در تولید ML، هدف ساخت یک مدل واحد و به کارگیری آن نیست. هدف، ساخت خطوط لوله خودکار برای توسعه، آزمایش و استقرار مدلها در طول زمان است. چرا؟ با تغییر جهان، روند دادهها تغییر میکند و باعث میشود که مدلهای تولید کهنه شوند. مدلها معمولاً به بازآموزی با دادههای بهروز نیاز دارند تا به پیشبینیهای با کیفیت بالا در دراز مدت ادامه دهند. به عبارت دیگر، شما راهی برای جایگزینی مدل های قدیمی با مدل های تازه می خواهید.
بدون خطوط لوله، جایگزینی یک مدل قدیمی فرآیندی مستعد خطا است. به عنوان مثال، هنگامی که یک مدل شروع به ارائه پیشبینیهای بد میکند، شخصی باید دادههای جدید را به صورت دستی جمعآوری و پردازش کند، مدل جدیدی را آموزش دهد، کیفیت آن را تأیید کند و در نهایت آن را به کار گیرد. خطوط لوله ML بسیاری از این فرآیندهای تکراری را خودکار می کند و مدیریت و نگهداری مدل ها را کارآمدتر و قابل اعتمادتر می کند.
ساخت خطوط لوله
خطوط لوله ML مراحل ساخت و استقرار مدل ها را در وظایف کاملاً تعریف شده سازماندهی می کند. خطوط لوله یکی از دو عملکرد را دارند: ارائه پیش بینی یا به روز رسانی مدل.
ارائه پیش بینی ها
خط لوله سرویس دهی پیش بینی ها را ارائه می دهد. این مدل شما را در معرض دنیای واقعی قرار می دهد و آن را در دسترس کاربران شما قرار می دهد. به عنوان مثال، هنگامی که یک کاربر پیشبینی میخواهد – فردا چگونه آب و هوا خواهد بود، یا چند دقیقه طول میکشد تا به فرودگاه سفر کند، یا فهرستی از ویدیوهای توصیهشده – خط لوله سرویس دادههای کاربر را دریافت و پردازش میکند، پیشبینی میکند و سپس آن را به کاربر تحویل میدهد.
به روز رسانی مدل
مدلها تقریباً بلافاصله پس از شروع تولید، کهنه میشوند. در اصل، آنها با استفاده از اطلاعات قدیمی پیش بینی می کنند. مجموعه دادههای آموزشی آنها وضعیت جهان را یک روز پیش، یا در برخی موارد، یک ساعت پیش نشان میدهد. به ناچار جهان تغییر کرده است: کاربر ویدیوهای بیشتری را تماشا کرده است و به لیست جدیدی از توصیهها نیاز دارد. باران باعث کاهش ترافیک شده است و کاربران نیاز به برآوردهای به روز برای زمان رسیدن خود دارند. یک روند محبوب باعث می شود که خرده فروشان برای اقلام خاص پیش بینی موجودی به روز شده را درخواست کنند.
به طور معمول، تیم ها مدل های جدید را قبل از اینکه مدل تولیدی کهنه شود، آموزش می دهند. در برخی موارد، تیم ها روزانه مدل های جدید را در یک چرخه آموزش و استقرار مداوم آموزش می دهند و مستقر می کنند. در حالت ایده آل، آموزش یک مدل جدید باید قبل از اینکه مدل تولیدی کهنه شود، اتفاق بیفتد.
خطوط لوله زیر برای آموزش یک مدل جدید با هم کار می کنند:
- خط لوله داده . خط لوله داده، داده های کاربر را برای ایجاد مجموعه داده های آموزشی و آزمایشی پردازش می کند.
- خط لوله آموزشی . خط لوله آموزشی با استفاده از مجموعه داده های آموزشی جدید از خط لوله داده، مدل ها را آموزش می دهد.
- خط لوله اعتبار سنجی خط لوله اعتبار سنجی مدل آموزش دیده را با مقایسه آن با مدل تولید با استفاده از مجموعه داده های آزمایشی تولید شده توسط خط لوله داده تایید می کند.
شکل 4 ورودی و خروجی هر خط لوله ML را نشان می دهد.
خطوط لوله ML
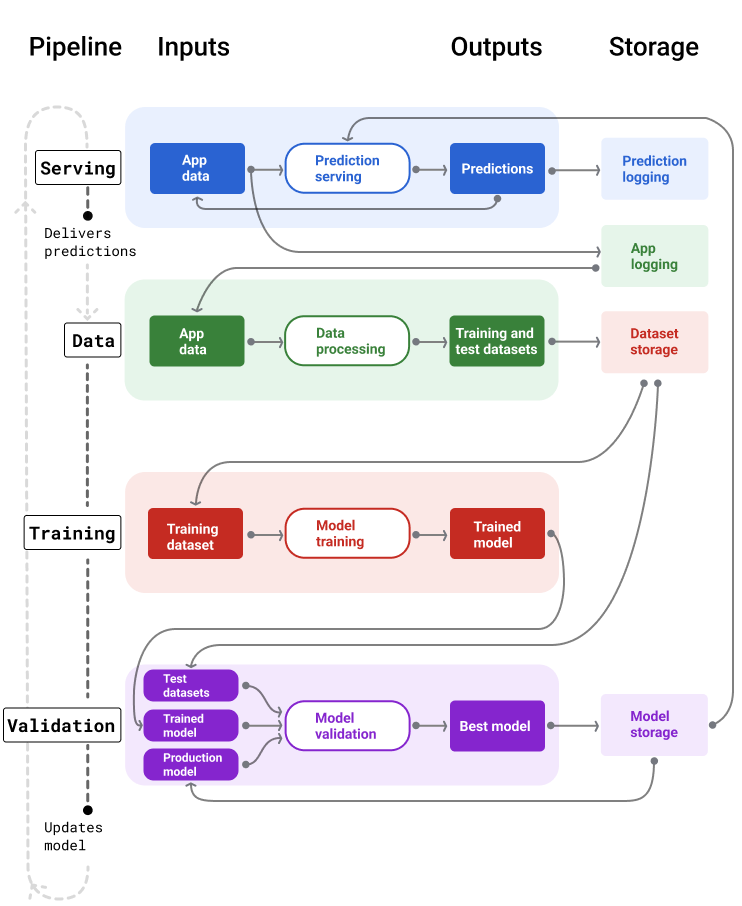
شکل 4 . خطوط لوله ML بسیاری از فرآیندها را برای توسعه و نگهداری مدل ها خودکار می کند. هر خط لوله ورودی و خروجی خود را نشان می دهد.
در یک سطح بسیار کلی، در اینجا آمده است که چگونه خطوط لوله یک مدل جدید را در تولید نگه میدارند:
ابتدا، یک مدل وارد تولید می شود و خط لوله سرویس دهنده شروع به ارائه پیش بینی ها می کند.
خط لوله داده بلافاصله شروع به جمع آوری داده ها برای تولید مجموعه داده های آموزشی و آزمایشی جدید می کند.
بر اساس یک برنامه زمانبندی یا یک محرک، خطوط لوله آموزشی و اعتبارسنجی مدل جدیدی را با استفاده از مجموعه دادههای تولید شده توسط خط لوله داده، آموزش میدهند و اعتبارسنجی میکنند.
وقتی خط لوله اعتبارسنجی تأیید کرد که مدل جدید بدتر از مدل تولیدی نیست، مدل جدید مستقر می شود.
این روند به طور مداوم تکرار می شود.
بیات بودن مدل و فرکانس تمرین
تقریباً همه مدل ها کهنه می شوند. برخی از مدل ها سریعتر از بقیه کهنه می شوند. برای مثال، مدلهایی که لباسها را توصیه میکنند، معمولاً به سرعت کهنه میشوند، زیرا ترجیحات مصرفکننده به دلیل تغییر مکرر بدنام است. از سوی دیگر، مدل هایی که گل ها را شناسایی می کنند ممکن است هرگز کهنه نشوند. ویژگی های شناسایی گل ثابت می ماند.
اکثر مدل ها بلافاصله پس از تولید شروع به کهنه شدن می کنند. شما می خواهید یک فرکانس آموزشی ایجاد کنید که ماهیت داده های شما را منعکس کند. اگر داده ها پویا هستند، اغلب تمرین کنید. اگر پویایی کمتری داشته باشد، ممکن است نیازی به تمرین زیاد نداشته باشید.
مدلها را قبل از کهنه شدن آموزش دهید. آموزش اولیه یک بافر برای حل مشکلات احتمالی فراهم می کند، به عنوان مثال، اگر داده ها یا خط لوله آموزشی از کار بیفتد، یا کیفیت مدل ضعیف باشد.
بهترین روش توصیه شده آموزش و استقرار مدل های جدید به صورت روزانه است. درست مانند پروژههای نرمافزاری معمولی که فرآیند ساخت و انتشار روزانه دارند، خطوط لوله ML برای آموزش و اعتبارسنجی اغلب زمانی بهترین عملکرد را دارند که روزانه اجرا شوند.
درک خود را بررسی کنید
خط لوله خدمات رسانی
خط لوله سرویسدهی پیشبینیها را به یکی از دو روش تولید و ارائه میکند: آنلاین یا آفلاین.
پیش بینی های آنلاین پیشبینیهای آنلاین در زمان واقعی اتفاق میافتند، معمولاً با ارسال یک درخواست به یک سرور آنلاین و بازگرداندن یک پیشبینی. به عنوان مثال، هنگامی که یک کاربر پیش بینی می خواهد، داده های کاربر به مدل ارسال می شود و مدل پیش بینی را برمی گرداند.
پیش بینی های آفلاین پیش بینی های آفلاین از قبل محاسبه و ذخیره می شوند. برای ارائه یک پیشبینی، برنامه پیشبینی ذخیرهشده را در پایگاه داده پیدا کرده و آن را برمیگرداند. به عنوان مثال، یک سرویس مبتنی بر اشتراک ممکن است نرخ ریزش را برای مشترکین خود پیش بینی کند. این مدل احتمال خراشیدن را برای هر مشترک پیشبینی میکند و آن را در حافظه پنهان ذخیره میکند. هنگامی که برنامه به پیش بینی نیاز دارد - به عنوان مثال، برای تشویق کاربرانی که ممکن است در شرف انحراف باشند - فقط پیش بینی از پیش محاسبه شده را جستجو می کند.
شکل 5 نشان می دهد که چگونه پیش بینی های آنلاین و آفلاین تولید و ارائه می شوند.
پیش بینی های آنلاین و آفلاین
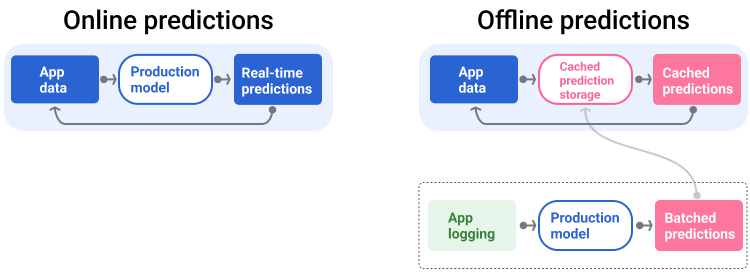
شکل 5 . پیش بینی های آنلاین پیش بینی ها را در زمان واقعی ارائه می دهند. پیشبینیهای آفلاین در حافظه پنهان ذخیره میشوند و در زمان ارائه خدمات جستجو میشوند.
پیشبینی پس پردازش
به طور معمول، پیشبینیها قبل از تحویل پس پردازش میشوند. برای مثال، پیشبینیها ممکن است پس از پردازش برای حذف محتوای سمی یا مغرضانه انجام شوند. نتایج طبقه بندی ممکن استیک فرآیند را طی کنیدبهعنوان مثال، برای تقویت محتوای معتبرتر، ارائه تنوعی از نتایج، کاهش نتایج خاص (مانند کلیک طعمه)، یا حذف نتایج به دلایل قانونی، به جای نشان دادن خروجی خام مدل، ترتیببندی مجدد نتایج را انجام دهید.
شکل 6 خط لوله سرویس دهی و وظایف معمولی درگیر در ارائه پیش بینی ها را نشان می دهد.
پیش بینی های پس از پردازش
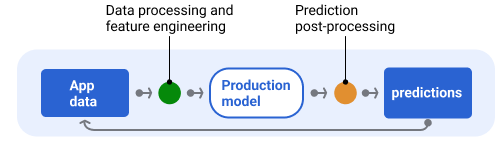
شکل 6 . سرویس خط لوله که وظایف معمولی را برای ارائه پیشبینیها نشان میدهد.
توجه داشته باشید که مرحله مهندسی ویژگی معمولاً در مدل ساخته شده است و نه یک فرآیند جداگانه و مستقل. کد پردازش داده در خط لوله سرویس دهی اغلب تقریباً مشابه کد پردازش داده ای است که خط لوله داده برای ایجاد آموزش و مجموعه داده های آزمایشی استفاده می کند.
ذخیره سازی دارایی ها و ابرداده ها
خط لوله سرویس دهی باید دارای یک مخزن برای ثبت پیش بینی های مدل و در صورت امکان، حقیقت زمین باشد.
ثبت پیشبینیهای مدل به شما امکان میدهد کیفیت مدل خود را نظارت کنید. با جمعآوری پیشبینیها، میتوانید کیفیت کلی مدل خود را کنترل کنید و تعیین کنید که آیا کیفیت آن کم شده است یا خیر. به طور کلی، پیشبینیهای مدل تولید باید میانگین یکسانی با برچسبهای مجموعه داده آموزشی داشته باشد. برای اطلاعات بیشتر، پیشبینی سوگیری را ببینید.
گرفتن حقیقت زمین
در برخی موارد، حقیقت زمینی بسیار دیرتر در دسترس قرار می گیرد. به عنوان مثال، اگر یک برنامه هواشناسی آب و هوا را شش هفته بعد از آینده پیش بینی کند، حقیقت زمین (آب و هوا در واقع چیست) به مدت شش هفته در دسترس نخواهد بود.
در صورت امکان، کاربران را وادار کنید تا با افزودن مکانیسمهای بازخورد به برنامه، حقیقت اصلی را گزارش کنند. هنگامی که کاربران نامهها را از صندوق ورودی خود به پوشه هرزنامه خود منتقل میکنند، یک برنامه ایمیل میتواند به طور ضمنی بازخورد کاربر را دریافت کند. با این حال، این تنها زمانی کار می کند که کاربر ایمیل های خود را به درستی دسته بندی کند. وقتی کاربران هرزنامه را در صندوق ورودی خود میگذارند (چون میدانند هرزنامه است و هرگز آن را باز نمیکنند)، دادههای آموزشی نادرست میشوند. آن نامه خاص در حالی که باید "هرزنامه" باشد، برچسب "نه هرزنامه" خواهد بود. به عبارت دیگر، همیشه سعی کنید راه هایی برای ثبت و ضبط حقیقت بیابید ، اما از کاستی هایی که ممکن است در مکانیسم های بازخورد وجود داشته باشد، آگاه باشید.
شکل 7 پیش بینی هایی را نشان می دهد که به یک کاربر تحویل داده شده و در یک مخزن ثبت شده اند.
پیش بینی های ثبت نام
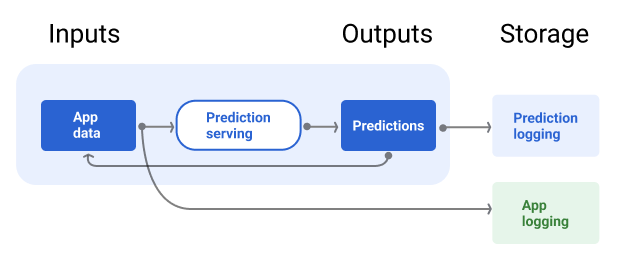
شکل 7 . ثبت پیشبینیها برای نظارت بر کیفیت مدل.
خطوط لوله داده
خطوط لوله داده، مجموعه داده های آموزشی و آزمایشی را از داده های برنامه تولید می کنند. خطوط لوله آموزش و اعتبارسنجی سپس از مجموعه داده ها برای آموزش و اعتبارسنجی مدل های جدید استفاده می کنند.
خط لوله داده مجموعه دادههای آموزشی و آزمایشی را با همان ویژگیها و برچسبی که در ابتدا برای آموزش مدل استفاده میشد، اما با اطلاعات جدیدتر ایجاد میکند. به عنوان مثال، یک برنامه نقشه مجموعه دادههای آموزشی و آزمایشی را از زمانهای سفر اخیر بین نقاط برای میلیونها کاربر، همراه با سایر دادههای مرتبط، مانند آب و هوا، تولید میکند.
یک برنامه توصیه ویدیویی مجموعه دادههای آموزشی و آزمایشی را تولید میکند که شامل ویدیوهایی میشود که کاربر از لیست توصیهشده روی آنها کلیک کرده است (همراه با مواردی که کلیک نکردهاند)، و همچنین سایر دادههای مرتبط، مانند سابقه تماشا.
شکل 8 خط لوله داده را با استفاده از داده های برنامه برای تولید آموزش و مجموعه داده های آزمایشی نشان می دهد.
خط لوله داده
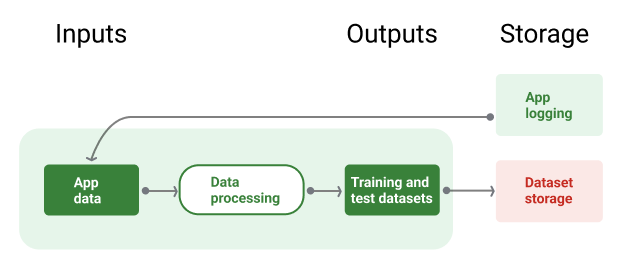
شکل 8 . خط لوله داده، داده های برنامه را برای ایجاد مجموعه داده برای خطوط لوله آموزشی و اعتبار سنجی پردازش می کند.
جمع آوری و پردازش داده ها
وظایف جمع آوری و پردازش داده ها در خطوط لوله داده احتمالاً با مرحله آزمایش (جایی که تشخیص دادید که راه حل شما امکان پذیر است) متفاوت خواهد بود.
جمع آوری داده ها . در طول آزمایش، جمع آوری داده ها معمولاً نیازمند دسترسی به داده های ذخیره شده است. برای خطوط لوله داده، جمعآوری دادهها ممکن است به کشف و دریافت تأییدیه برای دسترسی به دادههای گزارشهای جریان نیاز داشته باشد.
اگر به دادههای دارای برچسب انسانی (مانند تصاویر پزشکی) نیاز دارید، به فرآیندی برای جمعآوری و بهروزرسانی آنها نیز نیاز دارید.
پردازش داده ها . در طول آزمایش، ویژگی های مناسب از خراش دادن، پیوستن، و نمونه برداری از مجموعه داده های آزمایش به دست آمد. برای خطوط لوله داده، تولید همان ویژگی ها ممکن است به فرآیندهای کاملاً متفاوتی نیاز داشته باشد. با این حال، مطمئن شوید که تبدیل داده ها را از مرحله آزمایش با اعمال همان عملیات ریاضی روی ویژگی ها و برچسب ها کپی کنید.
ذخیره سازی دارایی ها و ابرداده ها
شما به فرآیندی برای ذخیره سازی، نسخه سازی و مدیریت مجموعه داده های آموزشی و آزمایشی خود نیاز دارید. مخازن کنترل شده با نسخه مزایای زیر را ارائه می دهند:
تکرارپذیری بازآفرینی و استانداردسازی محیط های آموزشی مدل و مقایسه کیفیت پیش بینی در بین مدل های مختلف.
رعایت . به الزامات انطباق با مقررات برای قابلیت حسابرسی و شفافیت پایبند باشید.
حفظ . مقادیر نگهداری داده را برای مدت زمان ذخیره داده ها تنظیم کنید.
مدیریت دسترسی از طریق مجوزهای دقیق، افرادی را که می توانند به داده های شما دسترسی داشته باشند، مدیریت کنید.
یکپارچگی داده ها . ردیابی و درک تغییرات مجموعه داده ها در طول زمان، تشخیص مشکلات مربوط به داده ها یا مدل شما را آسان تر می کند.
قابلیت کشف یافتن مجموعه داده ها و ویژگی های شما را برای دیگران آسان کنید. سپس تیم های دیگر می توانند تعیین کنند که آیا آنها برای اهدافشان مفید هستند یا خیر.
مستندسازی داده های شما
اسناد خوب به دیگران کمک می کند تا اطلاعات کلیدی در مورد داده های شما مانند نوع، منبع، اندازه و سایر ابرداده های ضروری را درک کنند. در بیشتر موارد، مستندسازی داده های خود در یک سند طراحی کافی است. اگر قصد دارید داده های خود را به اشتراک بگذارید یا منتشر کنید، استفاده کنیدکارت های دادهبرای ساختار دادن به اطلاعات کارت های داده کشف و درک مجموعه داده های شما را برای دیگران آسان تر می کند.
خطوط لوله آموزشی و اعتبارسنجی
خطوط لوله آموزش و اعتبارسنجی مدلهای جدیدی را برای جایگزینی مدلهای تولیدی قبل از کهنه شدن تولید میکنند. آموزش مداوم و اعتبارسنجی مدل های جدید تضمین می کند که بهترین مدل همیشه در حال تولید است.
خط لوله آموزشی یک مدل جدید از مجموعه داده های آموزشی تولید می کند و خط لوله اعتبار سنجی کیفیت مدل جدید را با مدلی که در حال تولید است با استفاده از مجموعه داده های آزمایشی مقایسه می کند.
شکل 9 خط لوله آموزشی را با استفاده از مجموعه داده های آموزشی برای آموزش یک مدل جدید نشان می دهد.
خط لوله آموزشی
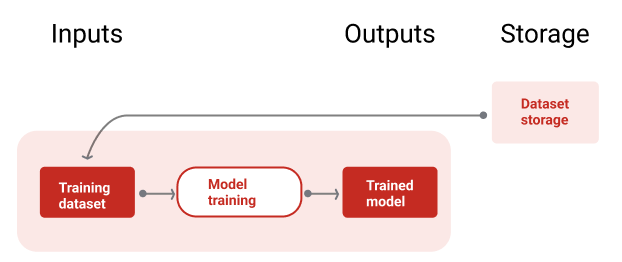
شکل 9 . خط لوله آموزشی با استفاده از جدیدترین مجموعه داده های آموزشی، مدل های جدیدی را آموزش می دهد.
پس از آموزش مدل، خط لوله اعتبارسنجی از مجموعه داده های آزمایشی برای مقایسه کیفیت مدل تولید با مدل آموزش دیده استفاده می کند.
به طور کلی، اگر مدل آموزش دیده به طور معناداری بدتر از مدل تولیدی نباشد، مدل آموزش دیده وارد تولید می شود. اگر مدل آموزش دیده بدتر است، زیرساخت نظارت باید یک هشدار ایجاد کند. مدلهای آموزشدیده با کیفیت پیشبینی بدتر میتوانند مشکلات بالقوه را در خطوط لوله داده یا اعتبارسنجی نشان دهند. این رویکرد برای اطمینان از اینکه بهترین مدل آموزش دیده بر روی تازه ترین داده ها همیشه در حال تولید است کار می کند.
ذخیره سازی دارایی ها و ابرداده ها
مدلها و ابردادههای آنها باید در مخازن نسخهسازیشده ذخیره شوند تا استقرار مدلها را سازماندهی و پیگیری کنند. مخازن مدل مزایای زیر را ارائه می دهند:
پیگیری و ارزیابی . ردیابی مدل ها در تولید و درک معیارهای کیفیت ارزیابی و پیش بینی آنها.
فرآیند انتشار مدل مدلها را بهآسانی بررسی، تأیید، انتشار یا بازگردانی کنید.
تکرارپذیری و اشکال زدایی . با ردیابی مجموعه دادهها و وابستگیهای مدل در سراسر استقرار، نتایج مدل را بازتولید کنید و مشکلات را بهطور مؤثرتر رفع اشکال کنید.
قابلیت کشف پیدا کردن مدل شما را برای دیگران آسان کنید. سپس تیم های دیگر می توانند تعیین کنند که آیا مدل شما (یا قسمت هایی از آن) می تواند برای اهداف خود استفاده شود یا خیر.
شکل 10 یک مدل معتبر ذخیره شده در یک مخزن مدل را نشان می دهد.
ذخیره سازی مدل
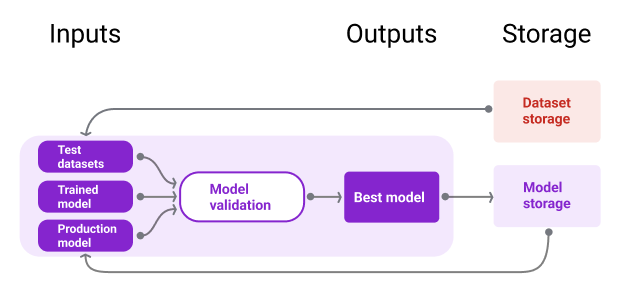
شکل 10 . مدل های تایید شده برای ردیابی و کشف در یک مخزن مدل ذخیره می شوند.
استفاده کنیدکارت های مدلبرای مستندسازی و به اشتراک گذاری اطلاعات کلیدی در مورد مدل خود، مانند هدف، معماری، الزامات سخت افزاری، معیارهای ارزیابی و غیره.
درک خود را بررسی کنید
ایجاد خطوط لوله را به چالش می کشد
هنگام ساخت خطوط لوله، ممکن است با چالش های زیر روبرو شوید:
دسترسی به داده هایی که نیاز دارید . دسترسی به دادهها ممکن است نیاز به توجیه این داشته باشد که چرا به آن نیاز دارید. به عنوان مثال، ممکن است لازم باشد توضیح دهید که چگونه از داده ها استفاده می شود و نحوه حل مسائل مربوط به اطلاعات هویتی شخصی (PII) را روشن کنید. برای نشان دادن اثبات مفهومی که نشان می دهد مدل شما چگونه پیش بینی های بهتری را با دسترسی به انواع خاصی از داده ها انجام می دهد، آماده باشید.
دریافت ویژگی های مناسب در برخی موارد، ویژگیهای مورد استفاده در مرحله آزمایش از دادههای بلادرنگ در دسترس نخواهد بود. بنابراین، هنگام آزمایش، سعی کنید تأیید کنید که می توانید همان ویژگی ها را در تولید به دست آورید.
درک نحوه جمع آوری و نمایش داده ها . یادگیری نحوه جمعآوری دادهها، افرادی که آنها را جمعآوری کردهاند و نحوه جمعآوری آنها (همراه با مسائل دیگر) میتواند زمان و تلاش داشته باشد. درک کامل داده ها مهم است. از داده هایی که به آنها اطمینان ندارید برای آموزش مدلی که ممکن است به تولید برسد استفاده نکنید.
درک معاوضه بین تلاش، هزینه و کیفیت مدل . گنجاندن یک ویژگی جدید در خط لوله داده می تواند به تلاش زیادی نیاز داشته باشد. با این حال، ویژگی اضافی ممکن است فقط کمی کیفیت مدل را بهبود بخشد. در موارد دیگر، افزودن یک ویژگی جدید ممکن است آسان باشد. با این حال، منابع دریافت و ذخیره این ویژگی ممکن است بسیار گران باشد.
محاسبه کردن اگر برای بازآموزی به TPU نیاز دارید، ممکن است کسب سهمیه مورد نیاز دشوار باشد. همچنین، مدیریت TPU ها پیچیده است. برای مثال، برخی از بخشهای مدل یا دادههای شما ممکن است نیاز داشته باشند که بهطور خاص برای TPUها با تقسیم بخشهایی از آنها در چند تراشه TPU طراحی شوند.
یافتن مجموعه داده طلایی مناسب اگر داده ها به طور مکرر تغییر کنند، دریافت مجموعه داده های طلایی با برچسب های سازگار و دقیق می تواند چالش برانگیز باشد.
کشف این نوع مشکلات در طول آزمایش باعث صرفه جویی در زمان می شود. برای مثال، شما نمیخواهید بهترین ویژگیها و مدلها را فقط برای اینکه بدانید در تولید قابل دوام نیستند، توسعه دهید. بنابراین، سعی کنید هرچه زودتر تأیید کنید که راه حل شما در چارچوب محدودیت های یک محیط تولید کار می کند. بهتر است به جای نیاز به بازگشت به مرحله آزمایش، زمانی را صرف تأیید کارکرد یک راه حل کنید، زیرا فاز خط لوله مشکلات غیر قابل حلی را آشکار کرد.