ধারণা এবং পরিকল্পনা পর্বের সময়, আপনি একটি এমএল সমাধানের উপাদানগুলি তদন্ত করেন। সমস্যা ফ্রেমিং টাস্কের সময়, আপনি একটি এমএল সমাধানের পরিপ্রেক্ষিতে একটি সমস্যা ফ্রেম করেন। মেশিন লার্নিং প্রবলেম ফ্রেমিং কোর্সের ভূমিকা সেই ধাপগুলিকে বিস্তারিতভাবে কভার করে। পরিকল্পনার কাজ চলাকালীন, আপনি একটি সমাধানের সম্ভাব্যতা অনুমান করেন, পরিকল্পনা পদ্ধতি এবং সাফল্যের মেট্রিক্স সেট করেন।
যদিও ML একটি তাত্ত্বিকভাবে ভাল সমাধান হতে পারে, তবুও আপনাকে এর বাস্তব-বিশ্বের সম্ভাব্যতা অনুমান করতে হবে। উদাহরণস্বরূপ, একটি সমাধান প্রযুক্তিগতভাবে কাজ করতে পারে কিন্তু বাস্তবায়িত করা অবাস্তব বা অসম্ভব। নিম্নলিখিত কারণগুলি একটি প্রকল্পের সম্ভাব্যতাকে প্রভাবিত করে:
- ডেটা প্রাপ্যতা
- সমস্যা অসুবিধা
- ভবিষ্যদ্বাণী গুণমান
- প্রযুক্তিগত প্রয়োজনীয়তা
- খরচ
ডেটা প্রাপ্যতা
এমএল মডেলগুলি শুধুমাত্র সেই ডেটার মতোই ভাল যা তারা প্রশিক্ষিত। উচ্চ-মানের ভবিষ্যদ্বাণী করতে তাদের প্রচুর উচ্চ-মানের ডেটা প্রয়োজন। নিম্নলিখিত প্রশ্নগুলি সম্বোধন করা আপনাকে একটি মডেলকে প্রশিক্ষণ দেওয়ার জন্য প্রয়োজনীয় ডেটা আছে কিনা তা বিচার করতে সাহায্য করতে পারে:
পরিমাণ। আপনি একটি মডেল প্রশিক্ষণের জন্য যথেষ্ট উচ্চ মানের ডেটা পেতে পারেন? লেবেলযুক্ত উদাহরণগুলি কি দুষ্প্রাপ্য, পাওয়া কঠিন বা খুব ব্যয়বহুল? উদাহরণস্বরূপ, মেডিকেল ইমেজ বা বিরল ভাষার অনুবাদ লেবেল করা কুখ্যাতভাবে কঠিন। ভাল ভবিষ্যদ্বাণী করার জন্য, শ্রেণীবিভাগ মডেলগুলির প্রতিটি লেবেলের জন্য অসংখ্য উদাহরণের প্রয়োজন৷ প্রশিক্ষণ ডেটাসেটে কিছু লেবেলের জন্য সীমিত উদাহরণ থাকলে, মডেলটি ভাল ভবিষ্যদ্বাণী করতে পারে না।
পরিবেশন সময় বৈশিষ্ট্য প্রাপ্যতা. প্রশিক্ষণে ব্যবহৃত সমস্ত বৈশিষ্ট্য কি পরিবেশনের সময়ে উপলব্ধ হবে? দলগুলি যথেষ্ট পরিমাণে সময় ব্যয় করেছে মডেল প্রশিক্ষণের জন্য শুধুমাত্র উপলব্ধি করার জন্য যে কিছু বৈশিষ্ট্য মডেলের প্রয়োজন হওয়ার কয়েক দিন পর্যন্ত উপলব্ধ হয়নি।
উদাহরণস্বরূপ, ধরুন একটি মডেল ভবিষ্যদ্বাণী করে যে একজন গ্রাহক একটি URL ক্লিক করবে কিনা এবং প্রশিক্ষণে ব্যবহৃত বৈশিষ্ট্যগুলির মধ্যে একটি হল
user_age। যাইহোক, যখন মডেলটি একটি ভবিষ্যদ্বাণী পরিবেশন করে,user_ageউপলব্ধ হয় না, সম্ভবত কারণ ব্যবহারকারী এখনও একটি অ্যাকাউন্ট তৈরি করেননি৷প্রবিধান। ডেটা অর্জন এবং ব্যবহার করার জন্য প্রবিধান এবং আইনি প্রয়োজনীয়তাগুলি কী কী? উদাহরণস্বরূপ, কিছু প্রয়োজনীয়তা নির্দিষ্ট ধরণের ডেটা সংরক্ষণ এবং ব্যবহারের জন্য সীমা নির্ধারণ করে।
জেনারেটিভ এআই
প্রাক-প্রশিক্ষিত জেনারেটিভ এআই মডেলগুলিতে প্রায়ই ডোমেন-নির্দিষ্ট কাজগুলিতে এক্সেল করার জন্য কিউরেটেড ডেটাসেটের প্রয়োজন হয়। নিম্নলিখিত ব্যবহারের ক্ষেত্রে আপনার সম্ভাব্য ডেটাসেটের প্রয়োজন হবে:
- প্রম্পট ইঞ্জিনিয়ারিং , প্যারামিটার দক্ষ টিউনিং এবং ফাইন-টিউনিং । ব্যবহারের ক্ষেত্রের উপর নির্ভর করে, একটি মডেলের আউটপুটকে আরও পরিমার্জিত করতে আপনার 10 থেকে 10,000টি উচ্চ-মানের উদাহরণের প্রয়োজন হতে পারে। উদাহরণ স্বরূপ, যদি কোনো মডেলকে কোনো নির্দিষ্ট কাজে এক্সেল করার প্রয়োজন হয়, যেমন মেডিকেল প্রশ্নের উত্তর দেওয়া, তাহলে আপনার একটি উচ্চ-মানের ডেটাসেট প্রয়োজন যা এটিকে যে ধরনের প্রশ্ন জিজ্ঞাসা করা হবে তার সাথে এর উত্তরের ধরনগুলির সাথে উত্তর দিতে হবে।
নিম্নলিখিত সারণী একটি প্রদত্ত কৌশলের জন্য একটি জেনারেটিভ এআই মডেলের আউটপুট পরিমার্জন করার জন্য প্রয়োজনীয় উদাহরণগুলির সংখ্যার জন্য অনুমান প্রদান করে:
- আপ টু ডেট তথ্য. একবার প্রাক-প্রশিক্ষিত হলে, জেনারেটিভ এআই মডেলগুলির একটি নির্দিষ্ট জ্ঞানের ভিত্তি থাকে। যদি মডেলের ডোমেনের বিষয়বস্তু প্রায়ই পরিবর্তিত হয়, তাহলে মডেলটিকে আপ-টু-ডেট রাখার জন্য আপনার একটি কৌশলের প্রয়োজন হবে, যেমন:
- ফাইন-টিউনিং
- পুনরুদ্ধার-বর্ধিত প্রজন্ম (RAG)
- পর্যায়ক্রমিক প্রাক-প্রশিক্ষণ
| টেকনিক | প্রয়োজনীয় উদাহরণের সংখ্যা |
|---|---|
| জিরো-শট প্রম্পটিং | 0 |
| কয়েক শট প্রম্পটিং | ~10-100 |
| প্যারামিটার দক্ষ টিউনিং 1 | ~100-10,000 |
| ফাইন-টিউনিং | ~1000s–10,000s (বা তার বেশি) |
সমস্যা অসুবিধা
একটি সমস্যার অসুবিধা অনুমান করা কঠিন হতে পারে। প্রাথমিকভাবে যা একটি যুক্তিসঙ্গত পদ্ধতি বলে মনে হয় তা আসলে একটি উন্মুক্ত গবেষণা প্রশ্ন হতে পারে; যা ব্যবহারিক এবং করণীয় বলে মনে হয় তা অবাস্তব বা অকার্যকর হতে পারে। নিম্নলিখিত প্রশ্নের উত্তর একটি সমস্যার অসুবিধা পরিমাপ করতে সাহায্য করতে পারে:
একটি অনুরূপ সমস্যা ইতিমধ্যে সমাধান করা হয়েছে? উদাহরণ স্বরূপ, আপনার প্রতিষ্ঠানের দলগুলো কি মডেল তৈরি করতে একই ধরনের (বা অভিন্ন) ডেটা ব্যবহার করেছে? আপনার প্রতিষ্ঠানের বাইরের লোকেরা বা দলগুলি কি অনুরূপ সমস্যার সমাধান করেছে, উদাহরণস্বরূপ, Kaggle বা TensorFlow Hub এ? যদি তাই হয়, তাহলে সম্ভবত আপনি তাদের মডেলের কিছু অংশ আপনার তৈরি করতে ব্যবহার করতে পারবেন।
সমস্যার প্রকৃতি কি কঠিন? টাস্কের জন্য মানবিক মানদণ্ডগুলি জানা সমস্যাটির অসুবিধার স্তরটি জানাতে পারে। যেমন:
- মানুষ প্রায় 95% নির্ভুলতার সাথে একটি ছবিতে প্রাণীর প্রকারকে শ্রেণীবদ্ধ করতে পারে।
- মানুষ প্রায় 99% নির্ভুলতার সাথে হাতে লেখা অঙ্কগুলিকে শ্রেণীবদ্ধ করতে পারে।
পূর্ববর্তী তথ্য পরামর্শ দেয় যে পশুদের শ্রেণীবদ্ধ করার জন্য একটি মডেল তৈরি করা হস্তলিখিত সংখ্যাগুলিকে শ্রেণীবদ্ধ করার জন্য একটি মডেল তৈরি করার চেয়ে আরও কঠিন।
সম্ভাব্য খারাপ অভিনেতা আছে? লোকেরা কি সক্রিয়ভাবে আপনার মডেলকে কাজে লাগানোর চেষ্টা করবে? যদি তাই হয়, আপনি মডেলটিকে অপব্যবহার করার আগে আপডেট করার জন্য একটি ধ্রুবক দৌড়ে থাকবেন। উদাহরণস্বরূপ, স্প্যাম ফিল্টারগুলি নতুন ধরনের স্প্যাম ধরতে পারে না যখন কেউ বৈধ বলে মনে হয় এমন ইমেলগুলি তৈরি করতে মডেলটি ব্যবহার করে৷
জেনারেটিভ এআই
জেনারেটিভ এআই মডেলগুলির সম্ভাব্য দুর্বলতা রয়েছে যা সমস্যার অসুবিধা বাড়াতে পারে:
- ইনপুট উৎস। ইনপুট কোথা থেকে আসবে? প্রতিপক্ষ কি প্রশিক্ষণের তথ্য, প্রস্তাবনা উপাদান, ডাটাবেস বিষয়বস্তু বা টুল তথ্য ফাঁস করতে পারে?
- আউটপুট ব্যবহার। কিভাবে আউটপুট ব্যবহার করা হবে? মডেলটি কি কাঁচা বিষয়বস্তু আউটপুট করবে বা সেখানে মধ্যস্থতাকারী পদক্ষেপগুলি থাকবে যা পরীক্ষা করে যাচাই করবে যে এটি উপযুক্ত? উদাহরণস্বরূপ, প্লাগইনগুলিতে কাঁচা আউটপুট প্রদানের ফলে বেশ কয়েকটি নিরাপত্তা সমস্যা হতে পারে।
- ফাইন-টিউনিং। একটি দূষিত ডেটাসেটের সাথে ফাইন-টিউনিং মডেলের ওজনকে নেতিবাচকভাবে প্রভাবিত করতে পারে। এই দুর্নীতির কারণে মডেলটি ভুল, বিষাক্ত বা পক্ষপাতদুষ্ট বিষয়বস্তু আউটপুট করবে। যেমন আগে উল্লেখ করা হয়েছে, ফাইন-টিউনিংয়ের জন্য একটি ডেটাসেট প্রয়োজন যা উচ্চ-মানের উদাহরণ ধারণ করার জন্য যাচাই করা হয়েছে।
ভবিষ্যদ্বাণী গুণমান
একটি মডেলের ভবিষ্যদ্বাণী আপনার ব্যবহারকারীদের উপর কী প্রভাব ফেলবে তা আপনি সাবধানে বিবেচনা করতে চাইবেন এবং মডেলের জন্য প্রয়োজনীয় ভবিষ্যদ্বাণী গুণমান নির্ধারণ করতে চাইবেন।
প্রয়োজনীয় ভবিষ্যদ্বাণী গুণমান ভবিষ্যদ্বাণী ধরনের উপর নির্ভর করে. উদাহরণস্বরূপ, একটি সুপারিশ সিস্টেমের জন্য প্রয়োজনীয় ভবিষ্যদ্বাণী গুণমান নীতি লঙ্ঘনগুলি চিহ্নিত করে এমন একটি মডেলের জন্য একই রকম হবে না৷ ভুল ভিডিও সুপারিশ করা একটি খারাপ ব্যবহারকারীর অভিজ্ঞতা তৈরি করতে পারে। যাইহোক, প্ল্যাটফর্মের নীতি লঙ্ঘনকারী হিসাবে একটি ভিডিওকে ভুলভাবে পতাকাঙ্কিত করলে সহায়তা খরচ বা আরও খারাপ, আইনি ফি তৈরি হতে পারে।
আপনার মডেলের কি খুব উচ্চ ভবিষ্যদ্বাণীর গুণমান থাকতে হবে কারণ ভুল ভবিষ্যদ্বাণী অত্যন্ত ব্যয়বহুল? সাধারণত, প্রয়োজনীয় ভবিষ্যদ্বাণীর গুণমান যত বেশি, সমস্যা তত কঠিন। দুর্ভাগ্যবশত, আপনি গুণমান উন্নত করার চেষ্টা করার সাথে সাথে প্রকল্পগুলি প্রায়শই হ্রাসকারী রিটার্নে পৌঁছায়। উদাহরণস্বরূপ, একটি মডেলের নির্ভুলতা 99.9% থেকে 99.99% বৃদ্ধি করার অর্থ প্রকল্পের ব্যয়ের 10-গুণ বৃদ্ধি হতে পারে (যদি বেশি না হয়)।
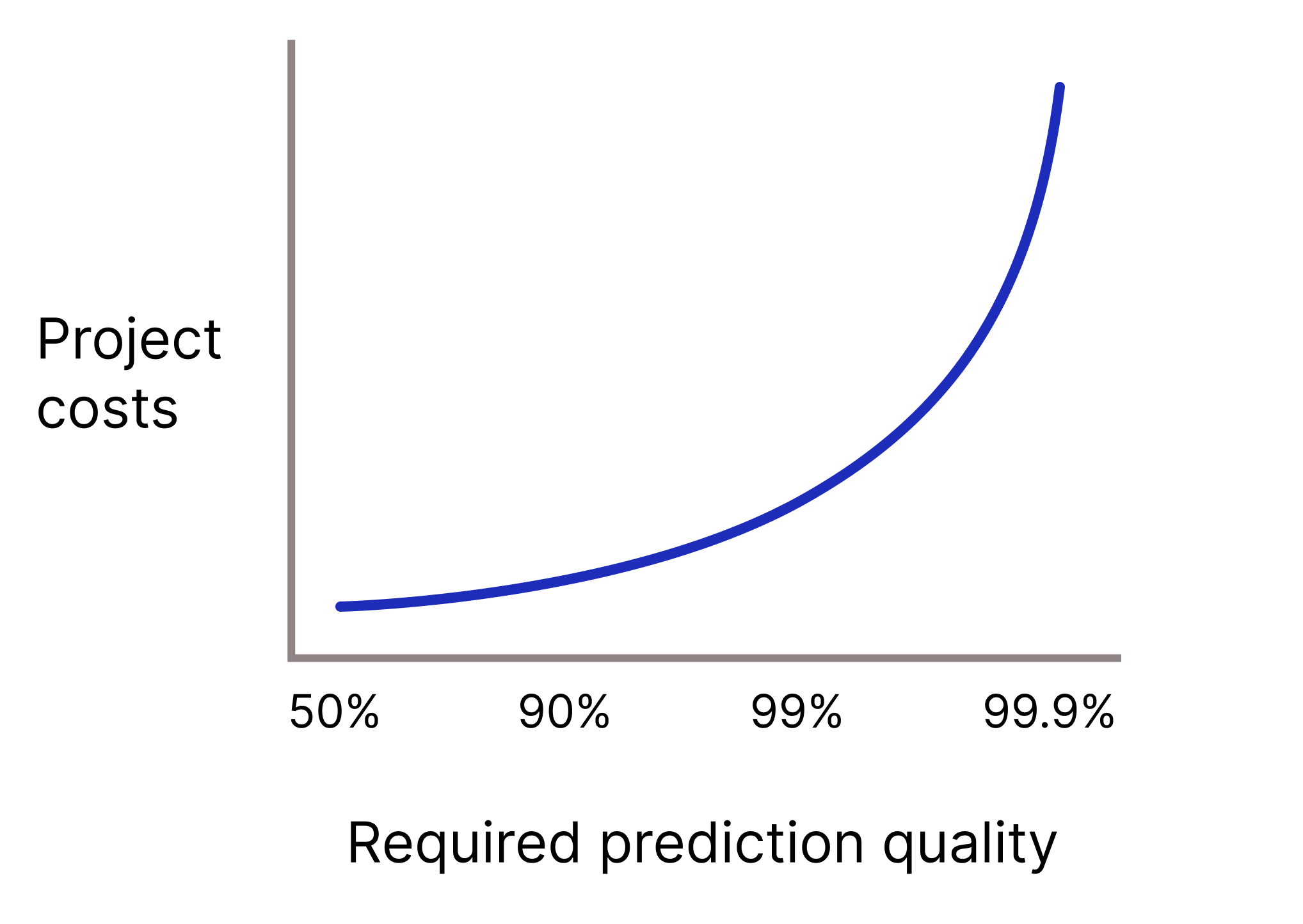
চিত্র 2 । প্রয়োজনীয় ভবিষ্যদ্বাণীর গুণমান বৃদ্ধির সাথে সাথে একটি এমএল প্রকল্পের জন্য সাধারণত আরও বেশি সংস্থান প্রয়োজন।
জেনারেটিভ এআই
জেনারেটিভ এআই আউটপুট বিশ্লেষণ করার সময়, নিম্নলিখিতগুলি বিবেচনা করুন:
- বাস্তব নির্ভুলতা। যদিও জেনারেটিভ এআই মডেলগুলি সাবলীল এবং সুসঙ্গত বিষয়বস্তু তৈরি করতে পারে, তবে এটি বাস্তবসম্মত হওয়ার নিশ্চয়তা নেই। জেনারেটিভ এআই মডেলের মিথ্যা বিবৃতিকে বলা হয় কনফ্যাবুলেশন । উদাহরণস্বরূপ, জেনারেটিভ এআই মডেলগুলি টেক্সটের ভুল সারসংক্ষেপ, গণিতের প্রশ্নের ভুল উত্তর বা বিশ্ব সম্পর্কে মিথ্যা বিবৃতি তৈরি করতে পারে এবং তৈরি করতে পারে। অনেক ব্যবহারের ক্ষেত্রে এখনও উৎপাদন পরিবেশে ব্যবহার করার আগে জেনারেটিভ এআই আউটপুট মানুষের যাচাইকরণের প্রয়োজন হয়, উদাহরণস্বরূপ, এলএলএম-জেনারেটেড কোড।
প্রথাগত ML-এর মতো, বাস্তবিক নির্ভুলতার জন্য প্রয়োজনীয়তা যত বেশি, বিকাশ এবং রক্ষণাবেক্ষণের খরচ তত বেশি।
- আউটপুট গুণমান। পক্ষপাতদুষ্ট, চুরি করা বা বিষাক্ত বিষয়বস্তুর মতো খারাপ ফলাফলের আইনি এবং আর্থিক পরিণতি (বা নৈতিক প্রভাব) কী?
প্রযুক্তিগত প্রয়োজনীয়তা
মডেলগুলির বেশ কয়েকটি প্রযুক্তিগত প্রয়োজনীয়তা রয়েছে যা তাদের সম্ভাব্যতাকে প্রভাবিত করে। আপনার প্রকল্পের সম্ভাব্যতা নির্ধারণের জন্য আপনাকে নিম্নলিখিত প্রধান প্রযুক্তিগত প্রয়োজনীয়তাগুলি সমাধান করতে হবে:
- লেটেন্সি। লেটেন্সি প্রয়োজনীয়তা কি কি? কত দ্রুত ভবিষ্যদ্বাণী পরিবেশন করা প্রয়োজন?
- প্রতি সেকেন্ডে প্রশ্ন (QPS)। QPS প্রয়োজনীয়তা কি?
- RAM ব্যবহার। প্রশিক্ষণ এবং পরিবেশন করার জন্য RAM এর প্রয়োজনীয়তাগুলি কী কী?
- প্ল্যাটফর্ম। মডেলটি কোথায় চলবে: অনলাইন (RPC সার্ভারে প্রশ্ন পাঠানো হয়েছে), WebML (একটি ওয়েব ব্রাউজারের ভিতরে), ODML (ফোন বা ট্যাবলেটে), অথবা অফলাইন (একটি টেবিলে ভবিষ্যদ্বাণী সংরক্ষিত)?
ব্যাখ্যাযোগ্যতা। ভবিষ্যদ্বাণী ব্যাখ্যাযোগ্য হতে হবে? উদাহরণস্বরূপ, আপনার পণ্যের কি প্রশ্নের উত্তর দিতে হবে যেমন, "কেন একটি নির্দিষ্ট বিষয়বস্তু স্প্যাম হিসাবে চিহ্নিত করা হয়েছিল?" অথবা "কেন একটি ভিডিও প্ল্যাটফর্মের নীতি লঙ্ঘন করার জন্য নির্ধারিত হয়েছিল?"
পুনরায় প্রশিক্ষণের ফ্রিকোয়েন্সি । যখন আপনার মডেলের অন্তর্নিহিত ডেটা দ্রুত পরিবর্তিত হয়, ঘন ঘন বা ক্রমাগত পুনরায় প্রশিক্ষণের প্রয়োজন হতে পারে। যাইহোক, ঘন ঘন পুনঃপ্রশিক্ষণের ফলে উল্লেখযোগ্য খরচ হতে পারে যা মডেলের ভবিষ্যদ্বাণী আপডেট করার সুবিধার চেয়ে বেশি হতে পারে।
বেশিরভাগ ক্ষেত্রে, আপনাকে সম্ভবত একটি মডেলের প্রযুক্তিগত বৈশিষ্ট্যগুলি মেনে চলার জন্য তার গুণমানের সাথে আপস করতে হবে। এই ক্ষেত্রে, আপনাকে নির্ধারণ করতে হবে যে আপনি এখনও এমন একটি মডেল তৈরি করতে পারেন যা উত্পাদনে যাওয়ার জন্য যথেষ্ট ভাল।
জেনারেটিভ এআই
জেনারেটিভ AI এর সাথে কাজ করার সময় নিম্নলিখিত প্রযুক্তিগত প্রয়োজনীয়তাগুলি বিবেচনা করুন:
- প্ল্যাটফর্ম। অনেক প্রাক-প্রশিক্ষিত মডেল বিভিন্ন আকারে আসে, যা তাদেরকে বিভিন্ন কম্পিউটেশনাল রিসোর্স সহ বিভিন্ন প্ল্যাটফর্মে কাজ করতে সক্ষম করে। উদাহরণস্বরূপ, প্রাক-প্রশিক্ষিত মডেলগুলি ডেটা সেন্টার স্কেল থেকে ফোনে ফিটিং পর্যন্ত হতে পারে। মডেলের আকার নির্বাচন করার সময় আপনাকে আপনার পণ্য বা পরিষেবার বিলম্ব, গোপনীয়তা এবং গুণমানের সীমাবদ্ধতা বিবেচনা করতে হবে। এই সীমাবদ্ধতা প্রায়ই বিরোধ হতে পারে. উদাহরণস্বরূপ, গোপনীয়তার সীমাবদ্ধতার জন্য অনুমানগুলি ব্যবহারকারীর ডিভাইসে চালানোর প্রয়োজন হতে পারে। যাইহোক, আউটপুট গুণমান খারাপ হতে পারে কারণ ডিভাইসটিতে ভাল ফলাফলের জন্য গণনামূলক সংস্থান নেই।
- লেটেন্সি। মডেল ইনপুট এবং আউটপুট আকার লেটেন্সি প্রভাবিত করে। বিশেষ করে, আউটপুট আকার ইনপুট আকারের চেয়ে বিলম্বকে বেশি প্রভাবিত করে। যদিও মডেলগুলি তাদের ইনপুটগুলিকে সমান্তরাল করতে পারে, তারা শুধুমাত্র ক্রমানুসারে আউটপুট তৈরি করতে পারে। অন্য কথায়, 500-শব্দ বা 10-শব্দের ইনপুট গ্রহণ করার জন্য লেটেন্সি একই হতে পারে, যখন 500-শব্দের সারাংশ তৈরি করতে 10-শব্দের সারাংশ তৈরি করার চেয়ে যথেষ্ট বেশি সময় লাগে।
- টুল এবং API ব্যবহার। মডেলটিকে কি টুল এবং API ব্যবহার করতে হবে, যেমন ইন্টারনেট অনুসন্ধান করা, একটি ক্যালকুলেটর ব্যবহার করা, বা একটি কাজ সম্পূর্ণ করার জন্য একটি ইমেল ক্লায়েন্ট অ্যাক্সেস করা? সাধারণত, একটি কাজ সম্পূর্ণ করার জন্য যত বেশি সরঞ্জামের প্রয়োজন হয়, ভুল প্রচার করার এবং মডেলের দুর্বলতা বাড়ানোর সম্ভাবনা তত বেশি থাকে।
খরচ
একটি ML বাস্তবায়ন তার খরচ মূল্য হবে? বেশিরভাগ ML প্রকল্প অনুমোদিত হবে না যদি ML সলিউশন বাস্তবায়ন এবং রক্ষণাবেক্ষণ করা অর্থের তুলনায় বেশি ব্যয়বহুল হয় (বা সঞ্চয় করে)। এমএল প্রকল্পের জন্য মানুষ এবং মেশিন উভয় খরচ বহন করে।
মানুষের খরচ। ধারণার প্রমাণ থেকে উৎপাদনে যেতে প্রকল্পটির জন্য কতজন লোক লাগবে? এমএল প্রকল্পগুলি বিকশিত হওয়ার সাথে সাথে ব্যয় সাধারণত বৃদ্ধি পায়। উদাহরণস্বরূপ, ML প্রকল্পগুলির জন্য প্রোটোটাইপ তৈরি করার চেয়ে একটি উত্পাদন-প্রস্তুত সিস্টেম স্থাপন এবং বজায় রাখার জন্য আরও বেশি লোকের প্রয়োজন। প্রতিটি পর্যায়ে প্রকল্পের প্রয়োজন হবে সংখ্যা এবং ভূমিকা অনুমান করার চেষ্টা করুন.
মেশিন খরচ. মডেলের প্রশিক্ষণ, স্থাপনা এবং রক্ষণাবেক্ষণের জন্য প্রচুর গণনা এবং মেমরির প্রয়োজন। উদাহরণস্বরূপ, আপনার ডেটা পাইপলাইনের জন্য প্রয়োজনীয় পরিকাঠামো সহ ট্রেনিং মডেল এবং ভবিষ্যদ্বাণী পরিবেশনের জন্য আপনার TPU কোটার প্রয়োজন হতে পারে। আপনাকে ডেটা লেবেল পেতে বা ডেটা লাইসেন্সিং ফি দিতে হতে পারে। একটি মডেলকে প্রশিক্ষণ দেওয়ার আগে, দীর্ঘমেয়াদে এমএল বৈশিষ্ট্যগুলি তৈরি এবং রক্ষণাবেক্ষণের জন্য মেশিনের খরচ অনুমান করার কথা বিবেচনা করুন।
অনুমান খরচ। মডেলটি কি শত শত বা হাজার হাজার অনুমান তৈরি করতে হবে যা উৎপন্ন রাজস্বের চেয়ে বেশি খরচ করে?
মনে রাখবেন
পূর্ববর্তী যেকোনো বিষয়ের সাথে সম্পর্কিত সমস্যার সম্মুখীন হওয়া একটি ML সমাধান বাস্তবায়নকে একটি চ্যালেঞ্জ করে তুলতে পারে, কিন্তু কঠোর সময়সীমা চ্যালেঞ্জগুলিকে আরও বাড়িয়ে তুলতে পারে। সমস্যার অনুভূত অসুবিধার উপর ভিত্তি করে পর্যাপ্ত সময় পরিকল্পনা এবং বাজেট করার চেষ্টা করুন এবং তারপরে একটি নন-এমএল প্রকল্পের জন্য আপনার চেয়েও বেশি ওভারহেড সময় সংরক্ষণ করার চেষ্টা করুন।
আপনার বোঝার চেক করুন
আপনি একটি প্রকৃতি সংরক্ষণ কোম্পানির জন্য কাজ করেন এবং কোম্পানির উদ্ভিদ শনাক্তকরণ সফ্টওয়্যার পরিচালনা করেন। আপনি 60 ধরনের আক্রমণাত্মক উদ্ভিদ প্রজাতির শ্রেণীবদ্ধ করার জন্য একটি মডেল তৈরি করতে চান যাতে সংরক্ষণবাদীদের বিপন্ন প্রাণীদের আবাসস্থল পরিচালনা করতে সহায়তা করা যায়।
আপনি নমুনা কোড খুঁজে পেয়েছেন যা একটি অনুরূপ উদ্ভিদ সনাক্তকরণ সমস্যার সমাধান করে এবং আপনার সমাধান বাস্তবায়নের জন্য আনুমানিক খরচ প্রকল্পের বাজেটের মধ্যে রয়েছে। যদিও ডেটাসেটে প্রচুর প্রশিক্ষণের উদাহরণ রয়েছে, এটি পাঁচটি সবচেয়ে আক্রমণাত্মক প্রজাতির জন্য মাত্র কয়েকটি রয়েছে। নেতৃত্বের প্রয়োজন হয় না যে মডেলের ভবিষ্যদ্বাণীগুলি ব্যাখ্যাযোগ্য হতে পারে এবং খারাপ ভবিষ্যদ্বাণীগুলির সাথে সম্পর্কিত নেতিবাচক পরিণতি বলে মনে হয় না৷ আপনার এমএল সমাধান কি সম্ভব?