Für die datengetriebene Gesundheitsversorgung ist es wichtig, schnell zuverlässige, umsetzbare Informationen zu generieren.
Der FHIR-Standard bietet Entwicklern, die digitale Gesundheitslösungen der nächsten Generation entwickeln, viele Vorteile. Die stark verschachtelte Struktur kann jedoch die Analyse erschweren.
Um Entwicklern die Entwicklung von Lösungen zu erleichtern, die die Arbeit mit FHIR-Daten vereinfachen, stellen wir FHIR Data Pipes bereit, eine Reihe von Tools: ETL-Pipelines zum Konvertieren von Ressourcen in das Parquet-on-FHIR-Schema, eine Ansichtsdefinition und Query Engine-Connectors.
FHIR Data Pipes ist für horizontale Skalierbarkeit und flexible Bereitstellungsoptionen (lokal oder in der Cloud) konzipiert. Gleichzeitig kann es auf einem einzelnen Computer bereitgestellt werden.
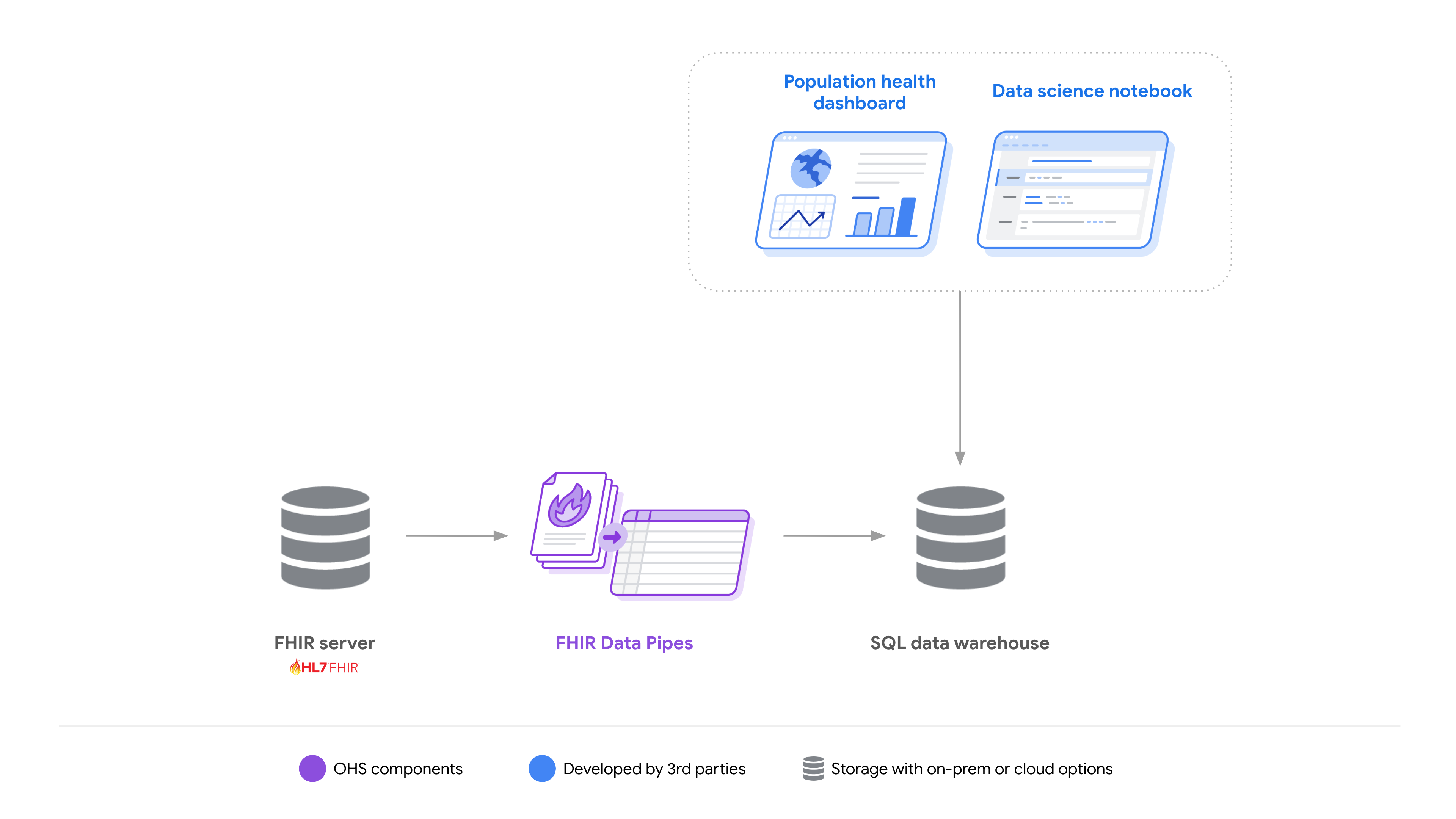
Zusammen erleichtern sie es Entwicklern, Analyselösungen mit verschiedenen Technologien für eine Vielzahl von Anwendungsfällen zu erstellen und bereitzustellen.
Weitere Informationen zu FHIR-Datenpipes und ihren Komponenten: