Page Summary
-
Machine learning solution feasibility hinges on data availability, problem complexity, desired prediction quality, technical requirements, and cost-effectiveness.
-
Sufficient, high-quality data is crucial for effective model training, especially for generative AI which often requires extensive datasets for tasks like fine-tuning.
-
Problem complexity and potential vulnerabilities should be assessed; simpler problems with readily available solutions are generally more feasible.
-
Consider prediction quality requirements, technical constraints (latency, platform, etc.), and associated costs, including human resources, infrastructure, and potential generative AI inference expenses.
-
Thoroughly evaluating these factors enables informed decision-making regarding the feasibility and successful implementation of an ML solution.
During the ideation and planning phase, you investigate the elements of an ML solution. During the problem framing task, you frame a problem in terms of an ML solution. The Introduction to Machine Learning Problem Framing course covers those steps in detail. During the planning task, you estimate a solution's feasibility, plan approaches, and set success metrics.
While ML might be a theoretically good solution, you still need to estimate its real-world feasibility. For instance, a solution might technically work but be impractical or impossible to implement. The following factors influence a project's feasibility:
- Data availability
- Problem difficulty
- Prediction quality
- Technical requirements
- Cost
Data availability
ML models are only as good as the data they're trained on. They need lots of high-quality data to make high-quality predictions. Addressing the following questions can help you judge whether you have the necessary data to train a model:
Quantity. Can you get enough high-quality data to train a model? Are labeled examples scarce, difficult to get, or too expensive? For instance, getting labeled medical images or translations of rare languages is notoriously hard. To make good predictions, classification models require numerous examples for every label. If the training dataset contains limited examples for some labels, the model can't make good predictions.
Feature availability at serving time. Will all the features used in training be available at serving time? Teams have spent considerable amounts of time training models only to realize that some features didn't become available until days after the model required them.
For example, suppose a model predicts whether a customer will click a URL, and one of the features used in training include
user_age. However, when the model serves a prediction,user_ageisn't available, perhaps because the user hasn't created an account yet.Regulations. What are the regulations and legal requirements for acquiring and using the data? For instance, some requirements set limits for storing and using certain types of data.
Generative AI
Pre-trained generative AI models often require curated datasets to excel at domain-specific tasks. You'll potentially need datasets for the following use cases:
-
Prompt engineering,
parameter efficient tuning, and
fine-tuning.
Depending on the use case, you might need between 10 and 10,000 high-quality
examples to further refine a model's output. For example, if a model needs
to be fine-tuned to excel at a particular task, like answering medical
questions, you'll need a high-quality dataset that's representative of
the kinds of questions it will be asked along with the types of answers it
should respond with.
The following table provides estimates for the number of examples needed to refine a generative AI model's output for a given technique:
-
Up-to-date information. Once pre-trained, generative AI models have
a fixed knowledge base. If content in the model's domain changes often,
you'll need a strategy to keep the model up-to-date, such as:
- fine-tuning
- retrieval-augmented generation (RAG)
- periodic pre-training
| Technique | Number of required examples |
|---|---|
| Zero-shot prompting | 0 |
| Few-shot prompting | ~10s–100s |
| Parameter efficient tuning 1 | ~100s–10,000s |
| Fine-tuning | ~1000s–10,000s (or more) |
Problem difficulty
A problem's difficulty can be hard to estimate. What initially appears to be a plausible approach might actually turn out to be an open research question; what seems practical and doable might turn out to be unrealistic or unworkable. Answering the following questions can help gauge a problem's difficulty:
Has a similar problem already been solved? For example, have teams in your organization used similar (or identical) data to build models? Have people or teams outside your organization solved similar problems, for instance, at Kaggle or TensorFlow Hub? If so, it's likely that you'll be able to use parts of their model to build yours.
Is the nature of the problem difficult? Knowing the human benchmarks for the task can inform the problem's level of difficulty. For example:
- Humans can classify the type of animal in an image at about 95% accuracy.
- Humans can classify handwritten digits at about 99% accuracy.
The preceding data suggests that creating a model to classify animals is more difficult than creating a model to classify handwritten digits.
Are there potentially bad actors? Will people be actively trying to exploit your model? If so, you'll be in a constant race to update the model before it can be misused. For instance, spam filters can't catch new types of spam when someone exploits the model to create emails that appear legitimate.
Generative AI
Generative AI models have potential vulnerabilities that can increase a problem's difficulty:
- Input source. Where will the input come from? Can adversarial prompts leak training data, preamble material, database content, or tool information?
- Output use. How will outputs be used? Will the model output raw content or will there be intermediary steps that test and verify it's appropriate? For example, providing raw output to plugins can cause a number of security issues.
- Fine-tuning. Fine-tuning with a corrupted dataset can negatively affect the model's weights. This corruption would cause the model to output incorrect, toxic, or biased content. As noted previously, fine-tuning requires a dataset that's been verified to contain high-quality examples.
Prediction quality
You'll want to carefully consider the impact a model's predictions will have on your users and determine the necessary prediction quality required for the model.
The required prediction quality depends upon the type of prediction. For instance, the prediction quality required for a recommendation system won't be the same for a model that flags policy violations. Recommending the wrong video might create a bad user experience. However, wrongly flagging a video as violating a platform's policies might generate support costs, or worse, legal fees.
Will your model need to have very high prediction quality because wrong predictions are extremely costly? Generally, the higher the required prediction quality, the harder the problem. Unfortunately, projects often reach diminishing returns as you try to improve quality. For instance, increasing a model's precision from 99.9% to 99.99% could mean a 10-times increase in the project's cost (if not more).
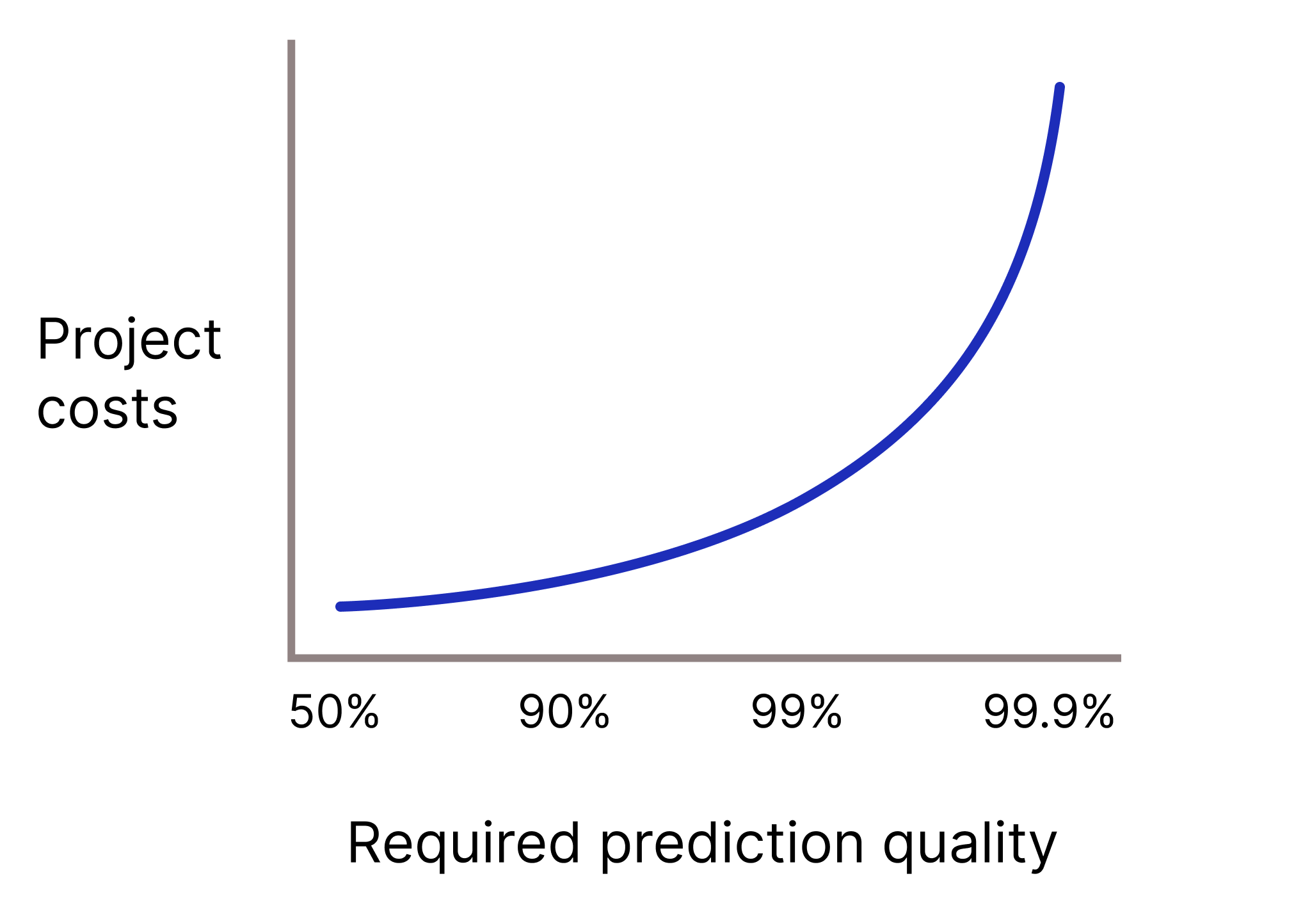
Figure 2. An ML project typically requires more and more resources as the required prediction quality increases.
Generative AI
When analyzing generative AI output, consider the following:
-
Factual accuracy. Although generative AI models can produce fluent
and coherent content, it's not guaranteed to be factual. False
statements from generative AI models are called
confabulations.
For example, generative AI models can confabulate and produce
incorrect summarizations of text, wrong answers to math questions,
or false statements about the world. Many use cases still
require human verification of generative AI output before being used
in a production environment, for example, LLM-generated code.
Like traditional ML, the higher the requirement for factual accuracy, the higher the cost to develop and maintain.
- Output quality. What are the legal and financial consequences (or ethical implications) of bad outputs, like biased, plagiarized, or toxic content?
Technical requirements
Models have a number of technical requirements that impact their feasibility. The following are the main technical requirements you'll need to address to determine your project's feasibility:
- Latency. What are the latency requirements? How fast do predictions need to be served?
- Queries per second (QPS). What are the QPS requirements?
- RAM usage. What are the RAM requirements for training and serving?
- Platform. Where will the model run: Online (queries sent to RPC server), WebML (inside a web browser), ODML (on a phone or tablet), or offline (predictions saved in a table)?
Interpretability. Will predictions need to be interpretable? For example, will your product need to answer questions like, "Why was a specific piece of content marked as spam?" or "Why was a video determined to violate the platform's policy?"
Retraining frequency. When the underlying data for your model changes rapidly, frequent or continuous retraining may be necessary. However, frequent retraining can lead to significant costs that may outweigh the benefits of updating the model's predictions.
In most cases, you'll probably have to compromise on a model's quality to adhere to its technical specifications. In those instances, you'll need to determine if you can still produce a model that's good enough to go to production.
Generative AI
Consider the following technical requirements when working with generative AI:
- Platform. Many pre-trained models come in a range of sizes, enabling them to work on a variety of platforms with different computational resources. For example, pre-trained models can range from data center scale to fitting on a phone. You'll need to consider your product or service's latency, privacy, and quality constraints when choosing a model size. These constraints can often conflict. For example, privacy constraints might require that inferences run on a user's device. However, the output quality might be poor because the device lacks the computational resources to produce good results.
- Latency. Model input and output size affects latency. In particular, output size affects latency more than input size. While models can parallelize their inputs, they can only generate outputs sequentially. In other words, the latency might be the same to ingest a 500-word or 10-word input, while generating a 500-word summary takes substantially longer than generating a 10-word summary.
- Tool and API use. Will the model need to use tools and APIs, like searching the internet, using a calculator, or accessing an email client to complete a task? Typically, the more tools needed to complete a task, the more chances exist for propagating mistakes and increasing the model's vulnerabilities.
Cost
Will an ML implementation be worth its costs? Most ML projects won't be approved if the ML solution is more expensive to implement and maintain than the money it generates (or saves). ML projects incur both human and machine costs.
Human costs. How many people will it take for the project to go from proof of concept to production? As ML projects evolve, expenses typically increase. For instance, ML projects require more people to deploy and maintain a production-ready system than to create a prototype. Try to estimate the number and kinds of roles the project will need at each phase.
Machine costs. Training, deploying, and maintaining models requires lots of compute and memory. For example, you might need TPU quota for training models and serving predictions, along with the necessary infrastructure for your data pipeline. You might have to pay to get data labeled or pay data licensing fees. Before training a model, consider estimating the machine costs for building and maintaining ML features for the long term.
Inference cost. Will the model need to make hundreds or thousands of inferences that cost more than the revenue generated?
Keep in mind
Encountering issues related to any of the previous topics can make implementing an ML solution a challenge, but tight deadlines can amplify the challenges. Try to plan and budget enough time based on the perceived difficulty of the problem, and then try to reserve even more overhead time than you might for a non-ML project.
Check Your Understanding
You work for a nature preservation company and manage the company's plant identification software. You want to create a model to classify 60 types of invasive plant species to help conservationists manage the habitats for endangered animals.
You found sample code that solves a similar plant identification problem, and the estimated costs to implement your solution are within the project's budget. While the dataset has lots of training examples, it has only a few for the five most invasive species. Leadership isn't requiring that the model's predictions be interpretable, and there doesn't appear to be negative consequences related to bad predictions. Is your ML solution feasible?