমস্যা হতে পারে যদি এটি কোনো ট্রায়ালে ঘটে থাকে। সেরা ট্রায়াল নির্বাচন সমস্যাযুক্ত ওভারফিটিং প্রদর্শনকারী কনফিগারেশনগুলিকে দমন করে এবং যেগুলি করে না তাদের পক্ষে। অন্য কথায়, সেরা ট্রায়াল নির্বাচন করা আরও নিয়মিতকরণের সাথে কনফিগারেশনের পক্ষে। যাইহোক, যেকোন কিছু যা প্রশিক্ষণকে আরও খারাপ করে তোলে তা নিয়মিতকারী হিসাবে কাজ করতে পারে, এমনকি যদি এটি সেভাবে উদ্দেশ্য না হয়। উদাহরণস্বরূপ, একটি ছোট শেখার হার বেছে নেওয়া অপ্টিমাইজেশন প্রক্রিয়াকে বাধা দিয়ে প্রশিক্ষণকে নিয়মিত করতে পারে, কিন্তু আমরা সাধারণত এইভাবে শেখার হার বেছে নিতে চাই না। মনে রাখবেন যে বৈজ্ঞানিক হাইপারপ্যারামিটারের প্রতিটি সেটিংয়ের জন্য "সেরা" ট্রায়াল এমনভাবে নির্বাচিত হতে পারে যা কিছু বৈজ্ঞানিক বা উপদ্রব হাইপারপ্যারামিটারের "খারাপ" মানকে সমর্থন করে।
প্রশিক্ষণে কি উচ্চ ধাপে ধাপে ভিন্নতা আছে বা প্রশিক্ষণের দেরিতে বৈধতা ত্রুটি আছে? যদি তাই হয়, এটি নিম্নলিখিত উভয়ের সাথে হস্তক্ষেপ করতে পারে:
- বৈজ্ঞানিক হাইপারপ্যারামিটারের বিভিন্ন মান তুলনা করার আপনার ক্ষমতা। কারণ প্রতিটি ট্রায়াল এলোমেলোভাবে একটি "ভাগ্যবান" বা "দুর্ভাগ্য" ধাপে শেষ হয়।
- উত্পাদনে সেরা পরীক্ষার ফলাফল পুনরুত্পাদন করার আপনার ক্ষমতা। কারণ অধ্যয়নের মতো একই "ভাগ্যবান" পদক্ষেপে উত্পাদন মডেলটি শেষ নাও হতে পারে।
ধাপে ধাপে ভিন্নতার সবচেয়ে সম্ভাব্য কারণগুলি হল:
- প্রতিটি ব্যাচের জন্য প্রশিক্ষণ সেট থেকে এলোমেলোভাবে নমুনা উদাহরণের কারণে ব্যাচের ভিন্নতা।
- ছোট বৈধতা সেট
- একটি শেখার হার ব্যবহার করা যা প্রশিক্ষণে খুব বেশি দেরি করে।
সম্ভাব্য প্রতিকার অন্তর্ভুক্ত:
- ব্যাচ আকার বৃদ্ধি.
- আরো বৈধতা তথ্য প্রাপ্তি.
- শেখার হার ক্ষয় ব্যবহার করে.
- Polyak গড় ব্যবহার করে।
প্রশিক্ষণ শেষে পরীক্ষাগুলি কি এখনও উন্নতি করছে? যদি তাই হয়, আপনি "কম্পিউট বাউন্ড" পদ্ধতিতে আছেন এবং প্রশিক্ষণের ধাপের সংখ্যা বাড়ানো বা শেখার হারের সময়সূচী পরিবর্তন করে উপকৃত হতে পারেন।
চূড়ান্ত প্রশিক্ষণ ধাপের অনেক আগে প্রশিক্ষণ এবং বৈধতা সেটের কর্মক্ষমতা কি পরিপূর্ণ হয়েছে? যদি তাই হয়, তাহলে এটি ইঙ্গিত দেয় যে আপনি "গণনা-আবদ্ধ নয়" শাসনে আছেন এবং আপনি প্রশিক্ষণের ধাপের সংখ্যা কমাতে সক্ষম হতে পারেন।
এই তালিকার বাইরে, ক্ষতির বক্ররেখা পরীক্ষা করে অনেক অতিরিক্ত আচরণ স্পষ্ট হতে পারে। উদাহরণস্বরূপ, প্রশিক্ষণের সময় প্রশিক্ষণের ক্ষতি বৃদ্ধি সাধারণত প্রশিক্ষণ পাইপলাইনে একটি বাগ নির্দেশ করে।
আইসোলেশন প্লটগুলির সাথে একটি পরিবর্তন কার্যকর কিনা তা সনাক্ত করা
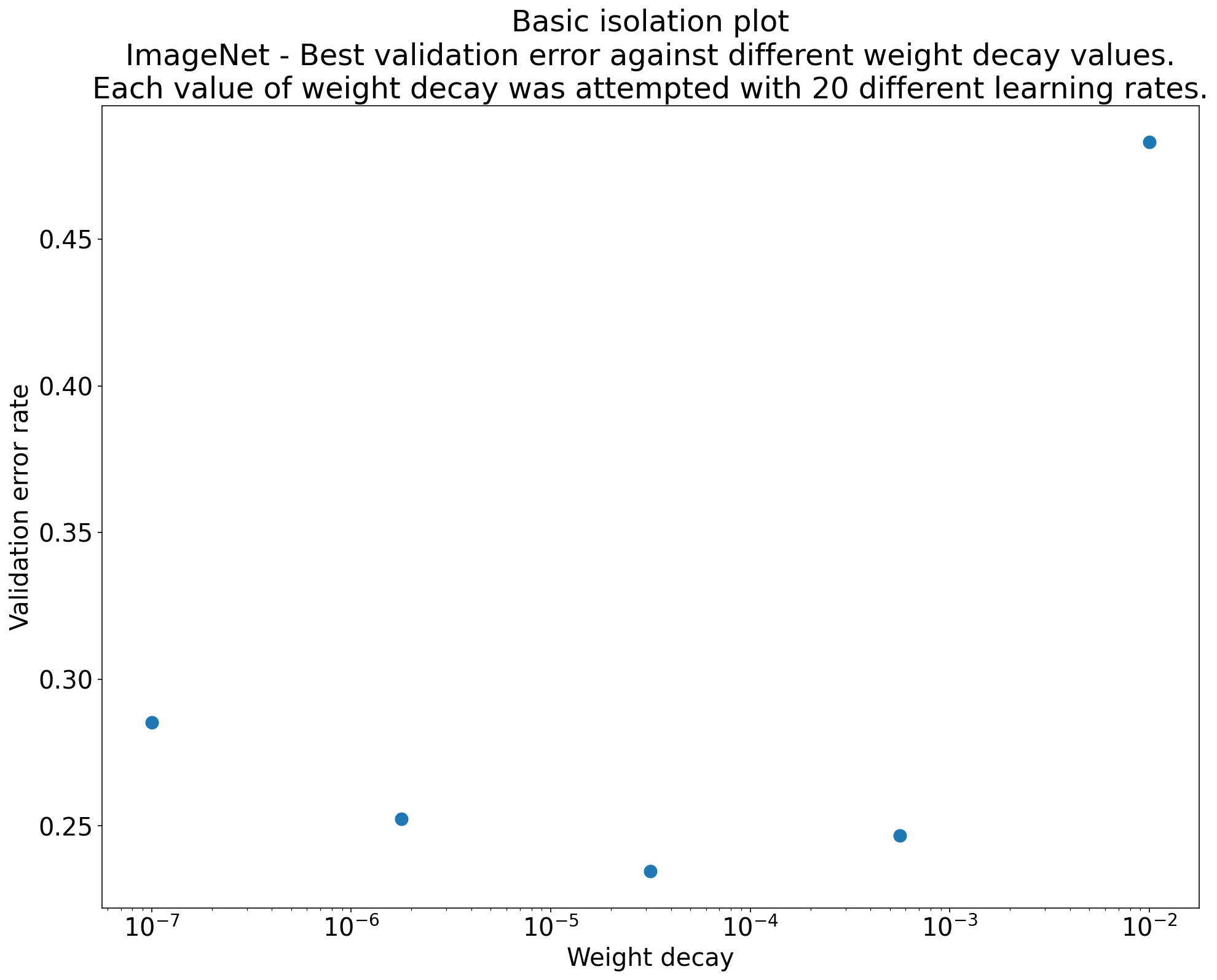
চিত্র 2: আইসোলেশন প্লট যা ইমেজনেটে প্রশিক্ষিত ResNet-50-এর জন্য ওজন ক্ষয়ের সর্বোত্তম মূল্যের তদন্ত করে।
প্রায়শই, পরীক্ষার একটি সেটের লক্ষ্য একটি বৈজ্ঞানিক হাইপারপ্যারামিটারের বিভিন্ন মান তুলনা করা হয়। উদাহরণ স্বরূপ, ধরুন আপনি ওজন ক্ষয়ের মান নির্ধারণ করতে চান যার ফলস্বরূপ সর্বোত্তম বৈধতা ত্রুটি দেখা দেয়। একটি বিচ্ছিন্নতা প্লট মৌলিক হাইপারপ্যারামিটার অক্ষ প্লটের একটি বিশেষ ক্ষেত্রে। একটি বিচ্ছিন্নতা প্লটের প্রতিটি পয়েন্ট উপদ্রব হাইপারপ্যারামিটারের কিছু (বা সমস্ত) জুড়ে সর্বোত্তম ট্রায়ালের পারফরম্যান্সের সাথে মিলে যায়। অন্য কথায়, উপদ্রব হাইপারপ্যারামিটারগুলিকে "অপ্টিমাইজ করার" পরে মডেলের কার্যকারিতা প্লট করুন।
একটি বিচ্ছিন্নতা প্লট বৈজ্ঞানিক হাইপারপ্যারামিটারের বিভিন্ন মানের মধ্যে আপেল-থেকে-আপেল তুলনা সম্পাদন করা সহজ করে। উদাহরণস্বরূপ, চিত্র 2-এর বিচ্ছিন্নতা প্লট ওজন ক্ষয়ের মান প্রকাশ করে যা ImageNet-এ প্রশিক্ষিত ResNet-50-এর একটি নির্দিষ্ট কনফিগারেশনের জন্য সর্বোত্তম বৈধতা কর্মক্ষমতা তৈরি করে।
ওজন ক্ষয়কে আদৌ অন্তর্ভুক্ত করতে হবে কিনা তা নির্ধারণ করা যদি লক্ষ্য হয়, তাহলে এই প্লট থেকে সেরা পয়েন্টটিকে তুলনা করুন ওজন ক্ষয় না হওয়ার বেসলাইনের সাথে। একটি ন্যায্য তুলনার জন্য, বেসলাইনে এর শেখার হারও সমানভাবে ভালভাবে টিউন করা উচিত।
আপনি যখন (অর্ধ) র্যান্ডম অনুসন্ধানের দ্বারা ডেটা তৈরি করেন এবং একটি বিচ্ছিন্ন প্লটের জন্য একটি ক্রমাগত হাইপারপ্যারামিটার বিবেচনা করছেন, তখন আপনি মৌলিক হাইপারপ্যারামিটার অক্ষ প্লটের x-অক্ষের মানগুলিকে বাকেটিং করে এবং প্রতিটি উল্লম্ব স্লাইসে সেরা ট্রায়াল নেওয়ার মাধ্যমে বিচ্ছিন্ন প্লটটি আনুমানিক করতে পারেন। বালতি দ্বারা সংজ্ঞায়িত।
সাধারণভাবে দরকারী প্লটগুলি স্বয়ংক্রিয় করুন
প্লট তৈরি করার জন্য যত বেশি প্রচেষ্টা করা হবে, আপনার যতটা উচিত ততটা সেগুলি দেখার সম্ভাবনা কম। অতএব, আমরা যতটা সম্ভব স্বয়ংক্রিয়ভাবে যতগুলি প্লট তৈরি করতে আপনার পরিকাঠামো সেট আপ করার পরামর্শ দিই৷ ন্যূনতম, আমরা সুপারিশ করি যে আপনি পরীক্ষায় পরিবর্তিত সমস্ত হাইপারপ্যারামিটারের জন্য স্বয়ংক্রিয়ভাবে মৌলিক হাইপারপ্যারামিটার অক্ষ প্লট তৈরি করুন৷
উপরন্তু, আমরা সমস্ত ট্রায়ালের জন্য স্বয়ংক্রিয়ভাবে ক্ষতি বক্ররেখা তৈরি করার পরামর্শ দিই। তদ্ব্যতীত, আমরা প্রতিটি অধ্যয়নের সেরা কয়েকটি পরীক্ষা খুঁজে বের করা এবং তাদের ক্ষতির বক্ররেখা পরীক্ষা করা যতটা সম্ভব সহজ করার পরামর্শ দিই।
আপনি অন্যান্য অনেক দরকারী সম্ভাব্য প্লট এবং ভিজ্যুয়ালাইজেশন যোগ করতে পারেন। জিওফ্রে হিন্টনকে ব্যাখ্যা করতে:
প্রতিবার আপনি নতুন কিছু করার পরিকল্পনা করেন, আপনি নতুন কিছু শিখেন।
প্রার্থী পরিবর্তনকে গ্রহণ করবেন কিনা তা নির্ধারণ করুন
সারাংশ: আমাদের মডেল বা প্রশিক্ষণ পদ্ধতিতে পরিবর্তন করতে বা একটি নতুন হাইপারপ্যারামিটার কনফিগারেশন গ্রহণ করার সিদ্ধান্ত নেওয়ার সময়, আপনার ফলাফলের ভিন্নতার বিভিন্ন উত্স নোট করুন।
কোনও মডেলকে উন্নত করার চেষ্টা করার সময়, কোনও নির্দিষ্ট প্রার্থী পরিবর্তন প্রাথমিকভাবে কোনও আগত কনফিগারেশনের তুলনায় আরও ভাল বৈধতা ত্রুটি অর্জন করতে পারে। যাইহোক, পরীক্ষার পুনরাবৃত্তি কোনও ধারাবাহিক সুবিধা প্রদর্শন করতে পারে না। অনানুষ্ঠানিকভাবে, বেমানান ফলাফলগুলির সর্বাধিক গুরুত্বপূর্ণ উত্সগুলি নিম্নলিখিত বিস্তৃত বিভাগগুলিতে বিভক্ত করা যেতে পারে:
- প্রশিক্ষণ পদ্ধতির বৈকল্পিকতা, পুনরায়চক্রের বৈকল্পিক বা পরীক্ষার বৈকল্পিক : প্রশিক্ষণের মধ্যে প্রকরণটি একই হাইপারপ্যারামিটারগুলি ব্যবহার করে তবে বিভিন্ন এলোমেলো বীজ ব্যবহার করে। উদাহরণস্বরূপ, বিভিন্ন এলোমেলো প্রাথমিককরণ, প্রশিক্ষণের ডেটা শ্যাফলস, ড্রপআউট মাস্কস, ডেটা বৃদ্ধির ক্রিয়াকলাপগুলির নিদর্শন এবং সমান্তরাল গাণিতিক ক্রিয়াকলাপগুলির ক্রমগুলি পরীক্ষার বৈচিত্র্যের সম্ভাব্য উত্স।
- হাইপারপ্যারামিটার অনুসন্ধানের বৈকল্পিকতা, বা অধ্যয়নের বৈকল্পিকতা : হাইপারপ্যারামিটারগুলি নির্বাচন করার জন্য আমাদের পদ্ধতির ফলে সৃষ্ট ফলাফলের প্রকরণ। উদাহরণস্বরূপ, আপনি একটি নির্দিষ্ট অনুসন্ধানের জায়গার সাথে একই পরীক্ষাটি চালাতে পারেন তবে কোয়াশি-এলোমেলো অনুসন্ধানের জন্য দুটি পৃথক বীজের সাথে এবং বিভিন্ন হাইপারপ্যারামিটার মান নির্বাচন করে শেষ করতে পারেন।
- ডেটা সংগ্রহ এবং স্যাম্পলিং বৈকল্পিকতা : প্রশিক্ষণ, বৈধতা এবং পরীক্ষার ডেটা বা বৈকল্পিকগুলিতে যে কোনও ধরণের এলোমেলো থেকে বিভক্ত হয়ে যায় প্রশিক্ষণ ডেটা উত্পাদন প্রক্রিয়াটির কারণে আরও সাধারণভাবে।
সত্য, আপনি Fastidious পরিসংখ্যান পরীক্ষা ব্যবহার করে সীমাবদ্ধ বৈধতা সেট উপর অনুমান করা বৈধতা ত্রুটির হারের তুলনা করতে পারেন। যাইহোক, প্রায়শই পরীক্ষার বৈকল্পিকতা একই হাইপারপ্যারামিটার সেটিংস ব্যবহার করে এমন দুটি পৃথক প্রশিক্ষিত মডেলের মধ্যে পরিসংখ্যানগতভাবে উল্লেখযোগ্য পার্থক্য তৈরি করতে পারে।
হাইপারপ্যারামিটার স্পেসে পৃথক পয়েন্টের স্তর ছাড়িয়ে যাওয়া সিদ্ধান্তগুলি তৈরি করার চেষ্টা করার সময় আমরা অধ্যয়নের বৈকল্পিকতা সম্পর্কে সবচেয়ে বেশি উদ্বিগ্ন। অধ্যয়নের বৈকল্পিকতা পরীক্ষার সংখ্যা এবং অনুসন্ধানের জায়গার উপর নির্ভর করে। আমরা এমন কেসগুলি দেখেছি যেখানে অধ্যয়নের বৈকল্পিকতা পরীক্ষার বৈকল্পিকের চেয়ে বড় এবং যেখানে এটি অনেক ছোট। অতএব, প্রার্থী পরিবর্তন গ্রহণের আগে, রান-টু-রান ট্রায়াল বৈকল্পিককে চিহ্নিত করার জন্য সেরা ট্রায়াল এন বার চালানোর বিষয়টি বিবেচনা করুন। সাধারণত, আপনি পাইপলাইনে বড় পরিবর্তনগুলির পরে কেবল পরীক্ষার বৈকল্পিকটি রিচারাকটারাইজ করে দূরে সরে যেতে পারেন, তবে কিছু ক্ষেত্রে আপনার আরও নতুন অনুমানের প্রয়োজন হতে পারে। অন্যান্য অ্যাপ্লিকেশনগুলিতে, পরীক্ষার বৈকল্পিককে চিহ্নিত করা খুব বেশি ব্যয়বহুল।
যদিও আপনি কেবল পরিবর্তনগুলি গ্রহণ করতে চান (নতুন হাইপারপ্যারামিটার কনফিগারেশন সহ) যা প্রকৃত উন্নতি উত্পাদন করে, সম্পূর্ণ নিশ্চিততার দাবি করে যে প্রদত্ত পরিবর্তনটি সঠিক উত্তর নয়। অতএব, যদি কোনও নতুন হাইপারপ্যারামিটার পয়েন্ট (বা অন্যান্য পরিবর্তন) বেসলাইনটির চেয়ে আরও ভাল ফলাফল পায় (নতুন পয়েন্ট এবং বেসলাইন উভয়ের পুনঃপ্রেরণকে বিবেচনা করে আপনি যথাসম্ভব সেরা), তবে আপনার সম্ভবত এটি নতুন হিসাবে গ্রহণ করা উচিত ভবিষ্যতের তুলনার জন্য বেসলাইন। যাইহোক, আমরা কেবলমাত্র এমন পরিবর্তনগুলি গ্রহণ করার পরামর্শ দিই যা তাদের যুক্ত কোনও জটিলতা ছাড়িয়ে যায় এমন উন্নতিগুলি উত্পাদন করে।
অনুসন্ধানের পরে শেষ হয়
সংক্ষিপ্তসার: বায়েসিয়ান অপ্টিমাইজেশন সরঞ্জামগুলি একটি বাধ্যতামূলক বিকল্প যা একবার আপনি ভাল অনুসন্ধানের জায়গাগুলির জন্য অনুসন্ধান করে শেষ করেন এবং হাইপারপ্যারামিটারগুলি কী সুর করার জন্য মূল্যবান তা স্থির করে নিয়েছেন।
অবশেষে, আপনার অগ্রাধিকারগুলি টিউনিং সমস্যা সম্পর্কে আরও শিখতে শুরু করে চালু বা অন্যথায় ব্যবহারের জন্য একক সেরা কনফিগারেশন উত্পাদন করতে। এই মুহুর্তে, একটি পরিশোধিত অনুসন্ধানের স্থান থাকা উচিত যা স্বাচ্ছন্দ্যে স্থানীয় অঞ্চলটি সর্বোত্তম পর্যবেক্ষণ পরীক্ষার আশেপাশে ধারণ করে এবং পর্যাপ্ত পরিমাণে নমুনা দেওয়া হয়েছে। আপনার অনুসন্ধানের কাজটি টিউন করার জন্য সর্বাধিক প্রয়োজনীয় হাইপারপ্যারামিটারগুলি এবং তাদের বুদ্ধিমান রেঞ্জগুলি প্রকাশ করা উচিত ছিল যা আপনি যতটা সম্ভব বৃহত টিউনিং বাজেট ব্যবহার করে একটি চূড়ান্ত স্বয়ংক্রিয় টিউনিং অধ্যয়নের জন্য অনুসন্ধানের স্থান তৈরি করতে ব্যবহার করতে পারেন।
যেহেতু আপনি আর টিউনিং সমস্যার অন্তর্দৃষ্টি সর্বাধিককরণের বিষয়ে যত্নশীল নন, তাই কোয়াশি-এলোমেলো অনুসন্ধানের অনেকগুলি সুবিধা আর প্রয়োগ হয় না। অতএব, সেরা হাইপারপ্যারামিটার কনফিগারেশনটি স্বয়ংক্রিয়ভাবে খুঁজে পেতে আপনার বায়েশিয়ান অপ্টিমাইজেশন সরঞ্জামগুলি ব্যবহার করা উচিত। ওপেন-সোর্স ভিজিয়ার বায়েশিয়ান অপ্টিমাইজেশন অ্যালগরিদম সহ এমএল মডেলগুলিকে টিউন করার জন্য বিভিন্ন ধরণের পরিশীলিত অ্যালগরিদম প্রয়োগ করে।
ধরুন অনুসন্ধানের স্থানটিতে ডাইভারজেন্ট পয়েন্টগুলির একটি অ-তুচ্ছ ভলিউম রয়েছে, যার অর্থ পয়েন্টগুলি যা ন্যান প্রশিক্ষণ ক্ষতি বা এমনকি প্রশিক্ষণের ক্ষতি করে যা গড়ের চেয়ে অনেক মানক বিচ্যুতিগুলি আরও খারাপ করে। এই ক্ষেত্রে, আমরা ব্ল্যাক-বক্স অপ্টিমাইজেশন সরঞ্জামগুলি ব্যবহার করার পরামর্শ দিই যা সঠিকভাবে ট্রায়ালগুলি পরিচালনা করে যা ডাইভার্জ করে। (এই সমস্যাটি মোকাবেলা করার জন্য একটি দুর্দান্ত উপায়ের জন্য অজানা সীমাবদ্ধতার সাথে বায়েশিয়ান অপ্টিমাইজেশন দেখুন)) ওপেন-সোর্স ভিজিয়ারের ট্রায়ালগুলি অকার্যকর হিসাবে চিহ্নিত করে ডাইভারজেন্ট পয়েন্টগুলি চিহ্নিত করার জন্য সমর্থন রয়েছে, যদিও এটি জেলবার্ট এট আল থেকে আমাদের পছন্দের পদ্ধতির ব্যবহার করতে পারে না। , এটি কীভাবে কনফিগার করা হয়েছে তার উপর নির্ভর করে।
অন্বেষণ শেষ হওয়ার পরে, পরীক্ষার সেটটিতে পারফরম্যান্স পরীক্ষা করার বিষয়টি বিবেচনা করুন। নীতিগতভাবে, আপনি এমনকি প্রশিক্ষণ সেটটিতে বৈধতা সেটটি ভাঁজ করতে পারেন এবং বায়েশিয়ান অপ্টিমাইজেশনের সাথে পাওয়া সেরা কনফিগারেশনটি পুনরায় প্রশিক্ষণ দিতে পারেন। যাইহোক, এটি কেবল তখনই উপযুক্ত যদি এই নির্দিষ্ট কাজের চাপের সাথে ভবিষ্যতের লঞ্চ না হয় (উদাহরণস্বরূপ, এককালীন কাগল প্রতিযোগিতা)।
,এই দস্তাবেজের উদ্দেশ্যে:
মেশিন লার্নিং বিকাশের চূড়ান্ত লক্ষ্য হ'ল মোতায়েন করা মডেলের কার্যকারিতা সর্বাধিক করা।
আপনি সাধারণত কোনও এমএল সমস্যার এই বিভাগে একই বেসিক পদক্ষেপ এবং নীতিগুলি ব্যবহার করতে পারেন।
এই বিভাগটি নিম্নলিখিত অনুমান করে:
- আপনার কাছে ইতিমধ্যে একটি সম্পূর্ণরূপে চলমান প্রশিক্ষণ পাইপলাইন রয়েছে যা একটি কনফিগারেশন রয়েছে যা যুক্তিসঙ্গত ফলাফল অর্জন করে।
- অর্থপূর্ণ টিউনিং পরীক্ষাগুলি পরিচালনা করার জন্য এবং সমান্তরালে কমপক্ষে বেশ কয়েকটি প্রশিক্ষণ কাজ চালানোর জন্য আপনার কাছে পর্যাপ্ত গণ্য সংস্থান রয়েছে।
ইনক্রিমেন্টাল টিউনিং কৌশল
প্রস্তাবনা: একটি সাধারণ কনফিগারেশন দিয়ে শুরু করুন। তারপরে, সমস্যার অন্তর্দৃষ্টি তৈরি করার সময় ক্রমবর্ধমানভাবে উন্নতি করুন। নিশ্চিত করুন যে কোনও উন্নতি দৃ strong ় প্রমাণের ভিত্তিতে রয়েছে।
আমরা ধরে নিই যে আপনার লক্ষ্যটি এমন একটি কনফিগারেশন সন্ধান করা যা আপনার মডেলের কার্যকারিতা সর্বাধিক করে তোলে। কখনও কখনও, আপনার লক্ষ্য একটি নির্দিষ্ট সময়সীমা দ্বারা মডেল উন্নতি সর্বাধিক করা। অন্যান্য ক্ষেত্রে, আপনি অনির্দিষ্টকালের জন্য মডেলটির উন্নতি করতে পারেন; উদাহরণস্বরূপ, ক্রমাগত উত্পাদনে ব্যবহৃত একটি মডেলকে উন্নত করে।
নীতিগতভাবে, আপনি সম্ভাব্য কনফিগারেশনের পুরো স্থানটি স্বয়ংক্রিয়ভাবে অনুসন্ধান করতে একটি অ্যালগরিদম ব্যবহার করে পারফরম্যান্স সর্বাধিক করতে পারেন, তবে এটি কোনও ব্যবহারিক বিকল্প নয়। সম্ভাব্য কনফিগারেশনের স্থানটি অত্যন্ত বড় এবং মানব দিকনির্দেশনা ছাড়াই এই স্থানটি দক্ষতার সাথে অনুসন্ধান করার জন্য এখনও কোনও অ্যালগরিদম পরিশীলিত নেই। বেশিরভাগ স্বয়ংক্রিয় অনুসন্ধান অ্যালগরিদমগুলি একটি হ্যান্ড-ডিজাইন করা অনুসন্ধান স্থানের উপর নির্ভর করে যা অনুসন্ধানের জন্য কনফিগারেশনের সেটকে সংজ্ঞায়িত করে এবং এই অনুসন্ধান স্পেসগুলি বেশ খানিকটা গুরুত্বপূর্ণ হতে পারে।
কর্মক্ষমতা সর্বাধিক করার সবচেয়ে কার্যকর উপায় হ'ল একটি সাধারণ কনফিগারেশন দিয়ে শুরু করা এবং ক্রমবর্ধমান বৈশিষ্ট্য যুক্ত করা এবং সমস্যার অন্তর্দৃষ্টি তৈরি করার সময় উন্নতি করা।
আমরা টিউনিংয়ের প্রতিটি রাউন্ডে স্বয়ংক্রিয় অনুসন্ধান অ্যালগরিদমগুলি ব্যবহার করার এবং আপনার বোঝাপড়া বাড়ার সাথে সাথে ক্রমাগত অনুসন্ধান স্পেসগুলি আপডেট করার পরামর্শ দিই। আপনি অন্বেষণ করার সাথে সাথে আপনি স্বাভাবিকভাবেই আরও ভাল এবং আরও ভাল কনফিগারেশনগুলি খুঁজে পাবেন এবং তাই আপনার "সেরা" মডেল ক্রমাগত উন্নতি করবে।
"লঞ্চ" শব্দটি আমাদের সেরা কনফিগারেশনের একটি আপডেটকে বোঝায় (যা কোনও প্রোডাকশন মডেলের প্রকৃত প্রবর্তনের সাথে মিল থাকতে পারে বা নাও পারে)। প্রতিটি "লঞ্চ" এর জন্য আপনাকে অবশ্যই নিশ্চিত করতে হবে যে পরিবর্তনটি দৃ strong ় প্রমাণের ভিত্তিতে রয়েছে - কেবল ভাগ্যবান কনফিগারেশনের উপর ভিত্তি করে এলোমেলো সুযোগ নয় - যাতে আপনি প্রশিক্ষণ পাইপলাইনে অপ্রয়োজনীয় জটিলতা যুক্ত করেন না।
একটি উচ্চ স্তরে, আমাদের ইনক্রিমেন্টাল টিউনিং কৌশলটিতে নিম্নলিখিত চারটি পদক্ষেপ পুনরাবৃত্তি জড়িত:
- পরীক্ষার পরবর্তী রাউন্ডের জন্য একটি লক্ষ্য চয়ন করুন। লক্ষ্যটি যথাযথভাবে স্কোপ করা হয়েছে তা নিশ্চিত করুন।
- পরীক্ষাগুলির পরবর্তী রাউন্ডটি ডিজাইন করুন। এই লক্ষ্যের দিকে অগ্রসর হওয়া পরীক্ষাগুলির একটি সেট ডিজাইন এবং সম্পাদন করুন।
- পরীক্ষামূলক ফলাফল থেকে শিখুন। একটি চেকলিস্টের বিরুদ্ধে পরীক্ষার মূল্যায়ন করুন।
- প্রার্থী পরিবর্তন গ্রহণ করবেন কিনা তা নির্ধারণ করুন।
এই বিভাগের বাকী অংশগুলি এই কৌশলটির বিবরণ দেয়।
পরীক্ষার পরবর্তী রাউন্ডের জন্য একটি লক্ষ্য চয়ন করুন
আপনি যদি একাধিক বৈশিষ্ট্য যুক্ত করার চেষ্টা করেন বা একবারে একাধিক প্রশ্নের উত্তর দেওয়ার চেষ্টা করেন তবে আপনি ফলাফলগুলিতে পৃথক প্রভাবগুলি বিচ্ছিন্ন করতে সক্ষম নাও হতে পারেন। উদাহরণ লক্ষ্যগুলির মধ্যে রয়েছে:
- পাইপলাইনে সম্ভাব্য উন্নতি করার চেষ্টা করুন (উদাহরণস্বরূপ, একটি নতুন নিয়মিতকরণকারী, প্রিপ্রসেসিং পছন্দ ইত্যাদি)।
- একটি নির্দিষ্ট মডেল হাইপারপ্যারামিটারের প্রভাব বুঝতে পারেন (উদাহরণস্বরূপ, অ্যাক্টিভেশন ফাংশন)
- বৈধতা ত্রুটি হ্রাস করুন।
স্বল্পমেয়াদী বৈধতা ত্রুটি উন্নতির চেয়ে দীর্ঘমেয়াদী অগ্রগতির অগ্রাধিকার দিন
সংক্ষিপ্তসার: বেশিরভাগ সময়, আপনার প্রাথমিক লক্ষ্যটি টিউনিং সমস্যাটির অন্তর্দৃষ্টি অর্জন করা।
আমরা আপনার বেশিরভাগ সময় সমস্যার অন্তর্দৃষ্টি অর্জনের জন্য ব্যয় করার পরামর্শ দিচ্ছি এবং তুলনামূলকভাবে অল্প সময় লোভের সাথে বৈধতা সেটটিতে সর্বাধিক পারফরম্যান্সের দিকে মনোনিবেশ করে। অন্য কথায়, আপনার বেশিরভাগ সময় "অন্বেষণ" এবং "শোষণ" এ অল্প পরিমাণে ব্যয় করুন। চূড়ান্ত কর্মক্ষমতা সর্বাধিক করার জন্য সমস্যাটি বোঝা গুরুত্বপূর্ণ। স্বল্পমেয়াদী লাভের উপর অন্তর্দৃষ্টি অগ্রাধিকার দেওয়া সাহায্য করে:
- কেবলমাত্র historical তিহাসিক দুর্ঘটনার মধ্য দিয়ে সু-পারফর্মিং রানগুলিতে উপস্থিত থাকার অপ্রয়োজনীয় পরিবর্তনগুলি চালু করা এড়িয়ে চলুন।
- কোন হাইপারপ্যারামিটারগুলি বৈধতা ত্রুটিটি সবচেয়ে সংবেদনশীল তা সনাক্ত করুন, যা হাইপারপ্যারামিটারগুলি সবচেয়ে বেশি ইন্টারঅ্যাক্ট করে এবং তাই একসাথে পুনরুদ্ধার করা দরকার এবং কোন হাইপারপ্যারামিটারগুলি অন্যান্য পরিবর্তনের সাথে তুলনামূলকভাবে সংবেদনশীল এবং তাই ভবিষ্যতের পরীক্ষায় স্থির করা যেতে পারে।
- চেষ্টা করার জন্য সম্ভাব্য নতুন বৈশিষ্ট্যগুলির পরামর্শ দিন, যেমন নতুন নিয়মিত ব্যবহারকারীরা যখন ওভারফিটিং কোনও সমস্যা হয়।
- এমন বৈশিষ্ট্যগুলি সনাক্ত করুন যা সহায়তা করে না এবং তাই অপসারণ করা যেতে পারে, ভবিষ্যতের পরীক্ষাগুলির জটিলতা হ্রাস করে।
- হাইপারপ্যারামিটার টিউনিং থেকে উন্নতিগুলি সম্ভবত স্যাচুরেটেড হয়ে গেলে স্বীকৃতি দিন।
- সুরের দক্ষতা উন্নত করতে আমাদের অনুসন্ধানের স্থানগুলি সর্বোত্তম মানের চারপাশে সংকীর্ণ করুন।
অবশেষে, আপনি সমস্যাটি বুঝতে পারবেন। তারপরে, পরীক্ষাগুলি টিউনিং সমস্যার কাঠামো সম্পর্কে সর্বাধিক তথ্যবহুল না থাকলেও আপনি বৈধতা ত্রুটির দিকে খাঁটিভাবে মনোনিবেশ করতে পারেন।
পরীক্ষাগুলির পরবর্তী রাউন্ডটি ডিজাইন করুন
সংক্ষিপ্তসার: পরীক্ষামূলক লক্ষ্যের জন্য কোন হাইপারপ্যারামিটারগুলি বৈজ্ঞানিক, উপদ্রব এবং স্থির হাইপারপ্যারামিটারগুলি সনাক্ত করুন। উপদ্রব হাইপারপ্যারামিটারগুলির উপর অনুকূলকরণের সময় বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির বিভিন্ন মান তুলনা করার জন্য অধ্যয়নের একটি ক্রম তৈরি করুন। বৈজ্ঞানিক মানের সাথে সংস্থান ব্যয়ের ভারসাম্য বজায় রাখতে উপদ্রব হাইপারপ্যারামিটারগুলির অনুসন্ধানের স্থানটি চয়ন করুন।
বৈজ্ঞানিক, উপদ্রব এবং স্থির হাইপারপ্যারামিটারগুলি সনাক্ত করুন
প্রদত্ত লক্ষ্যের জন্য, সমস্ত হাইপারপ্যারামিটারগুলি নিম্নলিখিত বিভাগগুলির মধ্যে একটিতে পড়ে:
- বৈজ্ঞানিক হাইপারপ্যারামিটারগুলি হ'ল যাদের মডেলের পারফরম্যান্সে প্রভাব আপনি পরিমাপ করার চেষ্টা করছেন।
- উপদ্রব হাইপারপ্যারামিটারগুলি হ'ল বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির বিভিন্ন মানকে মোটামুটি তুলনা করার জন্য যেগুলি অপ্টিমাইজ করা দরকার। উপদ্রব হাইপারপ্যারামিটারগুলি পরিসংখ্যানগুলিতে উপদ্রব পরামিতিগুলির অনুরূপ।
- স্থির হাইপারপ্যারামিটারগুলির বর্তমান পরীক্ষার ক্ষেত্রে ধ্রুবক মান রয়েছে। আপনি যখন বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির বিভিন্ন মান তুলনা করেন তখন স্থির হাইপারপ্যারামিটারগুলির মানগুলি পরিবর্তন করা উচিত নয়। পরীক্ষার একটি সেটের জন্য নির্দিষ্ট হাইপারপ্যারামিটারগুলি ঠিক করে, আপনাকে অবশ্যই গ্রহণ করতে হবে যে পরীক্ষাগুলি থেকে প্রাপ্ত সিদ্ধান্তগুলি স্থির হাইপারপ্যারামিটারগুলির অন্যান্য সেটিংসের জন্য বৈধ হতে পারে না। অন্য কথায়, স্থির হাইপারপ্যারামিটারগুলি পরীক্ষাগুলি থেকে আপনি যে কোনও সিদ্ধান্তে আঁকেন তার জন্য সতর্কতা তৈরি করে।
উদাহরণস্বরূপ, ধরুন আপনার লক্ষ্যটি নিম্নরূপ:
আরও লুকানো স্তরগুলির সাথে কোনও মডেলের কম বৈধতা ত্রুটি রয়েছে কিনা তা নির্ধারণ করুন।
এই ক্ষেত্রে:
- শেখার হার একটি উপদ্রব হাইপারপ্যারামিটার কারণ আপনি যদি প্রতিটি সংখ্যক লুকানো স্তরগুলির জন্য শেখার হার পৃথকভাবে সুর করা হয় তবে আপনি কেবলমাত্র বিভিন্ন সংখ্যক লুকানো স্তরগুলির সাথে মডেলগুলির তুলনা করতে পারেন। (সর্বোত্তম শিক্ষার হার সাধারণত মডেল আর্কিটেকচারের উপর নির্ভর করে)।
- অ্যাক্টিভেশন ফাংশনটি একটি স্থির হাইপারপ্যারামিটার হতে পারে যদি আপনি পূর্বের পরীক্ষায় নির্ধারণ করেন যে সেরা অ্যাক্টিভেশন ফাংশনটি মডেল গভীরতার জন্য সংবেদনশীল নয়। অথবা, আপনি এই অ্যাক্টিভেশন ফাংশনটি কভার করতে লুকানো স্তরগুলির সংখ্যা সম্পর্কে আপনার সিদ্ধান্তগুলি সীমাবদ্ধ করতে ইচ্ছুক। বিকল্পভাবে, আপনি যদি প্রতিটি সংখ্যক লুকানো স্তরগুলির জন্য আলাদাভাবে টিউন করতে প্রস্তুত হন তবে এটি একটি উপদ্রব হাইপারপ্যারামিটার হতে পারে।
একটি নির্দিষ্ট হাইপারপ্যারামিটার একটি বৈজ্ঞানিক হাইপারপ্যারামিটার, উপদ্রব হাইপারপ্যারামিটার বা স্থির হাইপারপ্যারামিটার হতে পারে; হাইপারপ্যারামিটারের উপাধি পরীক্ষামূলক লক্ষ্যের উপর নির্ভর করে পরিবর্তিত হয়। উদাহরণস্বরূপ, অ্যাক্টিভেশন ফাংশন নিম্নলিখিতগুলির মধ্যে যে কোনও হতে পারে:
- বৈজ্ঞানিক হাইপারপ্যারামিটার: আমাদের সমস্যার জন্য রিলু বা তানহ কি আরও ভাল পছন্দ?
- উপদ্রব হাইপারপ্যারামিটার: আপনি যখন বেশ কয়েকটি বিভিন্ন সম্ভাব্য অ্যাক্টিভেশন ফাংশনগুলির অনুমতি দেন তখন সেরা ছয়-স্তর মডেলের চেয়ে সেরা পাঁচ-স্তর মডেল কি ভাল?
- স্থির হাইপারপ্যারামিটার: রিলু নেটগুলির জন্য, কোনও নির্দিষ্ট অবস্থানে ব্যাচের নরমালাইজেশন যুক্ত করা কি সহায়তা করে?
পরীক্ষাগুলির একটি নতুন রাউন্ড ডিজাইন করার সময়:
- পরীক্ষামূলক লক্ষ্যের জন্য বৈজ্ঞানিক হাইপারপ্যারামিটারগুলি সনাক্ত করুন। (এই পর্যায়ে, আপনি অন্যান্য সমস্ত হাইপারপ্যারমিটারকে উপদ্রব হাইপারপ্যারামিটার হিসাবে বিবেচনা করতে পারেন))
- কিছু উপদ্রব হাইপারপ্যারামিটারগুলি স্থির হাইপারপ্যারামিটারগুলিতে রূপান্তর করুন।
সীমাহীন সংস্থানগুলির সাথে, আপনি সমস্ত অ-বৈজ্ঞানিক হাইপারপ্যারামিটারগুলি উপদ্রব হাইপারপ্যারামিটার হিসাবে ছেড়ে যাবেন যাতে আপনার পরীক্ষাগুলি থেকে আপনি যে সিদ্ধান্তগুলি আঁকেন তা স্থির হাইপারপ্যারামিটার মান সম্পর্কে সতর্কতা থেকে মুক্ত থাকে। যাইহোক, আপনি যত বেশি উপদ্রব হাইপারপ্যারামিটারগুলি টিউন করার চেষ্টা করছেন, তত বেশি ঝুঁকি যে আপনি বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির প্রতিটি সেটিংয়ের জন্য তাদের যথেষ্ট পরিমাণে ভালভাবে টিউন করতে ব্যর্থ হন এবং আপনার পরীক্ষাগুলি থেকে ভুল সিদ্ধান্তে পৌঁছতে পারেন। পরবর্তী বিভাগে বর্ণিত হিসাবে, আপনি গণ্য বাজেট বাড়িয়ে এই ঝুঁকির বিরুদ্ধে লড়াই করতে পারেন। যাইহোক, আপনার সর্বাধিক সংস্থান বাজেট প্রায়শই সমস্ত অ-বৈজ্ঞানিক হাইপারপ্যারামিটারগুলি টিউন করার প্রয়োজনের চেয়ে কম।
আমরা যখন উপদ্রব হাইপারপ্যারামিটার হিসাবে অন্তর্ভুক্ত করা হয় তখন এটি একটি স্থির হাইপারপ্যারামিটারে রূপান্তরিত করার পরামর্শ দিই যখন এটি একটি উপদ্রব হাইপারপ্যারামিটার হিসাবে অন্তর্ভুক্ত করার ব্যয়ের চেয়ে কম বোঝা কম হয়। হাইপারপ্যারামিটার যত বেশি উপদ্রব বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির সাথে ইন্টারঅ্যাক্ট করে, তার মান ঠিক করতে তত বেশি ক্ষতিকারক। উদাহরণস্বরূপ, ওজন ক্ষয় শক্তির সর্বোত্তম মান সাধারণত মডেলের আকারের উপর নির্ভর করে, তাই ওজন ক্ষয়ের একক নির্দিষ্ট মান ধরে ধরে বিভিন্ন মডেলের আকারের তুলনা করা খুব অন্তর্দৃষ্টিপূর্ণ হবে না।
কিছু অপ্টিমাইজার প্যারামিটার
থাম্বের নিয়ম হিসাবে, কিছু অপ্টিমাইজার হাইপারপ্যারামিটারগুলি (যেমন শেখার হার, গতি, শেখার হারের সময়সূচী পরামিতি, অ্যাডাম বিটা ইত্যাদি) হ'ল উপদ্রব হাইপারপ্যারামিটার কারণ তারা অন্যান্য পরিবর্তনের সাথে সর্বাধিক ইন্টারঅ্যাক্ট করার ঝোঁক থাকে। এই অপ্টিমাইজার হাইপারপ্যারামিটারগুলি খুব কমই বৈজ্ঞানিক হাইপারপ্যারামিটার হয় কারণ "বর্তমান পাইপলাইনের জন্য সেরা শিক্ষার হার কী" এর মতো একটি লক্ষ্য? খুব বেশি অন্তর্দৃষ্টি সরবরাহ করে না। সর্বোপরি, সেরা সেটিংটি পরবর্তী পাইপলাইন পরিবর্তনের সাথে পরিবর্তিত হতে পারে।
সম্পদের সীমাবদ্ধতা বা বিশেষত দৃ strong ় প্রমাণের কারণে আপনি মাঝে মাঝে কিছু অপ্টিমাইজার হাইপারপ্যারামিটারগুলি ঠিক করতে পারেন যে তারা বৈজ্ঞানিক পরামিতিগুলির সাথে যোগাযোগ করে না। তবে, আপনার সাধারণত ধরে নেওয়া উচিত যে বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির বিভিন্ন সেটিংসের মধ্যে ন্যায্য তুলনা করার জন্য আপনাকে অবশ্যই অপ্টিমাইজার হাইপারপ্যারামিটারগুলি আলাদাভাবে টিউন করতে হবে এবং এইভাবে এটি ঠিক করা উচিত নয়। তদুপরি, অন্যটির চেয়ে একটি অপ্টিমাইজার হাইপারপ্যারামিটার মান পছন্দ করার কোনও অগ্রাধিকার কারণ নেই; উদাহরণস্বরূপ, অপ্টিমাইজার হাইপারপ্যারামিটার মানগুলি সাধারণত কোনওভাবেই ফরোয়ার্ড পাস বা গ্রেডিয়েন্টগুলির গণ্য ব্যয়কে প্রভাবিত করে না।
অপ্টিমাইজারের পছন্দ
অপ্টিমাইজারের পছন্দটি সাধারণত হয়:
- একটি বৈজ্ঞানিক হাইপারপ্যারামিটার
- একটি স্থির হাইপারপ্যারামিটার
যদি আপনার পরীক্ষামূলক লক্ষ্য দুটি বা ততোধিক ভিন্ন অপ্টিমাইজারগুলির মধ্যে ন্যায্য তুলনা করা জড়িত থাকে তবে একটি অপ্টিমাইজার একটি বৈজ্ঞানিক হাইপারপ্যারামিটার। যেমন:
কোন অপ্টিমাইজার নির্দিষ্ট সংখ্যক পদক্ষেপে সর্বনিম্ন বৈধতা ত্রুটি উত্পাদন করে তা নির্ধারণ করুন।
বিকল্পভাবে, আপনি বিভিন্ন কারণে অপ্টিমাইজারটিকে একটি স্থির হাইপারপ্যারামিটার তৈরি করতে পারেন, সহ:
- পূর্বের পরীক্ষাগুলি পরামর্শ দেয় যে আপনার টিউনিং সমস্যার জন্য সেরা অপ্টিমাইজারটি বর্তমান বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির প্রতি সংবেদনশীল নয়।
- আপনি এই অপ্টিমাইজারটি ব্যবহার করে বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির মানগুলির তুলনা করতে পছন্দ করেন কারণ এর প্রশিক্ষণ বক্ররেখাগুলি সম্পর্কে যুক্তি করা সহজ।
- আপনি এই অপ্টিমাইজারটি ব্যবহার করতে পছন্দ করেন কারণ এটি বিকল্পগুলির চেয়ে কম মেমরি ব্যবহার করে।
নিয়মিত হাইপারপ্যারামিটার
নিয়মিত কৌশল দ্বারা প্রবর্তিত হাইপারপ্যারামিটারগুলি সাধারণত উপদ্রব হাইপারপ্যারামিটার হয়। তবে নিয়মিতকরণের কৌশলটি আদৌ অন্তর্ভুক্ত করা উচিত কিনা তা পছন্দ হয় বৈজ্ঞানিক বা স্থির হাইপারপ্যারামিটার।
উদাহরণস্বরূপ, ড্রপআউট নিয়মিতকরণ কোড জটিলতা যুক্ত করে। অতএব, ড্রপআউট নিয়মিতকরণ অন্তর্ভুক্ত করবেন কিনা তা সিদ্ধান্ত নেওয়ার সময়, আপনি "কোনও ড্রপআউট" বনাম "ড্রপআউট" তৈরি করতে পারেন একটি বৈজ্ঞানিক হাইপারপ্যারামিটার তবে ড্রপআউট একটি উপদ্রব হাইপারপ্যারামিটারকে রেট করে। যদি আপনি এই পরীক্ষার ভিত্তিতে পাইপলাইনে ড্রপআউট নিয়মিতকরণ যুক্ত করার সিদ্ধান্ত নেন, তবে ড্রপআউট হারটি ভবিষ্যতের পরীক্ষাগুলিতে একটি উপদ্রব হাইপারপ্যারামিটার হবে।
আর্কিটেকচারাল হাইপারপ্যারামিটার
আর্কিটেকচারাল হাইপারপ্যারামিটারগুলি প্রায়শই বৈজ্ঞানিক বা স্থির হাইপারপ্যারামিটার হয় কারণ আর্কিটেকচার পরিবর্তনগুলি পরিবেশন এবং প্রশিক্ষণের ব্যয়, বিলম্ব এবং মেমরির প্রয়োজনীয়তাগুলিকে প্রভাবিত করতে পারে। উদাহরণস্বরূপ, স্তরগুলির সংখ্যা সাধারণত একটি বৈজ্ঞানিক বা স্থির হাইপারপ্যারামিটার হয় কারণ এটি প্রশিক্ষণের গতি এবং মেমরির ব্যবহারের জন্য নাটকীয় পরিণতি হতে পারে।
বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির উপর নির্ভরতা
কিছু ক্ষেত্রে, উপদ্রব এবং স্থির হাইপারপ্যারামিটারগুলির সেটগুলি বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির মানগুলির উপর নির্ভর করে। উদাহরণস্বরূপ, ধরুন আপনি নেস্টারভ মোমেন্টাম এবং এডিএএম -এর কোন অপ্টিমাইজারটি সর্বনিম্ন বৈধতা ত্রুটির উত্পাদন করে তা নির্ধারণ করার চেষ্টা করছেন। এই ক্ষেত্রে:
- বৈজ্ঞানিক হাইপারপ্যারামিটারটি হ'ল অপ্টিমাইজার, যা মান নেয়
{"Nesterov_momentum", "Adam"} - মান
optimizer="Nesterov_momentum"হাইপারপ্যারামিটারগুলি{learning_rate, momentum}পরিচয় করিয়ে দেয়, যা উপদ্রব বা স্থির হাইপারপ্যারামিটার হতে পারে। - মান
optimizer="Adam"হাইপারপ্যারামিটারগুলি{learning_rate, beta1, beta2, epsilon}পরিচয় করিয়ে দেয়, যা উপদ্রব বা স্থির হাইপারপ্যারামিটার হতে পারে।
হাইপারপ্যারামিটারগুলি যা কেবলমাত্র বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির নির্দিষ্ট মানগুলির জন্য উপস্থিত থাকে তাদেরকে শর্তসাপেক্ষ হাইপারপ্যারামিটার বলা হয়। ধরে নিবেন না যে দুটি শর্তযুক্ত হাইপারপ্যারামিটারগুলি কেবল তাদের একই নাম রয়েছে বলে একই রকম! পূর্ববর্তী উদাহরণে, learning_rate নামক শর্তাধীন হাইপারপ্যারামিটারটি optimizer="Nesterov_momentum" এর জন্য optimizer="Adam" এর চেয়ে আলাদা হাইপারপ্যারামিটার। দুটি অ্যালগরিদমে এর ভূমিকা একই রকম (যদিও অভিন্ন নয়), তবে প্রতিটি অপ্টিমাইজারগুলিতে ভাল কাজ করে এমন মানগুলির পরিসীমা সাধারণত বিভিন্নতার বিভিন্ন আদেশের দ্বারা পৃথক।
অধ্যয়নের একটি সেট তৈরি করুন
বৈজ্ঞানিক এবং উপদ্রব হাইপারপ্যারামিটারগুলি সনাক্ত করার পরে, পরীক্ষামূলক লক্ষ্যের দিকে অগ্রগতি করতে আপনার অধ্যয়নের একটি অধ্যয়ন বা ক্রম ডিজাইন করা উচিত। একটি অধ্যয়ন পরবর্তী বিশ্লেষণের জন্য চালানোর জন্য হাইপারপ্যারামিটার কনফিগারেশনের একটি সেট নির্দিষ্ট করে। প্রতিটি কনফিগারেশনকে একটি ট্রায়াল বলা হয়। একটি অধ্যয়ন তৈরি করা সাধারণত নিম্নলিখিতগুলি বেছে নেওয়া জড়িত:
- হাইপারপ্যারামিটারগুলি যা ট্রায়ালগুলিতে পরিবর্তিত হয়।
- এই হাইপারপ্যারামিটারগুলি যে মানগুলি গ্রহণ করতে পারে ( অনুসন্ধানের স্থান )।
- পরীক্ষার সংখ্যা।
- অনুসন্ধানের স্থান থেকে অনেকগুলি পরীক্ষার নমুনা দেওয়ার জন্য একটি স্বয়ংক্রিয় অনুসন্ধান অ্যালগরিদম।
বিকল্পভাবে, আপনি ম্যানুয়ালি হাইপারপ্যারামিটার কনফিগারেশনের সেট নির্দিষ্ট করে একটি অধ্যয়ন তৈরি করতে পারেন।
অধ্যয়নের উদ্দেশ্য একই সাথে:
- বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির বিভিন্ন মান সহ পাইপলাইনটি চালান।
- "অপ্টিমাইজিং দূরে" (বা "অপ্টিমাইজিং") উপদ্রব হাইপারপ্যারামিটারগুলি যাতে বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির বিভিন্ন মানের মধ্যে তুলনা যতটা সম্ভব ন্যায্য হয়।
সবচেয়ে সহজ ক্ষেত্রে, আপনি বৈজ্ঞানিক পরামিতিগুলির প্রতিটি কনফিগারেশনের জন্য একটি পৃথক অধ্যয়ন করবেন, যেখানে প্রতিটি অধ্যয়ন উপদ্রব হাইপারপ্যারামিটারগুলির উপর সুর করে। উদাহরণস্বরূপ, যদি আপনার লক্ষ্যটি নেস্টারভ মোমেন্টাম এবং অ্যাডাম থেকে সেরা অপ্টিমাইজারটি নির্বাচন করা হয় তবে আপনি দুটি অধ্যয়ন তৈরি করতে পারেন:
- একটি সমীক্ষায় যা
optimizer="Nesterov_momentum"এবং উপদ্রব হাইপারপ্যারামিটারগুলি হ'ল{learning_rate, momentum} - আরেকটি গবেষণায়
optimizer="Adam"এবং উপদ্রব হাইপারপ্যারামিটারগুলি হ'ল{learning_rate, beta1, beta2, epsilon}।
আপনি প্রতিটি অধ্যয়ন থেকে সেরা পারফরম্যান্স ট্রায়াল নির্বাচন করে দুটি অপ্টিমাইজারকে তুলনা করবেন।
উপদ্রব হাইপারপ্যারামিটারগুলি অনুকূল করতে আপনি বায়েশিয়ান অপ্টিমাইজেশন বা বিবর্তনীয় অ্যালগরিদমগুলির মতো পদ্ধতি সহ যে কোনও গ্রেডিয়েন্ট-মুক্ত অপ্টিমাইজেশন অ্যালগরিদম ব্যবহার করতে পারেন। যাইহোক, আমরা এই সেটিংটিতে বিভিন্ন ধরণের সুবিধার কারণে টিউনিংয়ের অনুসন্ধানের পর্যায়ে কোয়াসি-এলোমেলো অনুসন্ধান ব্যবহার করতে পছন্দ করি। অন্বেষণ শেষ হওয়ার পরে, আমরা অত্যাধুনিক বায়েশিয়ান অপ্টিমাইজেশন সফ্টওয়্যার (যদি এটি উপলব্ধ থাকে) ব্যবহার করার পরামর্শ দিই।
আরও জটিল কেসটি বিবেচনা করুন যেখানে আপনি বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির প্রচুর সংখ্যক মান তুলনা করতে চান তবে এটি অনেক স্বাধীন অধ্যয়ন করা অযৌক্তিক। এই ক্ষেত্রে, আপনি নিম্নলিখিতগুলি করতে পারেন:
- উপদ্রব হাইপারপ্যারামিটারগুলির মতো একই অনুসন্ধানের জায়গাতে বৈজ্ঞানিক পরামিতিগুলি অন্তর্ভুক্ত করুন।
- একক গবেষণায় বৈজ্ঞানিক এবং উপদ্রব হাইপারপ্যারামিটার উভয়ের নমুনা মানগুলির জন্য একটি অনুসন্ধান অ্যালগরিদম ব্যবহার করুন।
এই পদ্ধতির গ্রহণের সময়, শর্তাধীন হাইপারপ্যারামিটারগুলি সমস্যার কারণ হতে পারে। সর্বোপরি, বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির সমস্ত মানের জন্য উপদ্রব হাইপারপ্যারামিটারগুলির সেট একই না হলে অনুসন্ধানের স্থান নির্দিষ্ট করা শক্ত। এই ক্ষেত্রে, ফ্যানসিয়ার ব্ল্যাক-বক্স অপ্টিমাইজেশন সরঞ্জামগুলির চেয়ে কোয়াসি-এলোমেলো অনুসন্ধান ব্যবহারের জন্য আমাদের পছন্দ আরও শক্তিশালী, যেহেতু এটি বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির বিভিন্ন মানকে অভিন্নভাবে নমুনা দেওয়া হবে। অনুসন্ধান অ্যালগরিদম নির্বিশেষে, এটি নিশ্চিত করুন যে এটি বৈজ্ঞানিক পরামিতিগুলি সমানভাবে অনুসন্ধান করে।
তথ্যমূলক এবং সাশ্রয়ী মূল্যের পরীক্ষাগুলির মধ্যে একটি ভারসাম্য বজায় রাখুন
অধ্যয়নের কোনও অধ্যয়ন বা ক্রম ডিজাইন করার সময়, নিম্নলিখিত তিনটি লক্ষ্য পর্যাপ্ত পরিমাণে অর্জনের জন্য একটি সীমিত বাজেট বরাদ্দ করুন:
- বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির পর্যাপ্ত বিভিন্ন মান তুলনা করা।
- একটি বৃহত পর্যাপ্ত অনুসন্ধানের জায়গার উপরে উপদ্রব হাইপারপ্যারামিটারগুলি সুর করা।
- উপদ্রব হাইপারপ্যারামিটারগুলির অনুসন্ধানের স্থানটি স্যাম্পলিং করা যথেষ্ট ঘন।
আপনি এই তিনটি লক্ষ্য যত ভাল অর্জন করতে পারবেন, তত বেশি অন্তর্দৃষ্টি আপনি পরীক্ষা থেকে বের করতে পারবেন। বৈজ্ঞানিক হাইপারপ্যারামিটারের যতগুলি সম্ভাব্যতার সাথে আপনি পরীক্ষা থেকে প্রাপ্ত অন্তর্দৃষ্টিগুলির সুযোগকে আরও প্রশস্ত করে।
যতটা সম্ভব উপদ্রব হাইপারপ্যারামিটারগুলি সহ যতটা সম্ভব এবং প্রতিটি উপদ্রব হাইপারপ্যারামিটারকে প্রশস্তভাবে বিস্তৃত করার অনুমতি দেয় যতটা সম্ভব বিস্তৃতভাবে পরিবর্তিত হয় যে বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির প্রতিটি কনফিগারেশনের জন্য অনুসন্ধানের জায়গাতে উপদ্রবগুলির একটি "ভাল" মান বিদ্যমান। অন্যথায়, আপনি উপদ্রব হাইপারপ্যারামিটার স্পেসের সম্ভাব্য অঞ্চলগুলি অনুসন্ধান না করে বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির মানগুলির মধ্যে অন্যায় তুলনা করতে পারেন যেখানে বৈজ্ঞানিক পরামিতিগুলির কিছু মানের জন্য আরও ভাল মান থাকতে পারে।
উপদ্রব হাইপারপ্যারামিটারগুলির অনুসন্ধানের স্থানটি যতটা সম্ভব ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন ঘন। এটি করা আত্মবিশ্বাস বাড়িয়ে তোলে যে অনুসন্ধান পদ্ধতিটি আপনার অনুসন্ধানের জায়গাতে বিদ্যমান উপদ্রব হাইপারপ্যারামিটারগুলির জন্য কোনও ভাল সেটিংস খুঁজে পাবে। অন্যথায়, উপদ্রব হাইপারপ্যারামিটারগুলির নমুনা দিয়ে ভাগ্যক্রমে কিছু মান পাওয়ার কারণে আপনি বৈজ্ঞানিক পরামিতিগুলির মানগুলির মধ্যে অন্যায় তুলনা করতে পারেন।
দুর্ভাগ্যক্রমে, এই তিনটি মাত্রার যে কোনও একটিতে উন্নতিগুলির জন্য নিম্নলিখিতগুলির মধ্যে একটির প্রয়োজন:
- পরীক্ষার সংখ্যা বৃদ্ধি করা, এবং তাই সংস্থান ব্যয় বৃদ্ধি করে।
- অন্যান্য মাত্রার একটিতে সংস্থান সংরক্ষণের একটি উপায় সন্ধান করা।
প্রতিটি সমস্যার নিজস্ব আইডিসিঙ্ক্রেসি এবং গণ্য সীমাবদ্ধতা রয়েছে, সুতরাং এই তিনটি লক্ষ্য জুড়ে সংস্থান বরাদ্দ করার জন্য কিছু স্তরের ডোমেন জ্ঞানের প্রয়োজন। একটি অধ্যয়ন চালানোর পরে, সর্বদা অধ্যয়নটি উপদ্রব হাইপারপ্যারামিটারগুলি যথেষ্ট পরিমাণে সুর করেছে কিনা তা বোঝার চেষ্টা করুন। এটি হ'ল, অধ্যয়নটি বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির মোটামুটি তুলনা করার জন্য যথেষ্ট পরিমাণে যথেষ্ট পরিমাণে অনুসন্ধান করেছে (পরবর্তী বিভাগে আরও বিশদে বর্ণিত হিসাবে)।
পরীক্ষামূলক ফলাফল থেকে শিখুন
প্রস্তাবনা: প্রতিটি গ্রুপের পরীক্ষার মূল বৈজ্ঞানিক লক্ষ্য অর্জনের চেষ্টা করার পাশাপাশি অতিরিক্ত প্রশ্নের একটি চেকলিস্টের মাধ্যমে যান। আপনি যদি সমস্যাগুলি আবিষ্কার করেন তবে পরীক্ষাগুলি সংশোধন করুন এবং পুনরায় চালু করুন।
শেষ পর্যন্ত, পরীক্ষার প্রতিটি গ্রুপের একটি নির্দিষ্ট লক্ষ্য রয়েছে। পরীক্ষাগুলি সেই লক্ষ্যে যে প্রমাণ সরবরাহ করে তা আপনার মূল্যায়ন করা উচিত। তবে, আপনি যদি সঠিক প্রশ্নগুলি জিজ্ঞাসা করেন তবে প্রদত্ত পরীক্ষার সেটগুলির আগে তাদের মূল লক্ষ্যের দিকে অগ্রসর হওয়ার আগে আপনি প্রায়শই সংশোধন করার জন্য সমস্যাগুলি খুঁজে পেতে পারেন। আপনি যদি এই প্রশ্নগুলি না জিজ্ঞাসা করেন তবে আপনি ভুল সিদ্ধান্তে আঁকতে পারেন।
যেহেতু চলমান পরীক্ষাগুলি ব্যয়বহুল হতে পারে, তাই আপনার পরীক্ষার প্রতিটি গ্রুপ থেকে অন্যান্য দরকারী অন্তর্দৃষ্টিও বের করা উচিত, এমনকি যদি এই অন্তর্দৃষ্টিগুলি বর্তমান লক্ষ্যের সাথে তাত্ক্ষণিকভাবে প্রাসঙ্গিক না হয়।
তাদের মূল লক্ষ্যে অগ্রগতি করার জন্য একটি প্রদত্ত পরীক্ষার সেট বিশ্লেষণ করার আগে, নিজেকে নিম্নলিখিত অতিরিক্ত প্রশ্নগুলি জিজ্ঞাসা করুন:
- অনুসন্ধানের জায়গাটি কি যথেষ্ট বড়? যদি কোনও অধ্যয়ন থেকে সর্বোত্তম পয়েন্টটি এক বা একাধিক মাত্রায় অনুসন্ধানের জায়গার সীমানার কাছাকাছি থাকে তবে অনুসন্ধান সম্ভবত যথেষ্ট প্রশস্ত নয়। এই ক্ষেত্রে, প্রসারিত অনুসন্ধানের স্থান সহ আরও একটি গবেষণা চালান।
- আপনি অনুসন্ধানের স্থান থেকে যথেষ্ট পয়েন্ট নমুনা করেছেন? যদি তা না হয় তবে আরও পয়েন্ট চালান বা টিউনিং লক্ষ্যগুলিতে কম উচ্চাভিলাষী হন।
- প্রতিটি গবেষণায় ট্রায়ালগুলির কোন ভগ্নাংশ অপ্রয়োজনীয়? এটি হ'ল, যা পরীক্ষাগুলি বিচ্যুত হয়, সত্যিই খারাপ ক্ষতির মানগুলি পায় বা একেবারে চালাতে ব্যর্থ হয় কারণ তারা কিছু অন্তর্নিহিত বাধা লঙ্ঘন করে? যখন কোনও গবেষণায় পয়েন্টগুলির খুব বড় ভগ্নাংশটি অপ্রয়োজনীয় হয়, তখন এই জাতীয় পয়েন্টগুলি নমুনা এড়াতে অনুসন্ধানের স্থানটি সামঞ্জস্য করুন, যার কখনও কখনও অনুসন্ধানের স্থানটি পুনরায় সরিয়ে ফেলা প্রয়োজন। কিছু ক্ষেত্রে, বিপুল সংখ্যক অনিবার্য পয়েন্ট প্রশিক্ষণ কোডে একটি বাগ নির্দেশ করতে পারে।
- মডেল কি অপ্টিমাইজেশনের সমস্যাগুলি প্রদর্শন করে?
- সেরা পরীক্ষার প্রশিক্ষণ বক্ররেখা থেকে আপনি কী শিখতে পারেন? উদাহরণস্বরূপ, সেরা ট্রায়ালগুলিতে কি সমস্যাযুক্ত ওভারফিটিংয়ের সাথে সামঞ্জস্য রেখে প্রশিক্ষণ বক্ররেখা রয়েছে?
পূর্ববর্তী প্রশ্নের উত্তরগুলির ভিত্তিতে প্রয়োজনে, অনুসন্ধানের স্থানটি উন্নত করতে এবং/অথবা আরও পরীক্ষার নমুনা দেওয়ার জন্য সাম্প্রতিক অধ্যয়ন বা অধ্যয়নের গোষ্ঠী পরিমার্জন করুন, বা অন্য কোনও সংশোধনমূলক পদক্ষেপ নিতে পারেন।
একবার আপনি পূর্ববর্তী প্রশ্নের উত্তর দিয়ে গেলে, আপনি পরীক্ষাগুলি আপনার মূল লক্ষ্যটির জন্য যে প্রমাণ সরবরাহ করে তা মূল্যায়ন করতে পারেন; উদাহরণস্বরূপ, কোনও পরিবর্তন কার্যকর কিনা তা মূল্যায়ন করা ।
খারাপ অনুসন্ধানের স্থানের সীমানা সনাক্ত করুন
এটি থেকে নমুনাযুক্ত সেরা পয়েন্টটি যদি তার সীমানার কাছাকাছি থাকে তবে একটি অনুসন্ধানের স্থান সন্দেহজনক। আপনি যদি সেই দিকে অনুসন্ধানের পরিসরটি প্রসারিত করেন তবে আপনি আরও ভাল পয়েন্ট খুঁজে পেতে পারেন।
অনুসন্ধানের স্থানের সীমানা পরীক্ষা করতে, আমরা বেসিক হাইপারপ্যারামিটার অক্ষ প্লটগুলিকে যা বলি সে সম্পর্কে সম্পূর্ণ ট্রায়ালগুলি প্লট করার পরামর্শ দিই। এর মধ্যে আমরা হাইপারপ্যারামিটারগুলির মধ্যে একটির তুলনায় বৈধতা উদ্দেশ্যমূলক মানটি প্লট করি (উদাহরণস্বরূপ, শেখার হার)। প্লটের প্রতিটি পয়েন্ট একটি একক পরীক্ষার সাথে মিলে যায়।
প্রতিটি পরীক্ষার জন্য বৈধতা উদ্দেশ্যমূলক মান সাধারণত প্রশিক্ষণের সময় এটি অর্জন করা সর্বোত্তম মান হওয়া উচিত।
চিত্র 1: খারাপ অনুসন্ধানের স্থানের সীমানা এবং গ্রহণযোগ্য অনুসন্ধান স্থানের সীমানার উদাহরণ।
চিত্র 1 এর প্লটগুলি প্রাথমিক শিক্ষার হারের বিপরীতে ত্রুটির হার (কম আরও ভাল) দেখায়। যদি কোনও অনুসন্ধানের জায়গার প্রান্তের দিকে সেরা পয়েন্ট ক্লাস্টার (কিছু মাত্রায়) থাকে তবে সেরা পর্যবেক্ষণ পয়েন্টটি আর সীমানার কাছাকাছি না হওয়া পর্যন্ত আপনাকে অনুসন্ধানের স্থানের সীমানা প্রসারিত করতে হবে।
প্রায়শই, একটি গবেষণায় "অযোগ্য" ট্রায়ালগুলি অন্তর্ভুক্ত থাকে যা খুব খারাপ ফলাফল দেয় বা খুব খারাপ ফলাফল পায় (চিত্র 1 -এ লাল xs দিয়ে চিহ্নিত)। যদি সমস্ত ট্রায়ালগুলি কিছু থ্রেশহোল্ড মানের চেয়ে বেশি শেখার হারের জন্য অপ্রয়োজনীয় হয় এবং যদি সেরা পারফর্মিং ট্রায়ালগুলির সেই অঞ্চলের প্রান্তে শেখার হার থাকে তবে মডেলটি উচ্চতর শিক্ষার হার অ্যাক্সেস করতে বাধা দেয় এমন স্থায়িত্বের সমস্যাগুলিতে ভুগতে পারে ।
অনুসন্ধানের জায়গাতে পর্যাপ্ত পয়েন্টগুলি নমুনা দিচ্ছেন না
সাধারণভাবে, অনুসন্ধানের স্থানটি যথেষ্ট পরিমাণে নমুনাযুক্ত হয়েছে কিনা তা জানা খুব কঠিন হতে পারে । Fric কয়েকটি কম ট্রায়াল চালানোর চেয়ে আরও বেশি ট্রায়াল চালানো ভাল, তবে আরও ট্রায়ালগুলি একটি সুস্পষ্ট অতিরিক্ত ব্যয় উত্পন্ন করে।
যেহেতু আপনি যখন যথেষ্ট নমুনা করেছেন তখন এটি জানা খুব কঠিন, আমরা সুপারিশ করি:
- আপনি যা সামর্থ্য করতে পারেন স্যাম্পলিং।
- বারবার বিভিন্ন হাইপারপ্যারামিটার অক্ষ প্লটগুলি দেখে আপনার স্বজ্ঞাত আত্মবিশ্বাসকে ক্যালিব্রেট করা এবং অনুসন্ধানের জায়গার "ভাল" অঞ্চলে কতগুলি পয়েন্ট রয়েছে তা বোঝার চেষ্টা করা।
প্রশিক্ষণ বক্ররেখা পরীক্ষা করুন
সংক্ষিপ্তসার: ক্ষতির বক্ররেখা পরীক্ষা করা সাধারণ ব্যর্থতা মোডগুলি সনাক্ত করার একটি সহজ উপায় এবং আপনাকে সম্ভাব্য পরবর্তী ক্রিয়াকলাপগুলিকে অগ্রাধিকার দিতে সহায়তা করতে পারে।
অনেক ক্ষেত্রে, আপনার পরীক্ষাগুলির প্রাথমিক উদ্দেশ্যটির জন্য কেবল প্রতিটি পরীক্ষার বৈধতা ত্রুটি বিবেচনা করা প্রয়োজন। যাইহোক, প্রতিটি ট্রায়ালকে একক সংখ্যায় হ্রাস করার সময় সাবধানতা অবলম্বন করুন কারণ সেই ফোকাসটি পৃষ্ঠের নীচে কী চলছে সে সম্পর্কে গুরুত্বপূর্ণ বিশদটি আড়াল করতে পারে। প্রতিটি অধ্যয়নের জন্য, আমরা কমপক্ষে সেরা কয়েকটি পরীক্ষার ক্ষতির বক্ররেখাগুলি দেখার দৃ strongly ়ভাবে সুপারিশ করি। এমনকি যদি প্রাথমিক পরীক্ষামূলক উদ্দেশ্যকে সম্বোধন করার জন্য এটি প্রয়োজনীয় না হয় তবে ক্ষতির বক্ররেখাগুলি পরীক্ষা করা (প্রশিক্ষণ ক্ষতি এবং বৈধতা উভয়ই সহ) সাধারণ ব্যর্থতা মোডগুলি সনাক্ত করার একটি ভাল উপায় এবং আপনাকে পরবর্তী কী পদক্ষেপ নিতে হবে তা অগ্রাধিকার দিতে সহায়তা করতে পারে।
ক্ষতির বক্ররেখা পরীক্ষা করার সময়, নিম্নলিখিত প্রশ্নগুলিতে ফোকাস করুন:
কোনও ট্রায়াল সমস্যাযুক্ত ওভারফিটিং প্রদর্শন করছে? প্রশিক্ষণের সময় বৈধতা ত্রুটি বাড়তে শুরু করলে সমস্যাযুক্ত ওভারফিটিং ঘটে। পরীক্ষামূলক সেটিংসে যেখানে আপনি বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির প্রতিটি সেটিংয়ের জন্য "সেরা" ট্রায়াল নির্বাচন করে উপদ্রব হাইপারপ্যারামিটারগুলি অপ্টিমাইজ করেন, আপনি তুলনা করছেন এমন বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির সেটিংসের সাথে সম্পর্কিত কমপক্ষে প্রতিটি সেরা ট্রায়ালগুলিতে সমস্যাযুক্ত ওভারফিটিংয়ের জন্য পরীক্ষা করুন। যদি সেরা পরীক্ষার কোনওটি সমস্যাযুক্ত ওভারফিটিং প্রদর্শন করে তবে নিম্নলিখিত বা উভয়ই করুন:
- অতিরিক্ত নিয়মিত কৌশল সহ পরীক্ষাটি পুনরায় চালু করুন
- বৈজ্ঞানিক হাইপারপ্যারামিটারগুলির মানগুলির তুলনা করার আগে বিদ্যমান নিয়মিতকরণ পরামিতিগুলি পুনরুদ্ধার করুন। যদি বৈজ্ঞানিক হাইপারপ্যারামিটারগুলিতে নিয়মিতকরণের পরামিতিগুলি অন্তর্ভুক্ত থাকে তবে এটি প্রয়োগ করতে পারে না, তখন থেকে যদি এই নিয়মিতকরণ পরামিতিগুলির নিম্ন-শক্তি সেটিংসের ফলে সমস্যাযুক্ত ওভারফিটিংয়ের ফলে ঘটে তবে অবাক হওয়ার কিছু নেই।
ওভারফিটিং হ্রাস করা প্রায়শই সাধারণ নিয়মিতকরণ কৌশলগুলি ব্যবহার করে সোজা হয় যা ন্যূনতম কোড জটিলতা বা অতিরিক্ত গণনা যুক্ত করে (উদাহরণস্বরূপ, ড্রপআউট নিয়মিতকরণ, লেবেল স্মুথিং, ওজন ক্ষয়)। অতএব, পরীক্ষার পরবর্তী রাউন্ডে এগুলির এক বা একাধিক যুক্ত করা সাধারণত তুচ্ছ। উদাহরণস্বরূপ, যদি বৈজ্ঞানিক হাইপারপ্যারামিটারটি "লুকানো স্তরগুলির সংখ্যা" হয় এবং সবচেয়ে ভাল ট্রায়াল যা লুকানো স্তরগুলির সর্বাধিক সংখ্যক ব্যবহার করে তা সমস্যাযুক্ত ওভারফিটিং প্রদর্শন করে, তবে আমরা তাত্ক্ষণিকভাবে লুকানো স্তরগুলির ছোট সংখ্যক নির্বাচন করার পরিবর্তে অতিরিক্ত নিয়মিতকরণের সাথে পুনরায় চেষ্টা করার পরামর্শ দিই।
এমনকি যদি "সেরা" ট্রায়ালগুলির কোনওটিই সমস্যাযুক্ত ওভারফিটিং প্রদর্শন করে না, তবে এটি যদি কোনও পরীক্ষার মধ্যে ঘটে তবে এখনও সমস্যা হতে পারে। Selecting the best trial suppresses configurations exhibiting problematic overfitting and favors those that don't. In other words, selecting the best trial favors configurations with more regularization. However, anything that makes training worse can act as a regularizer, even if it wasn't intended that way. For example, choosing a smaller learning rate can regularize training by hobbling the optimization process, but we typically don't want to choose the learning rate this way. Note that the "best" trial for each setting of the scientific hyperparameters might be selected in such a way that favors "bad" values of some of the scientific or nuisance hyperparameters.
Is there high step-to-step variance in the training or validation error late in training? If so, this could interfere with both of the following:
- Your ability to compare different values of the scientific hyperparameters. That's because each trial randomly ends on a "lucky" or "unlucky" step.
- Your ability to reproduce the result of the best trial in production. That's because the production model might not end on the same "lucky" step as in the study.
The most likely causes of step-to-step variance are:
- Batch variance due to randomly sampling examples from the training set for each batch.
- Small validation sets
- Using a learning rate that's too high late in training.
সম্ভাব্য প্রতিকার অন্তর্ভুক্ত:
- Increasing the batch size.
- Obtaining more validation data.
- Using learning rate decay.
- Using Polyak averaging.
Are the trials still improving at the end of training? If so, you are in the "compute bound" regime and may benefit from increasing the number of training steps or changing the learning rate schedule.
Has performance on the training and validation sets saturated long before the final training step? If so, this indicates that you are in the "not compute-bound" regime and that you may be able to decrease the number of training steps.
Beyond this list, many additional behaviors can become evident from examining the loss curves. For example, training loss increasing during training usually indicates a bug in the training pipeline.
Detecting whether a change is useful with isolation plots
Figure 2: Isolation plot that investigates the best value of weight decay for ResNet-50 trained on ImageNet.
Often, the goal of a set of experiments is to compare different values of a scientific hyperparameter. For example, suppose you want to determine the value of weight decay that results in the best validation error. An isolation plot is a special case of the basic hyperparameter axis plot. Each point on an isolation plot corresponds to the performance of the best trial across some (or all) of the nuisance hyperparameters. In other words, plot the model performance after "optimizing away" the nuisance hyperparameters.
An isolation plot simplifies performing an apples-to-apples comparison between different values of the scientific hyperparameter. For example, the isolation plot in Figure 2 reveals the value of weight decay that produces the best validation performance for a particular configuration of ResNet-50 trained on ImageNet.
If the goal is to determine whether to include weight decay at all, then compare the best point from this plot against the baseline of no weight decay. For a fair comparison, the baseline should also have its learning rate equally well tuned.
When you have data generated by (quasi)random search and are considering a continuous hyperparameter for an isolation plot, you can approximate the isolation plot by bucketing the x-axis values of the basic hyperparameter axis plot and taking the best trial in each vertical slice defined by the buckets.
Automate generically useful plots
The more effort it is to generate plots, the less likely you are to look at them as much as you should. Therefore, we recommend setting up your infrastructure to automatically produce as many plots as possible. At a minimum, we recommend automatically generating basic hyperparameter axis plots for all hyperparameters that you vary in an experiment.
Additionally, we recommend automatically producing loss curves for all trials. Furthermore, we recommend making it as easy as possible to find the best few trials of each study and to examine their loss curves.
You can add many other useful potential plots and visualizations. To paraphrase Geoffrey Hinton :
Every time you plot something new, you learn something new.
Determine whether to adopt the candidate change
Summary: When deciding whether to make a change to our model or training procedure or adopt a new hyperparameter configuration, note the different sources of variation in your results.
When trying to improve a model, a particular candidate change might initially achieve a better validation error compared to an incumbent configuration. However, repeating the experiment might demonstrate no consistent advantage. Informally, the most important sources of inconsistent results can be grouped into the following broad categories:
- Training procedure variance, retrain variance, or trial variance : the variation between training runs that use the same hyperparameters but different random seeds. For example, different random initializations, training data shuffles, dropout masks, patterns of data augmentation operations, and orderings of parallel arithmetic operations are all potential sources of trial variance.
- Hyperparameter search variance, or study variance : the variation in results caused by our procedure to select the hyperparameters. For example, you might run the same experiment with a particular search space but with two different seeds for quasi-random search and end up selecting different hyperparameter values.
- Data collection and sampling variance : the variance from any sort of random split into training, validation, and test data or variance due to the training data generation process more generally.
True, you can compare validation error rates estimated on a finite validation set using fastidious statistical tests. However, often the trial variance alone can produce statistically significant differences between two different trained models that use the same hyperparameter settings.
We are most concerned about study variance when trying to make conclusions that go beyond the level of an individual point in hyperparameters space. The study variance depends on the number of trials and the search space. We have seen cases where the study variance is larger than the trial variance and cases where it is much smaller. Therefore, before adopting a candidate change, consider running the best trial N times to characterize the run-to-run trial variance. Usually, you can get away with only recharacterizing the trial variance after major changes to the pipeline, but you might need fresher estimates in some cases. In other applications, characterizing the trial variance is too costly to be worth it.
Although you only want to adopt changes (including new hyperparameter configurations) that produce real improvements, demanding complete certainty that a given change helps isn't the right answer either. Therefore, if a new hyperparameter point (or other change) gets a better result than the baseline (taking into account the retrain variance of both the new point and the baseline as best as you can), then you probably should adopt it as the new baseline for future comparisons. However, we recommend only adopting changes that produce improvements that outweigh any complexity they add.
After exploration concludes
Summary: Bayesian optimization tools are a compelling option once you're done searching for good search spaces and have decided what hyperparameters are worth tuning.
Eventually, your priorities will shift from learning more about the tuning problem to producing a single best configuration to launch or otherwise use. At that point, there should be a refined search space that comfortably contains the local region around the best observed trial and has been adequately sampled. Your exploration work should have revealed the most essential hyperparameters to tune and their sensible ranges that you can use to construct a search space for a final automated tuning study using as large a tuning budget as possible.
Since you no longer care about maximizing insight into the tuning problem, many of the advantages of quasi-random search no longer apply. Therefore, you should use Bayesian optimization tools to automatically find the best hyperparameter configuration. Open-Source Vizier implements a variety of sophisticated algorithms for tuning ML models, including Bayesian Optimization algorithms.
Suppose the search space contains a non-trivial volume of divergent points , meaning points that get NaN training loss or even training loss many standard deviations worse than the mean. In this case, we recommend using black-box optimization tools that properly handle trials that diverge. (See Bayesian Optimization with Unknown Constraints for an excellent way to deal with this issue.) Open-Source Vizier has supports for marking divergent points by marking trials as infeasible, although it may not use our preferred approach from Gelbart et al. , depending on how it is configured.
After exploration concludes, consider checking the performance on the test set. In principle, you could even fold the validation set into the training set and retrain the best configuration found with Bayesian optimization. However, this is only appropriate if there won't be future launches with this specific workload (for example, a one-time Kaggle competition).
,For the purposes of this document:
The ultimate goal of machine learning development is to maximize the usefulness of the deployed model.
You can typically use the same basic steps and principles in this section on any ML problem.
এই বিভাগটি নিম্নলিখিত অনুমান করে:
- You already have a fully-running training pipeline along with a configuration that obtains a reasonable result.
- You have enough computational resources to conduct meaningful tuning experiments and to run at least several training jobs in parallel.
The incremental tuning strategy
Recommendation: Start with a simple configuration. Then, incrementally make improvements while building up insight into the problem. Make sure that any improvement is based on strong evidence.
We assume that your goal is to find a configuration that maximizes the performance of your model. Sometimes, your goal is to maximize model improvement by a fixed deadline. In other cases, you can keep improving the model indefinitely; for example, continually improving a model used in production.
In principle, you could maximize performance by using an algorithm to automatically search the entire space of possible configurations, but this is not a practical option. The space of possible configurations is extremely large and there are not yet any algorithms sophisticated enough to efficiently search this space without human guidance. Most automated search algorithms rely on a hand-designed search space that defines the set of configurations to search in, and these search spaces can matter quite a bit.
The most effective way to maximize performance is to start with a simple configuration and incrementally add features and make improvements while building up insight into the problem.
We recommend using automated search algorithms in each round of tuning and continually updating search spaces as your understanding grows. As you explore, you will naturally find better and better configurations and therefore your "best" model will continually improve.
The term "launch" refers to an update to our best configuration (which may or may not correspond to an actual launch of a production model). For each "launch," you must ensure that the change is based on strong evidence—not just random chance based on a lucky configuration—so that you don't add unnecessary complexity to the training pipeline.
At a high level, our incremental tuning strategy involves repeating the following four steps:
- Pick a goal for the next round of experiments. Make sure that the goal is appropriately scoped.
- Design the next round of experiments. Design and execute a set of experiments that progresses towards this goal.
- Learn from the experimental results. Evaluate the experiment against a checklist.
- Determine whether to adopt the candidate change.
The remainder of this section details this strategy.
Pick a goal for the next round of experiments
If you try to add multiple features or answer multiple questions at once, you may not be able to disentangle the separate effects on the results. Example goals include:
- Try a potential improvement to the pipeline (for example, a new regularizer, preprocessing choice, etc.).
- Understand the impact of a particular model hyperparameter (for example, the activation function)
- Minimize validation error.
Prioritize long term progress over short term validation error improvements
Summary: Most of the time, your primary goal is to gain insight into the tuning problem.
We recommend spending the majority of your time gaining insight into the problem and comparatively little time greedily focused on maximizing performance on the validation set. In other words, spend most of your time on "exploration" and only a small amount on "exploitation". Understanding the problem is critical to maximize final performance. Prioritizing insight over short term gains helps to:
- Avoid launching unnecessary changes that happened to be present in well-performing runs merely through historical accident.
- Identify which hyperparameters the validation error is most sensitive to, which hyperparameters interact the most and therefore need to be retuned together, and which hyperparameters are relatively insensitive to other changes and can therefore be fixed in future experiments.
- Suggest potential new features to try, such as new regularizers when overfitting is an issue.
- Identify features that don't help and therefore can be removed, reducing the complexity of future experiments.
- Recognize when improvements from hyperparameter tuning have likely saturated.
- Narrow our search spaces around the optimal value to improve tuning efficiency.
Eventually, you'll understand the problem. Then, you can focus purely on the validation error even if the experiments aren't maximally informative about the structure of the tuning problem.
Design the next round of experiments
Summary: Identify which hyperparameters are scientific, nuisance, and fixed hyperparameters for the experimental goal. Create a sequence of studies to compare different values of the scientific hyperparameters while optimizing over the nuisance hyperparameters. Choose the search space of nuisance hyperparameters to balance resource costs with scientific value.
Identify scientific, nuisance, and fixed hyperparameters
For a given goal, all hyperparameters fall into one of the following categories:
- scientific hyperparameters are those whose effect on the model's performance is what you're trying to measure.
- nuisance hyperparameters are those that need to be optimized over in order to fairly compare different values of the scientific hyperparameters. Nuisance hyperparameters are similar to nuisance parameters in statistics.
- fixed hyperparameters have constant values in the current round of experiments. The values of fixed hyperparameters shouldn't change when you compare different values of scientific hyperparameters. By fixing certain hyperparameters for a set of experiments, you must accept that conclusions derived from the experiments might not be valid for other settings of the fixed hyperparameters. In other words, fixed hyperparameters create caveats for any conclusions you draw from the experiments.
For example, suppose your goal is as follows:
Determine whether a model with more hidden layers has lower validation error.
এই ক্ষেত্রে:
- Learning rate is a nuisance hyperparameter because you can only fairly compare models with different numbers of hidden layers if the learning rate is tuned separately for each number of hidden layers. (The optimal learning rate generally depends on the model architecture).
- The activation function could be a fixed hyperparameter if you have determined in prior experiments that the best activation function is not sensitive to model depth. Or, you are willing to limit your conclusions about the number of hidden layers to cover this activation function. Alternatively, it could be a nuisance hyperparameter if you are prepared to tune it separately for each number of hidden layers.
A particular hyperparameter could be a scientific hyperparameter, nuisance hyperparameter, or fixed hyperparameter; the hyperparameter's designation changes depending on the experimental goal. For example, activation function could be any of the following:
- Scientific hyperparameter: Is ReLU or tanh a better choice for our problem?
- Nuisance hyperparameter: Is the best five-layer model better than the best six-layer model when you allow several different possible activation functions?
- Fixed hyperparameter: For ReLU nets, does adding batch normalization in a particular position help?
When designing a new round of experiments:
- Identify the scientific hyperparameters for the experimental goal. (At this stage, you can consider all other hyperparameters to be nuisance hyperparameters.)
- Convert some nuisance hyperparameters into fixed hyperparameters.
With limitless resources, you would leave all non-scientific hyperparameters as nuisance hyperparameters so that the conclusions you draw from your experiments are free from caveats about fixed hyperparameter values. However, the more nuisance hyperparameters you attempt to tune, the greater the risk that you fail to tune them sufficiently well for each setting of the scientific hyperparameters and end up reaching the wrong conclusions from your experiments. As described in a later section , you could counter this risk by increasing the computational budget. However, your maximum resource budget is often less than would be needed to tune all non-scientific hyperparameters.
We recommend converting a nuisance hyperparameter into a fixed hyperparameter when the caveats introduced by fixing it are less burdensome than the cost of including it as a nuisance hyperparameter. The more a nuisance hyperparameter interacts with the scientific hyperparameters, the more damaging to fix its value. For example, the best value of the weight decay strength typically depends on the model size, so comparing different model sizes assuming a single specific value of the weight decay wouldn't be very insightful.
Some optimizer parameters
As a rule of thumb, some optimizer hyperparameters (eg the learning rate, momentum, learning rate schedule parameters, Adam betas etc.) are nuisance hyperparameters because they tend to interact the most with other changes. These optimizer hyperparameters are rarely scientific hyperparameters because a goal like "what is the best learning rate for the current pipeline?" doesn't provide much insight. After all, the best setting could change with the next pipeline change anyway.
You might fix some optimizer hyperparameters occasionally due to resource constraints or particularly strong evidence that they don't interact with the scientific parameters. However, you should generally assume that you must tune optimizer hyperparameters separately to make fair comparisons between different settings of the scientific hyperparameters, and thus shouldn't be fixed. Furthermore, there is no a priori reason to prefer one optimizer hyperparameter value over another; for example, optimizer hyperparameter values don't usually affect the computational cost of forward passes or gradients in any way.
The choice of optimizer
The choice of optimizer is typically either:
- a scientific hyperparameter
- a fixed hyperparameter
An optimizer is a scientific hyperparameter if your experimental goal involves making fair comparisons between two or more different optimizers. যেমন:
Determine which optimizer produces the lowest validation error in a given number of steps.
Alternatively, you might make the optimizer a fixed hyperparameter for a variety of reasons, including:
- Prior experiments suggest that the best optimizer for your tuning problem is not sensitive to current scientific hyperparameters.
- You prefer to compare values of the scientific hyperparameters using this optimizer because its training curves are easier to reason about.
- You prefer to use this optimizer because it uses less memory than the alternatives.
Regularization hyperparameters
Hyperparameters introduced by a regularization technique are typically nuisance hyperparameters. However, the choice of whether or not to include the regularization technique at all is either a scientific or fixed hyperparameter.
For example, dropout regularization adds code complexity. Therefore, when deciding whether to include dropout regularization, you could make "no dropout" vs "dropout" a scientific hyperparameter but dropout rate a nuisance hyperparameter. If you decide to add dropout regularization to the pipeline based on this experiment, then the dropout rate would be a nuisance hyperparameter in future experiments.
Architectural hyperparameters
Architectural hyperparameters are often scientific or fixed hyperparameters because architecture changes can affect serving and training costs, latency, and memory requirements. For example, the number of layers is typically a scientific or fixed hyperparameter since it tends to have dramatic consequences for training speed and memory usage.
Dependencies on scientific hyperparameters
In some cases, the sets of nuisance and fixed hyperparameters depends on the values of the scientific hyperparameters. For example, suppose you are trying to determine which optimizer in Nesterov momentum and Adam produces in the lowest validation error. এই ক্ষেত্রে:
- The scientific hyperparameter is the optimizer, which takes values
{"Nesterov_momentum", "Adam"} - The value
optimizer="Nesterov_momentum"introduces the hyperparameters{learning_rate, momentum}, which might be either nuisance or fixed hyperparameters. - The value
optimizer="Adam"introduces the hyperparameters{learning_rate, beta1, beta2, epsilon}, which might be either nuisance or fixed hyperparameters.
Hyperparameters that are only present for certain values of the scientific hyperparameters are called conditional hyperparameters . Don't assume two conditional hyperparameters are the same just because they have the same name! In the preceding example, the conditional hyperparameter called learning_rate is a different hyperparameter for optimizer="Nesterov_momentum" than for optimizer="Adam" . Its role is similar (although not identical) in the two algorithms, but the range of values that work well in each of the optimizers is typically different by several orders of magnitude.
Create a set of studies
After identifying the scientific and nuisance hyperparameters, you should design a study or sequence of studies to make progress towards the experimental goal. A study specifies a set of hyperparameter configurations to be run for subsequent analysis. Each configuration is called a trial . Creating a study typically involves choosing the following:
- The hyperparameters that vary across trials.
- The values those hyperparameters can take on (the search space ).
- The number of trials.
- An automated search algorithm to sample that many trials from the search space.
Alternatively, you can create a study by specifying the set of hyperparameter configurations manually.
The purpose of the studies is to simultaneously:
- Run the pipeline with different values of the scientific hyperparameters.
- "Optimizing away" (or "optimizing over") the nuisance hyperparameters so that comparisons between different values of the scientific hyperparameters are as fair as possible.
In the simplest case, you would make a separate study for each configuration of the scientific parameters, where each study tunes over the nuisance hyperparameters. For example, if your goal is to select the best optimizer out of Nesterov momentum and Adam, you could create two studies:
- One study in which
optimizer="Nesterov_momentum"and the nuisance hyperparameters are{learning_rate, momentum} - Another study in which
optimizer="Adam"and the nuisance hyperparameters are{learning_rate, beta1, beta2, epsilon}.
You would compare the two optimizers by selecting the best performing trial from each study.
You can use any gradient-free optimization algorithm, including methods such as Bayesian optimization or evolutionary algorithms, to optimize over the nuisance hyperparameters. However, we prefer to use quasi-random search in the exploration phase of tuning because of a variety of advantages it has in this setting. After exploration concludes, we recommend using state-of-the-art Bayesian optimization software (if it is available).
Consider a more complicated case where you want to compare a large number of values of the scientific hyperparameters but it is impractical to make that many independent studies. In this case, you can do the following:
- Include the scientific parameters in the same search space as the nuisance hyperparameters.
- Use a search algorithm to sample values of both the scientific and nuisance hyperparameters in a single study.
When taking this approach, conditional hyperparameters can cause problems. After all, it is hard to specify a search space unless the set of nuisance hyperparameters is the same for all values of the scientific hyperparameters. In this case, our preference for using quasi-random search over fancier black-box optimization tools is even stronger, since it guarantees different values of the scientific hyperparameters will be sampled uniformly. Regardless of the search algorithm, ensure that it searches the scientific parameters uniformly.
Strike a balance between informative and affordable experiments
When designing a study or sequence of studies, allocate a limited budget to adequately achieve the following three goals:
- Comparing enough different values of the scientific hyperparameters.
- Tuning the nuisance hyperparameters over a large enough search space.
- Sampling the search space of nuisance hyperparameters densely enough.
The better you can achieve these three goals, the more insight you can extract from the experiment. Comparing as many values of the scientific hyperparameters as possible broadens the scope of the insights you gain from the experiment.
Including as many nuisance hyperparameters as possible and allowing each nuisance hyperparameter to vary over as wide a range as possible increases confidence that a "good" value of the nuisance hyperparameters exists in the search space for each configuration of the scientific hyperparameters. Otherwise, you might make unfair comparisons between values of the scientific hyperparameters by not searching possible regions of the nuisance hyperparameter space where better values might lie for some values of the scientific parameters.
Sample the search space of nuisance hyperparameters as densely as possible. Doing so increases confidence that the search procedure will find any good settings for the nuisance hyperparameters that happen to exist in your search space. Otherwise, you might make unfair comparisons between values of the scientific parameters due to some values getting luckier with the sampling of the nuisance hyperparameters.
Unfortunately, improvements in any of these three dimensions require either of the following:
- Increasing the number of trials, and therefore increasing the resource cost.
- Finding a way to save resources in one of the other dimensions.
Every problem has its own idiosyncrasies and computational constraints, so allocating resources across these three goals requires some level of domain knowledge. After running a study, always try to get a sense of whether the study tuned the nuisance hyperparameters well enough. That is, the study searched a large enough space extensively enough to fairly compare the scientific hyperparameters (as described in greater detail in the next section).
Learn from the experimental results
Recommendation: In addition to trying to achieve the original scientific goal of each group of experiments, go through a checklist of additional questions. If you discover issues, revise and rerun the experiments.
Ultimately, each group of experiments has a specific goal. You should evaluate the evidence the experiments provide toward that goal. However, if you ask the right questions, you can often find issues to correct before a given set of experiments can progress towards their original goal. If you don't ask these questions, you may draw incorrect conclusions.
Since running experiments can be expensive, you should also extract other useful insights from each group of experiments, even if these insights are not immediately relevant to the current goal.
Before analyzing a given set of experiments to make progress toward their original goal, ask yourself the following additional questions:
- Is the search space large enough? If the optimal point from a study is near the boundary of the search space in one or more dimensions, the search is probably not wide enough. In this case, run another study with an expanded search space.
- Have you sampled enough points from the search space? If not, run more points or be less ambitious in the tuning goals.
- What fraction of the trials in each study are infeasible? That is, which trials diverge, get really bad loss values, or fail to run at all because they violate some implicit constraint? When a very large fraction of points in a study are infeasible, adjust the search space to avoid sampling such points, which sometimes requires reparameterizing the search space. In some cases, a large number of infeasible points can indicate a bug in the training code.
- Does the model exhibit optimization issues?
- What can you learn from the training curves of the best trials? For example, do the best trials have training curves consistent with problematic overfitting?
If necessary, based on the answers to the preceding questions, refine the most recent study or group of studies to improve the search space and/or sample more trials, or take some other corrective action.
Once you have answered the preceding questions, you can evaluate the evidence the experiments provide towards your original goal; for example, evaluating whether a change is useful .
Identify bad search space boundaries
A search space is suspicious if the best point sampled from it is close to its boundary. You might find an even better point if you expand the search range in that direction.
To check search space boundaries, we recommend plotting completed trials on what we call basic hyperparameter axis plots . In these, we plot the validation objective value versus one of the hyperparameters (for example, learning rate). Each point on the plot corresponds to a single trial.
The validation objective value for each trial should usually be the best value it achieved over the course of training.
Figure 1: Examples of bad search space boundaries and acceptable search space boundaries.
The plots in Figure 1 show the error rate (lower is better) against the initial learning rate. If the best points cluster towards the edge of a search space (in some dimension), then you might need to expand the search space boundaries until the best observed point is no longer close to the boundary.
Often, a study includes "infeasible" trials that diverge or get very bad results (marked with red Xs in Figure 1). If all trials are infeasible for learning rates greater than some threshold value, and if the best performing trials have learning rates at the edge of that region, the model may suffer from stability issues preventing it from accessing higher learning rates .
Not sampling enough points in the search space
In general, it can be very difficult to know if the search space has been sampled densely enough. 🤖 Running more trials is better than running fewer trials, but more trials generates an obvious extra cost.
Since it is so hard to know when you have sampled enough, we recommend:
- Sampling what you can afford.
- Calibrating your intuitive confidence from repeatedly looking at various hyperparameter axis plots and trying to get a sense of how many points are in the "good" region of the search space.
Examine the training curves
Summary: Examining the loss curves is an easy way to identify common failure modes and can help you prioritize potential next actions.
In many cases, the primary objective of your experiments only requires considering the validation error of each trial. However, be careful when reducing each trial to a single number because that focus can hide important details about what's going on below the surface. For every study, we strongly recommend looking at the loss curves of at least the best few trials. Even if this is not necessary for addressing the primary experimental objective, examining the loss curves (including both training loss and validation loss) is a good way to identify common failure modes and can help you prioritize what actions to take next.
When examining the loss curves, focus on the following questions:
Are any of the trials exhibiting problematic overfitting? Problematic overfitting occurs when the validation error starts increasing during training. In experimental settings where you optimize away nuisance hyperparameters by selecting the "best" trial for each setting of the scientific hyperparameters, check for problematic overfitting in at least each of the best trials corresponding to the settings of the scientific hyperparameters that you're comparing. If any of the best trials exhibits problematic overfitting, do either or both of the following:
- Rerun the experiment with additional regularization techniques
- Retune the existing regularization parameters before comparing the values of the scientific hyperparameters. This may not apply if the scientific hyperparameters include regularization parameters, since then it wouldn't be surprising if low-strength settings of those regularization parameters resulted in problematic overfitting.
Reducing overfitting is often straightforward using common regularization techniques that add minimal code complexity or extra computation (for example, dropout regularization, label smoothing, weight decay). Therefore, it's usually trivial to add one or more of these to the next round of experiments. For example, if the scientific hyperparameter is "number of hidden layers" and the best trial that uses the largest number of hidden layers exhibits problematic overfitting, then we recommend retrying with additional regularization instead of immediately selecting the smaller number of hidden layers.
Even if none of the "best" trials exhibit problematic overfitting, there might still be a problem if it occurs in any of the trials. Selecting the best trial suppresses configurations exhibiting problematic overfitting and favors those that don't. In other words, selecting the best trial favors configurations with more regularization. However, anything that makes training worse can act as a regularizer, even if it wasn't intended that way. For example, choosing a smaller learning rate can regularize training by hobbling the optimization process, but we typically don't want to choose the learning rate this way. Note that the "best" trial for each setting of the scientific hyperparameters might be selected in such a way that favors "bad" values of some of the scientific or nuisance hyperparameters.
Is there high step-to-step variance in the training or validation error late in training? If so, this could interfere with both of the following:
- Your ability to compare different values of the scientific hyperparameters. That's because each trial randomly ends on a "lucky" or "unlucky" step.
- Your ability to reproduce the result of the best trial in production. That's because the production model might not end on the same "lucky" step as in the study.
The most likely causes of step-to-step variance are:
- Batch variance due to randomly sampling examples from the training set for each batch.
- Small validation sets
- Using a learning rate that's too high late in training.
সম্ভাব্য প্রতিকার অন্তর্ভুক্ত:
- Increasing the batch size.
- Obtaining more validation data.
- Using learning rate decay.
- Using Polyak averaging.
Are the trials still improving at the end of training? If so, you are in the "compute bound" regime and may benefit from increasing the number of training steps or changing the learning rate schedule.
Has performance on the training and validation sets saturated long before the final training step? If so, this indicates that you are in the "not compute-bound" regime and that you may be able to decrease the number of training steps.
Beyond this list, many additional behaviors can become evident from examining the loss curves. For example, training loss increasing during training usually indicates a bug in the training pipeline.
Detecting whether a change is useful with isolation plots
Figure 2: Isolation plot that investigates the best value of weight decay for ResNet-50 trained on ImageNet.
Often, the goal of a set of experiments is to compare different values of a scientific hyperparameter. For example, suppose you want to determine the value of weight decay that results in the best validation error. An isolation plot is a special case of the basic hyperparameter axis plot. Each point on an isolation plot corresponds to the performance of the best trial across some (or all) of the nuisance hyperparameters. In other words, plot the model performance after "optimizing away" the nuisance hyperparameters.
An isolation plot simplifies performing an apples-to-apples comparison between different values of the scientific hyperparameter. For example, the isolation plot in Figure 2 reveals the value of weight decay that produces the best validation performance for a particular configuration of ResNet-50 trained on ImageNet.
If the goal is to determine whether to include weight decay at all, then compare the best point from this plot against the baseline of no weight decay. For a fair comparison, the baseline should also have its learning rate equally well tuned.
When you have data generated by (quasi)random search and are considering a continuous hyperparameter for an isolation plot, you can approximate the isolation plot by bucketing the x-axis values of the basic hyperparameter axis plot and taking the best trial in each vertical slice defined by the buckets.
Automate generically useful plots
The more effort it is to generate plots, the less likely you are to look at them as much as you should. Therefore, we recommend setting up your infrastructure to automatically produce as many plots as possible. At a minimum, we recommend automatically generating basic hyperparameter axis plots for all hyperparameters that you vary in an experiment.
Additionally, we recommend automatically producing loss curves for all trials. Furthermore, we recommend making it as easy as possible to find the best few trials of each study and to examine their loss curves.
You can add many other useful potential plots and visualizations. To paraphrase Geoffrey Hinton :
Every time you plot something new, you learn something new.
Determine whether to adopt the candidate change
Summary: When deciding whether to make a change to our model or training procedure or adopt a new hyperparameter configuration, note the different sources of variation in your results.
When trying to improve a model, a particular candidate change might initially achieve a better validation error compared to an incumbent configuration. However, repeating the experiment might demonstrate no consistent advantage. Informally, the most important sources of inconsistent results can be grouped into the following broad categories:
- Training procedure variance, retrain variance, or trial variance : the variation between training runs that use the same hyperparameters but different random seeds. For example, different random initializations, training data shuffles, dropout masks, patterns of data augmentation operations, and orderings of parallel arithmetic operations are all potential sources of trial variance.
- Hyperparameter search variance, or study variance : the variation in results caused by our procedure to select the hyperparameters. For example, you might run the same experiment with a particular search space but with two different seeds for quasi-random search and end up selecting different hyperparameter values.
- Data collection and sampling variance : the variance from any sort of random split into training, validation, and test data or variance due to the training data generation process more generally.
True, you can compare validation error rates estimated on a finite validation set using fastidious statistical tests. However, often the trial variance alone can produce statistically significant differences between two different trained models that use the same hyperparameter settings.
We are most concerned about study variance when trying to make conclusions that go beyond the level of an individual point in hyperparameters space. The study variance depends on the number of trials and the search space. We have seen cases where the study variance is larger than the trial variance and cases where it is much smaller. Therefore, before adopting a candidate change, consider running the best trial N times to characterize the run-to-run trial variance. Usually, you can get away with only recharacterizing the trial variance after major changes to the pipeline, but you might need fresher estimates in some cases. In other applications, characterizing the trial variance is too costly to be worth it.
Although you only want to adopt changes (including new hyperparameter configurations) that produce real improvements, demanding complete certainty that a given change helps isn't the right answer either. Therefore, if a new hyperparameter point (or other change) gets a better result than the baseline (taking into account the retrain variance of both the new point and the baseline as best as you can), then you probably should adopt it as the new baseline for future comparisons. However, we recommend only adopting changes that produce improvements that outweigh any complexity they add.
After exploration concludes
Summary: Bayesian optimization tools are a compelling option once you're done searching for good search spaces and have decided what hyperparameters are worth tuning.
Eventually, your priorities will shift from learning more about the tuning problem to producing a single best configuration to launch or otherwise use. At that point, there should be a refined search space that comfortably contains the local region around the best observed trial and has been adequately sampled. Your exploration work should have revealed the most essential hyperparameters to tune and their sensible ranges that you can use to construct a search space for a final automated tuning study using as large a tuning budget as possible.
Since you no longer care about maximizing insight into the tuning problem, many of the advantages of quasi-random search no longer apply. Therefore, you should use Bayesian optimization tools to automatically find the best hyperparameter configuration. Open-Source Vizier implements a variety of sophisticated algorithms for tuning ML models, including Bayesian Optimization algorithms.
Suppose the search space contains a non-trivial volume of divergent points , meaning points that get NaN training loss or even training loss many standard deviations worse than the mean. In this case, we recommend using black-box optimization tools that properly handle trials that diverge. (See Bayesian Optimization with Unknown Constraints for an excellent way to deal with this issue.) Open-Source Vizier has supports for marking divergent points by marking trials as infeasible, although it may not use our preferred approach from Gelbart et al. , depending on how it is configured.
After exploration concludes, consider checking the performance on the test set. In principle, you could even fold the validation set into the training set and retrain the best configuration found with Bayesian optimization. However, this is only appropriate if there won't be future launches with this specific workload (for example, a one-time Kaggle competition).
,For the purposes of this document:
The ultimate goal of machine learning development is to maximize the usefulness of the deployed model.
You can typically use the same basic steps and principles in this section on any ML problem.
এই বিভাগটি নিম্নলিখিত অনুমান করে:
- You already have a fully-running training pipeline along with a configuration that obtains a reasonable result.
- You have enough computational resources to conduct meaningful tuning experiments and to run at least several training jobs in parallel.
The incremental tuning strategy
Recommendation: Start with a simple configuration. Then, incrementally make improvements while building up insight into the problem. Make sure that any improvement is based on strong evidence.
We assume that your goal is to find a configuration that maximizes the performance of your model. Sometimes, your goal is to maximize model improvement by a fixed deadline. In other cases, you can keep improving the model indefinitely; for example, continually improving a model used in production.
In principle, you could maximize performance by using an algorithm to automatically search the entire space of possible configurations, but this is not a practical option. The space of possible configurations is extremely large and there are not yet any algorithms sophisticated enough to efficiently search this space without human guidance. Most automated search algorithms rely on a hand-designed search space that defines the set of configurations to search in, and these search spaces can matter quite a bit.
The most effective way to maximize performance is to start with a simple configuration and incrementally add features and make improvements while building up insight into the problem.
We recommend using automated search algorithms in each round of tuning and continually updating search spaces as your understanding grows. As you explore, you will naturally find better and better configurations and therefore your "best" model will continually improve.
The term "launch" refers to an update to our best configuration (which may or may not correspond to an actual launch of a production model). For each "launch," you must ensure that the change is based on strong evidence—not just random chance based on a lucky configuration—so that you don't add unnecessary complexity to the training pipeline.
At a high level, our incremental tuning strategy involves repeating the following four steps:
- Pick a goal for the next round of experiments. Make sure that the goal is appropriately scoped.
- Design the next round of experiments. Design and execute a set of experiments that progresses towards this goal.
- Learn from the experimental results. Evaluate the experiment against a checklist.
- Determine whether to adopt the candidate change.
The remainder of this section details this strategy.
Pick a goal for the next round of experiments
If you try to add multiple features or answer multiple questions at once, you may not be able to disentangle the separate effects on the results. Example goals include:
- Try a potential improvement to the pipeline (for example, a new regularizer, preprocessing choice, etc.).
- Understand the impact of a particular model hyperparameter (for example, the activation function)
- Minimize validation error.
Prioritize long term progress over short term validation error improvements
Summary: Most of the time, your primary goal is to gain insight into the tuning problem.
We recommend spending the majority of your time gaining insight into the problem and comparatively little time greedily focused on maximizing performance on the validation set. In other words, spend most of your time on "exploration" and only a small amount on "exploitation". Understanding the problem is critical to maximize final performance. Prioritizing insight over short term gains helps to:
- Avoid launching unnecessary changes that happened to be present in well-performing runs merely through historical accident.
- Identify which hyperparameters the validation error is most sensitive to, which hyperparameters interact the most and therefore need to be retuned together, and which hyperparameters are relatively insensitive to other changes and can therefore be fixed in future experiments.
- Suggest potential new features to try, such as new regularizers when overfitting is an issue.
- Identify features that don't help and therefore can be removed, reducing the complexity of future experiments.
- Recognize when improvements from hyperparameter tuning have likely saturated.
- Narrow our search spaces around the optimal value to improve tuning efficiency.
Eventually, you'll understand the problem. Then, you can focus purely on the validation error even if the experiments aren't maximally informative about the structure of the tuning problem.
Design the next round of experiments
Summary: Identify which hyperparameters are scientific, nuisance, and fixed hyperparameters for the experimental goal. Create a sequence of studies to compare different values of the scientific hyperparameters while optimizing over the nuisance hyperparameters. Choose the search space of nuisance hyperparameters to balance resource costs with scientific value.
Identify scientific, nuisance, and fixed hyperparameters
For a given goal, all hyperparameters fall into one of the following categories:
- scientific hyperparameters are those whose effect on the model's performance is what you're trying to measure.
- nuisance hyperparameters are those that need to be optimized over in order to fairly compare different values of the scientific hyperparameters. Nuisance hyperparameters are similar to nuisance parameters in statistics.
- fixed hyperparameters have constant values in the current round of experiments. The values of fixed hyperparameters shouldn't change when you compare different values of scientific hyperparameters. By fixing certain hyperparameters for a set of experiments, you must accept that conclusions derived from the experiments might not be valid for other settings of the fixed hyperparameters. In other words, fixed hyperparameters create caveats for any conclusions you draw from the experiments.
For example, suppose your goal is as follows:
Determine whether a model with more hidden layers has lower validation error.
এই ক্ষেত্রে:
- Learning rate is a nuisance hyperparameter because you can only fairly compare models with different numbers of hidden layers if the learning rate is tuned separately for each number of hidden layers. (The optimal learning rate generally depends on the model architecture).
- The activation function could be a fixed hyperparameter if you have determined in prior experiments that the best activation function is not sensitive to model depth. Or, you are willing to limit your conclusions about the number of hidden layers to cover this activation function. Alternatively, it could be a nuisance hyperparameter if you are prepared to tune it separately for each number of hidden layers.
A particular hyperparameter could be a scientific hyperparameter, nuisance hyperparameter, or fixed hyperparameter; the hyperparameter's designation changes depending on the experimental goal. For example, activation function could be any of the following:
- Scientific hyperparameter: Is ReLU or tanh a better choice for our problem?
- Nuisance hyperparameter: Is the best five-layer model better than the best six-layer model when you allow several different possible activation functions?
- Fixed hyperparameter: For ReLU nets, does adding batch normalization in a particular position help?
When designing a new round of experiments:
- Identify the scientific hyperparameters for the experimental goal. (At this stage, you can consider all other hyperparameters to be nuisance hyperparameters.)
- Convert some nuisance hyperparameters into fixed hyperparameters.
With limitless resources, you would leave all non-scientific hyperparameters as nuisance hyperparameters so that the conclusions you draw from your experiments are free from caveats about fixed hyperparameter values. However, the more nuisance hyperparameters you attempt to tune, the greater the risk that you fail to tune them sufficiently well for each setting of the scientific hyperparameters and end up reaching the wrong conclusions from your experiments. As described in a later section , you could counter this risk by increasing the computational budget. However, your maximum resource budget is often less than would be needed to tune all non-scientific hyperparameters.
We recommend converting a nuisance hyperparameter into a fixed hyperparameter when the caveats introduced by fixing it are less burdensome than the cost of including it as a nuisance hyperparameter. The more a nuisance hyperparameter interacts with the scientific hyperparameters, the more damaging to fix its value. For example, the best value of the weight decay strength typically depends on the model size, so comparing different model sizes assuming a single specific value of the weight decay wouldn't be very insightful.
Some optimizer parameters
As a rule of thumb, some optimizer hyperparameters (eg the learning rate, momentum, learning rate schedule parameters, Adam betas etc.) are nuisance hyperparameters because they tend to interact the most with other changes. These optimizer hyperparameters are rarely scientific hyperparameters because a goal like "what is the best learning rate for the current pipeline?" doesn't provide much insight. After all, the best setting could change with the next pipeline change anyway.
You might fix some optimizer hyperparameters occasionally due to resource constraints or particularly strong evidence that they don't interact with the scientific parameters. However, you should generally assume that you must tune optimizer hyperparameters separately to make fair comparisons between different settings of the scientific hyperparameters, and thus shouldn't be fixed. Furthermore, there is no a priori reason to prefer one optimizer hyperparameter value over another; for example, optimizer hyperparameter values don't usually affect the computational cost of forward passes or gradients in any way.
The choice of optimizer
The choice of optimizer is typically either:
- a scientific hyperparameter
- a fixed hyperparameter
An optimizer is a scientific hyperparameter if your experimental goal involves making fair comparisons between two or more different optimizers. যেমন:
Determine which optimizer produces the lowest validation error in a given number of steps.
Alternatively, you might make the optimizer a fixed hyperparameter for a variety of reasons, including:
- Prior experiments suggest that the best optimizer for your tuning problem is not sensitive to current scientific hyperparameters.
- You prefer to compare values of the scientific hyperparameters using this optimizer because its training curves are easier to reason about.
- You prefer to use this optimizer because it uses less memory than the alternatives.
Regularization hyperparameters
Hyperparameters introduced by a regularization technique are typically nuisance hyperparameters. However, the choice of whether or not to include the regularization technique at all is either a scientific or fixed hyperparameter.
For example, dropout regularization adds code complexity. Therefore, when deciding whether to include dropout regularization, you could make "no dropout" vs "dropout" a scientific hyperparameter but dropout rate a nuisance hyperparameter. If you decide to add dropout regularization to the pipeline based on this experiment, then the dropout rate would be a nuisance hyperparameter in future experiments.
Architectural hyperparameters
Architectural hyperparameters are often scientific or fixed hyperparameters because architecture changes can affect serving and training costs, latency, and memory requirements. For example, the number of layers is typically a scientific or fixed hyperparameter since it tends to have dramatic consequences for training speed and memory usage.
Dependencies on scientific hyperparameters
In some cases, the sets of nuisance and fixed hyperparameters depends on the values of the scientific hyperparameters. For example, suppose you are trying to determine which optimizer in Nesterov momentum and Adam produces in the lowest validation error. এই ক্ষেত্রে:
- The scientific hyperparameter is the optimizer, which takes values
{"Nesterov_momentum", "Adam"} - The value
optimizer="Nesterov_momentum"introduces the hyperparameters{learning_rate, momentum}, which might be either nuisance or fixed hyperparameters. - The value
optimizer="Adam"introduces the hyperparameters{learning_rate, beta1, beta2, epsilon}, which might be either nuisance or fixed hyperparameters.
Hyperparameters that are only present for certain values of the scientific hyperparameters are called conditional hyperparameters . Don't assume two conditional hyperparameters are the same just because they have the same name! In the preceding example, the conditional hyperparameter called learning_rate is a different hyperparameter for optimizer="Nesterov_momentum" than for optimizer="Adam" . Its role is similar (although not identical) in the two algorithms, but the range of values that work well in each of the optimizers is typically different by several orders of magnitude.
Create a set of studies
After identifying the scientific and nuisance hyperparameters, you should design a study or sequence of studies to make progress towards the experimental goal. A study specifies a set of hyperparameter configurations to be run for subsequent analysis. Each configuration is called a trial . Creating a study typically involves choosing the following:
- The hyperparameters that vary across trials.
- The values those hyperparameters can take on (the search space ).
- The number of trials.
- An automated search algorithm to sample that many trials from the search space.
Alternatively, you can create a study by specifying the set of hyperparameter configurations manually.
The purpose of the studies is to simultaneously:
- Run the pipeline with different values of the scientific hyperparameters.
- "Optimizing away" (or "optimizing over") the nuisance hyperparameters so that comparisons between different values of the scientific hyperparameters are as fair as possible.
In the simplest case, you would make a separate study for each configuration of the scientific parameters, where each study tunes over the nuisance hyperparameters. For example, if your goal is to select the best optimizer out of Nesterov momentum and Adam, you could create two studies:
- One study in which
optimizer="Nesterov_momentum"and the nuisance hyperparameters are{learning_rate, momentum} - Another study in which
optimizer="Adam"and the nuisance hyperparameters are{learning_rate, beta1, beta2, epsilon}.
You would compare the two optimizers by selecting the best performing trial from each study.
You can use any gradient-free optimization algorithm, including methods such as Bayesian optimization or evolutionary algorithms, to optimize over the nuisance hyperparameters. However, we prefer to use quasi-random search in the exploration phase of tuning because of a variety of advantages it has in this setting. After exploration concludes, we recommend using state-of-the-art Bayesian optimization software (if it is available).
Consider a more complicated case where you want to compare a large number of values of the scientific hyperparameters but it is impractical to make that many independent studies. In this case, you can do the following:
- Include the scientific parameters in the same search space as the nuisance hyperparameters.
- Use a search algorithm to sample values of both the scientific and nuisance hyperparameters in a single study.
When taking this approach, conditional hyperparameters can cause problems. After all, it is hard to specify a search space unless the set of nuisance hyperparameters is the same for all values of the scientific hyperparameters. In this case, our preference for using quasi-random search over fancier black-box optimization tools is even stronger, since it guarantees different values of the scientific hyperparameters will be sampled uniformly. Regardless of the search algorithm, ensure that it searches the scientific parameters uniformly.
Strike a balance between informative and affordable experiments
When designing a study or sequence of studies, allocate a limited budget to adequately achieve the following three goals:
- Comparing enough different values of the scientific hyperparameters.
- Tuning the nuisance hyperparameters over a large enough search space.
- Sampling the search space of nuisance hyperparameters densely enough.
The better you can achieve these three goals, the more insight you can extract from the experiment. Comparing as many values of the scientific hyperparameters as possible broadens the scope of the insights you gain from the experiment.
Including as many nuisance hyperparameters as possible and allowing each nuisance hyperparameter to vary over as wide a range as possible increases confidence that a "good" value of the nuisance hyperparameters exists in the search space for each configuration of the scientific hyperparameters. Otherwise, you might make unfair comparisons between values of the scientific hyperparameters by not searching possible regions of the nuisance hyperparameter space where better values might lie for some values of the scientific parameters.
Sample the search space of nuisance hyperparameters as densely as possible. Doing so increases confidence that the search procedure will find any good settings for the nuisance hyperparameters that happen to exist in your search space. Otherwise, you might make unfair comparisons between values of the scientific parameters due to some values getting luckier with the sampling of the nuisance hyperparameters.
Unfortunately, improvements in any of these three dimensions require either of the following:
- Increasing the number of trials, and therefore increasing the resource cost.
- Finding a way to save resources in one of the other dimensions.
Every problem has its own idiosyncrasies and computational constraints, so allocating resources across these three goals requires some level of domain knowledge. After running a study, always try to get a sense of whether the study tuned the nuisance hyperparameters well enough. That is, the study searched a large enough space extensively enough to fairly compare the scientific hyperparameters (as described in greater detail in the next section).
Learn from the experimental results
Recommendation: In addition to trying to achieve the original scientific goal of each group of experiments, go through a checklist of additional questions. If you discover issues, revise and rerun the experiments.
Ultimately, each group of experiments has a specific goal. You should evaluate the evidence the experiments provide toward that goal. However, if you ask the right questions, you can often find issues to correct before a given set of experiments can progress towards their original goal. If you don't ask these questions, you may draw incorrect conclusions.
Since running experiments can be expensive, you should also extract other useful insights from each group of experiments, even if these insights are not immediately relevant to the current goal.
Before analyzing a given set of experiments to make progress toward their original goal, ask yourself the following additional questions:
- Is the search space large enough? If the optimal point from a study is near the boundary of the search space in one or more dimensions, the search is probably not wide enough. In this case, run another study with an expanded search space.
- Have you sampled enough points from the search space? If not, run more points or be less ambitious in the tuning goals.
- What fraction of the trials in each study are infeasible? That is, which trials diverge, get really bad loss values, or fail to run at all because they violate some implicit constraint? When a very large fraction of points in a study are infeasible, adjust the search space to avoid sampling such points, which sometimes requires reparameterizing the search space. In some cases, a large number of infeasible points can indicate a bug in the training code.
- Does the model exhibit optimization issues?
- What can you learn from the training curves of the best trials? For example, do the best trials have training curves consistent with problematic overfitting?
If necessary, based on the answers to the preceding questions, refine the most recent study or group of studies to improve the search space and/or sample more trials, or take some other corrective action.
Once you have answered the preceding questions, you can evaluate the evidence the experiments provide towards your original goal; for example, evaluating whether a change is useful .
Identify bad search space boundaries
A search space is suspicious if the best point sampled from it is close to its boundary. You might find an even better point if you expand the search range in that direction.
To check search space boundaries, we recommend plotting completed trials on what we call basic hyperparameter axis plots . In these, we plot the validation objective value versus one of the hyperparameters (for example, learning rate). Each point on the plot corresponds to a single trial.
The validation objective value for each trial should usually be the best value it achieved over the course of training.
Figure 1: Examples of bad search space boundaries and acceptable search space boundaries.
The plots in Figure 1 show the error rate (lower is better) against the initial learning rate. If the best points cluster towards the edge of a search space (in some dimension), then you might need to expand the search space boundaries until the best observed point is no longer close to the boundary.
Often, a study includes "infeasible" trials that diverge or get very bad results (marked with red Xs in Figure 1). If all trials are infeasible for learning rates greater than some threshold value, and if the best performing trials have learning rates at the edge of that region, the model may suffer from stability issues preventing it from accessing higher learning rates .
Not sampling enough points in the search space
In general, it can be very difficult to know if the search space has been sampled densely enough. 🤖 Running more trials is better than running fewer trials, but more trials generates an obvious extra cost.
Since it is so hard to know when you have sampled enough, we recommend:
- Sampling what you can afford.
- Calibrating your intuitive confidence from repeatedly looking at various hyperparameter axis plots and trying to get a sense of how many points are in the "good" region of the search space.
Examine the training curves
Summary: Examining the loss curves is an easy way to identify common failure modes and can help you prioritize potential next actions.
In many cases, the primary objective of your experiments only requires considering the validation error of each trial. However, be careful when reducing each trial to a single number because that focus can hide important details about what's going on below the surface. For every study, we strongly recommend looking at the loss curves of at least the best few trials. Even if this is not necessary for addressing the primary experimental objective, examining the loss curves (including both training loss and validation loss) is a good way to identify common failure modes and can help you prioritize what actions to take next.
When examining the loss curves, focus on the following questions:
Are any of the trials exhibiting problematic overfitting? Problematic overfitting occurs when the validation error starts increasing during training. In experimental settings where you optimize away nuisance hyperparameters by selecting the "best" trial for each setting of the scientific hyperparameters, check for problematic overfitting in at least each of the best trials corresponding to the settings of the scientific hyperparameters that you're comparing. If any of the best trials exhibits problematic overfitting, do either or both of the following:
- Rerun the experiment with additional regularization techniques
- Retune the existing regularization parameters before comparing the values of the scientific hyperparameters. This may not apply if the scientific hyperparameters include regularization parameters, since then it wouldn't be surprising if low-strength settings of those regularization parameters resulted in problematic overfitting.
Reducing overfitting is often straightforward using common regularization techniques that add minimal code complexity or extra computation (for example, dropout regularization, label smoothing, weight decay). Therefore, it's usually trivial to add one or more of these to the next round of experiments. For example, if the scientific hyperparameter is "number of hidden layers" and the best trial that uses the largest number of hidden layers exhibits problematic overfitting, then we recommend retrying with additional regularization instead of immediately selecting the smaller number of hidden layers.
Even if none of the "best" trials exhibit problematic overfitting, there might still be a problem if it occurs in any of the trials. Selecting the best trial suppresses configurations exhibiting problematic overfitting and favors those that don't. In other words, selecting the best trial favors configurations with more regularization. However, anything that makes training worse can act as a regularizer, even if it wasn't intended that way. For example, choosing a smaller learning rate can regularize training by hobbling the optimization process, but we typically don't want to choose the learning rate this way. Note that the "best" trial for each setting of the scientific hyperparameters might be selected in such a way that favors "bad" values of some of the scientific or nuisance hyperparameters.
Is there high step-to-step variance in the training or validation error late in training? If so, this could interfere with both of the following:
- Your ability to compare different values of the scientific hyperparameters. That's because each trial randomly ends on a "lucky" or "unlucky" step.
- Your ability to reproduce the result of the best trial in production. That's because the production model might not end on the same "lucky" step as in the study.
The most likely causes of step-to-step variance are:
- Batch variance due to randomly sampling examples from the training set for each batch.
- Small validation sets
- Using a learning rate that's too high late in training.
সম্ভাব্য প্রতিকার অন্তর্ভুক্ত:
- Increasing the batch size.
- Obtaining more validation data.
- Using learning rate decay.
- Using Polyak averaging.
Are the trials still improving at the end of training? If so, you are in the "compute bound" regime and may benefit from increasing the number of training steps or changing the learning rate schedule.
Has performance on the training and validation sets saturated long before the final training step? If so, this indicates that you are in the "not compute-bound" regime and that you may be able to decrease the number of training steps.
Beyond this list, many additional behaviors can become evident from examining the loss curves. For example, training loss increasing during training usually indicates a bug in the training pipeline.
Detecting whether a change is useful with isolation plots
Figure 2: Isolation plot that investigates the best value of weight decay for ResNet-50 trained on ImageNet.
Often, the goal of a set of experiments is to compare different values of a scientific hyperparameter. For example, suppose you want to determine the value of weight decay that results in the best validation error. An isolation plot is a special case of the basic hyperparameter axis plot. Each point on an isolation plot corresponds to the performance of the best trial across some (or all) of the nuisance hyperparameters. In other words, plot the model performance after "optimizing away" the nuisance hyperparameters.
An isolation plot simplifies performing an apples-to-apples comparison between different values of the scientific hyperparameter. For example, the isolation plot in Figure 2 reveals the value of weight decay that produces the best validation performance for a particular configuration of ResNet-50 trained on ImageNet.
If the goal is to determine whether to include weight decay at all, then compare the best point from this plot against the baseline of no weight decay. For a fair comparison, the baseline should also have its learning rate equally well tuned.
When you have data generated by (quasi)random search and are considering a continuous hyperparameter for an isolation plot, you can approximate the isolation plot by bucketing the x-axis values of the basic hyperparameter axis plot and taking the best trial in each vertical slice defined by the buckets.
Automate generically useful plots
The more effort it is to generate plots, the less likely you are to look at them as much as you should. Therefore, we recommend setting up your infrastructure to automatically produce as many plots as possible. At a minimum, we recommend automatically generating basic hyperparameter axis plots for all hyperparameters that you vary in an experiment.
Additionally, we recommend automatically producing loss curves for all trials. Furthermore, we recommend making it as easy as possible to find the best few trials of each study and to examine their loss curves.
You can add many other useful potential plots and visualizations. To paraphrase Geoffrey Hinton :
Every time you plot something new, you learn something new.
Determine whether to adopt the candidate change
Summary: When deciding whether to make a change to our model or training procedure or adopt a new hyperparameter configuration, note the different sources of variation in your results.
When trying to improve a model, a particular candidate change might initially achieve a better validation error compared to an incumbent configuration. However, repeating the experiment might demonstrate no consistent advantage. Informally, the most important sources of inconsistent results can be grouped into the following broad categories:
- Training procedure variance, retrain variance, or trial variance : the variation between training runs that use the same hyperparameters but different random seeds. For example, different random initializations, training data shuffles, dropout masks, patterns of data augmentation operations, and orderings of parallel arithmetic operations are all potential sources of trial variance.
- Hyperparameter search variance, or study variance : the variation in results caused by our procedure to select the hyperparameters. For example, you might run the same experiment with a particular search space but with two different seeds for quasi-random search and end up selecting different hyperparameter values.
- Data collection and sampling variance : the variance from any sort of random split into training, validation, and test data or variance due to the training data generation process more generally.
True, you can compare validation error rates estimated on a finite validation set using fastidious statistical tests. However, often the trial variance alone can produce statistically significant differences between two different trained models that use the same hyperparameter settings.
We are most concerned about study variance when trying to make conclusions that go beyond the level of an individual point in hyperparameters space. The study variance depends on the number of trials and the search space. We have seen cases where the study variance is larger than the trial variance and cases where it is much smaller. Therefore, before adopting a candidate change, consider running the best trial N times to characterize the run-to-run trial variance. Usually, you can get away with only recharacterizing the trial variance after major changes to the pipeline, but you might need fresher estimates in some cases. In other applications, characterizing the trial variance is too costly to be worth it.
Although you only want to adopt changes (including new hyperparameter configurations) that produce real improvements, demanding complete certainty that a given change helps isn't the right answer either. Therefore, if a new hyperparameter point (or other change) gets a better result than the baseline (taking into account the retrain variance of both the new point and the baseline as best as you can), then you probably should adopt it as the new baseline for future comparisons. However, we recommend only adopting changes that produce improvements that outweigh any complexity they add.
After exploration concludes
Summary: Bayesian optimization tools are a compelling option once you're done searching for good search spaces and have decided what hyperparameters are worth tuning.
Eventually, your priorities will shift from learning more about the tuning problem to producing a single best configuration to launch or otherwise use. At that point, there should be a refined search space that comfortably contains the local region around the best observed trial and has been adequately sampled. Your exploration work should have revealed the most essential hyperparameters to tune and their sensible ranges that you can use to construct a search space for a final automated tuning study using as large a tuning budget as possible.
Since you no longer care about maximizing insight into the tuning problem, many of the advantages of quasi-random search no longer apply. Therefore, you should use Bayesian optimization tools to automatically find the best hyperparameter configuration. Open-Source Vizier implements a variety of sophisticated algorithms for tuning ML models, including Bayesian Optimization algorithms.
Suppose the search space contains a non-trivial volume of divergent points , meaning points that get NaN training loss or even training loss many standard deviations worse than the mean. In this case, we recommend using black-box optimization tools that properly handle trials that diverge. (See Bayesian Optimization with Unknown Constraints for an excellent way to deal with this issue.) Open-Source Vizier has supports for marking divergent points by marking trials as infeasible, although it may not use our preferred approach from Gelbart et al. , depending on how it is configured.
After exploration concludes, consider checking the performance on the test set. In principle, you could even fold the validation set into the training set and retrain the best configuration found with Bayesian optimization. However, this is only appropriate if there won't be future launches with this specific workload (for example, a one-time Kaggle competition).