Para os fins deste documento:
O objetivo final do desenvolvimento de machine learning é maximizar a utilidade do modelo implantado.
Normalmente, é possível usar as mesmas etapas e princípios básicos desta seção em qualquer problema de ML.
Esta seção parte das seguintes premissas:
- Você já tem um pipeline de treinamento em execução completa e uma configuração que gera um resultado razoável.
- Você tem recursos computacionais suficientes para realizar experimentos de ajuste significativos e executar pelo menos vários jobs de treinamento em paralelo.
A estratégia de ajuste incremental
Recomendação: comece com uma configuração simples. Em seguida, faça melhorias incrementais enquanto desenvolve um insight sobre o problema. Verifique se as melhorias são baseadas em evidências sólidas.
Presumimos que sua meta é encontrar uma configuração que maximize a performance do modelo. Às vezes, o objetivo é maximizar a melhoria do modelo até um prazo fixo. Em outros casos, é possível continuar melhorando o modelo indefinidamente, por exemplo, aprimorando continuamente um modelo usado na produção.
Em princípio, você pode maximizar a performance usando um algoritmo para pesquisar automaticamente todo o espaço de possíveis configurações, mas essa não é uma opção prática. O espaço de configurações possíveis é extremamente grande, e ainda não há algoritmos sofisticados o suficiente para pesquisar esse espaço de maneira eficiente sem orientação humana. A maioria dos algoritmos de pesquisa automatizados depende de um espaço de pesquisa projetado manualmente que define o conjunto de configurações a serem pesquisadas. Esses espaços podem ser muito importantes.
A maneira mais eficaz de maximizar a performance é começar com uma configuração simples e adicionar recursos e melhorias de forma incremental à medida que você entende melhor o problema.
Recomendamos usar algoritmos de pesquisa automatizados em cada rodada de ajuste e atualizar continuamente os espaços de pesquisa à medida que você entende melhor o problema. Ao explorar, você vai encontrar configurações cada vez melhores e, portanto, seu modelo "ideal" vai melhorar continuamente.
O termo "lançamento" se refere a uma atualização da nossa melhor configuração, que pode ou não corresponder ao lançamento real de um modelo de produção. Para cada "lançamento", verifique se a mudança é baseada em evidências sólidas, não apenas em uma chance aleatória com base em uma configuração de sorte, para não adicionar complexidade desnecessária ao pipeline de treinamento.
Em geral, nossa estratégia de ajuste incremental envolve repetir as quatro etapas a seguir:
- Escolha uma meta para a próxima rodada de experimentos. Verifique se o escopo da meta está adequado.
- Crie a próxima rodada de experimentos. Projete e execute um conjunto de experimentos que avance em direção a essa meta.
- Aprenda com os resultados experimentais. Avalie o experimento em relação a uma lista de verificação.
- Determine se a mudança de candidato será adotada.
O restante desta seção detalha essa estratégia.
Escolha uma meta para a próxima rodada de experimentos
Se você tentar adicionar vários recursos ou responder a várias perguntas de uma vez, talvez não seja possível separar os efeitos nos resultados. Exemplos de metas:
- Teste uma possível melhoria no pipeline (por exemplo, um novo regularizador, uma opção de pré-processamento etc.).
- Entender o impacto de um hiperparâmetro específico do modelo (por exemplo, a função de ativação)
- Minimizar o erro de validação.
Priorize o progresso de longo prazo em vez de melhorias de erros de validação de curto prazo
Resumo: na maioria das vezes, o objetivo principal é entender o problema de ajuste.
Recomendamos que você passe a maior parte do tempo entendendo o problema e relativamente pouco tempo focado em maximizar a performance no conjunto de validação. Em outras palavras, passe a maior parte do tempo na "exploração" e apenas uma pequena parte na "explotação". Entender o problema é fundamental para maximizar a performance final. Priorizar insights em vez de ganhos de curto prazo ajuda a:
- Evite lançar mudanças desnecessárias que estavam presentes em execuções de bom desempenho por acaso.
- Identifique a quais hiperparâmetros o erro de validação é mais sensível, quais hiperparâmetros interagem mais e, portanto, precisam ser reajustados juntos, e quais hiperparâmetros são relativamente insensíveis a outras mudanças e, portanto, podem ser corrigidos em experimentos futuros.
- Sugerir novos recursos para testar, como novos regularizadores quando o overfitting é um problema.
- Identifique recursos que não ajudam e, portanto, podem ser removidos, reduzindo a complexidade de experimentos futuros.
- Reconhecer quando as melhorias do ajuste de hiperparâmetros provavelmente atingiram o limite.
- Reduzimos nossos espaços de pesquisa em torno do valor ideal para melhorar a eficiência do ajuste.
Eventualmente, você vai entender o problema. Assim, você pode se concentrar apenas no erro de validação, mesmo que os experimentos não sejam totalmente informativos sobre a estrutura do problema de ajuste.
Projetar a próxima rodada de experimentos
Resumo: identifique quais hiperparâmetros são científicos, de ruído e fixos para a meta experimental. Crie uma sequência de estudos para comparar diferentes valores dos hiperparâmetros científicos e otimizar os hiperparâmetros de ruído. Escolha o espaço de pesquisa de hiperparâmetros de ruído para equilibrar os custos de recursos com o valor científico.
Identificar hiperparâmetros científicos, de ruído e fixos
Para uma determinada meta, todos os hiperparâmetros se enquadram em uma das seguintes categorias:
- Os hiperparâmetros científicos são aqueles cujo efeito no desempenho do modelo é o que você está tentando medir.
- Os hiperparâmetros de ruído são aqueles que precisam ser otimizados para comparar diferentes valores dos hiperparâmetros científicos. Hiperparâmetros de ruído são semelhantes a parâmetros de ruído em estatística.
- hiperparâmetros fixos têm valores constantes na rodada atual de experimentos. Os valores dos hiperparâmetros fixos não devem mudar ao comparar valores diferentes de hiperparâmetros científicos. Ao fixar determinados hiperparâmetros para um conjunto de experimentos, você precisa aceitar que as conclusões derivadas dos experimentos podem não ser válidas para outras configurações dos hiperparâmetros fixos. Em outras palavras, hiperparâmetros fixos criam ressalvas para qualquer conclusão que você tire dos experimentos.
Por exemplo, suponha que sua meta seja:
Determine se um modelo com mais camadas ocultas tem um erro de validação menor.
Neste caso:
- A taxa de aprendizado é um hiperparâmetro problemático porque só é possível comparar modelos com diferentes números de camadas ocultas se a taxa de aprendizado for ajustada separadamente para cada número de camadas ocultas. A taxa de aprendizado ideal geralmente depende da arquitetura do modelo.
- A função de ativação pode ser um hiperparâmetro fixo se você tiver determinado em experimentos anteriores que a melhor função de ativação não é sensível à profundidade do modelo. Ou você está disposto a limitar suas conclusões sobre o número de camadas ocultas para abranger essa função de ativação. Como alternativa, ele pode ser um hiperparâmetro de nuisance se você estiver preparado para ajustá-lo separadamente para cada número de camadas ocultas.
Um hiperparâmetro específico pode ser científico, de ruído ou fixo. A designação muda dependendo da meta experimental. Por exemplo, a função de ativação pode ser uma destas opções:
- Hiperparâmetro científico: ReLU ou tanh é uma opção melhor para nosso problema?
- Hiperparâmetro de ruído: o melhor modelo de cinco camadas é melhor do que o melhor modelo de seis camadas quando você permite várias funções de ativação possíveis diferentes?
- Hiperparâmetro fixo: para redes ReLU, adicionar normalização em lote em uma posição específica ajuda?
Ao criar uma nova rodada de experimentos:
- Identifique os hiperparâmetros científicos para a meta experimental. Nesta etapa, considere todos os outros hiperparâmetros como hiperparâmetros de ruído.
- Converter alguns hiperparâmetros de ruído em hiperparâmetros fixos.
Com recursos ilimitados, você deixaria todos os hiperparâmetros não científicos como hiperparâmetros de ruído para que as conclusões dos experimentos não tenham ressalvas sobre valores fixos de hiperparâmetros. No entanto, quanto mais hiperparâmetros de ruído você tentar ajustar, maior será o risco de não conseguir ajustá-los bem o suficiente para cada configuração dos hiperparâmetros científicos e acabar chegando a conclusões erradas nos experimentos. Conforme descrito em uma seção posterior, é possível reduzir esse risco aumentando o orçamento computacional. No entanto, seu orçamento máximo de recursos geralmente é menor do que o necessário para ajustar todos os hiperparâmetros não científicos.
Recomendamos converter um hiperparâmetro de incômodo em um hiperparâmetro fixo quando as ressalvas introduzidas pela fixação são menos onerosas do que o custo de incluí-lo como um hiperparâmetro de incômodo. Quanto mais um hiperparâmetro de ruído interage com os hiperparâmetros científicos, mais prejudicial é fixar o valor dele. Por exemplo, o melhor valor da intensidade do decaimento de peso geralmente depende do tamanho do modelo. Portanto, comparar tamanhos diferentes de modelo usando um único valor específico de decaimento de peso não seria muito útil.
Alguns parâmetros do otimizador
Como regra geral, alguns hiperparâmetros do otimizador (por exemplo, taxa de aprendizado, momentum, parâmetros de programação da taxa de aprendizado, betas de Adam etc.) são hiperparâmetros de incômodo porque tendem a interagir mais com outras mudanças. Esses hiperparâmetros do otimizador raramente são científicos porque uma meta como "qual é a melhor taxa de aprendizado para o pipeline atual?" não oferece muita informação. Afinal, a melhor configuração pode mudar com a próxima alteração no pipeline.
Às vezes, você pode corrigir alguns hiperparâmetros do otimizador devido a restrições de recursos ou evidências particularmente fortes de que eles não interagem com os parâmetros científicos. No entanto, geralmente é preciso ajustar os hiperparâmetros do otimizador separadamente para fazer comparações justas entre diferentes configurações dos hiperparâmetros científicos. Portanto, eles não devem ser fixos. Além disso, não há um motivo a priori para preferir um valor de hiperparâmetro de otimizador em vez de outro. Por exemplo, os valores de hiperparâmetro de otimizador geralmente não afetam o custo computacional de transmissões diretas ou gradientes de forma alguma.
A escolha do otimizador
A escolha do otimizador geralmente é:
- um hiperparâmetro científico
- um hiperparâmetro fixo
Um otimizador é um hiperparâmetro científico se a meta experimental envolver comparações justas entre dois ou mais otimizadores diferentes. Exemplo:
Determine qual otimizador produz o menor erro de validação em um determinado número de etapas.
Como alternativa, você pode tornar o otimizador um hiperparâmetro fixo por vários motivos, incluindo:
- Experimentos anteriores sugerem que o melhor otimizador para seu problema de ajuste não é sensível aos hiperparâmetros científicos atuais.
- Você prefere comparar valores dos hiperparâmetros científicos usando esse otimizador porque as curvas de treinamento dele são mais fáceis de entender.
- Você prefere usar esse otimizador porque ele usa menos memória do que as alternativas.
Hiperparâmetros de regularização
Os hiperparâmetros introduzidos por uma técnica de regularização são geralmente hiperparâmetros de ruído. No entanto, a escolha de incluir ou não a técnica de regularização é um hiperparâmetro científico ou fixo.
Por exemplo, a regularização de dropout aumenta a complexidade do código. Portanto, ao decidir se incluirá a regularização de dropout, você pode transformar "sem dropout" x "com dropout" em um hiperparâmetro científico, mas a taxa de dropout em um hiperparâmetro de incômodo. Se você decidir adicionar a regularização de dropout ao pipeline com base nesse experimento, a taxa de dropout será um hiperparâmetro de nuisance em experimentos futuros.
Hiperparâmetros arquitetônicos
Os hiperparâmetros arquitetônicos geralmente são científicos ou fixos porque as mudanças na arquitetura podem afetar os custos de disponibilização e treinamento, a latência e os requisitos de memória. Por exemplo, o número de camadas geralmente é um hiperparâmetro científico ou fixo, já que tende a ter consequências drásticas para a velocidade de treinamento e o uso de memória.
Dependências de hiperparâmetros científicos
Em alguns casos, os conjuntos de hiperparâmetros fixos e de ruído dependem dos valores dos hiperparâmetros científicos. Por exemplo, suponha que você esteja tentando determinar qual otimizador em Nesterov momentum e Adam produz o menor erro de validação. Neste caso:
- O hiperparâmetro científico é o otimizador, que usa valores
{"Nesterov_momentum", "Adam"} - O valor
optimizer="Nesterov_momentum"apresenta os hiperparâmetros{learning_rate, momentum}, que podem ser de incômodo ou fixos. - O valor
optimizer="Adam"apresenta os hiperparâmetros{learning_rate, beta1, beta2, epsilon}, que podem ser de incômodo ou fixos.
Os hiperparâmetros que estão presentes apenas para determinados valores dos hiperparâmetros científicos são chamados de hiperparâmetros condicionais.
Não suponha que dois hiperparâmetros condicionais sejam iguais só porque têm o mesmo nome. No exemplo anterior, o hiperparâmetro condicional chamado learning_rate é diferente para optimizer="Nesterov_momentum" e optimizer="Adam". A função é semelhante (embora não idêntica) nos dois algoritmos, mas o intervalo de valores que funcionam bem em cada um dos otimizadores geralmente é diferente em várias ordens de magnitude.
Criar um conjunto de estudos
Depois de identificar os hiperparâmetros científicos e de ruído, crie um estudo ou uma sequência de estudos para avançar em direção à meta experimental. Um estudo especifica um conjunto de configurações de hiperparâmetros a serem executadas para análise subsequente. Cada configuração é chamada de teste. Para criar um estudo, geralmente é necessário escolher o seguinte:
- Os hiperparâmetros que variam entre os testes.
- Os valores que esses hiperparâmetros podem assumir (o espaço de pesquisa).
- O número de tentativas.
- Um algoritmo de pesquisa automatizada para fazer amostragem de tantas tentativas no espaço de pesquisa.
Como alternativa, é possível criar um estudo especificando manualmente o conjunto de configurações de hiperparâmetros.
O objetivo dos estudos é simultaneamente:
- Execute o pipeline com diferentes valores dos hiperparâmetros científicos.
- "Otimizar" (ou "otimizar em relação a") os hiperparâmetros de ruído para que as comparações entre diferentes valores dos hiperparâmetros científicos sejam as mais justas possível.
No caso mais simples, você faria um estudo separado para cada configuração dos parâmetros científicos, em que cada estudo ajusta os hiperparâmetros de ruído. Por exemplo, se sua meta for selecionar o melhor otimizador entre o momentum de Nesterov e o Adam, crie dois estudos:
- Um estudo em que
optimizer="Nesterov_momentum"e os hiperparâmetros de ruído são{learning_rate, momentum} - Outro estudo em que
optimizer="Adam"e os hiperparâmetros de ruído são{learning_rate, beta1, beta2, epsilon}.
Para comparar os dois otimizadores, selecione o teste com melhor performance de cada estudo.
Você pode usar qualquer algoritmo de otimização sem gradiente, incluindo métodos como otimização bayesiana ou algoritmos evolutivos, para otimizar os hiperparâmetros de ruído. No entanto, preferimos usar a pesquisa quase aleatória na fase de exploração do ajuste por causa de várias vantagens que ela tem nessa configuração. Depois que a análise terminar, recomendamos usar um software de otimização bayesiana de última geração, se disponível.
Considere um caso mais complicado em que você quer comparar um grande número de valores dos hiperparâmetros científicos, mas não é prático fazer tantos estudos independentes. Nesse caso, faça o seguinte:
- Inclua os parâmetros científicos no mesmo espaço de pesquisa que os hiperparâmetros de ruído.
- Use um algoritmo de pesquisa para fazer amostragem de valores dos hiperparâmetros científicos e de ruído em um único estudo.
Ao adotar essa abordagem, os hiperparâmetros condicionais podem causar problemas. Afinal, é difícil especificar um espaço de pesquisa, a menos que o conjunto de hiperparâmetros de ruído seja o mesmo para todos os valores dos hiperparâmetros científicos. Nesse caso, nossa preferência por usar a pesquisa quase aleatória em vez de ferramentas de otimização de caixa preta mais sofisticadas é ainda maior, já que ela garante que diferentes valores dos hiperparâmetros científicos sejam amostrados de maneira uniforme. Independente do algoritmo de pesquisa, verifique se ele pesquisa os parâmetros científicos de maneira uniforme.
Encontre um equilíbrio entre experimentos informativos e acessíveis
Ao planejar um estudo ou uma sequência de estudos, aloque um orçamento limitado para alcançar adequadamente as três metas a seguir:
- Comparar valores diferentes suficientes dos hiperparâmetros científicos.
- Ajustar os hiperparâmetros de ruído em um espaço de pesquisa grande o suficiente.
- Amostrar o espaço de pesquisa de hiperparâmetros de ruído de maneira densa o suficiente.
Quanto melhor você alcançar essas três metas, mais insights poderá extrair do experimento. Comparar o maior número possível de valores dos hiperparâmetros científicos amplia o escopo dos insights que você recebe do experimento.
Incluir o maior número possível de hiperparâmetros de ruído e permitir que cada um varie em um intervalo o mais amplo possível aumenta a confiança de que um valor "bom" dos hiperparâmetros de ruído existe no espaço de pesquisa para cada configuração dos hiperparâmetros científicos. Caso contrário, você pode fazer comparações injustas entre valores dos hiperparâmetros científicos ao não pesquisar possíveis regiões do espaço de hiperparâmetros de ruído em que valores melhores podem estar para alguns valores dos parâmetros científicos.
Faça uma amostragem do espaço de pesquisa de hiperparâmetros de ruído o mais densamente possível. Isso aumenta a confiança de que o procedimento de pesquisa vai encontrar boas configurações para os hiperparâmetros de ruído que existem no espaço de pesquisa. Caso contrário, você pode fazer comparações injustas entre valores dos parâmetros científicos porque alguns valores têm mais sorte com a amostragem dos hiperparâmetros de confusão.
Infelizmente, melhorias em qualquer uma dessas três dimensões exigem uma das seguintes opções:
- Aumentar o número de testes e, portanto, o custo dos recursos.
- Encontrar uma maneira de economizar recursos em uma das outras dimensões.
Cada problema tem suas próprias idiossincrasias e restrições computacionais. Por isso, alocar recursos para essas três metas exige um certo nível de conhecimento do domínio. Depois de executar um estudo, sempre tente entender se ele ajustou bem os hiperparâmetros de ruído. Ou seja, o estudo pesquisou um espaço grande o suficiente para comparar de maneira justa os hiperparâmetros científicos (descritos com mais detalhes na próxima seção).
Aprenda com os resultados experimentais
Recomendação: além de tentar alcançar a meta científica original de cada grupo de experimentos, passe por uma lista de verificação de outras perguntas. Se você encontrar problemas, revise e execute os experimentos novamente.
Cada grupo de experimentos tem uma meta específica. Avalie as evidências que os experimentos fornecem para essa meta. No entanto, se você fizer as perguntas certas, poderá encontrar problemas para corrigir antes que um determinado conjunto de experimentos avance em direção à meta original. Se você não fizer essas perguntas, poderá tirar conclusões incorretas.
Como a execução de experimentos pode ser cara, extraia outros insights úteis de cada grupo, mesmo que eles não sejam relevantes para a meta atual.
Antes de analisar um determinado conjunto de experimentos para progredir em direção à meta original, faça as seguintes perguntas:
- O espaço de pesquisa é grande o suficiente? Se o ponto ideal de um estudo estiver perto do limite do espaço de pesquisa em uma ou mais dimensões, a pesquisa provavelmente não será ampla o suficiente. Nesse caso, faça outro estudo com um espaço de pesquisa maior.
- Você fez uma amostragem de pontos suficientes do espaço de pesquisa? Caso contrário, execute mais pontos ou seja menos ambicioso nas metas de ajuste.
- Qual fração dos testes em cada estudo é inviável? Ou seja, quais testes divergem, têm valores de perda muito ruins ou não são executados porque violam alguma restrição implícita? Quando uma fração muito grande de pontos em um estudo é inviável, ajuste o espaço de pesquisa para evitar a amostragem desses pontos, o que às vezes exige a reparametrização do espaço de pesquisa. Em alguns casos, um grande número de pontos inviáveis pode indicar um bug no código de treinamento.
- O modelo apresenta problemas de otimização?
- O que você pode aprender com as curvas de treinamento dos melhores testes? Por exemplo, os melhores testes têm curvas de treinamento consistentes com overfitting problemático?
Se necessário, com base nas respostas às perguntas anteriores, refine o estudo ou grupo de estudos mais recente para melhorar o espaço de pesquisa e/ou amostrar mais testes ou tome alguma outra ação corretiva.
Depois de responder às perguntas anteriores, avalie as evidências que os experimentos fornecem para sua meta original. Por exemplo, avalie se uma mudança é útil.
Identificar limites ruins do espaço de pesquisa
Um espaço de pesquisa é suspeito se o melhor ponto amostrado dele estiver perto do limite. Você pode encontrar um ponto ainda melhor se ampliar o intervalo de pesquisa nessa direção.
Para verificar os limites do espaço de pesquisa, recomendamos criar gráficos de testes concluídos no que chamamos de gráficos básicos de eixos de hiperparâmetros. Neles, representamos o valor objetivo da validação em relação a um dos hiperparâmetros (por exemplo, taxa de aprendizado). Cada ponto no gráfico corresponde a um único teste.
O valor objetivo de validação de cada teste geralmente é o melhor valor alcançado durante o treinamento.
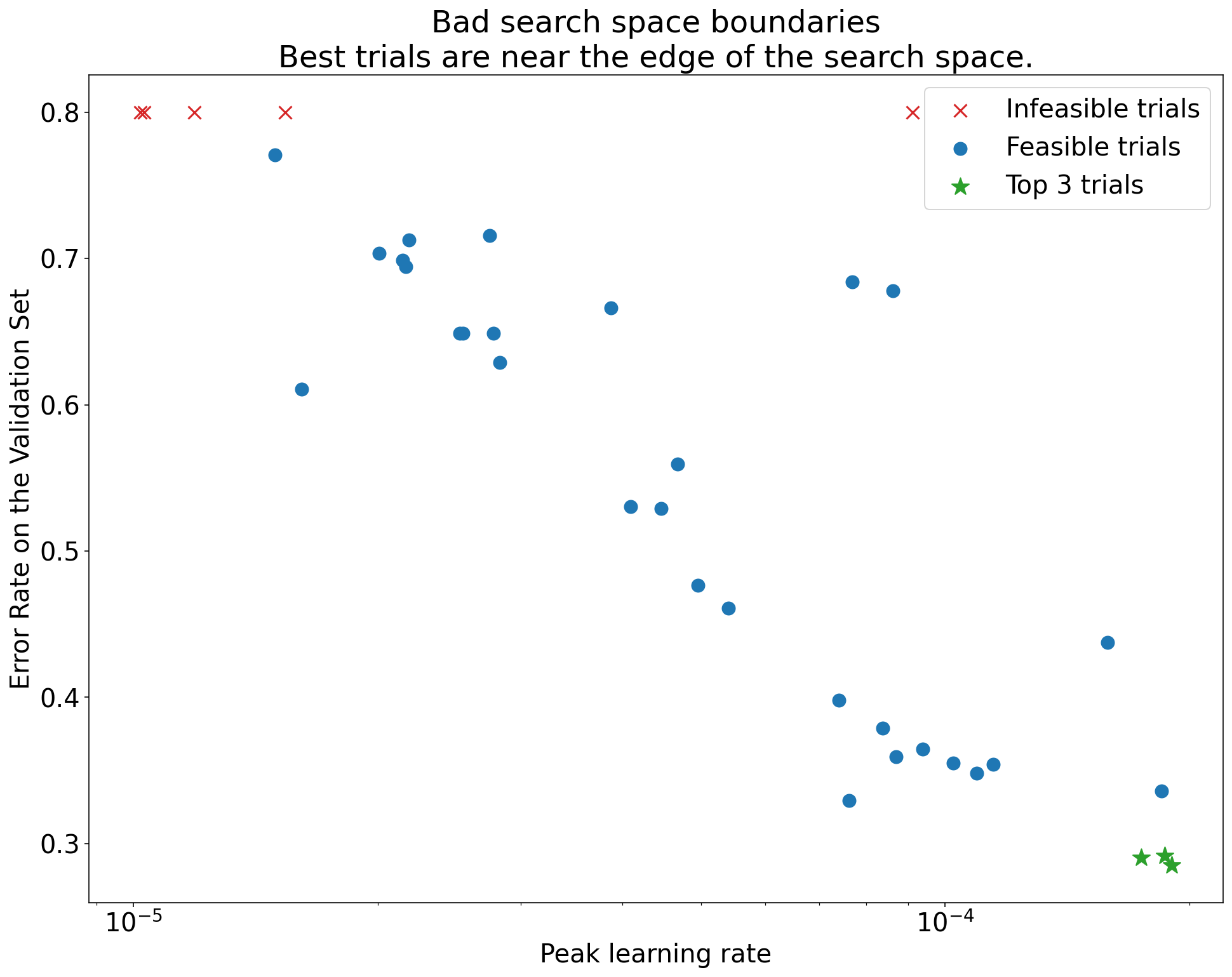
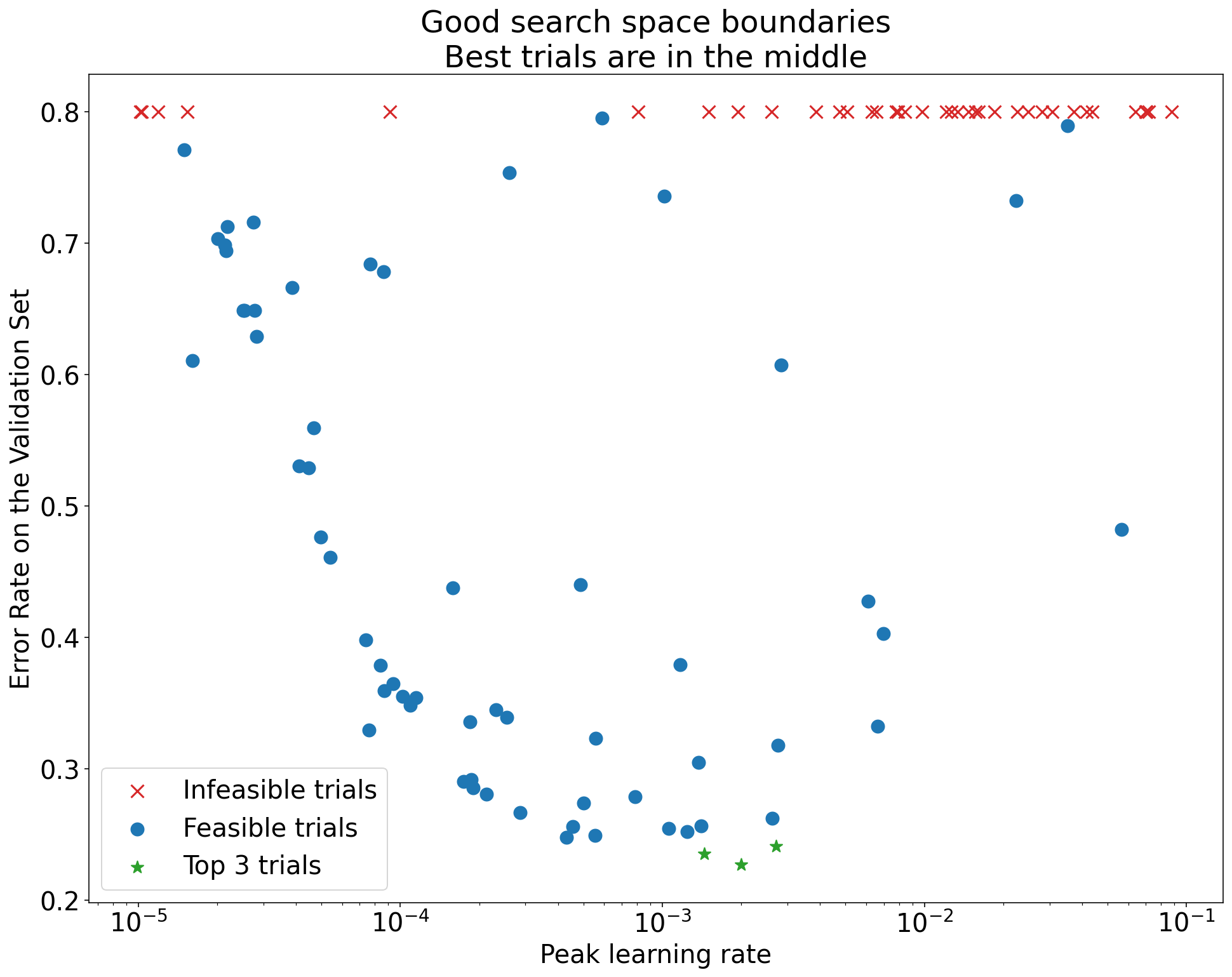
Figura 1:exemplos de limites ruins e aceitáveis do espaço de pesquisa.
Os gráficos na Figura 1 mostram a taxa de erro (quanto menor, melhor) em relação à taxa de aprendizado inicial. Se os melhores pontos se agruparem na borda de um espaço de pesquisa (em alguma dimensão), talvez seja necessário expandir os limites do espaço até que o melhor ponto observado não esteja mais perto da borda.
Muitas vezes, um estudo inclui testes "inviáveis" que divergem ou têm resultados muito ruins (marcados com Xs vermelhos na Figura 1). Se todos os testes forem inviáveis para taxas de aprendizado maiores que um determinado valor de limite, e se os testes de melhor desempenho tiverem taxas de aprendizado na extremidade dessa região, o modelo poderá sofrer problemas de estabilidade que o impeçam de acessar taxas de aprendizado mais altas.
Não há pontos suficientes de amostragem no espaço de pesquisa
Em geral, pode ser muito difícil saber se o espaço de pesquisa foi amostrado de maneira densa o suficiente. 🤖 Executar mais testes é melhor do que executar menos, mas isso gera um custo extra óbvio.
Como é difícil saber quando você coletou amostras suficientes, recomendamos:
- Comprar amostras do que você pode pagar.
- Calibrar sua confiança intuitiva olhando repetidamente vários gráficos de eixos de hiperparâmetros e tentando ter uma ideia de quantos pontos estão na região "boa" do espaço de pesquisa.
Examinar as curvas de treinamento
Resumo: analisar as curvas de perda é uma maneira fácil de identificar modos de falha comuns e pode ajudar você a priorizar as próximas ações possíveis.
Em muitos casos, o objetivo principal dos experimentos exige apenas considerar o erro de validação de cada teste. No entanto, tenha cuidado ao reduzir cada teste a um único número, porque esse foco pode ocultar detalhes importantes sobre o que está acontecendo. Para cada estudo, recomendamos analisar as curvas de perda de pelo menos alguns dos melhores testes. Mesmo que isso não seja necessário para atingir o objetivo principal do experimento, analisar as curvas de perda (incluindo perda de treinamento e validação) é uma boa maneira de identificar modos de falha comuns e pode ajudar você a priorizar as próximas ações.
Ao analisar as curvas de perda, concentre-se nas seguintes perguntas:
Algum dos testes está mostrando overfitting problemático? O overfitting problemático ocorre quando o erro de validação começa a aumentar durante o treinamento. Em configurações experimentais em que você otimiza hiperparâmetros de ruído selecionando o "melhor" teste para cada configuração dos hiperparâmetros científicos, verifique se há overfitting problemático em pelo menos cada um dos melhores testes correspondentes às configurações dos hiperparâmetros científicos que você está comparando. Se algum dos melhores testes apresentar overfitting problemático, faça uma ou ambas as ações a seguir:
- Execute o experimento novamente com outras técnicas de regularização
- Ajuste novamente os parâmetros de regularização atuais antes de comparar os valores dos hiperparâmetros científicos. Isso pode não se aplicar se os hiperparâmetros científicos incluírem parâmetros de regularização. Nesse caso, não seria surpreendente se configurações de baixa intensidade desses parâmetros resultassem em overfitting problemático.
Reduzir o overfitting geralmente é simples usando técnicas comuns de regularização que adicionam complexidade mínima ao código ou computação extra (por exemplo, regularização de dropout, suavização de rótulos, decaimento de peso). Portanto, geralmente é trivial adicionar um ou mais deles à próxima rodada de experimentos. Por exemplo, se o hiperparâmetro científico for "número de camadas ocultas" e o melhor teste que usa o maior número de camadas ocultas apresentar overfitting problemático, recomendamos tentar de novo com mais regularização em vez de selecionar imediatamente o menor número de camadas ocultas.
Mesmo que nenhum dos testes "melhores" apresente overfitting problemático, ainda pode haver um problema se ele ocorrer em qualquer um dos testes. Selecionar o melhor teste suprime configurações com overfitting problemático e favorece aquelas que não têm esse problema. Em outras palavras, selecionar o melhor teste favorece configurações com mais regularização. No entanto, qualquer coisa que piore o treinamento pode agir como um regularizador, mesmo que não tenha sido essa a intenção. Por exemplo, escolher uma taxa de aprendizado menor pode regularizar o treinamento ao prejudicar o processo de otimização, mas geralmente não queremos escolher a taxa de aprendizado dessa forma. O "melhor" teste para cada configuração dos hiperparâmetros científicos pode ser selecionado de forma a favorecer valores "ruins" de alguns dos hiperparâmetros científicos ou de ruído.
Há alta variância de etapa a etapa no erro de treinamento ou validação no final do treinamento? Se for esse o caso, isso poderá interferir em:
- Sua capacidade de comparar diferentes valores dos hiperparâmetros científicos. Isso acontece porque cada teste termina aleatoriamente em uma etapa "de sorte" ou "de azar".
- Sua capacidade de reproduzir o resultado da melhor tentativa em produção. Isso acontece porque o modelo de produção pode não terminar na mesma etapa "sortuda" do estudo.
As causas mais prováveis de variância de etapa para etapa são:
- Variância de lote devido à amostragem aleatória de exemplos do conjunto de treinamento para cada lote.
- Conjuntos de validação pequenos
- Usar uma taxa de aprendizado muito alta no final do treinamento.
Possíveis soluções:
- Aumentar o tamanho do lote.
- Obtenção de mais dados de validação.
- Usando o decaimento da taxa de aprendizado.
- Usando a média de Polyak.
Os testes ainda estão melhorando no final do treinamento? Se for esse o caso, você está no regime "limitado por computação" e pode se beneficiar do aumento do número de etapas de treinamento ou da mudança da programação da taxa de aprendizado.
O desempenho nos conjuntos de treinamento e validação ficou saturado muito antes da etapa final de treinamento? Se for o caso, isso indica que você está no regime "não limitado à computação" e que talvez seja possível diminuir o número de etapas de treinamento.
Além dessa lista, muitos outros comportamentos podem ficar evidentes ao examinar as curvas de perda. Por exemplo, o aumento da perda de treinamento durante o treinamento geralmente indica um bug no pipeline de treinamento.
Detectar se uma mudança é útil com gráficos de isolamento
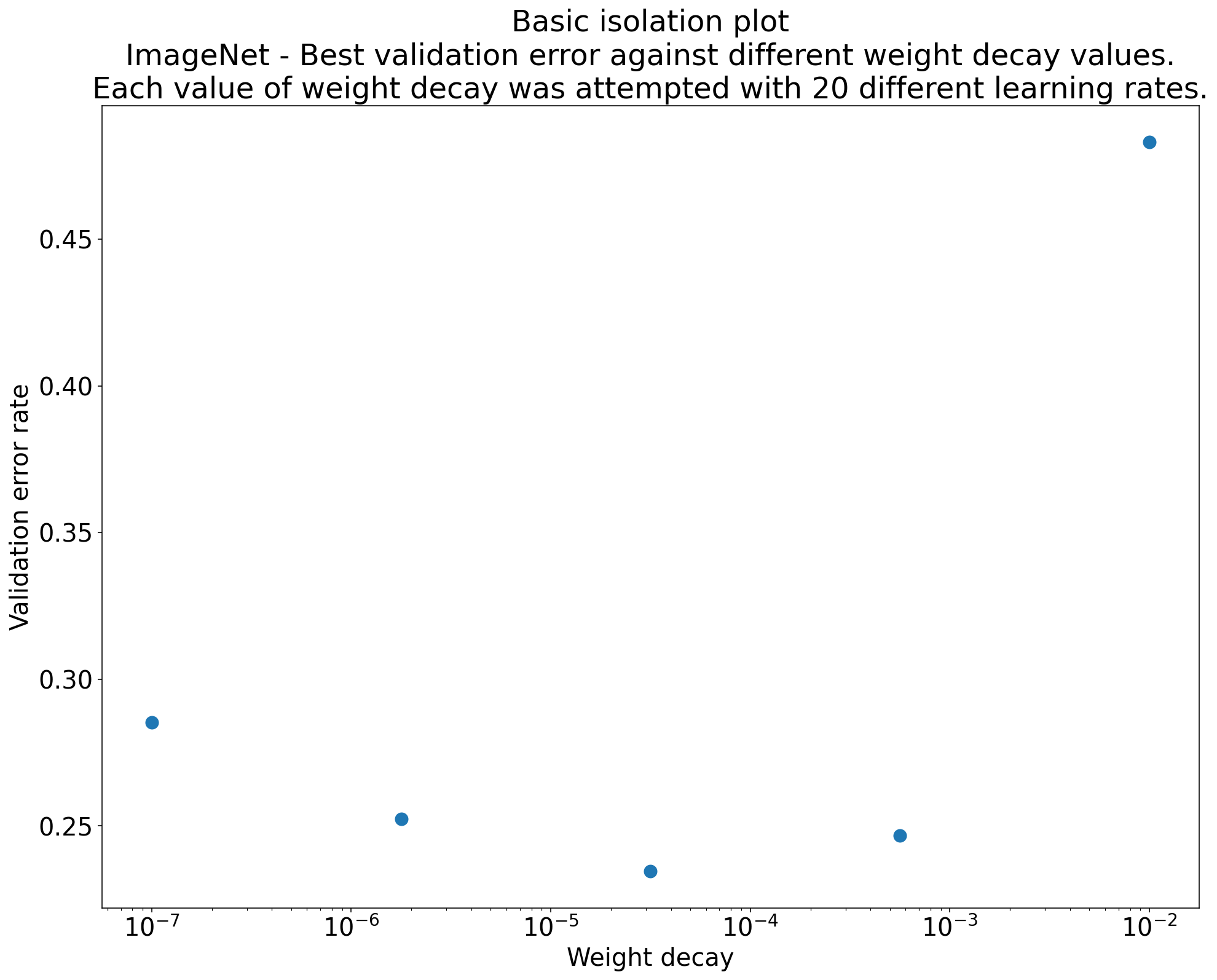
Figura 2:gráfico de isolamento que investiga o melhor valor de decaimento de peso para a ResNet-50 treinada no ImageNet.
Muitas vezes, o objetivo de um conjunto de experimentos é comparar diferentes valores de um hiperparâmetro científico. Por exemplo, suponha que você queira determinar o valor do decaimento de peso que resulta no melhor erro de validação. Um gráfico de isolamento é um caso especial do gráfico de eixo de hiperparâmetro básico. Cada ponto em um gráfico de isolamento corresponde à performance do melhor teste em alguns (ou todos) hiperparâmetros de ruído. Em outras palavras, represente o desempenho do modelo depois de "otimizar" os hiperparâmetros de ruído.
Um gráfico de isolamento simplifica a comparação entre diferentes valores do hiperparâmetro científico. Por exemplo, o gráfico de isolamento na Figura 2 revela o valor do decaimento de peso que produz a melhor performance de validação para uma configuração específica da ResNet-50 treinada no ImageNet.
Se o objetivo for determinar se é necessário incluir a redução de peso, compare o melhor ponto desse gráfico com o valor de referência sem redução de peso. Para uma comparação justa, a taxa de aprendizado da variável de comparação também precisa ser ajustada igualmente.
Quando você tem dados gerados por uma pesquisa (quase) aleatória e está considerando um hiperparâmetro contínuo para um gráfico de isolamento, é possível aproximar o gráfico de isolamento agrupando os valores do eixo x do gráfico básico de hiperparâmetros e usando o melhor teste em cada corte vertical definido pelos agrupamentos.
Automatizar gráficos genericamente úteis
Quanto mais esforço for necessário para gerar gráficos, menor será a probabilidade de você olhar para eles o quanto deveria. Portanto, recomendamos configurar sua infraestrutura para gerar automaticamente o maior número possível de gráficos. Recomendamos gerar automaticamente gráficos de eixos de hiperparâmetros básicos para todos os hiperparâmetros que você varia em um experimento.
Além disso, recomendamos produzir automaticamente curvas de perda para todos os testes. Além disso, recomendamos facilitar ao máximo a localização dos melhores testes de cada estudo e o exame das curvas de perda.
Você pode adicionar muitos outros gráficos e visualizações úteis. Para parafrasear Geoffrey Hinton:
Toda vez que você cria um gráfico novo, aprende algo novo.
Determinar se é preciso adotar a mudança candidata
Resumo: ao decidir se é necessário fazer uma mudança no modelo ou no procedimento de treinamento ou adotar uma nova configuração de hiperparâmetro, observe as diferentes fontes de variação nos resultados.
Ao tentar melhorar um modelo, uma mudança candidata específica pode inicialmente alcançar um erro de validação melhor em comparação com uma configuração atual. No entanto, repetir o experimento pode não demonstrar uma vantagem consistente. Informalmente, as fontes mais importantes de resultados inconsistentes podem ser agrupadas nas seguintes categorias gerais:
- Variância do procedimento de treinamento, variância de retreinamento ou variância de teste: a variação entre execuções de treinamento que usam os mesmos hiperparâmetros, mas diferentes sementes aleatórias. Por exemplo, diferentes inicializações aleatórias, embaralhamentos de dados de treinamento, máscaras de dropout, padrões de operações de aumento de dados e ordenações de operações aritméticas paralelas são todas fontes potenciais de variância de teste.
- Variância da pesquisa de hiperparâmetros ou variância do estudo: a variação nos resultados causada pelo procedimento de seleção dos hiperparâmetros. Por exemplo, você pode executar o mesmo experimento com um espaço de pesquisa específico, mas com duas sementes diferentes para pesquisa quase aleatória, e acabar selecionando valores de hiperparâmetros diferentes.
- Variância de coleta e amostragem de dados: a variância de qualquer tipo de divisão aleatória em dados de treinamento, validação e teste ou variância devido ao processo de geração de dados de treinamento de maneira mais geral.
Verdadeiro. É possível comparar as taxas de erro de validação estimadas em um conjunto de validação finito usando testes estatísticos meticulosos. No entanto, muitas vezes, a variância do teste por si só pode produzir diferenças estatisticamente significativas entre dois modelos treinados diferentes que usam as mesmas configurações de hiperparâmetros.
A variância do estudo é mais preocupante quando tentamos tirar conclusões que vão além do nível de um ponto individual no espaço de hiperparâmetros. A variância do estudo depende do número de testes e do espaço de pesquisa. Já vimos casos em que a variância do estudo é maior do que a do teste e casos em que ela é muito menor. Portanto, antes de adotar uma mudança candidata, execute o melhor teste N vezes para caracterizar a variância de teste para teste. Normalmente, é possível redefinir a variância do teste somente após grandes mudanças no pipeline, mas talvez você precise de estimativas mais recentes em alguns casos. Em outros aplicativos, caracterizar a variância do teste é muito caro para valer a pena.
Embora você só queira adotar mudanças (incluindo novas configurações de hiperparâmetros) que produzam melhorias reais, exigir certeza absoluta de que uma determinada mudança ajuda também não é a resposta certa. Portanto, se um novo ponto de hiperparâmetro (ou outra mudança) tiver um resultado melhor do que o valor de referência (considerando a variância de retreinamento do novo ponto e do valor de referência da melhor maneira possível), adote-o como o novo valor de referência para comparações futuras. No entanto, recomendamos adotar apenas mudanças que produzam melhorias que superem qualquer complexidade adicionada.
Após a conclusão da análise detalhada
Resumo: as ferramentas de otimização bayesiana são uma opção interessante depois que você termina de pesquisar bons espaços de pesquisa e decide quais hiperparâmetros vale a pena ajustar.
Com o tempo, suas prioridades vão mudar de aprender mais sobre o problema de ajuste para produzir uma única configuração ideal para lançamento ou outro uso. Nesse ponto, deve haver um espaço de pesquisa refinado que contenha confortavelmente a região local ao redor do melhor teste observado e tenha sido amostrado adequadamente. Seu trabalho de análise precisa ter revelado os hiperparâmetros mais essenciais para ajuste e os intervalos adequados que podem ser usados para construir um espaço de pesquisa para um estudo final de ajuste automático com o maior orçamento possível.
Como você não se importa mais em maximizar o insight sobre o problema de ajuste, muitas das vantagens da pesquisa quase aleatória não se aplicam mais. Portanto, use ferramentas de otimização bayesiana para encontrar automaticamente a melhor configuração de hiperparâmetros. O Vizier de código aberto implementa vários algoritmos sofisticados para ajustar modelos de ML, incluindo algoritmos de otimização bayesiana.
Suponha que o espaço de pesquisa contenha um volume não trivial de pontos divergentes, ou seja, pontos que recebem perda de treinamento NaN ou até mesmo perda de treinamento muito desvios padrão pior do que a média. Nesse caso, recomendamos usar ferramentas de otimização de caixa preta que processem corretamente testes divergentes. Consulte Otimização bayesiana com restrições desconhecidas (link em inglês) para saber como lidar com esse problema. O Vizier de código aberto oferece suporte para marcar pontos divergentes marcando testes como inviáveis, embora possa não usar nossa abordagem preferida de Gelbart et al., dependendo de como ele é configurado.
Após a conclusão da análise detalhada, confira a performance no conjunto de teste. Em princípio, você pode até mesmo juntar o conjunto de validação ao de treinamento e treinar novamente a melhor configuração encontrada com a otimização bayesiana. No entanto, isso só é adequado se não houver lançamentos futuros com essa carga de trabalho específica (por exemplo, uma competição única do Kaggle).